Das IaC-Modell (Infrastructure as a Code), manchmal auch als "programmierbare Infrastruktur" bezeichnet, ist ein Modell, bei dem der Konfigurationsprozess der Infrastruktur dem Softwareprogrammierungsprozess ähnlich ist. Im Wesentlichen war dies der Beginn des Aufhebens der Grenzen zwischen dem Schreiben von Anwendungen und dem Erstellen von Umgebungen für diese Anwendungen. Anwendungen können Skripte enthalten, die ihre eigenen virtuellen Maschinen erstellen und verwalten. Dies ist die Grundlage des Cloud Computing und ein wesentlicher Bestandteil von DevOps.
Mit Infrastruktur als Code können Sie virtuelle Maschinen auf Softwareebene verwalten. Dadurch sind keine manuellen Konfigurationen und Aktualisierungen für einzelne Gerätekomponenten erforderlich. Die Infrastruktur wird extrem „belastbar“, dh reproduzierbar und skalierbar. Ein Bediener kann sowohl einen als auch 1000 Computer mit demselben Codesatz bereitstellen und verwalten. Zu den garantierten Vorteilen der Infrastruktur als Code zählen Geschwindigkeit, Kosteneffizienz und Risikominderung.
Genau darum geht es bei der Dekodierung von Kirill Vetchinkins Bericht bei DevOpsDays Moscow 2018. Der Bericht: Wiederverwendung von Ansible-Modulen, Speicherung in Git, Überprüfung, Neuerstellung, finanzielle Vorteile, horizontale Skalierung mit einem Klick.
Wen kümmert es bitte unter der Katze.
Hallo an alle. Wie bereits gesagt, bin ich Vetchinkin Kirill. Ich arbeite bei TYME und heute werden wir über Infrastruktur als Code sprechen. Wir werden auch darüber sprechen, wie wir gelernt haben, bei dieser Praxis zu sparen, weil sie ziemlich teuer ist. Das Schreiben einer Menge Code ist ziemlich teuer, um die Infrastruktur einzurichten.
Ich werde kurz über das Unternehmen sprechen. Ich arbeite bei TYME. Wir hatten ein Rebranding. Jetzt heißen wir PaySystem - wie der Name schon sagt, beschäftigen wir uns mit Zahlungssystemen. Wir haben unsere eigenen Lösungen - dies sind Verarbeitungen und kundenspezifische Entwicklungen. Kundenspezifische Entwicklung ist E-Banking, Abrechnung und dergleichen. Und wie Sie wissen, wenn es sich um eine kundenspezifische Entwicklung handelt, handelt es sich jedes Jahr um eine große Anzahl von Projekten. Das Projekt folgt dem Projekt. Je mehr Projekte, desto mehr Infrastruktur des gleichen Typs muss aufgebaut werden. Da Projekte häufig stark ausgelastet sind, verwenden wir die Microservice-Architektur. Daher gibt es in einem Projekt viele, viele kleine Teilprojekte.

Dementsprechend ist es sehr schwierig, diesen gesamten Zoo ohne vollständige DevOps zu verwalten. Daher hat unser Unternehmen verschiedene DevOps-Praktiken implementiert. Natürlich arbeiten wir an Kanban, an SCRUM speichern wir alles in Git. Nach dem Festschreiben erfolgt eine kontinuierliche Integration, Tests werden ausgeführt. Tester schreiben End-to-End-Tests auf PyTest, die jede Nacht beginnen. Der Unit-Test beginnt nach jedem Commit. Wir verwenden einen separaten Erstellungs- und Bereitstellungsprozess: Zusammengesetzt und dann viele Male in verschiedenen Umgebungen bereitgestellt. Wir waren an Fenstern. Unter Windows, das wir mit Octopus Deploy bereitgestellt haben, entwickeln wir dieses Jahr auf DotNet Core. Daher können wir jetzt Software auf Linux-Systemen ausführen. Wir verließen Octopus und kamen zu Ansible. Heute werden wir über diesen Teil sprechen, eine neue Praxis, die wir in diesem Jahr entwickelt haben, etwas, das wir vorher nicht hatten. Wenn Sie Tests haben und wissen, wie man die Anwendung gut erstellt, ist es in Ordnung, sie irgendwo bereitzustellen. Wenn Sie jedoch zwei Umgebungen unterschiedlich konfiguriert haben, fallen Sie immer noch und fallen in die Produktion. Daher ist das Verwalten von Konfigurationen eine sehr wichtige Praxis. Darüber werden wir heute sprechen.

Ich werde kurz beschreiben, wie die Arbeitsökonomie des Produkts aufgebaut ist: 60 Prozent werden für die Entwicklung ausgegeben, die Analyse dauert etwa 10 Prozent, die Qualitätssicherung (Testen) dauert etwa 20 Prozent, und alles andere wird der Konfiguration zugewiesen. Wenn die Systeme in vollem Gange sind, verfügen sie über viele Software von Drittanbietern. Die Betriebssysteme selbst sind fast gleich konfiguriert. Wir verbringen zusätzliche Zeit damit und tun im Wesentlichen das Gleiche. Es gab die Idee, alles zu automatisieren und die Kosten für die Konfiguration der Infrastruktur zu senken. Ähnliche Aufgaben sind automatisiert, gut getestet und enthalten keine manuellen Vorgänge.

Jede Anwendung funktioniert in einer Umgebung. Mal sehen, woraus das alles besteht. Zumindest müssen wir ein Betriebssystem haben , es muss konfiguriert werden, es gibt einige Anwendungen von Drittanbietern , die ebenfalls konfiguriert werden müssen, die Anwendung selbst muss die Konfigurationen erhalten, aber damit das gesamte Produkt funktioniert, muss die Anwendung selbst gestartet werden, die in diesem gesamten System ausgeführt wird. Es gibt auch ein Netzwerk , das ebenfalls konfiguriert werden muss, aber wir werden heute nicht über das Netzwerk sprechen, da wir unterschiedliche Kunden und unterschiedliche Netzwerkgeräte haben. Wir haben auch versucht, die Netzwerkkonfiguration zu automatisieren, aber da die Geräte unterschiedlich sind, gab es keinen besonderen Vorteil, wir haben mehr Ressourcen dafür ausgegeben. Wir haben jedoch die Betriebssysteme, Anwendungen von Drittanbietern und die Übertragung von Konfigurationsparametern auf die Anwendungen selbst automatisiert.

Es gibt zwei Ansätze, wie Sie die Server konfigurieren können: von Hand - Wenn Sie sie von Hand konfigurieren, kann es dementsprechend zu einer solchen Situation kommen, dass Sie die Produktion auf die eine Weise konfiguriert haben, den Test auf die andere, beim Test ist alles grün, die Tests sind grün. Sie stellen für die Produktion bereit und es gibt dort kein Framework - nichts funktioniert für Sie. Ein weiteres Beispiel: Drei Anwendungsserver werden von Hand konfiguriert. Ein Anwendungsserver wurde auf eine Weise konfiguriert, ein anderer Anwendungsserver auf eine andere Weise. Server können auf verschiedene Arten arbeiten. Ein weiteres Beispiel: Es gab eine Situation, in der ein Stage-Server für uns nicht mehr funktionierte. Wir haben angefangen, einen neuen Server mit zu erstellen, und nach 30 war der Server bereit. Ein weiteres Beispiel: Der Server hat gerade aufgehört zu arbeiten. Wenn Sie es mit Ihren Händen einrichten, müssen Sie nach einer Person suchen, die weiß, wie man es konfiguriert, und die Dokumentation erstellen. Wie wir wissen, ist die Dokumentation kaum relevant. Das sind große Probleme. Und vor allem handelt es sich um ein Audit. Das heißt, Sie haben ungefähr zehn Administratoren, von denen jeder etwas mit seinen Händen einrichtet. Es ist nicht ganz klar, ob sie es richtig oder falsch eingerichtet haben und wie Sie verstehen, ob dann könnten die Einstellungen, sie etwas überflüssiges setzen, einige unnötige Ports öffnen.

Es gibt eine alternative Option - genau das ist es, worüber wir heute sprechen - dies ist die Konfiguration aus Code. Das heißt, wir haben ein Git-Repository, in dem die gesamte Infrastruktur gespeichert ist. Dort werden alle Skripte gespeichert, mit deren Hilfe wir sie konfigurieren. Da dies alles in git ist, erhalten wir alle Vorteile des Code-Managements, wie in der Entwicklung, dh wir können Überprüfungen, Audits durchführen, den Verlauf ändern, wer es getan hat, warum es getan hat, Kommentare, wir können ein Rollback durchführen. Um mit dem Code arbeiten zu können, müssen Sie die Pipeline für die fortlaufende Assembly verwenden - die Bereitstellungspipeline. Damit ein bestimmtes System Änderungen an den Servern vornehmen kann, würde nicht eine Person etwas mit ihren Händen tun, sondern das System würde dies ausschließlich tun.

Als das System, das die Änderungen vornimmt, verwenden wir Ansible. Da wir nicht viele Server haben, ist es für uns durchaus geeignet. Wenn Sie dort 100 bis 200 Server haben, treten kleine Probleme auf, da diese (d. H. Ansible) weiterhin eine Verbindung zu den einzelnen Servern herstellen und diese nacheinander konfigurieren - dies ist ein Problem. Es ist besser, andere Mittel zu verwenden, die nicht drücken, sondern ziehen. Aber für unsere Geschichte, wenn wir viele Projekte haben, aber nicht mehr als 20 Server, ist dies für uns durchaus geeignet. Ansible hat ein großes Plus - es ist eine niedrige Einstiegsschwelle. Das heißt, buchstäblich jeder IT-Spezialist in drei Wochen kann es vollständig beherrschen. Er hat viele Module. Das heißt, Sie können die Clouds, Netzwerke, Dateien verwalten, Programme installieren, bereitstellen - absolut alles. Wenn es keine Module gibt, können Sie Ihre eigenen schreiben, Sie können schließlich etwas mit der Ansible-Shell oder dem Befehlsmodul schreiben.

Im Allgemeinen werden wir kurz darauf eingehen, wie es im Allgemeinen aussieht, dieses Tool. Ansible hat Module, über die ich bereits gesprochen habe. Das heißt, sie können geliefert werden, von sich selbst geschrieben, die etwas tun. Es gibt Inventare - hier werden wir unsere Änderungen vornehmen, dh dies sind die Hosts, ihre IP-Adressen und Variablen, die für diese Hosts spezifisch sind. Und dementsprechend die Rolle. Rollen sind das, was wir auf diesen Servern rollen werden. Und auch unsere Hosts sind in Gruppen gruppiert, dh in diesem Fall haben wir zwei Gruppen: den Datenbankserver und den Anwendungsserver. In jeder Gruppe haben wir drei Autos. Sie sind über ssh verbunden. Damit lösen wir die Probleme, über die wir zuvor gesprochen haben, dass unsere Server zunächst identisch konfiguriert sind, da dieselbe Rolle auf die Server übertragen wird. Wenn wir diese Rolle auf mehreren Computern ausführen, funktioniert sie für jeden auf dieselbe Weise.
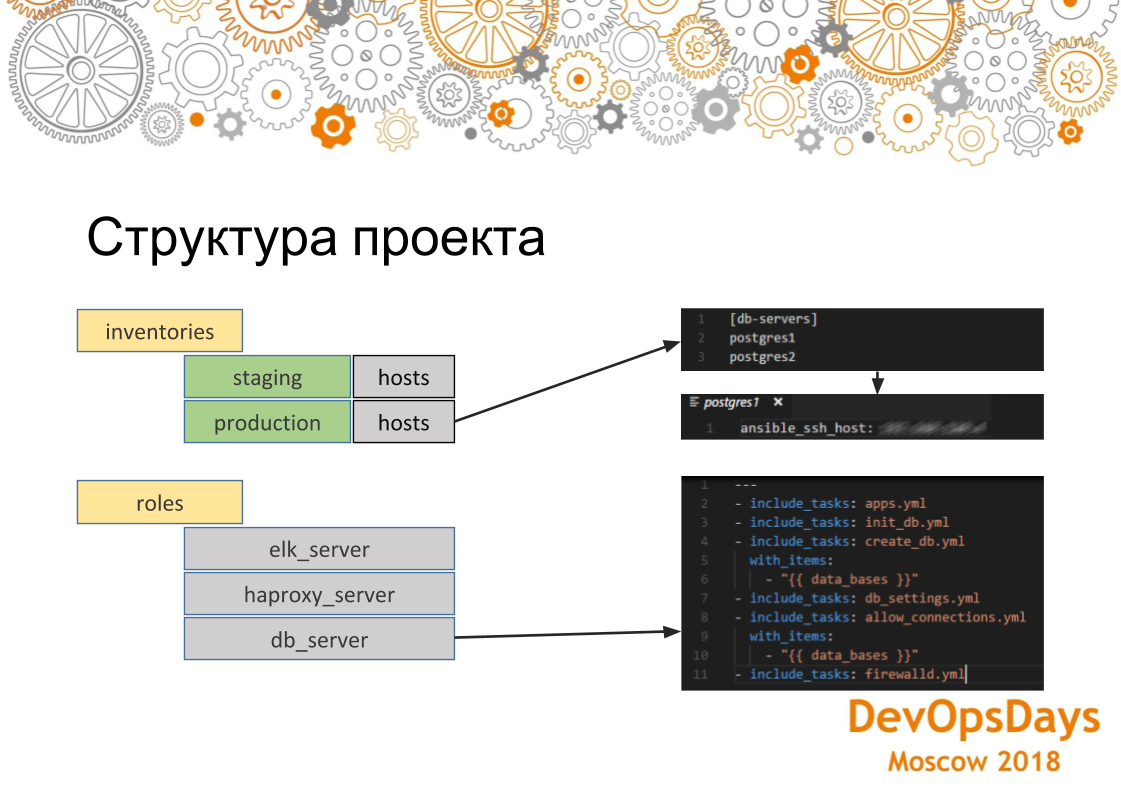
Wenn wir uns die Struktur des Ansible-Projekts genauer ansehen, sehen wir hier, dass Hosts für Produktionsinventare akzeptabel sind. Diese Gruppe wird angezeigt und enthält zwei Server. Wenn wir zu einem bestimmten Server gehen, sehen wir, dass die IP-Adresse dieses Computers hier angegeben ist. Dort können auch andere Parameter angegeben werden - für diese Umgebung spezifische Variablen. Wenn wir uns die Rollen ansehen. Diese Rolle enthält mehrere Aufgaben, die ausgeführt werden. In diesem Fall ist dies die Rolle für die Installation von PostgreSQL. Das heißt, wir installieren die erforderliche Anwendung und erstellen die Datenbank. Hier verwenden wir eine Schleife. Sie (Datenbanken) werden ein wenig erstellt. Dann stellen wir die erforderliche Verbindung her - IP-Adressen, die sich bei dieser Datenbank anmelden können. Dementsprechend konfigurieren wir ganz am Ende der Firewall. Die Einstellungen werden auf alle Server in der Gruppe angewendet.

Gehen Sie einfach das Problem selbst an: Wir haben gelernt, wie Sie den Server mit Ansible konfigurieren, und alles war in Ordnung. Aber wie gesagt, wir haben viele Projekte. Sie sind fast alle gleich. Einige dieser Systeme sind an jedem Projekt beteiligt (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). Für jeden haben wir eine Rolle geschrieben. Wir können es vom Knopf rollen.

Aber wir haben viele Projekte, und in jedem überschneiden sie sich im Wesentlichen. Das heißt, in einer solchen Menge, in der zweiten, in der dritten. Wir erhalten Schnittpunkte, an denen in verschiedenen Projekten die gleichen Rollen spielen.

Wir haben ein Repository mit einer Anwendung, wir haben ein Repository mit Infrastruktur für das Projekt. Das zweite Projekt hat genau das gleiche. Fortsetzung der Infrastruktur. Und der dritte. Wenn wir dasselbe implementieren, wird sich im Wesentlichen das Kopieren und Einfügen herausstellen. Wir werden die gleiche Rolle an 10 Stellen spielen. Wenn es dann einen Fehler gibt, werden wir an 10 Stellen regieren.

Was wir getan haben: Wir haben jede Rolle, die allen Projekten und all ihren Konfigurationen, die von außen kommen, gemeinsam ist, in ein separates Repository übernommen und sie in einem Git in einem separaten Ordner abgelegt - wir haben TYME Infrastructure genannt. Dort haben wir eine Rolle für PostgreSQL, für ELK, für die Bereitstellung von Kubernetes-Clustern. Wenn wir ein Projekt einfügen müssen, sagen wir dasselbe PostgreSQL, dann schalten Sie es einfach als Submodul ein, schreiben Inventare neu, dh grob gesagt die Konfiguration, in der diese Rolle ausgeführt werden soll. Wir schreiben die Rolle selbst nicht neu: Sie existiert bereits. Und mit einem Klick auf eine Schaltfläche erscheint PostgreSQL in allen neuen Projekten. Wenn Sie einen Kubernetes-Cluster erstellen müssen - das Gleiche.

So stellte sich heraus, dass die Kosten für das Schreiben von Rollen gesenkt wurden. Das heißt, sie haben einmal geschrieben - sie haben es 10 Mal benutzt. Wenn das Projekt nach dem Projekt läuft, ist es sehr praktisch. Da wir jetzt mit der Infrastruktur als Code arbeiten, benötigen wir natürlich die Pipelines, über die wir gesprochen haben. Die Leute begehen sich in Git, sie können irgendeine Art von Unrichtigkeit begehen - wir müssen das alles verfolgen. Deshalb haben wir eine solche Pipeline gebaut. Das heißt, der Entwickler schreibt Ansible-Skripte in git fest. Teamity verfolgt sie und überträgt sie an Ansible. Teamcity wird hier nur aus einem Grund benötigt: Erstens hat es eine visuelle Oberfläche (es gibt eine kostenlose Version von Ansible Tower - AWX, die das gleiche Problem löst), im Gegensatz zu Ansible, das kostenlos ist und im Prinzip Teamcity als Single hat Ci. Im Prinzip hat Ansible also ein Modul, das selbst Git verfolgen kann. Aber in diesem Fall taten sie nur das Bild und die Ähnlichkeit. Sobald er es verfolgt hat, überträgt es den gesamten Code an Ansible bzw. Ansible, startet sie auf dem Integrationsserver und ändert die Konfiguration. Wenn dieser Prozess verletzt wird, analysieren wir, was falsch ist und warum die Skripte schlecht geschrieben wurden.

Der zweite Punkt ist, dass es eine bestimmte Infrastruktur gibt. Hier wird die Infrastruktur separat bereitgestellt, die Anwendung wird separat bereitgestellt. Es gibt jedoch eine spezifische Infrastruktur für jede Anwendung, die bereitgestellt werden muss, bevor wir sie starten. Hier ist es dementsprechend unmöglich, es auf eine andere Pipeline zu übertragen. Sie sollten dies im selben Container wie die Anwendung selbst bereitstellen. Das heißt, Frameworks sind eine beliebte Sache, wenn Sie ein Framework für eine neue Anwendung installieren und ein anderes Framework für ein anderes installieren müssen. Hier ist, wie mit dieser Situation. Oder Sie müssen die Caches bereinigen. Zum Beispiel kann Ansible auch klettern und den Cache bereinigen.

Aber hier verwenden wir Docker in Kombination mit Ansible. Das heißt, die spezifische Infrastruktur von uns befindet sich im Docker, in Ansible nicht spezifisch. Und so teilen wir dieses kleine Delta im Docker, alles andere, grundlegend - in Ansible.

Ein sehr wichtiger Punkt: Wenn Sie die Infrastruktur durch Skripte oder Code rollen und dann noch manuelle Servermanipulationen durchführen, ist dies eine potenzielle Sicherheitsanfälligkeit. Nehmen wir an, Sie haben Java auf den Testserver gestellt, die ELK-Rolle geschrieben und sie gerollt. Die Bereitstellung im Test war erfolgreich. In der Produktion bereitstellen, aber es gibt kein Java. Und Sie haben im Skript kein Java angegeben - die Bereitstellung in der Produktion ist gesunken. Daher müssen Sie den Administratoren die Rechte aller Server entziehen, damit diese nicht mit Ihren Händen hineinkriechen und alle Änderungen über git vornehmen. All dieses Förderband haben wir selbst durchlaufen. Es gibt eine Sache, aber - ziehen Sie die Muttern nicht zu fest an. Das heißt, es ist notwendig, einen solchen Prozess schrittweise einzuführen. Weil es noch nicht beschnitten ist. In unserem Fall haben wir bei unvorhergesehenen Vorfällen den Zugriff auf alle Systeme an der Spitze des Hauptadministrators gelassen. Der Zugriff wird unter der Bedingung gewährt, dass nichts von Hand konfiguriert wird.

Wie funktioniert die Entwicklung? Beim Rollout in der Inszenierung sollte die Produktion fehlerfrei sein. Hier könnte etwas kaputt gehen. Wenn der Rollout in der Integrationsumgebung ständig auf Fehler stößt, ist er schlecht. Dies ähnelt dem Debuggen von Anwendungen auf einem Remotecomputer. Wenn ein Entwickler zum ersten Mal alles auf einer Maschine entwickelt, kompiliert er es. Wenn alles kompiliert ist, wird es an das Repository gesendet. Es verwendet den gleichen Ansatz. Entwickler verwenden Visual Studio Code mit den Plugins Ansible, Vagrant, Docker usw. Entwickler testen ihren Infrastrukturcode auf einem lokalen Landstreicher. Es entsteht ein sauberes Betriebssystem. Die Skripte selbst zum Auslösen dieses Computers befinden sich ebenfalls in diesem Repository mit der Infrastruktur, über die wir gesprochen haben. Der Entwickler beginnt mit der Installation eines FTP-Servers. Wenn etwas schief gelaufen ist, löscht er es einfach, lädt es neu und versucht erneut, die erforderliche Software mithilfe von Bereitstellungsskripten darauf zu installieren. Nach dem Debuggen der Bereitstellungsskripts wird eine Zusammenführungsanforderung an den Hauptzweig gesendet. Nach dem Zusammenführen der Zusammenführungsanforderung setzt das CI diese Änderungen auf den Integrationsserver zurück.

Da alle Skripte Code sind, können wir Tests schreiben. Angenommen, wir haben PostgreSQL installiert. Wir wollen prüfen, ob es funktioniert oder nicht. Verwenden Sie dazu das Ansible-Assert-Modul. Vergleichen Sie die installierte Version von PostgreSQL mit der Version in den Skripten. Wir verstehen also, dass es installiert ist, im Allgemeinen ausgeführt wird und genau die Version ist, die wir erwartet haben.

Wir sehen, dass der Test bestanden wurde. Unser Spielbuch hat also richtig funktioniert. Sie können so viele Tests schreiben, wie Sie möchten. Sie sind idempotent. Idempotenz (eine Operation, die, wenn sie mehrmals auf einen Wert angewendet wird, immer den gleichen Wert ergibt wie bei einer einzelnen Anwendung). Wenn Sie kostenlose Skripte für die Installation und Konfiguration schreiben, stellen Sie sicher, dass Ihre Skripte immer den gleichen Wert erhalten, wenn Sie sie mehrmals ausführen.

Es gibt eine andere Art von Test, die sich nicht direkt auf Infrastrukturtests bezieht. Aber sie scheinen ihn indirekt zu beeinflussen. Dies sind End-to-End-Tests. Wir haben die Infrastruktur und die Anwendungen selbst sind auf demselben Server installiert, den Tester testen. Wenn wir eine falsche Infrastruktur eingeführt haben, werden nur komplexe Tests nicht bestanden. Das heißt, unsere Anwendung wird irgendwie falsch funktionieren. In diesem Beispiel haben wir eine neue Version in der Produktion installiert - die Anwendung funktioniert. Dann wurde ein Commit in Git- und End-to-End-Tests durchgeführt, die nachts stattfinden. Dabei wurde festgestellt, dass wir hier keine Datei auf FTP haben. Wir zerlegen diesen Fall und sehen, dass das Problem in den FTP-Einstellungen liegt. Wir korrigieren die Skripte im Code, stellen sie erneut bereit und alles wird grün. Gleiche Geschichte mit dem Code. Der Infrastrukturcode und die Infrastruktur werden auf die eine oder andere Weise indirekt getestet. Wir können es dann für die Produktion bereitstellen.

Als wir diesen Ansatz einführten, fiel CI (Teamcity), das Änderungen am Integrationsserver einführte, achtmal von zehn. Niemand achtete darauf, weil es kein Feedback gab. Für Entwickler sind diese Prozesse schon lange implementiert, aber die Nachrichten erreichten die OPS (Systemadministratoren) nicht. Aus diesem Grund haben wir einem großen Monitor an prominenter Stelle im Büro ein Dashboard mit den Baugruppen dieses Projekts hinzugefügt. Darauf sind verschiedene Projekte grün hervorgehoben - das bedeutet, dass bei ihm alles in Ordnung ist. Wenn rot hervorgehoben, bedeutet das, dass bei ihm alles schlecht ist. Wir sehen, dass einige Tests fehlgeschlagen sind. In der Präsentation auf der linken Seite der zweiten sehen wir von oben das Ergebnis der Bereitstellungsbereitstellungen . , , , . : - . . Slack , - - - .

Ok, , , - , . trunk based . Master — . Master CI (Teamcity) integration . CI , integration . release candidate. . . , end-to-end , staging . production. , staging .

. ? , PostgreSQL. 5 . , . 1-2 . . , PostgreSQL . PostgreSQL , staging, production 4 . , , . , . - .

git submodule Ansible . , . git submodule Ansible . inventories , . 30 . git submodule .

: , . , , , staging , . , , , , , , staging. — , , - .

6 . — 10 . . . , . - git submodule, . . , , , . , , .

.
-, , : , Ansible git , : “ , - ”. ? git . , . 100% . . .
, . . , RabbitMQ, ELK, . , ELK . , , ELK. ELK, , ELK .
, , , , . , , , , . , . .
. , , , , , , . git. , — git, , : , - . .
, , , code review. , , . , . , , , , , . , : . . . , - - .
, .
: , git submodule, . - , latest . inventories. — , . , , .. . — . .
: - Ansible ( A B, B C A, )? , ?
: . . , - IP , , , , . . , , , , , . , - , , , RabbitMQ RabbitMQ, . - , .
PS github . github . github — Pull request .