Im Laufe des vergangenen Jahres hat das Thema Cyber Intelligence oder Threat Intelligence im Cyberwaffenrennen zwischen Angreifern und Verteidigern zunehmend an Beliebtheit gewonnen. Das proaktive Abrufen von Informationen über Cyberthreats ist natürlich sehr nützlich, schützt jedoch nicht die Infrastruktur selbst. Es ist erforderlich, einen Prozess zu erstellen, mit dessen Hilfe sowohl Informationen über die Methode eines möglichen Angriffs als auch die verfügbare Zeit für die Vorbereitung korrekt verwaltet werden können. Und die Schlüsselbedingung für die Bildung eines solchen Prozesses ist die Vollständigkeit der Informationen über Cyberthreats.

Threat Intelligence-Primärdaten können aus einer Vielzahl von Quellen abgerufen werden. Dies können
kostenlose Abonnements , Informationen von Partnern, einem technischen Untersuchungsteam des Unternehmens usw. sein.
Es gibt drei Hauptphasen der Arbeit mit Informationen, die im Rahmen des Threat Intelligence-Prozesses erhalten wurden (obwohl wir als Zentrum für die Überwachung und Reaktion auf Cyber-Angriffe eine vierte Phase haben - die Benachrichtigung der Kunden über die Bedrohung):
- Informationen erhalten, primäre Verarbeitung.
- Erkennung von Kompromissindikatoren (Indikator für Kompromisse, IOC).
- Rückwirkende Überprüfung.
Informationsbeschaffung, Primärverarbeitung
Die erste Stufe kann als die kreativste bezeichnet werden. Die Beschreibung einer neuen Bedrohung richtig verstehen, relevante Indikatoren hervorheben, ihre Anwendbarkeit auf eine bestimmte Organisation bestimmen, unnötige Informationen über Angriffe herausfiltern (z. B. eng auf bestimmte Regionen ausgerichtet) - all dies ist oft eine schwierige Aufgabe. Gleichzeitig gibt es Quellen, die ausschließlich verifizierte und relevante Daten bereitstellen, die automatisch zur Datenbank hinzugefügt werden können.
Für einen systematischen Ansatz bei der Informationsverarbeitung empfehlen wir, die im Rahmen von Threat Intelligence erhaltenen Indikatoren in zwei große Gruppen zu unterteilen - Host und Netzwerk. Die Erkennung von Netzwerkindikatoren bedeutet keinen eindeutigen Kompromiss des Systems, aber die Erkennung von Hostindikatoren signalisiert in der Regel zuverlässig den Erfolg eines Angriffs.
Zu den Netzwerkindikatoren gehören Domänen, URLs, E-Mail-Adressen, eine Reihe von IP-Adressen und Ports. Host-Indikatoren führen Prozesse, Änderungen an Registrierungszweigen und -dateien sowie Hash-Beträge aus.
Indikatoren, die als Teil einer einzelnen Bedrohungswarnung empfangen werden, ist sinnvoll, in einer Gruppe zu kombinieren. Im Falle der Erkennung von Indikatoren erleichtert dies die Bestimmung der Art des Angriffs erheblich und erleichtert die Überprüfung des potenziell gefährdeten Systems auf alle möglichen Indikatoren anhand eines bestimmten Bedrohungsberichts.
Oft muss man sich jedoch mit Indikatoren befassen, deren Erkennung es uns nicht erlaubt, eindeutig über ein kompromittiertes System zu sprechen. Dies können IP-Adressen großer Unternehmen und Hosting-Netzwerke, Mail-Domains von Werbe-Mailing-Diensten, Namen und Hash-Summen legitimer ausführbarer Dateien sein. Die einfachsten Beispiele sind die häufig aufgelisteten IP-Adressen von Microsoft, Amazon, CloudFlare oder legitime Prozesse, die nach der Installation von Softwarepaketen im System angezeigt werden, z. B. pageant.exe, ein Agent zum Speichern von Schlüsseln. Um eine große Anzahl von Fehlalarmen zu vermeiden, ist es besser, solche Indikatoren herauszufiltern, aber sagen wir, werfen Sie sie nicht weg - die meisten von ihnen sind nicht völlig nutzlos. Wenn der Verdacht auf ein kompromittiertes System besteht, werden alle Indikatoren einer vollständigen Überprüfung unterzogen, und die Erkennung selbst eines indirekten Indikators kann diesen Verdacht bestätigen.
Da nicht alle Indikatoren gleichermaßen nützlich sind, verwenden wir bei Solar JSOC das sogenannte Indikatorgewicht. Konventionell hat die Erkennung eines Dateistarts, dessen Hash-Summe mit dem Hash der schädlichen ausführbaren Datei übereinstimmt, ein Schwellengewicht. Die Erkennung eines solchen Indikators führt sofort zum Auftreten eines Informationssicherheitsereignisses. Ein einzelner Zugriff auf die IP-Adresse eines potenziell gefährlichen Hosts an einem unspezifischen Port führt nicht zu einem IB-Ereignis, sondern in ein spezielles Profil, das Statistiken sammelt, und die Erkennung weiterer Anrufe führt ebenfalls zu einer Untersuchung.
Gleichzeitig gibt es Mechanismen, die uns zum Zeitpunkt der Schöpfung vernünftig erschienen, aber letztendlich als unwirksam anerkannt wurden. Beispielsweise wurde ursprünglich festgelegt, dass bestimmte Arten von Indikatoren eine begrenzte Lebensdauer haben und danach deaktiviert werden. Wie die Praxis gezeigt hat, werden beim Herstellen einer Verbindung zu einer neuen Infrastruktur manchmal Hosts gefunden, die seit Jahren mit verschiedenen Arten von Malware infiziert sind. Zum Beispiel wurde einmal beim Verbinden eines Kunden der Corkow-Virus auf dem Computer des Leiters des IS-Dienstes entdeckt (die Indikatoren waren zu diesem Zeitpunkt mehr als fünf Jahre alt), und weitere Untersuchungen ergaben, dass die Hintertür und der Keylogger auf dem Host ausgenutzt waren.
Erkennung von Kompromissindikatoren
Wir arbeiten mit vielen Installationen verschiedener SIEM-Systeme. Die allgemeine Struktur der Datensätze, die in die Indikatordatenbank fallen, ist jedoch standardisiert und sieht folgendermaßen aus:
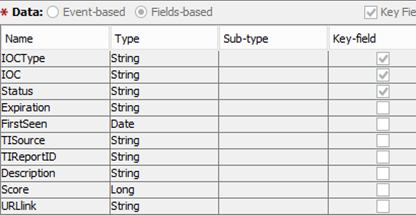
Wenn Sie beispielsweise die Indikatoren nach TIReportID sortieren, finden Sie alle Indikatoren, die in der Beschreibung einer bestimmten Bedrohung enthalten sind. Wenn Sie auf den URL-Link klicken, erhalten Sie eine detaillierte Beschreibung.
Beim Aufbau des Threat Intelligence-Prozesses ist es sehr wichtig, die mit dem SIEM verbundenen Informationssysteme auf ihre Nützlichkeit für die Identifizierung von Kompromissindikatoren zu analysieren.
Tatsache ist, dass die Beschreibung des Angriffs normalerweise verschiedene Arten von Kompromissindikatoren enthält - zum Beispiel die Hash-Menge der Malware, die IP-Adresse des SS-Servers, auf den sie klopft, und so weiter. Wenn jedoch die IP-Adressen, auf die der Host zugreift, durch viele Schutzmaßnahmen überwacht werden, ist es viel schwieriger, Informationen über die Hash-Mengen zu erhalten. Daher betrachten wir alle Systeme, die als Quelle für Protokolle dienen können, unter dem Gesichtspunkt, welche Indikatoren sie verfolgen können:
Anzeigetyp
| Sourcetype
|
Domain
| Proxyserver, NGFW, DNS-Server
|
URL
|
Steckdose
| Proxies, NGFW, FW
|
Mail
| Mailserver, Antispam, DLP
|
Prozess
| Protokolle vom Host, DB AVPO, Sysmon
|
Registrierung
| Protokolle vom Host
|
Hash-Summe
| Protokolle vom Host, DB AVPO, Sysmon, Sandboxes CMDB
|
Schematisch kann der Prozess der Erkennung von Kompromissindikatoren wie folgt dargestellt werden:

Ich habe bereits über die ersten beiden Punkte oben gesprochen, jetzt etwas mehr über die IOC-Datenbankprüfung. Als Beispiel nehmen wir die Ereignisse, die Informationen zu IP-Adressen enthalten. Die Korrelationsregel für jedes Ereignis führt vier mögliche Überprüfungen auf der Grundlage von Indikatoren durch:

Die Suche wird von relevanten Indikatoren des Socket-Typs durchgeführt, während das Gesamtdesign der IP-Adresse und des entsprechenden Ports auf Übereinstimmung mit dem Indikator überprüft wird. Weil In den Informationen zur Bedrohung wird nicht immer der spezifische Port angegeben, sondern die IP: Jedes Konstrukt prüft, ob eine Adresse mit einem undefinierten Port in der Datenbank vorhanden ist.
Ein ähnliches Design wird in einer Regel implementiert, die Kompromissindikatoren bei Registrierungsänderungsereignissen erkennt. In den eingehenden Informationen sind häufig keine Daten zu einem bestimmten Schlüssel oder Wert vorhanden. Wenn daher ein Indikator in die Datenbank eingegeben wird, werden Daten, die unbekannt sind oder keinen genauen Wert haben, durch "any" ersetzt. Die endgültigen Suchoptionen lauten wie folgt:

Nachdem der Indikator für einen Kompromiss in den Protokollen gefunden wurde, erstellt die Korrelationsregel ein Korrelationsereignis, das mit der Kategorie gekennzeichnet ist, die von der Vorfallregel verarbeitet wird (dies wurde im Artikel „
RIGHT Kitchen “ ausführlich erläutert).
Zusätzlich zur Kategorie wird das Korrelationsereignis durch Informationen ergänzt, in welcher Warnung oder in welchem Bericht dieser Indikator angezeigt wurde, sein Gewicht, Bedrohungsdaten und einen Link zur Quelle. Die weitere Verarbeitung von Ereignissen zur Erkennung von Indikatoren aller Art erfolgt durch die Vorfallregel. Seine Arbeit kann wie folgt schematisch dargestellt werden:

Aber natürlich sollten Sie die Ausnahmen berücksichtigen: In fast jeder Infrastruktur gibt es Geräte, deren Aktionen legitim sind, obwohl sie formal Anzeichen eines kompromittierten Systems enthalten. Solche Geräte umfassen meistens Sandkästen, verschiedene Scanner usw.
Die Notwendigkeit, die Erkennungsereignisse von Indikatoren unterschiedlicher Art zu korrelieren, beruht auch auf der Tatsache, dass heterogene Indikatoren am häufigsten in Informationen über Bedrohungen enthalten sind.
Dementsprechend können Sie durch eine Gruppierung von Indikatorerkennungsereignissen die gesamte Angriffskette vom Moment des Eindringens bis zum Betrieb sehen.
Wir schlagen vor, die Implementierung eines der folgenden Szenarien als Informationssicherheitsereignis zu betrachten:
- Erkennung eines hochrelevanten Kompromissindikators.
- Erkennung von zwei verschiedenen Indikatoren aus einem Bericht.
- Schwelle erreichen.
Mit den ersten beiden Optionen ist alles klar, und die dritte ist erforderlich, wenn wir keine anderen Daten als die Netzwerkaktivität des Systems haben.
Rückwirkende Überprüfung von Kompromissindikatoren
Nachdem Sie Informationen über die Bedrohung erhalten, Indikatoren identifiziert und deren Identifizierung organisiert haben, ist eine nachträgliche Überprüfung erforderlich, mit der Sie einen bereits eingetretenen Kompromiss erkennen können.
Wenn ich etwas tiefer in die Funktionsweise von SOC eintauche, kann ich sagen, dass dieser Prozess eine wirklich enorme Menge an Zeit und Ressourcen erfordert. Die Suche nach Kompromissindikatoren in den Protokollen für ein halbes Jahr zwingt uns, eine beeindruckende Menge davon für Online-Überprüfungen verfügbar zu halten. Darüber hinaus sollte das Ergebnis der Überprüfung nicht nur Informationen über das Vorhandensein von Indikatoren sein, sondern auch allgemeine Daten zur Entwicklung des Angriffs. Beim Anschluss neuer Kundeninformationssysteme müssen auch deren Daten auf Indikatoren überprüft werden. Dazu ist es notwendig, den sogenannten „Inhalt“ des SOC - Korrelationsregeln und Kompromissindikatoren - ständig zu verfeinern.
Für das ArcSight SIEM-System kann selbst eine solche Suche in den letzten Wochen lange dauern. Daher wurde beschlossen, die Trends zu nutzen.
"Ein Trend ist eine ESM-Ressource, die definiert, wie und über welchen Zeitraum Daten aggregiert und auf vorherrschende Tendenzen oder Strömungen ausgewertet werden. Ein Trend führt eine bestimmte Abfrage nach einem definierten Zeitplan und einer definierten Zeitdauer aus. “
ESM_101_Guide
Nach mehreren Tests auf geladenen Systemen wurde der folgende Algorithmus zur Verwendung von Trends entwickelt:

Mithilfe von Profilerstellungsregeln, die die entsprechenden aktiven Blätter mit nützlichen Daten füllen, können Sie die Gesamtlast auf das SIEM verteilen. Nach Erhalt der Indikatoren werden Anforderungen in den entsprechenden Blättern und Trends erstellt, auf deren Grundlage Berichte erstellt werden, die wiederum auf alle Installationen verteilt werden. Tatsächlich müssen nur noch Berichte ausgeführt und die Ergebnisse verarbeitet werden.
Es ist erwähnenswert, dass der Verarbeitungsprozess kontinuierlich verbessert und automatisiert werden kann. Zum Beispiel haben wir eine Plattform zum Speichern und Verarbeiten von MISP-Kompromissindikatoren eingeführt, die derzeit unsere Anforderungen an Flexibilität und Funktionalität erfüllt. Seine Analoga sind auf dem Open-Source-Markt weit verbreitet - YETI, Ausland - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, Russisch - TI.Platform, R-Vision Threat Intelligence Platform. Jetzt führen wir abschließende Tests zum automatischen Entladen von Ereignissen direkt aus der SIEM-Datenbank durch. Dies wird die Berichterstattung über Kompromissindikatoren erheblich beschleunigen.
Das Hauptelement der Cyber Intelligence
Das letzte Glied bei der Verarbeitung der Indikatoren selbst und der Berichte sind jedoch Ingenieure und Analysten, und die oben aufgeführten Tools helfen nur bei der Entscheidungsfindung. In unserem Land ist die Antwortgruppe für das Hinzufügen von Indikatoren verantwortlich, und die Überwachungsgruppe ist für die Richtigkeit der Berichte verantwortlich.
Ohne Menschen funktioniert das System nicht ausreichend, Sie können nicht alle kleinen Dinge und Ausnahmen vorhersehen. Beispielsweise notieren wir Aufrufe an die IP-Adressen von TOR-Knoten, aber in den Berichten für den Kunden teilen wir die Aktivität des gefährdeten Hosts und des Hosts, auf dem TOR Browser einfach installiert wurde. Es ist möglich, es zu automatisieren, aber es ist ziemlich schwierig, all diese Punkte beim Einrichten der Regeln im Voraus zu durchdenken. Es stellt sich also heraus, dass die Antwortgruppe nach verschiedenen Kriterien Indikatoren eliminiert, die eine große Anzahl von Fehlalarmen erzeugen. Und umgekehrt - es kann ein spezifischer Indikator hinzugefügt werden, der für einige Kunden (z. B. den Finanzsektor) von hoher Relevanz ist.
Die Überwachungsgruppe kann Sandbox-Aktivitäten aus dem Abschlussbericht entfernen, Administratoren auf erfolgreiche Blockierung einer schädlichen Ressource überprüfen, aber Aktivitäten zum erfolglosen externen Scannen hinzufügen und dem Kunden anzeigen, dass seine Infrastruktur von Angreifern überprüft wird. Die Maschine wird solche Entscheidungen nicht treffen.

Anstelle von Ausgabe
Warum empfehlen wir diese Methode für die Arbeit mit Threat Intelligence? Erstens können Sie sich vom Schema entfernen, wenn Sie für jeden neuen Angriff eine separate Korrelationsregel erstellen müssen. Dies dauert unannehmbar lange und zeigt nur den laufenden Angriff.
Die beschriebene Methode nutzt die TI-Funktionen optimal aus. Sie müssen lediglich Indikatoren hinzufügen. Dies beträgt maximal 20 Minuten ab dem Zeitpunkt, zu dem sie angezeigt werden, und führt dann eine vollständige retrospektive Überprüfung der Protokolle durch. So reduzieren Sie die Reaktionszeit und erhalten vollständigere Testergebnisse.
Wenn Sie Fragen haben, können Sie diese gerne kommentieren.