Im vergangenen Jahr gab es in der russischen und ukrainischen Presse eine Welle von Artikeln über Partys im Silicon Valley mit einer gewissen Hollywood-Atmosphäre, jedoch ohne Angabe spezifischer Namen, Fotos und ohne Beschreibung der mit diesen Namen verbundenen Hardwareentwicklungs- und Software-Schreibtechnologien. Dieser Artikel ist anders! Es wird auch Milliardäre, Genies und Mädchen geben, aber mit Fotos, Folien, Diagrammen und Fragmenten des Programmcodes. Also:
Neulich hat der Bürgermeister von Campbell mit dem russischen Namen Paul Resnikoff bei der Eröffnung des neuen Startup-Büros von Wave Computing, das zusammen mit Broadcom einen 7-Nanometer-Chip entwickelt, um die Berechnung neuronaler Netze zu beschleunigen, das Band durchtrennt. Das Büro befindet sich im Gebäude der historischen Obst- und Konservenfabrik des späten 19. und frühen 20. Jahrhunderts, als das Silicon Valley der größte Obstgarten der Welt war. Schon damals beschäftigte sich das Büro mit Innovationen und führte die ersten in der Aprikosenpflaumenindustrie eingeführten Elektromotoren für Förderer ein, für die etwa 200 Mitarbeiter, hauptsächlich Frauen, arbeiteten.
Auf der Party, die auf das Durchschneiden des Bandes folgte, wurden viele branchenberühmte Personen ins Rampenlicht gerückt, darunter Kernigan-Richies Mitstreiter und Autor des beliebtesten C-Compilers der späten 70er - frühen 80er Jahre, Stephen Johnson, einer der Autoren des Gleitkommazahlen-Standards Jerome Kunen, Erfinder lokale Buskonzepte und der erste PC AT-Chipsatzentwickler Diosdado Banatao, ehemalige Entwickler von Sun-, DEC-, Cyrix-, Intel-, AMD- und Silicon Graphics-Prozessoren, Qualcomm-, Xilinx- und Cypress-Chips, Industrieanalysten, ein Mädchen mit roten Haaren und andere Einwohner Kaliforniens mpany dieses Typs.
Am Ende des Beitrags werden wir darüber sprechen, welche Bücher zu lesen sind und welche Übungen zu tun sind, um dieser Community beizutreten.
Beginnen wir mit Jerome Kunen, einem Innovator in der Gleitkomma-Arithmetik und Apple-Manager seit dem ersten Macintosh.
Dissertationen von Kandidaten sind nicht so häufig, dass sie sich auf Milliarden von Geräten auswirken. So wurde Jerome Kunens Diser (Beiträge zu einem vorgeschlagenen Standard für binäre Gleitkomma-Arithmetik), dessen Ergebnisse in den Gleitkommazahlen des IEEE-Standards 754 enthalten sind. Nach seinem Abschluss an der Berkeley Graduiertenschule im Jahr 1982 ging Jerome zu Apple, wo er die Gleitkomma-Bibliothek in den ersten Macintosh einführte.
Nach 10 Jahren Management bei Apple beriet Kunen Hewlett-Packard und Microsoft und optimierte im Jahr 2000 die 128-Bit-Arithmetik für die neue 64-Bit-x86-Version von AMD. Jerome wandte sich kürzlich der Erforschung von Gleitkomma-Standards für neuronale Netze zu, insbesondere Streitigkeiten über Unum und Posit. Unum ist der neue vorgeschlagene Standard, der vom Wissenschaftler von Caltech John Gustafson, dem Autor des jetzt lauten Buches The End of Error, "The End of Error", beworben wird. Posit ist eine Version von Unum, die effizienter (*) als Unum in Hardware implementiert werden kann.
(*) Effizienter bei der Kombination von Parametern: Taktfrequenz, Anzahl der Zyklen pro Vorgang, Fördererdurchsatz, relative Fläche auf dem Chip und relativer Stromverbrauch.

Bilder aus Artikeln (nicht von Jerome)
Gleitkomma-Mathematik für KI-Hardware und
Floating Point in seinem eigenen Spiel schlagen: Posit Arithmetic von John L. Gustafson und Isaac Yonemoto :

Aber auf der Party ist Stephen / Steve Johnson die Person, auf deren Compiler die Programmiersprache C populär geworden ist. Der erste C-Compiler wurde von Denis Ritchie geschrieben, aber Richies Compiler war eng an die PDP-11-Architektur gebunden. Steve Johnson, basierend auf der Arbeit von Alan Snyder, schrieb Mitte der 1970er Jahre den Portable C Compiler (PCC), der leicht neu zu erstellen war, um Code für verschiedene Architekturen zu generieren. Gleichzeitig arbeitete der Johnson-Compiler schnell und optimierte. Wie hat er das erreicht?
Am PCC-Eingang verwendete Steve Johnson den von YACC (Yet Another Compiler Compiler) generierten LALR (1) -Parser, der ebenfalls von Steve Johnson verfasst wurde. Danach wurde die Kompilierungsaufgabe darauf reduziert, Bäume in rekursiven Funktionen zu bearbeiten und Code aus der Vorlagentabelle zu generieren. Einige dieser rekursiven Funktionen waren maschinenunabhängig, der andere Teil wurde von Personen geschrieben, die PCC auf eine andere Maschine übertragen haben. Die Vorlagentabelle bestand aus Regeleinträgen vom Typ "Wenn ein Register vom Typ A und zwei Register vom Typ B frei sind, bauen Sie den Baum in einen Knoten vom Typ C um und generieren Sie Code mit einer Zeichenfolge D". Der Tisch war maschinenabhängig.
Aufgrund der Kombination aus Eleganz, Flexibilität und Effizienz wurde der PCC-Compiler auf mehr als 200 Architekturen portiert - von PDP, VAX, IBM / 370, x86 bis zum sowjetischen BESM-6 und Orbit 20-700 (ein Bordcomputer in frühen Versionen der MiG-29). Laut Denis Ritchie basierte fast jeder C-Compiler der frühen 1980er Jahre auf PCC. Aus der BSD-Unix-Welt wurde PCC 1994 als Standard-GNU-GCC-Compiler abgelöst.
Neben PCC und Yacc ist Steve Johnson auch Autor des ursprünglichen Verifizierungsprogramms für das Lint-Programm (siehe beispielsweise den
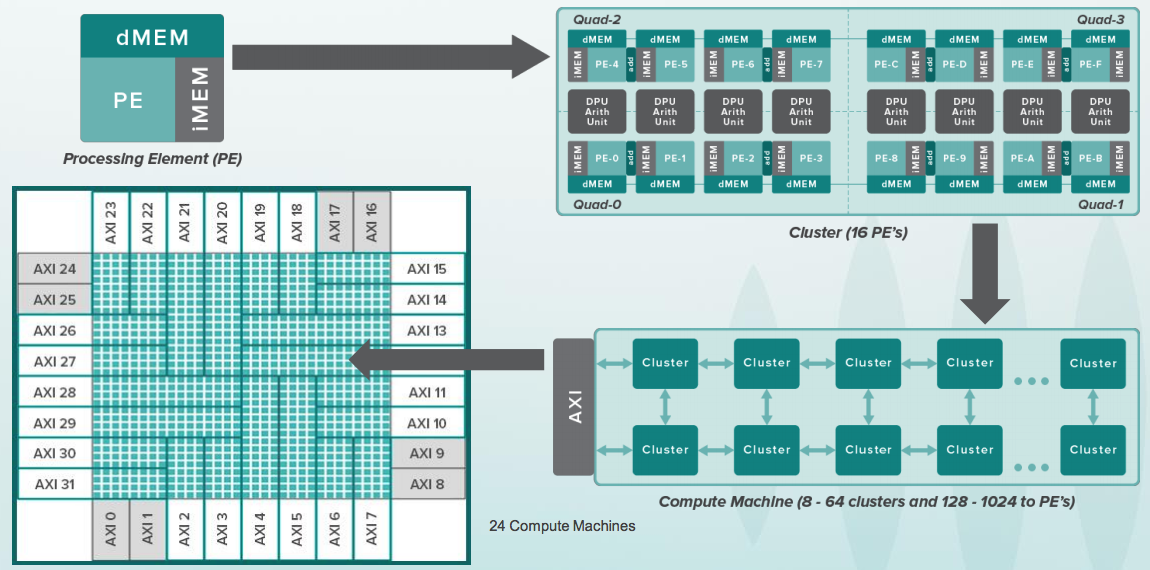
Artikel von 1978 ). Die Namen der Programme Yacc und Lint sind inzwischen zu gebräuchlichen Substantiven geworden. In den 2000er Jahren schrieb Steve das Frontend von MATLAB neu und schrieb MLint. Jetzt beschäftigt sich Steve Johnson mit der Parallelisierung der Algorithmen zur Berechnung neuronaler Netze auf Geräten wie CGRA (Coarse-Grained Reconfigurable Architecture) mit Zehntausenden prozessorähnlichen Elementen, die von Tensoren über ein Netzwerk von Zehntausenden von Schaltern in einem massiven Chip mit Milliarden von Transistoren überspannt werden:

Aber mit einem Glas Wein, Milliardär Diosdado Banatao, Gründer von Chips & Technologies, S3 Graphics und Investor in Marvell. Wenn Sie einen IBM-PC in den Jahren 1985-1988 programmiert haben, als er zum ersten Mal in der UdSSR erschien, wissen Sie vielleicht, dass in den meisten AT-Sheks mit EGA- und VGA-Grafik Chipsätze von Chips & Technologies vorhanden waren, die gleichzeitig mit denen von IBM herauskamen. Die frühen C & T-Chipsätze wurden von Banatao entworfen, der gelernt hatte, Elektronikingenieur bei Stanford zu sein, und bevor Stanford als Ingenieur bei Boeing arbeitete. 1987 erwarb Intel Chips & Technologies.


Links im Bild unten ist John Bourgoin, Präsident von MIPS Technologies seit seinem Höhepunkt in den 2000er Jahren, als sich Chips mit MIPS-Kernen in den meisten DVD-Playern, Digitalkameras und Fernsehgeräten befanden, mit Chipsätzen von Zoran, Sigma Design, Realtek, Broadcom und andere Unternehmen. Zuvor war John Präsident von MIPS Silicon Graphics seit 1996, als sich MIPS-Prozessoren in den Silicon Graphics-Workstations befanden, auf denen Hollywood die ersten realistischen 3D-Jurassic Park-Filme drehte. Vor seiner Zeit bei Silicon Graphics war John seit 1976 einer der Vizepräsidenten von AMD.
Art Swift, rechts, war in den 2000er Jahren Vizepräsident für Marketing bei MIPS. Davor arbeitete er in den 1980er Jahren als Ingenieur bei Fairchild Semiconductor (ja, dieser), dann als Vizepräsident für Marketing bei Sun, DEC, Cirrus Logic und Präsident von Transmet. Vor kurzem war Art stellvertretender Vorsitzender des RISC-V-Marketingausschusses und war in dieser Position mit Syntacore und CloudBear in Russland vertraut. Und jetzt ist er Präsident von Wave's MIPS IP:

Die Folien aus der
Präsentation zur Geschichte des MIPS bezogen sich auf die Zeit, als das MIPS von John Bourgoin kontrolliert wurde, im Bild oben links:

Das Transmet-Unternehmen, dessen Präsident einige Zeit Art Swift war (siehe Bild oben rechts), veröffentlichte Ende der neunziger Jahre den Crusoe-Prozessor, der den x86-Anweisungen folgen konnte und den Markt für Toshiba Libretto L-Sub-Laptops, NEC- und Sharp-Laptops erreichte , Thin Client von Compaq. Ihr Wettbewerbsvorteil gegenüber Intel und AMD bestand darin, den geringen Stromverbrauch zu kontrollieren.
Die direkte Implementierung und Überprüfung der vollständigen x86-Suite ist ein sehr teures Unterfangen, daher ging Transmeta den anderen Weg, der dem Weg des russischen MTsST-Unternehmens mit dem Elbrus-Prozessor ähnelt (die Linie, die mit Elbrus 2000 begann und jetzt als Elbrus 8C präsentiert wird). Transmeta und Elbrus basierten auf einem strukturell einfachen Prozessor mit einer VLIW-Mikroarchitektur, und die x86-Emulationsstufe arbeitete darüber hinaus mit der von Transmeta als Code-Morphing bezeichneten Technologie.
Die Idee von VLIW (Very Long Instruction Word) ist recht einfach: Mehrere Prozessorbefehle werden explizit als ein Superbefehl deklariert und parallel ausgeführt. Im Gegensatz zu superskalaren Prozessoren, insbesondere Intel, beginnend mit PentiumPro (1996), bei dem der Prozessor mehrere Befehle aus dem Speicher auswählt und dann anhand einer automatischen Analyse der Abhängigkeiten zwischen Befehlen entscheidet, was parallel und was nacheinander ausgeführt werden soll.
Ein superskalarer Prozessor ist viel komplizierter als VLIW, da ein superskalarer Prozessor die Logik aufwenden muss, um die Illusion eines Programmierers aufrechtzuerhalten, dass alle ausgewählten Befehle nacheinander ausgeführt werden, obwohl sich in der Realität Dutzende davon in verschiedenen Ausführungsstufen im Prozessor befinden können. Im Fall von VLIW liegt die Last für die Aufrechterhaltung einer solchen Illusion beim Compiler aus einer Hochsprache. Letztendlich bricht die VLIW-Schaltung ab, wenn der Prozessor mit einem mehrstufigen Cache arbeiten muss, der unvorhersehbare Verzögerungen aufweist, die es dem Compiler erschweren, Taktbefehle zu planen. Bei mathematischen Berechnungen (z. B. Elbrus auf das Radar setzen und die Bewegung des Ziels berechnen) ist dies jedoch der Fall, insbesondere unter Bedingungen eines Mangels an qualifiziertem Ingenieurpersonal (mehr Personen müssen den Superskalar überprüfen).
Illustration der VLIW-Idee, des Crusoe-Prozessors und des Toshiba Libretto L1-Sub-Laptops:

Und hier in der Mitte auf dem Foto unten Derek Meyer, Derek Meyer, aktueller CEO von Wave Computing. Vor Wave war Derek CEO von ARC, einem Entwickler von ARC-Prozessorkernen, die in Audio-Chips verwendet werden. Diese Kerne wurden einmal von der
russischen Firma NIIMA Progress lizenziert, die später die MIPS-Kerne lizenzierte und
auf einer Ausstellung in Kasan Innopolis darauf basierende Chips zeigte . Derek Meyer ist wiederholt nach Russland gereist, nach St. Petersburg, wo sich das Entwicklungsteam von Virage Logic befand. Im Jahr 2009 erwarb ARC Virage Logic und im Jahr 2010 erwarb Synopsys, das weltweit führende Unternehmen für Chipdesign, das ARC.
Rechts auf dem Foto -
Sergey Vakulenko , der zu Beginn seiner Karriere an den Ursprüngen von Runet stand, arbeitete in den kooperativen Demos und im Kurchatov-Institut, die das Internet in die UdSSR brachten. Jetzt schreibt Sergey ein zyklusgenaues Modell des Wave-Prozessorelements für die Berechnung neuronaler Netze. Zuvor hat er anweisungsgenaue Modelle von MIPS-Kernen geschrieben, mit denen die MIPS-Prozessorkerne I6400 Samurai, I7200 Shaolin und andere überprüft wurden.

Hier sind Vadim Antonov und Sergey Vakulenko aus dem Jahr 1990, mit dem ersten Computer in der UdSSR, der mit dem Internet verbunden ist:

Und hier ist Larry Hudepohl auf der rechten Seite (Hüdepol wird auf Russisch geschrieben?). Larry begann seine Karriere bei der Digital Equipment Corporation (DEC) als Prozessordesigner für MicroVAX. Dann arbeitete Larry für eine kleine Firma Cyrix, die Ende der 1980er Jahre Intel herausforderte und einen FPU-Coprozessor herstellte, der mit Intel 80387 kompatibel und 50% schneller war. Dann entwarf Larry MIPS-Chips bei Silicon Graphics. Als sich MIPS Technologies von Silicon Graphics trennte, brachten Larry und Ryan Quinter gemeinsam das erste unabhängige MIPS-Produkt auf den Markt, MIPS 4K, das das Rückgrat der Linie bildete, die die Heimelektronik der 2000er Jahre dominierte (DVD-Player, Kameras, Digitalfernseher). Dann flog MIPS 5K ins All - es wurde von der japanischen Raumfahrtagentur JAXA genutzt. Dann leitete Larry als VP Hardware Engineering die Entwicklung der folgenden Linien und arbeitet nun an neuen Wave Accelerator-Architekturen.

Das japanische Raumschiff mit dem stolzen Namen Hayabusa-2 (Sapsan-2), das
letztes Jahr auf der Oberfläche des Ryugu-Asteroiden gelandet ist, wird vom HR5000-Prozessor gesteuert, der auf dem MIPS 5Kf-Prozessorkern basiert, der seit langem von MIPS Technologies lizenziert wird.
Hier ist eine einfache serielle Pipeline des 64-Bit-MIPS 5Kf-Prozessorkerns aus seinem
Datenblatt :

Direkt auf dem Foto - Darren Jones, Darren Jones. Er war der Director of Hardware Engineering bei MIPS, der die Entwicklung komplexer Kerne mit Hardware-Multithreading und Superskalaren mit außergewöhnlicher Ausführung von Anweisungen leitete. Dann ging Darren zu Xilinx, wo er an Xilinx Zynq - Chips beteiligt war, auf denen eine Kombination aus FPGAs und ARM - Prozessoren steht. Darren ist jetzt Vice President of Engineering bei Wave.
Bei MIPS war Darren der Leiter einer Gruppe, deren Mitglieder später für Apple und Samsung arbeiteten. Die Designerin Monica, die zu Samsung ging, erzählte mir einmal einen Satz, an den ich mich gut erinnerte: „RTL-Design: ein paar einfache Prinzipien und der Rest betrügt“ (Entwicklung von Geräten auf der Ebene der Registerübertragungen: ein paar einfache Prinzipien, alles andere ist muhlezh) Ein kanonisches Beispiel für Muhlezh ist der Cache (das Programm hat die Daten geschrieben und gelesen, aber es wird erst einige Zeit später in Erinnerung bleiben), aber dies ist nur ein ganz besonderer Fall dessen, was Monica konnte.

Hardware-Multithreading und ein außergewöhnlicher Superskalar sind zwei verschiedene Ansätze zur Verbesserung der Prozessorleistung. Mit Hardware-Multithreading können Sie den Durchsatz ohne großen Energieverbrauch, jedoch mit nicht trivialer Programmierung erhöhen. Mit dem Superskalar können Sie Single-Threaded-Programme ungefähr doppelt so schnell ausführen, verbrauchen aber auch doppelt so viel Watt. Aber ohne Tricks in der Programmierung.
Schließlich wurde das Hardware-Multithreading in der russischen Wikipedia gut erklärt. Hier ist das
temporäre Multithreading (es ist in MIPS interAptiv und MIPS I7200 Shaolin implementiert), aber das
gleichzeitige Multithreading (es wurde in den 1990er Jahren in DEC Alpha-Prozessoren, dann in SPARC und dann in MIPS I6400 Samurai / I6500 Daimyo).
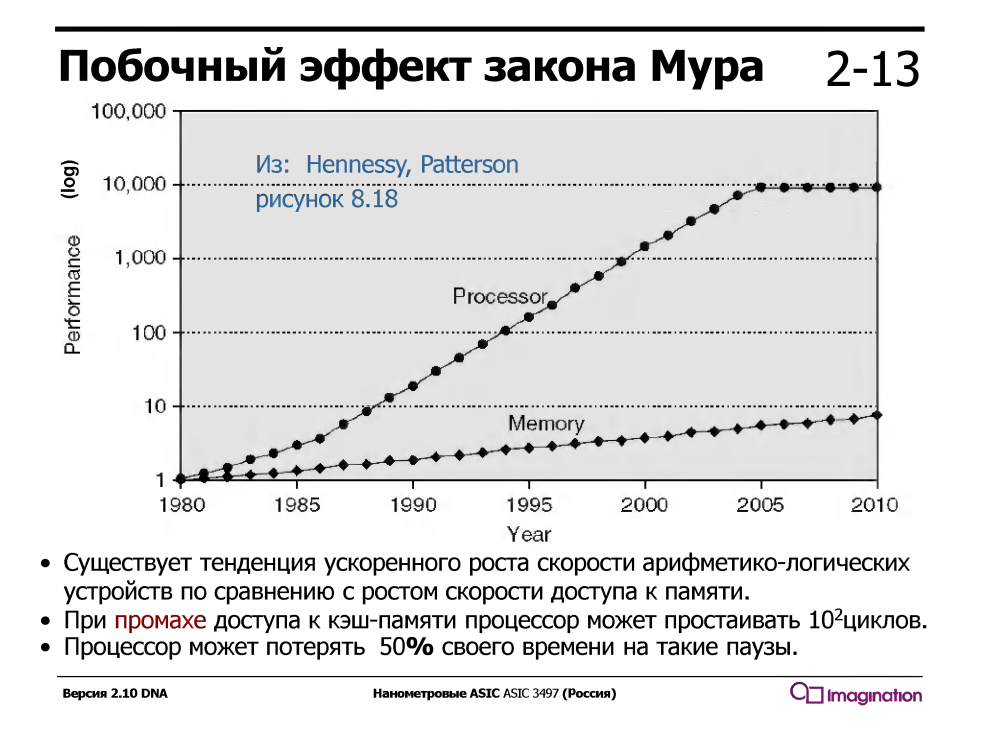
Temporäres Multithreading nutzt die Tatsache aus, dass ein Prozessor mit einer herkömmlichen seriellen Pipeline im Leerlauf ist und auf die Hälfte der Ausführungszeit wartet. Worauf wartet er noch? Daten, die Caches aus dem Speicher durchlaufen. Und es wartet lange - während der Prozessor auf einen Cache-Fehler wartet, kann er Dutzende oder sogar hundert oder zwei einfache arithmetische Anweisungen wie das Hinzufügen ausführen.
Dies war nicht immer der Fall - in den 1960er Jahren waren Rechengeräte viel langsamer als der Speicher. Aber seit ungefähr 1980 ist die Geschwindigkeit von Prozessorkernen viel schneller gewachsen als die Geschwindigkeit des Speichers, und selbst das Auftreten von mehrstufigen Caches in Prozessoren hat das Problem nur teilweise gelöst.
Prozessoren mit temporärem Multithreading unterstützen mehrere Registersätze, einen für jeden Thread. Wenn der aktuelle Thread während eines Cache-Fehlers auf Daten aus dem Speicher wartet, wechselt der Prozessor zu einem anderen Thread. Dies geschieht sofort in einem Zyklus ohne Unterbrechungen und Tausende von Zyklen des Interrupt-Handlers, der während des Multithreading von Software (nicht Hardware) aktiviert wird.
Hier ist die Idee des Multithreading
auf den Folien aus den Workshops von Charles Danchek , Professor an der University of California in Santa Cruz, Silicon Valley Extension. Warum auf Russisch? Weil Charles Danchek Vorträge am Moskauer MISiS und dann am St. Petersburger ITMO und am Kiewer KPI hielt:


Interessanterweise kann Multithread-Hardware einfach in C programmiert werden. So sieht es aus:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
Hier auf der Seite der Partei befindet sich das Wave-Gerät für Rechenzentren. Es funktioniert noch nicht vollständig, obwohl die Chips einigen Kunden im Rahmen des Beta-Programms zur Verfügung stehen:

Was macht dieses Gerät? Wissen Sie, wie man in Python programmiert? Hier in Python können Sie mithilfe der TensorFlow-Bibliothek das sogenannte Data Flow Graph (DFG) aufrufen. Neuronale Netze sind im Wesentlichen solche spezialisierten Graphen mit Operationen auf Matrizen. In der Wave-Softwaregruppe, die teilweise von Steve Johnson geleitet wird, gibt es einen Compiler mit einer Teilmenge der Google TensorFlow-Darstellung in Konfigurationsdateien für die Chips dieses Geräts. Nach der Konfiguration können solche Diagramme sehr schnell berechnet werden. Das Gerät ist für Rechenzentren konzipiert, aber das gleiche Prinzip kann auf kleine Chips angewendet werden, auch in mobilen Geräten, beispielsweise zur Gesichtserkennung:

Chijioke Anyanwu (links) - Seit vielen Jahren ist er der Verwalter des gesamten MIPS-Prozessorkern-Testsystems. Baldwyn Chieh (Mitte) ist der Designer der neuen Generation prozessorähnlicher Elemente in Wave. Baldwin war Senior Designer bei Qualcomm. Hier sind die
Folien zum Wave-Gerät von der HotChips-Konferenz :


Die nanometerdigitale digitale Innovations-KI jedes Silicon Valley-Unternehmens muss ein eigenes Mädchen mit hellem Haar haben. Hier ist so ein Mädchen in Wave. Sie heißt Athena, ist ausgebildete Soziologin und im Büro tätig:

Und so sieht das Büro von außen aus und seine mehr als hundertjährige Geschichte aus der Zeit, als es eine innovative Konservenfabrik war:


Und jetzt lautet die Frage: Wie kann man Architektur, Mikroarchitektur, digitale Schaltkreise und Prinzipien des Entwurfs von KI-Chips verstehen und an solchen Parteien teilnehmen? Am einfachsten ist es, das Lehrbuch „Digitale Schaltkreise und Computerarchitektur“ von David Harris und Sarah Harris zu studieren und für den Sommerpraktikanten zu Wave Computing zu gehen (für den Sommer sollen 15 Praktikanten eingestellt werden). Ich hoffe, dass dies auch in russischen mikroelektronischen Unternehmen möglich ist, die an ähnlichen Entwicklungen beteiligt sind - ELVIS, Milander, Baikal Electronics, IVA Technologies und mehreren anderen. In Kiew kann dies theoretisch in der Firma Melexis erfolgen, die mit dem KPI zusammenarbeitet.
Neulich wurde eine neue, endgültig korrigierte Version des Lehrbuchs Harris & Harris veröffentlicht, die hier kostenlos sein sollte
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , aber Dieser Link funktioniert bei mir nicht und wenn er funktioniert, werde ich einen separaten Beitrag darüber schreiben. Mit Fragen, die während der Interviews in Apple, Intel, AMD gestellt wurden, und auf welchen Seiten dieses Lehrbuchs (und anderer Quellen) können Sie die Antworten sehen.