Nachdem wir uns 2019 kennengelernt hatten und uns ein wenig von der Entwicklung neuer Funktionen für Smart IDReader erholt hatten, erinnerten wir uns daran, dass wir lange Zeit nichts über inländische Prozessoren geschrieben hatten. Aus diesem Grund haben wir uns entschlossen, ein anderes Erkennungssystem für Elbrus dringend zu korrigieren und anzuzeigen.
Als Erkennungssystem wurde das Erkennungssystem von Malobjekten „unter unkontrollierten Bedingungen nach der Methode mit Training nach einem Beispiel“ betrachtet [1]. Dieses System erstellt eine Beschreibung des Bildes basierend auf einzelnen Punkten und ihren Deskriptoren, die es in einer indizierten Datenbank von Bildern durchsucht. Wir haben die Leistung dieses Systems analysiert und den zeitaufwändigsten Teil des Algorithmus auf niedriger Ebene identifiziert, der dann mit den Tools der Elbrus-Plattform optimiert wurde.
Um welche Art von Erkennungssystem handelt es sich?
Derzeit verwenden die meisten Museen und Galerien verschiedene Werkzeuge, um sich unabhängig mit der Ausstellung vertraut zu machen. Neben klassischen Audioguides sind mobile Anwendungen mit Bildverarbeitungs- und Analysemethoden weit verbreitet. Einige dieser Anwendungen erkennen grafische Ausstellungscodes (Balken oder QR) [2], andere [3-4] sind die Eingabedaten Foto- oder Videobilder, bei denen ein Exponat in Nahaufnahme aufgenommen wurde (Smartify, Artbit). Natürlich sind die „mobilen Anleitungen“ der letzteren Kategorie für den Benutzer bequemer [5] als die Lösungen mit manueller Eingabe der Exponatnummer oder QR-Erkennung: Die Nummer und der Code sind recht klein, und ihre Suche und Eingabe erfordert zusätzliche Aktionen, die nicht mit der Expositionsüberprüfung zusammenhängen. Es ist ein solches System, das wir betrachten werden.
Die Aufgabe, Bilder in Bildern zu erkennen, wurde wie folgt formuliert. Bild anfordern muss einer der Klassen zugeordnet werden C = \ {C_i \} _ {i \ in [0, N]} wo - Bildklasse ausstellen bei , - eine Klasse anderer Bilder, die dem Wert „unbekanntes Bild“ entsprechen. Für jeden Referenzbildsatz .
Darüber hinaus haben wir uns von folgenden Annahmen leiten lassen:
- Bild anfordern erhalten mit der Kamera eines mobilen Geräts von einem unvorbereiteten Benutzer während eines Ausflugs, daher:
a) es kann visuelle Defekte enthalten - Blendung, defokussierte Bereiche, Lärm;
b) Winkel, Rahmen, Beleuchtung und Farbbalance sind unbekannt (Abb. 1a);
c) Auf dem Bild können Fremdkörper wie Landschaften, Bilderrahmen und Besucher vorhanden sein (Abb. 1b). - Referenzbild Es ist ein hochauflösendes Bild mit einer Frontalprojektion eines Bildes oder seiner digitalen Wiedergabe. Die Norm enthält keine Fremdkörper und Sichtfehler. Standards können beispielsweise qualitativ gescannte Seiten von Kunstalben sein (Abb. 2).
- Das Bild (sowohl auf Anfrage als auch auf Standard) kann auf jeden Stil angewendet werden - Realismus,
Impressionismus, Abstraktionismus, fraktale Grafiken usw. - Anzahl der Klassen entspricht der Größe der Sammlung und kann für eine Galerie erreicht werden
Hunderttausende von Exponaten [6].

Abbildung 1 - Beispiele für Bildanforderungen a) Ein Bild wird aus der Ferne bei schlechten Lichtverhältnissen fotografiert. B) Ein Besucher befindet sich im Rahmen.

Abbildung 2 - Beispiele für Referenzbilder für Gemälde a) Claude Monet "De Voorzaan en de Westerhem", b) Salvador Dali "La persistència de la memòria"
Die Hauptidee unserer Lösung für dieses Problem basiert auf der Erstellung einer speziellen Beschreibung des Bildes aus dem Eingabebild, die dann zur Suche nach diesem Bild in der Datenbank mit Beschreibungen von Referenzbildern hochauflösender Gemälde verwendet wird, die keinen geometrischen Verzerrungen und anderen Fotodefekten unterliegen. Die Koordinaten der mit dem YACIPE-Algorithmus [7] gefundenen singulären Punkte und ihre RFD-Deskriptoren dienen als solche Beschreibung.
Für jede Referenz Erstellen Sie eine Beschreibung und indizieren Sie sie dann. Für jeden Punkt in der Beschreibung geben Sie einen Datensatz des Formulars ein in einen randomisierten hierarchischen Cluster-Suchbaum [8], mit dem Sie eine ungefähre Suche nach den nächsten Nachbarn mit einem signifikanten Geschwindigkeitsgewinn im Vergleich zu einer linearen Suche durchführen können. Der Hamming-Abstand wird als Metrik verwendet, da wir einen binären Deskriptor verwenden.
Der Erkennungsprozess ist wie folgt:
Im Anforderungsbild Malbereich unter der Annahme der Rechteckigkeit des Rahmens vorlokalisiert. Die Zonensuche wird unter Verwendung des schnellen Viereck-Suchalgorithmus [9] durchgeführt, wobei die Einschränkung des Seitenverhältnisses entfernt wird. Dies verhindert die folgenden Probleme:
- unzureichende Beschreibung des Bildbereichs aufgrund von Fremdkörpern im Rahmen, die spezielle Punkte mit den besten Bewertungen aufweisen können;
- Berechnungskosten für den Vergleich von Deskriptoren von Bereichen außerhalb des Bildes;
- eine signifikante Nichtübereinstimmung in Maßstab und Winkel zwischen dem Standard in der Datenbank und dem Bild des Bildes, was zu einem falschen Ergebnis übereinstimmender Deskriptoren führt.
Das Bild in der gefundenen Zone wird projektiv normalisiert:
wo - projektive Transformation.
Erstellen Sie eine kompakte Beschreibung ::
a) das Bild wird unter Beibehaltung der Proportionen auf eine Standardgröße reduziert, um den Algorithmus skalierbarer zu machen;
b) hochfrequentes Rauschen wird durch ein Gauß-Filter unterdrückt;
c) Singularpunkte werden auf dem resultierenden Bild berechnet, ihre Anzahl ist künstlich begrenzt auf Das Beste durch interne Bewertung von YACIPE;
d) Farb-RFD-ähnliche Deskriptoren der Nachbarschaften der gefundenen singulären Punkte werden berechnet, da es in unserer Aufgabe wichtig war, Informationen über die Farbeigenschaften der Eingabebilder zu speichern. Zum Beispiel sind die Bilder in Abb. 3 es wäre äußerst schwierig, ohne es zu unterscheiden;
d) somit die Beschreibung des Bildes kann dargestellt werden als: w ^ * = \ {\ langle p_i, f_i) \ rangle \} _ {i \ in [1, M]} wo Sind die Koordinaten des i-ten Singularpunktes und Ist der Griff zur Nachbarschaft des i-ten Singularpunktes.
Für jeden Eintrag Der Index führt eine ungefähre Suche nach den nächsten Nachbarn des Deskriptors durch . Das Abstimmungsverfahren wird auf die gefundenen Deskriptoren angewendet - den Deskriptor fügt dem Standard eine Stimme hinzu . Dann werden K Kandidaten mit der höchsten Stimmenzahl ausgewählt.
Für jeden von Mit den ausgewählten Optionen unter Verwendung des RANSAC-Algorithmus wird eine Suche nach projektiver Transformation durchgeführt Übersetzen innerhalb eines gegebenen geometrischen Fehlers Abfragepunkte zu Referenzpunkten . Paar Punkte mit engen Deskriptoren wird als gültige Übereinstimmung angesehen, wenn:
Als Endergebnis wird der Standard ausgewählt für die sich die Anzahl der korrekten Vergleiche als das Maximum herausstellte. Wenn es kleiner als ein bestimmter Schwellenwert ist Das Ergebnis ist die Antwort „Unbekanntes Bild“, um Fehlalarme zu vermeiden (z. B. bei Bildern, für die in der Suchdatenbank keine Beschreibung des Standards vorhanden ist).


Abbildung 3 - Claude Monet. Kathedrale von Rouen, Westfassade, Sonnenlicht (links) und Kathedrale von Rouen, Portal und Turm Saint-Romain in der Sonne (rechts).
Einer der Hauptteile des Systems ist die Suche nach engen Deskriptoren unter Verwendung der Hamming-Distanz als Metrik. Da diese Phase viele Male berechnet wird, ist sie rechenintensiv und benötigt 65% der Systemzeit. Deshalb haben wir es optimiert.
Eine sehr kleine Beschreibung der Architektur von Elbrus
Die Prozessorarchitektur von Elbrus verwendet das Prinzip eines breiten Befehlsworts (Very Long Instruction Word, VLIW). Dies bedeutet, dass der Prozessor Anweisungen in Gruppen ausführt und innerhalb jeder Gruppe keine Abhängigkeiten bestehen und diese Anweisungen parallel ausgeführt werden. Jede solche Gruppe wird ein breites Befehlswort genannt. Breite Befehle werden von einem optimierenden Compiler generiert, der eine detailliertere Analyse des Quellcodes ermöglicht und zu einer effizienteren Parallelisierung führt [10].
Ein Merkmal der Elbrus-Architektur sind die Methoden zum Arbeiten mit dem Speicher. Elbrus-Prozessoren verfügen nicht nur über einen Cache, der die Speicherzugriffszeit optimiert, sondern unterstützen auch eine Hardware-Software-Methode zum Vorablesen von Daten. Diese Methode ermöglicht die Vorhersage von Speicherzugriffen und das Pumpen von Daten in den vorläufigen Datenpuffer. Die Hardware des Prozessors enthält ein spezielles Gerät für den Zugriff auf Arrays (Array Access Unit, AAU). Die Notwendigkeit des Austauschs wird jedoch vom Compiler bestimmt, der spezielle Anweisungen für AAU generiert. Die Verwendung eines Auslagerungsgeräts ist effizienter als das Platzieren von Array-Elementen im Cache, da Array-Elemente am häufigsten nacheinander verarbeitet und selten mehr als einmal verwendet werden [11]. Es ist jedoch zu beachten, dass die Verwendung von Pre-Paging-Puffer auf Elbrus nur möglich ist, wenn mit ausgerichteten Daten gearbeitet wird. Aus diesem Grund erfolgt das Lesen / Schreiben ausgerichteter Daten viel schneller als die entsprechenden Vorgänge für nicht ausgerichtete Daten.
Darüber hinaus unterstützen Elbrus-Prozessoren neben der Parallelität auf Befehlsebene verschiedene Arten von Parallelität: SIMD-Parallelität, Parallelität von Kontrollflüssen, Parallelität von Aufgaben in einem Mehrmaschinenkomplex. Von besonderem Interesse für uns ist die SIMD-Parallelität.
Funktionen der Verwendung des SIMD-Erweiterungsprozessors Elbrus
Die Verwendung von SIMD-Erweiterungen kann in zwei Modi erfolgen: automatisch und direkt. Im ersten Fall wird die Parallelisierung von Operationen vollständig vom Compiler ohne Beteiligung des Entwicklers durchgeführt. Dieser Modus ist begrenzt, da optimierter Code das Verhalten des Quellcodes vollständig wiederholen muss, einschließlich des Verhaltens beim Überlaufen, Runden usw. In diesem Fall kann sich das Verhalten von SIMD-Erweiterungsanweisungen in diesen Aspekten von Prozessoranweisungen unterscheiden. Darüber hinaus sind die in Compilern verwendeten Algorithmen unvollständig und können nicht immer eine effiziente Parallelisierung durchführen. Entwickler können jedoch auch direkt über intrinsics auf SIMD-Erweiterungsbefehle zugreifen. Intrinsics sind Funktionen, deren Aufrufe vom Compiler durch Hochleistungscode für eine bestimmte Plattform ersetzt werden, insbesondere durch SIMD-Erweiterungsbefehle. Die Elbrus-4C- und Elbrus-8C-Prozessoren unterstützen eine Reihe von Eigenheiten, für die die Registergröße 64 Bit beträgt. Es umfasst Operationen zur Datenkonvertierung, Initialisierung von Vektorelementen, arithmetische Operationen, bitweise logische Operationen, Permutation von Vektorelementen usw.
Bei der Verwendung von Intrinsics auf der Elbrus-Plattform sollte besonderes Augenmerk auf den Zugriff auf den Speicher gelegt werden, da praktische Aufgaben, z. B. Bildverarbeitungsaufgaben, häufig ein unausgeglichenes Lesen von Daten in ein 64-Bit-Register erfordern. Ein solches Lesen an sich ist ineffizient, da ein Paar von Lesebefehlen und ein nachfolgender Befehl erforderlich sind, um einen Datenblock zu bilden. Noch wichtiger ist jedoch, dass ein Array-Swap-Puffer nicht verwendet werden kann, um die Geschwindigkeit des Datenzugriffs zu erhöhen. Es ist jedoch anzumerken, dass das Problem des ineffizienten Zugriffs auf nicht ausgerichtete Daten für die Elbrus-4C- und Elbrus-8C-Prozessoren relevant ist, während es für das neuere Elbrus-8CV mit der 5. Version des Befehlssystems teilweise gelöst ist. Es wird erwartet, dass Elbrus-Prozessoren mit der 6. Version des Befehlssystems vollständig gelöst werden.
Auf den Elbrus-4C- und Elbrus-8C-Prozessoren wird die Datenverarbeitung auf niedriger Ebene jedoch unter Berücksichtigung der Ausrichtung effizient durchgeführt. Beispielsweise kann es für numerische Arrays aus mehreren Schritten bestehen: Verarbeiten des Anfangsteils (bis zur 64-Bit-Ausrichtungsgrenze eines der Arrays), Verarbeiten des Hauptteils unter Verwendung des ausgerichteten Speicherzugriffs und Verarbeiten der verbleibenden Elemente des Arrays. Da das Parsen von Zeigern während der Kompilierung keine triviale Aufgabe ist, können Sie das Compiler- –faligned , mit dem alle Speicherzugriffsvorgänge ausgerichtet ausgeführt werden.
Die nächste Funktion zur Verwendung von Intrinsics auf der Elbrus-Plattform steht in direktem Zusammenhang mit der VLIW-Architektur. Aufgrund des Vorhandenseins mehrerer arithmetischer Logikbausteine (ALU), die parallel arbeiten und beim Bilden breiter Befehlswörter geladen werden, können mehrere Befehle gleichzeitig ausgeführt werden. Insgesamt verfügen die Elbrus-4C- und Elbrus-8C-Prozessoren über sechs ALUs, die als Teil eines breiten Teams verwendet werden können. Jede ALU unterstützt jedoch ihre eigenen Eigenheiten. Einfache Operationen wie das Hinzufügen oder Multiplizieren von Elementen in 64-Bit-Registern unterstützen in der Regel zwei ALUs. Dies bedeutet, dass der Elbrus-Prozessor zwei solcher Befehle in einem einzigen Taktzyklus ausführen kann. Zu diesem Zweck sollte in ausführbarem Code eine Ausführungsschleife verwendet werden. Der optimierende Compiler für die Elbrus-Plattform unterstützt das Pragma #pragma unroll(n) , mit dem n Schleifeniterationen bereitgestellt werden können.
Ein Beispiel für die Implementierung der Additionsfunktion unter Berücksichtigung dieser Funktionen finden Sie in unserem vorherigen Artikel .
Die Experimente
Hurra, der Text ist vorbei und endlich werden wir etwas auf Elbrus starten!
Zunächst betrachten wir den Hamming-Abstand separat. Ohne weiteres haben wir zwei Bitvektoren von Zufallsdaten verglichen. Die Binärwerte wurden in Arrays von 8-Bit-Ganzzahlen gepackt, und der Einfachheit halber dachten wir, dass die Längen der ursprünglichen Vektoren ein Vielfaches von 8 sind. Wie üblich wird der Code in C ++ geschrieben, kompiliert von lcc 1.21.24 - einem optimierenden Elbrus-Compiler.
Wir haben mehrere Implementierungen von Hamming Distance geschrieben, die nacheinander die Merkmale von Elbrus-Prozessoren berücksichtigten. Sie sahen so aus:
- Ein bitweises XOR zwischen 8-Bit-Ganzzahlen und einer Tabelle vorberechneter Werte wird verwendet. Dies ist eine grundlegende Implementierung ohne Probleme und andere Tricks.
- Es verwendet XOR zwischen 32-Bit-Ganzzahlen und Intrinsics, um die Anzahl der Einheiten in einer 32-Bit-Ganzzahl - popcnt32 - zu berechnen. Eine 32-Bit-Grenzausrichtung wurde nicht durchgeführt.
- Es verwendet XOR zwischen 64-Bit-Ganzzahlen und Intrinsics, um die Anzahl der Einheiten in einer 64-Bit-Ganzzahl zu berechnen - popcnt64. Eine 64-Bit-Rahmenausrichtung wurde nicht durchgeführt.
- Es verwendet XOR zwischen 64-Bit-Ganzzahlen und Intrinsics, um die Anzahl der Einheiten in einer 64-Bit-Ganzzahl zu berechnen - popcnt64. Der Zugriff auf den Speicher erfolgt ausgerichtet. Da die Startadressen von Arrays unterschiedlich ausgerichtet sein können, werden beim Lesen eines der Arrays zwei benachbarte 64-Bit-Blöcke gelesen und der erforderliche 64-Bit-Block daraus gebildet.
- Es verwendet XOR zwischen 64-Bit-Ganzzahlen und Intrinsics, um die Anzahl der Einheiten in einer 64-Bit-Ganzzahl zu berechnen - popcnt64. Der Zugriff auf den Speicher erfolgt ausgerichtet. Da die Startadressen von Arrays unterschiedlich ausgerichtet sein können, werden beim Lesen eines der Arrays zwei benachbarte 64-Bit-Blöcke gelesen und der erforderliche 64-Bit-Block daraus gebildet. Zusätzlich wird das Compiler-Flag
-faligned . - Es verwendet XOR zwischen 64-Bit-Ganzzahlen und Intrinsics, um die Anzahl der Einheiten in einer 64-Bit-Ganzzahl zu berechnen - popcnt64. Der Zugriff auf den Speicher erfolgt ausgerichtet. Da die Startadressen von Arrays unterschiedlich ausgerichtet sein können, werden beim Lesen eines der Arrays zwei benachbarte 64-Bit-Blöcke gelesen und der erforderliche 64-Bit-Block daraus gebildet. Zusätzlich wurden das
-faligned Compiler- -faligned und die Compiler-Pragmas #pragma unroll(2) (um beide verfügbaren ALUs zur Berechnung von popcnt64 zu verwenden) und #pragma loop count(1000) (um zusätzliche #pragma loop count(1000) zu ermöglichen) verwendet.
Die Ergebnisse der Zeitmessungen sind in Tabelle 1 gezeigt.
Tabelle 1. Zeit für die Berechnung des Hamming-Abstands zwischen zwei Arrays gepackter Binärzahlen mit einer Länge von 10 ^ 5 auf einer Maschine mit einem Elbrus-4C-Prozessor. Die über 10 ^ 5 gemittelte Zeit beginnt.
| Nein, nein. | Ein Experiment | Zeit, ms |
|---|
| 1 | Tabelle der berechneten Werte | 141,18 |
| 2 | popcnt32, keine Ausrichtung | 125,54 |
| 3 | popcnt64, keine Ausrichtung | 58.00 |
| 4 | popcnt64 Ausrichtung | 17.36 |
| 5 | popcnt64 Ausrichtung, -faligned | 17.15 |
| 6 | popcnt64, Ausrichtung, -faligned, pragma unroll | 12.23 |
Es ist ersichtlich, dass alle berücksichtigten Optimierungen zu einer 11,5-fachen Verringerung der Laufzeit führten. Es ist anzumerken, dass die Verwendung von Intrinsics mit unausgeglichenem Zugriff auf den Speicher nur eine 1,13-fache (für popcnt32) und 2,4-fache (für popcnt64) Beschleunigung aufwies, während die Berücksichtigung der Datenausrichtung zur Verwendung des APB-Array-Swap-Puffers führte mit deren Hilfe eine weitere Beschleunigung um das 3,4-fache (58 ms gegenüber 17,15 ms) erreicht werden konnte. Trotz der Tatsache, dass die Verwendung des Flags -faligned im obigen Beispiel keinen signifikanten Leistungsgewinn zeigte, kann es bei komplexeren Algorithmen vorkommen, dass der Compiler den Quellcode nicht tief genug analysieren kann, um Befehle für APB zu generieren. Unter Berücksichtigung der tatsächlichen Anzahl spezialisierter ALUs konnten wir die Berechnungen um das 1,4-fache beschleunigen.
Nicht so schlimm! Da wir bis zu 6 Implementierungsoptionen verglichen haben, geben wir den Pseudocode des endgültigen, schnellsten an:
: 8- A B, T, T[i] i : res, A B offset ← A 64- effective_len ← , 64- for i from 1 to offset: res ← res + T[xor(A[i] , B[i])] v_a ← 64- , A[offset+1] v_b1 ← 64- , B[offset] v_b2 ← 64- , v_b1 // 64- for i from offset to effective_len: v_b ← align(v_b1, v_b2) // 64- , v_a res ← res + popcnt64(xor(v_a, v_b)) v_a ← 64- v_b1 ← v_b2 v_b2 ← 64- //
Es wäre ein für allemal großartig, die Berechnung der Hamming-Distanz um das 11,5-fache zu beschleunigen, aber im Leben ist alles etwas komplizierter: Eine solche Implementierung hat nur bei ausreichend großen Arraylängen einen Vorteil. In Abb. Abbildung 4 zeigt einen Vergleich der Berechnungszeit anhand der Tabelle der vorberechneten Werte und unserer endgültigen Implementierung. Sie können sehen, dass unsere Version erst ab einer Länge von mehr als 400 Byte gewinnt. Dies muss auch bei der Optimierung auf Elbrus berücksichtigt werden.
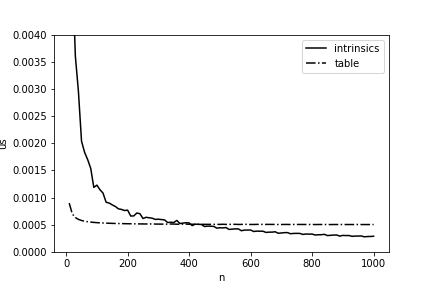
Abbildung 4 - Durchschnittliche Zeit (pro 1 Byte) für die Berechnung des Hamming-Abstands zwischen zwei Arrays in Abhängigkeit von ihrer Länge bei Elbrus-4C.
Das ist alles, jetzt sind wir bereit, die Betriebszeit des gesamten Systems zu messen. Wir haben die durchschnittliche Anforderungsverarbeitungszeit (ohne Laden von Bildern) für 933 Anforderungen gemessen. Bei der Erstellung einer kompakten Beschreibung des Bildes wurde ein 5328-Bit-Farb-RFD-ähnlicher Binärdeskriptor verwendet. Es bestand aus 3 verketteten grauen RFD-Deskriptoren mit 1776 Bit, die für jeden Kanal des Eingangsbildabschnitts berechnet wurden. Einerseits gefallen solche langen Deskriptoren nicht mit einer hohen Geschwindigkeit der Berechnung und des Vergleichs, andererseits bieten sie eine ausreichend hohe Arbeitsqualität. Es gibt jedoch gute Nachrichten - wir können die schnelle Implementierung der Hamming-Distanz nutzen, um sie zu vergleichen! Die Längen der verglichenen Arrays betragen 666 Bytes, was mehr als der Schwellenwert von 400 Bytes für Elbrus-4C ist.
Die Messergebnisse sind in Tabelle 2 gezeigt. Es ist ersichtlich, dass nur eine schnelle Implementierung der Hamming-Distanz eine 1,5-mal schnellere Abfrageverarbeitung ergibt. Es ist auch erwähnenswert, dass diese Optimierung die Ergebnisse von Berechnungen und damit die Qualität der Erkennung nicht verändert.
Tabelle 2. Durchschnittliche Verarbeitungszeit einer Anforderung an ein Erkennungssystem zum Malen von Objekten unter unkontrollierten Bedingungen.
| Ein Experiment | Zeit anfordern, s | Hamming Distanzberechnung dauerte | Beschleunigungszeiten |
|---|
| Basisimplementierung | 2.81 | 63% | - - |
| Schnelle Implementierung | 1,87 | 40% | 1.5 |
Fazit
In diesem Artikel haben wir ein wenig über die Struktur des Erkennungssystems zum Malen von Objekten unter unkontrollierten Bedingungen gesprochen und erneut gezeigt, wie Manipulationen auf niedriger Ebene die Geschwindigkeit auf der Elbrus-Plattform erheblich steigern können. Die vorgeschlagene Implementierung der Hamming-Distanz funktioniert also um eine Größenordnung (!) Schneller als die Implementierung unter Verwendung einer Tabelle vorberechneter Werte mit einer ausreichend großen Länge der Eingabevektoren, und das gesamte System wurde um das Eineinhalbfache beschleunigt! Um dieses Ergebnis zu erzielen, wurden SIMD-Erweiterungen verwendet und die Architektur- und Speicherzugriffsfunktionen von Elbrus-4C- und Elbrus-8C-Prozessoren berücksichtigt. Diese Ergebnisse zeigen, dass Elbrus-Prozessoren erhebliche Ressourcen für einen effizienten Betrieb enthalten, die ohne speziell durchgeführte Optimierung nicht vollständig genutzt werden. Es wird jedoch erwartet, dass die Speicherzugriffsmethoden auf neueren Elbrus-Prozessoren verbessert werden, wodurch einige dieser Optimierungen automatisch durchgeführt werden können und das Leben der Entwickler erheblich erleichtert wird.
Literatur
[1] N.S. Skoryukina, A.N. Milovzorov, D.V. Field, V.V. Arlazarov. Die Methode zur Erkennung von Malobjekten unter unkontrollierten Bedingungen mit Training nach einem Beispiel // Transaktionen von ISA RAS. - Sonderausgabe, 2018 - p. 5-15.
[2] Pérez-Sanagustín M. et al. Verwendung von QR-Codes zur Steigerung des Benutzereingriffs in musealen Räumen // Computer im menschlichen Verhalten. - 2016. - T. 60. - S. 73-85. doi: 10.1016 / j.chb.2016.02.02.012
[3] Antoshchuk S. G., Godovichenko N. A. Analyse der Punktmerkmale des Bildes im Mobile Virtual Guide-System // Pratsi. - 2013. - Nein. 1 (40). - S. 67-72.
[4] Andreatta C., Leonardi F. Auf Aussehen basierende Bilderkennung für einen mobilen Museumsführer // Internationale Konferenz für Theorie und Anwendungen des Computer-Sehens, VISAPP. - 2006.
[5] Leonard Wein. 2014. Visuelle Erkennung in Museumsführer-Apps: Wollen Besucher es? .. In Proceedings der SIGCHI-Konferenz über Human Factors in Computersystemen (CHI '14). ACM, New York, NY, USA, 635-638.
doi: 10.1145 / 2556288.2557270
[6] Tretyakov Gallery, https://www.tretyakovgallery.ru/collection/
[7] Lukoyanov A. S., Nikolaev D. P., Konovalenko I. A. Modifikation des YAPE-Algorithmus für Bilder mit einer großen Streuung lokaler Kontraste // Informationstechnologien und Nanotechnologien. - 2018 - S. 1193-1204.
[8] Muja M., Lowe DG Schnelle Anpassung von Binärmerkmalen // Computer and Robot Vision (CRV), 9. Konferenz 2012 über. - IEEE, 2012 - S. 404-410.
doi: 10.1109 / CRV.2012.60
[9] N. Skoryukina, DP Nikolaev, A. Sheshkus, D. Polevoy (2015, Februar). Rechteckige Dokumentenerkennung in Echtzeit auf Mobilgeräten. In der siebten internationalen Konferenz über Bildverarbeitung (ICMV 2014) (Vol. 9445, S. 94452A). Internationale Gesellschaft für Optik und Photonik.
doi: 10.1117 / 12.2181377
[10] Kim A.K., Bychkov I.N. und andere russische Technologien „Elbrus“ für PCs, Server und Supercomputer // Moderne Informationstechnologien und IT-Bildung, M .: Grundlage für die Entwicklung von Internetmedien, IT-Bildung, Humanpotential „Liga der Internetmedien“, 2014, Nr. 10, p. 39-50.
[11] Kim A.K., Perekatov V.I., Ermakov S.G. Mikroprozessoren und Computersysteme
die Familie Elbrus. - St. Petersburg: Peter, 2013. - 272 S.