Vor einiger Zeit haben sich unter der Marke VTB drei große Banken zusammengeschlossen: VTB, Ex-VTB24 und Ex-Bank of Moscow. Für externe Beobachter arbeitet die kombinierte VTB-Bank jetzt als Ganzes, aber von innen sieht alles viel komplizierter aus. In diesem Beitrag werden wir über Pläne sprechen, ein einheitliches Netzwerk der integrierten VTB-Bank zu schaffen, Life-Hacks über die Organisation der Interaktion von Firewalls auszutauschen, Netzwerksegmente zu verbinden und zu kombinieren, ohne die Dienste zu unterbrechen.
Schwierigkeiten beim Zusammenspiel unterschiedlicher Infrastrukturen
Die Aktivitäten von VTB werden derzeit von drei bestehenden Infrastrukturen unterstützt: Ex-Bank of Moscow, Ex-VTB24 und VTB selbst. Die Infrastrukturen von jedem von ihnen haben ihre eigenen Netzwerkperimeter, an deren Grenze sich Schutzausrüstung befindet. Eine der Bedingungen für die Integration von Infrastrukturen auf Netzwerkebene ist das Vorhandensein einer konsistenten IP-Adressierungsstruktur.
Unmittelbar nach dem Zusammenführen haben wir begonnen, die Adressräume auszurichten, und jetzt steht die Fertigstellung kurz bevor. Der Prozess ist jedoch zeitaufwändig und schnell, und die Fristen für die Organisation des Querzugriffs zwischen Infrastrukturen waren sehr eng. Daher haben wir in der ersten Phase die Infrastrukturen verschiedener Banken in ihrer jetzigen Form miteinander verbunden - durch Firewalling für eine Reihe von Hauptsicherheitszonen. Gemäß diesem Schema ist es zum Organisieren des Zugriffs von einem Netzwerkperimeter zu einem anderen erforderlich, den Verkehr durch viele Firewalls und andere Schutzmittel zu leiten, die unter Verwendung von NAT- und PAT-Technologien an die gemeinsamen Adressen von Ressourcen und Benutzern gesendet werden. Darüber hinaus sind alle Firewalls an den Kreuzungen sowohl lokal als auch geografisch reserviert. Dies muss bei der Organisation von Interaktionen und beim Aufbau von Serviceketten immer berücksichtigt werden.
Ein solches Schema ist ziemlich funktional, aber Sie können es sicherlich nicht als optimal bezeichnen. Es gibt sowohl technische als auch organisatorische Probleme. Es ist notwendig, die Interaktionen vieler Systeme zu koordinieren und zu dokumentieren, deren Komponenten über verschiedene Infrastrukturen und Sicherheitszonen verteilt sind. Gleichzeitig ist es bei der Umgestaltung von Infrastrukturen erforderlich, diese Dokumentation für jedes System schnell zu aktualisieren. Die Durchführung dieses Prozesses belastet unsere wertvollste Ressource - hochqualifizierte Spezialisten - erheblich.
Technische Probleme äußern sich in der Multiplikation des Datenverkehrs auf den Verbindungen, der hohen Anzahl an Sicherheitstools, der Komplexität der Organisation von Netzwerkinteraktionen und der Unfähigkeit, einige Interaktionen ohne Adressübersetzung zu erstellen.
Das Problem der Verkehrsmultiplikation entsteht hauptsächlich aufgrund der vielen Sicherheitszonen, die über Firewalls an verschiedenen Standorten miteinander interagieren. Unabhängig vom geografischen Standort der Server selbst wird der Datenverkehr, wenn er über den Umfang der Sicherheitszone hinausgeht, eine Reihe von Sicherheitsfunktionen durchlaufen, die sich möglicherweise an anderen Standorten befinden. Zum Beispiel haben wir zwei Server in einem Rechenzentrum, aber einen im Umkreis von VTB und den anderen im Umkreis des Ex-VTB24-Netzwerks. Der Datenverkehr zwischen ihnen erfolgt nicht direkt, sondern über 3-4 Firewalls, die in anderen Rechenzentren aktiv sein können. Der Datenverkehr wird mehrmals über das Trunk-Netzwerk an die Firewall und zurück übertragen.
Um eine hohe Zuverlässigkeit zu gewährleisten, benötigen wir jede Firewall in 3-4 Kopien - zwei an einem Standort in Form eines HA-Clusters und eine oder zwei Firewalls an einem anderen Standort, zu denen der Datenverkehr umgeschaltet wird, wenn der Haupt-Firewall-Cluster oder der Standort insgesamt unterbrochen wird.
Wir fassen zusammen. Drei unabhängige Netzwerke sind eine
Menge Probleme : übermäßige Komplexität, der Bedarf an zusätzlichen teuren Geräten, Engpässe, Redundanzschwierigkeiten und infolgedessen hohe Kosten für den Betrieb der Infrastruktur.
Allgemeiner Integrationsansatz
Da wir uns entschlossen haben, die Transformation der Netzwerkarchitektur zu übernehmen, werden wir mit den grundlegenden Dingen beginnen. Lassen Sie uns von oben nach unten gehen und zunächst die Anforderungen des Unternehmens, der Bewerber, der Systemingenieure und des Sicherheitspersonals analysieren.
- Basierend auf ihren Anforderungen entwerfen wir die Zielstruktur von Sicherheitszonen und die Prinzipien der Verbindung zwischen diesen Zonen.
- Wir legen diese Zonenstruktur auf die Geografie unserer Hauptverbraucher - Rechenzentren und große Büros.
- Als nächstes bilden wir das Transport-MPLS-Netzwerk.
- Darunter bringen wir bereits das primäre Netzwerk, das Dienste für die physische Schicht bereitstellt.
- Wir wählen Standorte für die Platzierung von Edge-Modulen und Firewall-Modulen.
- Nachdem das Zielbild geklärt ist, erarbeiten und genehmigen wir die Migrationsmethode von der vorhandenen Infrastruktur zur Zielinfrastruktur, damit der Prozess für funktionierende Systeme transparent ist.
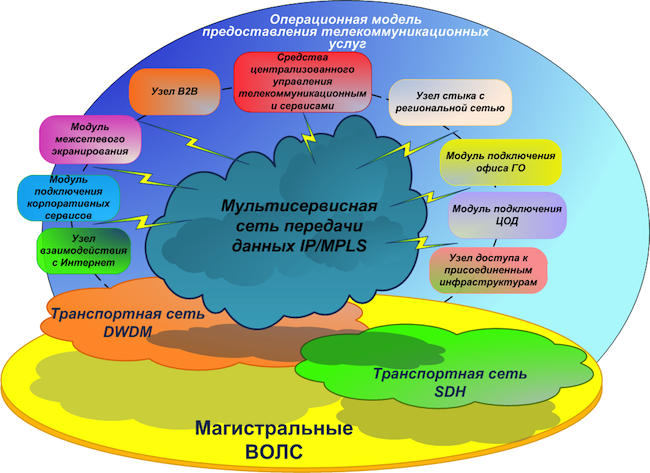
ZielnetzwerkkonzeptWir werden ein primäres Backbone-Netzwerk haben - dies ist eine Telekommunikations-Transportinfrastruktur, die auf Glasfaser-Kommunikationsleitungen (FOCL), passiven und aktiven kanalbildenden Geräten basiert. Es kann auch das xWDM-Subsystem für die optische Kanalverdichtung und möglicherweise ein SDH-Netzwerk verwenden.
Basierend auf dem primären Netzwerk bauen wir das sogenannte
Kernnetzwerk auf . Es wird einen einzelnen Adressplan und einen einzelnen Satz von Routing-Protokollen haben. Das Kernnetz umfasst:
- MPLS - Multiservice-Netzwerk;
- DCI - Verbindungen zwischen Rechenzentren;
- EDGE-Module - verschiedene Verbindungsmodule: Firewall, Partnerorganisationen, Internetkanäle, Rechenzentren, LANs, regionale Netzwerke.
Wir
erstellen ein Multiservice-Netzwerk
nach einem hierarchischen Prinzip mit der Zuordnung von Transit- (P) und Endknoten (PE) . Bei einer vorläufigen Analyse der heute auf dem Markt verfügbaren Geräte wurde klar, dass es wirtschaftlicher ist, die Pegel von P-Knoten auf separate Geräte zu übertragen, als die P / PE-Funktionalität in einem Gerät zu kombinieren.
Ein Multiservice-Netzwerk bietet hohe Verfügbarkeit, Fehlertoleranz, minimale Konvergenzzeit, Skalierbarkeit, hohe Leistung und Funktionalität, insbesondere IPv6- und Multicast-Unterstützung.
Während des Aufbaus des Backbone-Netzwerks beabsichtigen wir
, proprietäre Technologien aufzugeben (soweit dies möglich ist, ohne die Qualität zu beeinträchtigen), da wir uns bemühen, die Lösung flexibel und nicht an einen bestimmten Anbieter gebunden zu machen. Gleichzeitig wollen wir aber keine „Vinaigrette“ aus den Geräten verschiedener Anbieter herstellen. Unser grundlegendes Konstruktionsprinzip besteht darin, bei Verwendung von Geräten die maximale Anzahl von Diensten bereitzustellen, die für diese Anzahl von Anbietern minimal ausreicht. Dies ermöglicht es unter anderem, die Wartung der Netzwerkinfrastruktur mit einer begrenzten Anzahl von Mitarbeitern zu organisieren. Es ist auch wichtig, dass die neuen Geräte mit vorhandenen Geräten kompatibel sind, um einen nahtlosen Migrationsprozess zu gewährleisten.
Die Struktur der Sicherheitszonen der Netze VTB, Ex-VTB24 und Ex-Bank von Moskau im Rahmen des Projekts soll komplett neu gestaltet werden, um funktional doppelte Segmente zu kombinieren. Eine einheitliche Struktur von Sicherheitszonen mit gemeinsamen Routing-Regeln und einem einheitlichen Konzept für den Zugang zum Internetwork ist geplant. Wir planen, eine Firewall zwischen Sicherheitszonen mithilfe separater Hardware-Firewalls durchzuführen, die an zwei Hauptstandorten verteilt sind. Wir planen außerdem, alle Edge-Module unabhängig voneinander an zwei verschiedenen Standorten mit automatischer Redundanz zwischen ihnen basierend auf standardisierten dynamischen Routing-Protokollen zu implementieren.
Wir organisieren die Verwaltung der Geräte des Kernnetzwerks über ein separates physisches Netzwerk (Out-of-Band). Der administrative Zugriff auf alle Netzwerkgeräte erfolgt über einen einzigen Dienst für Authentifizierung, Autorisierung und Buchhaltung (AAA).
Um Probleme im Netzwerk schnell zu finden, ist es sehr wichtig, den Datenverkehr von jedem Punkt im Netzwerk zur Analyse kopieren und über einen unabhängigen Kommunikationskanal an den Analysator senden zu können. Zu diesem Zweck erstellen wir ein isoliertes Netzwerk für den SPAN-Verkehr, mit dessen Hilfe wir Verkehrsströme sammeln, filtern und an Analyseserver übertragen.
Um die vom Netzwerk bereitgestellten Dienste und die Möglichkeit der Kostenverteilung zu standardisieren, werden wir einen einzigen Katalog mit SLA-Indikatoren einführen. Wir gehen weiter zum Servicemodell, in dem wir die Verknüpfung der Netzwerkinfrastruktur mit angewandten Aufgaben, die Verknüpfung von Elementen von Steuerungsanwendungen und deren Auswirkungen auf Services berücksichtigen. Dieses Servicemodell wird von einem Netzwerküberwachungssystem unterstützt, damit wir die IT-Kosten korrekt zuordnen können.
Von der Theorie zur Praxis
Jetzt gehen wir eine Ebene tiefer und informieren Sie über die interessantesten Lösungen in unserer neuen Infrastruktur, die für Sie nützlich sein können.
Ressourcenwald: Details
Wir haben
die Einwohner von Chabrowsk bereits mit dem VTB-Ressourcenwald
vertraut gemacht. Versuchen Sie nun, eine detailliertere technische Beschreibung zu geben.
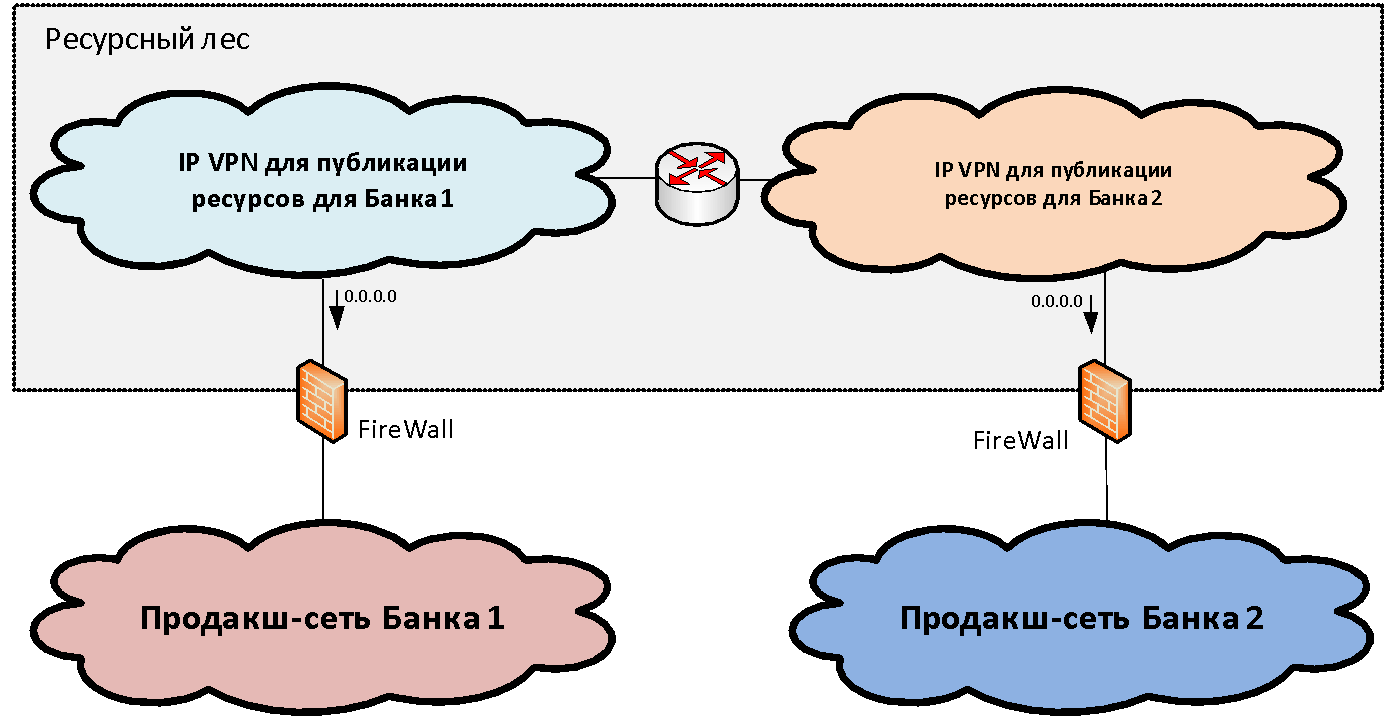
Angenommen, wir haben zwei (der Einfachheit halber) Netzwerkinfrastrukturen verschiedener Organisationen, die kombiniert werden müssen. Innerhalb jeder Infrastruktur kann in der Regel unter den funktionalen Netzwerksegmenten (Sicherheitszonen) das wichtigste produktive Netzwerksegment unterschieden werden, in dem sich die wichtigsten industriellen Systeme befinden. Wir verbinden diese Produktivzonen mit einer bestimmten Struktur von Sperrsegmenten, die wir als
„Ressourcenwald“ bezeichnen . Diese Gateway-Segmente veröffentlichen die gemeinsam genutzten Ressourcen, die von den beiden Infrastrukturen verfügbar sind.
Das Konzept einer Ressourcengesamtstruktur besteht aus Netzwerksicht darin, eine Gateway-Sicherheitszone zu erstellen, die aus zwei IP-VPNs besteht (für den Fall von zwei Banken). Diese IP-VPNs werden frei untereinander geroutet und über Firewalls mit produktiven Segmenten verbunden. Die IP-Adressierung für diese Segmente wird aus einem disjunkten Bereich von IP-Adressen ausgewählt. Somit wird ein Routing in Richtung der Ressourcenstruktur aus den Netzwerken beider Organisationen möglich.
Beim Routing vom Ressourcenwald zu den Industriesegmenten ist die Situation jedoch etwas schlimmer, da sich die Adressierung in diesen häufig überschneidet und es unmöglich ist, eine einzige Tabelle zu bilden. Um dieses Problem zu lösen, benötigen wir nur zwei Segmente in der Ressourcengesamtstruktur. In jedem der Segmente der Ressourcengesamtstruktur wird eine Standardroute in Richtung des industriellen Netzwerks "ihrer" Organisation geschrieben. Das heißt, Benutzer können über PAT zugreifen, ohne Adressen in ihr „eigenes“ Segment der Ressourcengesamtstruktur und in ein anderes Segment zu übersetzen.
Somit stellen zwei Segmente der Ressourcengesamtstruktur eine einzelne Gateway-Sicherheitszone dar, wenn Sie die Grenze entlang der Firewalls zeichnen. Jeder von ihnen hat sein eigenes Routing: Das Standard-Gateway blickt auf "seine" Bank. Wenn wir eine Ressource in einem Segment der Ressourcengesamtstruktur platzieren, können Benutzer der entsprechenden Bank ohne NAT damit interagieren.
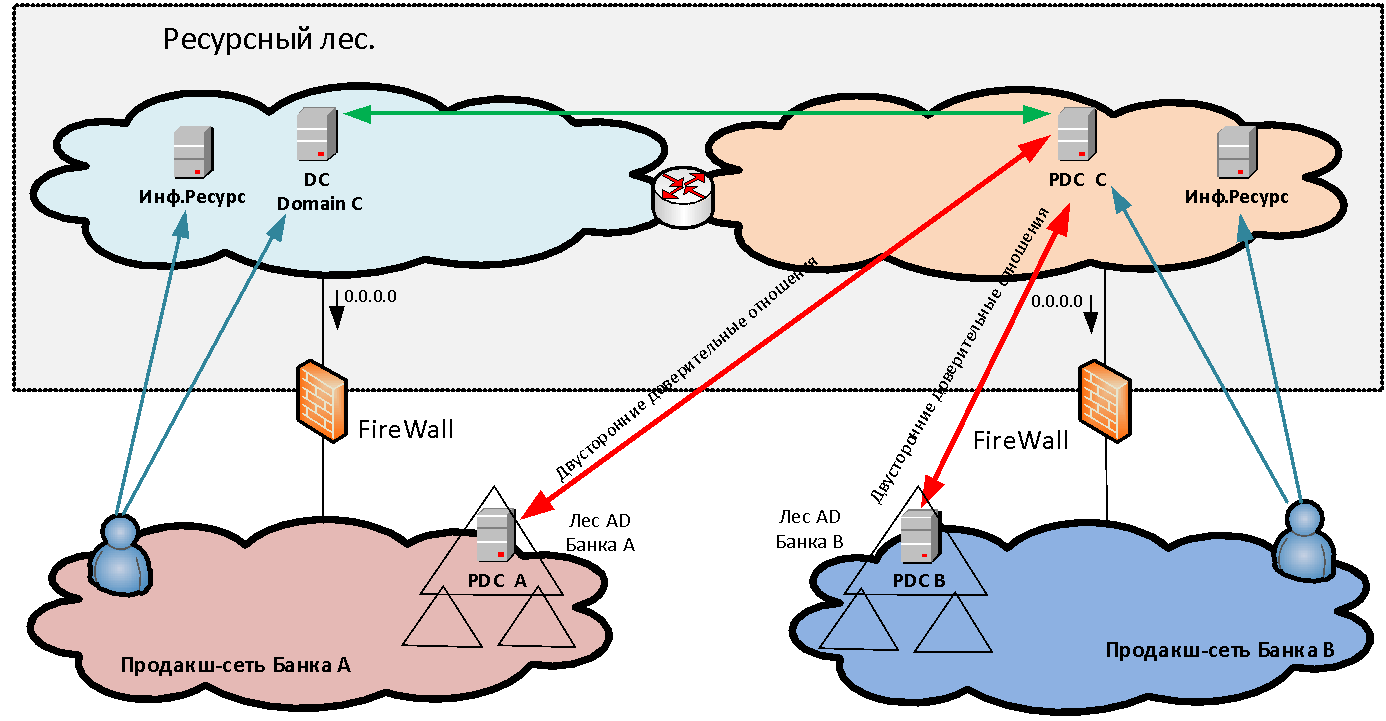
Die Interaktion ohne NAT ist für viele Systeme und vor allem für Microsoft-Domäneninteraktionen sehr wichtig. Schließlich verfügen wir in der Ressourcenstruktur über Active Directory-Server für die neue gemeinsame Domäne, mit denen von beiden Organisationen Vertrauensstellungen eingerichtet werden. Ohne NAT-Interaktion sind auch Systeme wie Skype for Business, ABS „MBANK“ und viele andere verschiedene Anwendungen erforderlich, bei denen der Server zur Adresse des Clients zurückkehrt. Und wenn sich der Client hinter PAT befindet, wird die umgekehrte Verbindung nicht mehr hergestellt.
Die Server, die wir in den Segmenten der Ressourcengesamtstruktur installieren, sind in zwei Kategorien unterteilt: Infrastruktur (z. B. MS AD-Server) und Zugriff auf einige Informationssysteme. Der letzte Servertyp, den wir Data Marts nennen. Storefronts sind normalerweise Webserver, deren Backend sich bereits hinter der Firewall im Produktionsnetzwerk der Organisation befindet, die diese Storefront in der Ressourcengesamtstruktur erstellt hat.
Und wie werden
Benutzer beim Zugriff auf veröffentlichte Ressourcen
authentifiziert ? Wenn wir einfach einem oder zwei Benutzern in einer anderen Domäne Zugriff auf einige Anwendungen gewähren, können wir für sie separate Konten für die Authentifizierung in unserer Domäne erstellen. Wenn wir jedoch über den Massenzusammenschluss von Infrastrukturen sprechen - beispielsweise 50.000 Benutzer - ist es völlig unrealistisch, separate Cross-Accounts für diese zu starten und zu verwalten. Das Erstellen direkter Vertrauensstellungen zwischen Gesamtstrukturen verschiedener Organisationen ist sowohl aus Sicherheitsgründen als auch aufgrund der Notwendigkeit, PAT-Benutzer unter den Bedingungen sich überschneidender Adressräume zu machen, nicht immer möglich. Um das Problem der einheitlichen Benutzerauthentifizierung zu lösen, wird daher im Umfang der Ressourcengesamtstruktur eine neue MS AD-Gesamtstruktur erstellt, die aus einer Domäne besteht. In dieser neuen Domäne authentifizieren sich Benutzer beim Zugriff auf Dienste. Um dies zu ermöglichen, werden bilaterale Vertrauensstellungen auf Forstebene zwischen der neuen Gesamtstruktur und den Domänenwäldern jeder Organisation eingerichtet. Somit kann sich der Benutzer einer der Organisationen bei jeder veröffentlichten Ressource authentifizieren.
Netzwerkintegration erhalten
Nachdem wir die Interaktion von Systemen über die Infrastruktur des Ressourcenwaldes hergestellt und damit die akuten Symptome beseitigt hatten, war es an der Zeit, die direkte Integration von Netzwerken aufzunehmen.
Zu diesem Zweck haben wir in der ersten Phase die Produktsegmente von drei Banken mit einer einzigen leistungsstarken Firewall verbunden (logisch vereinheitlicht, aber physisch oft an verschiedenen Standorten reserviert). Die Firewall bietet eine direkte Interaktion zwischen den Systemen verschiedener Banken.
Mit ex-VTB24 ist es uns bereits gelungen, die Adressräume auszurichten, bevor direkte Interaktionen zwischen den Systemen organisiert wurden. Nachdem wir die Routing-Tabellen in der Firewall erstellt und die entsprechenden Zugriffe geöffnet hatten, konnten wir die Interaktion zwischen Systemen in zwei verschiedenen Infrastrukturen sicherstellen.
Bei der Ex-Bank von Moskau waren die Adressräume zum Zeitpunkt der Organisation der angewandten Interaktionen nicht aufeinander abgestimmt, und wir mussten das gegenseitige NAT verwenden, um die Interaktion der Systeme zu organisieren. Die Verwendung von NAT verursachte eine Reihe von DNS-Auflösungsproblemen, die durch die Pflege doppelter DNS-Zonen behoben wurden. Darüber hinaus gab es aufgrund von NAT Schwierigkeiten beim Betrieb einer Reihe von Anwendungssystemen. Jetzt haben wir die Schnittpunkte von Adressräumen fast beseitigt, aber wir sind mit der Tatsache konfrontiert, dass viele Systeme von VTB und Ex-Bank of Moscow eng miteinander verbunden sind, um an den übersetzten Adressen zu interagieren. Jetzt müssen wir diese Interaktionen auf echte IP-Adressen migrieren und gleichzeitig die Geschäftskontinuität gewährleisten.
NAT-Abschaffung
Hier ist es unser Ziel, den Betrieb von Systemen in einem einzigen Adressraum für die weitere Integration von Infrastrukturdiensten (MS AD, DNS) und Anwendungen (Skype for Business, MBANK) sicherzustellen. Da einige der Anwendungssysteme bereits an den übersetzten Adressen miteinander verbunden sind, ist leider eine individuelle Arbeit mit jedem Anwendungssystem erforderlich, um NAT für bestimmte Interaktionen zu eliminieren.
Manchmal können Sie
sich für einen solchen Trick entscheiden : Stellen Sie denselben Server zur gleichen Zeit sowohl unter der übersetzten als auch unter der realen Adresse ein. So können Anwendungsadministratoren die Arbeit vor der Migration an einer realen Adresse testen, versuchen, selbst auf Nicht-NAT-Interaktion umzuschalten und bei Bedarf ein Rollback durchzuführen. Gleichzeitig überwachen wir die Firewall mithilfe der Paketerfassungsfunktion, um festzustellen, ob jemand über die übersetzte Adresse mit dem Server kommuniziert. Sobald eine solche Kommunikation unterbrochen wird, beenden wir im Einvernehmen mit dem Eigentümer der Ressource die Übertragung: Der Server hat nur eine echte Adresse.
Nach dem Parsen von NAT muss die Firewall leider einige Zeit zwischen funktionsidentischen Segmenten gewartet werden, da nicht alle Zonen denselben Sicherheitsstandards entsprechen. Nach der Standardisierung der Segmente wird die Firewall zwischen den Segmenten durch Routing ersetzt und funktional identische Sicherheitszonen werden zusammengeführt.
Firewall
Kommen wir zum Problem der Internetwork-Firewall. Grundsätzlich ist es für jede große Organisation relevant, in der es erforderlich ist, sowohl lokale als auch globale Fehlertoleranz für Schutzausrüstung bereitzustellen.
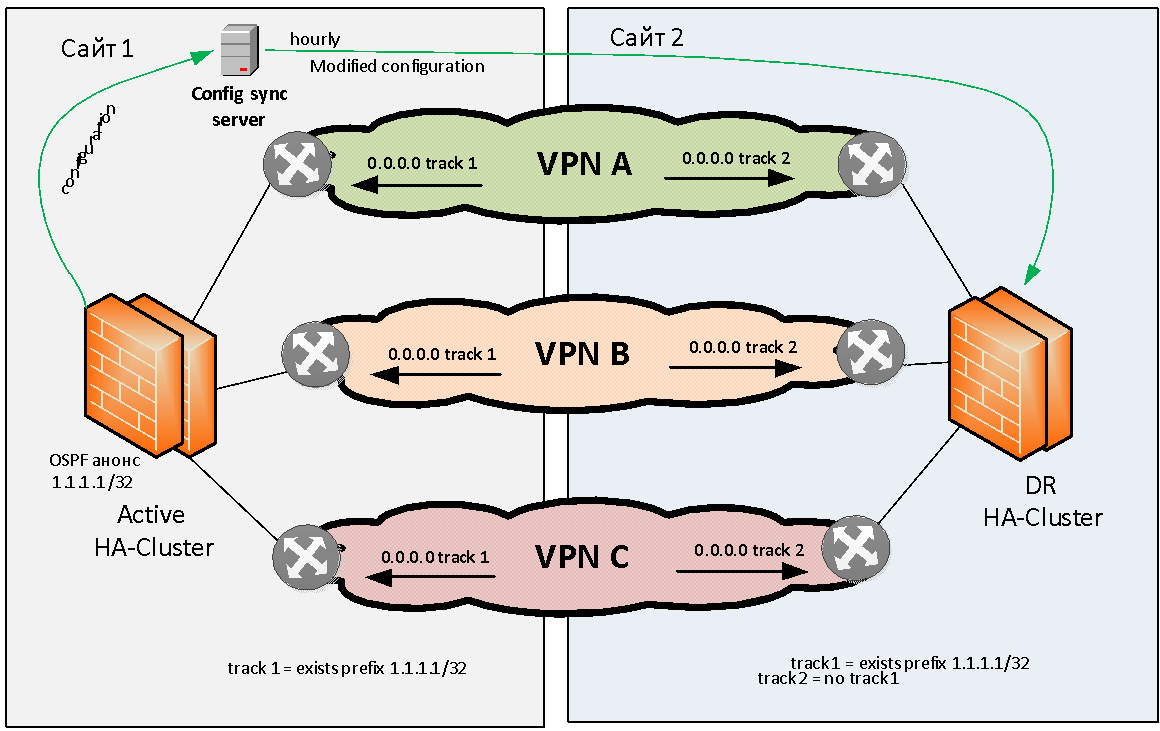
Versuchen wir, das Problem der Firewall-Reservierung im Allgemeinen zu formulieren. Wir haben zwei Standorte: Standort 1 und Standort 2. Es gibt mehrere (z. B. drei) MPLS-IP-VPNs, die über eine zustandsbehaftete Firewall miteinander kommunizieren. Diese Firewall muss lokal und geografisch reserviert werden.
Wir werden das Problem der lokalen Sicherung von Firewalls nicht berücksichtigen, da fast jeder Hersteller die Möglichkeit bietet, Firewalls zu einem lokalen HA-Cluster zusammenzusetzen. Bei der geografischen Reservierung von Firewalls hat praktisch kein Anbieter diese Aufgabe sofort erledigt.
, «» L2 , . - , split brain - L2- . - L2 .
, . .
Active/Standby, . , L3 VPN.
- . OSPF () /32. 1 (, 0.0.0.0 /0), . - ( ) MP BGP . , OSPF , , IP VPN.
, , , .
1 - , , 1 , 2 — . , , VPN' . , , , .
, active/standby. active-. , . , (, IP- ). . . .
L3 , . .
. , , — , , . L3-, .
, IP-. MPLS VPN. MPLS VPN «IN» VPN «OUT». VPN HUB-and-spoke VPN. Spoke HUB' VPN, .
«IN»
- Spoke VPN' VPN. «OUT»
Spoke VPN' .
MPLS VPN «IN». VPN . VPN HUB-VPN «IN» . . , Policy Based Routing. VPN «OUT», VPN «OUT» Spoke-VPN.
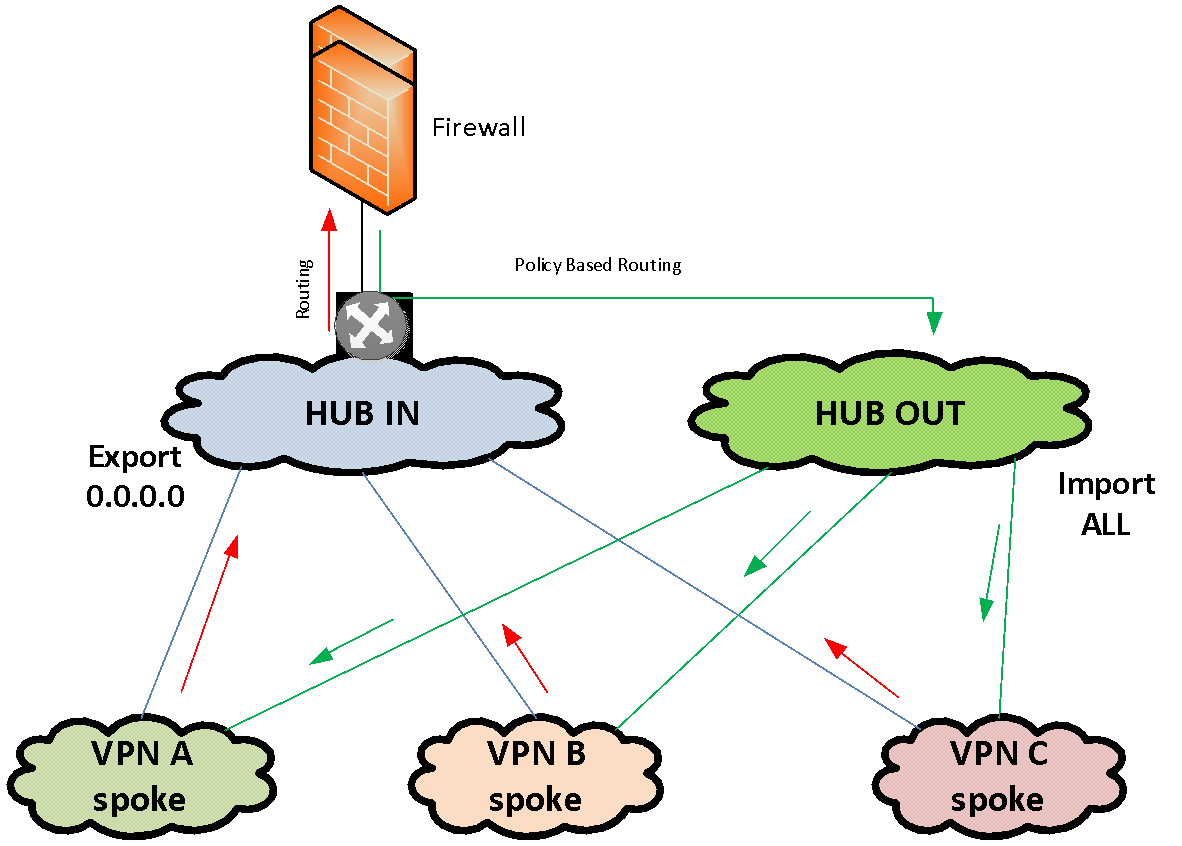
VPN, . MPLS import / export HUB VPN.
VPN , — , VLAN, ..
Fazit
, , . , , , . .