Das Erkennen von Angriffen ist seit Jahrzehnten eine wichtige Aufgabe in der Informationssicherheit. Die ersten bekannten Beispiele für die Implementierung von IDS stammen aus den frühen 1980er Jahren.
Nach mehreren Jahrzehnten bildete sich eine ganze Branche von Angriffserkennungswerkzeugen. Derzeit gibt es verschiedene Arten von Produkten wie IDS, IPS, WAF und Firewalls, von denen die meisten eine regelbasierte Angriffserkennung bieten. Die Idee, Anomalieerkennungstechniken zu verwenden, um Angriffe basierend auf Produktionsstatistiken zu erkennen, scheint nicht so realistisch wie in der Vergangenheit. Oder egal? ..
Anomalieerkennung in Webanwendungen
Die ersten Firewalls, die speziell zur Erkennung von Angriffen auf Webanwendungen entwickelt wurden, wurden Anfang der neunziger Jahre auf den Markt gebracht. Seitdem haben sich sowohl die Angriffsmethoden als auch die Abwehrmechanismen erheblich geändert, und Angreifer können jederzeit einen Schritt voraus sein.
Derzeit versuchen die meisten WAFs, Angriffe wie folgt zu erkennen: Es gibt einige regelbasierte Mechanismen, die in den Reverse-Proxy-Server integriert sind. Das auffälligste Beispiel ist mod_security, das WAF-Modul für den Apache-Webserver, das 2002 entwickelt wurde. Das Identifizieren von Angriffen anhand von Regeln hat mehrere Nachteile. Beispielsweise können die Regeln keine Zero-Day-Angriffe erkennen, während dieselben Angriffe von einem Experten leicht erkannt werden können. Dies ist nicht überraschend, da das menschliche Gehirn nicht wie eine Reihe regulärer Ausdrücke funktioniert.
Aus Sicht von WAF können Angriffe in solche unterteilt werden, die wir anhand der Reihenfolge der Anforderungen erkennen können, und solche, bei denen eine HTTP-Anforderung (Antwort) ausreicht, um sie zu lösen. Unsere Forschung konzentriert sich auf die Erkennung der letzteren Arten von Angriffen - SQL-Injection, Cross Site Scripting, Injection von externen XML-Entitäten, Pfadüberquerung, Betriebssystembefehle, Objektinjektion usw.
Aber zuerst testen wir uns.
Was wird der Experte denken, wenn er die folgenden Fragen sieht?
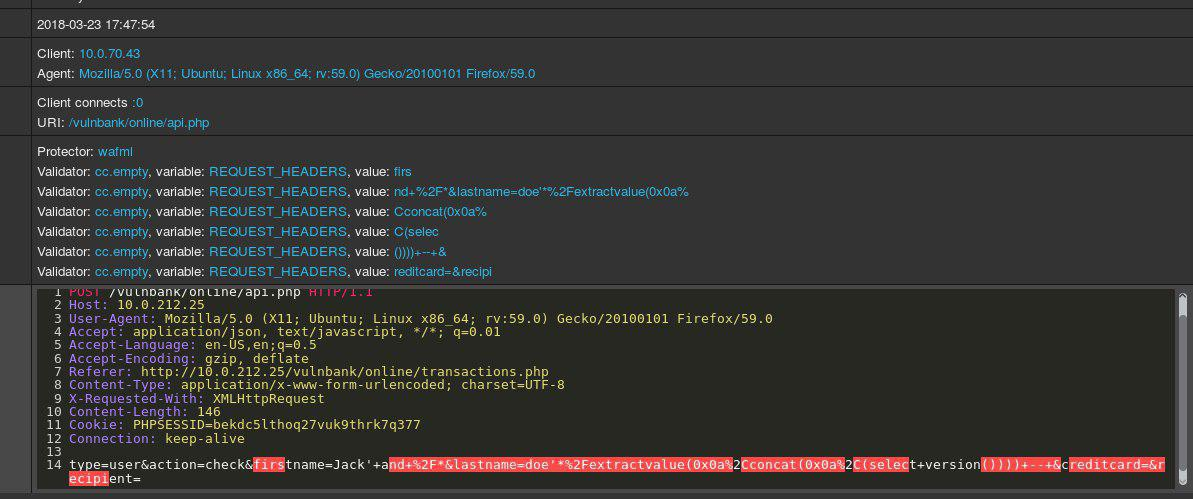
Sehen Sie sich eine Beispiel-HTTP-Anfrage an Anwendungen an:
Wenn Sie die Aufgabe erhalten haben, böswillige Anforderungen an eine Anwendung zu erkennen, möchten Sie höchstwahrscheinlich das übliche Benutzerverhalten für einige Zeit beobachten. Wenn Sie die Abfragen auf mehrere Endpunkte der Anwendung untersuchen, erhalten Sie einen allgemeinen Überblick über die Struktur und Funktionen ungefährlicher Abfragen.
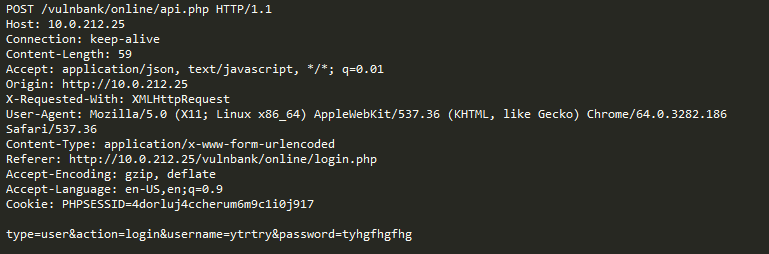
Jetzt erhalten Sie die folgende Abfrage zur Analyse:

Es ist sofort ersichtlich, dass hier etwas nicht stimmt. Es wird einige Zeit dauern, um zu verstehen, wie es hier wirklich ist, und sobald Sie den Teil der Anfrage identifiziert haben, der abnormal erscheint, können Sie darüber nachdenken, um welche Art von Angriff es sich handelt. Im Wesentlichen ist es unser Ziel, dass unsere „künstliche Intelligenz zur Erkennung von Angriffen“ auf die gleiche Weise funktioniert - ähnlich wie menschliches Denken.
Die offensichtliche Sache ist, dass ein Teil des Datenverkehrs, der auf den ersten Blick böswillig erscheint, für eine bestimmte Website normal sein kann.
Betrachten wir zum Beispiel die folgenden Abfragen:
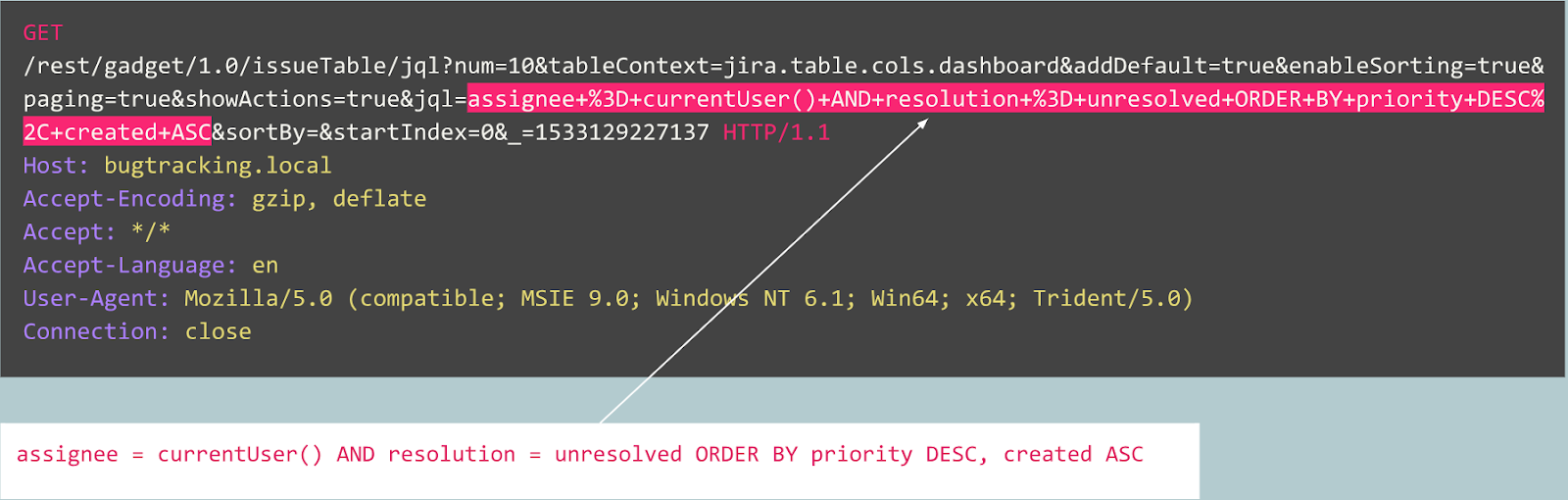
Ist diese Abfrage abnormal?
Tatsächlich handelt es sich bei dieser Anforderung um eine Veröffentlichung eines Fehlers im Jira-Tracker, der für diesen Dienst typisch ist. Dies bedeutet, dass die Anforderung erwartet und normal ist.
Betrachten Sie nun das folgende Beispiel:

Auf den ersten Blick sieht die Anfrage wie eine normale Benutzerregistrierung auf einer auf Joomla CMS basierenden Website aus. Die angeforderte Operation ist jedoch user.register anstelle der üblichen register.register. Die erste Option ist veraltet und enthält eine Sicherheitsanfälligkeit, mit der sich jeder als Administrator registrieren kann. Ein Exploit für diese Sicherheitsanfälligkeit wird als Joomla <3.6.4 Kontoerstellung / Eskalation von Berechtigungen (CVE-2016-8869, CVE-2016-8870) bezeichnet.

Wo haben wir angefangen?
Natürlich haben wir zuerst die vorhandenen Lösungen für das Problem untersucht. Seit Jahrzehnten werden verschiedene Versuche unternommen, Angriffserkennungsalgorithmen auf der Grundlage von Statistiken oder maschinellem Lernen zu erstellen. Einer der beliebtesten Ansätze ist die Lösung des Klassifizierungsproblems, wenn es sich bei Klassen um „erwartete Abfragen“, „SQL-Injektionen“, XSS, CSRF usw. handelt. Auf diese Weise können Sie mit dem Klassifizierer eine gute Genauigkeit für den Datensatz erzielen Dieser Ansatz löst jedoch aus unserer Sicht keine sehr wichtigen Probleme:
- Die Klassenauswahl ist begrenzt und vorbestimmt . Was ist, wenn Ihr Modell im Lernprozess durch drei Klassen dargestellt wird, z. B. "normale Abfragen", SQLi und XSS, und während des Systembetriebs auf eine CSRF oder einen Zero-Day-Angriff stößt?
- Die Bedeutung dieser Klassen . Angenommen, Sie müssen zehn Clients schützen, auf denen jeweils völlig unterschiedliche Webanwendungen ausgeführt werden. Für die meisten von ihnen haben Sie keine Ahnung, wie die SQL-Injection für ihre Anwendung tatsächlich aussieht. Dies bedeutet, dass Sie Trainingsdatensätze irgendwie künstlich erstellen müssen. Dieser Ansatz ist nicht optimal, da Sie letztendlich aus Daten lernen, die sich in der Verteilung von realen Daten unterscheiden.
- Interpretierbarkeit der Modellergebnisse . Nun, das Modell hat das SQL Injection-Ergebnis erzeugt, und was nun? Sie und, was noch wichtiger ist, Ihr Kunde, der als erster eine Warnung sieht und normalerweise kein Experte für Webangriffe ist, müssen raten, welchen Teil der Anfrage Ihr Modell als bösartig ansieht.
Angesichts all dieser Probleme haben wir uns entschlossen, das Klassifikatormodell trotzdem zu trainieren.
Da das HTTP-Protokoll ein Textprotokoll ist, war es offensichtlich, dass wir uns moderne Textklassifizierer ansehen mussten. Ein bekanntes Beispiel ist die Stimmungsanalyse in einem IMDB-Filmkritik-Datensatz. Einige Lösungen verwenden RNN, um Bewertungen zu klassifizieren. Wir haben uns entschlossen, ein ähnliches Modell mit RNN-Architektur mit einigen geringfügigen Unterschieden auszuprobieren. Beispielsweise verwendet die RNN-Architektur in natürlicher Sprache eine Vektordarstellung von Wörtern, es ist jedoch nicht klar, welche Wörter in einer unnatürlichen Sprache wie HTTP gefunden werden. Aus diesem Grund haben wir uns für die Vektordarstellung von Symbolen für unsere Aufgabe entschieden.
Vorgefertigte Darstellungen lösen unser Problem nicht. Daher haben wir einfache Zuordnungen von Zeichen zu numerischen Codes mit mehreren internen Markierungen wie
GO und
EOS .
Nachdem die Entwicklung und das Testen des Modells abgeschlossen waren, wurden alle zuvor vorhergesagten Probleme offensichtlich, aber zumindest unser Team wechselte von nutzlosen Annahmen zu einem Ergebnis.
Was weiter?
Als nächstes beschlossen wir, einige Schritte zur Interpretierbarkeit der Modellergebnisse zu unternehmen. Irgendwann stießen wir auf den Aufmerksamkeitsmechanismus „Aufmerksamkeit“ und begannen, ihn in unser Modell zu implementieren. Und es gab vielversprechende Ergebnisse. Jetzt zeigte unser Modell nicht nur Klassenbezeichnungen an, sondern auch Aufmerksamkeitsfaktoren für jedes Zeichen, das wir an das Modell weitergaben.
Jetzt konnten wir den genauen Ort, an dem der SQL-Injection-Angriff erkannt wurde, visualisieren und in der Weboberfläche anzeigen. Dies war ein gutes Ergebnis, aber andere Probleme aus der Liste waren noch ungelöst.
Es war offensichtlich, dass wir uns weiterhin darauf konzentrieren sollten, vom Aufmerksamkeitsmechanismus zu profitieren und uns von der Aufgabe der Klassifizierung zu entfernen. Nachdem wir eine große Anzahl verwandter Studien zu Sequenzmodellen (zu Aufmerksamkeitsmechanismen [2], [3], [4], zur Vektordarstellung, zur Architektur von Auto-Encodern) gelesen und mit unseren Daten experimentiert hatten, konnten wir ein Anomalie-Erkennungsmodell erstellen, das letztendlich würde mehr oder weniger so funktionieren wie ein Experte.
Auto Encoder
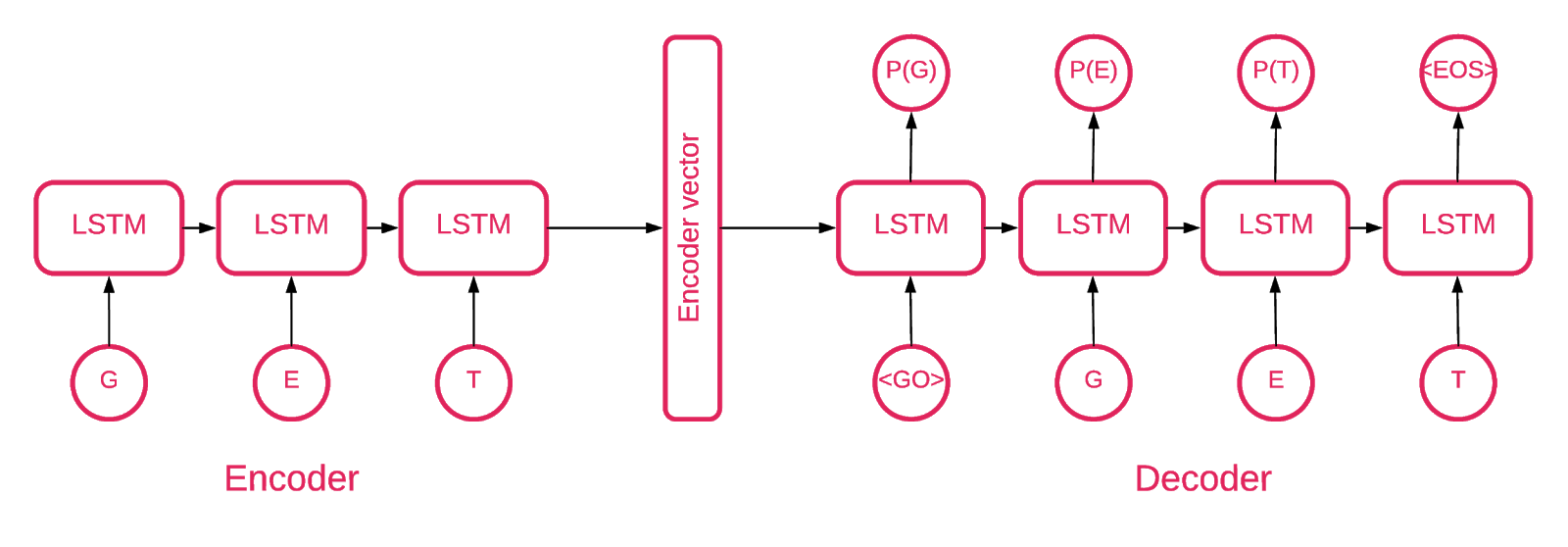
Irgendwann wurde klar, dass die Architektur von Seq2Seq [5] für unsere Aufgabe am besten geeignet ist.
Das Seq2Seq-Modell [7] besteht aus zwei mehrschichtigen LSTMs - einem Encoder und einem Decoder. Der Codierer ordnet die Eingabesequenz einem Vektor fester Länge zu. Der Decodierer decodiert den Zielvektor unter Verwendung des Codiererausgangs. Im Training ist ein Auto-Encoder ein Modell, bei dem die Zielwerte auf die gleichen Werte wie die Eingabewerte eingestellt werden.
Die Idee ist, dem Netzwerk beizubringen, die Dinge zu dekodieren, die es gesehen hat, oder mit anderen Worten, die Identität näher zu bringen. Wenn einem trainierten Autoencoder ein abnormales Muster zugewiesen wird, wird es wahrscheinlich mit einem hohen Fehlergrad neu erstellt, einfach weil es nie gesehen wurde.
Lösung
Unsere Lösung besteht aus mehreren Teilen: Modellinitialisierung, Schulung, Prognose und Verifizierung. Wir hoffen, dass der größte Teil des im Repository befindlichen Codes keiner Erklärung bedarf, sodass wir uns nur auf die wichtigen Teile konzentrieren werden.
Das Modell wird als Instanz der Seq2Seq-Klasse erstellt, die die folgenden Konstruktorargumente enthält:
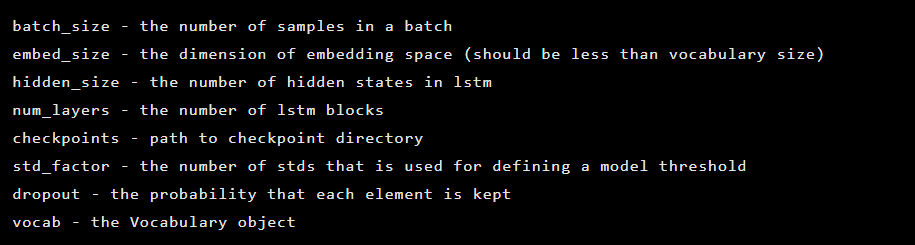
Als nächstes werden Auto-Encoder-Ebenen initialisiert. Erster Encoder:
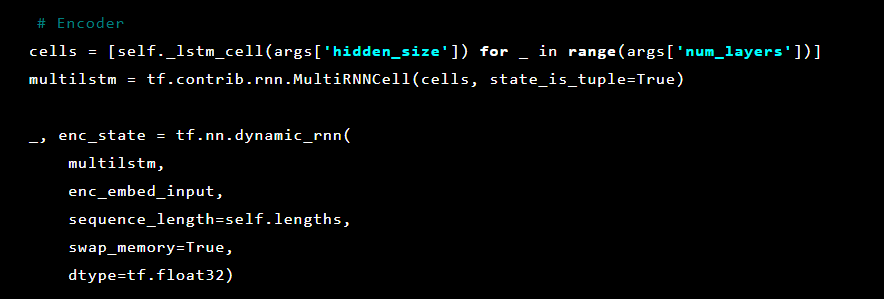
Dann der Decoder:
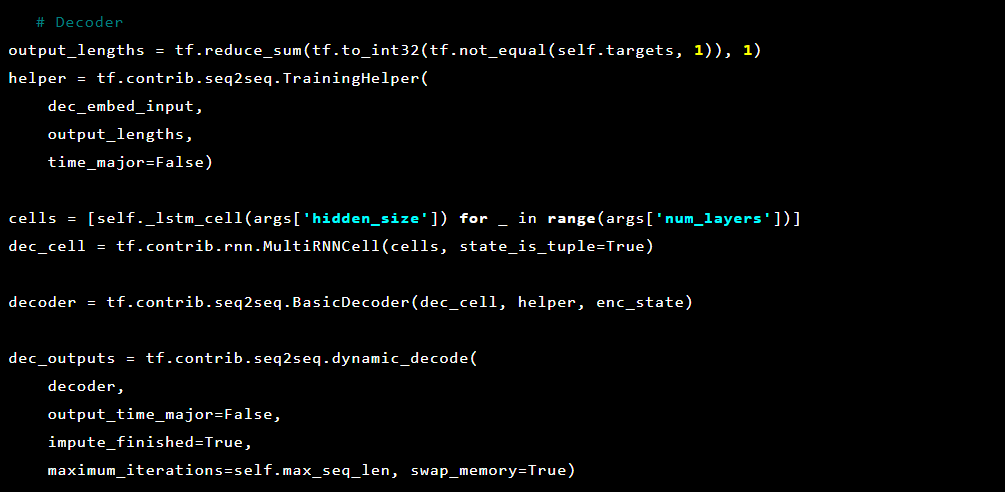
Da das Problem, das wir lösen, darin besteht, Anomalien zu erkennen, sind die Zielwerte und die Eingabe gleich. Unser feed_dict sieht also so aus:
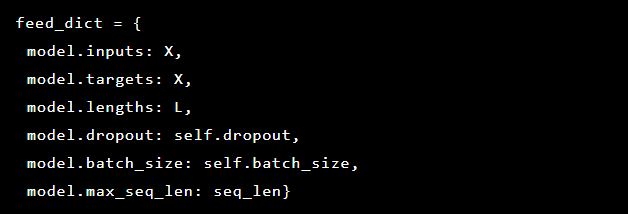
Nach jeder Ära wird das beste Modell als Referenzpunkt gespeichert, der dann heruntergeladen werden kann. Zu Testzwecken wurde eine Webanwendung erstellt, die wir mit einem Modell verteidigten, um zu überprüfen, ob echte Angriffe erfolgreich waren.
Inspiriert vom Aufmerksamkeitsmechanismus haben wir versucht, ihn auf das Auto-Encoder-Modell anzuwenden, um die abnormalen Teile dieser Abfrage zu markieren. Dabei haben wir jedoch festgestellt, dass die aus der letzten Schicht abgeleiteten Wahrscheinlichkeiten besser funktionieren.

In der Testphase unserer verzögerten Probe haben wir sehr gute Ergebnisse erzielt: Präzision und Rückruf liegen nahe bei 0,99. Und die ROC-Kurve tendiert zu 1. Es sieht toll aus, nicht wahr?
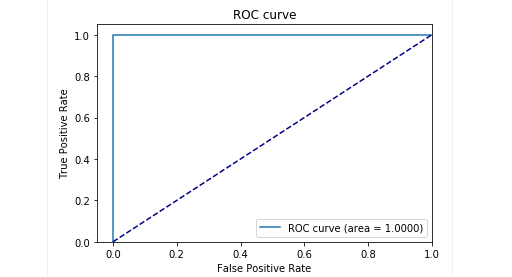
Ergebnisse
Das vorgeschlagene Modell des Seq2Seq-Auto-Encoders konnte Anomalien in HTTP-Anforderungen mit sehr hoher Genauigkeit erkennen.
Dieses Modell verhält sich wie eine Person: Es untersucht nur die „normalen“ Benutzeranforderungen für eine Webanwendung. Und wenn es Anomalien in Anforderungen erkennt, wählt es den genauen Ort der Anforderung aus, den es als anomal betrachtet.
Wir haben dieses Modell bei einigen Angriffen auf eine Testanwendung getestet und die Ergebnisse waren vielversprechend. Das obige Bild zeigt beispielsweise, wie unser Modell eine SQL-Injektion erkannt hat, die in einem Webformular in zwei Parameter unterteilt ist. Solche SQL-Injections werden als fragmentiert bezeichnet: Teile der Angriffsnutzlast werden in mehreren HTTP-Parametern bereitgestellt, was die Erkennung für regelbasierte WAFs erschwert, da sie normalerweise jeden Parameter einzeln testen.
Der Modellcode sowie die Trainings- und Testdaten werden als Jupyter-Laptop veröffentlicht, damit jeder unsere Ergebnisse reproduzieren und Verbesserungen vorschlagen kann.
Abschließend
Wir glauben, dass unsere Aufgabe eher nicht trivial war. Wir möchten mit minimalem Aufwand (vor allem, um Fehler aufgrund der Komplexität der Lösung zu vermeiden) einen Weg finden, um Angriffe zu erkennen, die wie durch Zauberei gelernt haben, zu entscheiden, was gut und was schlecht ist. Zweitens wollte ich Probleme mit dem menschlichen Faktor vermeiden, wenn genau ein Experte entscheidet, was ein Zeichen für einen Angriff ist und was nicht. Zusammenfassend möchte ich feststellen, dass der Auto-Encoder mit der Seq2Seq-Architektur für das Problem der Suche nach Anomalien unserer Meinung nach und für unser Problem hervorragende Arbeit geleistet hat.
Wir wollten das Problem auch mit der Interpretierbarkeit von Daten lösen. Die Verwendung komplexer neuronaler Netzwerkarchitekturen ist normalerweise sehr schwierig. In einer Reihe von Transformationen ist es bereits schwierig, am Ende zu sagen, welcher Teil der Daten die Entscheidung am meisten beeinflusst hat. Nachdem wir den Ansatz zur Dateninterpretation durch das Modell überdacht hatten, stellte sich heraus, dass es für uns ausreichend war, die Wahrscheinlichkeiten für jedes Symbol aus der letzten Schicht zu erhalten.
Es ist zu beachten, dass dies keine Produktionsversion ist. Wir können die Details der Implementierung dieses Ansatzes in einem realen Produkt nicht offenlegen, und wir möchten warnen, dass das einfache Nehmen und Einbetten dieser Lösung in ein Produkt nicht funktioniert.
GitHub-Repository:
goo.gl/aNwq9UAutoren : Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sacharow (
GitHub ), Arseniy
Reutov (
Raz0r )
Referenzen:
- Grundlegendes zu LSTM-Netzwerken
- Aufmerksamkeit und erweiterte wiederkehrende neuronale Netze
- Aufmerksamkeit ist alles was Sie brauchen
- Aufmerksamkeit ist alles was Sie brauchen (kommentiert)
- Tutorial für neuronale maschinelle Übersetzung (seq2seq)
- Autoencoder
- Sequenz-zu-Sequenz-Lernen mit neuronalen Netzen
- Erstellen von Autoencodern in Keras