In letzter Zeit ist Jupyter Notebook unter Data Science-Experten sehr beliebt geworden und zum De-facto-Standard für Rapid Prototyping und Datenanalyse geworden. Bei Netflix versuchen wir, die Grenzen seiner Funktionen noch weiter zu erweitern, indem wir überdenken, was Notebook sein kann, wer verwendet werden kann und was sie damit tun können. Wir haben uns sehr bemüht, unsere Vision in die Realität umzusetzen.
In diesem Artikel möchten wir Ihnen erklären, warum wir Jupyter Notebooks für so attraktiv halten und uns auf diesem Weg inspirieren. Darüber hinaus beschreiben wir die Komponenten unserer Infrastruktur und prüfen neue Möglichkeiten zur Verwendung von Jupyter Notebook in Netflix.

Anmerkung des Übersetzers: Vorsicht, viel Text und wenige Bilder
Wenn Sie nicht viel Zeit haben, empfehlen wir Ihnen, sofort zum Abschnitt " Anwendungsfälle" zu wechseln .
Warum das alles?
Daten sind die Stärke von Netflix. Sie durchdringen unsere Gedanken, beeinflussen unsere Entscheidungen und stellen unsere Hypothesen in Frage. Sie laden Experimente und die Entstehung eines neuen in beispiellosem Ausmaß auf . Die Daten ermöglichen es uns, unerwartete Bedeutungen zu entdecken und eine unglaubliche personalisierte Erfahrung für 130 Millionen unserer Benutzer auf der ganzen Welt zu erleben .
All dies zu verwirklichen, ist eine beachtliche Leistung, die beeindruckende technische und infrastrukturelle Unterstützung erfordert. Täglich werden mehr als 1 Billion Ereignisse in einem Stream (Streaming Ingestion Pipeline) empfangen, der in einem 100PB-Cloud-Speicher verarbeitet und aufgezeichnet wird. Täglich führen unsere Benutzer mehr als 150.000 Aufgaben mit diesen Daten aus, von Berichten über maschinelles Lernen bis hin zu Empfehlungsalgorithmen.
Um solche Nutzungsszenarien in einem solchen Maßstab zu unterstützen, haben wir eine der branchenweit besten entwickelt, eine flexible, leistungsstarke und bei Bedarf hochentwickelte Datenplattform (Netflix Data Platform). Wir haben auch zusätzliche Tools und Services entwickelt, wie Genie (Task Execution Service) und Metacat (Meta-Storage). Diese Tools reduzieren die Komplexität und ermöglichen so die Unterstützung einer größeren Anzahl von Benutzern im gesamten Unternehmen.

Die Vielfalt der Benutzer ist beeindruckend, aber Sie müssen dafür bezahlen: Die Netflix-Datenplattform und ihr Ökosystem aus Tools und Diensten müssen skaliert werden, um zusätzliche Nutzungsszenarien, Sprachen, Zugriffsschemata und vieles mehr zu unterstützen. Zum besseren Verständnis des Problems betrachten wir drei gängige Positionen: einen Analysteningenieur, einen Dateningenieur und einen Datenwissenschaftler.
 Der Unterschied in der Präferenz von Sprachen und Werkzeugen für verschiedene Positionen
Der Unterschied in der Präferenz von Sprachen und Werkzeugen für verschiedene PositionenIn der Regel bevorzugt jede Position ihre eigenen Tools und Sprachen. Ein Dateningenieur kann beispielsweise mit Scala in IntelliJ ein neues Datenensemble erstellen, das Billionen von Ereignisströmen enthält. Der Analyst kann sie mit SQL und Tableau in einem neuen globalen Bericht zur Streaming-Qualität verwenden. Dieser Bericht kann an einen Datenwissenschaftler gehen, der ein neues Streaming-Komprimierungsmodell mit R und RStudio erstellt. Auf den ersten Blick scheinen diese Prozesse fragmentiert zu sein, wenn auch komplementär. Wenn Sie jedoch genauer hinschauen, hat jeder dieser Prozesse mehrere überlappende Aufgaben:
Datenexploration - erfolgt in einem frühen Stadium des Projekts; kann eine Übersicht über Probendaten, Abfragen zur statistischen Analyse und Datenvisualisierung enthalten
Datenaufbereitung - Eine sich wiederholende Aufgabe kann das Bereinigen, Standardisieren, Transformieren, Denormalisieren und Aggregieren von Daten umfassen. normalerweise der zeitaufwändigste Teil des Projekts
Datenvalidierung - eine regelmäßig auftretende Aufgabe; kann eine Erhebung von Stichprobendaten, statistische Analyse, aggregierte Analyse und Datenvisualisierung umfassen; tritt normalerweise im Rahmen der Datenexploration, Datenaufbereitung, -entwicklung, Vorbereitstellung und Nachbereitstellung auf
Produktionalisierung - erfolgt zu einem späten Zeitpunkt des Projekts; Dies kann die Codebereitstellung, das Hinzufügen von Beispielen, das Modelltraining, die Datenvalidierung und das Planen von Workflows umfassen
Um die Fähigkeiten unserer Benutzer zu erweitern, möchten wir diese Aufgaben so einfach wie möglich gestalten.
Um die Funktionen unserer Plattform zu erweitern, möchten wir die Anzahl der Tools minimieren, die unterstützt werden müssen. Aber wie? Kein einzelnes Tool kann alle diese Aufgaben abdecken. Darüber hinaus erfordert eine Aufgabe häufig die Verwendung mehrerer Werkzeuge. Wenn wir uns jedoch deaktivieren, entsteht für alle Tools und Sprachen ein gemeinsames Muster: Code ausführen, Daten untersuchen, Ergebnis präsentieren.
So kam es, dass speziell dafür ein Open-Source-Projekt entwickelt wurde: Project Jupyter .
Jupyter-Notizbücher

Das Jupyter-Notizbuch in nteract zeigt Vega und Altair an
Das Jupyter-Projekt wurde 2014 mit dem Ziel gestartet, einen konsistenten Satz von Open-Source-Tools für Forschung, reproduzierbaren Workflow und Datenanalyse zu erstellen. Diese Tools wurden von der Branche hoch gelobt und heute ist Jupyter ein wesentlicher Bestandteil des Toolkits eines jeden Datenwissenschaftlers. Um das Ausmaß seines Einflusses zu verstehen, stellen wir fest, dass Jupyter 2017 mit dem ACM Software Systems Award ausgezeichnet wurde - einer prestigeträchtigen Auszeichnung, die er mit Java, Unix und the_Web teilt.
Um zu verstehen, warum das Jupyter-Notebook für uns so attraktiv ist, betrachten Sie seine Hauptmerkmale:
- Messaging-Protokoll zum Analysieren und Ausführen von Code unabhängig von der Sprache
- Dateiformat mit der Fähigkeit zum Bearbeiten, Beschreiben, Anzeigen und Ausführen von Code, Ausgabe- und Abschriftennotizen
- Webinterface für interaktives Schreiben, Codeausführung und Visualisierung von Ergebnissen
Das Jupyter-Protokoll bietet eine standardisierte Messaging-API mit Kerneln, die als Rechenmodule fungieren, und stellt eine zusammensetzbare Architektur bereit, wodurch gemeinsam genutzt wird, wo der Code (UI) gespeichert ist und wo er ausgeführt wird (der Kernel). Durch die Trennung von Schnittstelle und Kern können Notebooks in mehreren Sprachen arbeiten und gleichzeitig die Flexibilität bei der Konfiguration der Laufzeit beibehalten. Wenn eine Sprache für eine Sprache vorhanden ist, die Nachrichten mithilfe des Jupyter-Protokolls austauschen kann, kann Notebook Code ausführen, indem Nachrichten an diesen Kernel gesendet und empfangen werden.
Zusätzlich zu allem wird all dies durch ein Dateiformat unterstützt, mit dem Sie sowohl den Code selbst als auch die Ergebnisse seiner Ausführung an einem Ort speichern können. Dies bedeutet, dass Sie die Ergebnisse der Ausführung später anzeigen können, ohne den Code selbst neu starten zu müssen. Notizbücher können auch eine detaillierte Beschreibung des Kontexts und dessen genaue Vorgänge speichern. Dies macht es zu einem idealen Format, um einen Geschäftskontext zu vermitteln, Annahmen festzulegen, Code zu kommentieren, Schlussfolgerungen zu beschreiben und vieles mehr.
Anwendungsfälle
Unter den vielen Szenarien sind die beliebtesten Anwendungsfälle: Datenzugriff, Notizbuchvorlagen und Planen von Notizbüchern.
Datenzugriff
Jupyter Notebook erschien ursprünglich auf Netflix, um Data Science-Workflows zu unterstützen. Als ihre Verwendung unter Data Science-Experten zunahm, sahen wir das Potenzial, die Fähigkeiten unserer Tools zu erweitern. Wir haben erkannt, dass wir die Vielseitigkeit und Architektur des Jupyter-Notebooks nutzen und seine Funktionen für den Datenaustausch erweitern können. Im dritten Quartal 2017 haben wir ernsthaft damit begonnen, Notebook zu einem Werkzeug für einen engen Kreis von Spezialisten zu einem erstklassigen Vertreter der Netflix-Datenplattform zu machen.
Aus Sicht unserer Benutzer bieten Notebooks eine komfortable Oberfläche für die interaktive Befehlsausführung, Ausgabeforschung und Datenvisualisierung - alles in einer Cloud-Entwicklungsumgebung. Wir unterstützen auch die Python-Bibliothek, die den Zugriff auf die Plattform-API kombiniert. Dies bedeutet, dass Benutzer über Notebook programmgesteuert auf praktisch die gesamte Netflix-Plattform zugreifen können. Dank dieser Kombination aus Flexibilität, Leistung und Benutzerfreundlichkeit verzeichnete das Unternehmen einen starken Anstieg seiner Nutzung durch alle Arten von Plattformbenutzern.
Heute ist Notebook das beliebteste Datentool in Netflix.
Notizbuchvorlagen
Als die Unterstützung für Jupyter-Notebooks innerhalb der Plattform erweitert wurde, haben wir begonnen, neue Funktionen einzuführen, um sie für neue Nutzungsszenarien zu verwenden. Von hier kamen parametrisierte Laptops. Parametrisierte Laptops stellen genau das dar, was ihr Name sagt: Ein Notizbuch, mit dem Sie Parameter im Code festlegen und zur Laufzeit Eingaben empfangen können. Dies bietet Benutzern einen guten Mechanismus, um Notebooks als wiederverwendbare Vorlagen zu definieren.
Unsere Benutzer haben viele Möglichkeiten gefunden, solche Muster zu verwenden. Wir listen einige der am häufigsten verwendeten auf:
- Data Scientist : Experimentieren Sie mit verschiedenen Koeffizienten und fassen Sie die Ergebnisse zusammen
- Data Engineer : Führen Sie im Rahmen des Bereitstellungsprozesses eine Sammlung von Datenqualitätsprüfungen durch.
- Datenanalyst : Teilen Sie vorbereitete Abfragen und Visualisierungen, damit Stakeholder die Daten genauer untersuchen können, als es Tableau zulässt
- Software Engineer : Senden Sie die Ergebnisse eines Skripts, um einen Absturz zu beheben
Planen von Notizbüchern (Scheduler)
Eine der ursprünglichen Möglichkeiten zur Verwendung von Notebook besteht darin, eine Zusammenführungsebene für die Planung von Workflows zu erstellen.
Da jeder Laptop auf einem beliebigen Kernel ausgeführt werden kann, können wir jede benutzerdefinierte Laufzeitumgebung unterstützen. Und da Notizbücher einen linearen Ausführungsfluss beschreiben, der in Zellen unterteilt ist, können wir den Fehler auf eine bestimmte Zelle beziehen. Auf diese Weise können Benutzer die Ausführung und Visualisierung in einer narrativeren Form beschreiben, die beim Start zu einem späteren Zeitpunkt genau erfasst werden kann.
Ein solches Paradigma ermöglicht es Ihnen, einen Laptop für interaktive Arbeiten zu verwenden und reibungslos zur Mehrfachausführung und Verwendung des Schedulers zu wechseln. Was sich für die Benutzer als sehr praktisch herausstellte. Viele Benutzer erstellen ganze Workflows nur in Notebooks, um sie dann in separate Dateien zu duplizieren und zum richtigen Zeitpunkt auszuführen. Indem wir Notebook als sequentielle Prozessbeschreibung behandeln, können wir sie einfach so planen, dass sie wie jeder andere Workflow ausgeführt werden.
Wir können die Ausführung anderer Arten von Arbeiten über Notizbücher planen. Wenn ein Spark- oder Presto-Job vom Scheduler ausgeführt wird, wird der Quellcode in das neu erstellte Notizbuch eingefügt und ausgeführt. Dieses Notizbuch wird zu einem Verlaufs-Repository, das Quellcode, Parameter, Konfigurationen, Ausführungsprotokolle, Fehlermeldungen usw. enthält. Bei der Fehlerbehebung bietet dies einen schnellen Ausgangspunkt für die Untersuchung, da alle relevanten Informationen enthalten sind und das Notebook für das interaktive Debuggen ausgeführt werden kann.
Notebook-Infrastruktur
Die Unterstützung der oben beschriebenen Szenarien auf der Netflix-Skala erfordert eine umfangreiche unterstützende Infrastruktur. Stellen Sie kurz einige Projekte vor, die in den folgenden Abschnitten behandelt werden:
nteract ist die neue Generation der reaktionsbasierten Benutzeroberfläche für Jupyter-Notebooks. Es bietet eine einfache, intuitive Benutzeroberfläche und verschiedene Verbesserungen für die klassische Jupyter-Benutzeroberfläche, z. B. Inline-Zellen-Symbolleisten, Drag & Drop-Zellen und einen integrierten Explorer.
Papermill- Bibliothek zur Parametrisierung, Ausführung und Analyse von Jupyter-Notebooks. Mit deren Hilfe Sie mehrere Notebooks mit verschiedenen Parametern verbreiten und gleichzeitig ausführen können. Mit Papermill können Sie auch Metriken für eine gesamte Notebook-Sammlung sammeln und zusammenfassen.
Commuter ist ein leichter, vertikal skalierbarer Dienst zum Anzeigen und Freigeben von Notebooks. Es bietet eine Jupyter-kompatible Version der API für Inhalte und erleichtert das Lesen lokal auf Amazon S3 gespeicherter Notebooks. Bietet auch einen Explorer zum Suchen und Freigeben von Dateien.
Titus ist eine Containerverwaltungsplattform, die einen skalierbaren und zuverlässigen Start von Containern und eine Cloud-native Integration in Amazon AWS bietet. Titus wurde bei Netflix entwickelt und wird im Kampf zur Unterstützung von Netflix-Streaming-, Empfehlungs- und Inhaltssystemen verwendet.
Eine detailliertere Beschreibung der Architektur finden Sie im Artikel Planen von Notebooks bei Netflix . Für den Zweck dieses Beitrags beschränken wir uns auf die drei grundlegenden Komponenten des Systems: Speicherung, Ausführung und Schnittstelle.
 Notebook-Infrastruktur auf Netflix
Notebook-Infrastruktur auf NetflixLagerung
Die Netflix-Datenplattform verwendet Amazon S3- und EFS-Cloud-Speicher, den Notebooks als virtuelle Dateisysteme behandeln. Dies bedeutet, dass jeder Benutzer über ein EFS-Ausgangsverzeichnis verfügt, das einen persönlichen Arbeitsbereich für Notebooks enthält. In diesem Bereich speichern wir alle vom Benutzer erstellten oder geladenen Notizbücher. Dies ist auch der Ort, an dem Lesen und Schreiben stattfinden, wenn der Benutzer den Laptop interaktiv startet. Wir verwenden die Kombination [Arbeitsbereich + Dateiname] für den Namespace, d. H. /efs/users/kylek/notebooks/MySparkJob.ipynb zum Anzeigen, Freigeben und im Ausführungsplaner. Eine solche Vereinbarung verhindert Kollisionen und erleichtert die Identifizierung sowohl des Benutzers als auch des Notebook-Standorts in EFS.
Über den Pfad zum Arbeitsbereich können Sie die Komplexität des Cloud-Speichers für den Benutzer ignorieren. Beispielsweise werden nur die Namen der Notebook-Dateien im Verzeichnis angezeigt, d. H. MySparkJob.ipynb. Dieselbe Datei ist über das Terminal verfügbar: ~ / notebooks / MySparkJob.ipynb.

Notebook-Speicher vs. Zugang
Wenn der Benutzer die Aufgabe zum Starten des Notizbuchs festlegt, kopiert der Scheduler das Notizbuch des Benutzers von EFS in das freigegebene Verzeichnis in S3. Das Notizbuch in S3 wird zur Quelle der Wahrheit für den Scheduler oder das Quellennotizbuch. Jedes Mal, wenn der Scheduler (Dispatcher) das Notizbuch startet, erstellt er ein neues Notizbuch aus der Quelle. Dieses neue Notizbuch startet tatsächlich und wird zu einem unveränderlichen Datensatz einer bestimmten Ausführung, der den ausführbaren Code, die Ausgabe und die Protokolle jeder Zelle enthält. Wir nennen es Ausgabe (Ausgabe) Notebook.
Co-Creation ist ein grundlegendes Merkmal von Netflix. Daher war es nicht überraschend, als Benutzer anfingen, URL-Links zu Notebooks auszutauschen. Mit der Zunahme dieser Praxis stehen wir vor dem Problem des versehentlichen Umschreibens, das durch den gleichzeitigen Zugriff mehrerer Benutzer auf dasselbe Notebook verursacht wird. Unsere Benutzer wollten eine Möglichkeit, ihr aktives Notizbuch im schreibgeschützten Modus freizugeben. Dies führte zur Schaffung von Commuter . Unter der Haube zeigt Commuter die Jupyter-API an, um / files und / api / content in einer Verzeichnisliste aufzulisten, den Inhalt von Dateien anzuzeigen und auf Dateimetadaten zuzugreifen. Dies bedeutet, dass Benutzer Notizbücher ohne Konsequenzen für Kampfaufgaben oder live laufende Notizbücher anzeigen können.
Berechnen
Das Verwalten von Computerressourcen ist einer der schwierigsten Teile der Arbeit mit Daten. Dies gilt insbesondere für Netflix, wo wir die hoch skalierbare Containerarchitektur in AWS verwenden. Alle Jobs auf der Datenplattform werden in Containern ausgeführt, einschließlich Abfragen, Pipelines und Notizbüchern. Natürlich wollten wir von dieser Komplexität so viel wie möglich abstrahieren.
Ein Container wird bereitgestellt, wenn der Benutzer den Notebook-Server startet. Wir bieten rationale Standardeinstellungen für Containerressourcen, die für ~ 87,3% der Ausführungsmuster funktionieren. Wenn dies nicht ausreicht, können Benutzer über eine einfache Oberfläche weitere Ressourcen anfordern.

Benutzer können so viel oder so wenig Rechenleistung + Speicher auswählen, wie sie benötigen
Wir bieten auch eine einheitliche Laufzeit mit einem fertigen Container-Image. Das Image verfügt über gemeinsam genutzte Bibliotheken und einen vordefinierten Satz von Standardkerneln. Nicht alles im Image ist statisch - unsere Kernel verwenden die neuesten Spark-Versionen und die neuesten Cluster-Konfigurationen für unsere Plattform. Dies reduziert die Unordnung und die Optimierungszeit für neue Laptops und hält uns im Allgemeinen in einer einzigen Laufzeitumgebung.
Unter der Haube verwalten wir Orchestrierung und Umgebungen mit Titus , unserem Docker-Containerverwaltungsdienst. Darüber hinaus erstellen wir einen Wrapper für diesen Service, der bestimmte Benutzerserverkonfigurationen und Images verwaltet. Das Bild enthält auch Benutzersicherheitsgruppen und -rollen sowie allgemeine Umgebungsvariablen zur Identifizierung in den enthaltenen Bibliotheken. Dies bedeutet, dass unsere Benutzer weniger Zeit für die Infrastruktur und mehr Zeit für Daten aufwenden können.
Schnittstelle
Zuvor haben wir unsere Vision beschrieben, dass Notebooks das effektivste und optimalste Werkzeug für die Arbeit mit Daten sein sollten. Dies ist jedoch eine interessante Herausforderung: Wie kann eine Benutzeroberfläche alle Benutzer unterstützen? Wir kennen die genaue Antwort nicht, haben aber einige Ideen.
Wir wissen, dass Einfachheit erforderlich ist. Es bedeutet eine intuitive Benutzeroberfläche mit minimalistischem Stil und erfordert eine durchdachte Benutzeroberfläche, die komplexe Aufgaben einfach macht. Diese Philosophie passt gut zu den Zielen von nteract , die im React-Frontend für Jupyter-Notebook geschrieben wurden. Es betont die Kompositionsfähigkeit als Grundprinzipien des Designs und macht es zu einem idealen Teil unserer Vision.
Die häufigste Beschwerde unserer Benutzer ist das Fehlen einer nativen Visualisierung für alle Sprachen, insbesondere für Nicht-Python-Sprachen. Der Daten-Explorer von Nteract ist ein gutes Beispiel dafür, wie komplexe Dinge vereinfacht werden können, indem eine sprachunabhängige Möglichkeit zum schnellen Durchsuchen von Daten bereitgestellt wird.
Sie können den Daten-Explorer in diesem Beispiel in MyBinder in Aktion betrachten. (Das Laden kann einige Minuten dauern.)

Visualisierung des World Happiness Report-Datasets mit dem Daten-Explorer von nteract
Wir führen auch eine integrierte Unterstützung für die Parametrisierung ein, die die Planung des Starts von Notebooks vereinfacht und wiederverwendbare Vorlagen erstellt.
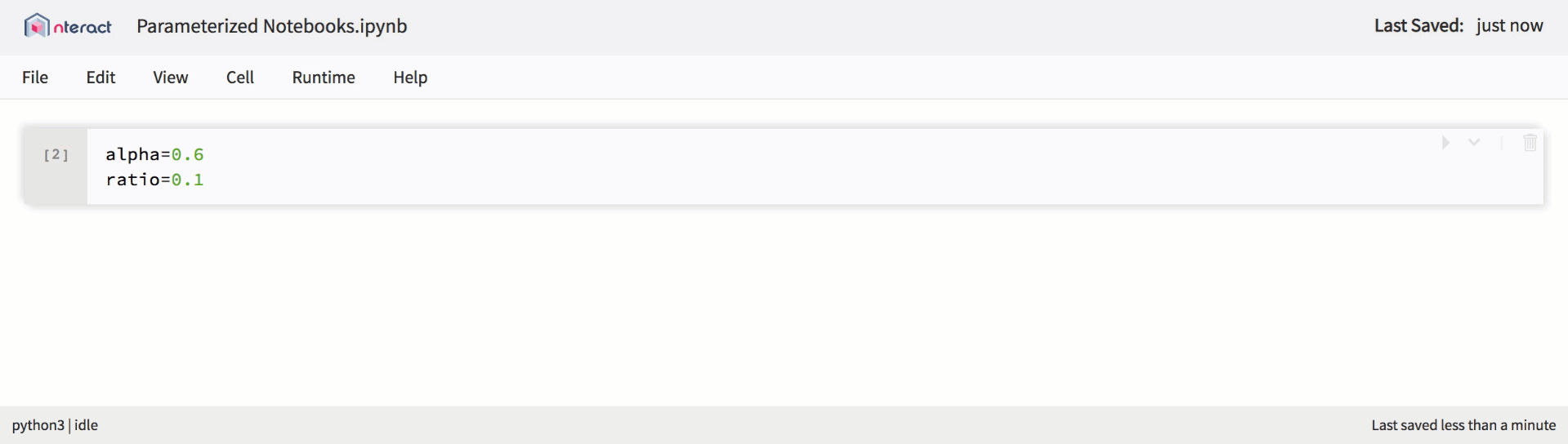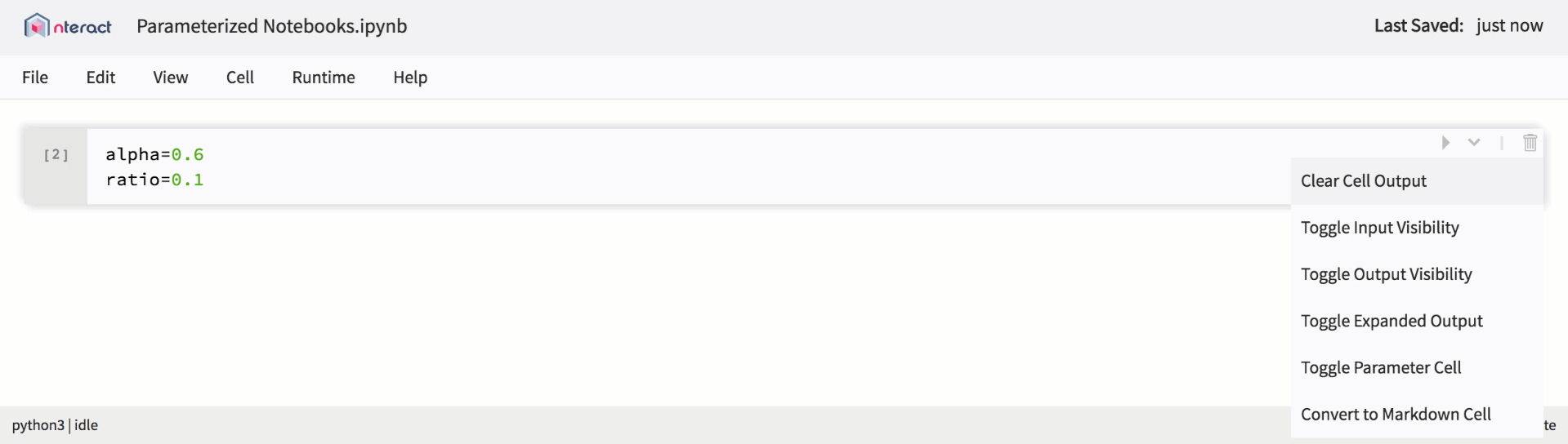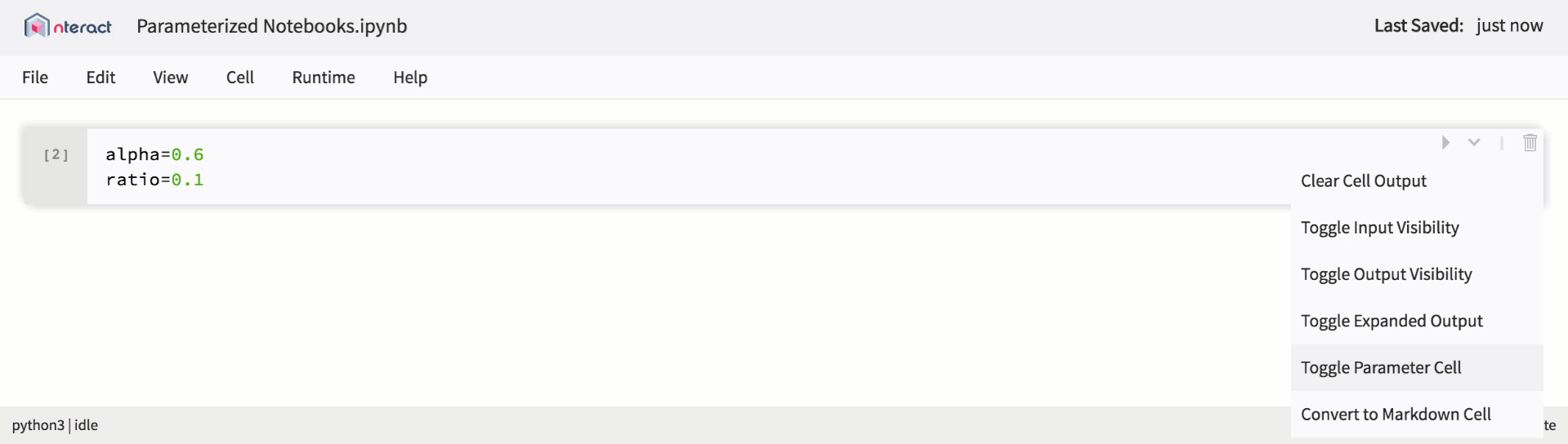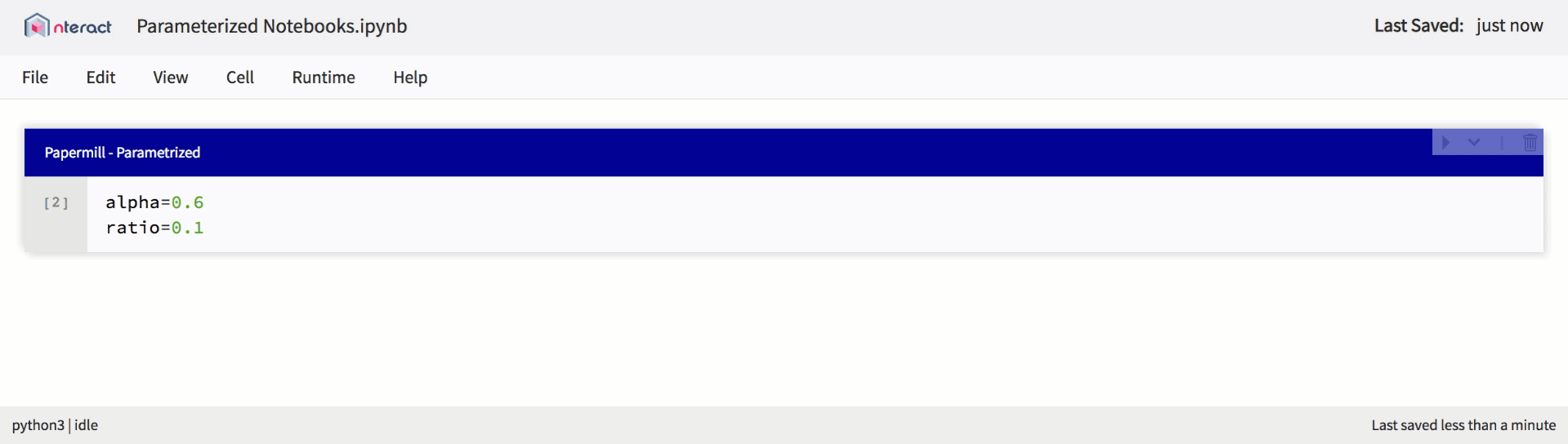
Native Unterstützung für parametrisierte Notebooks in nteract
Jupyter notebook , . , notebook. 12 , . , , , . , , Spark DataFrames, Scala. .
Open Source Projects
Netflix . , , . Netflix Data Platform Netflix OSS . “Not Invented Here”. Spark , Jupyter pandas .
, , Jupyter Project, . , nteract notebook UI Netflix. , . , Jupyter Notebook, , , . nteract.
, Netflix, . , , , , . , Papermill, .
What's Next ( )
, – (Netflixers) . Notebook Netflix. , . , .
! . , notebook. notebook Netflix, . :
I: Notebook Innovation ( )
II: Scheduling Notebooks
:
Scheduling workflows , — .