In jüngster Zeit wird zunehmend von statischen Analysen als einem der wichtigsten Mittel zur Sicherstellung der Qualität von Softwareprodukten gesprochen, die gerade unter Sicherheitsgesichtspunkten entwickelt werden. Mithilfe der statischen Analyse können Sie Schwachstellen und andere Fehler finden. Sie kann im Entwicklungsprozess verwendet und in benutzerdefinierte Prozesse integriert werden. Im Zusammenhang mit seiner Anwendung stellen sich jedoch viele Fragen. Was ist der Unterschied zwischen kostenpflichtigen und kostenlosen Tools? Warum reicht es nicht aus, den Linter zu verwenden? Was hat die Statistik am Ende damit zu tun? Versuchen wir es herauszufinden.

Beantworten wir gleich die letzte Frage - Statistiken haben nichts damit zu tun, obwohl statische Analysen oft fälschlicherweise als statistisch bezeichnet werden. Die Analyse ist statisch, da die Anwendung beim Scannen nicht gestartet wird.
Lassen Sie uns zunächst herausfinden, wonach wir im Programmcode suchen möchten. Statische Analysen werden am häufigsten verwendet, um nach Schwachstellen zu suchen - Codeabschnitten, deren Vorhandensein zu einer Verletzung der Vertraulichkeit, Integrität oder Verfügbarkeit des Informationssystems führen kann. Dieselben Technologien können jedoch verwendet werden, um nach anderen Fehlern oder Codefunktionen zu suchen.
Wir machen den Vorbehalt, dass das Problem der statischen Analyse im Allgemeinen algorithmisch unlösbar ist (zum Beispiel nach dem Rice-Theorem). Daher müssen Sie entweder die Bedingungen der Aufgabe einschränken oder Ungenauigkeiten in den Ergebnissen zulassen (Schwachstellen überspringen, Fehlalarme angeben). Es stellt sich heraus, dass bei echten Programmen die zweite Option funktioniert.
Es gibt viele kostenpflichtige und kostenlose Tools, die die Suche nach Sicherheitslücken in Anwendungen beanspruchen, die in verschiedenen Programmiersprachen geschrieben sind. Betrachten wir, wie der statische Analysator normalerweise angeordnet ist. Weiter werden wir uns auf den Analysatorkern und die Algorithmen konzentrieren. Natürlich können sich die Tools in der Benutzerfreundlichkeit der Benutzeroberfläche, im Funktionsumfang, im Plug-In-Satz für verschiedene Systeme und in der Benutzerfreundlichkeit der API unterscheiden. Dies ist wahrscheinlich ein Thema für einen separaten Artikel.
Zwischenpräsentation
Im Betriebsschema eines statischen Analysators können drei grundlegende Schritte unterschieden werden.
- Erstellen einer Zwischendarstellung (eine Zwischendarstellung wird auch als interne Darstellung oder Codemodell bezeichnet).
- Verwendung statischer Analysealgorithmen, durch die das Codemodell durch neue Informationen ergänzt wird.
- Anwenden von Regeln für die Suche nach Sicherheitslücken auf ein erweitertes Codemodell.
Verschiedene statische Analysatoren können unterschiedliche Codemodelle verwenden, z. B. den Programmquellcode, den Token-Stream, den Analysebaum, den Drei-Adressen-Code, das Kontrollflussdiagramm, den Bytecode (Standard oder native) usw.

Wie bei Compilern wird die lexikalische und syntaktische Analyse verwendet, um eine interne Darstellung zu erstellen, meistens einen Analysebaum (AST, Abstract Syntax Tree). Die lexikalische Analyse unterteilt den Programmtext in minimale semantische Elemente, wobei die Ausgabe einen Strom von Token empfängt. Durch das Parsen wird überprüft, ob der Token-Stream mit der Grammatik der Programmiersprache übereinstimmt, dh, der resultierende Token-Stream ist aus sprachlicher Sicht korrekt. Als Ergebnis der Analyse wird ein Analysebaum erstellt - eine Struktur, die den Quellcode des Programms modelliert. Als nächstes wird eine semantische Analyse angewendet, die die Erfüllung komplexerer Bedingungen überprüft, beispielsweise die Entsprechung von Datentypen in Zuweisungsanweisungen.
Der Analysebaum kann als interne Darstellung verwendet werden. Sie können auch andere Modelle aus dem Analysebaum abrufen. Sie können es beispielsweise in einen Code mit drei Adressen übersetzen, der wiederum ein Kontrollflussdiagramm (CFG) erstellt. In der Regel ist CFG das primäre Modell für statische Analysealgorithmen.

In der Binäranalyse (statische Analyse von binärem oder ausführbarem Code) wird ebenfalls ein Modell erstellt, aber hier werden bereits Reverse Engineering-Praktiken angewendet: Dekompilierung, Deobfuscation, Reverse Translation. Infolgedessen können Sie dieselben Modelle wie aus dem Quellcode erhalten, einschließlich des Quellcodes (unter vollständiger Dekompilierung). Manchmal kann der Binärcode selbst als Zwischendarstellung dienen.
Theoretisch ist die Qualität der Analyse umso schlechter, je näher das Modell am Quellcode liegt. Im Quellcode selbst können Sie nur nach regulären Ausdrücken suchen, wodurch Sie zumindest keine komplizierten Sicherheitslücken finden können.
Datenflussanalyse
Einer der wichtigsten statischen Analysealgorithmen ist die Datenflussanalyse. Die Aufgabe dieser Analyse besteht darin, an jedem Punkt im Programm einige Informationen über die Daten zu ermitteln, mit denen der Code arbeitet. Die Informationen können unterschiedlich sein, z. B. Datentyp oder Wert. Je nachdem, welche Informationen ermittelt werden müssen, kann die Aufgabe der Analyse des Datenflusses formuliert werden.

Wenn beispielsweise bestimmt werden muss, ob ein Ausdruck eine Konstante ist, sowie der Wert dieser Konstante, ist das Problem der Ausbreitung von Konstanten (konstante Ausbreitung) gelöst. Wenn es notwendig ist, den Typ einer Variablen zu bestimmen, können wir über das Problem der Typausbreitung sprechen. Wenn Sie verstehen müssen, welche Variablen auf einen bestimmten Speicherbereich verweisen können (dieselben Daten speichern), sprechen wir über die Aufgabe der Synonymanalyse (Alias-Analyse). Es gibt viele andere Aufgaben zur Datenflussanalyse, die in einem statischen Analysator verwendet werden können. Wie die Schritte zum Erstellen eines Codemodells werden diese Aufgaben auch in Compilern verwendet.
In der Theorie der Erstellung von Compilern werden Lösungen für das Problem der intraprozeduralen Analyse eines Datenstroms beschrieben (es ist erforderlich, Daten in einer einzigen Prozedur / Funktion / Methode zu verfolgen). Entscheidungen basieren auf der Theorie algebraischer Gitter und anderen Elementen mathematischer Theorien. Das Problem der Analyse des Datenflusses kann in Polynomzeit gelöst werden, dh für eine für Computer akzeptable Zeit, wenn die Bedingungen des Problems die Bedingungen des Lösbarkeitssatzes erfüllen, was in der Praxis nicht immer der Fall ist.
Wir werden Ihnen mehr über die Lösung des Problems der prozeduralen Analyse des Datenflusses erzählen. Um eine bestimmte Aufgabe festzulegen, müssen Sie zusätzlich zur Ermittlung der benötigten Informationen die Regeln für die Änderung dieser Informationen beim Übergeben von Daten gemäß den Anweisungen in CFG festlegen. Denken Sie daran, dass die Knoten in der CFG die Basisblöcke sind - Befehlssätze, deren Ausführung immer sequentiell ist, und die Bögen zeigen die mögliche Übertragung der Kontrolle zwischen den Basisblöcken an.
Für jede Anweisung
S. Mengen sind definiert:
- g e n ( S ) (Informationen, die durch die Anweisung generiert werden S. ),
- k i l l ( S ) (Informationen durch die Anweisung zerstört S. ),
- i n ( S ) (Informationen am Punkt vor der Anweisung S. ),
- o u t ( S ) (Informationen am Punkt nach der Anweisung S. )
Ziel der Datenflussanalyse ist es, Mengen zu definieren
i n ( S ) und
o u t ( S ) für jede Anweisung
S. Programme. Das grundlegende Gleichungssystem, mit dem die Aufgaben der Analyse des Datenflusses gelöst werden, wird durch die folgende Beziehung (Datenflussgleichungen) bestimmt:
o u t ( S ) = ( i n ( S ) - t ö t e n ( S ) ) ∪ g e n ( S ) ,
i n ( S ) = ∪ i o u t ( S i ) .
Die zweite Beziehung formuliert die Regeln, nach denen Informationen an den Konfluenzpunkten der CFG-Bögen „kombiniert“ werden (
S i - Vorgänger
S. in CFG). Die Operation von Vereinigung, Kreuzung und einigen anderen kann verwendet werden.
Die gewünschte Information (der Wertesatz der oben eingeführten Funktionen) wird als algebraisches Gitter formalisiert. Funktionen
g e n und
k i l l werden als monotone Abbildungen auf Gittern (Strömungsfunktionen) betrachtet. Für Datenflussgleichungen ist die Lösung der feste Punkt dieser Abbildungen.
Algorithmen zur Lösung von Datenflussanalyseproblemen suchen nach maximalen Fixpunkten. Es gibt verschiedene Lösungsansätze: iterative Algorithmen, Analyse stark verbundener Komponenten, T1-T2-Analyse, Intervallanalyse, Strukturanalyse usw. Es gibt Theoreme zur Korrektheit dieser Algorithmen, die den Umfang ihrer Anwendbarkeit auf reale Probleme bestimmen. Ich wiederhole, die Bedingungen der Theoreme sind möglicherweise nicht erfüllt, was zu komplizierteren Algorithmen und ungenauen Ergebnissen führt.
Interprocedurale Analyse
In der Praxis ist es notwendig, die Probleme der interprozeduralen Analyse des Datenflusses zu lösen, da die Sicherheitsanfälligkeit selten vollständig in einer Funktion lokalisiert wird. Es gibt mehrere gängige Algorithmen.
Inline-Funktionen . Am Funktionsaufrufpunkt binden wir die aufgerufene Funktion ein, wodurch die Aufgabe der interprozeduralen Analyse auf die Aufgabe der intraprozeduralen Analyse reduziert wird. Diese Methode ist leicht zu implementieren, aber in der Praxis wird bei Anwendung schnell eine kombinatorische Explosion erreicht.
Erstellen eines allgemeinen Diagramms des Programmsteuerungsablaufs, in dem Funktionsaufrufe durch Übergänge zur Startadresse der aufgerufenen Funktion ersetzt werden und Rückgabeanweisungen durch Übergänge zu allen Anweisungen ersetzt werden, die allen Anweisungen zum Aufrufen dieser Funktion folgen. Dieser Ansatz fügt eine große Anzahl nicht realisierbarer Ausführungspfade hinzu, was die Genauigkeit der Analyse erheblich verringert.
Ein Algorithmus ähnlich dem vorherigen, aber beim Umschalten auf eine Funktion wird
der Kontext gespeichert - beispielsweise ein Stapelrahmen. Damit ist das Problem der Erstellung nicht realisierbarer Pfade gelöst. Der Algorithmus ist jedoch mit begrenzter Anruftiefe anwendbar.
Gebäudefunktionsinformationen (Funktionsübersicht). Der am besten geeignete Algorithmus für die interprozedurale Analyse. Es basiert auf der Erstellung einer Zusammenfassung für jede Funktion: Die Regeln, nach denen Informationen über Daten bei Anwendung dieser Funktion konvertiert werden, hängen von den verschiedenen Werten der Eingabeargumente ab. Bei der internen prozeduralen Analyse von Funktionen werden vorgefertigte Zusammenfassungen verwendet. Eine separate Schwierigkeit ist hier die Bestimmung der Reihenfolge der Funktionsdurchquerung, da in der Einzelfallanalyse bereits eine Zusammenfassung für alle aufgerufenen Funktionen erstellt werden sollte. In der Regel werden spezielle iterative Algorithmen zum Durchlaufen eines Anrufdiagramms erstellt.
Die interprozedurale Datenflussanalyse ist eine exponentiell schwierige Aufgabe, weshalb der Analysator eine Reihe von Optimierungen und Annahmen durchführen muss (es ist unmöglich, die genaue Lösung in angemessener Zeit für die Rechenleistung zu finden). In der Regel muss bei der Entwicklung eines Analysegeräts ein Kompromiss zwischen der Menge der verbrauchten Ressourcen, der Analysezeit, der Anzahl der gefundenen Fehlalarme und den gefundenen Schwachstellen gefunden werden. Daher kann ein statischer Analysator lange arbeiten, viele Ressourcen verbrauchen und falsch positive Ergebnisse liefern. Ohne dies ist es jedoch unmöglich, die wichtigsten Schwachstellen zu finden.
An diesem Punkt unterscheiden sich ernsthafte statische Analysegeräte von vielen offenen Tools, die sich insbesondere bei der Suche nach Schwachstellen positionieren können. Schnelle Überprüfungen in linearer Zeit sind gut, wenn Sie das Ergebnis schnell erhalten möchten, z. B. während der Kompilierung. Dieser Ansatz kann jedoch nicht die kritischsten Schwachstellen finden - beispielsweise im Zusammenhang mit der Implementierung von Daten.
Verschmutzungsanalyse
Wir sollten uns auch mit einer der Aufgaben der Datenflussanalyse befassen - der Verschmutzungsanalyse. Mit der Verschmutzungsanalyse können Sie Flags im gesamten Programm verteilen. Diese Aufgabe ist der Schlüssel zur Informationssicherheit, da mit ihrer Hilfe Sicherheitslücken im Zusammenhang mit der Implementierung von Daten (SQL-Injection, Crossite-Scripting, offene Weiterleitungen, Fälschung des Dateipfads usw.) sowie dem Verlust vertraulicher Daten (Passworteingabe in) entdeckt werden Ereignisprotokolle, unsichere Datenübertragung).
Versuchen wir, eine Aufgabe zu simulieren. Angenommen, wir möchten n Flags verfolgen -
f 1 , f 2 , . . . , f n . Viele Informationen hier werden viele Teilmengen sein
\ {f_1, ..., f_n \} , da wir für jede Variable an jedem Punkt im Programm ihre Flags definieren möchten.
Als nächstes müssen wir die Flussfunktionen definieren. In diesem Fall können die Flussfunktionen durch die folgenden Überlegungen bestimmt werden.
- Es werden viele Regeln angegeben, in denen Konstruktionen definiert werden, die zum Auftreten oder Ändern einer Reihe von Flags führen.
- Die Zuweisungsoperation dreht die Flags von rechts nach links.
- Jede für Regelsätze unbekannte Operation kombiniert Flags aus allen Operanden, und der endgültige Satz von Flags wird zu den Operationsergebnissen hinzugefügt.
Schließlich müssen Sie die Regeln für das Zusammenführen von Informationen an den Verbindungspunkten von CFG-Bögen definieren. Das Zusammenführen wird durch die Vereinigungsregel bestimmt. Wenn also verschiedene Sätze von Flags für eine einzelne Variable aus verschiedenen Basisblöcken stammen, werden sie beim Zusammenführen zusammengeführt. Einschließlich falsch positiver Ergebnisse stammen von hier: Der Algorithmus garantiert nicht, dass der Pfad zu der CFG, auf der das Flag angezeigt wurde, ausgeführt werden kann.
Beispielsweise müssen Sie Schwachstellen wie SQL Injection erkennen. Diese Sicherheitsanfälligkeit tritt auf, wenn nicht überprüfte Daten des Benutzers in die Arbeitsmethoden für die Datenbank fallen. Es muss festgestellt werden, dass die Daten vom Benutzer stammen, und diesen Daten das Taint-Flag hinzugefügt werden. In der Regel legt die Regelbasis des Analysators die Regeln für das Setzen des Taint-Flags fest. Setzen Sie beispielsweise ein Flag auf den Rückgabewert der Methode getParameter () der Request-Klasse.
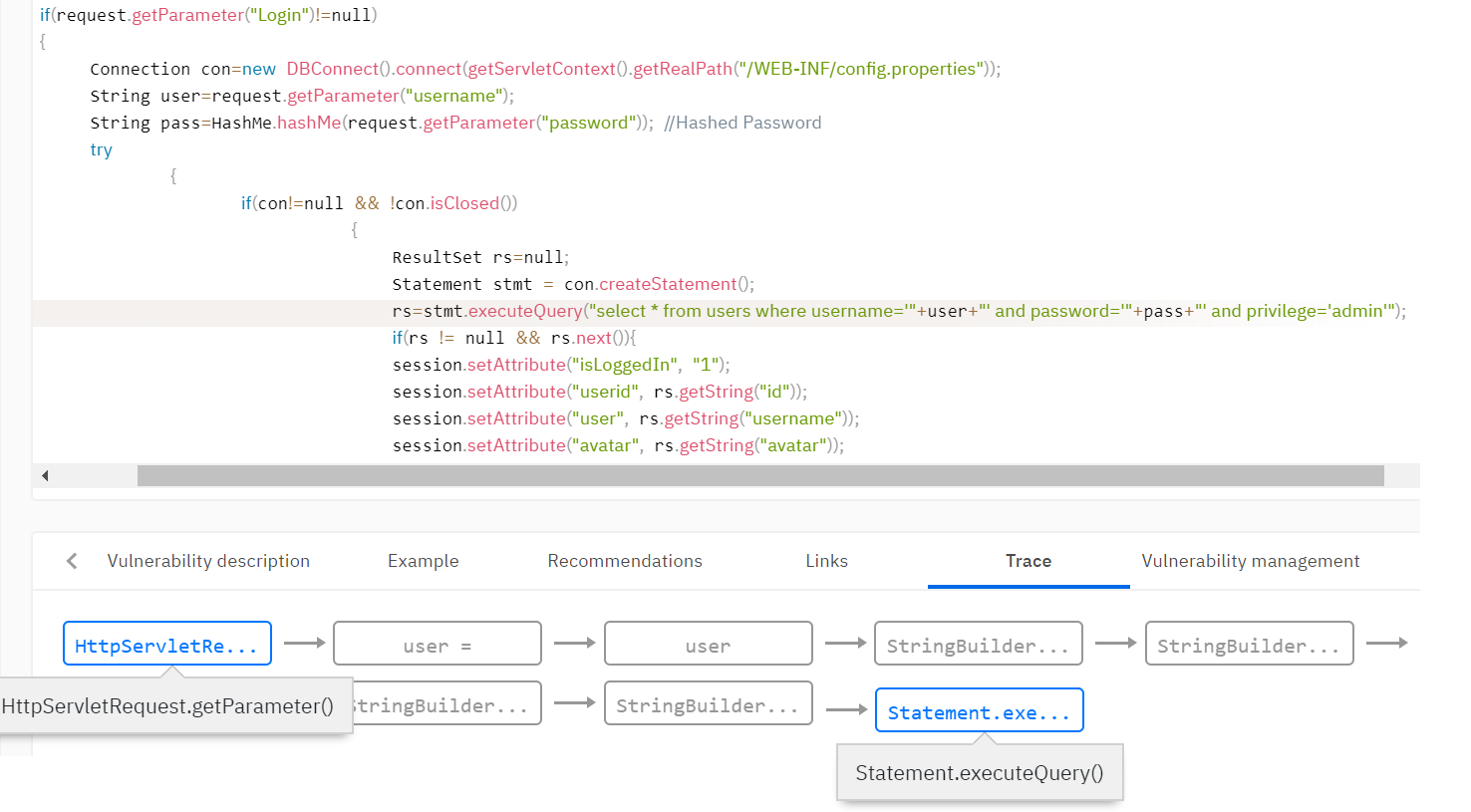
Als Nächstes müssen Sie das Flag mithilfe der Taint-Analyse im gesamten analysierten Programm verteilen, da die Daten validiert werden können und das Flag möglicherweise auf einem der Ausführungspfade verschwindet. Der Analysator setzt viele Funktionen, die Flags entfernen. Beispielsweise kann die Funktion zum Überprüfen von Daten aus HTML-Tags das Flag für XSS-Schwachstellen (Cross-Site Scripting) löschen. Oder die Funktion zum Binden einer Variablen an einen SQL-Ausdruck entfernt das Flag zum Einbetten in SQL.
Regeln für die Suche nach Sicherheitslücken
Durch die Anwendung der oben genannten Algorithmen wird die Zwischendarstellung durch die Informationen ergänzt, die zur Suche nach Schwachstellen erforderlich sind. Im Codemodell werden beispielsweise Informationen darüber angezeigt, welche Variablen zu bestimmten Flags gehören und welche Daten konstant sind. Sicherheitsregeln für Sicherheitslücken werden in Form eines Codemodells formuliert. Die Regeln beschreiben, welche Funktionen in der endgültigen Zwischenansicht auf eine Sicherheitsanfälligkeit hinweisen können.
Beispielsweise können Sie eine Schwachstellensuchregel anwenden, die einen Methodenaufruf mit einem Parameter definiert, der das Flag taint enthält. Zurück zum Beispiel der SQL-Injection stellen wir sicher, dass die Variablen mit dem Taint-Flag nicht in die Datenbankabfragefunktion fallen.
Es stellt sich heraus, dass ein wichtiger Teil des statischen Analysators neben der Qualität der Algorithmen die Konfiguration und die Regelbasis ist: Eine Beschreibung, welche Konstrukte im Code Flags oder andere Informationen erzeugen, welche Konstrukte solche Daten validieren und für welche Konstrukte die Verwendung solcher Daten entscheidend ist.
Andere Ansätze
Neben der Datenflussanalyse gibt es weitere Ansätze. Eine der bekanntesten ist die symbolische Ausführung oder abstrakte Interpretation. Bei diesen Ansätzen läuft das Programm auf abstrakten Domänen, der Berechnung und Verteilung von Datenbeschränkungen im Programm. Mit diesem Ansatz kann man nicht nur die Sicherheitsanfälligkeit finden, sondern auch die Bedingungen für die Eingabedaten berechnen, unter denen die Sicherheitsanfälligkeit ausgenutzt werden kann. Dieser Ansatz weist jedoch schwerwiegende Nachteile auf: Bei Standardlösungen für reale Programme explodieren Algorithmen exponentiell und Optimierungen führen zu schwerwiegenden Einbußen bei der Qualität der Analyse.
Schlussfolgerungen
Letztendlich denke ich, dass es sich lohnt, zusammenzufassen und über die Vor- und Nachteile der statischen Analyse zu sprechen. Es ist logisch, dass wir mit der dynamischen Analyse vergleichen, bei der die Schwachstellensuche während der Programmausführung erfolgt.

Der zweifelsfreie Vorteil der statischen Analyse ist die vollständige Abdeckung des analysierten Codes. Zu den Vorteilen der statischen Analyse gehört auch die Tatsache, dass die Anwendung nicht in einer Kampfumgebung ausgeführt werden muss, um sie auszuführen. Statische Analysen können in einem sehr frühen Entwicklungsstadium implementiert werden, wodurch die Kosten der gefundenen Schwachstellen minimiert werden.
Die Nachteile der statischen Analyse sind das unvermeidliche Vorhandensein von Fehlalarmen, der Ressourcenverbrauch und eine lange Scanzeit bei großen Codemengen. Diese Nachteile sind jedoch aufgrund der Besonderheiten der Algorithmen unvermeidlich. Wie wir gesehen haben, wird ein schneller Analysator niemals eine echte Sicherheitslücke wie SQL-Injection und dergleichen finden.
Wir haben in
einem anderen Artikel über die verbleibenden Schwierigkeiten bei der Verwendung statischer Analysewerkzeuge geschrieben, die, wie sich herausstellt, recht gut überwunden werden können.