EvE online ist ein lustiges Spiel. Dies ist eines der wenigen MMOs, in denen es nur einen „Server“ für den Eintrag gibt, was bedeutet, dass jeder in derselben logischen Welt spielt. Sie hatte auch eine aufregende Reihe von Ereignissen, die innerhalb des Spiels passiert sind, und sie bleibt auch ein sehr optisch ansprechendes Spiel:
Es gibt auch eine umfangreiche Weltkarte, auf die alle diese Spieler passen können. Auf dem Höhepunkt hatte EvE 63.000 Online-Spieler in einer Welt mit 500.000 registrierten bezahlten Abonnements auf dem Höhepunkt der Popularität, und obwohl diese Zahl jedes Jahr kleiner wird, bleibt die Welt unglaublich groß. Dies bedeutet, dass der Übergang von einer Seite zur anderen eine erhebliche Zeitspanne ist (sowie ein Risiko aufgrund der Abhängigkeit des Spielers von der Fraktion).
Die Übersetzung wurde von EDISON Software , einem professionellen Sicherheitsunternehmen , unterstützt und entwickelt auch elektronische medizinische Verifizierungssysteme .Sie reisen im Warp-Modus (innerhalb desselben Systems) in verschiedene Gebiete oder springen mit Hopping Gates zu verschiedenen Systemen:

Und all diese Systeme bilden zusammen eine Karte von Schönheit und Komplexität:

Ich habe diese Karte immer als Netzwerk betrachtet. Es handelt sich um ein großes Netzwerk von Systemen, die miteinander verbunden sind, damit die Benutzer sie durchlaufen können, und die meisten Systeme verfügen über mehr als zwei Sprungtore. Ich habe darüber nachgedacht, was passieren würde, wenn Sie die Idee einer Karte buchstäblich als Netzwerk betrachten würden. Wie wird das EvE-Internet-System aussehen?
Dazu müssen wir verstehen, wie das echte Internet funktioniert. Das Internet ist eine große Sammlung von Internetanbietern, die alle numerisch anhand einer standardisierten und eindeutigen Internetanbieternummer identifiziert werden, die als Autonomous System Number oder ASN (oder AS für die kürzere Version) bezeichnet wird. Diese AS benötigen eine Möglichkeit, Routen miteinander auszutauschen, da sie IP-Adressbereiche besitzen, und sie müssen anderen Internetanbietern mitteilen, dass ihre Router diese IP-Adressen weiterleiten können. Zu diesem Zweck stoppte die Welt mit dem Boundary Gateway Protocol oder BGP.
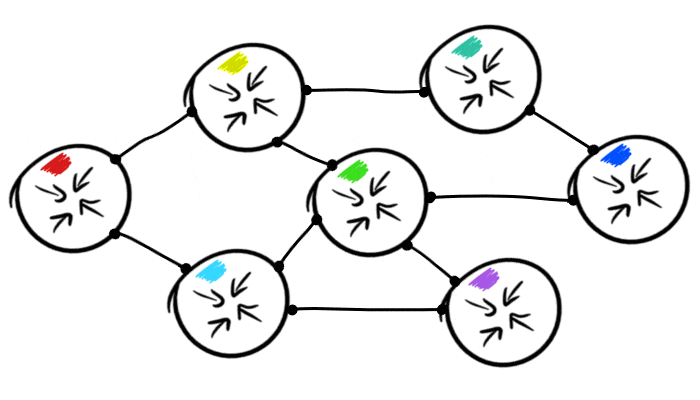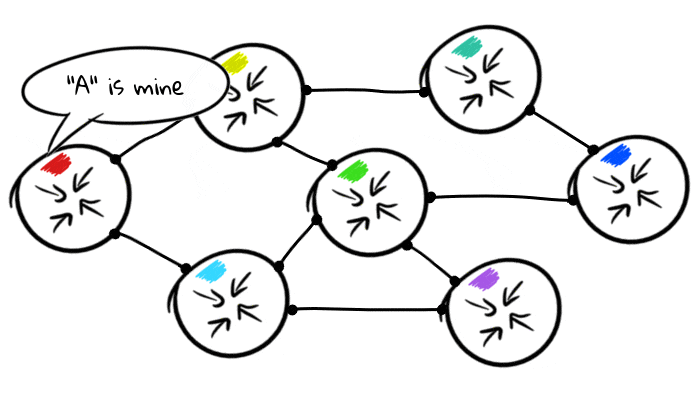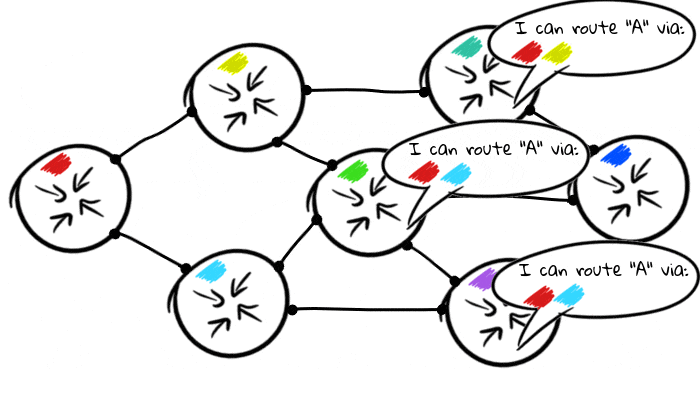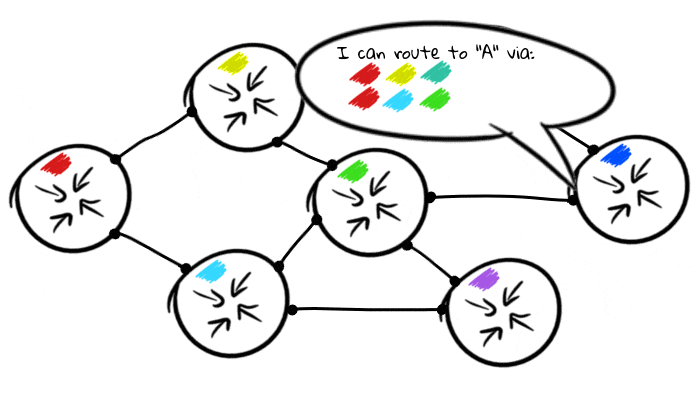
BGP teilt anderen AS (als Host bezeichnet) ihre Routen mit:

Das Standardverhalten von BGP beim Empfang einer Route von einem Host besteht darin, diese an alle anderen Hosts weiterzuleiten, mit denen sie ebenfalls verbunden ist. Dies bedeutet, dass Knoten ihre Routing-Tabellen automatisch miteinander teilen.
Dieses Verhalten ist jedoch nur nützlich, wenn Sie BGP zum Senden von Routen an interne Router verwenden, da das moderne Internet unterschiedliche logische Beziehungen zueinander hat. Anstelle des Netzwerks sieht das moderne Internet ungefähr so aus:
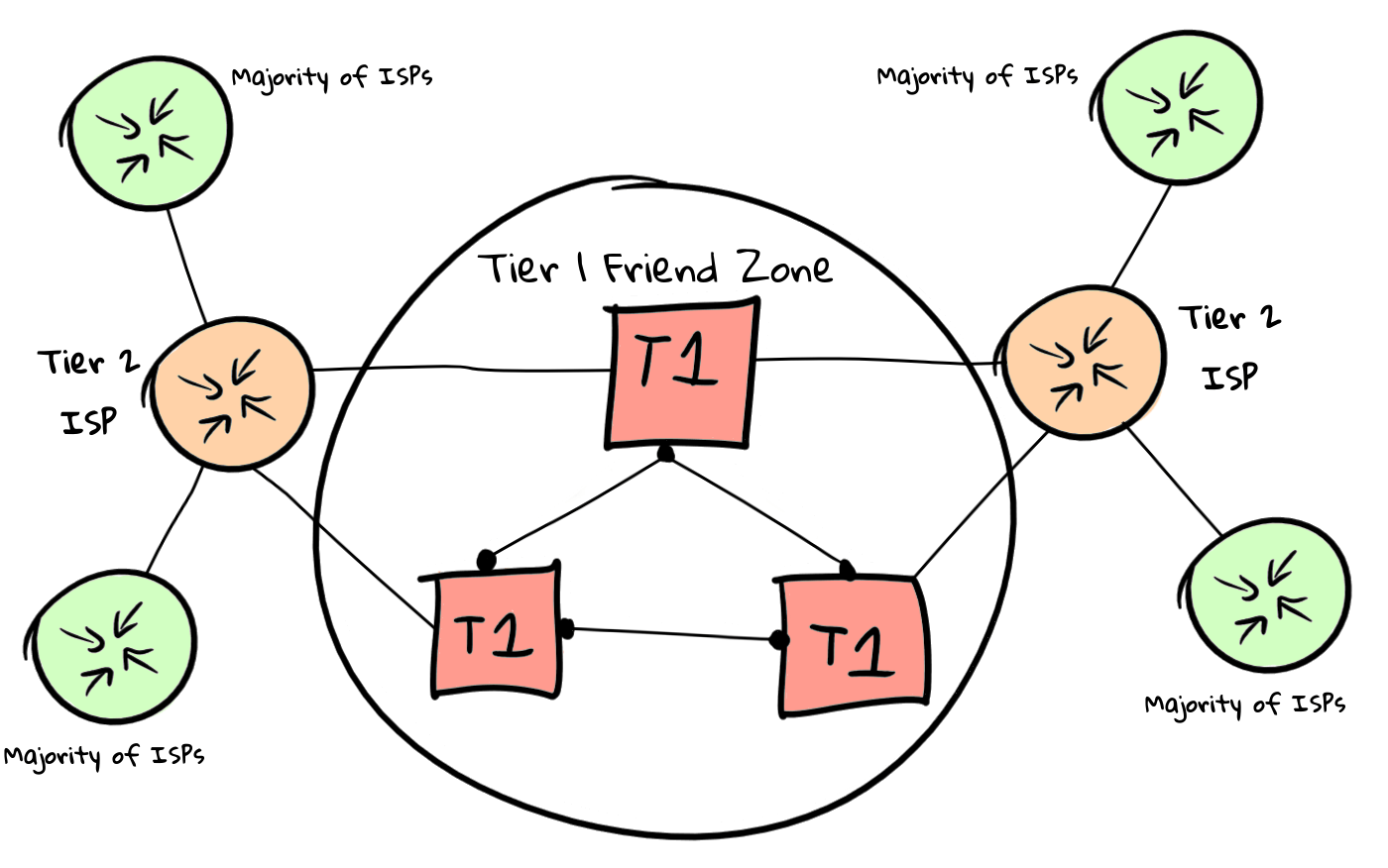
EvE online wird jedoch in Zukunft installiert. Wer weiß, ob das Internet auf dieses Routing-Schema angewiesen ist, um Gewinn zu erzielen. Stellen wir uns vor, dass dies nicht so ist, dass wir sehen können, wie BGP in größeren Netzwerken skaliert.
Dazu müssen wir das tatsächliche Verhalten des BGP-Routers und der Verbindung simulieren. Angesichts der Tatsache, dass EvE eine relativ geringe Anzahl von 8000 Systemen und 13,8 Tausend Verbindungen zwischen ihnen hat. Ich schlug vor, dass es tatsächlich unmöglich wäre, 8000 virtuelle Maschinen mit realem BGP und einem Netzwerk auszuführen, um herauszufinden, wie diese realen Systeme aussehen, wenn sie zusammen als Netzwerk fungieren.
Da wir jedoch nicht über unbegrenzte Ressourcen verfügen, müssen wir einen Weg finden, um das kleinste Linux-Image sowohl bei Verwendung von Speicherplatz als auch bei Verwendung von Speicher zu erstellen. Aus diesem Grund habe ich auf eingebettete Systeme aufmerksam gemacht, da eingebettete Systeme häufig in Umgebungen mit sehr geringen Ressourcen arbeiten müssen. Ich bin auf
Buildroot gestoßen und hatte nach ein paar Stunden ein kleines Linux-Image, das nur das enthielt, was ich brauchte, damit dieses Projekt funktioniert.
$ ls -alh total 17M drwxrwxr-x 2 ben ben 4.0K Jan 22 22:46 . drwxrwxr-x 6 ben ben 4.0K Jan 22 22:45 .. -rw-r--r-- 1 ben ben 7.0M Jan 22 22:46 bzImage -rw-r--r-- 1 ben ben 10M Jan 22 22:46 rootfs.ext2
Dieses Image enthält Boot Linux, das außerdem
Folgendes enthält: *
Bird 2 BGP Daemon *
tcpdump und My Traceroute (mtr) für das Netzwerk-Debugging *
Busybox für die Basis-Shell und die Systemdienstprogramme
Dieses Bild kann mit ein paar Optionen einfach in Qemu ausgeführt werden:
qemu-system-i386 -kernel ../bzImage \ -hda rootfs.ext2 \ -hdb fat:./30045343/ \ -append "root=/dev/sda rw" \ -m 64
Um im Netzwerk zu arbeiten, habe ich mich für eine undokumentierte Funktion von qemu (in meiner Version) entschieden, mit der Sie zwei qemu-Prozesse aufeinander lenken und UDP-Sockets verwenden können, um Daten zwischen ihnen zu übertragen. Dies ist praktisch, da wir eine große Anzahl von Links bereitstellen möchten, sodass die Verwendung der üblichen
TUN / TAP- Adaptermethode schnell zu Verwirrung führen kann.
Da diese Funktion teilweise nicht dokumentiert ist, gab es einige Probleme bei der Bedienung. Es hat lange gedauert, bis ich verstanden habe, dass der Netzwerkname in der Befehlszeile für beide Seiten der Verbindung gleich sein sollte. Später stellte sich heraus, dass diese Funktion bereits gut dokumentiert ist, wie es normalerweise der Fall ist. Änderungen benötigen Zeit, um zu älteren Versionen der Distribution zu gelangen.
Sobald dies funktionierte, haben wir einige virtuelle Maschinen, die Pakete aneinander senden können, und der Hypervisor sendet sie als UDP-Datagramme. Da wir eine große Anzahl solcher Systeme starten werden, benötigen wir eine schnelle Möglichkeit, sie mithilfe einer zuvor erstellten Konfiguration zu konfigurieren. Zu diesem Zweck können wir die praktische qemu-Funktion verwenden, mit der Sie ein Verzeichnis auf dem Hypervisor in ein virtuelles FAT32-Dateisystem umwandeln können. Dies ist nützlich, da wir damit für jedes System, das wir starten möchten, ein Verzeichnis erstellen können und jeder qemu-Prozess auf dieses Verzeichnis verweist. Dies bedeutet, dass wir für alle virtuellen Maschinen im Cluster dasselbe Startabbild verwenden können.
Da jedes System über 64 MB RAM verfügt und wir 8000 ~ VMs verwenden möchten, benötigen wir mit Sicherheit eine angemessene Menge an RAM. Dafür habe ich 3 m2.xlarge.x86 mit packet.net verwendet, da sie 256 GB RAM mit 2x Xeon Gold 5120 bieten, was bedeutet, dass sie eine angemessene Menge an Unterstützung haben.

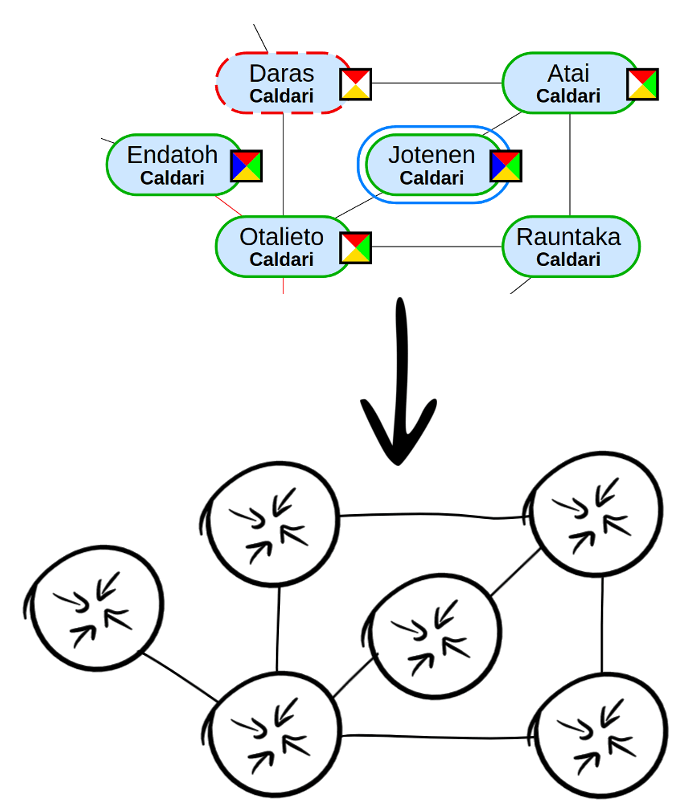
Ich habe ein
anderes Open Source-Projekt verwendet , um eine EvE-Map in Form von JSON zu erstellen, und dann ein benutzerdefiniertes Konfigurationsprogramm basierend auf diesen Daten erstellt. Nachdem ich mehrere Testläufe mit nur wenigen Systemen durchgeführt hatte, habe ich bewiesen, dass sie die Konfiguration von VFAT übernehmen und diesbezüglich BGP-Sitzungen miteinander einrichten können.
Also habe ich den entscheidenden Schritt zum Laden des Universums getan:
Zuerst habe ich versucht, alle Systeme in einem großen Ereignis zu starten, aber leider führte dies zu einer großen Explosion beim Laden des Systems. Danach wechselte ich alle 2,5 Sekunden zum Starten des Systems und 48 Systemkerne kümmerten sich schließlich darum.
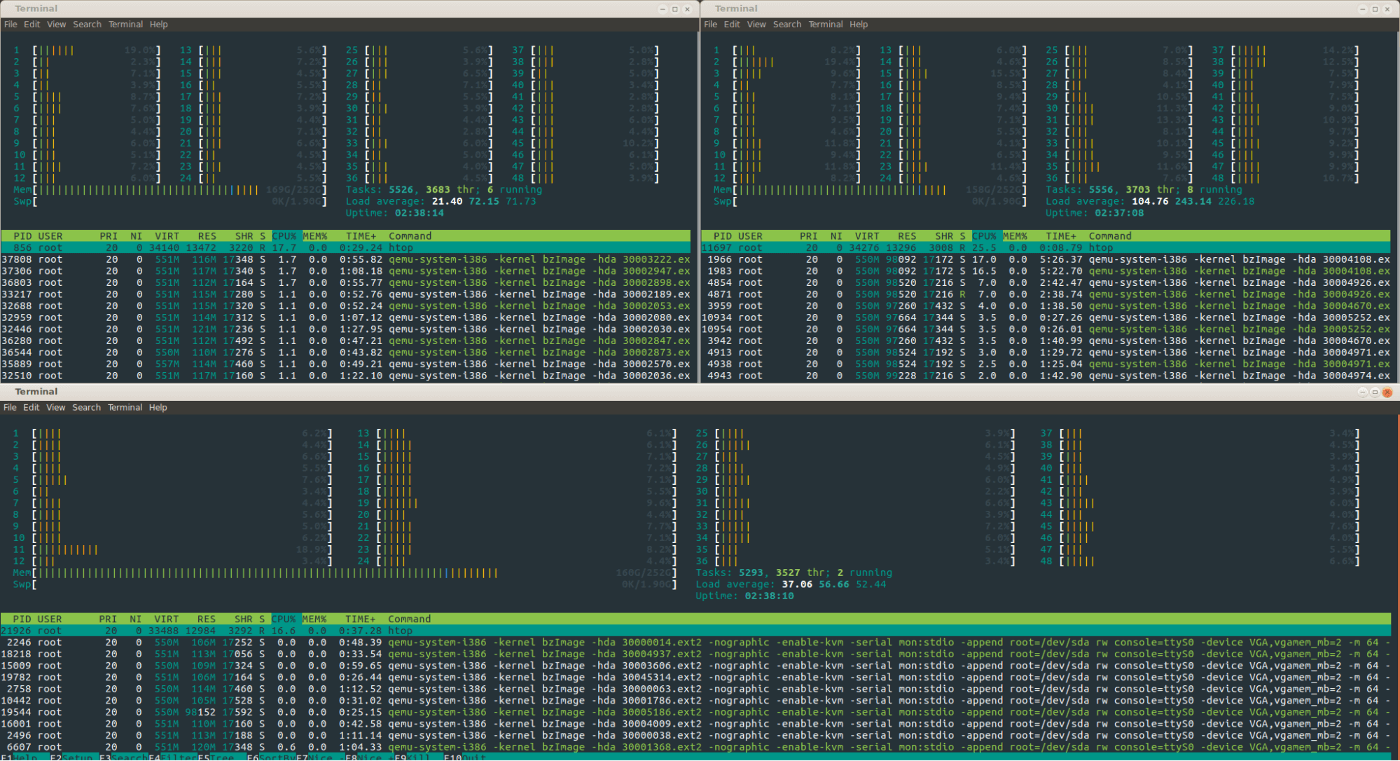
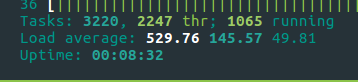
Während des Startvorgangs stellte ich fest, dass auf allen virtuellen Maschinen große „Explosionen“ der CPU-Auslastung auftreten. Später stellte ich fest, dass dies große Teile des Universums waren, die miteinander verbunden waren, wodurch auf beiden Seiten der neu verbundenen virtuellen Maschine große Mengen an BGP-Verkehr verursacht wurden Autos.

root@evehyper1:~/147.75.81.189# ifstat -i bond0,lo bond0 lo KB/s in KB/s out KB/s in KB/s out 690.46 157.37 11568.95 11568.95 352.62 392.74 20413.64 20413.64 468.95 424.58 21983.50 21983.50
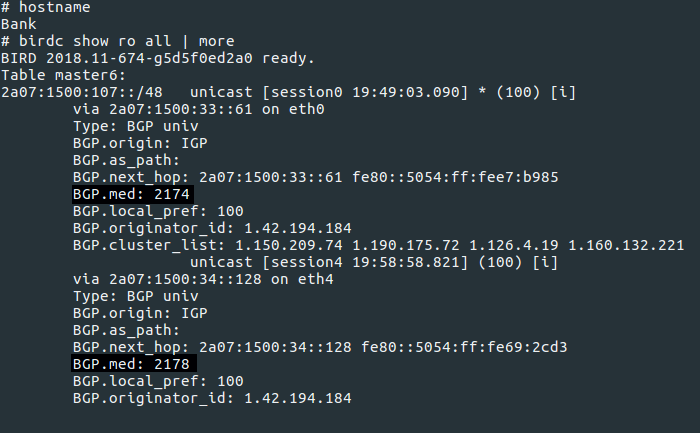
Am Ende sahen wir einige ziemlich erstaunliche BGP-Pfade, da jedes System / 48 IPv6-Adressen ankündigt, können Sie die Routen zu jedem System und zu allen anderen Systemen sehen, die es durchlaufen müsste, um dorthin zu gelangen.
$ birdc6 s ro all 2a07:1500:b4f::/48 unicast [session0 18:13:15.471] * (100) [AS2895i] via 2a07:1500:d45::2215 on eth0 Type: BGP univ BGP.origin: IGP BGP.as_path: 3397 3396 3394 3385 3386 3387 2049 2051 2721 2720 2719 2692 2645 2644 2643 145 144 146 2755 1381 1385 1386 1446 1448 849 847 862 867 863 854 861 859 1262 1263 1264 1266 1267 2890 2892 2895 BGP.next_hop: 2a07:1500:d45::2215 fe80::5054:ff:fe6e:5068 BGP.local_pref: 100
Ich habe einen Schnappschuss der Routing-Tabelle auf jedem Router im Universum erstellt und dann häufig verwendete Systeme für den Zugriff auf andere Systeme dargestellt. Dieses Bild ist jedoch riesig. Hier ist eine kleine Version davon in der Veröffentlichung. Wenn Sie auf ein Bild klicken, denken Sie daran,
dass dieses Bild höchstwahrscheinlich dazu führen wird, dass Ihrem Gerät der Speicherplatz ausgeht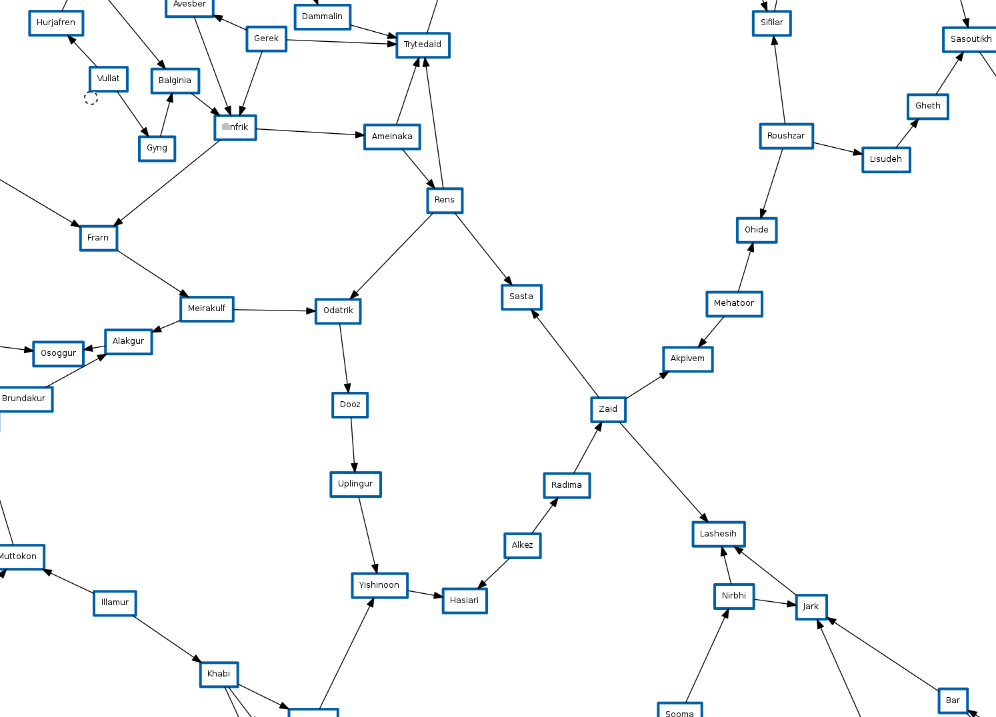
Danach, dachte ich, was können Sie noch BGP-gerouteten Netzwerken zuordnen? Könnten Sie ein kleineres Modell verwenden, um zu testen, wie die Routing-Konfiguration in großen Netzwerken funktioniert?
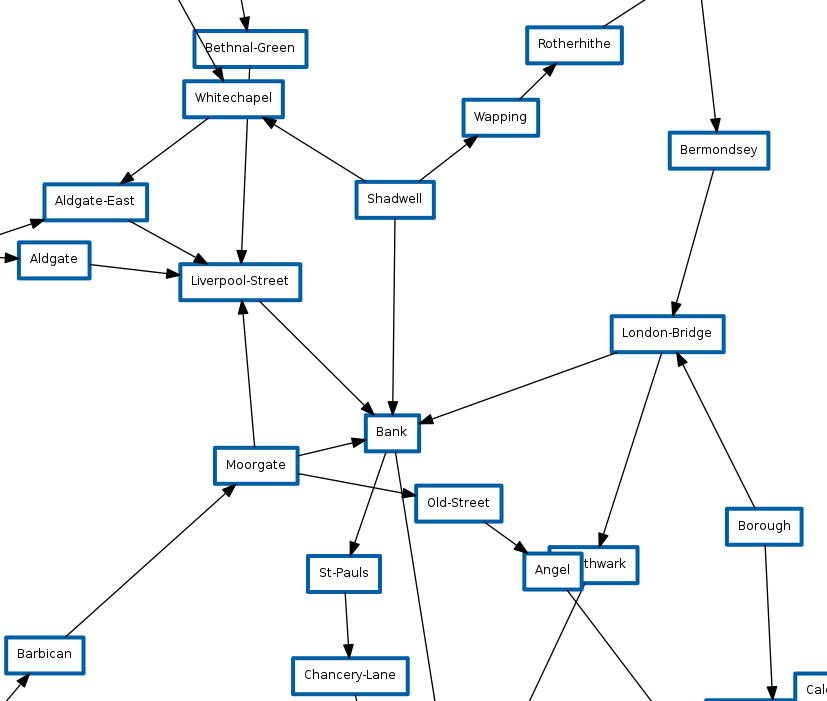
Ich habe eine Datei vorbereitet, in der das Londoner U-Bahn-System angezeigt wird, um dies zu überprüfen :

Das TFL-System ist viel kleiner und hat viel mehr Sprünge, die nur eine Richtung haben, da die meisten Stationen nur eine „Transportlinie“ haben. Wir können jedoch eines daraus lernen: Wir können dies verwenden, um sicher mit
BGP-MEDs zu spielen.
Es gibt jedoch ein Problem, wenn wir eine TFL-Karte als BGP-Netzwerk betrachten. In der realen Welt ist die Zeit / Verzögerung zwischen den einzelnen Stopps nicht gleich. Wenn wir diese Verzögerung simulieren würden, würden wir das System daher nicht so schnell wie möglich umgehen. da wir uns nur die kleinste Anzahl von Stationen ansehen, die den Weg gehen.
Dank des Gesetzes über die Informationsfreiheit (FOIA) gab uns die an die
TFL gesendete Anfrage jedoch die Zeit, die erforderlich war, um von einer Station zur anderen zu wechseln. Sie wurden in der BGP-Routerkonfiguration generiert, zum Beispiel:
protocol bgp session1 { neighbor 2a07:1500:34::62 as 1337; source address 2a07:1500:34::63; local as 1337; enable extended messages; enable route refresh; ipv6 { import filter{ bgp_med = bgp_med + 162; accept; }; export all; }; } protocol bgp session2 { neighbor 2a07:1500:1a::b3 as 1337; source address 2a07:1500:1a::b2; local as 1337; enable extended messages; enable route refresh; ipv6 { import filter{ bgp_med = bgp_med + 486; accept; }; export all; }; }
In
session1 Zeitintervall zwischen zwei Stationen 1,6 Minuten, in dieser Richtung 4,86 Minuten. Diese Nummer wird der Route für jede Station / jeden Router hinzugefügt, die bzw. den sie durchläuft. Dies bedeutet, dass jeder Router / jede Station im Netzwerk weiß, dass es Zeit ist, über jede Route zu jeder Station zu gelangen:
Dies bedeutet, dass Traceroutes genau bestimmen, wie Sie beispielsweise in London zu meiner Paddington-Station reisen können:

Wir können auch Spaß mit BGP haben, indem wir Wartungsarbeiten oder einen Vorfall an der Waterloo Station simulieren:
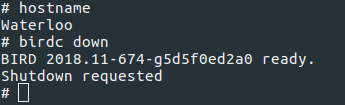
Und da das gesamte Netzwerk sofort die nächstschnellste Route wählt und nicht die mit der geringsten Anzahl von Überholstationen.
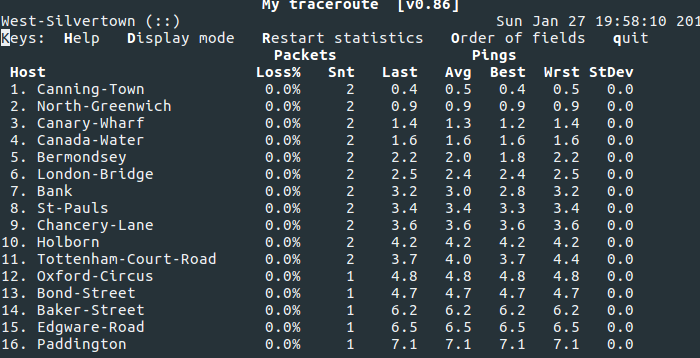
Und das ist die Magie von BGP MED beim Routing!
Der Code für all dies ist bereits verfügbar. Sie können Ihre eigenen Netzwerkstrukturen mit einem relativ einfachen JSON-Schema erstellen oder EvE einfach online oder TFL verwenden, da sie sich bereits im Repository befinden.
Den gesamten Code dazu finden Sie hier