Wir setzen die Geschichte fort, wie man Nummernschilder für diejenigen erkennt, die die Hallo-Welt-Anwendung in Python schreiben können! In diesem Teil lernen wir, wie man Modelle trainiert, die nach einer Region eines bestimmten Objekts suchen, und wie man ein einfaches RNN-Netzwerk schreibt, das besser mit dem Lesen von Zahlen umgehen kann als einige kommerzielle Gegenstücke.
In diesem Teil werde ich Ihnen erklären, wie Sie Nomeroff Net für Ihre Daten trainieren, wie Sie eine qualitativ hochwertige Erkennung erhalten, wie Sie die GPU-Unterstützung konfigurieren und alles um eine Größenordnung beschleunigen ...
Wir trainieren Mask RCNN, um den Bereich mit der Nummer zu finden
Natürlich können Sie nicht nur eine Nummer finden, sondern auch jedes andere Objekt, das Sie suchen müssen. Sie können beispielsweise analog nach einer Kreditkarte suchen und deren Details lesen. Im Allgemeinen wird das Finden der Maske, in die das Objekt im Bild eingeschrieben ist, als Aufgabe „Instanzsegmentierung“ bezeichnet (darüber habe ich bereits im ersten Teil geschrieben).
Jetzt werden wir herausfinden, wie das Netzwerk trainiert werden kann, um dieses Problem zu lösen. Tatsächlich gibt es hier wenig Programmierung, alles läuft auf ein monotones, langwieriges, einheitliches Datenmarkup hinaus. Ja, ja, nachdem Sie Ihre ersten hundert markiert haben, werden Sie verstehen, was ich meine :)
Der Datenaufbereitungsalgorithmus lautet also wie folgt:
- Wir nehmen Bilder mit einer Größe von mindestens 300 x 300 auf und legen alles in einem Ordner ab
- Laden Sie das Markup- Tool VGG Image Annotator (VIA) herunter. Sie können es online markieren. Die Ausgabe ist ein Verzeichnis mit einem Foto und der JSON-Datei, die Sie mit dem Markup erstellt haben. Es gibt zwei solcher Ordner, in dem einen, der Zug genannt wird , der den Hauptteil der Beispiele darstellt, im zweiten Wert etwa 20-30% der Anzahl der Beispiele der ersten Packung (Natürlich sollten diese Ordner nicht die gleichen Fotos haben). Sie können ein Beispiel für markierte Daten für das Nomeroff Net-Projekt sehen . Nach Menge - je mehr desto besser. Einige Experten empfehlen 5.000 Beispiele, wir sind faul und tippen etwas mehr als 1.000, da das Ergebnis für uns ganz gut war.

- Um mit dem Training zu beginnen, müssen Sie das Nomeroff Net- Projekt von Github herunterladen, Mask RCNN mit allen Abhängigkeiten installieren und versuchen, das Trainingsskript train / mrcnn.ipynb für unsere Daten auszuführen
- Ich warne Sie sofort, das geht nicht schnell. Wenn Sie keine GPU haben, kann dies Tage dauern. Um den Lernprozess erheblich zu beschleunigen, ist es ratsam, Tensorflow mit GPU-Unterstützung zu installieren.
- Wenn das Training für unseren Datensatz erfolgreich war, können Sie jetzt sicher zu Ihrem eigenen wechseln.
Bitte beachten Sie, dass wir nicht alles von Grund auf neu trainieren. Wir trainieren das Modell, das auf COCO-Datensatzdaten trainiert wurde, die Mask RCNN beim ersten Durchlauf herunterlädt
- Sie können nicht coco, sondern unser Modell mask_rcnn_numberplate_0700.h5 trainieren und den Pfad zu diesem Modell im Konfigurationsparameter WEIGHTS angeben (standardmäßig "WEIGHTS": "coco").
- Folgende Parameter können erweitert werden: EPOCH, STEPS_PER_EPOCH
- Das Ergebnis nach jeder Ära wird in den Ordner ./logs/numberplate< Datum des Starts> / verschoben
Um das trainierte Modell in der Praxis zu testen
, ersetzen
Sie in den
Projektbeispielen MASK_RCNN_MODEL_PATH durch den Pfad zu Ihrem Modell.
Verbesserung des Kennzeichenklassifikators gemäß Ihren Anforderungen
Nachdem die Bereiche mit Nummernschildern gefunden wurden, müssen Sie versuchen, festzustellen, welchen Status / Typ der Nummer wir erkennen. Hier wirkt die Universalisierung der Qualität der Anerkennung entgegen. Daher müssen Sie im Idealfall einen Klassifikator trainieren, der nicht nur bestimmt, in welchem Land sich die Nummer befindet, sondern auch die Art des Designs dieser Nummer (Position der Zeichen, Symboloptionen für einen bestimmten Nummerntyp).
In unserem Projekt haben wir Unterstützung für die Erkennung der Nummern der Ukraine, der Russischen Föderation und der europäischen Nummern im Allgemeinen implementiert. Die Erkennungsqualität europäischer Zahlen ist etwas schlechter, da Zahlen mit unterschiedlichen Designs und einer erhöhten Anzahl von Zeichen gefunden werden. Vielleicht wird es im Laufe der Zeit separate Erkennungsmodule für "eu-ee", "eu-pl", "eu-nl", ... geben.
Bevor Sie ein Nummernschild klassifizieren, müssen Sie es aus dem Bild „ausschneiden“ und normalisieren. Mit anderen Worten, entfernen Sie alle Verzerrungen maximal und erhalten Sie ein ordentliches Rechteck, das einer weiteren Analyse unterzogen wird. Diese Aufgabe stellte sich als nicht trivial heraus, ich musste mich sogar an die Schulmathematik erinnern und eine spezielle Implementierung des k-means :) Clustering-Algorithmus :) schreiben. Das Modul, das dies verarbeitet, heißt RectDetector. So sehen normalisierte Zahlen aus, die wir weiter klassifizieren und erkennen werden.

Um den Prozess der Erstellung eines Datensatzes zur Klassifizierung von Zahlen irgendwie zu automatisieren, haben wir ein
kleines Admin-Panel für NodeJS entwickelt . Mit diesem Admin-Bereich können Sie die Beschriftung auf dem Nummernschild und die Klasse, zu der sie gehört, markieren.
Es kann mehrere Klassifikatoren geben. In unserem Fall nach Art der Nummer und danach, ob sie auf dem Foto skizziert / übermalt ist.
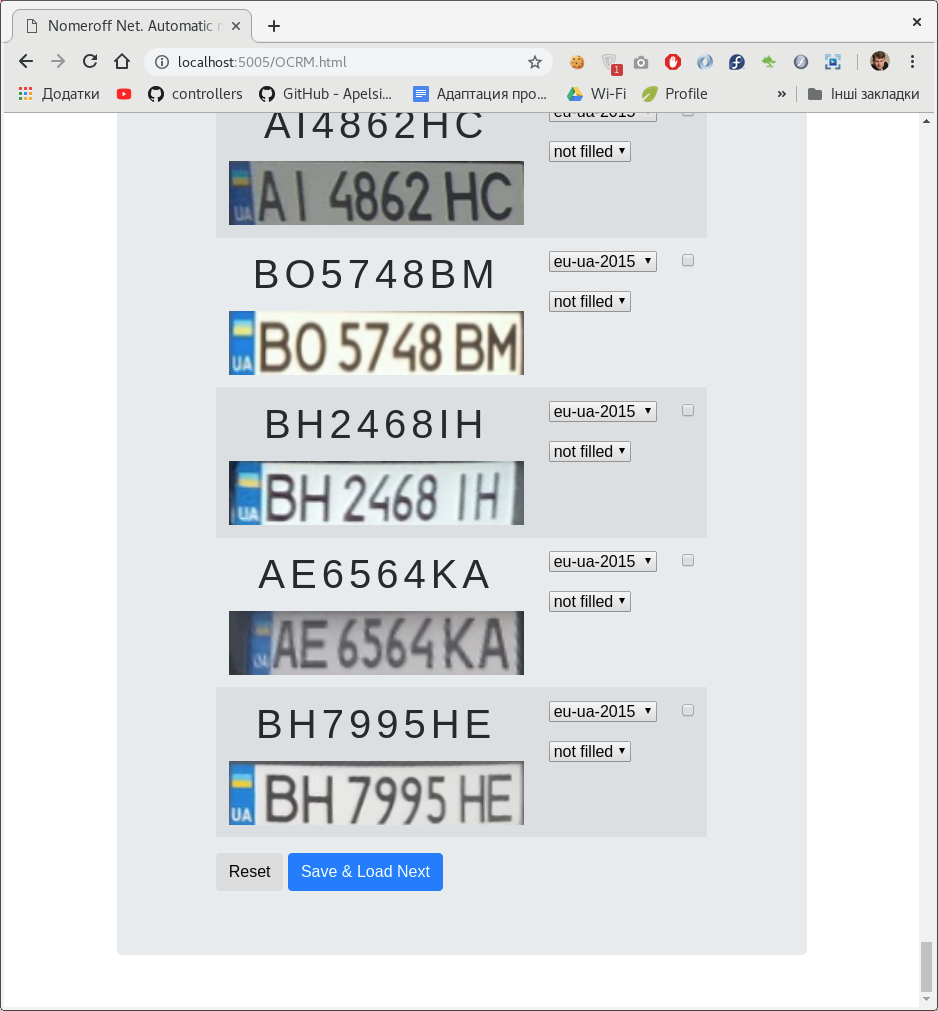
Nachdem wir den Datensatz markiert haben, teilen wir ihn in Trainings-, Validierungs- und Testmuster auf. Laden Sie beispielsweise unser
Dataset autoriaNumberplateOptions3Dataset-2019-05-20.zip herunter, um zu sehen, wie dort alles
funktioniert .
Da die Auswahl bereits markiert (moderiert) wurde, müssen Sie "isModerated": 1 in "isModerated" in den zufälligen json-Dateien: 0 ändern und dann das Admin-Panel starten .
Wir trainieren den Klassifikator:
Das Trainingsskript
train / options.ipynb hilft Ihnen dabei, Ihre Version des Modells zu erhalten. Unser Beispiel zeigt, dass wir für die Klassifizierung von Regionen / Typen von Kennzeichen eine Genauigkeit von
98,8% für die Klassifizierung von "Ist die Nummer übermalt?" Erhalten haben.
99,4% auf unseren Datensatz. Ich stimme zu, es ist gut geworden.
Trainieren Sie Ihre OCR (Texterkennung)
Nun, wir haben den Bereich mit der Nummer gefunden und ihn zu einem Rechteck normalisiert, das die Inschrift mit der Nummer enthält. Wie lesen wir den Text? Am einfachsten ist es, FineReader oder Tesseract auszuführen. Die Qualität wird "nicht sehr" sein, aber mit einer guten Auflösung des Bereichs mit der Zahl können Sie eine Genauigkeit von 80% erhalten. Eigentlich ist das keine schlechte Genauigkeit, aber wenn ich Ihnen sage, dass Sie
97% erhalten und gleichzeitig deutlich weniger Computerressourcen ausgeben können? Hört sich gut an - lass es uns versuchen. Für diese Zwecke ist eine etwas ungewöhnliche Architektur geeignet, bei der sowohl Faltungsschichten als auch wiederkehrende Schichten verwendet werden. Die Architektur dieses Netzwerks sieht ungefähr so aus:
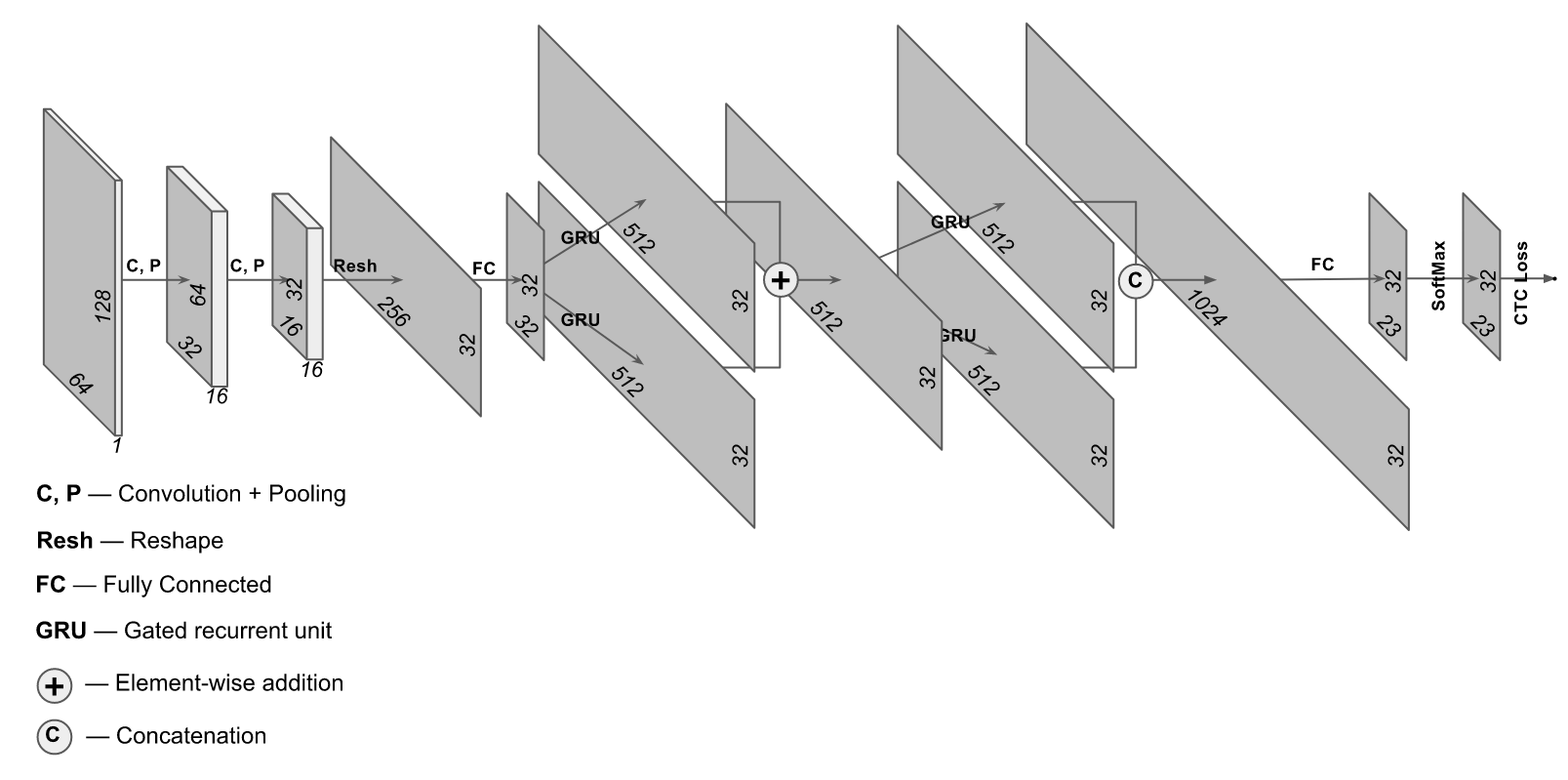
Die Implementierung wurde von der Website
https://supervise.ly/ übernommen . Wir haben sie ein wenig geändert, um sie an realen Fotos zu trainieren (auf der betreffenden Website wurde eine Option für synthetische Stichproben festgelegt).
Jetzt beginnt der lustige Teil, markiere mindestens 5.000 Zahlen :). Wir haben ungefähr
~ 100.000 Ukrainer ,
~ 50.000 Ukrainer mit dem "alten" Design markiert,
~ 6.500 Europäer ,
~ 10.000 RF . Dies war der schwierigste Teil der Entwicklung. Sie können sich nicht einmal vorstellen, wie oft ich auf einem Computerstuhl eingeschlafen bin und mehrere Stunden am Tag für den nächsten Teil der Zahlen moderiert habe. Aber der wahre Held des
Markups ist
Dimabendera - er hat 2/3 des gesamten Inhalts markiert (geben Sie ihm ein Plus, wenn Sie verstehen, wie langweilig es war, all diese Arbeit zu erledigen :))
Sie können versuchen, diesen Prozess irgendwie zu automatisieren, indem Sie beispielsweise jedes Bild zuvor mit Tesseract erkannt haben, und dann die Fehler mithilfe
unseres Admin-Panels korrigieren.
Bitte beachten Sie: Das gleiche Admin-Panel wird verwendet, um den Klassifikator und die OCR auf der Nummer zu markieren. Sie können dort und dort dieselben Daten laden, außer natürlich die skizzierten Zahlen.
Wenn Sie mindestens 5000 Nummern markieren und Ihre OCR trainieren können - zögern Sie nicht, mit Ihren Vorgesetzten einen Preis für sich selbst zu vereinbaren. Ich bin sicher, dieser Test ist nichts für Weicheier!
Erste Schritte mit dem Training
Das
Skript train / ocr-ru.ipynb trainiert das Modell für russische Zahlen, es gibt Beispiele für die
Ukraine und
Europa .
Bitte beachten Sie, dass es in den Trainingseinstellungen nur eine Ära gibt (ein Durchgang).
Ein Merkmal des Trainings eines solchen Datensatzes ist für jeden Versuch ein sehr unterschiedliches Ergebnis. Vor jeder Trainingseinheit werden die Daten in zufälliger Reihenfolge gemischt. Manchmal ist es für das Training eher „nicht sehr gut“. Ich empfehle, dass Sie es mindestens fünf Mal versuchen, während Sie die Genauigkeit der Testdaten kontrollieren. Bei verschiedenen Startversuchen könnte unsere Genauigkeit von
87% auf 97% „springen“.
Einige Empfehlungen :
- Sie müssen nicht alles neu initialisieren. Starten Sie einfach die Zeile model = ocrTextDetector.train (mode = MODE) neu, bis Sie das erwartete Ergebnis erhalten
- Ein Grund für die schlechte Genauigkeit sind unzureichende Daten. Wenn es Ihnen nicht gefällt, markieren wir es immer wieder. Irgendwann wächst die Qualität nicht mehr. Für jeden Datensatz, der anders ist, können Sie sich auf die Anzahl von 10.000 gekennzeichneten Beispielen konzentrieren
- Das Training wird schneller, wenn Sie den NVIDIA CuDNN-Treiber installiert haben. Ändern Sie den Wert MODE = "gpu" im Trainingsskript, und CuDNNGRU wird anstelle der GRU-Schicht verbunden, was zu einer dreifachen Beschleunigung führt.
Ein bisschen über das Einrichten von Tensorflow für NVIDIA-GPUs
Wenn Sie ein glücklicher Besitzer einer GPU von NVIDIA sind, können Sie die Dinge manchmal beschleunigen: sowohl Modelltraining als auch Inferenzzahlen (Erkennungsmodus). Das Problem ist, alles richtig zu installieren und zu kompilieren.
Wir verwenden Fedora Linux auf unseren ML-Servern (dies geschah historisch).
Die ungefähre Reihenfolge der Aktionen für diejenigen, die dieses Betriebssystem verwenden, ist wie folgt:
- Wir haben den GPU-Treiber für Ihre Betriebssystemversion hier für Fedora eingestellt
- Wir verbinden das NVIDIA-Repository und installieren von dort aus das CUDA-Paket, hier für CentOS / Fedora
- Wir setzen Bazel und sammeln Tensorflow aus Quellen auf diesem Dock
- Es ist auch ratsam, die alte Version des gcc-Compilers namens cuda-gcc zu installieren. Auf cuda-gcc 6.4 lief alles gut für mich. Geben Sie beim Konfigurieren der Assembly den Pfad zu cuda-gcc an
Wenn Sie Tensorflow nicht mit GPU-Unterstützung erstellen können, können Sie alles über Docker ausführen. Zusätzlich zu Docker müssen Sie das Paket nvidia-docker2 installieren. Im Docker-Container können Sie das Jupyter-Notebook ausführen und dort alles ausführen.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Nützliche Links
Ich möchte auch den 2expres,
glassofkvass habrausers,
dafür danken, dass sie die Fotos mit Zahlen und
dimabendera versehen haben, um den größten Teil des Codes zu schreiben und die meisten Daten aus dem Nomeroff Net-Projekt zu markieren.
UPD1: Da ich und Dmitri an den PM Standardfragen zur Erkennung von Zahlen, einer Kombination von Tensorflow mit GPU usw. gesendet werden. und Dmitry und ich geben die gleichen Antworten, ich möchte diesen Prozess irgendwie optimieren.
Wir empfehlen, die Korrespondenz in den Kommentaren strukturierter und thematischer zu gestalten. Dafür gibt es auf GitHub praktische Funktionen. Bitte stellen Sie in Zukunft Fragen nicht in den Kommentaren, sondern in der
thematischen Ausgabe von github Nomeroff NetUPD2: Im Laufe der Zeit erschienen auch Datensätze:
kasachische Zahlen ,
georgische Zahlen