Ist es Ihnen passiert, dass Sie sich auf ein einfaches Spiel eingelassen haben und dachten, künstliche Intelligenz könnte damit durchaus fertig werden? Früher habe ich mich entschlossen, einen solchen Bot-Player zu entwickeln. Darüber hinaus gibt es jetzt viele Tools für Computer Vision und maschinelles Lernen, mit denen Sie Modelle erstellen können, ohne die Details der Implementierung genau zu kennen. Gewöhnliche Sterbliche können einen Prototyp herstellen, ohne monatelang von Grund auf neuronale Netze aufzubauen.

Unter dem Schnitt finden Sie den Prozess der Erstellung eines Proof-of-Concept-Bots für das Clash Royale-Spiel, in dem ich Scala-, Python- und CV-Bibliotheken verwendet habe. Mit Computer Vision und maschinellem Lernen habe ich versucht, einen Bot für ein Spiel zu erstellen, das wie ein Live-Spieler interagiert.
Mein Name ist Sergey Tolmachev, ich bin leitender Scala-Entwickler auf der Waves-Plattform und unterrichte
einen Scala-Kurs im Binary District. In meiner Freizeit studiere ich andere Technologien wie KI. Und ich wollte die erworbenen Fähigkeiten mit etwas praktischer Erfahrung stärken. Im Gegensatz zu KI-Wettbewerben, bei denen Ihr Bot gegen die Bots anderer Benutzer spielt, kann Clash Royale gegen Menschen spielen, was lustig klingt. Ihr Bot kann lernen, echte Spieler zu schlagen!
Spielmechanik in Clash Royale
Die Spielmechanik ist recht einfach. Sie und Ihr Gegner haben drei Gebäude: eine Festung und zwei Türme. Spieler vor dem Spiel sammeln Decks - 8 verfügbare Einheiten, die dann im Kampf eingesetzt werden. Sie haben verschiedene Level und können gepumpt werden, indem sie mehr Karten dieser Einheiten sammeln und Updates kaufen.
Nach dem Start des Spiels können Sie verfügbare Einheiten in sicherer Entfernung von den feindlichen Türmen platzieren und gleichzeitig Manaeinheiten ausgeben, die während des Spiels langsam wiederhergestellt werden. Einheiten werden zu feindlichen Gebäuden geschickt und von Feinden abgelenkt, die auf dem Weg angetroffen werden. Der Spieler kann nur die Ausgangsposition der Einheiten kontrollieren - er kann ihre weitere Bewegung und ihren Schaden nur durch Einstellen anderer Einheiten beeinflussen.
Es gibt immer noch Zaubersprüche, die überall auf dem Spielfeld gespielt werden können. Sie verursachen normalerweise Schaden an Einheiten auf unterschiedliche Weise. Zauber können Einheiten in einem Gebiet klonen, einfrieren oder beschleunigen.
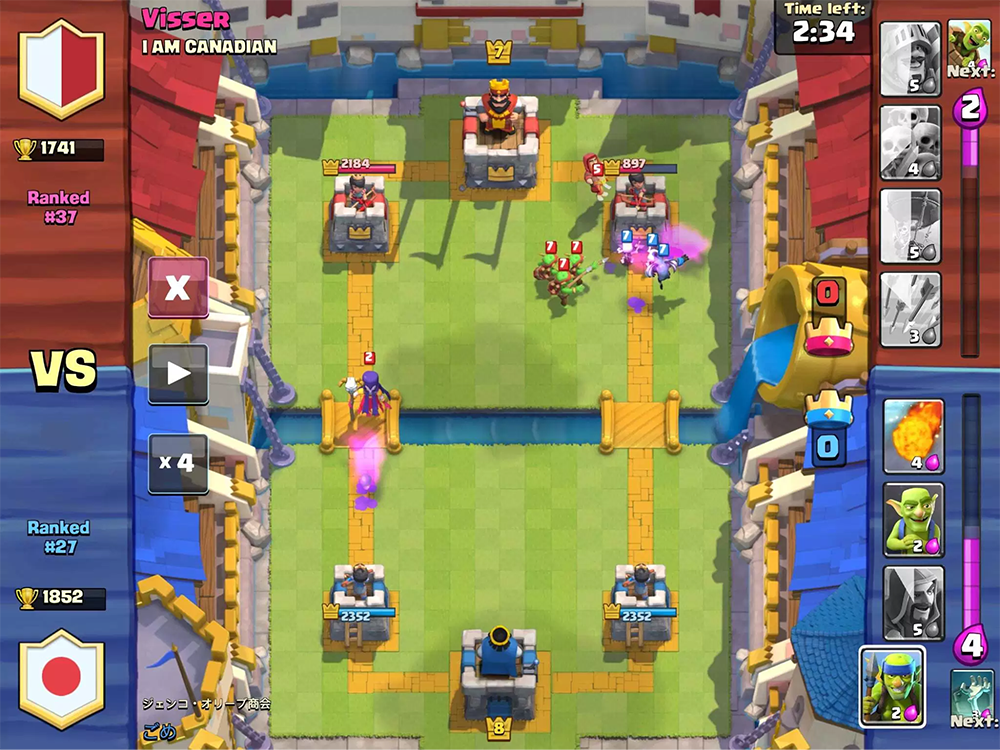
Das Ziel des Spiels ist es, feindliche Gebäude zu zerstören. Um einen vollständigen Sieg zu erringen, müssen Sie die Festung zerstören oder nach zwei Minuten des Spiels weitere Gebäude zerstören (die Regeln hängen von den Spielmodi ab, aber im Allgemeinen klingen sie so).
Während des Spiels müssen Sie die Bewegung der Einheiten, die mögliche Anzahl an Mana und die aktuellen feindlichen Karten berücksichtigen. Sie müssen auch berücksichtigen, wie sich die Installation des Geräts auf das Spielfeld auswirkt.
Eine Lösung entwickeln
Clash Royale ist ein Handyspiel, daher habe ich beschlossen, es auf Android auszuführen und über ADB damit zu interagieren. Dies würde die Arbeit mit dem Simulator oder mit einem realen Gerät unterstützen.
Ich entschied, dass der Bot, wie viele andere Spiel-AIs, am Perception-Analysis-Action-Algorithmus arbeiten sollte. Die gesamte Umgebung des Spiels wird auf dem Bildschirm angezeigt, und die Interaktion mit ihr erfolgt durch Klicken auf den Bildschirm. Daher sollte der Bot ein Programm sein, dessen Eingabe den aktuellen Status des Spiels beschreibt: den Ort und die Eigenschaften von Einheiten und Gebäuden, die aktuell möglichen Karten und die Menge an Mana. Am Ausgang sollte der Bot ein Array von Koordinaten angeben, auf denen die Einheit aufgezeichnet werden soll.
Bevor der Bot selbst erstellt wurde, musste das Problem des Extrahierens von Informationen über den aktuellen Status des Spiels aus dem Screenshot gelöst werden. Im Großen und Ganzen ist der weitere Inhalt des Artikels dieser Aufgabe gewidmet.
Um dieses Problem zu lösen, habe ich mich für Computer Vision entschieden. Vielleicht ist dies nicht die beste Lösung: Ein Lebenslauf ohne viel Erfahrung und Ressourcen weist eindeutig Einschränkungen auf und kann nicht alles auf menschlicher Ebene erkennen.
Es wäre genauer, Daten aus dem Speicher zu entnehmen, aber ich hatte keine solche Erfahrung. Root ist erforderlich und insgesamt sieht diese Lösung komplizierter aus. Es ist auch unklar, ob hier eine Geschwindigkeit in Echtzeit erreicht werden kann, wenn Sie nach Objekten mit einer Heap-JVM im Gerät suchen. Außerdem wollte ich das CV-Problem mehr als das lösen.
Theoretisch könnte man einen Proxyserver erstellen und Informationen von dort abrufen. Das Netzwerkprotokoll des Spiels ändert sich jedoch häufig, Proxys im Internet werden angezeigt, sind jedoch schnell veraltet und werden nicht unterstützt.
Verfügbare Spielressourcen
Zunächst habe ich mich entschlossen, die verfügbaren Materialien aus dem Spiel kennenzulernen. Ich fand einen
Club von Handwerkern , die gepackte Spielressourcen herausholten
[1] [2] . Zunächst interessierte ich mich für Bilder von Einheiten, aber im entpackten Spielpaket werden sie in Form einer Kachelkarte (Teile, aus denen eine Einheit besteht) dargestellt.
Ich fand auch geklebte (wenn auch nicht perfekte) Skripte von Einheitenanimationsrahmen - sie waren nützlich für das Training des Erkennungsmodells.

Darüber hinaus finden Sie in den Ressourcen CSV mit verschiedenen Spieldaten - der Menge an HP, dem Schaden an Einheiten verschiedener Level usw. Dies ist nützlich, wenn Sie eine Bot-Logik erstellen. Aus den Daten ging beispielsweise hervor, dass das Feld in 18 x 29 Zellen unterteilt war und nur Einheiten darauf platziert werden können. Es gab auch alle Bilder von Einheitenkarten, die uns später nützlich sein werden.
Computer Vision für die Faulen
Nach der Suche nach verfügbaren CV-Lösungen wurde klar, dass diese auf jeden Fall an einem gekennzeichneten Datensatz geschult werden müssen. Ich machte Screenshots und war bereits bereit, eine bestimmte Anzahl von Screenshots mit meinen Händen zu markieren. Dies stellte sich als Herausforderung heraus.
Das Auffinden verfügbarer Erkennungsprogramme dauerte einige Zeit. Ich habe mich für
labelImg entschieden . Alle Annotationsanwendungen, die ich fand, waren ziemlich primitiv: Viele unterstützten keine Tastaturkürzel, die Auswahl von Objekten und deren Typen war viel weniger bequem als in labelImg.
Während des Markups erwies es sich als nützlich, den Quellcode der Anwendung zu haben. Ich habe alle paar Sekunden des Spiels Screenshots gemacht. Die Screenshots enthalten viele Objekte (z. B. eine Armee von Skeletten), und ich habe eine Änderung in labelImg vorgenommen. Standardmäßig wurden beim Markieren des nächsten Bildes die Beschriftungen des vorherigen Bilds übernommen. Oft mussten sie einfach an eine neue Position der Einheiten gebracht werden, die toten Einheiten entfernen und einige hinzugefügte hinzufügen, und nicht von Grund auf neu markieren.

Der Prozess erwies sich als ressourcenintensiv - in zwei Tagen im stillen Modus habe ich ungefähr 200 Screenshots gepostet. Die Stichprobe sieht sehr klein aus, aber ich habe beschlossen, mit dem Experimentieren zu beginnen. Sie können jederzeit weitere Beispiele hinzufügen und die Qualität des Modells verbessern.
Zum Zeitpunkt des Markups wusste ich nicht, welches Trainingstool ich verwenden würde, und entschied mich daher, die Markup-Ergebnisse im VOC-Format zu speichern - einem der konservativen und scheinbar universellen.
Es kann sich die Frage stellen: Warum nicht einfach nach Pixel-für-Pixel-Bildern von Einheiten suchen? Das Problem ist, dass man dafür nach einer großen Anzahl unterschiedlicher Animationsrahmen verschiedener Einheiten suchen müsste. Es würde kaum funktionieren. Ich wollte eine universelle Lösung entwickeln, die verschiedene Berechtigungen unterstützt. Darüber hinaus können Einheiten je nach dem auf sie ausgeübten Effekt eine andere Farbe haben - Einfrieren, Beschleunigen.
Warum habe ich mich für YOLO entschieden?
Ich begann mögliche Bilderkennungslösungen zu untersuchen. Ich habe mir die Anwendung verschiedener Algorithmen angesehen: OpenCV, TensorFlow, Torch. Ich wollte so schnell wie möglich erkennen, sogar die Genauigkeit opfern und so schnell wie möglich POC erhalten.
Nachdem ich die
Artikel gelesen hatte, stellte ich fest, dass meine Aufgabe nicht zu den Klassifizierern HOG / LBP / SVM / HAAR / ... passt. Obwohl sie schnell sind, müssten sie - je nach Klassifikator für jede Einheit - viele Male angewendet werden und dann einzeln, um sie für die Suche auf das Bild anzuwenden. Darüber hinaus würde ihr theoretisches Funktionsprinzip zu schlechten Ergebnissen führen: Einheiten können eine andere Form haben, beispielsweise wenn sie sich nach links und oben bewegen.
Theoretisch kann man mit einem neuronalen Netzwerk es einmal auf ein Bild anwenden und alle Einheiten unterschiedlichen Typs mit ihrer Position ermitteln, sodass ich anfing, nach neuronalen Netzwerken zu suchen. TensorFlow hat Unterstützung für Convolutional Neural Networks (CNN) gefunden. Es stellte sich heraus, dass es nicht erforderlich ist, neuronale Netze von Grund auf neu zu trainieren - Sie können
das vorhandene leistungsstarke Netz neu trainieren.
Dann fand ich einen praktischeren YOLO-Algorithmus, der weniger Komplexität verspricht und daher einen Hochgeschwindigkeits-Suchalgorithmus bereitstellen musste, ohne die Genauigkeit zu beeinträchtigen (und in einigen Fällen andere Modelle zu übertreffen).
Die YOLO-Website verspricht einen großen Geschwindigkeitsunterschied mit dem winzigen Modell und einem kleineren, optimierten Netzwerk. Mit YOLO können Sie auch das fertige neuronale Netzwerk für Ihre Aufgabe neu
trainieren. Darknet - ein
Open- Source-Framework für die Verwendung verschiedener Neuronen, deren Entwickler YOLO entwickelt haben - ist eine einfache native C-Anwendung, und alle Arbeiten damit erfolgen über ihre Parameteraufrufe.
TensorFlow, in Python geschrieben, ist in der Tat eine Python-Bibliothek und wird mit selbst geschriebenen Skripten verwendet, die Sie herausfinden oder verfeinern müssen, um sie Ihren Anforderungen anzupassen. Für einige ist die Flexibilität von TensorFlow wahrscheinlich ein Plus, aber ohne auf Details einzugehen, ist es kaum möglich, es schnell zu nutzen. Daher fiel in meinem Projekt die Wahl auf YOLO.
Modellbau
Um an der Modellschulung zu arbeiten, habe ich Ubuntu 18.10 installiert, Assembly-Pakete, das OpenCL-Paket von NVIDIA und andere Abhängigkeiten geliefert und Darknet erstellt.
Github hat einen
Abschnitt mit einfachen Schritten zur Umschulung des YOLO-Modells : Sie müssen das Modell und die Konfigurationen herunterladen, ändern und mit der Umschulung beginnen.
Zuerst wollte ich versuchen, ein einfaches YOLO-Modell umzuschulen, dann Tiny und sie zu vergleichen. Es stellte sich jedoch heraus, dass Sie für das Training einfacher Modelle 4 GB Grafikkartenspeicher benötigen und ich nur eine 3 GB NVIDIA GeForce GTX 1060-Grafikkarte für Spiele gekauft habe. Daher konnte ich sofort nur das Tiny-Modell trainieren.
Das Markup der Einheiten auf den Bildern, die ich hatte, war im VOC-Format, und YOLO arbeitete mit seinem eigenen Format.
Daher habe ich das Dienstprogramm
convert2Yolo verwendet , um Anmerkungsdateien zu konvertieren.
Nach einer Nacht Training in meinen 200 Screenshots bekam ich die ersten Ergebnisse und sie überraschten mich - das Modell konnte wirklich etwas richtig erkennen! Ich erkannte, dass ich mich in die richtige Richtung bewegte und beschloss, mehr Unterrichtsbeispiele zu machen.

Ich wollte keine Screenshots mehr erstellen und erinnerte mich an Frames aus Einheitenanimationen. Ich habe alle kleinen Bilder mit ihren Klassen markiert und versucht, das Netzwerk auf diesem Set zu trainieren. Das Ergebnis war sehr schlecht. Ich gehe davon aus, dass das Modell aus kleinen Bildern nicht die richtigen Muster für die Verwendung in großen Bildern auswählen konnte.
Danach entschied ich mich, sie auf vorgefertigten Hintergründen von Kampfarenen zu platzieren und programmgesteuert eine VOC-Markup-Datei zu erstellen. Es stellte sich heraus, dass es sich um einen synthetischen Screenshot mit einem automatisch 100% genauen Layout handelt.
Ich habe in Scala ein Skript geschrieben, das den Screenshot in 16 4x4-Quadrate unterteilt und die Einheiten so in ihre Mitte setzt, dass sie sich nicht überschneiden. Das Skript ermöglichte es mir auch, die Erstellung von Trainingsbeispielen anzupassen - wenn Schaden genommen wird, werden Einheiten in der Farbe ihres Teams (rot / blau) gemalt, und während der Klassifizierung erkenne ich Einheiten verschiedener Farben separat. Zusätzlich zur Färbung weisen Einheiten verschiedener Teams, die Schaden erlitten haben, geringfügige Unterschiede in der Kleidung auf. Außerdem habe ich die Einheiten zufällig etwas vergrößert und verkleinert, so dass das Modell gelernt hat, nicht viel von der Größe der Einheit abzuhängen. Als Ergebnis habe ich gelernt, wie man Zehntausende von Trainingsbeispielen erstellt, die in etwa echten Screenshots ähneln.
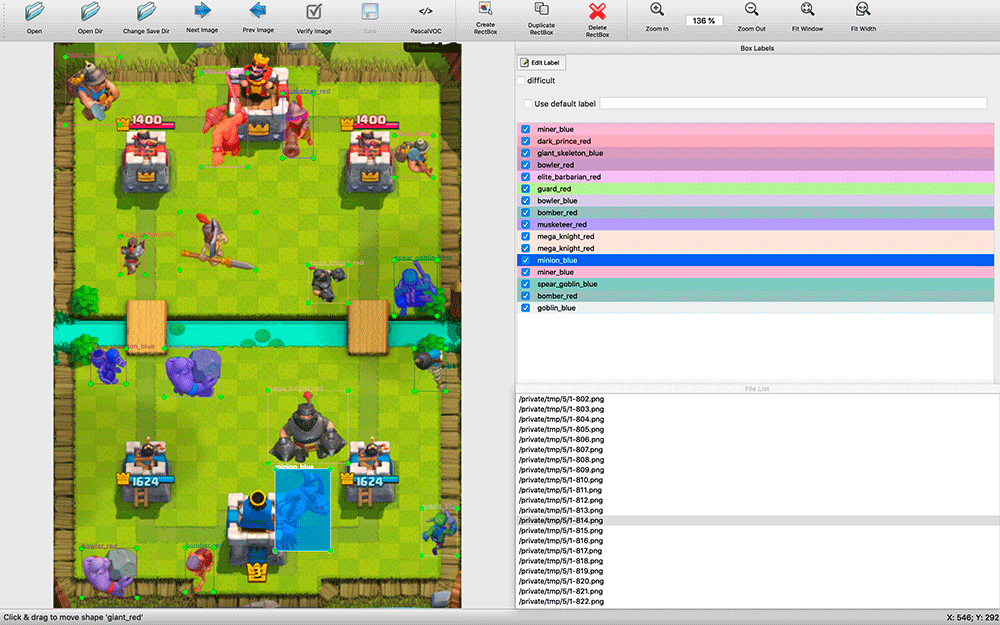
Die Generation war nicht perfekt. Oft wurden Einheiten auf Gebäuden platziert, obwohl sie sich im Spiel hinter ihnen befanden. Es gab keine Beispiele für überlappende Teile der Einheit, obwohl dies keine seltene Situation im Spiel ist. Aber bisher habe ich beschlossen, es zu vernachlässigen.

Das Modell, das nach mehreren Trainingsnächten mit einer Mischung aus 200 realen Screenshots und 5000 generierten Bildern erhalten wurde, die während des Trainingsprozesses einmal täglich neu erstellt wurden, ergab beim Testen mit diesen Screenshots schlechte Ergebnisse. Es ist nicht überraschend, denn die erzeugten Bilder unterscheiden sich stark von den realen.
Daher habe ich das resultierende Modell für eine Umschulung einer mittleren Stichprobe verwendet, in der nur 200 meiner Screenshots vorhanden waren. Danach begann sie viel besser zu arbeiten.
Verdammt schadeIch entschuldige mich dafür, dass ich mit solchen unwissenschaftlichen Maßnahmen als "viel besser" umgegangen bin, aber ich weiß nicht, wie ich Bilder schnell gegenseitig validieren kann. Deshalb habe ich mehrere Screenshots aus einem nicht trainierten Set ausprobiert und nachgefragt, ob die Ergebnisse mich zufriedenstellen. Das ist das Wichtigste. Wir sind faul und machen einen Prototyp, oder?
Die folgenden Schritte zur Verbesserung des Modells waren verständlich: Markieren Sie mit diesen Händen weitere dieser Screenshots und trainieren Sie sie am Modell, trainiert an den generierten Screenshots.
Kommen wir zum Bot
Ich habe beschlossen, einen Bot in Python zu schreiben - er hat viele Tools für ML. Ich entschied mich, mein Modell mit OpenCV zu verwenden, das ab
3.5 den Umgang mit neuronalen Netzwerkmodellen lernte , und fand sogar ein
einfaches Beispiel . Nachdem ich mehrere Bibliotheken für die Arbeit mit ADB ausprobiert hatte, entschied ich mich für
pure-python-adb - alles, was ich brauche, wird einfach dort implementiert: die Bildschirmaufnahmefunktion und die Operation auf dem Shell-Gerät; Ich tippe mit dem 'Eingabetipp'.
Nachdem ich einen Screenshot des Spiels erhalten, Einheiten darauf erkannt und auf dem Bildschirm angezeigt hatte, arbeitete ich weiter daran, den Spielstatus zu erkennen. Zusätzlich zu den Einheiten musste ich die aktuelle Manastufe und die Karten, die dem Spieler zur Verfügung stehen, erkennen.
Das Mana-Level im Spiel wird als Fortschrittsbalken und Zahlen angezeigt. Ohne nachzudenken, fing ich an, die Zahl auszuschneiden,
umzukehren und mit
Pytesseract zu erkennen .
Um die verfügbaren Karten und ihre Position zu bestimmen, habe ich den
Schlüsselpunktdetektor KAZE von OpenCV verwendet . Bisher wollte ich nicht wieder zum Erlernen des neuronalen Netzwerks zurückkehren, und ich entschied mich für eine Methode, die schneller und einfacher war, obwohl sich am Ende herausstellte, dass sie für den Fall, dass Sie nach vielen Objekten suchen müssen, nur eine minimale Genauigkeit aufweist.
Beim Starten des Bots habe ich die Schlüsselpunkte für alle Kartenbilder gezählt (es gibt insgesamt mehrere Dutzend) und während des Spiels nach Übereinstimmungen aller Karten mit dem Kartenbereich des Spielers gesucht, um die Anzahl der Fehler zu verringern und die Geschwindigkeit zu erhöhen. Sie wurden nach Genauigkeit und nach der
x- Koordinate sortiert, um die Reihenfolge der Karten zu erhalten - Informationen darüber, wie sie sich auf dem Bildschirm befinden.
Nachdem ich ein wenig mit den Parametern gespielt hatte, bekam ich in der Praxis viele Fehler, obwohl einige komplexe Bilder von Karten, die manchmal vom Algorithmus mit anderen verwechselt wurden, mit großer Genauigkeit erkannt wurden. Ich musste einen Puffer aus drei Elementen hinzufügen: Wenn drei Erkennungen hintereinander dieselben Werte erhalten, glauben wir unter bestimmten Bedingungen, dass wir ihnen vertrauen können.

Nachdem Sie alle erforderlichen Informationen erhalten haben (Einheiten und ihre ungefähre Position, verfügbares Mana und Karten), können Sie einige Entscheidungen treffen.
Zunächst habe ich mich für etwas Einfaches entschieden: Wenn beispielsweise auf einer zugänglichen Karte genügend Mana vorhanden ist, spielen Sie es auf dem Spielfeld aus. Aber der Bot weiß immer noch nicht, wie man Karten „spielt“ - er weiß, welche Karten wir haben, wo sich das Feld befindet. Sie müssen auf die gewünschte Karte und dann auf die gewünschte Zelle im Feld klicken.
Wenn Sie die Auflösung des Screenshots kennen, können Sie die Koordinaten der Karte und der gewünschten Feldzelle verstehen. Jetzt habe ich mich an die genaue Bildschirmauflösung gebunden, aber wenn nötig, kann ich dies ignorieren. Die Entscheidungsfunktion gibt eine Reihe von Abgriffen zurück, die in naher Zukunft ausgeführt werden müssen. Im Allgemeinen wird unser Bot eine Endlosschleife sein (vereinfacht):
: = : ( ) : = () = () = () += (, , , )
Bisher kann der Bot Einheiten nur an einem Punkt platzieren, verfügt jedoch bereits über genügend Informationen, um eine komplexere Strategie zu entwickeln.
Erste Probleme
In Wirklichkeit stieß ich auf ein unerwartetes und sehr unangenehmes Problem. Das Erstellen eines Screenshots über ADB dauert ungefähr 100 ms, was zu einer erheblichen Verzögerung führt. Ich habe mit einer solchen maximalen Verzögerung gerechnet, wobei alle Berechnungen und die Auswahl der Aktion berücksichtigt wurden, jedoch nicht in einem Schritt zum Erstellen eines Screenshots. Eine einfache und schnelle Lösung konnte nicht gefunden werden. Theoretisch können Sie mit dem Android-Emulator Screenshots direkt aus dem Anwendungsfenster machen oder ein Dienstprogramm zum Streamen von Bildern von einem Telefon mit Komprimierung über UDP erstellen und den Bot damit verbinden, aber ich habe hier auch keine schnellen Lösungen gefunden.
Also
Nachdem ich den Stand meines Projekts nüchtern eingeschätzt hatte, beschloss ich, mich vorerst mit diesem Modell zu befassen. Ich habe mehrere Wochen meiner Freizeit damit verbracht, und die Erkennung von Einheiten ist nur ein Teil des Gameplays.
Ich beschloss, die Teile des Bots schrittweise zu entwickeln - um die grundlegende Logik der Wahrnehmung, dann die einfache Logik des Spiels und die Interaktion mit dem Spiel zu erstellen, und dann wird es möglich sein, die einzelnen abklingenden Teile des Bots zu verbessern. Wenn die Stufe des Einheitenerkennungsmodells ausreichend wird, kann das Hinzufügen von Informationen über HP und die Stufe der Einheiten die Entwicklung des Spielbot zu einer völlig neuen Stufe führen. Vielleicht ist dies das nächste Ziel, aber im Moment lohnt es sich definitiv nicht, sich auf diese Aufgabe zu konzentrieren.
Github-Projekt-RepositoryIch habe viel Zeit mit dem Projekt verbracht und ehrlich gesagt bin ich es leid, aber ich bereue es nicht ein bisschen - ich habe neue Erfahrungen in ML / CV gesammelt.
Vielleicht werde ich später zu ihm zurückkehren - ich werde froh sein, wenn sich mir jemand anschließt. Wenn Sie interessiert sind, schließen Sie sich der Gruppe für
Telegramm an und besuchen Sie auch meinen
Scala-Kurs .