Dieser Artikel ist eine Abschrift des Videoberichts von Alexei Vakhov von Uchi.ru „Wolken in den Wolken“.
Uchi.ru ist eine Online-Plattform für die Schulbildung, mehr als 2 Millionen Schüler, interaktive Klassen entscheiden regelmäßig mit uns. Alle unsere Projekte werden vollständig in öffentlichen Clouds gehostet. 100% der Anwendungen arbeiten in Containern, angefangen bei den kleinsten für den internen Gebrauch bis hin zu großen Produktionen mit mehr als 1.000 Anfragen pro Sekunde. So kam es, dass wir 15 isolierte Docker-Cluster (nicht Kubernetes, sic!) In fünf Cloud-Anbietern haben. Eintausendfünfhundert Benutzeranwendungen, deren Anzahl ständig wächst.
Ich werde über ganz bestimmte Dinge sprechen: wie wir auf Container umgestiegen sind, wie wir die Infrastruktur verwalten, auf welche Probleme wir gestoßen sind, was funktioniert hat und was nicht.
Während des Berichts werden wir diskutieren:
- Motivation für Technologieauswahl und Geschäftsmerkmale
- Tools: Ansible, Terraform, Docker, Github Flow, Konsul, Nomad, Prometheus, Schamane - eine Weboberfläche für Nomad.
- Verwenden der Cluster-Föderation zum Verwalten der verteilten Infrastruktur
- NoOps-Rollouts, Testumgebungen, Anwendungsschaltungen (Entwickler nehmen ihre eigenen Änderungen praktisch selbst vor)
- Unterhaltsame Geschichten aus der Praxis
Wen kümmert es bitte unter der Katze.
Ich heiße Alexey Vakhov. Ich arbeite als technischer Direktor bei Uchi.ru. Wir hosten in öffentlichen Wolken. Wir nutzen Terraform, Ansible aktiv. Seitdem sind wir komplett auf Docker umgestiegen. Sehr zufrieden. Wie glücklich, wie glücklich wir sind - ich werde es sagen.

Die Firma Uchi.ru produziert Produkte für die Schulbildung. Wir haben eine Hauptplattform, auf der Kinder interaktive Probleme in verschiedenen Fächern in Russland, Brasilien und den USA lösen. Wir führen Online-Olympiaden, Wettbewerbe, Vereine und Camps durch. Jedes Jahr wächst diese Aktivität.

Aus technischer Sicht der klassische Webstack (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). Das Hauptmerkmal ist, dass viele Anwendungen. Anwendungen werden weltweit gehostet. Jeden Tag gibt es Rollouts in der Produktion.
Das zweite Merkmal ist, dass sich unsere Systeme sehr oft ändern. Sie bitten darum, eine neue Anwendung zu erstellen, die alte zu stoppen und Cron für Hintergrundjobs hinzuzufügen. Alle 2 Wochen gibt es eine neue Olympiade - dies ist eine neue Anwendung. Es ist alles notwendig, um zu begleiten, zu überwachen, zu sichern. Daher ist die Umgebung superdynamisch. Dynamik ist unsere Hauptschwierigkeit.
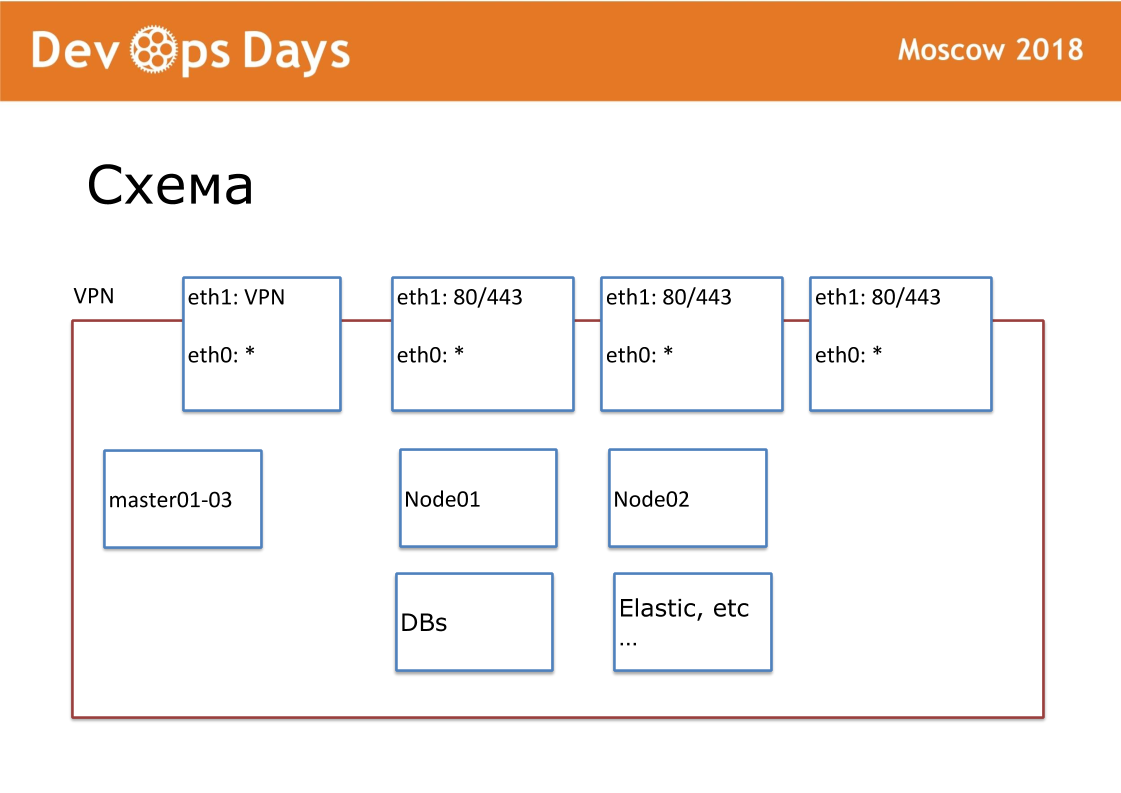
Unsere Arbeitseinheit ist der Standort. In Bezug auf Cloud-Anbieter ist dies Project. Unsere Site ist eine vollständig isolierte Einheit mit einer API und einem privaten Subnetz. Bei der Einreise suchen wir nach lokalen Cloud-Anbietern. Nicht überall gibt es Google und Amazon. Manchmal gibt es keine API für den Cloud-Anbieter. Äußerlich veröffentlichen wir VPN und HTTP, HTTPS für Balancer. Alle anderen Dienste kommunizieren innerhalb der Cloud.

Für jede Site haben wir ein eigenes Ansible-Repository erstellt. Das Repository enthält hosts.yml, ein Playbook, Rollen und 3 geheime Ordner, über die ich später sprechen werde. Dies ist Terraform, Bereitstellung, Routing. Wir sind Fans der Standardisierung. Unser Repository sollte immer als "Ansible-Name der Site" bezeichnet werden. Wir standardisieren jeden Dateinamen und jede interne Struktur. Dies ist sehr wichtig für die weitere Automatisierung.

Wir haben Terraform vor anderthalb Jahren gegründet und verwenden es daher. Terraform ohne Module, ohne Dateistruktur (flache Struktur wird verwendet). Terraform-Dateistruktur: 1 Server - 1 Datei, Netzwerkeinstellungen und andere Einstellungen. Mit terraform beschreiben wir Server, Laufwerke, Domänen, s3-Buckets, Netzwerke usw. Terraform vor Ort bereitet das Eisen vollständig vor.

Terraform erstellt den Server, dann rollt das Ensemble diese Server. Aufgrund der Tatsache, dass wir überall dieselbe Version des Betriebssystems verwenden, haben wir alle Rollen von Grund auf neu geschrieben. Ansible Rollen werden normalerweise im Internet für alle Betriebssysteme veröffentlicht, die nirgendwo funktionieren. Wir haben alle Ansible-Rollen übernommen und nur das gelassen, was wir brauchten. Standardisierte Ansible-Rollen. Wir haben 6 grundlegende Spielbücher. Beim Start installiert Ansible eine Standardliste von Software: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes verwenden wir nicht.

Wir verwenden Consul + Nomad. Dies sind sehr einfache Programme. Führen Sie auf jedem Server 2 in Golang geschriebene Programme aus. Consul ist für die Serviceerkennung, die Integritätsprüfung und den Schlüsselwert zum Speichern der Konfiguration verantwortlich. Nomad ist für die Planung und den Rollout verantwortlich. Nomad startet Container, bietet Rollouts, einschließlich Rolling-Updates zur Integritätsprüfung, und ermöglicht das Ausführen von Beiwagencontainern. Der Cluster lässt sich leicht erweitern oder umgekehrt reduzieren. Nomad unterstützt verteilte Cron.
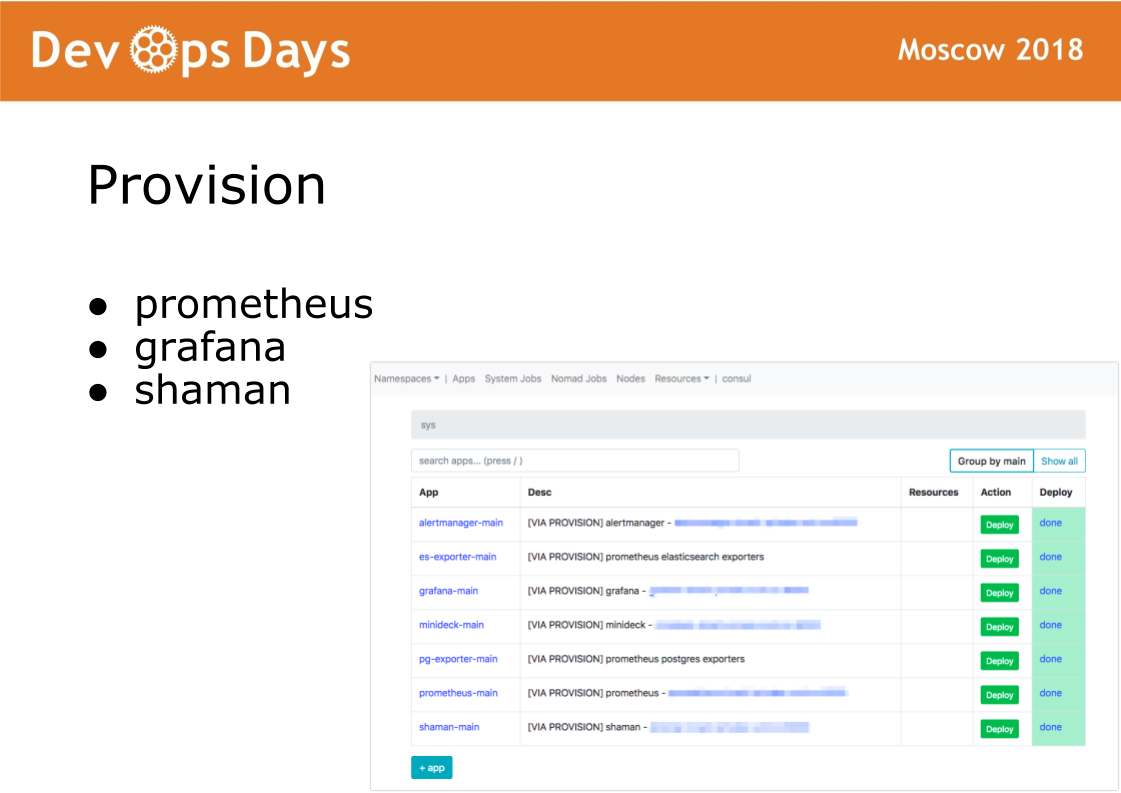
Nachdem wir die Site betreten haben, führt Ansible das Playbook aus, das sich im Bereitstellungsverzeichnis befindet. Das Playbook in diesem Verzeichnis ist für die Installation der Software im Docker-Cluster verantwortlich, die Administratoren verwenden. Installieren Sie Prometheus, Grafana und geheime Schamanen-Software.
Shaman ist ein Web-Dashboard für Nomaden. Nomad ist auf niedrigem Niveau und ich möchte Entwickler nicht wirklich darin lassen. In Schamanen sehen wir eine Liste von Anwendungen, wir geben Entwicklern eine Bereitstellungsschaltfläche für Anwendungen. Entwickler können Konfigurationen ändern: Container hinzufügen, Umgebungsvariablen, Dienste starten.
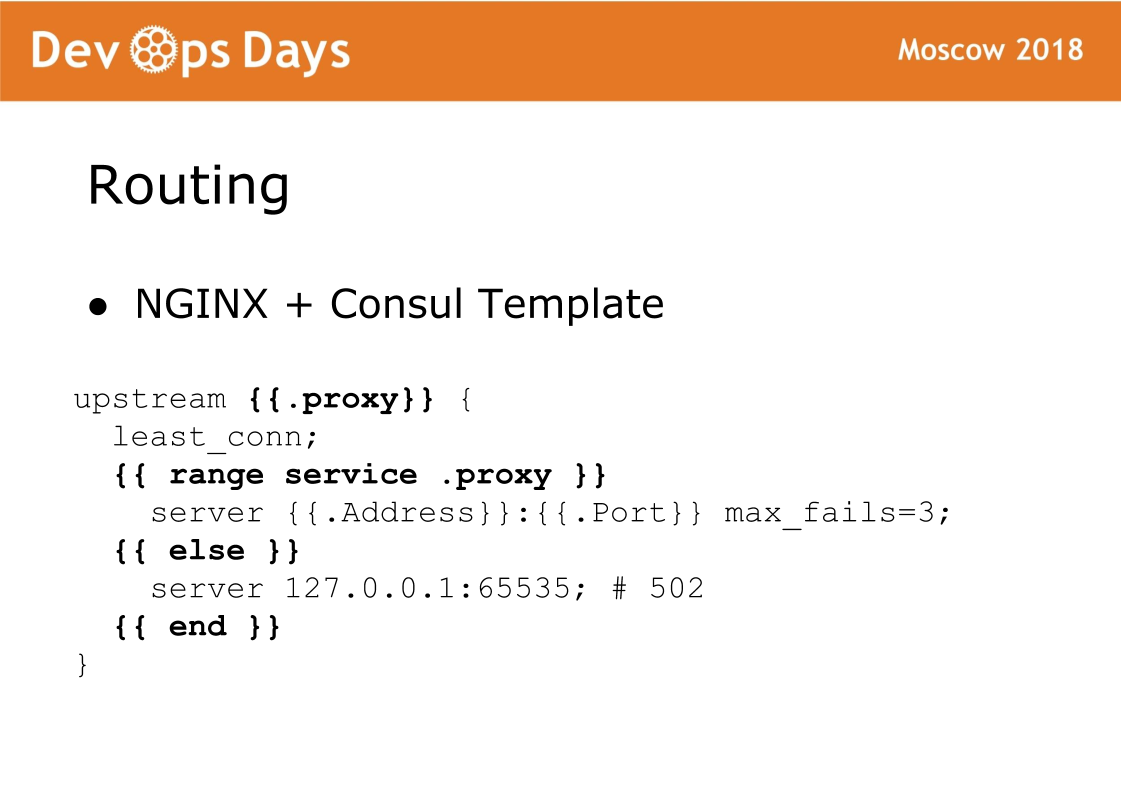
Und schließlich ist die letzte Komponente der Site das Routing. Das Routing wird im K / V-Speicher des Konsuls gespeichert, dh es besteht eine Verbindung zwischen Upstream, Service, URL usw. Auf jedem Balancer gibt es eine Consul-Vorlage, die eine Nginx-Konfiguration generiert und neu lädt. Eine sehr zuverlässige Sache, wir hatten nie ein Problem damit. Das Merkmal dieses Schemas ist, dass der Datenverkehr Standard-Nginx akzeptiert und Sie immer sehen können, welche Konfiguration generiert wurde und wie mit Standard-Nginx funktioniert.

Somit besteht jede Stelle aus 5 Schichten. Mit Terraform passen wir die Hardware an. Ansible führen wir die Grundkonfiguration der Server durch, setzen den Docker-Cluster. Provision rollt Systemsoftware zusammen. Das Routing leitet den Verkehr innerhalb der Site. Anwendungen enthält Benutzeranwendungen und Administratoranwendungen.
Wir haben diese Ebenen lange getestet, damit sie so identisch wie möglich sind. Bereitstellung, Routing stimmen zu 100% zwischen Standorten überein. Daher ist für Entwickler jede Site absolut gleich.
Wenn IT-Experten von Projekt zu Projekt wechseln, fallen sie in eine völlig typische Umgebung. In ansible konnten wir die Firewall- und VPN-Einstellungen für verschiedene Cloud-Anbieter nicht identisch machen. Mit einem Netzwerk arbeiten alle Cloud-Anbieter unterschiedlich. Terraform ist überall seine eigene, da es spezifische Designs für jeden Cloud-Anbieter enthält.
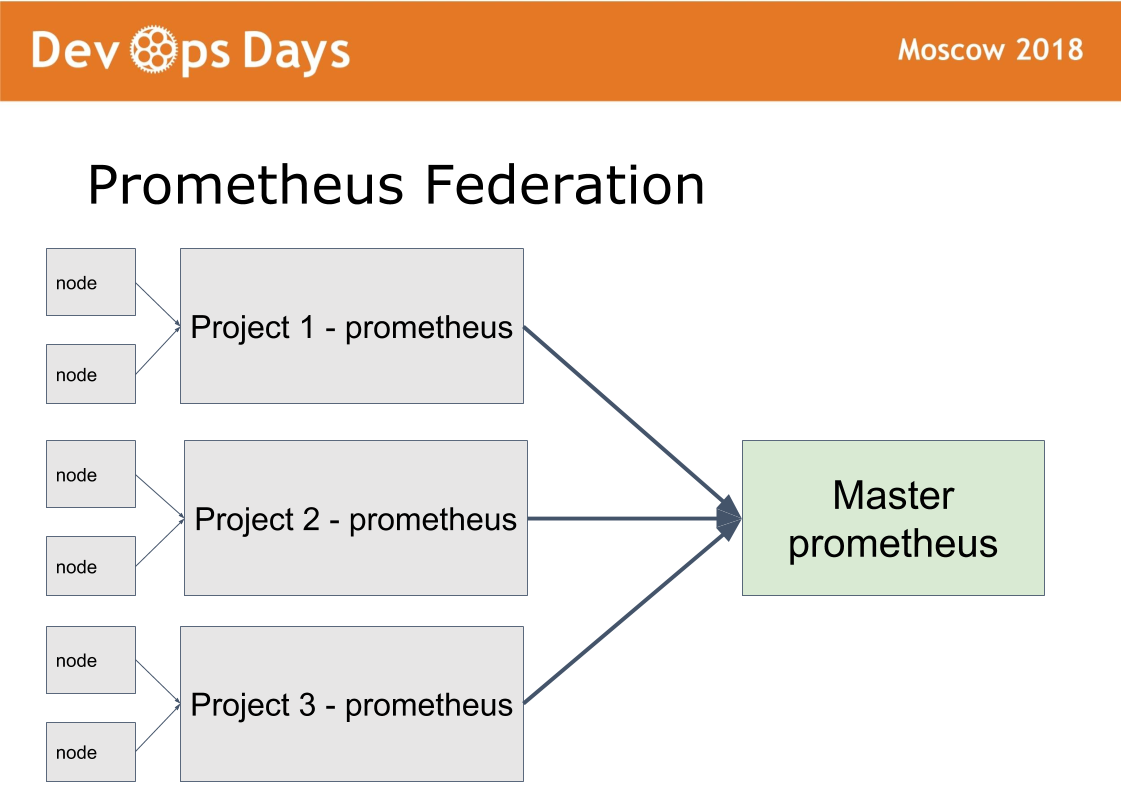
Wir haben 14 Produktionsstätten. Es stellt sich die Frage: Wie geht man damit um? Wir haben die 15. Master-Site erstellt, in der nur Administratoren zugelassen sind. Sie arbeitet an einem Föderationsschema.
Die Idee wurde von Prometheus übernommen. Es gibt einen Modus in Prometheus, wenn wir Prometheus auf jeder Site installieren. Wir veröffentlichen Prometheus über die HTTPS-Basisauthentifizierungsautorisierung. Prometheus-Meister übernimmt nur die erforderlichen Metriken von Remote-Prometheus. Auf diese Weise können Sie Anwendungsmetriken in verschiedenen Clouds vergleichen und die am häufigsten heruntergeladenen oder entladenen Anwendungen finden. Die zentralisierte Benachrichtigung (Alarmierung) durchläuft den Prometheus-Master für Administratoren. Entwickler erhalten Benachrichtigungen von lokalen Prometheus.

Der Schamane ist auf die gleiche Weise konfiguriert. Über den Hauptstandort können Administratoren über eine einzige Schnittstelle auf jedem Standort bereitstellen und konfigurieren. Wir lösen eine ausreichend große Klasse von Problemen, ohne diese Master-Site zu verlassen.

Ich werde Ihnen sagen, wie wir zu Docker gewechselt sind. Dieser Prozess ist sehr langsam. Wir haben ungefähr 10 Monate gekreuzt. Im Sommer 2017 hatten wir 0 Produktionsbehälter. Im April 2018 haben wir unsere neueste Anwendung angedockt und in die Produktion eingeführt.

Wir sind aus der Welt des Rubins auf Schienen. Früher gab es 99% der Ruby on Rails-Anwendungen. Schienen rollen durch Capistrano. Technisch gesehen funktioniert Capistrano wie folgt: Der Entwickler startet Cap Deploy, Capistrano geht über ssh zu allen Anwendungsservern, nimmt die neueste Version des Codes, sammelt Assets und Datenbankmigrationen. Capistrano stellt einen Symlink zur neuen Version des Codes her und sendet ein USR2-Signal an die Webanwendung. Bei diesem Signal nimmt der Webserver neuen Code auf.
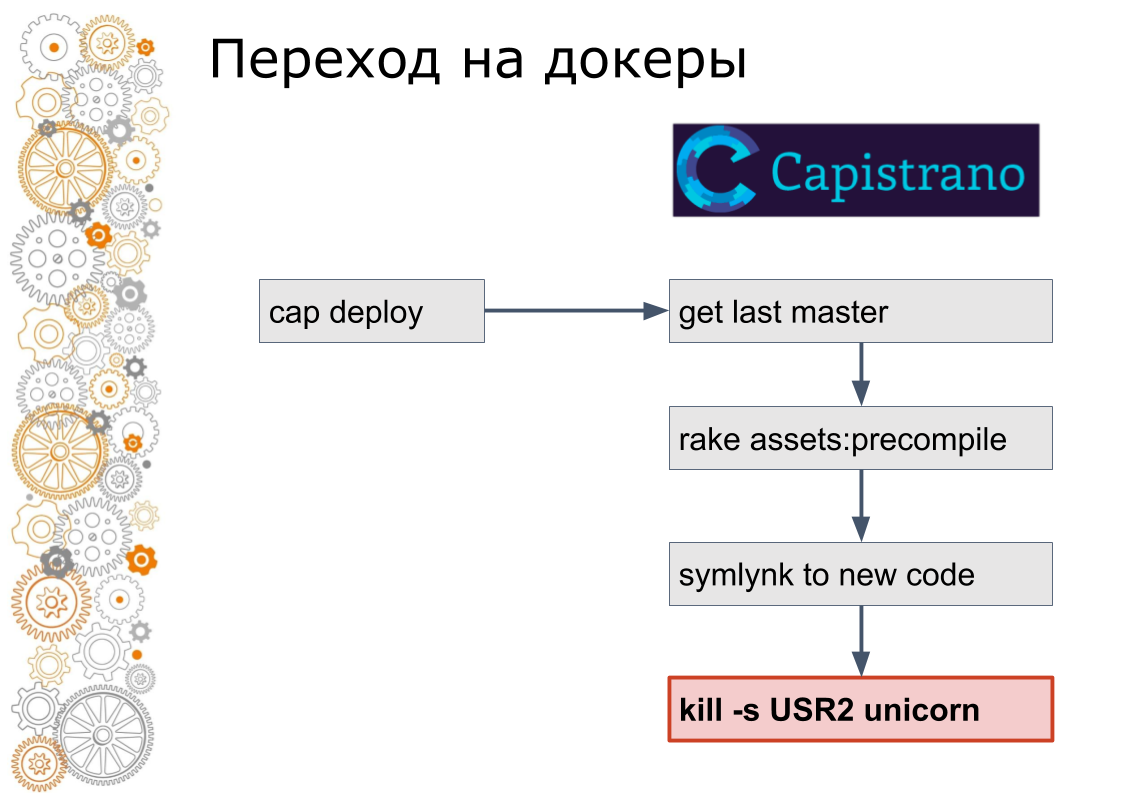
Der letzte Schritt im Docker wird nicht so gemacht. Im Docker müssen Sie den alten Container stoppen und den neuen Container anheben. Dies wirft die Frage auf: Wie wird der Verkehr gewechselt? In der Cloud-Welt ist die Serviceerkennung dafür verantwortlich.

Aus diesem Grund haben wir jedem Standort einen Konsul hinzugefügt. Konsul wurde hinzugefügt, weil sie Terraform verwendeten. Wir haben alle Nginx-Konfigurationen in eine Konsul-Vorlage eingewickelt. Formal das Gleiche, aber wir waren bereits bereit, den Verkehr innerhalb der Websites dynamisch zu verwalten.

Als nächstes schrieben wir ein Ruby-Skript, das ein Bild auf einem der Server sammelte, es in die Registrierung schob, dann per SSH zu jedem Server ging, neue aufnahm und die alten Container stoppte und sie beim Konsul registrierte. Die Entwickler führten auch weiterhin Cap Deploy aus, aber die Dienste wurden bereits im Docker ausgeführt.
Ich erinnere mich, dass es zwei Versionen des Skripts gab, die zweite erwies sich als ziemlich fortgeschritten, es gab ein fortlaufendes Update, als eine kleine Anzahl von Containern anhielt, neue auftauchten, der Konsul Helfcheki wartete und weiterging.

Dann erkannten sie, dass dies eine Sackgasse ist. Das Skript wurde auf 600 Zeilen erhöht. Im nächsten Schritt der manuellen Planung haben wir Nomad ersetzt. Versteckt die Details der Arbeit vor dem Entwickler. Das heißt, sie nannten Cap Deploy immer noch, aber im Inneren befand sich bereits eine völlig andere Technologie.
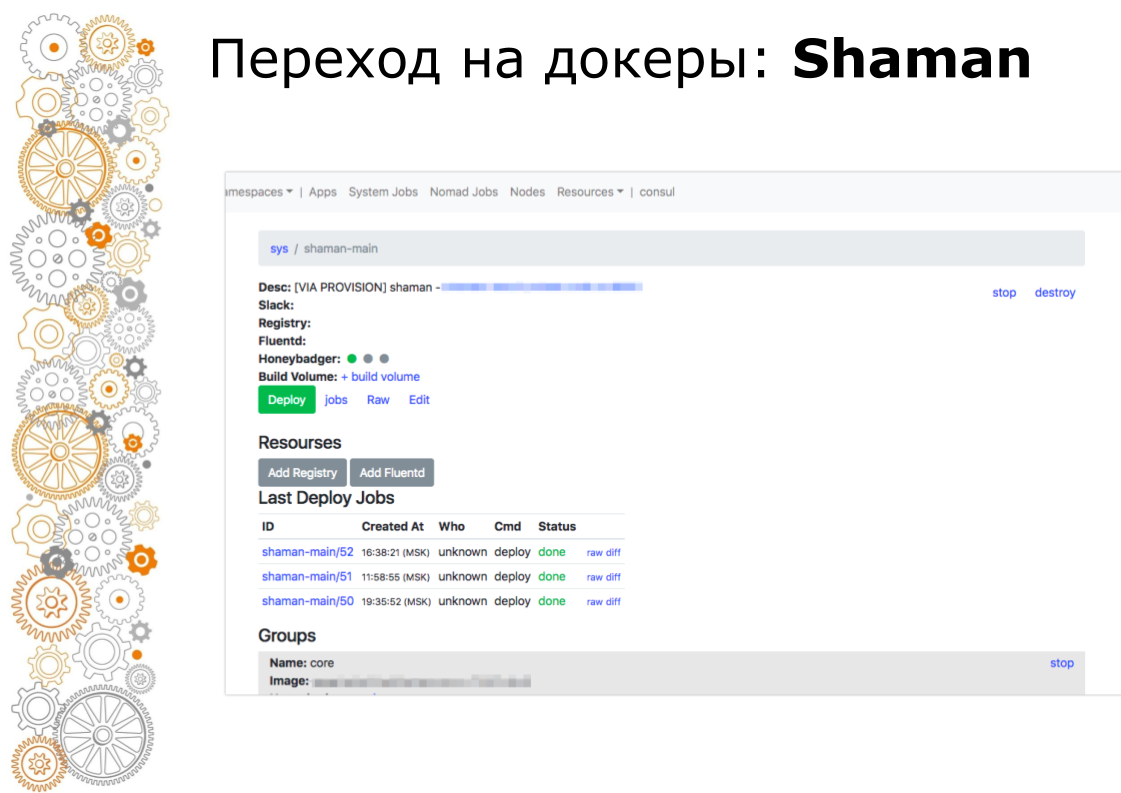
Am Ende haben wir die Bereitstellung auf die Benutzeroberfläche verschoben und den Zugriff auf den Server entfernt, wobei die grüne Schaltfläche für die Bereitstellung und die Steuerungsoberfläche erhalten blieben.
Im Prinzip stellte sich ein solcher Übergang natürlich als lang heraus, aber wir haben das Problem vermieden, das ich einige Male getroffen habe.
Es gibt eine Art Legacy-Stack, System oder ähnliches. Khachennaya schon gerade in Klappen. Die Entwicklung einer neuen Version beginnt. Nach ein paar Monaten oder ein paar Jahren, abhängig von der Größe des Unternehmens, ist in der neuen Version weniger als die Hälfte der erforderlichen Funktionen implementiert, und die alte Version ist immer noch entkommen. Und dieses neue wurde auch sehr Vermächtnis. Und es ist Zeit, eine neue, dritte Version von Grund auf neu zu starten. Im Allgemeinen ist dies ein endloser Prozess.
Daher verschieben wir immer den gesamten Stapel als Ganzes. In kleinen Schritten schief, mit Krücken, aber ganz. Wir können beispielsweise keine Docker-Engine an einem Standort aktualisieren. Es ist notwendig, überall zu aktualisieren, wenn es einen Wunsch gibt.

Roll-outs. Alle Docker-Anweisungen rollen 10 Nginx-Container oder 10 Redis-Container in Docker aus. Dies ist ein schlechtes Beispiel, da die Bilder bereits zusammengestellt sind und die Bilder hell sind. Wir haben unsere Schienenanwendungen in Docker verpackt. Die Größe der Docker-Images betrug 2-3 Gigabyte. Sie werden nicht so schnell herausspringen.
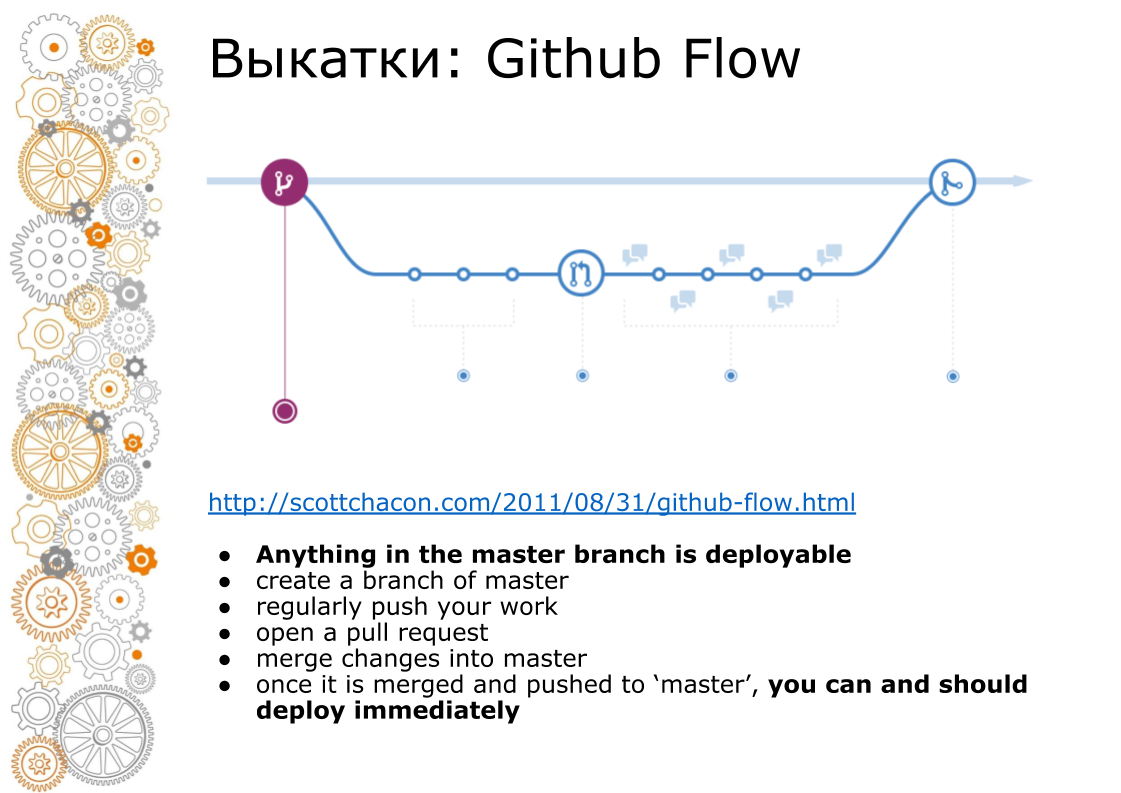
Das zweite Problem kam aus dem Hipster-Web. Ein Hipster-Web ist immer Github Flow. Im Jahr 2011 gab es einen epochalen Beitrag, den Github Flow steuert, sodass die gesamte Bahn rollt. Wie sieht es aus? Master Branch ist immer Produktion. Beim Hinzufügen neuer Funktionen erstellen wir eine Verzweigung. Bei der Fusion führen wir eine Codeüberprüfung durch, führen Tests durch und erhöhen die Staging-Umgebung. Business suchende Inszenierungsumgebung. Wenn zum Zeitpunkt X alles erfolgreich ist, führen wir die Niederlassung in Master zusammen und rollen sie in die Produktion aus.
Auf Capistrano hat das gut funktioniert, weil es dafür geschaffen wurde. Docker verkauft uns immer eine Pipeline. Den Behälter zusammengebaut. Der Behälter kann an den Entwickler, Tester, übergeben und an die Produktion übergeben werden. Zum Zeitpunkt der Zusammenführung im Master ist der Code jedoch bereits anders. Alle Docker-Bilder, die aus dem Feature-Zweig erfasst wurden, wurden nicht vom Master erfasst.

Wie haben wir das gemacht? Wir sammeln das Bild und legen es in der lokalen Docker-Registrierung ab. Danach erledigen wir den Rest der Vorgänge: Migration, Bereitstellung in der Produktion.

Um dieses Bild schnell zusammenzusetzen, verwenden wir Docker-in-Docker. Im Internet schreibt jeder, dass dies ein Anti-Muster ist, es stürzt ab. Wir hatten nichts dergleichen. Wie viele schon mit ihm arbeiten, hatte nie ein Problem. Wir leiten das Verzeichnis / var / lib / docker unter Verwendung des persistenten Volumes an den Hauptserver weiter. Alle Zwischenabbilder befinden sich auf dem Primärserver. Das Zusammenstellen eines neuen Bildes dauert nur wenige Minuten.

Für jede Anwendung erstellen wir eine lokale interne Docker-Registrierung und unser Build-Volume. Weil Docker alle Ebenen auf der Festplatte speichert und schwer zu reinigen ist. Jetzt kennen wir die Festplattenauslastung jeder lokalen Docker-Registrierung. Wir wissen, wie viel Festplatte benötigt wird. Sie können Benachrichtigungen über zentralisierte Grafana erhalten und bereinigen. Während wir ihre Hände reinigen. Aber wir werden es automatisieren.

Ein weiterer Punkt. Docker-Bild gesammelt. Jetzt muss dieses Image in Server zerlegt werden. Beim Kopieren eines großen Docker-Images kommt das Netzwerk nicht zurecht. In der Cloud haben wir 1 Gbit / s. In der Cloud wird global heruntergefahren. Jetzt stellen wir ein Docker-Image auf 4 schweren Produktionsservern bereit. In der Grafik sehen Sie, wie die Festplatte auf einem Serverpaket funktioniert. Dann wird das zweite Serverpaket bereitgestellt. Unten sehen Sie die Auslastung des Kanals. Über 1 Gbit / s ziehen wir fast. Dort gibt es nicht mehr viel Beschleunigung.

Meine Lieblingsproduktion ist Südafrika. Es gibt sehr teures und langsames Eisen. Viermal teurer als in Russland. Es gibt sehr schlechtes Internet. Internet auf Modem-Ebene, aber nicht fehlerhaft. Dort rollen wir Anwendungen in 40 Minuten aus, wobei die Optimierung der Caches und die Timeout-Parameter berücksichtigt werden.

Das letzte Problem, das mich beunruhigte, bevor Docker Kontakt aufnahm, war die Ladung. In der Tat ist die Ladung die gleiche wie ohne Docker mit identischem Eisen. Die einzige Nuance, auf die wir nur einen Punkt stießen. Wenn Sie Protokolle von der Docker-Engine über den integrierten Fluentd-Treiber sammeln, wird bei einer Last von etwa 1000 U / s der interne Fluentd-Puffer verschmutzt und die Anforderungen werden langsamer. Wir haben uns in Beiwagencontainern angemeldet. In Nomaden wird dies als Log-Shipper bezeichnet. Ein kleiner Container hängt neben einem großen Anwendungscontainer. Die einzige Aufgabe besteht darin, es aufzunehmen und an ein zentrales Repository zu senden.

Was waren die Probleme / Lösungen / Herausforderungen. Ich habe versucht zu analysieren, was die Aufgabe war. Merkmale unserer Probleme sind:
- viele unabhängige Anwendungen
- kontinuierliche Veränderungen in der Infrastruktur
- Github Flow und große Docker-Bilder

Unsere Lösungen
- Föderation von Docker-Clustern. Aus Sicht der Handhabung ist es schwierig. Docker ist jedoch gut darin, Geschäftsfunktionen in der Produktion einzuführen. Wir arbeiten mit personenbezogenen Daten und sind in jedem Land zertifiziert. An einem isolierten Standort ist eine solche Zertifizierung leicht zu bestehen. Während der Zertifizierung stellen sich alle Fragen: Wo hosten Sie, wie haben Sie einen Cloud-Anbieter, wo speichern Sie personenbezogene Daten, wo sichern Sie, wer hat Zugriff auf die Daten. Wenn alles isoliert ist, ist es viel einfacher, den Kreis der Verdächtigen zu beschreiben und all dies zu überwachen.
- Orchestrierung. Es ist klar, dass Kubernetes. Er ist überall. Aber ich möchte sagen, dass Consul + Nomad eine vollständig produktive Lösung ist.
- Zusammenstellung von Bildern. Sie können Bilder schnell in Docker-in-Docker erstellen.
- Bei Verwendung von Docker ist es auch möglich, eine Last von 1000 U / s zu halten.
Entwicklungsrichtungsvektor
Eines der großen Probleme ist nun die Unsynchronisation der Softwareversionen auf den Websites. Zuvor haben wir den Server von Hand eingerichtet. Dann wurden wir Entwickleringenieure. Konfigurieren Sie nun den Server mit ansible. Jetzt haben wir völlige Vereinheitlichung, Standardisierung. Wir führen gewöhnliches Denken in den Kopf ein. Wir können PostgreSQL nicht mit unseren Händen auf dem Server reparieren. Wenn Sie eine Feinabstimmung auf nur einem Server benötigen, überlegen wir, wie Sie diese Einstellung überall verbreiten können. Wenn Sie nicht standardisieren, gibt es einen Zoo mit Einstellungen.
Ich freue mich und bin sehr froh, dass wir kostenlos eine wirklich, wirklich gut funktionierende Infrastruktur haben.

Sie können mich auf Facebook hinzufügen. Wenn wir etwas Gutes tun, werde ich darüber schreiben.
Fragen:
Was ist der Vorteil der Consul-Vorlage gegenüber der Ansible-Vorlage, um beispielsweise Firewall-Regeln und mehr zu konfigurieren?
Antwort: Jetzt haben wir Datenverkehr von externen Balancern, die direkt zu Containern geleitet werden. Dazwischen ist niemand. Dort wird eine Konfiguration gebildet, die die IP-Adressen und Ports des Clusters weiterleitet. Außerdem haben wir alle Balance-Einstellungen in K / V in Consul. Wir haben die Idee, Entwicklern Routing-Einstellungen über eine sichere Schnittstelle zu geben, damit sie nichts kaputt machen.
Frage: In Bezug auf die Homogenität aller Standorte. Gibt es wirklich keine Anfragen von Unternehmen oder Entwicklern, dass Sie auf dieser Website etwas Ungewöhnliches einführen müssen? Zum Beispiel Tarantool mit Cassandra.
Antwort: Es passiert, aber es ist sehr selten. Hiermit erstellen wir ein internes separates Artefakt. Es gibt ein solches Problem, aber es ist selten.
Frage: Die Lösung für das Übermittlungsproblem besteht darin, an jedem Standort eine private Docker-Registrierung zu verwenden. Von dort aus können Docker-Images bereits schnell abgerufen werden.
Antwort: Auf jeden Fall wird die Bereitstellung im Netzwerk ausgeführt, da wir das Docker-Image dort gleichzeitig auf 15 Servern bereitstellen. Wir ruhen uns gegen das Netzwerk aus. Innerhalb des Netzwerks 1 Gbit / s.
Frage: So viele Docker-Container basieren auf ungefähr demselben Technologie-Stack?
Antwort: Ruby, Python, NodeJS.
Frage: Wie oft testen oder überprüfen Sie Ihre Docker-Images auf Updates? Wie lösen Sie Update-Probleme, zum Beispiel wenn glibc, openssl in allen Docker behoben werden muss?
Antwort: Wenn Sie einen solchen Fehler oder eine solche Sicherheitslücke finden, setzen wir uns für eine Woche hin und reparieren ihn. Wenn Sie ein Rollout durchführen müssen, können wir die gesamte Cloud (alle Anwendungen) von Grund auf über den Verbund ausrollen. Wir können auf alle grünen Schaltflächen klicken, um Anwendungen bereitzustellen, und Tee trinken lassen.
Frage: Wirst du deinen Schamanen in Open Source freigeben?
Antwort: Hier verspricht uns Andrei (zeigt auf die Person aus dem Publikum), im Herbst einen Schamanen auszulegen. Dort müssen Sie jedoch Unterstützung für Kubernetes hinzufügen. OpenSource sollte immer besser sein.