
Skandalöse, wichtige und einfach sehr coole Materialien werden nicht jeden Tag in den Medien veröffentlicht, und kein Herausgeber wird sich verpflichten, den Erfolg eines Artikels mit 100% iger Genauigkeit vorherzusagen. Das Maximum, das das Team hat, liegt auf der Ebene des Instinkts, „starkes“ Material oder „gewöhnlich“ zu sagen. Das ist alles. Dann beginnt die unvorhersehbare Magie der Medien, dank derer der Artikel mit Dutzenden von Links aus anderen Veröffentlichungen an die Spitze der Suchergebnisse gelangen kann oder das Material in Vergessenheit gerät. Und gerade bei der Veröffentlichung cooler Artikel fallen Medienseiten regelmäßig unter einen ungeheuren Zustrom von Nutzern, den wir bescheiden als „Habraeffekt“ bezeichnen.
In diesem Sommer wurde die Website der
Republik Opfer der Professionalität ihrer eigenen Autoren: Artikel zum Thema Rentenreform, Schulbildung und richtige Ernährung zogen insgesamt ein Publikum von mehreren Millionen Lesern an. Die Veröffentlichung jedes der genannten Materialien führte zu einer derart hohen Belastung, dass bis zum Fall der Website der Republik absolut „ein wenig Platz“ übrig blieb. Die Verwaltung erkannte, dass etwas geändert werden musste: Es war notwendig, die Struktur des Projekts so zu ändern, dass es energisch auf Änderungen der Arbeitsbedingungen (hauptsächlich externe Belastung) reagieren konnte, während es auch in Zeiten sehr starker Anwesenheitssprünge voll funktionsfähig und für die Leser zugänglich blieb. Und ein großer Bonus wäre der minimale manuelle Eingriff des technischen Teams der Republik in solchen Zeiten.
Basierend auf den Ergebnissen einer gemeinsamen Diskussion mit Spezialisten der Republik über verschiedene Optionen zur Implementierung der stimmhaften Wunschliste haben wir beschlossen, die Website der Veröffentlichung auf Kubernetes * zu übertragen. Über das, was uns das alles gekostet hat und was unsere heutige Geschichte sein wird.
* Während des Umzugs wurde kein einziger republikanischer technischer Spezialist verletztWie es allgemein aussah
Alles begann natürlich mit Verhandlungen darüber, wie „jetzt“ und „später“ alles passieren wird. Leider impliziert das moderne Paradigma auf dem IT-Markt, dass ein Unternehmen, sobald es sich für eine Infrastrukturlösung zur Seite stellt, diese auf eine schlüsselfertige Service-Preisliste setzt. Es scheint, dass die Arbeit „schlüsselfertig“ ist - was könnte schöner und schöner sein als ein bedingter Direktor oder Geschäftsinhaber? Ich habe bezahlt und mein Kopf tut nicht weh: Planung, Entwicklung, Support - alles ist da, auf der Seite des Auftragnehmers kann das Unternehmen nur Geld verdienen, um für einen so angenehmen Service zu bezahlen.
Der vollständige Transfer der IT-Infrastruktur ist für den Kunden jedoch langfristig nicht immer angemessen. Unter allen Gesichtspunkten ist es korrekter, als ein großes Team zu arbeiten, sodass der Kunde nach Abschluss des Projekts versteht, wie er mit der neuen Infrastruktur weiter leben kann, und die Kollegen in der Werkstatt nicht die Frage haben: "Oh, aber was haben Sie hier getan?" nach Unterzeichnung des Abschlusszertifikats und Nachweis der Ergebnisse. Die Republikaner waren der gleichen Meinung. Infolgedessen landeten wir zwei Monate lang eine Landung von vier Personen für den Kunden, der nicht nur unsere Idee verwirklichte, sondern auch technisch ausgebildete Spezialisten auf republikanischer Seite für die weitere Arbeit und Existenz in der Realität von Kubernetes.
Davon profitierten alle Seiten: Wir haben die Arbeiten schnell abgeschlossen, unsere Spezialisten auf neue Erfolge vorbereitet und Republic als Kunden mit beratender Unterstützung durch unsere eigenen Ingenieure beauftragt. Die Publikation hingegen erhielt eine neue Infrastruktur, die an „Habraeffekte“ angepasst war, ein eigenes Personal von technischen Spezialisten und die Möglichkeit, bei Bedarf Hilfe zu suchen.
Wir bereiten einen Brückenkopf vor
"Zerstören - nicht bauen." Dieses Sprichwort gilt für alles. Die einfachste Lösung scheint natürlich die zuvor erwähnte Geiselnahme der Infrastruktur des Kunden zu sein und ihn, den Kunden, an sich selbst zu ketten oder das vorhandene Personal zu übertakten und die Anforderung, einen Guru für neue Technologien einzustellen. Wir gingen den dritten, heute nicht den beliebtesten Weg und begannen mit der Ausbildung von Ingenieuren der Republik.
Ungefähr zu Beginn sahen wir eine solche Lösung, um den Betrieb der Website sicherzustellen:
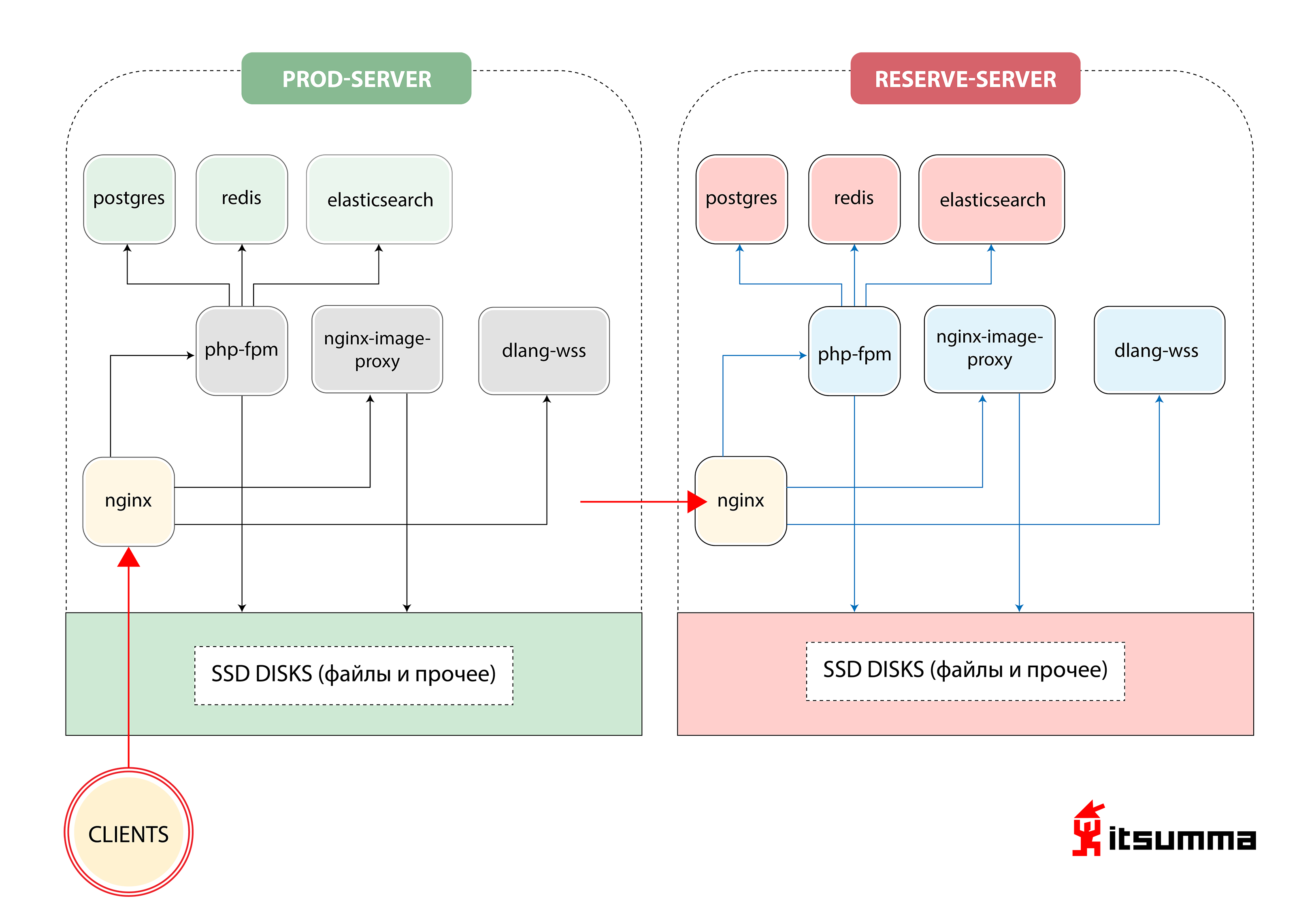
Das heißt, Republic hatte nur zwei Eisenserver - den Haupt- und den Backup-Backup. Das Wichtigste für uns war, einen Paradigmenwechsel im Denken der technischen Spezialisten des Kunden zu erreichen, da sie sich früher mit einer sehr einfachen Gruppe von NGINX, PHP-fpm und PostgreSQL befassten. Jetzt wurden sie mit der skalierbaren Containerarchitektur von Kubernetes konfrontiert. Also haben wir zuerst die lokale Entwicklung der Republik auf die Docker-Compose-Umgebung umgestellt. Und das war nur der erste Schritt.
Vor unserer Landung behielten die Entwickler der Republik ihre lokale Arbeitsumgebung in virtuellen Maschinen, die über Vagrant konfiguriert wurden, oder arbeiteten direkt mit dem Entwicklungsserver über SFTP zusammen. Basierend auf dem allgemeinen Grundbild einer virtuellen Maschine „konfigurierte“ jeder Entwickler seine Maschine „für sich selbst“, was zu einer ganzen Reihe unterschiedlicher Konfigurationen führte. Infolge dieses Ansatzes erhöhte sich die Aufnahme neuer Mitarbeiter in das Team exponentiell, sobald sie in das Projekt eintraten.
In den neuen Realitäten haben wir dem Team eine transparentere Struktur des Arbeitsumfelds angeboten. Es wurde deklarativ beschrieben, welche Software und welche Versionen für das Projekt benötigt werden, die Reihenfolge der Verbindungen und Interaktionen zwischen Diensten (Anwendungen). Diese Beschreibung wurde in ein separates Git-Repository hochgeladen, damit sie bequem zentral verwaltet werden kann.
Alle erforderlichen Anwendungen wurden in separaten Docker-Containern ausgeführt - und dies ist eine reguläre PHP-Site mit Nginx, vielen statischen Daten, Diensten für die Arbeit mit Bildern (Größenänderung, Optimierung usw.) und ... einem separaten Dienst für in D geschriebene Web-Sockets Alle Konfigurationsdateien (nginx-conf, php-conf ...) wurden ebenfalls Teil der Projektcodebasis.
Dementsprechend wurde die lokale Umgebung vollständig "neu erstellt", völlig identisch mit der aktuellen Serverinfrastruktur. Dadurch wurde der Zeitaufwand für die Wartung derselben Umgebung sowohl auf den lokalen Computern der Entwickler als auch auf dem Produkt reduziert. Dies trug wiederum wesentlich dazu bei, völlig unnötige Probleme zu vermeiden, die durch die selbstgeschriebenen lokalen Konfigurationen jedes Entwicklers verursacht wurden.
Infolgedessen wurden die folgenden Dienste in der Docker-Compose-Umgebung aufgerufen:
- Web für PHP-Fpm-Anwendung;
- Nginx;
- impproxy und cairosvg (Dienste für die Arbeit mit Bildern);
- postgres
- redis;
- elastische Suche;
- Trompete (der gleiche Dienst für Web-Sockets auf D).
Aus Sicht der Entwickler blieb die Arbeit mit der Codebasis unverändert - sie wurde in den erforderlichen Diensten aus einem separaten Verzeichnis (dem Basis-Repository mit dem Site-Code) in die erforderlichen Dienste eingebunden: das öffentliche Verzeichnis im Nginx-Dienst, der gesamte PHP-Anwendungscode im PHP-Fpm-Dienst. Aus dem separaten Verzeichnis (das alle Konfigurationen der Compose-Umgebung enthält) werden die entsprechenden Konfigurationsdateien in den Diensten nginx und php-fpm bereitgestellt. Verzeichnisse mit Datenpostgres, Elasticsearch und Redis werden ebenfalls auf dem lokalen Computer des Entwicklers bereitgestellt, sodass die Daten in diesen Diensten nicht verloren gehen, wenn alle Container neu erstellt / gelöscht werden müssen.
Um mit Anwendungsprotokollen zu arbeiten - auch in der Docker-Compose-Umgebung - wurden die Dienste des ELK-Stacks erhöht. Zuvor wurde ein Teil der Anwendungsprotokolle in Standard / var / log / ... geschrieben, PHP-Anwendungsprotokolle und Ausführungen wurden in Sentry geschrieben, und diese Option der „dezentralen“ Protokollspeicherung war äußerst unpraktisch. Jetzt wurden Anwendungen und Dienste für die Interaktion mit dem ELK-Stack konfiguriert und verfeinert. Die Verwendung von Protokollen ist viel einfacher geworden. Entwickler haben jetzt eine praktische Oberfläche zum Suchen und Filtern von Protokollen. In der Zukunft (bereits im Cube) - Sie können die Protokolle einer bestimmten Version der Anwendung anzeigen (z. B. eine Krone, die vorgestern gestartet wurde).
Ferner begann das republikanische Team eine kurze Anpassungsphase. Das Team musste verstehen und lernen, wie man in dem neuen Entwicklungsparadigma arbeitet, in dem Folgendes berücksichtigt werden sollte:
- Anwendungen werden zustandslos und können jederzeit Daten verlieren. Daher sollte die Arbeit mit Datenbanken, Sitzungen und statischen Dateien anders erstellt werden. PHP-Sitzungen sollten zentral gespeichert und von allen Anwendungsinstanzen gemeinsam genutzt werden. Es kann sich weiterhin um Dateien handeln, aber aufgrund der einfacheren Verwaltung werden Redis häufiger für diese Zwecke verwendet. Container für Datenbanken sollten entweder ein Datenverzeichnis "mounten" oder die Datenbank sollte außerhalb der Containerinfrastruktur ausgeführt werden.
- Ein Dateispeicher von ca. 50-60 GB Bildern sollte sich nicht "in der Webanwendung" befinden. Für solche Zwecke ist es notwendig, einige externe Speicher, CDN-Systeme usw. zu verwenden.
- Alle Anwendungen (Datenbanken, Anwendungsserver ...) sind jetzt separate "Dienste", und die Interaktion zwischen ihnen sollte relativ zum neuen Namespace konfiguriert werden.
Nachdem sich das Entwicklungsteam der Republik an die Innovationen gewöhnt hatte, begannen wir, die Vertriebsinfrastruktur der Publikation auf Kubernetes zu übertragen.
Und hier ist Kubernetes
Basierend auf der Docker-Compose-Umgebung für die lokale Entwicklung haben wir begonnen, das Projekt in einen "Cube" zu übersetzen. Alle Services, auf denen das Projekt lokal aufgebaut ist, haben wir "in Container gepackt": Wir haben ein lineares und verständliches Verfahren zum Erstellen von Anwendungen, Speichern von Konfigurationen und Kompilieren von Statiken organisiert. Aus entwicklungspolitischer Sicht entfernten sie die benötigten Konfigurationsparameter in Umgebungsvariablen und begannen, Sitzungen nicht in Dateien, sondern in Radieschen zu speichern. Wir haben die Testumgebung erhöht, in der wir eine funktionsfähige Version der Site bereitgestellt haben.
Da es sich um ein ehemaliges monolithisches Projekt handelt, besteht offensichtlich eine enge Beziehung zwischen der Frontend- und der Backend-Version, und diese beiden Komponenten wurden gleichzeitig bereitgestellt. Aus diesem Grund haben wir beschlossen, die Pods der Webanwendung so zu erstellen, dass sich zwei Container in einem Pod drehen: php-fpm und nginx.
Wir haben auch eine automatische Skalierung erstellt, sodass Webanwendungen, die zu Spitzenzeiten des Datenverkehrs auf maximal 12 skaliert werden, bestimmte Liveness / Readiness-Tests festlegen, da die Ausführung der Anwendung mindestens 2 Minuten dauert (da Sie den Cache aufwärmen und Konfigurationen generieren müssen ...).
Natürlich gab es sofort alle Arten von Schwärmen und Nuancen. Beispiel: Kompilierte Statik war sowohl für den Webserver, der sie verteilt hat, als auch für den Anwendungsserver auf fpm erforderlich, der irgendwo im laufenden Betrieb Bilder erzeugte, irgendwo, wo svg den Code direkt gab. Wir haben erkannt, dass wir, um nicht zweimal aufzustehen, einen Zwischencontainer erstellen und die Endmontage mehrstufig containerisieren müssen. Zu diesem Zweck haben wir mehrere Zwischencontainer erstellt, in denen die Abhängigkeiten jeweils separat abgerufen werden. Anschließend werden die Statiken (css und js) separat erfasst und anschließend in zwei Container - in nginx und in fpm - aus dem Zwischenerstellungscontainer kopiert.
Wir fangen an
Um in der ersten Iteration mit Dateien zu arbeiten, haben wir ein gemeinsames Verzeichnis erstellt, das mit allen Arbeitsmaschinen synchronisiert wurde. Mit dem Wort „synchronisiert“ meine ich hier genau das, was Sie sich mit Entsetzen vorstellen können - rsync in einem Kreis. Offensichtlich eine schlechte Entscheidung. Infolgedessen haben wir den gesamten Speicherplatz auf GlusterFS erhalten und die Arbeit mit Bildern so eingerichtet, dass sie immer von jedem Computer aus zugänglich sind und nichts langsamer wird. Für die Interaktion unserer Anwendungen mit Speichersystemen (postgres, elasticsearch, redis) wurden externalName-Dienste in k8s erstellt, sodass beispielsweise bei einem dringenden Wechsel zur Sicherungsdatenbank die Verbindungsparameter an einer Stelle aktualisiert werden.
Alle Arbeiten mit Crones wurden auf die neuen k8s-Entitäten übertragen - Cronjob, der nach einem bestimmten Zeitplan ausgeführt werden kann.
Als Ergebnis haben wir diese Architektur:
 Klickbar
KlickbarOh schwer
Dies war der Start der ersten Version, da parallel zur vollständigen Umstrukturierung der Infrastruktur die Website noch neu gestaltet wurde. Ein Teil der Site wurde mit einigen Parametern erstellt - für Statik und alles andere, und ein Teil - mit anderen. Dort war es notwendig ... um es milde auszudrücken ... mit all diesen mehrstufigen Containern zu pervertieren, Daten von ihnen in einer anderen Reihenfolge zu kopieren usw.
Wir mussten auch mit Tamburinen um das CI \ CD-System herum tanzen, um all dies zu lehren, wie es aus verschiedenen Repositories und aus verschiedenen Umgebungen bereitgestellt und gesteuert werden kann. Schließlich ist eine ständige Kontrolle über Anwendungsversionen erforderlich, damit Sie nachvollziehen können, wann ein Dienst oder ein anderer Dienst bereitgestellt wurde und mit welcher Version der Anwendung der eine oder andere Fehler gestartet wurde. Zu diesem Zweck haben wir das richtige Protokollierungssystem (sowie die Protokollierungskultur selbst) eingerichtet und ELK implementiert. Die Kollegen haben gelernt, bestimmte Selektoren festzulegen, um zu sehen, welcher Cron welche Fehler erzeugt und wie er im Allgemeinen ausgeführt wird, da Sie im „Cube“ nach Ausführung des Cron-Containers nicht mehr darauf zugreifen können.
Am schwierigsten für uns war es jedoch, die gesamte Codebasis zu überarbeiten und zu überarbeiten.
Ich möchte Sie daran erinnern, dass Republic ein Projekt ist, das jetzt 10 Jahre alt ist. Es begann mit einem Team, ein anderes entwickelt sich gerade und es ist wirklich schwierig, alle Quellcodes auf mögliche Fehler und Fehler zu untersuchen. In diesem Moment verband unsere vierköpfige Landegruppe natürlich die Ressourcen des restlichen Teams: Wir haben die gesamte Site angeklickt und mit Tests getestet, auch in den Bereichen, die lebende Menschen seit 2016 nicht mehr besucht hatten.
Nein fällt nirgendwo aus
Am Montag, am frühen Morgen, als die Leute mit einem Digest zum Massenmailing gingen, bekamen wir alle einen Anteil. Der Täter wurde ziemlich schnell gefunden: Cronjob begann und begann verzweifelt, Briefe an alle zu senden, die in der vergangenen Woche eine Auswahl an Nachrichten erhalten wollten, und verschlang dabei die Ressourcen des gesamten Clusters. Wir konnten uns ein solches Verhalten nicht gefallen lassen und haben daher schnell alle Ressourcen begrenzt: wie viel Prozessor und Speicher ein Container verbrauchen kann und so weiter.
Wie ist das Entwicklerteam der Republik damit umgegangen?
Unsere Aktivitäten haben viele Veränderungen mit sich gebracht, und wir haben dies verstanden. Tatsächlich haben wir nicht nur die Infrastruktur der Veröffentlichung neu gezeichnet, sondern anstelle des üblichen "Main-Backup-Server" -Pakets eine Containerlösung implementiert, die bei Bedarf zusätzliche Ressourcen miteinander verbindet, sondern den Ansatz für die weitere Entwicklung vollständig geändert.
Nach einiger Zeit begannen die Jungs zu verstehen, dass dies nicht direkt mit Code funktioniert, sondern mit einer abstrakten Anwendung. Angesichts der CI \ CD-Prozesse (die auf Jenkins basieren) haben sie angefangen, Tests zu schreiben. Sie haben vollwertige Dev-Stage-Prod-Umgebungen erhalten, in denen sie neue Versionen ihrer Anwendung in Echtzeit testen, sehen können, wo etwas abfällt, und lernen, darin zu leben neue ideale Welt.
Was hat der Kunde bekommen?
Zunächst hat Republic endlich einen kontrollierten Bereitstellungsprozess erhalten! Früher war es so: In der Republik gab es eine verantwortliche Person, die zum Server ging, alles manuell startete, dann Statiken sammelte und mit den Händen überprüfte, ob nichts heruntergefallen war ... Jetzt ist der Bereitstellungsprozess so aufgebaut, dass die Entwickler an der Entwicklung beteiligt sind und keine Zeit mit etwas anderem verschwenden . Und die verantwortliche Person hat jetzt eine Aufgabe - zu überwachen, wie die Veröffentlichung im Allgemeinen verlaufen ist.
Nachdem ein Push an den Hauptzweig entweder automatisch oder durch eine Bereitstellung per Knopfdruck erfolgt (aufgrund bestimmter Geschäftsanforderungen wird die automatische Bereitstellung regelmäßig deaktiviert), tritt Jenkins in den Kampf ein: Die Montage des Projekts beginnt. Zunächst werden alle Docker-Container zusammengestellt: Abhängigkeiten (Composer, Garn, npm) werden in den vorbereitenden Containern installiert, sodass Sie den Erstellungsprozess beschleunigen können, wenn sich die Liste der erforderlichen Bibliotheken während der Bereitstellung nicht geändert hat. Dann werden Container für PHP-Fpm, Nginx und andere Dienste gesammelt, in die analog zur Docker-Compose-Umgebung nur die erforderlichen Teile der Codebasis kopiert werden. Danach werden Tests gestartet, und im Falle eines erfolgreichen Bestehens der Tests werden Bilder in den privaten Speicher verschoben und tatsächlich Bereitstellungen im Cuber eingeführt.
Dank der Übertragung der Republik auf k8s haben wir eine Architektur erhalten, die einen Cluster von drei realen Maschinen verwendet, auf denen bis zu zwölf Kopien der Webanwendung gleichzeitig „gedreht“ werden können. Gleichzeitig entscheidet das System selbst auf der Grundlage der aktuellen Auslastung, wie viele Kopien es derzeit benötigt. Wir haben Republic aus der Lotterie „Works - funktioniert nicht“ mit statischen Primär- und Backup-Servern genommen und ein flexibles System für sie erstellt, das für eine Lawinen-ähnliche Erhöhung der Belastung auf der Website bereit ist.
In diesem Moment könnte sich die Frage stellen: "Leute, Sie haben zwei Eisenstücke gegen dieselben Eisenstücke ausgetauscht, aber mit der Virtualisierung, was ist der Gewinn, sind Sie in Ordnung?" Und natürlich wird es logisch sein. Aber nur teilweise. Infolgedessen haben wir nicht nur Hardware mit Virtualisierung erhalten. Wir haben ein stabiles Arbeitsumfeld, das sowohl für Lebensmittel als auch für Jungfrauen gleich ist. Eine Umgebung, die für alle Projektteilnehmer zentral verwaltet wird. Wir haben einen Mechanismus für die Zusammenstellung des gesamten Projekts und die Einführung von Releases, der für alle gleich ist. Wir haben ein praktisches Projekt-Orchestrierungssystem. Sobald das Team der Republik feststellt, dass es im Allgemeinen nicht mehr über genügend aktuelle Ressourcen und das Risiko ultrahoher Lasten verfügt (oder wenn dies bereits geschehen ist und sich alles beruhigt hat), nimmt es einfach einen anderen Server, rollt in 10 Minuten die Rolle eines Clusterknotens darauf aus und op-op Alles ist wieder schön und gut. Die vorherige Projektstruktur schlug einen solchen Ansatz überhaupt nicht vor, es gab weder langsame noch schnelle Lösungen für solche Probleme.
Zweitens ist eine nahtlose Bereitstellung aufgetreten: Der Besucher gelangt entweder zur alten oder zur neuen Version der Anwendung. Und nicht wie zuvor, wenn der Inhalt neu sein könnte, aber die Stile alt sind.
Damit ist das Geschäft zufrieden: Alle möglichen neuen Dinge können jetzt schneller und häufiger erledigt werden.
Insgesamt dauerte die Arbeit an dem Projekt von „aber versuchen wir es“ bis „erledigt“ 2 Monate. Das Team unsererseits ist eine heldenhafte Landung von vier Personen + Unterstützung für die "Basis" bei der Überprüfung von Code und Tests.
Was Benutzer haben
Und die Besucher haben die Veränderungen im Prinzip nicht gesehen. Der Bereitstellungsprozess für die Strategie von RollingUpdate ist "nahtlos" aufgebaut. Die Einführung einer neuen Version der Website schadet den Benutzern in keiner Weise. Die neue Version der Website ist nicht verfügbar, bis die Tests bestanden und die Lebendigkeits- / Bereitschaftstests durchgeführt wurden. Sie sehen nur, dass die Website funktioniert und nach der Veröffentlichung cooler Artikel nicht fallen wird. Welches ist im Allgemeinen, was jedes Projekt braucht.