Wir sind Big Data bei MTS und dies ist unser erster Beitrag. Heute werden wir darüber sprechen, mit welchen Technologien wir Big Data speichern und verarbeiten können, damit immer genügend Ressourcen für Analysen zur Verfügung stehen und die Kosten für den Kauf von Eisen nicht in die Höhe gehen.
Sie dachten darüber nach, das Big Data Center bei MTS im Jahr 2014 einzurichten: Es bestand die Notwendigkeit, den klassischen analytischen Speicher und die BI-Berichterstellung darüber zu skalieren. Zu dieser Zeit war die Datenverarbeitungs- und BI-Engine SAS - dies geschah historisch. Und obwohl die geschäftlichen Anforderungen an den Speicher geschlossen wurden, wuchs die Funktionalität von BI- und Ad-hoc-Analysen zusätzlich zum analytischen Speicher im Laufe der Zeit so stark, dass das Problem der Produktivitätssteigerung gelöst werden musste, da sich die Anzahl der Benutzer im Laufe der Jahre verzehnfachte und weiter zunahm.
Als Ergebnis des Wettbewerbs erschien das Teradata MPP-System in MTS und deckte die damaligen Bedürfnisse der Telekommunikation ab. Dies war der Anstoß, etwas Populäreres und Open Source auszuprobieren.
 Auf dem Foto - das Big Data MTS-Team im neuen Descartes-Büro in Moskau
Auf dem Foto - das Big Data MTS-Team im neuen Descartes-Büro in Moskau Der erste Cluster bestand aus 7 Knoten. Dies war genug, um mehrere Geschäftshypothesen zu testen und die ersten Probleme zu lösen. Die Bemühungen waren nicht umsonst: Big Data gibt es in MTS seit drei Jahren und jetzt ist die Datenanalyse in fast allen Funktionsbereichen involviert. Das Team wuchs von drei auf zweihundert.
Wir wollten einfache Entwicklungsprozesse haben und Hypothesen schnell testen. Dazu benötigen Sie drei Dinge: ein Team mit Startup-Denken, leichten Entwicklungsprozessen und entwickelter Infrastruktur. Es gibt viele Orte, an denen Sie die erste und die zweite lesen und anhören können, aber es lohnt sich, die entwickelte Infrastruktur separat zu beschreiben, da hier Legacy- und Datenquellen in der Telekommunikation wichtig sind. Eine entwickelte Dateninfrastruktur baut nicht nur einen Datensee, eine detaillierte Datenschicht und eine Storefront-Schicht auf. Es umfasst auch Tools und Datenzugriffsschnittstellen, die Isolierung von Computerressourcen für Produkte und Befehle sowie Mechanismen zur Bereitstellung von Daten für Verbraucher - sowohl in Echtzeit als auch im Batch-Modus. Und vieles mehr.
All diese Arbeiten wurden in einem separaten Bereich hervorgehoben, der sich mit der Entwicklung von Dienstprogrammen und Datentools befasst. Dieser Bereich wird als Big Data IT-Plattform bezeichnet.
Woher kommt Big Data in MTS?
MTS hat viele Datenquellen. Eine der wichtigsten sind Basisstationen. Wir bedienen die Abonnentenbasis von mehr als 78 Millionen Abonnenten in Russland. Wir haben auch viele Dienste, die nicht mit Telekommunikation zu tun haben und es Ihnen ermöglichen, vielseitigere Daten zu erhalten (E-Commerce, Systemintegration, Internet der Dinge, Cloud-Dienste usw. - alle „Nicht-Telekommunikationsdienste“ bringen bereits etwa 20% aller Einnahmen).
Kurz gesagt, unsere Architektur kann als solches Diagramm dargestellt werden:
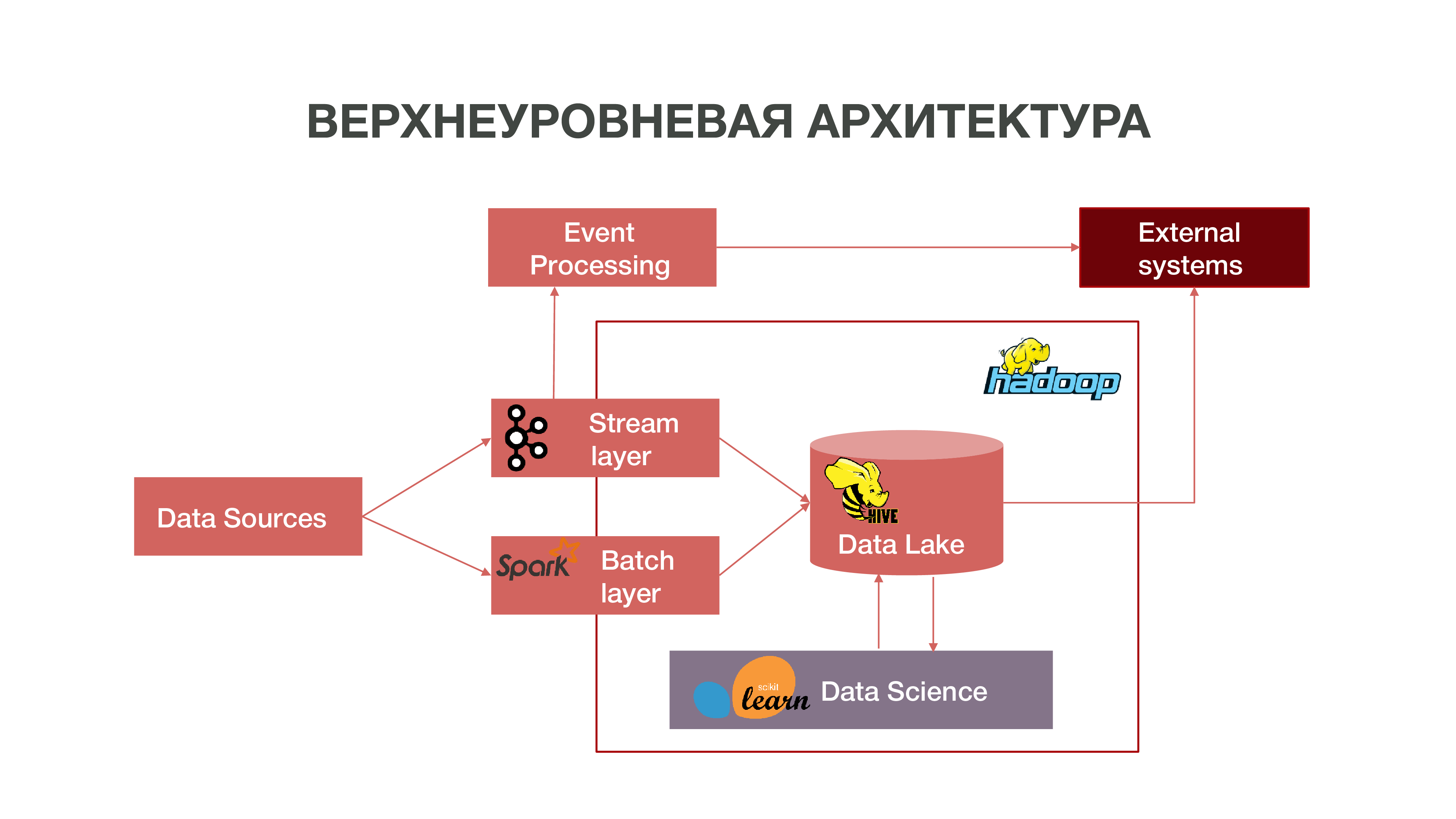
Wie Sie in der Tabelle sehen können, können Datenquellen Informationen in Echtzeit liefern. Wir verwenden die Stream-Schicht - wir können Echtzeitinformationen verarbeiten, daraus einige Ereignisse extrahieren, die für uns von Interesse sind, und darauf Analysen aufbauen. Um eine solche Ereignisverarbeitung bereitzustellen, haben wir eine ziemlich standardmäßige Implementierung (aus Sicht der Architektur) unter Verwendung von Apache Kafka, Apache Spark und Code in der Scala-Sprache entwickelt. Informationen, die als Ergebnis einer solchen Analyse erhalten werden, können sowohl innerhalb als auch in Zukunft außerhalb von MTS konsumiert werden: Unternehmen sind häufig an der Tatsache bestimmter Aktionen von Abonnenten interessiert.
Es gibt auch einen Modus zum Laden von Daten in Chargen - Chargenebene. Normalerweise erfolgt der Download einmal pro Stunde nach einem Zeitplan, wir verwenden Apache Airflow als Planer und die Batch-Download-Prozesse selbst sind in Python implementiert. In diesem Fall wird eine erheblich größere Datenmenge in Data Lake geladen, die zum Füllen von Big Data mit historischen Daten erforderlich ist, auf denen unsere Data Science-Modelle trainiert werden sollten. Infolgedessen wird im historischen Kontext ein Teilnehmerprofil basierend auf Daten zu seiner Netzwerkaktivität erstellt. Dies ermöglicht es uns, prädiktive Statistiken zu erhalten, Modelle des menschlichen Verhaltens zu erstellen und sogar ein psychologisches Porträt von ihm zu erstellen - wir haben ein so separates Produkt. Diese Informationen sind beispielsweise für Marketingunternehmen sehr nützlich.
Wir haben auch eine große Datenmenge, aus der das klassische Repository besteht. Das heißt, wir sammeln Informationen zu verschiedenen Ereignissen - sowohl Benutzer als auch Netzwerk. All diese anonymisierten Daten helfen auch dabei, Benutzerinteressen und Ereignisse, die für das Unternehmen wichtig sind, genauer vorherzusagen - beispielsweise um mögliche Geräteausfälle vorherzusagen und Fehler rechtzeitig zu beheben.
Hadoop
Wenn Sie in die Vergangenheit schauen und sich daran erinnern, wie Big Data im Allgemeinen aussah, sollte beachtet werden, dass die Akkumulation von Daten im Wesentlichen zu Marketingzwecken durchgeführt wurde. Es gibt keine so klare Definition von Big Data - Gigabyte, Terabyte, Petabyte. Es ist unmöglich, eine Linie zu ziehen. Für einige sind Big Data mehrere zehn Gigabyte, für andere Petabyte.
So kam es, dass sich im Laufe der Zeit weltweit viele Daten angesammelt haben. Und um eine mehr oder weniger signifikante Analyse dieser Daten durchzuführen, reichten die üblichen Repositories, die sich seit den 70er Jahren des letzten Jahrhunderts entwickelt haben, nicht mehr aus. Als der Informationsschacht in den 2000er, 10er Jahren begann und als es viele Geräte gab, die über einen Internetzugang verfügten, als das Internet der Dinge erschien, konnten diese Repositories konzeptionell einfach nicht fertig werden. Die Grundlage dieser Repositories war die relationale Theorie. Das heißt, es gab Beziehungen verschiedener Formen, die miteinander interagierten. Es gab ein System zur Beschreibung des Erstellens und Entwerfens von Repositorys.
Wenn alte Technologien versagen, erscheinen neue. In der modernen Welt wird das Problem der Big-Data-Analyse auf zwei Arten gelöst:
Erstellen Sie Ihr eigenes Framework, mit dem Sie große Informationsmengen verarbeiten können. In der Regel handelt es sich hierbei um eine verteilte Anwendung von vielen Hunderttausenden von Servern - wie Google und Yandex, die ihre eigenen verteilten Datenbanken erstellt haben, mit denen Sie mit einem solchen Informationsvolumen arbeiten können.
Die Entwicklung der Hadoop-Technologie ist ein verteiltes Computer-Framework, ein verteiltes Dateisystem, das eine sehr große Menge an Informationen speichern und verarbeiten kann. Data Science-Tools sind hauptsächlich mit Hadoop kompatibel, und diese Kompatibilität eröffnet viele Möglichkeiten für erweiterte Datenanalysen. Viele Unternehmen, einschließlich uns, bewegen sich in Richtung Open-Source-Hadoop-Ökosystem.
Der zentrale Hadoop-Cluster befindet sich in Nischni Nowgorod. Es sammelt Informationen aus fast allen Regionen des Landes. In Bezug auf das Volumen können dort jetzt etwa 8,5 Petabyte Daten heruntergeladen werden. Auch in Moskau haben wir separate RND-Cluster, in denen wir Experimente durchführen.
Da wir ungefähr tausend Server in verschiedenen Regionen haben, auf denen wir Analysen durchführen und eine Erweiterung geplant ist, stellt sich die Frage nach der richtigen Auswahl der Ausrüstung für verteilte Analysesysteme. Sie können Geräte kaufen, die für die Datenspeicherung ausreichen, sich jedoch für die Analyse als ungeeignet herausstellen - einfach, weil nicht genügend Ressourcen, die Anzahl der CPU-Kerne und der freie Arbeitsspeicher auf den Knoten vorhanden sind. Es ist wichtig, ein Gleichgewicht zu finden, um gute Analysemöglichkeiten und nicht sehr hohe Gerätekosten zu erhalten.
Intel bot uns verschiedene Optionen zur Optimierung der Arbeit mit einem verteilten System an, damit Analysen in unserem Datenvolumen für angemessenes Geld abgerufen werden können. Intel verbessert die NAND SSD Solid State Drive-Technologie Es ist hunderte Male schneller als eine normale Festplatte. Dann ist es gut für uns: SSD, insbesondere mit NVMe-Schnittstelle, bietet ausreichend schnellen Zugriff auf Daten.
Außerdem hat Intel Intel Optane SSD-Server-SSDs veröffentlicht, die auf dem neuen Typ des nichtflüchtigen Speichers Intel 3D XPoint basieren. Sie bewältigen intensive gemischte Belastungen des Speichersystems und verfügen über eine längere Ressource als normale NAND-SSDs. Warum ist es gut für uns: Mit Intel Optane SSD können Sie unter hoher Last mit geringer Latenz stabil arbeiten. Wir haben die NAND-SSD zunächst als Ersatz für herkömmliche Festplatten angesehen, da sich sehr viel Daten zwischen Festplatte und RAM bewegen - und wir mussten diese Prozesse optimieren.
Erster Test
Der erste Test, den wir 2016 durchgeführt haben. Wir haben gerade versucht, die Festplatte durch eine schnelle NAND-SSD zu ersetzen. Zu diesem Zweck haben wir Muster des neuen Intel-Laufwerks bestellt - damals war es DC P3700. Und sie haben den Standardtest von Hadoop durchgeführt - einem Ökosystem, mit dem Sie bewerten können, wie sich die Leistung unter verschiedenen Bedingungen ändert. Dies sind standardisierte Tests TeraGen, TeraSort, TeraValidate.

Mit TeraGen können Sie künstliche Daten eines bestimmten Volumens "generieren". Zum Beispiel haben wir 1 GB und 1 TB genommen. Mit TeraSort haben wir diese Datenmenge in Hadoop sortiert. Dies ist eine ziemlich ressourcenintensive Operation. Mit dem letzten Test - TeraValidate - können Sie sicherstellen, dass die Daten in der richtigen Reihenfolge sortiert sind. Das heißt, wir gehen sie ein zweites Mal durch.

Als Experiment haben wir Autos nur mit SSDs genommen - das heißt, Hadoop wurde nur auf SSDs ohne Festplatten installiert. In der zweiten Version haben wir SSD zum Speichern temporärer Dateien verwendet, HDD - zum Speichern von Basisdaten. In der dritten Version wurden für beide Festplatten verwendet.
Die Ergebnisse dieser Experimente waren für uns nicht sehr erfreulich, da der Unterschied in den Leistungsindikatoren 10-20% nicht überschritt. Das heißt, wir haben festgestellt, dass Hadoop in Bezug auf die Speicherung nicht sehr mit SSDs vertraut ist, da das System ursprünglich zum Speichern großer Datenmengen auf der Festplatte entwickelt wurde und niemand es speziell für schnelle und teure SSDs optimiert hat. Und da die Kosten für SSD zu dieser Zeit ziemlich hoch waren, haben wir uns bisher entschieden, nicht auf diese Geschichte einzugehen und mit Festplatten auszukommen.
Zweiter Test
Anschließend führte Intel neue serverseitige Intel Optane-SSDs ein, die auf 3D-XPoint-Speicher basieren. Sie wurden Ende 2017 veröffentlicht, aber die Muster standen uns früher zur Verfügung. Mit den 3D XPoint-Speicherfunktionen können Sie die Intel Optane SSD als RAM-Erweiterung in Servern verwenden. Da wir bereits erkannt haben, dass es nicht einfach ist, das Leistungsproblem von IO Hadoop auf der Ebene von Blockspeichergeräten zu lösen, haben wir uns für eine neue Option entschieden - die Erweiterung des Arbeitsspeichers mithilfe der Intel Memory Drive Technology (IMDT). Und zu Beginn dieses Jahres waren wir einer der ersten auf der Welt, die es getestet haben.
Das ist gut für uns: Es ist billiger als RAM, wodurch Sie Server mit Terabyte RAM sammeln können. Und da RAM schnell genug ist, können Sie große Datenmengen darin laden und analysieren. Ich möchte Sie daran erinnern, dass die Besonderheit unseres Analyseprozesses darin besteht, dass wir mehrmals auf die Daten zugreifen. Um eine Art von Analyse durchzuführen, müssen wir so viele Daten wie möglich in den Speicher laden und eine Art Analyse dieser Daten mehrmals "scrollen".
Das Intel English Labor in Swindon hat uns einen Cluster von drei Servern zugewiesen, die wir während der Tests mit unserem Testcluster in MTS verglichen haben.

Wie aus der Grafik ersichtlich ist, haben wir nach den Testergebnissen recht gute Ergebnisse erzielt.
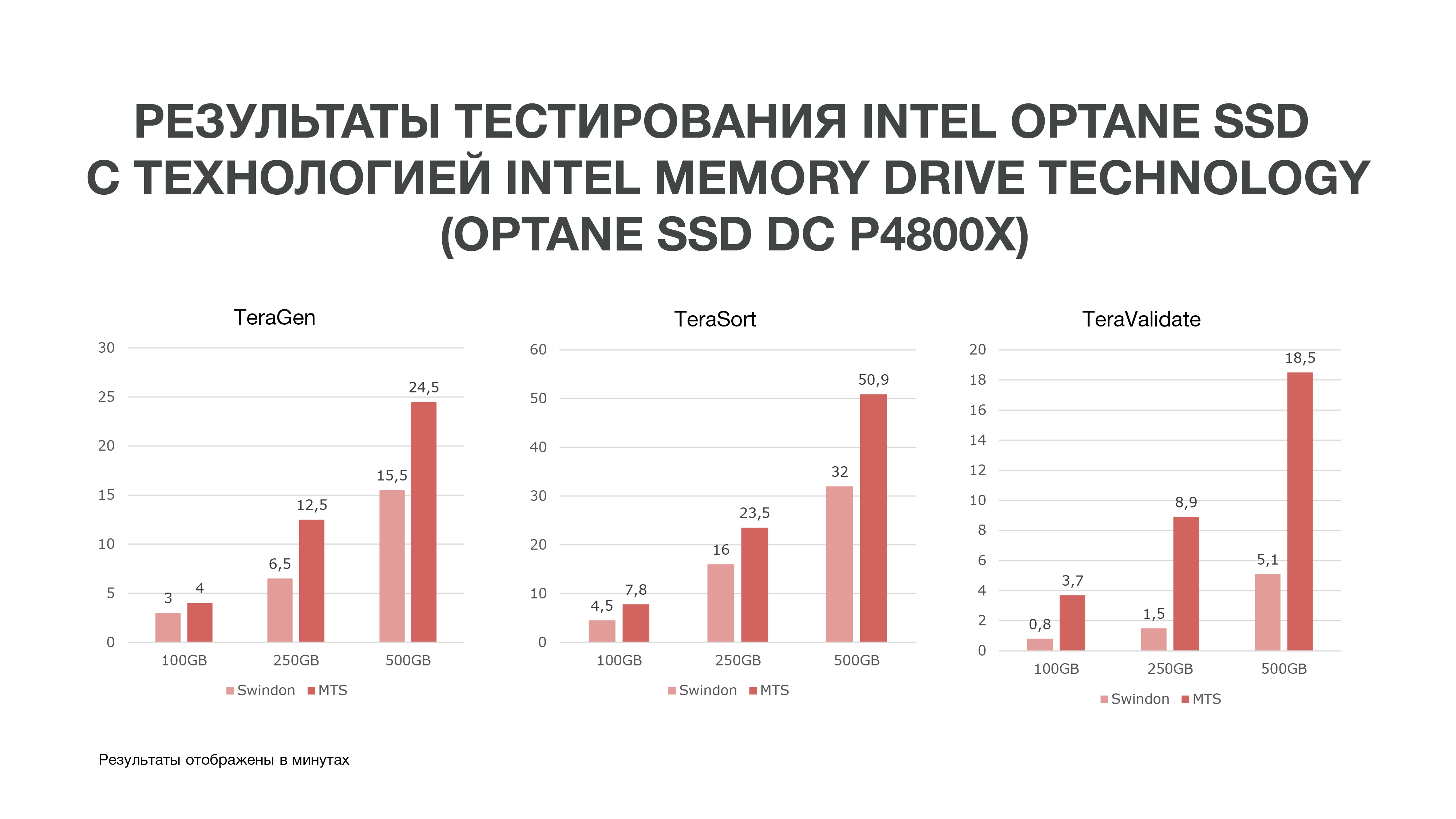
Das gleiche TeraGen zeigte eine fast zweifache Produktivitätssteigerung, TeraValidate - um 75%. Das ist sehr gut für uns, denn wie gesagt, wir greifen mehrmals auf die Daten zu, die wir in unserem Gedächtnis haben. Wenn wir einen solchen Leistungsgewinn erzielen, hilft uns dies insbesondere bei der Datenanalyse, insbesondere in Echtzeit.
Wir haben drei Tests unter verschiedenen Bedingungen durchgeführt. 100 GB, 250 GB und 500 GB. Und je mehr Speicher wir verwendeten, desto besser schnitt die Intel Optane SSD mit Intel Memory Drive-Technologie ab. Das heißt, je mehr Daten wir analysieren, desto effizienter werden wir. Analysen, die auf mehr Knoten durchgeführt wurden, können auf weniger von ihnen durchgeführt werden. Außerdem verfügen wir über eine relativ große Menge an Speicher auf unseren Computern, was für Data Science-Aufgaben sehr gut ist. Aufgrund der Testergebnisse haben wir uns entschlossen, diese Laufwerke für die Arbeit bei MTS zu kaufen.
Wenn Sie auch Hardware zum Speichern und Verarbeiten einer großen Datenmenge auswählen und testen mussten, ist es für uns interessant zu lesen, auf welche Schwierigkeiten Sie gestoßen sind und welche Ergebnisse Sie erzielt haben: Schreiben Sie in die Kommentare.
Autoren:
Grigory Koval, Leiter des Kompetenzzentrums für Angewandte Architektur der Big Data-Abteilung von MTS, grigory_koval
Leiter des Datenverwaltungsstammes der Big Data MTS-Abteilung Dmitry Shostko zloi_diman