
Ich betrete das Tarantool Core Team und beteilige mich an der Entwicklung eines Datenbankmoduls, der internen Kommunikation von Serverkomponenten und der Replikation. Und heute werde ich Ihnen sagen, wie die Replikation funktioniert.
Informationen zur Replikation
Bei der Replikation werden Kopien von Daten von einem Geschäft in ein anderes erstellt. Jede Kopie wird als Replikat bezeichnet. Die Replikation kann verwendet werden, wenn Sie ein Backup erstellen, Hot Standby implementieren oder das System horizontal skalieren müssen. Und dafür ist es notwendig, die gleichen Daten auf verschiedenen Knoten des Computernetzwerks des Clusters verwenden zu können.
Wir klassifizieren die Replikation auf zwei Arten:
- Richtung: Master-Master oder Master-Slave . Die Master-Slave-Replikation ist die einfachste Option. Sie haben einen Knoten, auf dem Sie Daten ändern. Sie übersetzen diese Änderungen auf die anderen Knoten, auf die sie angewendet werden. Bei der Master-Master-Replikation werden Änderungen an mehreren Knoten gleichzeitig vorgenommen. In diesem Fall ändert jeder Knoten seine Daten selbst und wendet die an anderen Knoten vorgenommenen Änderungen auf sich selbst an.
- Betriebsart: asynchron oder synchron . Die synchrone Replikation bedeutet, dass keine Daten festgeschrieben werden und die Replikation dem Benutzer erst bestätigt wird, wenn die Änderungen über mindestens die Mindestanzahl von Clusterknoten übertragen werden. Bei der asynchronen Replikation sind das Festschreiben einer Transaktion (Festschreiben) und die Interaktion mit einem Benutzer zwei unabhängige Prozesse. Um Daten festzuschreiben, müssen sie nur in das lokale Protokoll fallen, und erst dann werden diese Änderungen auf irgendeine Weise an andere Knoten übertragen. Offensichtlich hat die asynchrone Replikation aus diesem Grund eine Reihe von Nebenwirkungen.
Wie funktioniert die Replikation in Tarantool?
Die Replikation in Tarantool bietet mehrere Funktionen:
- Es besteht aus einfachen Bausteinen, mit denen Sie einen Cluster beliebiger Topologie erstellen können. Jedes dieser grundlegenden Konfigurationselemente ist unidirektional, dh Sie haben immer Master und Slave. Der Master führt einige Aktionen aus und generiert ein Protokoll der Vorgänge, das auf dem Replikat verwendet wird.
- Die Tarantool-Replikation ist asynchron. Das heißt, das System bestätigt das Festschreiben an Sie, unabhängig davon, wie viele Replikate diese Transaktion gesehen hat, wie viel sie auf sich selbst angewendet wurde und ob sie überhaupt ausgeführt wurde.
- Eine weitere Eigenschaft der Replikation in Tarantool ist, dass sie zeilenbasiert ist. Tarantool führt ein Operationsprotokoll (WAL). Die Operation gelangt zeilenweise dorthin, dh wenn sich ein Tapla aus dem Leerzeichen ändert, wird diese Operation als eine Zeile in das Protokoll geschrieben. Danach liest der Hintergrundprozess diese Zeile aus dem Protokoll und sendet sie an das Replikat. Wie viele Replikate der Master hat, so viele Hintergrundprozesse. Das heißt, jeder Replikationsprozess auf verschiedene Knoten des Clusters wird asynchron von anderen ausgeführt.
- Jeder Clusterknoten verfügt über eine eigene eindeutige Kennung, die beim Erstellen des Knotens generiert wird. Darüber hinaus verfügt der Knoten über eine Kennung im Cluster (Mitgliedsnummer). Dies ist eine numerische Konstante, die einem Replikat zugewiesen wird, wenn eine Verbindung zu einem Cluster besteht, und die während ihrer gesamten Lebensdauer im Cluster beim Replikat verbleibt.
Aufgrund der Asynchronität werden Daten an verzögerte Replikate geliefert. Das heißt, Sie haben einige Änderungen vorgenommen, das System hat das Festschreiben bestätigt, die Operation wurde bereits auf den Master angewendet, aber auf Replikaten wird sie mit einer gewissen Verzögerung angewendet, die durch die Geschwindigkeit bestimmt wird, mit der der Hintergrundreplikationsprozess die Operation liest, an die Replik sendet und diese angewendet wird .
Aus diesem Grund besteht die Möglichkeit, dass Daten nicht synchron sind. Angenommen, wir haben mehrere Master, die miteinander verbundene Daten ändern. Es kann sich herausstellen, dass die von Ihnen verwendeten Vorgänge nicht kommutativ sind und sich auf dieselben Daten beziehen. Dann haben zwei verschiedene Clustermitglieder unterschiedliche Versionen der Daten.
Wenn die Replikation in Tarantool ein unidirektionaler Master-Slave ist, wie wird dann Master-Master erstellt? Ganz einfach: Erstellen Sie einen anderen Replikationskanal, jedoch in die andere Richtung. Sie müssen verstehen, dass die Master-Master-Replikation in Tarantool nur eine Kombination aus zwei voneinander unabhängigen Datenströmen ist.
Nach dem gleichen Prinzip können wir den dritten Master verbinden und als Ergebnis ein vollständiges Mesh-Netzwerk aufbauen, in dem jedes Replikat ein Master und ein Slave für alle anderen Replikate ist.
Beachten Sie, dass nicht nur die Vorgänge repliziert werden, die lokal auf diesem Master initiiert werden, sondern auch diejenigen, die er extern über Replikationsprotokolle empfangen hat. In diesem Fall werden die auf Replikat Nr. 1 erstellten Änderungen zweimal auf Replikat Nr. 3 angewendet: direkt und über Replikat Nr. 2. Mit dieser Eigenschaft können komplexere Topologien ohne Verwendung eines vollständigen Netzes erstellt werden. Sagen wir diesen.
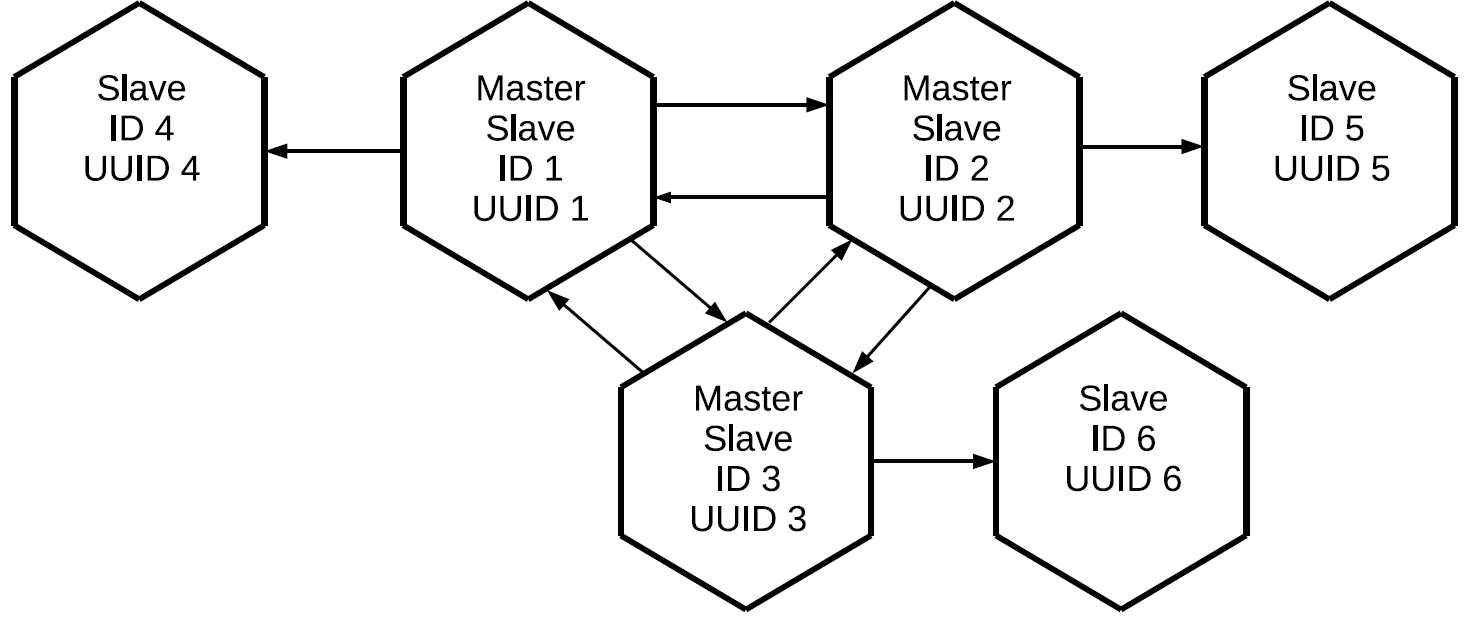
Allen drei Mastern, die zusammen den vollständigen Netzkern des Clusters bilden, ist ein individuelles Replikat zugeordnet. Da das Proxying von Protokollen auf jedem der Master durchgeführt wird, enthalten alle drei "sauberen" Slaves alle Operationen, die auf einem der Clusterknoten ausgeführt wurden.
Diese Konfiguration kann für eine Vielzahl von Aufgaben verwendet werden. Sie können keine redundanten Verbindungen zwischen allen Knoten des Clusters erstellen. Wenn Replikate in der Nähe platziert werden, verfügen sie mit minimaler Verzögerung über eine exakte Kopie des Masters. All dies geschieht mit dem grundlegenden Master-Slave-Replikationselement.
Beschriften von Cluster-Vorgängen
Es stellt sich die Frage:
Wenn Vorgänge zwischen allen Clustermitgliedern übertragen werden und mehrmals zu jedem Replikat gelangen, wie verstehen wir, welche Vorgänge ausgeführt werden müssen und welche nicht? Dies erfordert einen Filtermechanismus. Jeder aus dem Protokoll gelesenen Operation werden zwei Attribute zugewiesen:
- Die Kennung des Servers, auf dem dieser Vorgang initiiert wurde.
- Die Sequenznummer der Operation auf dem Server, lsn, der sein Initiator ist. Jeder Server weist bei der Ausführung einer Operation jeder empfangenen Protokollzeile eine zunehmende Nummer zu: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Wenn wir also wissen, dass für einen Server mit einer bestimmten Kennung die Operation mit angewendet wurde lsn 10, dann sind Operationen mit lsn 9, 8, 7, 10, die über andere Replikationskanäle kamen, nicht erforderlich. Stattdessen wenden wir Folgendes an: 11, 12 usw.
Replikatstatus
Und wie speichert Tarantool Informationen zu den bereits angewendeten Vorgängen? Dazu gibt es eine Vclock-Uhr - dies ist der Vektor des letzten lsn, der auf jeden Knoten im Cluster angewendet wird.
[lsn 1 , lsn 2 , lsn n ]Dabei ist
lsn i die Nummer der letzten bekannten Operation vom Server mit der Kennung i.
Vclock kann auch als bestimmte Momentaufnahme des gesamten Clusterstatus bezeichnet werden, der diesem Replikat bekannt ist. Wenn wir die Server-ID der Operation kennen, die angekommen ist, isolieren wir die Komponente der lokalen Vclock, die wir benötigen, vergleichen die erhaltene lsn mit der lsn-Operation und entscheiden, ob diese Operation verwendet werden soll. Infolgedessen werden von einem bestimmten Master initiierte Vorgänge nacheinander gesendet und angewendet. Gleichzeitig können die auf verschiedenen Mastern erstellten Workflows aufgrund der asynchronen Replikation miteinander gemischt werden.
Clustererstellung
Angenommen, wir haben einen Cluster, der aus zwei Elementen besteht, Master und Slave, und wir möchten eine dritte Instanz damit verbinden. Es hat eine eindeutige UUID, aber es gibt noch keine Cluster-ID. Wenn Tarantool noch nicht initialisiert ist, möchte es dem Cluster beitreten. Es muss eine JOIN-Operation an einen der Master senden, der sie ausführen kann, dh es befindet sich im Lese- / Schreibmodus. Als Antwort auf JOIN sendet der Master seinen lokalen Snapshot an das Verbindungsreplikat. Das Replikat rollt es zu Hause, solange es noch keine Kennung hat. Jetzt wird das Replikat mit einer leichten Verzögerung mit dem Cluster synchronisiert. Danach weist der Master, auf dem JOIN ausgeführt wurde, diesem Replikat eine Kennung zu, die protokolliert und an das Replikat gesendet wird. Wenn einem Replikat ein Bezeichner zugewiesen wird, wird er zu einem vollwertigen Knoten und kann danach die Protokollreplikation auf seiner Seite initiieren.
Zeilen aus dem Journal werden ab dem Status dieses Replikats zum Zeitpunkt der Anforderung des Replikationsprotokolls vom Master gesendet, dh von der Uhr, die es während des JOIN-Prozesses empfangen hat, oder von der Stelle, an der das Replikat zuvor gestoppt wurde. Wenn das Replikat aus irgendeinem Grund heruntergefallen ist, wird beim nächsten Herstellen einer Verbindung zum Cluster kein JOIN mehr ausgeführt, da bereits ein lokaler Snapshot vorhanden ist. Sie fragt nur nach allen Operationen, die während ihrer Abwesenheit im Cluster stattgefunden haben.
Registrieren Sie ein Replikat in einem Cluster
Um den Status über die Struktur des Clusters zu speichern, wird ein spezieller Bereich verwendet - Cluster. Es enthält die Server-IDs im Cluster, ihre Seriennummern und eindeutigen IDs.
[1, 'c35b285c-c5b1-4bbe-83b1-b825eb594aa4']
[2, '37b12cb7-d324-4d75-b428-cde92c18e708']
[3, 'b72b1aa6-42a0-4d73-a611-900e44cdd465']Bezeichner müssen nicht in der richtigen Reihenfolge ausgeführt werden, da Knoten gelöscht und hinzugefügt werden können.
Hier ist die erste Falle. In der Regel werden Cluster nicht von einem Knoten erfasst: Sie führen eine bestimmte Anwendung aus und sie stellt den gesamten Cluster auf einmal bereit. Die Replikation in Tarantool ist jedoch asynchron. Was ist, wenn zwei Master gleichzeitig neue Knoten verbinden und ihnen identische Kennungen zuweisen? Es wird einen Konflikt geben.
Hier ist ein Beispiel für einen falschen und korrekten JOIN:

Wir haben zwei Master und zwei Repliken, die eine Verbindung herstellen möchten. Sie machen JOINs auf verschiedenen Meistern. Angenommen, Replikate erhalten dieselben Bezeichner. Dann fällt die Replikation zwischen den Mastern und denen, die es schaffen, ihre Protokolle zu replizieren, auseinander, der Cluster fällt auseinander.
Um dies zu verhindern, müssen Sie Replikate jederzeit ausschließlich auf einem Master initiieren. Zu diesem Zweck führte Tarantool ein solches Konzept als Initialisierungsleiter ein und implementierte einen Algorithmus zur Auswahl dieses Leiters. Ein Replikat, das eine Verbindung zum Cluster herstellen möchte, stellt zunächst eine Verbindung zu allen Mastern her, die ihm aus der übertragenen Konfiguration bekannt sind. Anschließend wählt das Replikat diejenigen aus, die bereits initiiert wurden (bei der Bereitstellung des Clusters können nicht alle Knoten das volle Geld verdienen). Und aus ihnen werden die Master ausgewählt, die für die Aufnahme verfügbar sind. In Tarantool gibt es schreibgeschützt und schreibgeschützt. Wir können uns nicht auf dem schreibgeschützten Knoten registrieren. Danach wählen wir aus der Liste der gefilterten Knoten den Knoten mit der niedrigsten UUID aus.
Wenn wir dieselbe Konfiguration und dieselbe Liste von Servern auf nicht initialisierten Instanzen verwenden, die eine Verbindung zum Cluster herstellen, wählen sie denselben Master aus, was bedeutet, dass JOIN höchstwahrscheinlich erfolgreich sein wird.
Von hier leiten wir eine Regel ab: Wenn Replikate parallel mit einem Cluster verbunden werden, müssen alle diese Replikate dieselbe Replikationskonfiguration haben. Wenn wir irgendwo etwas weglassen, besteht die Möglichkeit, dass Instanzen mit einer anderen Konfiguration auf verschiedenen Mastern initiiert werden und der Cluster nicht zusammengesetzt werden kann.
Angenommen, wir haben uns geirrt oder der Administrator hat vergessen, die Konfiguration zu reparieren, oder Ansible ist kaputt gegangen, und der Cluster ist immer noch auseinandergefallen. Was kann das bezeugen? Erstens können steckbare Replikate ihre lokalen Snapshots nicht erstellen: Replikate werden nicht gestartet und melden Fehler. Zweitens werden auf den Mastern in den Protokollen Fehler im Zusammenhang mit Konflikten im Space-Cluster angezeigt.
Wie lösen wir diese Situation? Es ist einfach:
- Zunächst müssen wir die Konfiguration überprüfen, die wir für die Verbindungsreplikate festgelegt haben. Wenn wir sie nicht reparieren, ist alles andere nutzlos.
- Danach beseitigen wir die Konflikte im Cluster und machen ein Bild.
Jetzt können Sie versuchen, die Replikate erneut zu initialisieren.
Konfliktlösung
Also haben wir einen Cluster erstellt und eine Verbindung hergestellt. Alle Knoten arbeiten im Abonnementmodus, dh sie erhalten die von verschiedenen Mastern generierten Änderungen. Da die Replikation asynchron ist, sind Konflikte möglich. Wenn Sie gleichzeitig Daten auf verschiedenen Mastern ändern, erhalten verschiedene Replikate unterschiedliche Kopien der Daten, da die Vorgänge in einer anderen Reihenfolge angewendet werden können.
Hier ist ein Beispielcluster nach der Ausführung von JOIN:
Wir haben drei Master-Slaves, zwischen denen Protokolle übertragen werden, die in verschiedene Richtungen übertragen werden und auf Slaves angewendet werden. Nicht synchronisierte Daten bedeuten, dass jedes Replikat seinen eigenen Vclock-Änderungsverlauf hat, da Streams von verschiedenen Mastern miteinander gemischt werden können. Dann kann die Reihenfolge der Operationen für Instanzen variieren. Wenn unsere Operationen nicht kommutativ sind, wie z. B. die REPLACE-Operation, sind die Daten, die wir auf diesen Replikaten erhalten, unterschiedlich.
Ein kleines Beispiel. Angenommen, wir haben zwei Master mit vclock = {0,0}. Und beide führen zwei Operationen aus, die als op1,1, op1,2, op2,1, op2,2 bezeichnet werden. Dies ist die zweite Zeitscheibe, in der jeder der Master eine lokale Operation ausführte:

Grün zeigt eine Änderung der entsprechenden vclock-Komponente an. Zuerst ändern beide Master ihre Uhr, und dann führt der zweite Master eine weitere lokale Operation aus und erhöht die Uhr erneut. Der erste Master empfängt die Replikationsoperation vom zweiten Master. Dies wird durch die rote Nummer 1 in vclock des ersten Clusterknotens angezeigt.

Dann empfängt der zweite Master die Operation von der ersten und die erste - die zweite Operation von der zweiten. Und am Ende führt der erste Master seine letzte Operation aus und der zweite Master empfängt sie.

Vclock im Nullzeitquantum haben wir das gleiche - {0,0}. In der letzten Zeit haben wir auch die gleiche Uhr {2,2}, es scheint, dass die Daten gleich sein sollten. Die Reihenfolge der Operationen, die an jedem Master ausgeführt werden, ist jedoch unterschiedlich. Und wenn dies eine REPLACE-Operation mit unterschiedlichen Werten für dieselben Schlüssel ist? Dann erhalten wir trotz der gleichen Uhr am Ende unterschiedliche Versionen der Daten auf beiden Replikaten.
Wir sind auch in der Lage, diese Situation zu lösen.
- Sharding-Datensätze . Erstens können wir Schreibvorgänge nicht für zufällig ausgewählte Replikate ausführen, sondern sie irgendwie zerlegen. Sie haben nur die Schreiboperationen zwischen verschiedenen Mastern unterbrochen und schließlich ein Konsistenzsystem erhalten. Beispielsweise haben sich die Schlüssel auf einem Master von 1 auf 10 und auf einem anderen von 11 auf 20 geändert. Die Knoten tauschen ihre Protokolle aus und erhalten genau dieselben Daten.
Sharding impliziert, dass wir einen bestimmten Router haben. Es muss überhaupt keine separate Entität sein, der Router kann Teil der Anwendung sein. Es kann ein Shard sein, der Schreiboperationen auf sich selbst anwendet oder sie auf die eine oder andere Weise an einen anderen Master überträgt. Es wird jedoch so übergeben, dass die Änderungen der zugehörigen Werte an einen bestimmten Master gehen: Ein Werteblock ging an einen Master, ein anderer Block an einen anderen Master. In diesem Fall können Lesevorgänge an jeden Knoten im Cluster gesendet werden. Und vergessen Sie nicht die asynchrone Replikation: Wenn Sie auf demselben Master aufgezeichnet haben, müssen Sie möglicherweise auch daraus lesen.
- Logische Reihenfolge der Operationen . Angenommen, Sie können gemäß den Bedingungen des Problems die Priorität der Operation irgendwie bestimmen. Geben Sie beispielsweise einen Zeitstempel, eine Version oder ein anderes Etikett ein, mit dem wir verstehen können, welche Operation früher physisch stattgefunden hat. Das heißt, wir sprechen von einer externen Bestellquelle.
Tarantool verfügt über einen before_replace Trigger, der während der Replikation ausgeführt werden kann. In diesem Fall sind wir nicht darauf beschränkt, Anfragen weiterzuleiten, sondern können sie senden, wohin wir wollen. Bei der Replikation am Eingang des Datenstroms haben wir jedoch einen Auslöser. Er liest die gesendete Leitung, vergleicht sie mit der bereits gespeicherten Leitung und entscheidet, welche der Leitungen eine höhere Priorität hat. Das heißt, der Trigger ignoriert entweder die Replikationsanforderung oder wendet sie möglicherweise mit den erforderlichen Änderungen an. Wir wenden diesen Ansatz bereits an, obwohl er auch seine Nachteile hat. Zunächst benötigen Sie eine externe Taktquelle. Angenommen, ein Betreiber in einem Mobiltelefonsalon nimmt Änderungen an einem Teilnehmer vor. Für solche Vorgänge können Sie die Zeit auf dem Computer des Betreibers verwenden, da es unwahrscheinlich ist, dass mehrere Bediener gleichzeitig Änderungen an einem Teilnehmer vornehmen. Operationen können auf unterschiedliche Weise erfolgen. Wenn jedoch jeder von ihnen eine bestimmte Version zugewiesen werden kann, bleiben beim Durchlaufen von Triggern nur die relevanten übrig.
Der zweite Nachteil der Methode: Da der Trigger auf jedes Delta angewendet wird, das durch Replikation für jede Anforderung kam, entsteht eine zusätzliche Rechenlast. Aber dann haben wir eine konsistente Kopie der Daten auf einer Cluster-Skala.
Synchronisieren
Unsere Replikation ist asynchron, dh durch Festschreibungsausführung wissen Sie nicht, ob sich diese Daten bereits auf einem anderen Clusterknoten befinden. Wenn Sie ein Commit für den Master vorgenommen haben, wurde es Ihnen bestätigt, und der Master hat aus irgendeinem Grund sofort aufgehört zu arbeiten. Dann können Sie nicht sicher sein, dass die Daten an einem anderen Ort gespeichert wurden. Um dieses Problem zu lösen, verfügt das Tarantool-Replikationsprotokoll über eine ACK. Jeder Master weiß, welche letzte ACK von jedem Slave kam.
Was ist ein ACK? Wenn der Slave das Delta empfängt, das mit dem Master lsn und seiner Kennung markiert ist, sendet er als Antwort ein spezielles ACK-Paket, in das er nach Anwendung dieser Operation seine lokale Uhr packt. Mal sehen, wie das funktionieren kann.
Wir haben einen Meister, der 4 Operationen in sich selbst durchgeführt hat. Angenommen, der Slave-Slave hat irgendwann die ersten drei Zeilen empfangen und seine Uhr auf {3.0} erhöht.
ACK ist noch nicht angekommen. Nachdem der Slave diese drei Leitungen empfangen hat, sendet er das ACK-Paket, an das er zum Zeitpunkt des Sendens des Pakets seine Uhr angeschlossen hat. Lassen Sie den Slave-Master eine weitere Leitung im selben Zeitfenster senden, dh die vclock des Slaves hat sich erhöht. Auf dieser Grundlage weiß Master Nr. 1 mit Sicherheit, dass die ersten drei Operationen, die er ausgeführt hat, bereits auf diesen Slave angewendet wurden. Diese Zustände werden für alle Slaves gespeichert, mit denen der Master arbeitet, sie sind völlig unabhängig.
Und am Ende antwortet der Slave mit einem vierten ACK-Paket. Danach weiß der Master, dass der Slave mit ihm synchronisiert ist.
Dieser Mechanismus kann im Anwendungscode verwendet werden. Wenn Sie eine Operation festschreiben, bestätigen Sie den Benutzer nicht sofort, sondern rufen zuerst eine spezielle Funktion auf. Es wartet darauf, dass der dem Master bekannte lsn-Slave zum Zeitpunkt des Abschlusses des Commits gleich dem lsn Ihres Masters ist. Sie müssen also nicht auf die vollständige Synchronisierung warten, sondern nur auf den genannten Moment warten.
Angenommen, unser erster Anruf hat drei Leitungen geändert, und der zweite Anruf hat eine geändert. Nach dem ersten Aufruf möchten Sie sicherstellen, dass die Daten synchronisiert sind. Der oben gezeigte Zustand bedeutet bereits, dass der erste Anruf auf mindestens einem Slave synchronisiert wurde.
Wo genau Sie nach Informationen dazu suchen, werden wir im nächsten Abschnitt betrachten.
Überwachung
Wenn die Replikation synchron ist, ist die Überwachung sehr einfach: Wenn sie auseinanderfällt, werden Fehler an Ihre Vorgänge ausgegeben. Und wenn die Replikation asynchron ist, wird die Situation verwirrend. Der Meister antwortet Ihnen, dass alles in Ordnung ist, es funktioniert, akzeptiert, aufgeschrieben. Gleichzeitig sind jedoch alle Replikate tot, die Daten sind nicht redundant, und wenn Sie den Master verlieren, verlieren Sie die Daten. Daher möchte ich den Cluster wirklich überwachen und verstehen, was mit der asynchronen Replikation geschieht, wo sich die Replikate befinden und in welchem Zustand sie sich befinden.
Für die grundlegende Überwachung verfügt Tarantool über eine box.info-Entität. Es lohnt sich, es in der Konsole aufzurufen, da Sie interessante Daten sehen werden.
id: 1 uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4 lsn : 5 vclock : {2: 1, 1: 5} replication : 1: id: 1 uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4 lsn : 5 2: id: 2 uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708 lsn : 1 upstream : status : follow idle : 0.30358312401222 peer : lag: 3.6001205444336 e -05 downstream : vclock : {2: 1, 1: 5}
Die wichtigste Metrik ist die ID-
id . In diesem Fall bedeutet 1, dass die lsn dieses Masters an der ersten Position in allen vclock gespeichert wird. Eine sehr nützliche Sache. Wenn Sie einen Konflikt mit JOIN haben, können Sie einen Master nur durch eindeutige Bezeichner von einem anderen unterscheiden. Lokale Mengen umfassen auch solche Mengen wie lsn. Dies ist die Nummer der letzten Zeile, die dieser Master ausgeführt und in sein Protokoll geschrieben hat. In unserem Beispiel hat der erste Master fünf Operationen ausgeführt. Vclock ist der Betriebszustand, von dem er weiß, dass er ihn auf sich selbst angewendet hat. Und schließlich führte er für Master Nummer 2 eine seiner Replikationsoperationen durch.
Nach den Anzeigen des lokalen Status können Sie sehen, was diese Instanz über den Status der Clusterreplikation weiß. Dazu gibt es einen
replication . Es listet alle der Instanz bekannten Clusterknoten auf, einschließlich sich selbst. Der erste Knoten hat die Kennung 1, id entspricht der aktuellen Instanz. Der zweite Knoten hat die Kennung 2, sein lsn 1 entspricht dem lsn, der in vclock geschrieben wird. In diesem Fall betrachten wir die Master-Master-Replikation, wenn Master Nr. 1 sowohl der Master für den zweiten Knoten des Clusters als auch dessen Slave ist, dh ihm folgt.
- Die Essenz von
upstream . Das status follow Attribut bedeutet, dass Master 1 auf Master 2 folgt. Leerlauf ist die Zeit, die seit der letzten Interaktion mit diesem Master lokal vergangen ist. Wir senden keinen Stream kontinuierlich, der Master sendet nur dann ein Delta, wenn Änderungen daran auftreten. Wenn wir eine Art ACK senden, kommunizieren wir auch. Wenn der Leerlauf groß wird (Sekunden, Minuten, Stunden), stimmt offensichtlich etwas nicht. lag Attribut. Wir haben über Lag gesprochen. Zusätzlich zu lsn und der server id jede Operation im Protokoll mit einem Zeitstempel gekennzeichnet - der Ortszeit, während der diese Operation in vclock auf dem Master aufgezeichnet wurde, der sie ausgeführt hat. Gleichzeitig vergleicht Slave seinen lokalen Zeitstempel mit dem Zeitstempel des Deltas, das er erhalten hat. Der letzte aktuelle Zeitstempel, der für die letzte Zeile empfangen wurde, wird vom Slave bei der Überwachung angezeigt.downstream Attribut. Es zeigt, was der Meister über seinen bestimmten Sklaven weiß. Dies ist die Bestätigung, die der Sklave an ihn sendet. Der oben dargestellte downstream bedeutet, dass sein Sklave, auch bekannt als Master auf Nummer 2, ihm das letzte Mal seine Uhr schickte, die 5.1 war. Dieser Meister weiß, dass alle fünf seiner Linien, die er an seinem Platz vervollständigte, zu einem anderen Knoten gingen.
XLOG-Verlust
Betrachten Sie die Situation mit dem Fall des Meisters.
lsn : 0 id: 3 replication : 1: <...> upstream : status: disconnected peer : lag: 3.9100646972656 e -05 idle: 1602.836148153 message: connect, called on fd 13, aka [::1]:37960 2: <...> upstream : status : follow idle : 0.65611373598222 peer : lag: 1.9550323486328 e -05 3: <...> vclock : {2: 2, 1: 5}
Zunächst ändert sich der Status.
Lag ändert sich nicht, da die von uns angewendete Linie dieselbe bleibt und wir keine neuen erhalten haben. Gleichzeitig wächst der
idle , in diesem Fall sind es bereits 1602 Sekunden, so viel Zeit war der Meister tot. Und wir sehen eine Fehlermeldung: Es besteht keine Netzwerkverbindung.
Was tun in einer ähnlichen Situation? Wir finden heraus, was mit unserem Master passiert ist, ziehen den Administrator an, starten den Server neu und heben den Knoten an. Die wiederholte Replikation wird durchgeführt, und wenn der Master das System betritt, stellen wir eine Verbindung her, abonnieren dessen XLOG, holen sie für uns selbst und der Cluster stabilisiert sich.
Aber es gibt ein kleines Problem. Stellen Sie sich vor, wir hätten einen Sklaven, der aus irgendeinem Grund ausgeschaltet war und lange Zeit abwesend war. Während dieser Zeit löschte der Meister, der es bediente, das XLOG. Beispielsweise ist die Festplatte voll, der Garbage Collector hat Protokolle gesammelt. Wie kann ein zurückkehrender Sklave weitermachen? Auf keinen Fall. Weil die Protokolle, die er anwenden muss, um mit dem Cluster synchronisiert zu werden, weg sind und es keinen Ort gibt, an dem sie abgerufen werden können. In diesem Fall wird ein interessanter Fehler angezeigt: Der Status wird nicht mehr
disconnected , sondern
stopped . Und eine bestimmte Nachricht: Es gibt keine Protokolldatei, die mit einer solchen lsn übereinstimmt.
id: 3 replication : 1: <...> upstream : peer : status: stopped lag : 0.0001683235168457 idle : 9.4331328970147 message: 'Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2' 2: <...> 3: <...> vclock : {2: 2, 1: 5}
In der Tat ist die Situation nicht immer tödlich. Angenommen, wir haben mehr als zwei Master, und auf einigen von ihnen bleiben diese Protokolle erhalten. Wir schütten sie allen Meistern gleichzeitig ein und lagern sie nicht nur auf einem. Dann stellt sich heraus, dass diese Replik, die sich mit allen Mastern verbindet, die sie kennt, auf einigen von ihnen die Protokolle findet, die sie benötigt. Sie wird alle diese Operationen zu Hause ausführen, ihre Uhr wird sich erhöhen und sie wird den aktuellen Status des Clusters erreichen. Danach können Sie versuchen, die Verbindung wiederherzustellen.
Wenn überhaupt keine Protokolle vorhanden sind, können wir das Replikat nicht fortsetzen. Es bleibt nur eine Neuinitialisierung. Denken Sie an die eindeutige Kennung. Sie können sie auf ein Blatt Papier oder in eine Datei schreiben. Dann bereinigen wir das Replikat lokal: Löschen Sie seine Bilder, Protokolle und so weiter. Verbinden Sie danach das Replikat erneut mit derselben UUID wie es.
UUID :
box.cfg{instance_uuid = uuid} .
, . UUID space cluster, . , . UUID, master, JOIN, , UUID, , .
, UUID , space cluster , . . , , .
, - . , . , , .
Tarantool .
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1, , , , , , master' 0,1 . 30 . , . 0,1 . , .
Keep alive
, ip tables drop. , - 30 30 , , . , keep alive-.
keep alive- :
box.cfg.replication_timeout .
master' , keep alive-, , . 4 master slave keep alive- , . master'.
, . 6 , 5 . 10 , 9 . .
, , . , master', . - . .
6 , 3. , . , 5 , 3 .
, :
, Telegram-, . , GitHub, .