Teil 2/3 hier
Teil 3/3 hier
Hallo allerseits! In diesem Artikel möchte ich die Informationen optimieren und die Erfahrungen beim Erstellen und Verwenden des internen Kubernetes-Clusters teilen.
In den letzten Jahren hat diese Container-Orchestrierungstechnologie einen großen Schritt nach vorne gemacht und ist für Tausende von Unternehmen zu einer Art Unternehmensstandard geworden. Einige verwenden es in der Produktion, andere testen es nur an Projekten, aber die Leidenschaften, egal wie Sie es sagen, leuchten ernst. Wenn Sie es noch nie benutzt haben, ist es Zeit, mit dem Dating zu beginnen.
0. Einleitung
Kubernetes ist eine skalierbare Orchestrierungstechnologie, die mit der Installation auf einem einzelnen Knoten beginnen und die Größe großer HA-Cluster erreichen kann, die auf mehreren hundert Knoten im Inneren basieren. Die meisten gängigen Cloud-Anbieter bieten verschiedene Arten von Kubernetes-Implementierungen an - nehmen und verwenden. Die Situationen sind jedoch anders, und es gibt Unternehmen, die die Clouds nicht nutzen, und sie möchten alle Vorteile moderner Orchestrierungstechnologien nutzen. Und hier kommt die Installation von Kubernetes auf Bare Metal.

1. Einleitung
In diesem Beispiel erstellen wir einen Kubernetes HA-Cluster mit der Topologie für mehrere Master, mit einem externen Cluster usw. als Basisschicht und einem MetalLB-Load-Balancer im Inneren. Auf allen Arbeitsknoten werden wir GlusterFS als einfachen internen verteilten Clusterspeicher bereitstellen. Wir werden auch versuchen, mehrere Testprojekte mithilfe unserer persönlichen Docker-Registrierung darin bereitzustellen.
Im Allgemeinen gibt es mehrere Möglichkeiten, einen Kubernetes-HA-Cluster zu erstellen: den schwierigen und detaillierten Pfad, der im beliebten Dokument kubernetes-the-hard-way beschrieben ist, oder den einfacheren Weg mit dem Dienstprogramm kubeadm .
Kubeadm ist ein Tool, das von der Kubernetes-Community speziell entwickelt wurde, um die Installation von Kubernetes zu vereinfachen und den Prozess zu vereinfachen. Zuvor wurde Kubeadm nur zum Erstellen kleiner Testcluster mit einem Masterknoten empfohlen, um loszulegen. Im letzten Jahr wurde jedoch viel verbessert, und jetzt können wir damit HA-Cluster mit mehreren Masterknoten erstellen. Laut Community-News von Kubernetes wird Kubeadm in Zukunft als Tool für die Installation von Kubernetes empfohlen.
Die Kubeadm-Dokumentation bietet zwei grundlegende Möglichkeiten zum Implementieren eines Clusters mit Stack- und externen etcd-Topologien. Ich werde den zweiten Pfad mit externen etcd-Knoten aufgrund der Fehlertoleranz des HA-Clusters wählen.
Hier ist ein Diagramm aus der Kubeadm-Dokumentation, das diesen Pfad beschreibt:
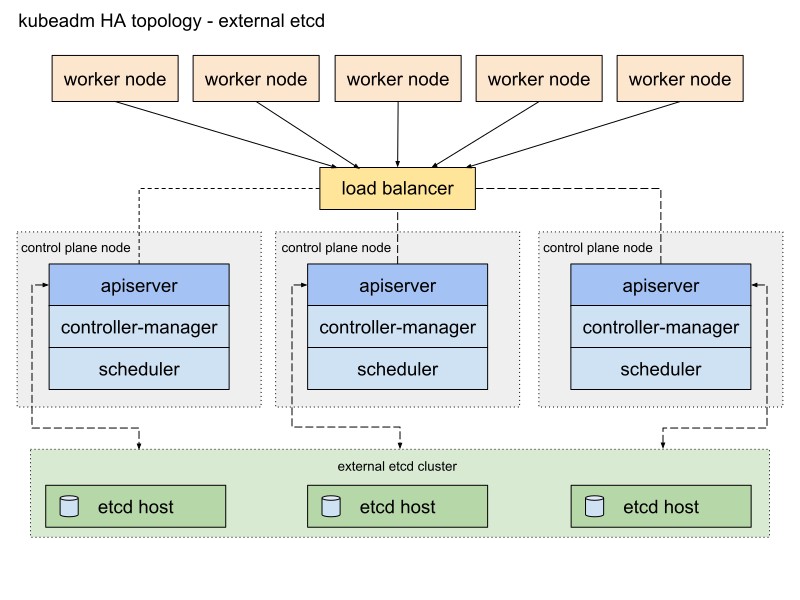
Ich werde es ein wenig ändern. Zunächst werde ich ein Paar HAProxy-Server als Load Balancer für das Heartbeat-Paket verwenden, das die virtuelle IP-Adresse gemeinsam nutzt. Heartbeat und HAProxy verwenden eine kleine Menge an Systemressourcen, daher werde ich sie auf einem Paar von etcd-Knoten platzieren, um die Anzahl der Server für unseren Cluster geringfügig zu reduzieren.
Für dieses Kubernetes-Clusterschema sind acht Knoten erforderlich. Drei Server für einen externen Cluster usw. (LB-Dienste verwenden auch einige davon), zwei für Knoten der Steuerebene (Hauptknoten) und drei für Arbeitsknoten. Es kann sich entweder um Bare-Metal- oder einen VM-Server handeln. In diesem Fall spielt es keine Rolle. Sie können das Schema einfach ändern, indem Sie weitere Masterknoten hinzufügen und HAProxy mit Heartbeat auf separaten Knoten platzieren, wenn viele freie Server vorhanden sind. Obwohl meine Option für die erste Implementierung des HA-Clusters für die Augen ausreicht.
Wenn Sie möchten, fügen Sie einen kleinen Server mit dem installierten Dienstprogramm kubectl hinzu , um diesen Cluster zu verwalten, oder verwenden Sie dazu Ihren eigenen Linux-Desktop.
Das Diagramm für dieses Beispiel sieht ungefähr so aus:
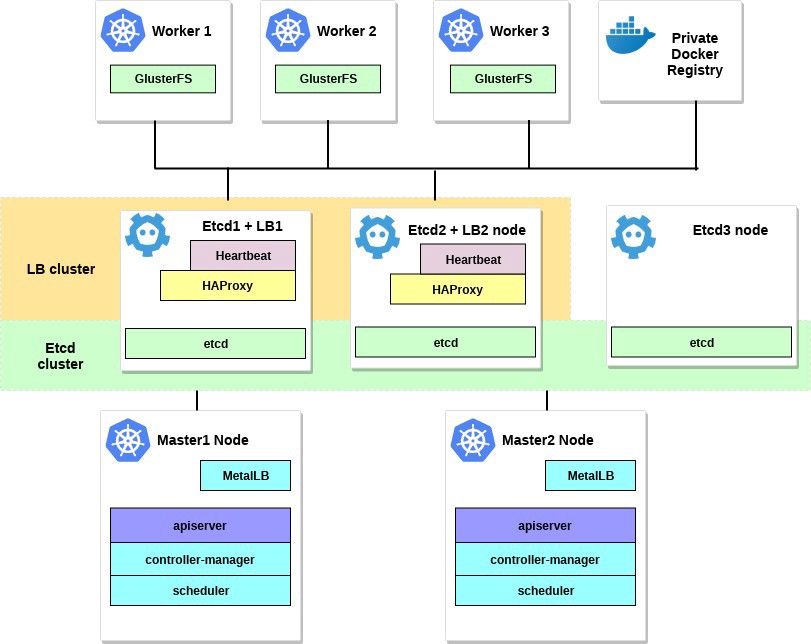
2. Anforderungen
Sie benötigen zwei Kubernetes-Masterknoten mit den empfohlenen Mindestsystemanforderungen: 2 CPUs und 2 GB RAM gemäß der kubeadm- Dokumentation. Für funktionierende Knoten empfehle ich die Verwendung leistungsfähigerer Server, da alle unsere Anwendungsdienste auf diesen ausgeführt werden. Und für Etcd + LB können wir auch Server mit zwei CPUs und mindestens 2 GB RAM verwenden.
Wählen Sie ein öffentliches oder privates Netzwerk für diesen Cluster aus. IP-Adressen spielen keine Rolle; Es ist wichtig, dass alle Server für einander und natürlich für Sie zugänglich sind. Später werden wir im Kubernetes-Cluster ein Overlay-Netzwerk einrichten.
Die Mindestanforderungen für dieses Beispiel sind:
- 2 Server mit 2 Prozessoren und 2 GB RAM für den Masterknoten
- 3 Server mit 4 Prozessoren und 4-8 GB RAM für Arbeitsknoten
- 3 Server mit 2 Prozessoren und 2 GB RAM für Etcd und HAProxy
- 192.168.0.0/24 - das Subnetz.
192.168.0.1 - Virtuelle HAProxy-IP-Adresse, 192.168.0.2 - 4 Haupt-IP-Adressen von Etcd- und HAProxy-Knoten, 192.168.0.5 - 6 Haupt-IP-Adressen des Kubernetes-Masterknotens, 192.168.0.7 - 9 Haupt-IP-Adressen der Kubernetes-Arbeitsknoten .
Die Debian 9-Datenbank ist auf allen Servern installiert.
Denken Sie auch daran, dass die Systemanforderungen davon abhängen, wie groß und leistungsfähig der Cluster ist. Weitere Informationen finden Sie in der Dokumentation zu Kubernetes.
3. Konfigurieren Sie HAProxy und Heartbeat.
Wir haben mehr als einen Kubernetes-Masterknoten. Daher müssen Sie einen HAProxy-Load-Balancer vor sich konfigurieren, um den Datenverkehr zu verteilen. Dies ist ein Paar HAProxy-Server mit einer gemeinsam genutzten virtuellen IP-Adresse. Die Fehlertoleranz wird mit dem Heartbeat-Paket geliefert. Für die Bereitstellung verwenden wir die ersten beiden etcd-Server.
Installieren und konfigurieren Sie HAProxy mit Heartbeat auf dem ersten und zweiten etcd-Server (in diesem Beispiel 192.168.0.2–3):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy
Speichern Sie die ursprüngliche Konfiguration und erstellen Sie eine neue:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg
Fügen Sie diese Konfigurationsoptionen für beide HAProxy hinzu:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2
Wie Sie sehen können, teilen sich beide HAProxy-Dienste die IP-Adresse - 192.168.0.1. Diese virtuelle IP-Adresse wird zwischen den Servern verschoben, daher sind wir etwas gerissen und aktivieren den Parameter net.ipv4.ip_nonlocal_bind , um die Bindung von Systemdiensten an eine nicht lokale IP-Adresse zu ermöglichen.
Fügen Sie diese Funktion zur Datei /etc/sysctl.conf hinzu :
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1
Auf beiden Servern ausführen:
sysctl -p
Führen Sie HAProxy auch auf beiden Servern aus:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy
Stellen Sie sicher, dass HAProxy auf beiden Servern ausgeführt wird und die virtuelle IP-Adresse überwacht:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
Haube! Installieren Sie nun Heartbeat und konfigurieren Sie diese virtuelle IP.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat
Es ist Zeit, mehrere Konfigurationsdateien dafür zu erstellen: Für den ersten und den zweiten Server sind sie im Grunde gleich.
Erstellen Sie zuerst die Datei /etc/ha.d/authkeys . In dieser Datei speichert Heartbeat Daten zur gegenseitigen Authentifizierung. Die Datei muss auf beiden Servern gleich sein:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
Diese Datei sollte nur für root zugänglich sein:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys
Erstellen Sie nun die Hauptkonfigurationsdatei für Heartbeat auf beiden Servern: Für jeden Server ist dies etwas anders.
Erstellen Sie /etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
Rufen Sie die "Knoten" -Parameter für diese Konfiguration ab, indem Sie uname -n auf beiden Etcd-Servern ausführen. Verwenden Sie auch den Namen Ihrer Netzwerkkarte anstelle von ens18.
Schließlich müssen Sie die Datei /etc/ha.d/haresources auf diesen Servern erstellen. Für beide Server muss die Datei identisch sein. In dieser Datei legen wir unsere gemeinsame IP-Adresse fest und bestimmen, welcher Knoten der Standardmaster ist:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1
Wenn alles fertig ist, starten Sie die Heartbeat-Dienste auf beiden Servern und stellen Sie sicher, dass wir diese deklarierte virtuelle IP auf dem Knoten etcd1 erhalten haben:
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary
Sie können überprüfen, ob HAProxy ordnungsgemäß funktioniert, indem Sie nc unter 192.168.0.1 6443 ausführen. Sie müssen eine Zeitüberschreitung festgestellt haben, da die Kubernetes-API auf der Serverseite noch nicht überwacht. Dies bedeutet jedoch, dass HAProxy und Heartbeat korrekt konfiguriert sind.
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded!
4. Vorbereitung der Knoten für Kubernetes
Der nächste Schritt besteht darin, alle Kubernetes-Knoten vorzubereiten. Sie müssen Docker mit einigen zusätzlichen Paketen installieren, das Kubernetes-Repository hinzufügen und die Pakete kubelet , kubeadm , kubectl daraus installieren. Diese Einstellung ist für alle Kubernetes-Knoten (Master, Worker usw.) gleich.
Der Hauptvorteil von Kubeadm besteht darin, dass keine zusätzliche Software benötigt wird. Installieren Sie kubeadm auf allen Hosts - und verwenden Sie es. Generieren Sie mindestens CA-Zertifikate.
Installieren Sie Docker auf allen Knoten:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4
Installieren Sie danach Kubernetes-Pakete auf allen Knoten:
kubeadm : Befehl zum Laden des Clusters.kubelet : Eine Komponente, die auf allen Computern im Cluster ausgeführt wird und Aktionen wie das Starten von Herden und Containern ausführt.kubectl : Verwenden Sie die Befehlszeile, um mit dem Cluster zu kommunizieren.- kubectl - nach Belieben; Ich installiere es oft auf allen Knoten, um einige Kubernetes-Befehle zum Debuggen auszuführen.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}
Vergessen Sie nach der Installation von kubeadm und anderen Paketen nicht, den Swap zu deaktivieren.
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab
Wiederholen Sie die Installation auf den verbleibenden Knoten. Softwarepakete sind für alle Knoten im Cluster gleich, und nur die folgende Konfiguration bestimmt die Rollen, die sie später erhalten.
5. Konfigurieren Sie den HA Etcd-Cluster
Nachdem wir die Vorbereitungen abgeschlossen haben, werden wir den Kubernetes-Cluster konfigurieren. Der erste Baustein ist der HA Etcd-Cluster, der ebenfalls mit dem kubeadm-Tool konfiguriert wird.
Bevor wir beginnen, stellen Sie sicher, dass alle etcd-Knoten über die Ports 2379 und 2380 kommunizieren. Außerdem müssen Sie den SSH-Zugriff zwischen ihnen konfigurieren, um scp verwenden zu können .
Beginnen wir mit dem ersten etcd-Knoten und kopieren dann einfach alle erforderlichen Zertifikate und Konfigurationsdateien auf die anderen Server.
Auf allen etcd- Knoten müssen Sie eine neue systemd- Konfigurationsdatei für die Kubelet- Einheit mit einer höheren Priorität hinzufügen:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet
Dann gehen wir über ssh zum ersten etcd- Knoten - wir werden ihn verwenden, um alle erforderlichen kubeadm- Konfigurationen für jeden etcd- Knoten zu generieren und sie dann zu kopieren.
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done
Erstellen Sie nun die Hauptzertifizierungsstelle mit kubeadm
etcd1# kubeadm init phase certs etcd-ca
Dieser Befehl erstellt zwei ca.crt- und ca.key-Dateien im Verzeichnis / etc / kubernetes / pki / etcd / .
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key
Jetzt werden wir Zertifikate für alle etcd- Knoten generieren:
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete
Kopieren Sie dann die Zertifikate und Konfigurationen von kubeadm auf die Knoten etcd2 und etcd3 .
Generieren Sie zuerst ein Paar SSH- Schlüssel auf etcd1 und fügen Sie den öffentlichen Teil zu den Knoten etcd2 und 3 hinzu . In diesem Beispiel werden alle Befehle im Auftrag eines Benutzers ausgeführt, der alle Rechte im System besitzt.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/
Stellen Sie vor dem Starten des etcd-Clusters sicher, dass die Dateien auf allen Knoten vorhanden sind:
Liste der erforderlichen Dateien auf etcd1 :
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Für den Knoten etcd2 lautet dies:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Und der letzte Knoten ist etcd3 :
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Wenn alle Zertifikate und Konfigurationen vorhanden sind, erstellen wir Manifeste. Führen Sie auf jedem Knoten den Befehl kubeadm aus , um ein statisches Manifest für den Cluster etcd zu generieren:
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
Jetzt ist der Cluster etcd - theoretisch - konfiguriert und fehlerfrei . Überprüfen Sie dies, indem Sie den folgenden Befehl auf dem Knoten etcd1 ausführen:
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy
Der etcd- Cluster ist gestiegen, fahren Sie fort.
6. Konfigurieren von Master- und Arbeitsknoten
Konfigurieren Sie die Masterknoten unseres Clusters - kopieren Sie diese Dateien vom ersten etcd- Knoten auf den ersten Masterknoten :
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:
Gehen Sie dann ssh zum Masterknoten master1 und erstellen Sie die Datei kubeadm-config.yaml mit dem folgenden Inhalt:
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
Verschieben Sie die zuvor kopierten Zertifikate und den Schlüssel wie in der Beschreibung der Einstellung in das entsprechende Verzeichnis auf dem Knoten master1.
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/
Gehen Sie wie folgt vor, um den ersten Masterknoten zu erstellen:
master1# kubeadm init --config kubeadm-config.yaml
Wenn alle vorherigen Schritte korrekt ausgeführt wurden, wird Folgendes angezeigt:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Kopieren Sie diese kubeadm- Initialisierungsausgabe in eine beliebige Textdatei. Wir werden dieses Token in Zukunft verwenden, wenn wir den zweiten Master und die Arbeitsknoten an unseren Cluster anhängen.
Ich habe bereits gesagt, dass der Kubernetes-Cluster eine Art Overlay-Netzwerk für Herde und andere Dienste verwenden wird. Daher müssen Sie an dieser Stelle eine Art CNI-Plugin installieren. Ich empfehle das Weave CNI Plugin. Die Erfahrung hat gezeigt: Es ist nützlicher und weniger problematisch, aber Sie können ein anderes wählen, zum Beispiel Calico.
Installieren des Weave-Netzwerk-Plugins auf dem ersten Masterknoten:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created
Warten Sie einen Moment und geben Sie dann den folgenden Befehl ein, um zu überprüfen, ob die Komponentenherde gestartet werden:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s
- Es wird empfohlen, neue Knoten der Steuerebene erst nach der Initialisierung des ersten Knotens anzuhängen.
Gehen Sie wie folgt vor, um den Clusterstatus zu überprüfen:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1
Großartig! Der erste Hauptknoten stieg. Jetzt ist es fertig und wir werden die Erstellung des Kubernetes-Clusters abschließen - wir werden einen zweiten Masterknoten und Arbeitsknoten hinzufügen.
Um einen zweiten Masterknoten hinzuzufügen, erstellen Sie einen SSH- Schlüssel auf Master1 und fügen Sie den öffentlichen Teil zu Master2 hinzu . Führen Sie eine Testanmeldung durch und kopieren Sie dann einige Dateien vom ersten Masterknoten auf den zweiten:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub
Verschieben Sie auf dem zweiten Masterknoten die zuvor kopierten Zertifikate und Schlüssel in die entsprechenden Verzeichnisse:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf
Verbinden Sie den zweiten Masterknoten mit dem Cluster. Dazu benötigen Sie die Ausgabe des Verbindungsbefehls, der zuvor von kubeadm init auf dem ersten Knoten an uns kubeadm init .
Führen Sie den Masterknoten master2 aus :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane
- Sie müssen das
--experimental-control-plane hinzufügen. Es automatisiert das Anhängen von Stammdaten an einen Cluster. Ohne dieses Flag wird einfach der übliche Arbeitsknoten hinzugefügt.
Warten Sie etwas, bis der Knoten dem Cluster beitritt, und überprüfen Sie den neuen Status des Clusters:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1
Stellen Sie außerdem sicher, dass alle Pods von allen Masterknoten normal gestartet werden:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m
Großartig! Wir sind fast fertig mit der Kubernetes-Cluster-Konfiguration. Als letztes müssen Sie die drei Arbeitsknoten hinzufügen, die wir zuvor vorbereitet haben.
Geben Sie die Arbeitsknoten ein und führen Sie den Befehl kubeadm join ohne das --experimental-control-plane .
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Überprüfen Sie den Clusterstatus erneut:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1
Wie Sie sehen können, haben wir einen vollständig konfigurierten Kubernetes HA-Cluster mit zwei Master- und drei Arbeitsknoten. Es basiert auf dem HA etcd-Cluster mit einem ausfallsicheren Load Balancer vor den Masterknoten. Klingt ziemlich gut für mich.
7. Konfigurieren der Remote-Clusterverwaltung
Eine weitere Aktion, die in diesem ersten Teil des Artikels noch berücksichtigt werden muss, ist das Einrichten des Remote-Dienstprogramms kubectl zum Verwalten des Clusters. Bisher haben wir alle Befehle vom Masterknoten master1 ausgeführt , dies ist jedoch nur zum ersten Mal geeignet - bei der Konfiguration des Clusters. Es wäre schön, einen externen Steuerknoten zu konfigurieren. Sie können hierfür einen Laptop oder einen anderen Server verwenden.
Melden Sie sich bei diesem Server an und führen Sie Folgendes aus:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1
Ok, jetzt führen wir einen Test in unserem Cluster durch und überprüfen, wie es funktioniert.
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s
Glückwunsch! Sie haben gerade Kubernetes bereitgestellt. Und das bedeutet, dass Ihr neuer HA-Cluster bereit ist. Tatsächlich ist das Einrichten eines Kubernetes-Clusters mit kubeadm recht einfach und schnell.
Im nächsten Teil des Artikels werden wir internen Speicher hinzufügen, indem wir GlusterFS auf allen Arbeitsknoten einrichten, einen internen Load Balancer für unseren Kubernetes-Cluster einrichten, bestimmte Stresstests ausführen, einige Knoten trennen und den Cluster auf Stabilität überprüfen.
Nachwort
Ja, wenn Sie an diesem Beispiel arbeiten, werden Sie auf eine Reihe von Problemen stoßen. Kein Grund zur Sorge: Um die Änderungen rückgängig zu machen und die Knoten in ihren ursprünglichen Zustand zurückzusetzen, führen Sie einfach kubeadm reset aus. Die zuvor von kubeadm vorgenommenen Änderungen werden zurückgesetzt und Sie können sie erneut konfigurieren. Vergessen Sie auch nicht, den Status der Docker-Container auf den Clusterknoten zu überprüfen. Stellen Sie sicher, dass alle fehlerfrei gestartet werden und funktionieren. Verwenden Sie den Befehl docker logs containerid , um weitere Informationen zu beschädigten Containern zu erhalten.
Das ist alles für heute. Viel Glück