Dies ist ein längst überfälliger Artikel über Reinforcement Learning (RL). RL ist ein cooles Thema!
Möglicherweise wissen Sie, dass Computer jetzt
automatisch lernen können, ATARI-Spiele zu spielen (indem sie am Eingang rohe Spielpixel erhalten!). Sie schlagen die Weltmeister im
Go- Spiel, lernen virtuell vierbeinig
Laufen und Springen und Roboter lernen komplexe Manipulationsaufgaben auszuführen, die eine explizite Programmierung herausfordern. Es stellt sich heraus, dass all diese Erfolge ohne RL nicht vollständig sind. Ich habe mich im letzten Jahr auch für RL interessiert: Ich habe mit
Richard Suttons Buch gearbeitet
(ca. Referenz: ersetzt) ,
David Silvers Kurs gelesen,
John Schulmans Vorlesungen besucht ,
die RL-Bibliothek über Javascript geschrieben und in der Sommerpraxis bei DeepMind in einer Gruppe gearbeitet DeepRL und zuletzt in der Entwicklung von
OpenAI Gym ist das neue RL-Toolkit. Ich bin natürlich seit mindestens einem Jahr auf dieser Welle, habe mir aber immer noch nicht die Mühe gemacht, eine Notiz darüber zu schreiben, warum RL von großer Bedeutung ist, worum es geht, wie sich alles entwickelt.
 Beispiele für die Verwendung von Deep Q-Learning. Von links nach rechts: Das neuronale Netzwerk spielt ATARI, das neuronale Netzwerk spielt AlphaGo, der Roboter faltet Lego, der virtuelle Vierbeiner läuft um virtuelle Hindernisse.
Beispiele für die Verwendung von Deep Q-Learning. Von links nach rechts: Das neuronale Netzwerk spielt ATARI, das neuronale Netzwerk spielt AlphaGo, der Roboter faltet Lego, der virtuelle Vierbeiner läuft um virtuelle Hindernisse.Es ist interessant, über die Art der jüngsten Fortschritte in RL nachzudenken. Ich möchte vier verschiedene Faktoren erwähnen, die die Entwicklung der KI beeinflussen:
- Rechengeschwindigkeit (GPU, ASIC-Spezialgeräte, Mooresches Gesetz)
- Ausreichende Daten in verwendbarer Form (z. B. ImageNet)
- Algorithmen (Forschung und Ideen, z. B. Backprop, CNN, LSTM)
- Infrastruktur (Linux, TCP / IP, Git, ROS, PR2, AWS, AMT, TensorFlow usw.).
Genau wie in der Computer Vision bewegt sich der Fortschritt in RL ... wenn auch nicht so sehr, wie es scheint. In der Bildverarbeitung ist das neuronale AlexNet 2012-Netzwerk beispielsweise eine Version des ConvNets-neuronalen Netzwerks aus den 1990er Jahren mit größerer Tiefe und Breite. In ähnlicher Weise ist ATARI Deep Q-Learning 2013 eine Implementierung des Standard-Q-Learning-Algorithmus, den Sie in Richard Suttons klassischem Buch von 1998 finden. Darüber hinaus verwendet AlphaGo die Policy Gradient-Technik und die Monte-Carlo-Baumsuche (MCTS) sind ebenfalls alte Ideen oder deren Kombinationen. Natürlich erfordert es viel Geschick und Geduld, um sie zum Laufen zu bringen, und viele knifflige Einstellungen wurden auf der Grundlage alter Algorithmen entwickelt.
In erster Näherung sind jedoch nicht neue Algorithmen und Ideen der Haupttreiber der jüngsten Fortschritte, sondern die Intensivierung von Berechnungen, ausreichende Daten und eine ausgereifte Infrastruktur.Nun zurück zu RL. Viele Menschen können nicht glauben, dass wir einem Computer beibringen können, ATARI-Spiele auf menschlicher Ebene zu spielen, indem rohe Pixel von Grund auf neu verwendet werden und derselbe selbstlernende Algorithmus verwendet wird. Gleichzeitig fühle ich jedes Mal eine Lücke - wie magisch es scheint und wie einfach es wirklich in mir ist.
Der grundlegende Ansatz, den wir verwenden, ist eigentlich ziemlich dumm. Wie dem auch sei, ich möchte Ihnen die Policy Gradient (PG) -Technik vorstellen, unsere derzeit bevorzugte Standardoption zur Lösung von Problemen mit RL. Sie werden vielleicht neugierig sein, warum ich mir stattdessen DQN nicht vorstellen kann, einen alternativen und bekannteren RL-Algorithmus, der auch im
ATARI-Training verwendet wird . Es stellt sich heraus, dass Q-Learning zwar bekannt ist, aber nicht so perfekt. Die meisten Menschen entscheiden sich für Policy Gradient, einschließlich der Autoren des ursprünglichen
DQN-Artikels , die gezeigt haben, dass Policy Gradient bei guter Abstimmung sogar noch besser funktioniert als Q-Learning. PG ist vorzuziehen, weil es explizit ist: Es gibt eine klare Politik und einen kohärenten Ansatz, der die erwarteten Belohnungen direkt optimiert. Als Beispiel lernen wir, wie man ATARI Pong spielt: von Grund auf, von rohen Pixeln bis zu einem Policy Gradient mit einem neuronalen Netzwerk. Und wir werden das alles in 130 Zeilen Python einfügen. (
Hauptlink ) Mal sehen, wie das gemacht wird.

 Oben: Tischtennis. Unten: Ping-Pong-Präsentation als Sonderfall des Markov-Entscheidungsprozesses (MDP) : Jeder Scheitelpunkt des Diagramms entspricht einem bestimmten Spielzustand, und die Kanten bestimmen die Wahrscheinlichkeiten für den Übergang in andere Zustände. Jede Rippe bestimmt auch die Belohnung. Das Ziel ist es, aus jedem Staat den besten Weg zu finden, um die Belohnung zu maximieren
Oben: Tischtennis. Unten: Ping-Pong-Präsentation als Sonderfall des Markov-Entscheidungsprozesses (MDP) : Jeder Scheitelpunkt des Diagramms entspricht einem bestimmten Spielzustand, und die Kanten bestimmen die Wahrscheinlichkeiten für den Übergang in andere Zustände. Jede Rippe bestimmt auch die Belohnung. Das Ziel ist es, aus jedem Staat den besten Weg zu finden, um die Belohnung zu maximierenPing Pong zu spielen ist ein großartiges Beispiel für eine RL-Herausforderung. In der ATARI 2600-Version spielen wir selbst einen Schläger. Ein weiterer Schläger wird von einem eingebauten Algorithmus gesteuert. Wir müssen den Ball schlagen, damit der andere Spieler keine Zeit hat, ihn zu schlagen. Ich hoffe, es ist nicht nötig zu erklären, was Ping Pong ist. Auf einer niedrigen Ebene funktioniert das Spiel wie folgt: Wir erhalten einen Bilderrahmen - ein Array von 210 x 160 x 3 Bytes - und entscheiden, ob wir den Schläger nach OBEN oder UNTEN bewegen möchten. Das heißt, wir haben nur zwei Möglichkeiten, um das Spiel zu verwalten. Nach jeder Auswahl führt der Spielesimulator seine Aktion aus und gibt uns eine Belohnung: entweder +1 Belohnung, wenn der Ball den Schläger des Gegners passiert hat, oder -1, wenn wir den Ball verpasst haben. Ansonsten 0. Und natürlich ist es unser Ziel, den Schläger so zu bewegen, dass wir so viel Belohnung wie möglich bekommen.
Denken Sie bei der Überlegung einer Lösung daran, dass wir versuchen werden, so wenige Annahmen über Pong zu treffen, da dies in der Praxis nicht besonders wichtig ist. Bei großen Aufgaben wie der Manipulation von Robotern, der Montage und der Navigation berücksichtigen wir viel mehr Dinge. Pong ist nur ein lustiger Spielzeug-Testfall, mit dem wir spielen, während wir herausfinden, wie man sehr allgemeine KI-Systeme schreibt, die eines Tages beliebige nützliche Aufgaben ausführen können.
Neuronales Netz als RL-Richtlinie . Zunächst werden wir die sogenannte Richtlinie festlegen, die unser Spieler (oder "Agent") implementiert. ((*) "Agent", "Umgebung" und "Agentenrichtlinie" sind Standardbegriffe aus der RL-Theorie). Die Richtlinienfunktion ist in unserem Fall ein neuronales Netzwerk. Sie akzeptiert den Stand des Spiels am Eingang und am Ausgang entscheidet sie, was zu tun ist - nach oben oder unten. Als unseren bevorzugten einfachen Berechnungsblock verwenden wir ein zweischichtiges neuronales Netzwerk, das Rohbildpixel (insgesamt 100.800 Zahlen (210 * 160 * 3)) verwendet und eine einzelne Zahl erzeugt, die die Wahrscheinlichkeit angibt, den Schläger nach oben zu bewegen. Bitte beachten Sie, dass die Verwendung der stochastischen Politik Standard ist, was bedeutet, dass wir nur die Wahrscheinlichkeit einer Aufwärtsbewegung erzeugen. Um den tatsächlichen Zug zu erhalten, verwenden wir diese Wahrscheinlichkeit. Der Grund dafür wird klarer, wenn wir über Training sprechen.
 Unsere Richtlinienfunktion besteht aus einem 2-lagigen, vollständig verbundenen neuronalen Netzwerk
Unsere Richtlinienfunktion besteht aus einem 2-lagigen, vollständig verbundenen neuronalen NetzwerkNehmen wir genauer an, dass wir am Eingang einen Vektor X erhalten, der einen Satz vorverarbeiteter Pixel enthält. Dann müssen wir mit Python \ numpy rechnen:
h = np.dot(W1, x)
In diesem Fragment sind W1 und W2 zwei Matrizen, die wir zufällig initialisieren. Wir verwenden keine Voreingenommenheit, weil wir wollten. Beachten Sie, dass wir am Ende die Nichtlinearität des Sigmoid verwenden, wodurch die Ausgabewahrscheinlichkeit auf den Bereich [0,1] reduziert wird. Intuitiv können Neuronen in einer verborgenen Schicht (deren Gewichte sich in W1 befinden) verschiedene Spielszenarien erkennen (zum Beispiel ist der Ball oben und unser Schläger ist in der Mitte), und Gewichte in W2 können dann entscheiden, ob wir jeweils steigen sollen oder runter. Die anfänglichen zufälligen W1 und W2 verursachen natürlich zuerst Krämpfe und Krämpfe in unserem Neurospieler, was ihn mit einem Dummkopf-Autisten an der Steuerung eines Flugzeugs gleichsetzt. Die einzige Aufgabe besteht nun darin, W1 und W2 zu finden, was zu einem guten Spiel führt!
Es gibt eine Bemerkung zur Pixelvorverarbeitung - idealerweise müssen Sie mindestens 2 Frames in das neuronale Netzwerk übertragen, damit es Bewegungen erkennen kann. Um die Situation zu vereinfachen, wenden wir die Differenz zweier Frames an. Das heißt, wir subtrahieren den aktuellen und den vorherigen Frame und wenden die Differenz erst dann auf die Eingabe des neuronalen Netzwerks an.
Klingt nach etwas Unmöglichem. An dieser Stelle möchte ich Sie bitten, zu schätzen, wie komplex das RL-Problem ist. Wir erhalten 100 800 Nummern (210 x 160 x 3) und senden sie an unser neuronales Netzwerk, das die Richtlinien des Spielers implementiert (die im Übrigen leicht etwa eine Million Parameter in den Matrizen W1 und W2 enthalten). Nehmen wir an, wir beschließen irgendwann, nach oben zu gehen. Der Spielesimulator kann antworten, dass wir diesmal 0 Auszeichnungen erhalten und uns weitere 100 800 Zahlen für den nächsten Frame geben. Wir können diesen Vorgang hunderte Male wiederholen, bevor wir eine Belohnung ungleich Null erhalten! Nehmen wir zum Beispiel an, wir haben endlich eine Belohnung von +1 erhalten. Das ist wunderbar, aber wie können wir dann sagen - was hat dazu geführt? War dies die Aktion, die wir gerade gemacht haben? Oder vielleicht 76 Frames zurück? Oder war dies zuerst mit Frame 10 verbunden, und dann haben wir in Frame 90 etwas richtig gemacht? Und wie finden wir heraus, welche der Millionen "Stifte" gedreht werden müssen, um in Zukunft noch erfolgreicher zu sein? Wir nennen dies die Aufgabe, den Vertrauenskoeffizienten für bestimmte Aktionen zu bestimmen. Im speziellen Fall mit dem Pong wissen wir, dass wir +1 erhalten, wenn der Ball den Gegner passiert hat. Der wahre Grund ist, dass wir den Ball versehentlich ein paar Frames zurück auf einen guten Weg getreten haben und jede nachfolgende Aktion, die wir ausgeführt haben, ihn überhaupt nicht beeinflusst hat. Mit anderen Worten, wir stehen vor einem sehr komplexen Rechenproblem, und alles sieht ziemlich düster aus.
Training mit einem Lehrer. Bevor wir uns mit dem Gradienten der Politik (PG) befassen, möchte ich kurz an das Unterrichten mit einem Lehrer erinnern, da RL, wie wir sehen werden, sehr ähnlich ist. Siehe die folgende Tabelle. Im normalen Unterricht mit einem Lehrer übertragen wir das Bild in das Netzwerk und erhalten am Ausgang einige numerische Wahrscheinlichkeiten für die Klassen. In unserem Fall haben wir beispielsweise zwei Klassen: UP und DOWN. Ich verwende die logarithmischen Wahrscheinlichkeiten (-1,2, -0,36) anstelle der Wahrscheinlichkeiten im 30% - und 70% -Format, weil wir die logarithmische Wahrscheinlichkeit der richtigen Klasse (oder Bezeichnung) optimieren. Dies macht mathematische Berechnungen eleganter und entspricht der Optimierung nur der Wahrscheinlichkeit, da der Logarithmus monoton ist.
In der Ausbildung mit einem Lehrer haben wir sofort Zugriff auf die richtige Klasse (Etikett). In der Trainingsphase werden sie uns genau sagen, welcher richtige Schritt gerade benötigt wird (sagen wir, es ist UP, Label 0), obwohl das neuronale Netzwerk möglicherweise anders denkt. Daher berechnen wir den Gradienten
n a b l a W l o g p ( y = U P m i d x ) um die Netzwerkeinstellungen zu optimieren. Dieser Gradient sagt uns nur, wie wir jeden unserer Millionen von Parametern ändern sollen, damit das Netzwerk UP in derselben Situation mit etwas höherer Wahrscheinlichkeit vorhersagt. Beispielsweise kann einer von einer Million Parametern im Netzwerk einen Gradienten von -2,1 haben. Wenn wir diesen Parameter um einen kleinen positiven Wert (z. B. 0,001) erhöhen, verringert sich die logarithmische Wahrscheinlichkeit von UP um 2,1 * 0,001. (Abnahme aufgrund des negativen Vorzeichens). Wenn wir den Gradienten anwenden und dann den Parameter mithilfe des Backpropagation-Algorithmus aktualisieren, gibt unser Netzwerk eine hohe Wahrscheinlichkeit für UP, wenn es in Zukunft dasselbe oder ein sehr ähnliches Bild sieht.
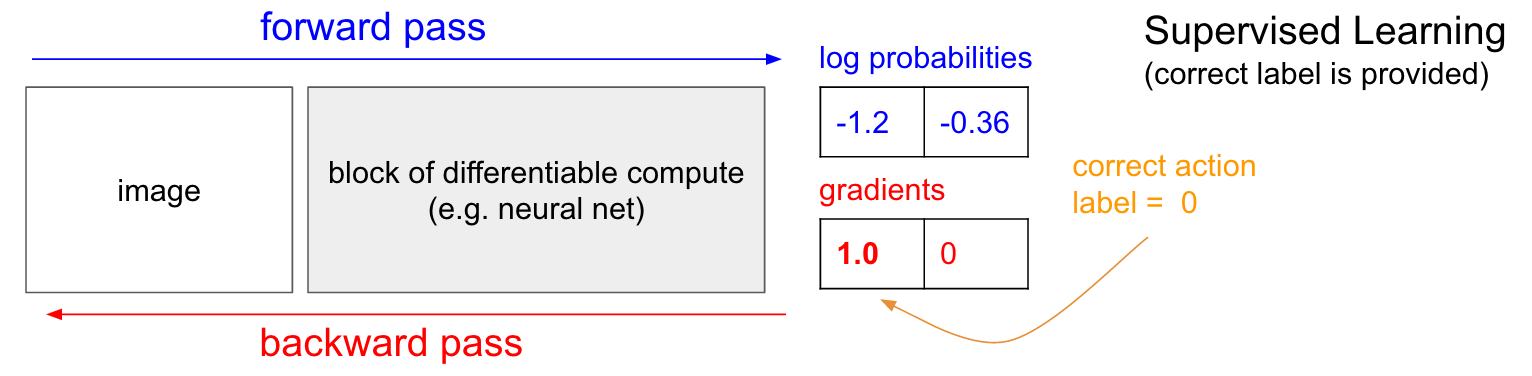 Gradienten der Politik (PG)
Gradienten der Politik (PG) . OK, aber was machen wir, wenn wir nicht das richtige Etikett für das Verstärkungstraining haben? Hier ist eine Lösung für PG (siehe Abbildung unten noch einmal). Unser neuronales Netzwerk berechnete die Wahrscheinlichkeit eines Anstiegs von 30% (logprob -1,2) und von DOWN um 70% (logprob -0,36). Jetzt treffen wir eine Auswahl aus dieser Distribution und geben an, welche Aktion wir ausführen werden. Zum Beispiel haben sie DOWN gewählt und diese Aktion an den Spielesimulator gesendet. Beachten Sie an dieser Stelle eine interessante Tatsache: Wir könnten den Gradienten für die DOWN-Aktion sofort berechnen und anwenden, wie wir es beim Unterrichten mit einem Lehrer getan haben, und dadurch die Wahrscheinlichkeit erhöhen, dass das Netzwerk die DOWN-Aktion in Zukunft ausführt. So können wir diesen Gradienten sofort erkennen und uns daran erinnern. Aber das Problem ist, dass wir im Moment noch nicht wissen - ist es gut, nach unten zu gehen?
Das Interessanteste ist jedoch, dass wir einfach etwas warten und den Farbverlauf später anwenden können! In Pong können wir bis zum Ende des Spiels warten, dann die Belohnung, die wir erhalten haben (entweder +1, wenn wir gewonnen haben, oder -1, wenn wir verloren haben), als Faktor für den Gradienten eingeben. Wenn wir also -1 für die DOWN-Wahrscheinlichkeit einführen und die Back-Propagation durchführen, werden wir die Netzwerkparameter neu erstellen, sodass es weniger wahrscheinlich ist, dass die DOWN-Aktion in Zukunft ausgeführt wird, wenn dasselbe Bild auftritt, da die Übernahme dieser Aktion dazu geführt hat, dass wir das Spiel verloren haben. Das heißt, wir müssen uns irgendwie an alle Aktionen (Ein- und Ausgänge des neuronalen Netzwerks) in einer Episode des Spiels erinnern und basierend auf diesem Array das neuronale Netzwerk auf die gleiche Weise verdrehen wie beim Unterrichten mit einem Lehrer.
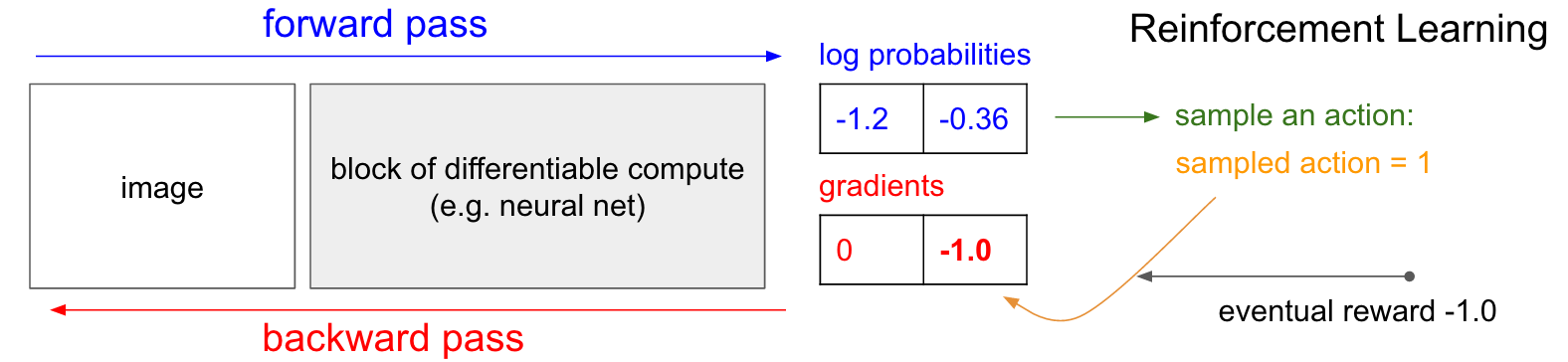
Und das ist alles, was benötigt wird: Wir haben eine stochastische Politik, die Maßnahmen auswählt, und in Zukunft werden Maßnahmen, die letztendlich zu guten Ergebnissen führen, und Maßnahmen, die zu schlechten Ergebnissen führen, nicht gefördert. Außerdem sollte die Belohnung nicht einmal +1 oder -1 betragen, wenn wir letztendlich das Spiel gewinnen. Es kann ein beliebiger Wert derselben Bedeutung sein. Wenn zum Beispiel alles wirklich gut funktioniert, könnte die Belohnung 10,0 sein, die wir dann als Farbverlauf verwenden, um die Backprop-Backpropagation zu starten. Das ist das Schöne an neuronalen Netzen. Ihre Verwendung mag wie ein Scherz erscheinen: Sie dürfen 1 Million Parameter in 1 Teraflop von Berechnungen einbauen lassen, und Sie können das Programm lernen lassen, beliebige Dinge mit stochastischem Gradientenabstieg (SGD) zu tun. Es sollte nicht funktionieren, aber es ist lustig, dass wir in einem Universum leben, in dem es funktioniert.
Wenn wir einfache Brettspiele wie Dame spielen würden, wäre die Reihenfolge ungefähr gleich. Es gibt einen spürbaren Unterschied zu Minimax- oder Alpha-Beta-Clipping-Algorithmen. Bei diesen Algorithmen blickt das Programm ein paar Schritte voraus, kennt die Spielregeln und analysiert Millionen von Positionen. Beim RL-Ansatz werden nur tatsächlich ausgeführte Bewegungen analysiert. Gleichzeitig freut sich das neuronale Netz nicht, da es nichts über die Spielregeln weiß.
Trainingsreihenfolge im Detail. Wir erstellen und initialisieren ein neuronales Netzwerk mit einigen W1, W2 und spielen 100 Pong-Spiele (wir nennen es den „Run-In“ der Politik, Policy Rollouts). Angenommen, jedes Spiel besteht aus 200 Frames. Insgesamt haben wir also 100 * 200 = 20.000 Entscheidungen getroffen, um nach oben oder unten zu gehen. Und für jede der Lösungen kennen wir einen Gradienten, der uns sagt, wie sich die Parameter ändern sollen, wenn wir diese Lösung in diesem Zustand in Zukunft fördern oder verbieten wollen. Jetzt müssen wir nur noch jede Entscheidung, die wir treffen, als gut oder schlecht bezeichnen. Angenommen, wir haben 12 Spiele gewonnen und 88 verloren. Wir werden alle 200 * 12 = 2400 Entscheidungen treffen, die wir in den Gewinnspielen getroffen haben, und ein positives Update durchführen (für jede Aktion einen Gradienten von +1,0 eingeben, Backprop ausführen und die Parameter aktualisieren Förderung der Maßnahmen, die wir unter all diesen Bedingungen gewählt haben). Und wir werden die anderen 200 * 88 = 17.600 Entscheidungen treffen, die wir beim Verlust von Spielen getroffen haben, und ein negatives Update vornehmen (ohne zu genehmigen, was wir getan haben). Und das ist alles was es braucht. Das Netzwerk wiederholt jetzt eher Aktionen, die funktioniert haben, und etwas weniger wahrscheinlich Aktionen, die nicht funktioniert haben. Jetzt spielen wir weitere 100 Spiele mit unserer neuen, leicht verbesserten Richtlinie und wiederholen dann die Anwendung von Verläufen.
 Cartoon-Schema von 4 Spielen. Jeder schwarze Kreis ist eine Art Spielstatus (drei Beispiele für Status sind unten dargestellt), und jeder Pfeil ist ein Übergang, der mit der ausgewählten Aktion markiert ist. In diesem Fall haben wir 2 Spiele gewonnen und 2 Spiele verloren. Wir haben die beiden Spiele, die wir gewonnen haben, genommen und jede Aktion, die wir in dieser Episode gemacht haben, leicht ermutigt. Umgekehrt werden wir auch die beiden verlorenen Spiele nehmen und jede einzelne Aktion, die wir in dieser Episode durchgeführt haben, leicht entmutigen.
Cartoon-Schema von 4 Spielen. Jeder schwarze Kreis ist eine Art Spielstatus (drei Beispiele für Status sind unten dargestellt), und jeder Pfeil ist ein Übergang, der mit der ausgewählten Aktion markiert ist. In diesem Fall haben wir 2 Spiele gewonnen und 2 Spiele verloren. Wir haben die beiden Spiele, die wir gewonnen haben, genommen und jede Aktion, die wir in dieser Episode gemacht haben, leicht ermutigt. Umgekehrt werden wir auch die beiden verlorenen Spiele nehmen und jede einzelne Aktion, die wir in dieser Episode durchgeführt haben, leicht entmutigen.Wenn Sie darüber nachdenken, werden Sie einige lustige Eigenschaften finden. Was wäre zum Beispiel, wenn wir in Bild 50 eine gute Aktion ausgeführt hätten, den Ball richtig getreten hätten, dann aber in Bild 150 den Ball verpasst hätten? Da wir das Spiel verloren haben, wird jede einzelne Aktion jetzt als schlecht markiert. Verhindert dies nicht den korrekten Treffer in Bild 50? Sie haben Recht - für diese Party wird es so sein. Wenn Sie jedoch den Prozess in Tausenden / Millionen von Spielen berücksichtigen, erhöht die korrekte Ausführung des Rebounds Ihre Gewinnwahrscheinlichkeit in der Zukunft. Im Durchschnitt werden Sie mehr positive als negative Updates für einen richtigen Schlägerschlag sehen. Und die Implementierungspolitik für neuronale Netze wird letztendlich die richtigen Reaktionen hervorrufen.
Update: Der 9. Dezember 2016 ist eine alternative Ansicht. In meiner obigen Erklärung verwende ich Begriffe wie "Definieren eines Gradienten und Backprop-Back-Propagation", was eine definitiv geschickte Technik ist. Wenn Sie es gewohnt sind, Ihren eigenen Backprop-Backspread-Code zu schreiben oder Torch zu verwenden, können Sie die Verläufe vollständig steuern. Wenn Sie jedoch an Theano oder TensorFlow gewöhnt sind, werden Sie ein wenig verwirrt sein, da der Backprop-Code vollständig automatisiert und schwer anzupassen ist. In diesem Fall kann die folgende alternative Ansicht produktiver sein. Im Unterricht mit einem Lehrer ist das übliche Ziel die Maximierung
s u m i l o g p ( y i m i d x i ) wo
x i , y i - Trainingsbeispiele (wie Bilder und deren Etiketten). Die Anwendung des Gradienten auf die Richtlinienfunktion fällt genau mit der Ausbildung beim Lehrer zusammen, jedoch mit zwei kleinen Unterschieden: 1) Wir haben nicht die richtigen Bezeichnungen
y i Daher verwenden wir als „gefälschtes Etikett“ die Aktion, die wir erhalten haben, um aus der Richtlinie auszuwählen, als sie angezeigt wurde
x i und 2) Wir führen für jede Aktion einen anderen Zweckmäßigkeitskoeffizienten (Vorteil) ein. Am Ende sieht unser Verlust also so aus
s u m i A i l o g p ( y i m i d x i ) wo
y i - Dies ist die Aktion, die wir mit der Probe durchgeführt haben, und
Ai Ist die Zahl, die wir den Zweckmäßigkeitskoeffizienten nennen. Zum Beispiel im Fall von Pong der Wert
Ai Es könnte 1,0 sein, wenn wir die Episode gewinnen, und -1,0, wenn wir verlieren. Dies stellt sicher, dass wir die Wahrscheinlichkeit der Aufzeichnung von Aktionen, die zu einem guten Ergebnis geführt haben, maximieren und die Wahrscheinlichkeit der Aufzeichnung von Aktionen, die dies nicht getan haben, minimieren. Und neutrale Aktionen aufgrund vieler Aufrufe werden die Funktion der Politik nicht besonders beeinträchtigen. Daher ist das verstärkte Lernen genau das gleiche wie das Lernen mit einem Lehrer, jedoch mit einem sich ständig ändernden Datensatz (Episoden), mit einem zusätzlichen Faktor.
Erweiterte Machbarkeitsfunktionen. Ich habe auch ein bisschen mehr Informationen versprochen. Bisher haben wir die Richtigkeit jeder einzelnen Aktion danach bewertet, ob wir gewinnen oder nicht. In einem allgemeineren RL-Setup erhalten wir eine „bedingte Belohnung“.
rt für jeden Schritt, abhängig von der Schrittnummer oder der Zeit. Eine der gängigen Optionen ist die Verwendung eines diskontierten Koeffizienten, sodass die „mögliche Belohnung“ im obigen Diagramm lautet
Rt= sum inftyk=0 gammakrt+k wo
gamma Ist eine Zahl von 0 bis 1, die als Abzinsungskoeffizient bezeichnet wird (z. B. 0,99). Der Ausdruck besagt, dass die Stärke, mit der wir zum Handeln ermutigen, die gewichtete Summe aller Belohnungen ist, aber nachfolgende Belohnungen sind exponentiell weniger wichtig. Das heißt, kurze Aktionsketten werden besser gefördert, und der Schwanz langer Aktionsketten wird weniger wichtig. In der Praxis müssen Sie sie auch normalisieren. Nehmen wir zum Beispiel an, wir berechnen
Rt für alle 20.000 Aktionen in einer Serie von 100 Folgen des Spiels. Eine sehr gute Idee ist es, diese Werte zu normalisieren (den Durchschnitt zu subtrahieren, durch die Standardabweichung zu dividieren), bevor wir sie mit dem Backprop-Algorithmus verbinden. Daher ermutigen und entmutigen wir immer etwa die Hälfte der durchgeführten Aktionen. Dies reduziert Schwankungen und macht die Politik konvergenter. Eine ausführlichere Studie finden Sie unter [
Link ].
Abgeleitet von einer Richtlinienfunktion. Ich wollte auch kurz beschreiben, wie Gradienten mathematisch genommen werden. Die Gradienten der Funktion der Politik sind ein Sonderfall einer allgemeineren Theorie. Der allgemeine Fall ist, wenn wir einen Ausdruck der Form haben
Ex simp(x mid theta)[f(x)] d.h. die Erwartung einer Skalarfunktion
f(x) mit einer gewissen Verteilung seines Parameters
p(x; theta) durch einen Vektor parametrisiert
theta . Dann
f(x) wird unsere Belohnungsfunktion (oder die Funktion der Zweckmäßigkeit im allgemeineren Sinne) und die diskrete Verteilung
p(x) wird unsere Politik sein, die tatsächlich die Form hat
p(a midI) Geben Sie die Wahrscheinlichkeiten einer Aktion für das Bild an
I . Dann interessiert uns, wie wir die Verteilung von p durch seine Parameter verschieben können
theta zu vergrößern
f (d. h. wie ändern wir die Netzwerkeinstellungen, damit die Aktionen eine höhere Belohnung erhalten). Wir haben das:
\ begin {align} \ nabla _ {\ theta} E_x [f (x)] & = \ nabla _ {\ theta} \ sum_x p (x) f (x) & \ text {Definition der Erwartung} \\ & = \ sum_x \ nabla _ {\ theta} p (x) f (x) & \ text {Summe und Gradient tauschen} \\ & = \ sum_x p (x) \ frac {\ nabla _ {\ theta} p (x)} {p (x)} f (x) & \ text {multiplizieren und dividieren durch} p (x) \\ & = \ sum_x p (x) \ nabla _ {\ theta} \ log p (x) f (x) & \ text {benutze die Tatsache, dass} \ nabla _ {\ theta} \ log (z) = \ frac {1} {z} \ nabla _ {\ theta} z \\ & = E_x [f (x) \ nabla _ {\ theta} \ log p (x)] & \ text {Definition der Erwartung} \ end {align}Ich werde versuchen, dies zu erklären. Wir haben eine gewisse Verteilung
p(x; theta) (Ich habe die Abkürzung verwendet
p(x) aus denen wir bestimmte Werte auswählen können. Beispielsweise kann es sich um eine Gaußsche Verteilung handeln, aus der ein Zufallszahlengenerator abtastet. Für jedes Beispiel können wir auch die Schätzfunktion berechnen
f , was nach dem aktuellen Beispiel eine skalare Schätzung ergibt. Die resultierende Gleichung sagt uns, wie wir die Verteilung durch ihre Parameter verschieben sollen
theta wenn wir weitere Beispiele für darauf basierende Maßnahmen wünschen, um höhere Raten zu erzielen
f . Wir nehmen einige Beispiele für Maßnahmen
x und ihre Bewertung
f(x) und auch für jedes x bewerten wir auch den zweiten Term
nabla theta logp(x; theta) . Was ist dieser Multiplikator? Dies ist genau der Vektor - der Gradient, der uns die Richtung im Parameterraum gibt, was zu einer Erhöhung der Wahrscheinlichkeit einer bestimmten Aktion führt
x . Mit anderen Worten, wenn wir θ in die Richtung drücken
nabla theta logp(x; theta) würden wir sehen, dass die neue Wahrscheinlichkeit dieser Aktion leicht zunehmen wird. Wenn Sie auf die Formel zurückblicken, heißt es, dass wir diese Richtung einschlagen und den Skalarwert damit multiplizieren sollten
f(x) . Dies stellt sicher, dass Beispiele für Aktionen mit einer höheren Bewertung (in unserem Fall eine Belohnung) stärker „ziehen“ als Beispiele mit einem niedrigeren Indikator. Wenn wir daher basierend auf mehreren Beispielen aus aktualisieren
p würde sich die Wahrscheinlichkeitsdichte in Richtung höherer resultierender Spielpunkte verschieben, was die Wahrscheinlichkeit erhöht, Beispiele für Aktionen mit hohen Belohnungen zu erhalten. Es ist wichtig, dass der Gradient nicht aus der Funktion übernommen wird
f , da es in der Regel undifferenziert und unvorhersehbar sein kann. A.
p differenzierbar durch
theta . Also
p ist eine kontinuierlich einstellbare diskrete Verteilung, bei der Sie die Wahrscheinlichkeiten einzelner Aktionen anpassen können. Das nehmen wir auch an
p normalisiert.
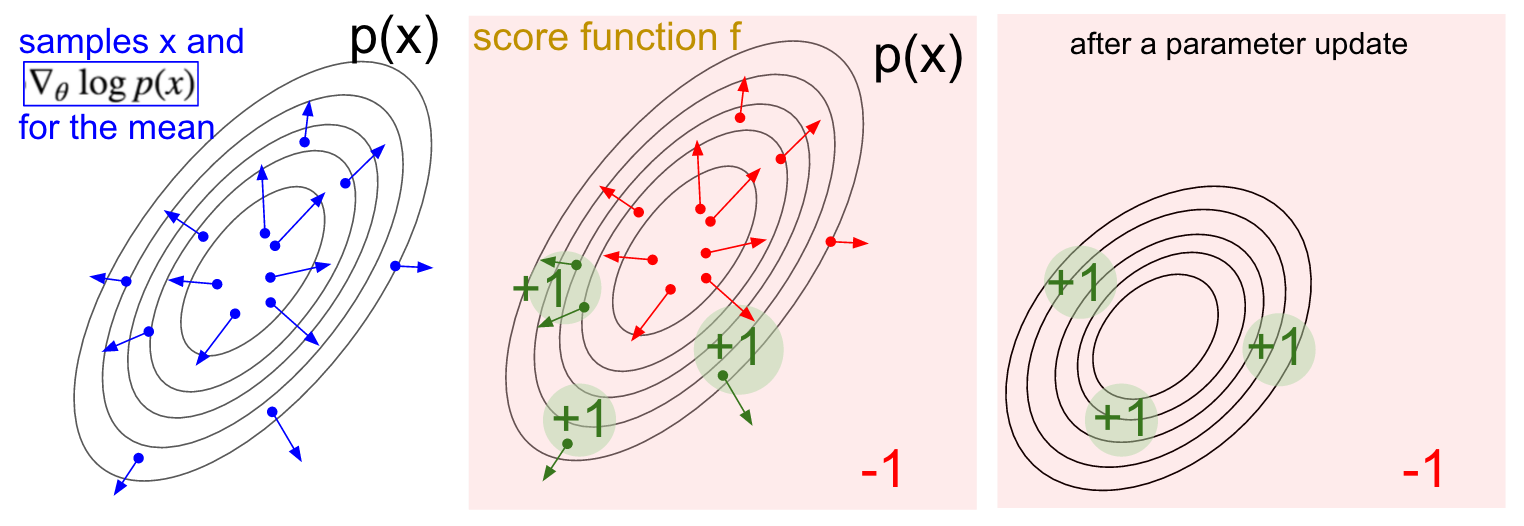 Gradientenvisualisierung. Links: Gaußsche Verteilung und einige Beispiele davon (blaue Punkte). An jedem blauen Punkt zeichnen wir auch den Gradienten der logarithmischen Wahrscheinlichkeit in Bezug auf den Durchschnittsparameter auf. Der Pfeil gibt die Richtung an, in die der durchschnittliche Verteilungswert verschoben werden soll, um die Wahrscheinlichkeit dieser Beispielaktion zu erhöhen. In der Mitte: Es wurde eine Bewertungsfunktion hinzugefügt, die überall -1 ergibt, außer in einigen kleinen Regionen +1 (beachten Sie, dass dies eine beliebige und nicht unbedingt differenzierbare Skalarfunktion sein kann). Die Pfeile sind jetzt farbcodiert, da aufgrund der Multiplikation alle grünen Pfeile mit einer positiven Bewertung und die negativen roten Pfeile gemittelt werden. Rechts: Nach dem Aktualisieren der Parameter drücken uns die grünen Pfeile und die umgekehrten roten Pfeile nach links und unten. Proben aus dieser Verteilung haben jetzt auf Wunsch eine höhere erwartete Bewertung.
Gradientenvisualisierung. Links: Gaußsche Verteilung und einige Beispiele davon (blaue Punkte). An jedem blauen Punkt zeichnen wir auch den Gradienten der logarithmischen Wahrscheinlichkeit in Bezug auf den Durchschnittsparameter auf. Der Pfeil gibt die Richtung an, in die der durchschnittliche Verteilungswert verschoben werden soll, um die Wahrscheinlichkeit dieser Beispielaktion zu erhöhen. In der Mitte: Es wurde eine Bewertungsfunktion hinzugefügt, die überall -1 ergibt, außer in einigen kleinen Regionen +1 (beachten Sie, dass dies eine beliebige und nicht unbedingt differenzierbare Skalarfunktion sein kann). Die Pfeile sind jetzt farbcodiert, da aufgrund der Multiplikation alle grünen Pfeile mit einer positiven Bewertung und die negativen roten Pfeile gemittelt werden. Rechts: Nach dem Aktualisieren der Parameter drücken uns die grünen Pfeile und die umgekehrten roten Pfeile nach links und unten. Proben aus dieser Verteilung haben jetzt auf Wunsch eine höhere erwartete Bewertung.Ich hoffe der Zusammenhang mit RL ist klar.
Unsere Politik gibt uns Beispiele für Maßnahmen, von denen einige besser funktionieren als andere (gemessen an der Zweckmäßigkeit). Sie können die Richtlinieneinstellungen ändern, indem Sie den Verlauf der ausgewählten Aktionen ausführen, ihn mit der Bewertung multiplizieren und alles hinzufügen, was wir oben getan haben. Für eine gründlichere Schlussfolgerung empfehle ich einen Vortrag von John Shulman.
Schulung. Nun, wir haben die Prinzipien von Gradienten der Funktion der Politik entwickelt. Ich habe den gesamten Ansatz in einem Python-Skript mit 130 Zeilen implementiert , das den vorgefertigten ATAI 2600 Pong-Emulator von OpenAI Gym verwendet. Ich habe ein zweischichtiges neuronales Netzwerk mit 200 Hidden-Layer-Neuronen unter Verwendung des RMSProp-Algorithmus für eine Reihe von 10 Episoden trainiert (jede Episode nach den Regeln besteht aus mehreren Ballzügen und die Episode erzielt weiterhin 21 Punkte). Ich habe nicht zu viele Hyperparameter eingerichtet und mit meinem langsamen Macbook experimentiert, aber nach einem dreitägigen Training habe ich eine Richtlinie erhalten, die etwas besser spielt als der eingebaute Player. Die Gesamtzahl der Episoden betrug ungefähr 8.000, so dass der Algorithmus ungefähr 200.000 Pong-Spiele spielte, was ziemlich viel ist, und insgesamt ~ 800 Aktualisierungen der Gewichte erzeugte. Wenn ich mit ConvNets auf der GPU trainierte, konnte ich innerhalb weniger Tage großartige Ergebnisse erzielen, und wenn ich die Hyperparameter optimierte, konnte ich immer gewinnen. Ich habe jedoch nicht zu viel Zeit mit Rechnen oder Einrichten verbracht.Stattdessen haben wir Pong AI, das die Hauptideen veranschaulicht und recht gut funktioniert: ..Wir können uns auch die erhaltenen Gewichte des neuronalen Netzwerks ansehen. Dank der Vorverarbeitung ist jeder unserer Eingänge ein Differenzbild von 80 x 80 (aktuelles Bild minus vorheriges Bild). Jedes Neuron aus Schicht W1 ist mit einer verborgenen Schicht W2 verbunden, die aus 200 Neuronen besteht. Die Anzahl der Anleihen beträgt 80 * 80 * 200. Versuchen wir, diese Zusammenhänge zu analysieren. Wir werden alle Neuronen der W2-Schicht sortieren und visualisieren, welche Gewichte dazu führen. Aus den Skalen, die von W1-Neuronen zu einem W2-Neuron führen, werden 80x80-Bilder erstellt. Unten sind 40 solcher Bilder von W2 (insgesamt 200). Weiße Pixel sind positive Gewichte und schwarze sind negative Gewichte. Beachten Sie, dass mehrere W2-Neuronen auf einen fliegenden Ball abgestimmt sind, der in gestrichelten Linien codiert ist. In einem Spiel kann der Ball nur an einer Stelle sein,Daher sind diese Neuronen vielseitig einsetzbar und „schießen“, wenn sich der Ball irgendwo innerhalb dieser Linien befindet. Der Wechsel von Schwarz und Weiß ist interessant, denn wenn sich der Ball entlang der Bahn bewegt, schwingt die Aktivität des Neurons wie eine Sinuswelle. Und wegen ReLU wird er nur an bestimmten Positionen „schießen“. Die Bilder enthalten viel Rauschen, was weniger wäre, wenn ich die L2-Regularisierung verwenden würde.
..Wir können uns auch die erhaltenen Gewichte des neuronalen Netzwerks ansehen. Dank der Vorverarbeitung ist jeder unserer Eingänge ein Differenzbild von 80 x 80 (aktuelles Bild minus vorheriges Bild). Jedes Neuron aus Schicht W1 ist mit einer verborgenen Schicht W2 verbunden, die aus 200 Neuronen besteht. Die Anzahl der Anleihen beträgt 80 * 80 * 200. Versuchen wir, diese Zusammenhänge zu analysieren. Wir werden alle Neuronen der W2-Schicht sortieren und visualisieren, welche Gewichte dazu führen. Aus den Skalen, die von W1-Neuronen zu einem W2-Neuron führen, werden 80x80-Bilder erstellt. Unten sind 40 solcher Bilder von W2 (insgesamt 200). Weiße Pixel sind positive Gewichte und schwarze sind negative Gewichte. Beachten Sie, dass mehrere W2-Neuronen auf einen fliegenden Ball abgestimmt sind, der in gestrichelten Linien codiert ist. In einem Spiel kann der Ball nur an einer Stelle sein,Daher sind diese Neuronen vielseitig einsetzbar und „schießen“, wenn sich der Ball irgendwo innerhalb dieser Linien befindet. Der Wechsel von Schwarz und Weiß ist interessant, denn wenn sich der Ball entlang der Bahn bewegt, schwingt die Aktivität des Neurons wie eine Sinuswelle. Und wegen ReLU wird er nur an bestimmten Positionen „schießen“. Die Bilder enthalten viel Rauschen, was weniger wäre, wenn ich die L2-Regularisierung verwenden würde. Was passiert nicht? Wir haben also gelernt, wie man mit dem Gradienten der Richtlinienfunktion Pong auf Bildern spielt, und das funktioniert ziemlich gut. Bei diesem Ansatz handelt es sich um ein bizarres Formular zum Vorschlagen und Überprüfen, bei dem sich das Erraten auf das Ausführen unserer Richtlinien für mehrere Episoden des Spiels bezieht und das Überprüfen von Aktionen Aktionen fördert, die zu guten Ergebnissen führen. Im Allgemeinen entspricht dies dem aktuellen Stand unserer derzeitigen Herangehensweise an die Probleme des verstärkten Lernens. Wenn Sie den Algorithmus intuitiv verstehen und wissen, wie er funktioniert, sollten Sie zumindest ein wenig enttäuscht sein. Insbesondere wann funktioniert es nicht?Vergleichen Sie dies damit, wie eine Person lernen kann, Pong zu spielen. Sie selbst zeigen ihnen das Spiel und sagen etwas wie: „Sie steuern den Schläger und können ihn auf und ab bewegen. Ihre Aufgabe ist es, den Ball an einem anderen Spieler vorbei zu werfen, der vom integrierten Programm gesteuert wird.“ Und Sie können loslegen. Bitte beachten Sie einige Unterschiede:
Was passiert nicht? Wir haben also gelernt, wie man mit dem Gradienten der Richtlinienfunktion Pong auf Bildern spielt, und das funktioniert ziemlich gut. Bei diesem Ansatz handelt es sich um ein bizarres Formular zum Vorschlagen und Überprüfen, bei dem sich das Erraten auf das Ausführen unserer Richtlinien für mehrere Episoden des Spiels bezieht und das Überprüfen von Aktionen Aktionen fördert, die zu guten Ergebnissen führen. Im Allgemeinen entspricht dies dem aktuellen Stand unserer derzeitigen Herangehensweise an die Probleme des verstärkten Lernens. Wenn Sie den Algorithmus intuitiv verstehen und wissen, wie er funktioniert, sollten Sie zumindest ein wenig enttäuscht sein. Insbesondere wann funktioniert es nicht?Vergleichen Sie dies damit, wie eine Person lernen kann, Pong zu spielen. Sie selbst zeigen ihnen das Spiel und sagen etwas wie: „Sie steuern den Schläger und können ihn auf und ab bewegen. Ihre Aufgabe ist es, den Ball an einem anderen Spieler vorbei zu werfen, der vom integrierten Programm gesteuert wird.“ Und Sie können loslegen. Bitte beachten Sie einige Unterschiede:- - , , , . RL , . , ( ), , . . , , , , , , , , .
- , ( , , , ..), ( «» « , , , - - . .). «» / . , , ( ) ( , ).
- — (brute force), , . . , , , . , «» , . , , .
- , , . , , . .
 : : RL. , , . , . , 99% . , «» . : «», , - , - , - , , . « , ».Ich möchte auch die Tatsache betonen, dass im Gegenteil in vielen Spielen die Gradienten der Politik eine Person ziemlich leicht besiegen würden. Dies gilt insbesondere für Spiele mit häufigen Belohnungen, die eine genaue und schnelle Reaktion und ohne langfristige Planung erfordern. Kurzfristige Korrelationen zwischen Belohnungen und Aktionen können durch den PG-Ansatz leicht erkannt werden. Sie können ähnliche in unserem Agenten Pong sehen. Er entwickelt eine Strategie, wenn er einfach auf den Ball wartet und sich dann schnell bewegt, um ihn nur am äußersten Rand zu fangen, weshalb der Ball mit einer hohen vertikalen Geschwindigkeit springt. Der Agent gewinnt mehrere Siege hintereinander und wiederholt diese einfache Strategie. Es gibt viele Spiele (Flipper, Breakout), in denen Deep Q-Learning eine Person mit ihren einfachen und präzisen Aktionen in den Schlamm zieht und trampelt.Sobald Sie den „Trick“ verstanden haben, mit dem diese Algorithmen arbeiten, können Sie ihre Stärken und Schwächen verstehen. Insbesondere sind diese Algorithmen weit hinter den Menschen zurück, wenn es darum geht, abstrakte Ideen über Spiele zu entwickeln, mit denen Menschen schnell lernen können. Sobald der Computer auf die Anordnung der Pixel schaut und den Schlüssel, die Tür, bemerkt und sich denkt, dass es wahrscheinlich schön wäre, den Schlüssel zu nehmen und zur Tür zu gelangen. Derzeit gibt es nichts in der Nähe, und der Versuch, dorthin zu gelangen, ist ein aktives Forschungsgebiet.Nicht differenzierbare Berechnungen in neuronalen Netzen.Ich möchte eine weitere interessante Anwendung von Nicht-Gaming-Richtlinienverläufen erwähnen: Sie ermöglicht es uns, neuronale Netze mithilfe von Komponenten zu entwerfen und zu trainieren, die mit nicht differenzierbarem Computing arbeiten (oder interagieren). Diese Idee wurde erstmals 1992 von Williams eingeführt . und wurde kürzlich in wiederkehrenden visuellen Aufmerksamkeitsmodellen populär gemacht .wird im Kontext eines Modells, das ein Bild mit einer Folge von engen fovealen Blicken mit niedriger Auflösung verarbeitet, als „enge Aufmerksamkeit“ bezeichnet, ähnlich wie unser Auge Objekte mit einer laufenden zentralen Sicht untersucht. Bei jeder Iteration empfängt der RNN ein kleines Fragment des Bildes und wählt den Ort aus, der weiter untersucht werden muss. Zum Beispiel kann der RNN die Position (5.30) betrachten, ein kleines Fragment des Bildes erhalten, sich dann für (24, 50) usw. entscheiden. Es gibt einen Abschnitt des neuronalen Netzwerks, der auswählt, wo weiter gesucht werden soll, und es dann inspiziert. Leider ist diese Operation nicht differenzierbar, da wir nicht wissen, was passieren würde, wenn wir anderswo eine Probe nehmen würden. Betrachten Sie in einem allgemeineren Fall ein neuronales Netzwerk mit mehreren Ein- und Ausgängen:
: : RL. , , . , . , 99% . , «» . : «», , - , - , - , , . « , ».Ich möchte auch die Tatsache betonen, dass im Gegenteil in vielen Spielen die Gradienten der Politik eine Person ziemlich leicht besiegen würden. Dies gilt insbesondere für Spiele mit häufigen Belohnungen, die eine genaue und schnelle Reaktion und ohne langfristige Planung erfordern. Kurzfristige Korrelationen zwischen Belohnungen und Aktionen können durch den PG-Ansatz leicht erkannt werden. Sie können ähnliche in unserem Agenten Pong sehen. Er entwickelt eine Strategie, wenn er einfach auf den Ball wartet und sich dann schnell bewegt, um ihn nur am äußersten Rand zu fangen, weshalb der Ball mit einer hohen vertikalen Geschwindigkeit springt. Der Agent gewinnt mehrere Siege hintereinander und wiederholt diese einfache Strategie. Es gibt viele Spiele (Flipper, Breakout), in denen Deep Q-Learning eine Person mit ihren einfachen und präzisen Aktionen in den Schlamm zieht und trampelt.Sobald Sie den „Trick“ verstanden haben, mit dem diese Algorithmen arbeiten, können Sie ihre Stärken und Schwächen verstehen. Insbesondere sind diese Algorithmen weit hinter den Menschen zurück, wenn es darum geht, abstrakte Ideen über Spiele zu entwickeln, mit denen Menschen schnell lernen können. Sobald der Computer auf die Anordnung der Pixel schaut und den Schlüssel, die Tür, bemerkt und sich denkt, dass es wahrscheinlich schön wäre, den Schlüssel zu nehmen und zur Tür zu gelangen. Derzeit gibt es nichts in der Nähe, und der Versuch, dorthin zu gelangen, ist ein aktives Forschungsgebiet.Nicht differenzierbare Berechnungen in neuronalen Netzen.Ich möchte eine weitere interessante Anwendung von Nicht-Gaming-Richtlinienverläufen erwähnen: Sie ermöglicht es uns, neuronale Netze mithilfe von Komponenten zu entwerfen und zu trainieren, die mit nicht differenzierbarem Computing arbeiten (oder interagieren). Diese Idee wurde erstmals 1992 von Williams eingeführt . und wurde kürzlich in wiederkehrenden visuellen Aufmerksamkeitsmodellen populär gemacht .wird im Kontext eines Modells, das ein Bild mit einer Folge von engen fovealen Blicken mit niedriger Auflösung verarbeitet, als „enge Aufmerksamkeit“ bezeichnet, ähnlich wie unser Auge Objekte mit einer laufenden zentralen Sicht untersucht. Bei jeder Iteration empfängt der RNN ein kleines Fragment des Bildes und wählt den Ort aus, der weiter untersucht werden muss. Zum Beispiel kann der RNN die Position (5.30) betrachten, ein kleines Fragment des Bildes erhalten, sich dann für (24, 50) usw. entscheiden. Es gibt einen Abschnitt des neuronalen Netzwerks, der auswählt, wo weiter gesucht werden soll, und es dann inspiziert. Leider ist diese Operation nicht differenzierbar, da wir nicht wissen, was passieren würde, wenn wir anderswo eine Probe nehmen würden. Betrachten Sie in einem allgemeineren Fall ein neuronales Netzwerk mit mehreren Ein- und Ausgängen: Beachten Sie, dass die meisten blauen Pfeile wie gewohnt differenzierbar sind. Einige Ansichtstransformationen können jedoch auch eine undifferenzierte Auswahloperation enthalten, die rot hervorgehoben ist. Wir können einfach durch die blauen Pfeile in die entgegengesetzte Richtung gehen, aber der rote Pfeil ist eine Abhängigkeit, durch die wir den Backprop nicht rückwärts verbreiten können.Gradientenpolitik zur Rettung! Lassen Sie uns über den Teil des Netzwerks nachdenken, der die Abtastung durchführt, die als Funktion der stochastischen Politik dargestellt werden kann, die in ein großes neuronales Netzwerk eingebettet ist. Daher werden wir während des Trainings mehrere Beispiele erstellen (angegeben durch die folgenden Zweige) und dann Proben ermutigen, die letztendlich zu guten Ergebnissen führen (in diesem Fall zum Beispiel gemessen an den Verlusten am Ende). Mit anderen Worten, wir werden die in den blauen Pfeilen enthaltenen Parameter wie gewohnt mit dem Backprop trainieren, aber die im roten Pfeil enthaltenen Parameter werden jetzt unabhängig vom Rückwärtsdurchlauf mithilfe von Richtliniengradienten aktualisiert, wodurch Stichproben gefördert werden, die zu geringen Verlusten führen. Diese Idee wurde auch kürzlich gut gerahmt.Gradientenschätzung unter Verwendung stochastischer Berechnungsgraphen.
Beachten Sie, dass die meisten blauen Pfeile wie gewohnt differenzierbar sind. Einige Ansichtstransformationen können jedoch auch eine undifferenzierte Auswahloperation enthalten, die rot hervorgehoben ist. Wir können einfach durch die blauen Pfeile in die entgegengesetzte Richtung gehen, aber der rote Pfeil ist eine Abhängigkeit, durch die wir den Backprop nicht rückwärts verbreiten können.Gradientenpolitik zur Rettung! Lassen Sie uns über den Teil des Netzwerks nachdenken, der die Abtastung durchführt, die als Funktion der stochastischen Politik dargestellt werden kann, die in ein großes neuronales Netzwerk eingebettet ist. Daher werden wir während des Trainings mehrere Beispiele erstellen (angegeben durch die folgenden Zweige) und dann Proben ermutigen, die letztendlich zu guten Ergebnissen führen (in diesem Fall zum Beispiel gemessen an den Verlusten am Ende). Mit anderen Worten, wir werden die in den blauen Pfeilen enthaltenen Parameter wie gewohnt mit dem Backprop trainieren, aber die im roten Pfeil enthaltenen Parameter werden jetzt unabhängig vom Rückwärtsdurchlauf mithilfe von Richtliniengradienten aktualisiert, wodurch Stichproben gefördert werden, die zu geringen Verlusten führen. Diese Idee wurde auch kürzlich gut gerahmt.Gradientenschätzung unter Verwendung stochastischer Berechnungsgraphen.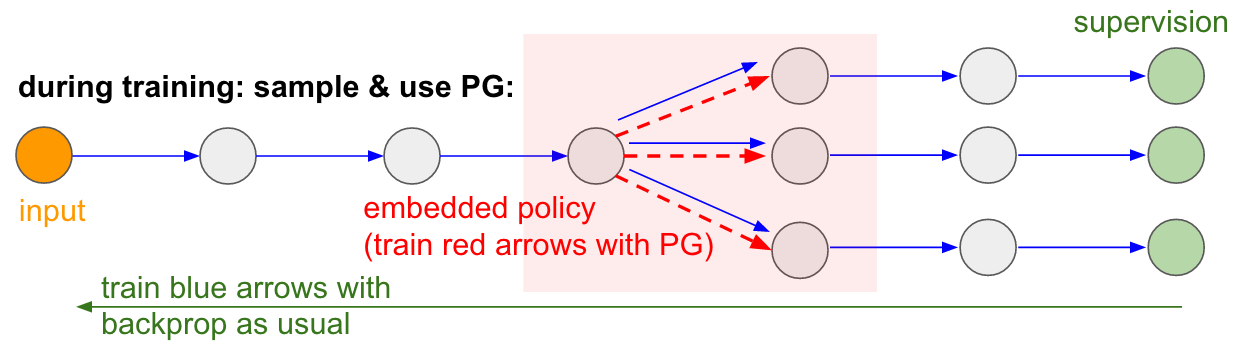 Geschulte Ein- / Ausgabe im Direktzugriffsspeicher. Sie finden diese Idee auch in vielen anderen Artikeln. Zum Beispiel verfügt die Neural Turing Machine über ein Speicherband, mit dem sie lesen und schreiben können. Um eine Schreiboperation auszuführen, müssen Sie etwas wie m [i] = x ausführen, wobei i und x vom neuronalen RNN-Netzwerk vorhergesagt werden. Es gibt jedoch kein Signal, das uns sagt, was mit der Verlustfunktion passieren würde, wenn wir j schreiben würden! = I. Daher kann NTM weiche Lese- und Schreibvorgänge ausführen. Er sagt die Aufmerksamkeitsverteilungsfunktion a voraus und führt dann für alle i: m [i] = a [i] * x aus. Es ist jetzt differenzierbar, aber wir müssen einen hohen Rechenpreis zahlen, indem wir alle Zellen sortieren.Wir können jedoch Richtlinienverläufe verwenden, um dieses Problem theoretisch zu umgehen, wie dies in RL-NTM der Fall ist. Wir sagen immer noch die Verteilung der Aufmerksamkeit a voraus, aber anstatt eine erschöpfende Suche durchzuführen, wählen wir zufällig Orte zum Schreiben aus: i = Probe (a); m [i] = x. Während des Trainings könnten wir dies für einen kleinen Satz von i tun und am Ende einen Satz finden, der besser funktioniert als andere. Ein großer Rechenvorteil besteht darin, dass Sie während des Testens aus einer Zelle lesen / schreiben können. Wie im Dokument angegeben, ist es jedoch sehr schwierig, diese Strategie zur Arbeit zu bringen, da Sie viele Optionen durchlaufen und fast versehentlich zu Arbeitsalgorithmen wechseln müssen. Derzeit sind sich die Forscher einig, dass PG nur dann gut funktioniert, wenn es mehrere diskrete Optionen gibt, wenn Sie keine großen Suchräume durchkämmen müssen.Mit Hilfe von Gradienten der Politik und in Fällen, in denen eine große Menge an Daten und Rechenleistung verfügbar ist, können wir im Prinzip von viel träumen. Zum Beispiel können wir neuronale Netze entwerfen, die lernen, mit großen nicht differenzierbaren Objekten wie Latex-Compilern zu interagieren. Zum Beispiel, damit char-rnn vorgefertigten Latexcode oder ein SLAM-System oder LQR-Löser oder etwas anderes generiert. Oder Superintelligenz möchte beispielsweise lernen, wie man über TCP / IP (was auch nicht differenzierbar ist) mit dem Internet interagiert, um auf die Informationen zuzugreifen, die zur Erfassung der Welt erforderlich sind. Dies ist ein großartiges Beispiel.
Geschulte Ein- / Ausgabe im Direktzugriffsspeicher. Sie finden diese Idee auch in vielen anderen Artikeln. Zum Beispiel verfügt die Neural Turing Machine über ein Speicherband, mit dem sie lesen und schreiben können. Um eine Schreiboperation auszuführen, müssen Sie etwas wie m [i] = x ausführen, wobei i und x vom neuronalen RNN-Netzwerk vorhergesagt werden. Es gibt jedoch kein Signal, das uns sagt, was mit der Verlustfunktion passieren würde, wenn wir j schreiben würden! = I. Daher kann NTM weiche Lese- und Schreibvorgänge ausführen. Er sagt die Aufmerksamkeitsverteilungsfunktion a voraus und führt dann für alle i: m [i] = a [i] * x aus. Es ist jetzt differenzierbar, aber wir müssen einen hohen Rechenpreis zahlen, indem wir alle Zellen sortieren.Wir können jedoch Richtlinienverläufe verwenden, um dieses Problem theoretisch zu umgehen, wie dies in RL-NTM der Fall ist. Wir sagen immer noch die Verteilung der Aufmerksamkeit a voraus, aber anstatt eine erschöpfende Suche durchzuführen, wählen wir zufällig Orte zum Schreiben aus: i = Probe (a); m [i] = x. Während des Trainings könnten wir dies für einen kleinen Satz von i tun und am Ende einen Satz finden, der besser funktioniert als andere. Ein großer Rechenvorteil besteht darin, dass Sie während des Testens aus einer Zelle lesen / schreiben können. Wie im Dokument angegeben, ist es jedoch sehr schwierig, diese Strategie zur Arbeit zu bringen, da Sie viele Optionen durchlaufen und fast versehentlich zu Arbeitsalgorithmen wechseln müssen. Derzeit sind sich die Forscher einig, dass PG nur dann gut funktioniert, wenn es mehrere diskrete Optionen gibt, wenn Sie keine großen Suchräume durchkämmen müssen.Mit Hilfe von Gradienten der Politik und in Fällen, in denen eine große Menge an Daten und Rechenleistung verfügbar ist, können wir im Prinzip von viel träumen. Zum Beispiel können wir neuronale Netze entwerfen, die lernen, mit großen nicht differenzierbaren Objekten wie Latex-Compilern zu interagieren. Zum Beispiel, damit char-rnn vorgefertigten Latexcode oder ein SLAM-System oder LQR-Löser oder etwas anderes generiert. Oder Superintelligenz möchte beispielsweise lernen, wie man über TCP / IP (was auch nicht differenzierbar ist) mit dem Internet interagiert, um auf die Informationen zuzugreifen, die zur Erfassung der Welt erforderlich sind. Dies ist ein großartiges Beispiel.Schlussfolgerungen
Wir haben gesehen, dass Richtlinienverläufe ein leistungsfähiger allgemeiner Algorithmus sind, und als Beispiel haben wir den ATARI Pong-Agenten in 130 Python-Zeilen von Grund auf neu trainiert . Im Allgemeinen kann derselbe Algorithmus verwendet werden, um Agenten für beliebige Spiele zu trainieren, und hoffentlich können wir ihn eines Tages verwenden, um Steuerungsprobleme in der realen Welt zu lösen. Abschließend möchte ich noch einige Kommentare hinzufügen:Über die Entwicklung der KI. Wir haben gesehen, dass der Algorithmus mittels Brute-Force-Suche funktioniert, bei der Sie zunächst zufällig zögern und mindestens einmal und im Idealfall häufig auf nützliche Situationen stoßen müssen, bevor die Richtlinienfunktion ihre Parameter ändert. Wir haben auch gesehen, dass eine Person diese Lösungen für diese Probleme auf eine völlig andere Art und Weise angeht, die der schnellen Konstruktion eines abstrakten Modells ähnelt. Da diese abstrakten Modelle nur sehr schwer (wenn nicht unmöglich) explizit vorstellbar sind, ist dies auch der Grund dafür, dass in letzter Zeit so viel Interesse an generativen Modellen und Software-Induktion besteht.Über den Einsatz in der Robotik.Der Algorithmus wird nicht angewendet, wenn es schwierig ist, eine große Menge an Forschung zu erhalten. Sie können beispielsweise einen (oder mehrere) Roboter in Echtzeit mit der Welt interagieren lassen. Dies reicht für eine naive Anwendung des Algorithmus nicht aus. Ein Arbeitsbereich zur Minderung dieses Problems sind deterministische politische Gradienten . Anstatt echte Versuche zu unternehmen, erhält dieser Ansatz Gradienteninformationen von einem zweiten neuronalen Netzwerk (als Kritiker bezeichnet), das die Bewertungsfunktion modelliert. Dieser Ansatz kann im Prinzip bei hochdimensionalen Aktionen effektiv sein, bei denen Zufallsstichproben eine schlechte Abdeckung bieten. Ein weiterer verwandter Ansatz besteht darin, die Robotik zu vergrößern, die wir in der Google Robot Farm sehenoder vielleicht sogar auf einem Tesla S + mit Autopilot.Es gibt auch eine Reihe von Arbeiten, die versuchen, den Suchprozess durch Hinzufügen zusätzlicher Kontrolle weniger hoffnungslos zu machen. In vielen praktischen Fällen können Sie beispielsweise die anfängliche Entwicklungsrichtung direkt von der Person erhalten. Zum Beispiel verwendet AlphaGo zuerst das Training mit einem Lehrer, um nur menschliche Handlungen vorherzusagen (z. B. Fernsteuerung des Roboters , Ausbildung , Flugbahnoptimierung , vollständige Richtliniensuche ). Die daraus resultierende Richtlinie wird später mithilfe von PG konfiguriert, um das eigentliche Ziel zu erreichen - das Spiel zu gewinnen.In einigen Fällen gibt es möglicherweise weniger Voreinstellungen (z. B. zur Fernsteuerung von Robotern ), und es gibt Methoden zur Verwendung dieser Daten vor dem Praktikum . Wenn Personen keine spezifischen Daten oder Einstellungen angeben, können sie in einigen Fällen auch durch Berechnung mit ziemlich teuren Optimierungsmethoden erhalten werden, beispielsweise durch Optimieren der Flugbahn in einem bekannten dynamischen Modell (wie F = ma in einem physikalischen Simulator) oder in Fällen wenn ein ungefähres lokales Modell erstellt wird (wie aus einer vielversprechenden Struktur für die Suche nach verwalteten Richtlinien hervorgeht).Über die Verwendung von PG in der Praxis.Ich würde gerne mehr über RNN sprechen. Ich denke, es scheint, dass RNNs magisch sind und automatisch Probleme im Zusammenhang mit beliebigen Sequenzen lösen. Die Wahrheit ist, dass es schwierig sein kann, diese Modelle zum Laufen zu bringen. Sorgfalt und Erfahrung sind erforderlich sowie das Wissen, wann einfachere Methoden Ihnen zu 90% helfen können. Gleiches gilt für Richtlinienverläufe. Sie funktionieren nicht einfach so automatisch: Sie müssen viele Beispiele haben, sie können für immer trainieren, sie sind schwer zu debuggen, wenn sie nicht funktionieren. Sie sollten immer versuchen, mit einer kleinen Pistole zu schießen, bevor Sie nach Bazooka greifen. Beispielsweise sollte beim Verstärkungstraining immer zuerst die Cross-Entropy-Methode (CEM) überprüft werden., ein einfacher stochastischer „Guess and Check“ -Ansatz, der von der Evolution inspiriert ist. Und wenn Sie darauf bestehen, Richtlinienverläufe für Ihre Aufgabe auszuprobieren, stellen Sie sicher, dass Sie die spezifischen Tricks kennen. Starten Sie einfach und verwenden Sie eine PG-Option namens TRPO , die fast immer besser und konsistenter funktioniert als klassisches PG . Die Grundidee besteht darin, zu vermeiden, dass Einstellungen aktualisiert werden, die Ihre Richtlinie aufgrund der Verwendung des Kulbak-Leibler-Abstands zwischen der alten und der neuen Richtlinie zu stark ändern.Das ist alles!
Ich hoffe, ich habe Ihnen eine Vorstellung davon gegeben, wo wir mit Reinforcement Learning sind, was die Probleme sind, und wenn Sie zur Förderung von RL beitragen möchten, lade ich Sie ein, dies in unserem OpenAI-Fitnessstudio zu tun :) Bis zum nächsten Mal!
Andrej Karpathy,Forscher, Entwickler, Direktor der Abteilung für KI und Autopilot TeslaZusätzliche Informationen:
Deep Learning on Fingers- Kurs 2018
https://habr.com/de/post/414165/ Deep Learning on Fingers
Open Course 2019
https: // habr.com/ru/company/ods/blog/438940/
Physikalische Fakultät der NSU
http://www.phys.nsu.ru/