Hallo allerseits! Ich präsentiere Ihnen eine Übersetzung des Analytics Vidhya- Artikels mit einem Überblick über AI / ML-Ereignisse in den Trends 2018 und 2019. Das Material ist ziemlich groß und daher in zwei Teile unterteilt. Ich hoffe, dass der Artikel nicht nur spezialisierte Spezialisten interessiert, sondern auch diejenigen, die sich für das Thema KI interessieren. Viel Spaß beim Lesen!
Einführung
Die letzten Jahre für KI-Enthusiasten und Profis des maschinellen Lernens sind auf der Suche nach einem Traum vergangen. Diese Technologien sind keine Nischen mehr, haben sich zum Mainstream entwickelt und wirken sich bereits jetzt auf das Leben von Millionen von Menschen aus. KI-Ministerien wurden in verschiedenen Ländern eingerichtet [
weitere Details hier - ca. per.] und Budgets werden zugewiesen, um mit diesem Rennen Schritt zu halten.
Gleiches gilt für Data-Science-Profis. Vor ein paar Jahren konnte man sich wohl fühlen, wenn man ein paar Werkzeuge und Tricks kannte, aber diesmal ist es vorbei. Die Anzahl der jüngsten Ereignisse in der Datenwissenschaft und die Menge an Wissen, die erforderlich ist, um mit der Zeit in diesem Bereich Schritt zu halten, sind erstaunlich.
Ich beschloss, einen Schritt zurückzutreten und die Entwicklungen in einigen Schlüsselbereichen auf dem Gebiet der künstlichen Intelligenz aus Sicht von Data-Science-Experten zu betrachten. Welche Ausbrüche sind aufgetreten? Was ist 2018 passiert und was erwartet Sie 2019? Lesen Sie diesen Artikel für Antworten!
PS Wie in jeder Prognose sind nachfolgend meine persönlichen Schlussfolgerungen aufgeführt, die auf Versuchen beruhen, einzelne Fragmente zu einem Gesamtbild zu kombinieren. Wenn sich Ihre Sichtweise von meiner unterscheidet, würde ich mich freuen, Ihre Meinung darüber zu erfahren, was sich 2019 in der Datenwissenschaft noch ändern könnte.
Die Bereiche, die wir in diesem Artikel behandeln werden, sind:
- Natürliche Sprachprozesse (NLP)
- Computer Vision
- Tools und Bibliotheken
- Verstärkungslernen
- Ethikprobleme in der KI
Verarbeitung natürlicher Sprache (NLP)
Maschinen zu zwingen, Wörter und Sätze zu analysieren, schien immer ein Wunschtraum zu sein. Es gibt viele Nuancen und Merkmale in Sprachen, die selbst für Menschen manchmal schwer zu verstehen sind, aber 2018 war ein echter Wendepunkt für NLP.
Wir haben einen großartigen Durchbruch nach dem anderen gesehen: ULMFiT, ELMO, OpenAl Transformer, Google BERT, und dies ist keine vollständige Liste. Die erfolgreiche Anwendung des Transfer-Lernens (die Kunst, vorab trainierte Modelle auf Daten anzuwenden) hat NLP die Tür für eine Vielzahl von Aufgaben geöffnet.
Transferlernen - Ermöglicht die Anpassung eines vorab trainierten Modells / Systems an Ihre spezifische Aufgabe mit relativ geringen Datenmengen.
Schauen wir uns einige dieser Schlüsselentwicklungen genauer an.
ULMFiT
ULMFiT wurde von Sebastian Ruder und Jeremy Howard (fast.ai) entwickelt und war das erste Framework, das in diesem Jahr Transferlernen erhielt. Für die Uneingeweihten steht das Akronym ULMFiT für „Universal Language Model Fine-Tuning“. Jeremy und Sebastian haben zu Recht das Wort „universal“ zu ULMFiT hinzugefügt - dieses Framework kann auf fast jede NLP-Aufgabe angewendet werden!
Das Beste an ULMFiT ist, dass Sie Modelle nicht von Grund auf neu trainieren müssen! Forscher haben bereits das Schwierigste für Sie getan - nehmen Sie an und bewerben Sie sich in Ihren Projekten. ULMFiT übertraf andere Methoden in sechs Textklassifizierungsaufgaben.
Sie können
das Tutorial von Pratek Joshi [Pateek Joshi - ca. trans.], wie Sie ULMFiT für jede Aufgabe der Textklassifizierung verwenden können.
ELMo
Ratet mal, was die Abkürzung ELMo bedeutet? Akronym für Einbettungen aus Sprachmodellen [Anhänge aus Sprachmodellen - ca. trans.]. Und ELMo erregte direkt nach der Veröffentlichung die Aufmerksamkeit der ML-Community.
ELMo verwendet Sprachmodelle, um Anhänge für jedes Wort zu erhalten, und berücksichtigt auch den Kontext, in dem das Wort in einen Satz oder Absatz passt. Der Kontext ist ein kritischer Aspekt von NLP, bei dem die meisten Entwickler zuvor versagt haben. ELMo verwendet bidirektionale LSTMs, um Anhänge zu erstellen.
Das Langzeitgedächtnis (LSTM) ist eine Art Architektur von wiederkehrenden neuronalen Netzen, die 1997 von Sepp Hochreiter und Jürgen Schmidhuber vorgeschlagen wurde. Wie die meisten wiederkehrenden neuronalen Netze ist ein LSTM-Netz in dem Sinne universell, dass es mit einer ausreichenden Anzahl von Netzelementen jede Berechnung durchführen kann, zu der ein normaler Computer in der Lage ist, was eine geeignete Gewichtsmatrix erfordert, die als Programm betrachtet werden kann. Im Gegensatz zu herkömmlichen wiederkehrenden neuronalen Netzen eignet sich das LSTM-Netz gut zum Training der Probleme der Klassifizierung, Verarbeitung und Vorhersage von Zeitreihen in Fällen, in denen wichtige Ereignisse durch Zeitverzögerungen mit unbestimmter Dauer und Grenzen getrennt sind.
- Quelle. Wikipedia
Wie ULMFiT verbessert ELMo die Produktivität bei der Lösung einer großen Anzahl von NLP-Aufgaben erheblich, z. B. bei der Analyse der Textstimmung oder der Beantwortung von Fragen.
BERT von Google
Viele Experten stellen fest, dass die Veröffentlichung von BERT den Beginn einer neuen Ära in NLP markiert. Nach ULMFiT und ELMo übernahm BERT die Führung und zeigte hohe Leistung. In der ursprünglichen Ankündigung heißt es: „BERT ist konzeptionell einfach und empirisch leistungsfähig.“
BERT hat in 11 NLP-Aufgaben hervorragende Ergebnisse gezeigt! Siehe die Ergebnisse in SQuAD-Tests:
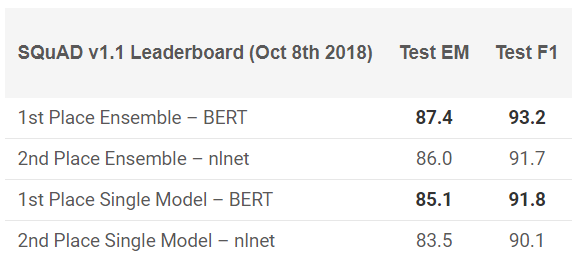
Willst du es versuchen? Sie können die Neuimplementierung in PyTorch oder den TensorFlow-Code von Google verwenden und versuchen, das Ergebnis auf Ihrem Computer zu wiederholen.
Facebook PyText
Wie konnte sich Facebook von diesem Rennen fernhalten? Das Unternehmen bietet ein eigenes Open-Source-NLP-Framework namens PyText an. Laut einer von Facebook veröffentlichten Studie hat PyText die Genauigkeit von Konversationsmodellen um 10% erhöht und die Trainingszeit verkürzt.
PyText steht tatsächlich hinter mehreren eigenen Facebook-Produkten wie Messenger. Die Zusammenarbeit mit ihm wird Ihrem Portfolio also einen guten Punkt und unschätzbares Wissen hinzufügen, das Sie zweifellos gewinnen werden.
Sie können es selbst versuchen und
den Code von GitHub herunterladen .
Google Duplex
Es ist kaum zu glauben, dass Sie noch nichts von Google Duplex gehört haben. Hier ist eine Demo, die lange Zeit in den Schlagzeilen aufblitzte:
Da es sich um ein Google-Produkt handelt, besteht kaum eine Chance, dass der Code früher oder später für alle veröffentlicht wird. Natürlich wirft diese Demonstration viele Fragen auf: von ethischen zu Datenschutzfragen, aber wir werden später darüber sprechen. Genießen Sie vorerst nur, wie weit wir mit ML in den letzten Jahren gekommen sind.
NLP-Trends 2019
Wer kann besser als Sebastian Ruder selbst eine Vorstellung davon geben, wohin die NLP 2019 steuert? Hier sind seine Ergebnisse:
- Die Verwendung von vorgefertigten Sprachinvestitionsmodellen wird weit verbreitet sein. Fortgeschrittene Modelle ohne Unterstützung werden sehr selten sein.
- Es werden vorab trainierte Ansichten angezeigt, die spezielle Informationen codieren können, die die Anhänge des Sprachmodells ergänzen. Abhängig von den Anforderungen der Aufgabe können wir verschiedene Arten von vorgefertigten Präsentationen gruppieren.
- Weitere Arbeiten werden im Bereich mehrsprachiger Anwendungen und mehrsprachiger Modelle erscheinen. Insbesondere wenn wir uns auf die Einbettung von Wörtern in verschiedenen Sprachen stützen, werden wir die Entstehung tief vorgefertigter Darstellungen in verschiedenen Sprachen sehen.
Computer Vision

Computer Vision ist heute das beliebteste Gebiet im Bereich des tiefen Lernens. Es scheint, dass die ersten Früchte der Technologie bereits erhalten wurden und wir uns im Stadium der aktiven Entwicklung befinden. Unabhängig davon, ob es sich um ein Bild oder ein Video handelt, entstehen viele Frameworks und Bibliotheken, mit denen sich die Probleme der Bildverarbeitung leicht lösen lassen.
Hier ist meine Liste der besten Lösungen, die dieses Jahr zu sehen waren.
BigGANs raus
Ian Goodfellow entwarf die GANs im Jahr 2014 und das Konzept brachte eine Vielzahl von Anwendungen hervor. Jahr für Jahr beobachteten wir, wie das ursprüngliche Konzept für die Anwendung in realen Fällen fertiggestellt wurde. Eines blieb jedoch bis zu diesem Jahr unverändert: Computergenerierte Bilder waren zu leicht zu unterscheiden. Im Rahmen trat immer eine gewisse Inkonsistenz auf, die den Unterschied sehr deutlich machte.
In den letzten Monaten haben sich Verschiebungen in diese Richtung ergeben, und mit der
Schaffung von BigGAN können solche Probleme ein für alle Mal gelöst werden. Schauen Sie sich die mit dieser Methode erzeugten Bilder an:

Ohne ein Mikroskop ist es schwer zu sagen, was mit diesen Bildern nicht stimmt. Natürlich wird jeder für sich selbst entscheiden, aber es besteht kein Zweifel daran, dass das GAN die Art und Weise verändert, wie wir digitale Bilder (und Videos) wahrnehmen.
Als Referenz: Diese Modelle wurden zuerst auf dem ImageNet-Datensatz und dann auf dem JFT-300M trainiert, um zu demonstrieren, dass diese Modelle gut von einem Datensatz auf einen anderen übertragen werden. Hier ist ein
Link zu einer Seite aus der GAN-Mailingliste, auf der erklärt wird, wie das GAN visualisiert und verstanden wird.
Model Fast.ai trainierte in 18 Minuten auf ImageNet
Dies ist eine wirklich coole Implementierung. Es ist weit verbreitet, dass Sie für die Durchführung von Deep-Learning-Aufgaben Terabyte an Daten und große Computerressourcen benötigen. Gleiches gilt für das Training des Modells von Grund auf auf ImageNet-Daten. Die meisten von uns dachten genauso, bevor ein paar Leute auf fast.ai nicht jedem das Gegenteil beweisen konnten.
Ihr Modell ergab eine Genauigkeit von 93% mit beeindruckenden 18 Minuten. Die von ihnen verwendete Hardware,
die in
ihrem Blog ausführlich
beschrieben wurde, bestand aus 16 öffentlichen AWS-Cloud-Instanzen mit jeweils 8 NVIDIA V100-GPUs. Sie erstellten einen Algorithmus unter Verwendung der Bibliotheken fast.ai und PyTorch.
Die Gesamtkosten für die Montage betrugen nur 40 US-Dollar! Jeremy hat ihre
Ansätze und Methoden hier ausführlicher beschrieben. Dies ist ein gemeinsamer Sieg!
vid2vid von NVIDIA
In den letzten 5 Jahren hat die Bildverarbeitung große Fortschritte gemacht, aber was ist mit Video? Die Methoden zum Konvertieren von einem statischen in einen dynamischen Frame erwiesen sich als etwas komplizierter als erwartet. Können Sie eine Folge von Bildern aus einem Video entnehmen und vorhersagen, was im nächsten Bild passieren wird? Solche Studien wurden bereits früher durchgeführt, aber die Veröffentlichungen waren bestenfalls vage.

NVIDIA hat beschlossen, seine Entscheidung Anfang dieses Jahres öffentlich zugänglich zu machen [2018 - ca. per.], die von der Gesellschaft positiv bewertet wurde. Der Zweck von vid2vid besteht darin, eine Anzeigefunktion aus einem bestimmten Eingabevideo abzuleiten, um ein Ausgabevideo zu erstellen, das den Inhalt des Eingabevideos mit unglaublicher Genauigkeit wiedergibt.
Sie können ihre Implementierung auf PyTorch ausprobieren und hier
zu GitHub bringen .
Bildverarbeitungstrends für 2019
Wie ich bereits erwähnt habe, werden wir 2019 eher die Entwicklung der Trends für 2018 als neue Durchbrüche sehen: selbstfahrende Autos, Gesichtserkennungsalgorithmen, virtuelle Realität und mehr. Können Sie mir nicht zustimmen, wenn Sie eine andere Sichtweise oder Ergänzungen haben, teilen Sie es uns mit, was können wir 2019 noch erwarten?
Das Thema Drohnen könnte in Erwartung der Zustimmung von Politikern und Regierung endlich grünes Licht in den Vereinigten Staaten bekommen (Indien liegt in dieser Angelegenheit weit zurück). Persönlich möchte ich, dass mehr Forschung in realen Szenarien durchgeführt wird. Konferenzen wie
CVPR und
ICML bieten einen guten
Überblick über die neuesten Errungenschaften in diesem Bereich, aber wie nah die Projekte an der Realität sind, ist nicht sehr klar.
"Visuelle Fragen beantworten" und "visuelle Dialogsysteme" könnten endlich mit einem lang erwarteten Debüt herauskommen. Diesen Systemen fehlt die Fähigkeit zur Verallgemeinerung, aber es wird erwartet, dass wir bald einen integrierten multimodalen Ansatz sehen werden.
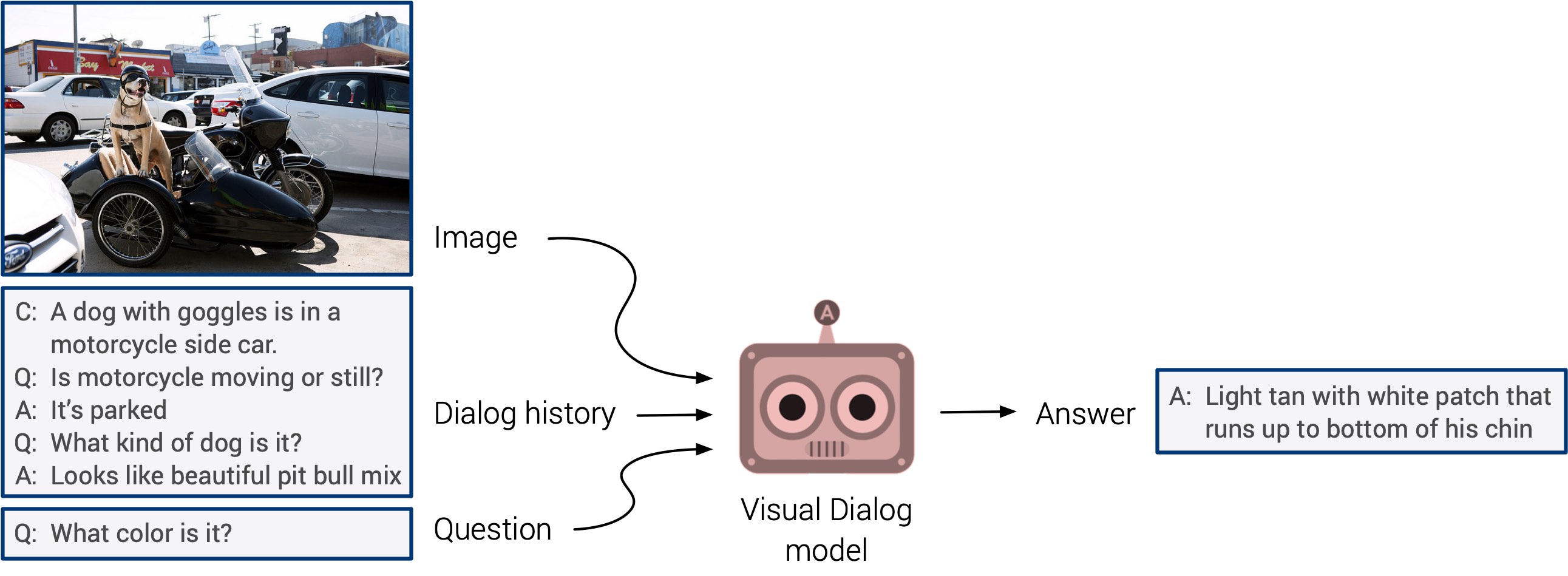
Das Selbsttraining stand in diesem Jahr im Vordergrund. Ich wette, dass es nächstes Jahr in einer viel größeren Anzahl von Studien Anwendung finden wird. Dies ist eine wirklich coole Richtung: Zeichen werden direkt aus den Eingabedaten ermittelt, anstatt Zeit damit zu verschwenden, die Bilder manuell zu markieren. Drücken wir die Daumen!