Hallo% habrauser%!
Heute möchte ich Ihnen von einem meiner Meinung nach ausgezeichneten
Moleculer Microservice Framework erzählen.

Ursprünglich wurde dieses Framework in Node.js geschrieben, später jedoch an Ports in anderen Sprachen wie Java, Go, Python und .NET, und höchstwahrscheinlich
werden in naher Zukunft andere Implementierungen
erscheinen . Wir verwenden es seit ungefähr einem Jahr in der Produktion in mehreren Produkten und es ist schwer mit Worten zu beschreiben, wie gesegnet er uns nach der Verwendung von Seneca und unseren Motorrädern erschien. Wir haben alles, was wir brauchen, sofort einsatzbereit: Sammeln von Metriken, Zwischenspeichern, Ausgleichen, Fehlertoleranz, Auswählen von Transporten, Parameterüberprüfung, Protokollieren, präzise Methodendeklarationen, verschiedene Arten der Interaktion zwischen Diensten, Mixins und vieles mehr. Und jetzt in Ordnung.
Einführung
Das Framework besteht in der Tat aus drei Komponenten (in der Tat, nein, aber Sie werden unten mehr darüber erfahren).
Transporter
Verantwortlich für die Entdeckung von Diensten und die Kommunikation zwischen ihnen. Dies ist eine Schnittstelle, die Sie selbst implementieren können, wenn Sie dies wünschen, oder Sie können vorgefertigte Implementierungen verwenden, die Teil des Frameworks selbst sind. Ab der Box stehen 7 Transporte zur Verfügung: TCP, Redis, AMQP, MQTT, NATS, NATS-Streaming, Kafka.
Hier können Sie mehr sehen. Wir verwenden den Redis-Transport, planen jedoch, mit dem Verlassen des experimentellen Zustands auf TCP umzusteigen.
In der Praxis interagieren wir beim Schreiben von Code nicht mit dieser Komponente. Sie müssen nur wissen, was er ist. Der verwendete Transport wird in der Konfiguration angegeben. Um von einem Transport zum anderen zu wechseln, ändern Sie einfach die Konfiguration. Das ist alles. Ungefähr so:
Daten werden standardmäßig im JSON-Format geliefert. Sie können jedoch alles verwenden: Avro, MsgPack, Notepack, ProtoBuf, Thrift usw.
Service
Die Klasse, von der wir beim Schreiben unserer Microservices erben.
Hier ist der einfachste Dienst ohne Methoden, der jedoch von anderen Diensten erkannt wird:
Service Broker
Der Kern des Frameworks.

Übertreibend können wir sagen, dass dies eine Schicht zwischen Transport und Service ist. Wenn ein Dienst irgendwie mit einem anderen Dienst interagieren möchte, geschieht dies über einen Broker (Beispiele werden unten angegeben). Der Broker befasst sich mit dem Lastausgleich (unterstützt standardmäßig mehrere Strategien, einschließlich benutzerdefinierter Strategien - Round-Robin), wobei Live-Dienste, verfügbare Methoden in diesen Diensten usw. berücksichtigt werden. Zu diesem Zweck verwendet ServiceBroker eine andere Komponente unter der Haube - die Registrierung, aber ich werde nicht darauf eingehen, wir werden sie nicht für Bekanntschaften benötigen.
Einen Makler zu haben, gibt uns eine äußerst bequeme Sache. Jetzt werde ich versuchen zu klären, muss aber ein wenig beiseite treten. Im Kontext des Frameworks gibt es so etwas wie einen Knoten. In einfacher Sprache ist ein Knoten ein Prozess im Betriebssystem (dh was passiert, wenn wir beispielsweise "node index.js" in die Konsole eingeben). Jeder Knoten ist ein ServiceBroker mit einem Satz von einem oder mehreren Mikrodiensten. Ja, du hast richtig gehört. Wir können unseren Service-Stack nach Herzenslust aufbauen. Warum ist das bequem? Für die Entwicklung starten wir einen Knoten, in dem alle Microservices gleichzeitig gestartet werden (jeweils 1), nur einen Prozess im System, mit dem beispielsweise Hotreload sehr einfach verbunden werden kann. In der Produktion - ein separater Knoten für jede Instanz des Dienstes. Nun, oder eine Mischung, wenn ein Teil der Dienste in einem Knoten, ein Teil in einem anderen usw. (obwohl ich nicht weiß, warum ich das tun soll, nur um zu verstehen, dass Sie dies auch tun können).
So sieht unsere index.js aus const { resolve } = require('path'); const { ServiceBroker } = require('moleculer'); const config = require('./moleculer.config.js'); const { SERVICES, NODE_ENV, } = process.env; const broker = new ServiceBroker(config); broker.loadServices( resolve(__dirname, 'services'), SERVICES ? `*/@(${SERVICES.split(',').map(i => i.trim()).join('|')}).service.js` : '*/*.service.js', ); broker.start().then(() => { if (NODE_ENV === 'development') { broker.repl(); } });
Wenn keine Umgebungsvariable vorhanden ist, werden alle Dienste aus dem Verzeichnis geladen, andernfalls per Maske. Broker.repl () ist übrigens eine weitere praktische Funktion des Frameworks. Wenn Sie im Entwicklungsmodus starten, haben wir genau dort in der Konsole eine Schnittstelle zum Aufrufen von Methoden (was Sie beispielsweise über einen Postboten in Ihrem Microservice tun würden, der über http kommuniziert). Nur hier ist es viel praktischer: Die Schnittstelle befindet sich in derselben Konsole wo sie npm angefangen haben.
Interservice-Interaktion
Es wird auf drei Arten durchgeführt:
anrufen
Am häufigsten verwendet. Eine Anfrage gestellt, eine Antwort (oder einen Fehler) erhalten.
Wie oben erwähnt, werden Anrufe automatisch ausgeglichen. Wir erhöhen nur die erforderliche Anzahl von Service-Instanzen, und das Framework selbst übernimmt den Ausgleich.

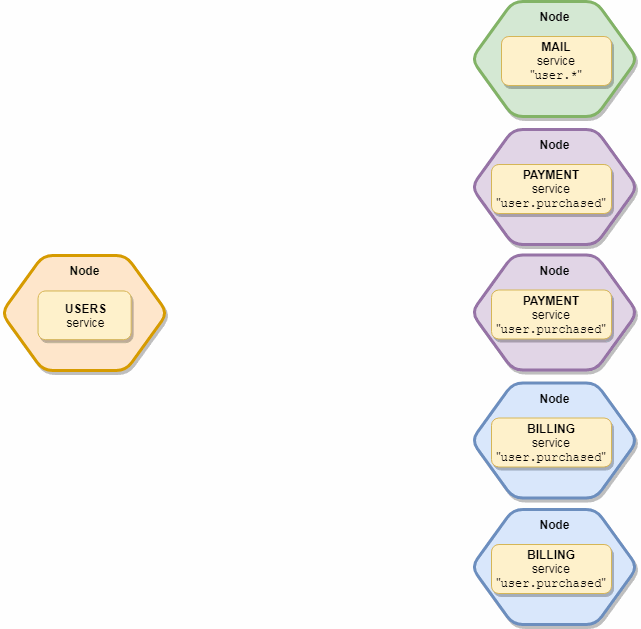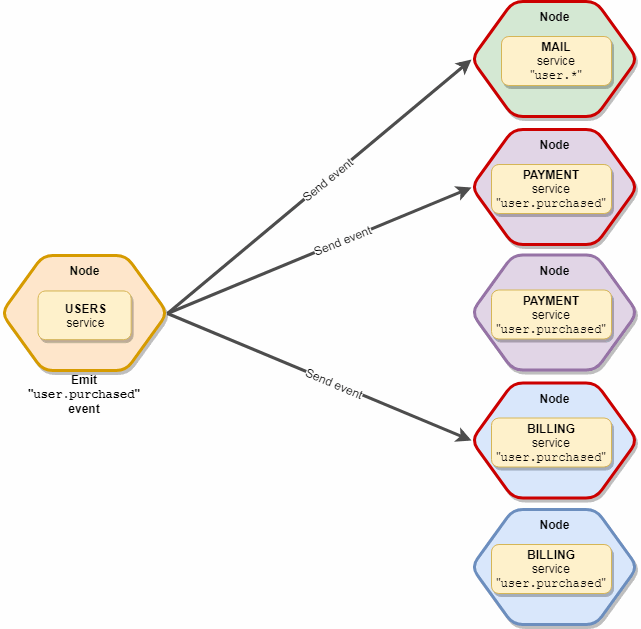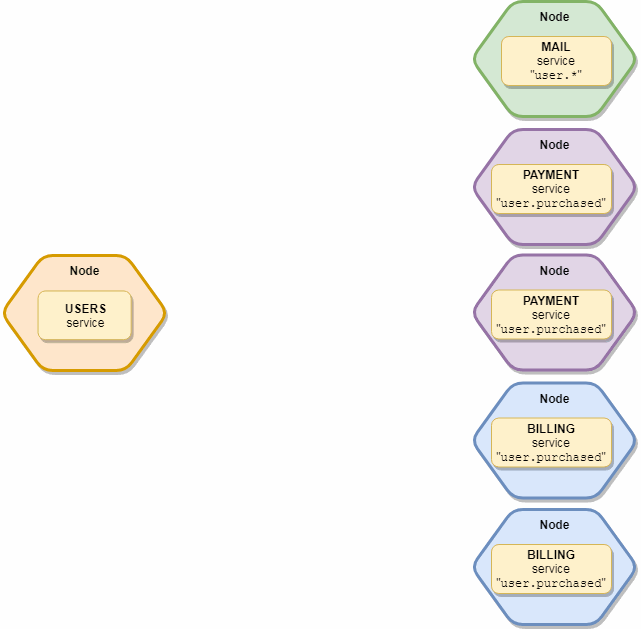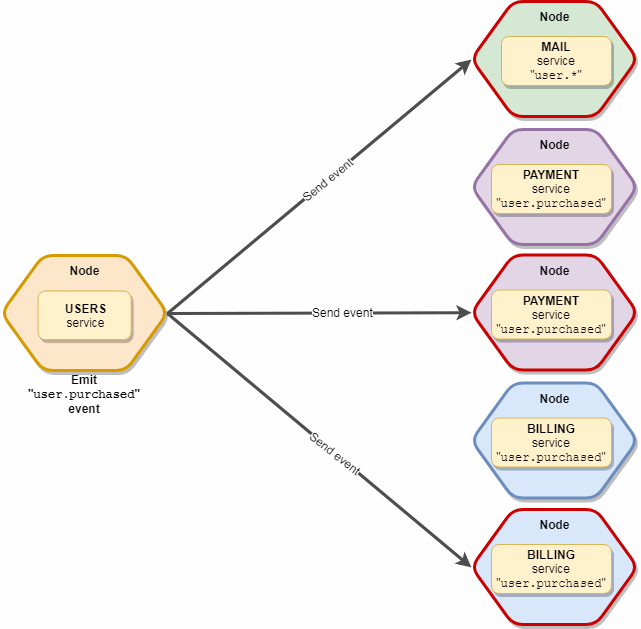
emittieren
Wird verwendet, wenn wir nur andere Dienste über ein Ereignis benachrichtigen möchten, das Ergebnis jedoch nicht benötigen.
Andere Dienste können dieses Ereignis abonnieren und entsprechend reagieren. Optional können Sie als drittes Argument explizit die Dienste festlegen, die für den Empfang dieses Ereignisses verfügbar sind.
Der wichtige Punkt ist, dass das Ereignis nur eine Instanz jeder Art von Dienst empfängt, d. H. Wenn wir 10 "Mail" - und 5 "Abonnement" -Dienste haben, die dieses Ereignis abonniert haben, erhalten es tatsächlich nur 2 Kopien - eine "Mail" und ein "Abonnement". Sieht schematisch so aus:
Sendung
Das gleiche wie emittieren, aber ohne Einschränkungen. Alle 10 Mail- und 5 Abonnementdienste werden diese Veranstaltung abfangen.
Validierung von Parametern
Standardmäßig wird der
schnellste Validator verwendet, um die Parameter zu validieren. Er scheint sehr schnell zu sein. Nichts hindert Sie jedoch daran, ein anderes, beispielsweise dasselbe Joi, zu verwenden, wenn Sie eine erweiterte Validierung benötigen.
Wenn wir einen Service schreiben, erben wir von der Service-Basisklasse, deklarieren Methoden mit darin enthaltener Geschäftslogik, aber diese Methoden sind "privat". Sie können nicht von außen (von einem anderen Service) aufgerufen werden, bis wir dies explizit deklarieren möchten Abschnitt "Sonderaktionen" während der Dienstinitialisierung (öffentliche Dienstmethoden im Kontext des Frameworks werden als Aktionen bezeichnet).
Beispiel einer Methodendeklaration mit Validierung module.exports = class JobService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'job', actions: { update: { params: { id: { type: 'number', convert: true }, name: { type: 'string', empty: false, optional: true }, data: { type: 'object', optional: true }, }, async handler(ctx) { return this.update(ctx.params); }, }, }, }); } async update({ id, name, data }) {
Mixins
Wird beispielsweise zum Initialisieren einer Datenbankverbindung verwendet. Vermeiden Sie die Vervielfältigung von Code von Dienst zu Dienst.
Beispiel-Mixin zum Initialisieren einer Verbindung zu Redis const Redis = require('ioredis'); module.exports = ({ key = 'redis', options } = {}) => ({ settings: { [key]: options, }, created() { this[key] = new Redis(this.settings[key]); }, async started() { await this[key].connect(); }, stopped() { this[key].disconnect(); }, });
Mixin im Service verwenden const { Service, Errors } = require('moleculer'); const redis = require('../../mixins/redis'); const server = require('../../mixins/server'); const router = require('./router'); const { REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, } = process.env; const redisOpts = { host: REDIS_HOST, port: REDIS_PORT, password: REDIS_PASSWORD, lazyConnect: true, }; module.exports = class AuthService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'auth', mixins: [redis({ options: redisOpts }), server({ router })], }); } }
Caching
Methodenaufrufe (Aktionen) können auf verschiedene Arten zwischengespeichert werden: LRU, Speicher, Redis. Optional können Sie angeben, nach welchen Schlüsselaufrufen zwischengespeichert werden soll (standardmäßig wird der Objekt-Hash als Caching-Schlüssel verwendet) und mit welcher TTL.
Beispiel für eine zwischengespeicherte Methodendeklaration module.exports = class InventoryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'inventory', actions: { getInventory: { params: { steamId: { type: 'string', pattern: /^76\d{15}$/ }, appId: { type: 'number', integer: true }, contextId: { type: 'number', integer: true }, }, cache: { keys: ['steamId', 'appId', 'contextId'], ttl: 15, }, async handler(ctx) { return true; }, }, }, }); }
Die Caching-Methode wird über die ServiceBroker-Konfiguration festgelegt.
Protokollierung
Hier ist aber auch alles ganz einfach. Es gibt einen ziemlich guten eingebauten Logger, der in die Konsole schreibt. Es ist möglich, benutzerdefinierte Formatierungen anzugeben. Nichts hindert daran, andere beliebte Holzfäller zu stehlen, sei es Winston oder Bunyan. Ein ausführliches Handbuch finden Sie in der
Dokumentation . Persönlich verwenden wir den integrierten Logger. Der benutzerdefinierte Formatierer für einige Codezeilen, die in die JSON-Konsole gelangen, wird einfach im Produkt abgeschnitten. Anschließend gelangen sie mithilfe des Docker-Protokolltreibers in Graylog.
Metriken
Falls gewünscht, können Sie Metriken für jede Methode sammeln und alles in einem Zipkin verfolgen. Hier finden Sie
die vollständige Liste der verfügbaren Exporteure. Derzeit gibt es fünf davon: Zipkin, Jaeger, Prometheus, Elastic, Console. Es wird wie das Caching konfiguriert, wenn eine Methode (Aktion) deklariert wird.
Visualisierungsbeispiele für das Elasticsearch + Kibana-Bundle unter Verwendung des
Elastic-Apm-Node- Moduls können unter
diesem Link in Github eingesehen werden.
Am einfachsten ist es natürlich, die Konsolenoption zu verwenden. Es sieht so aus:

Fehlertoleranz
Das Framework verfügt über einen eingebauten Leistungsschalter, der über die ServiceBroker-Einstellungen gesteuert wird. Wenn ein Dienst ausfällt und die Anzahl dieser Fehler einen bestimmten Schwellenwert überschreitet, wird er als fehlerhaft markiert. Die Anforderungen werden stark eingeschränkt, bis keine Fehler mehr auftreten.
Als Bonus gibt es auch einen Fallback, der für jede Methode (Aktion) individuell einstellbar ist, falls wir davon ausgehen, dass die Methode fehlschlägt, und beispielsweise zwischengespeicherte Daten oder einen Stub senden.
Fazit
Die Einführung dieses Frameworks wurde für mich zu einem Hauch frischer Luft, der eine große Menge an Bunts sparte (mit Ausnahme der Tatsache, dass die Microservice-Architektur eine große Bunt ist) und das Radfahren das Schreiben des nächsten Microservice einfach und transparent machte. Es ist nichts überflüssig, es ist einfach und sehr flexibel, und Sie können den ersten Dienst innerhalb von ein oder zwei Stunden nach dem Lesen der Dokumentation schreiben. Ich werde mich freuen, wenn dieses Material für Sie nützlich ist und Sie in Ihrem nächsten Projekt dieses Wunder versuchen möchten, wie wir es getan haben (und es noch nicht bereut haben). Gut zu allen!
Wenn Sie an diesem Framework interessiert sind, nehmen Sie am Chat in Telegram -
@moleculerchat teil