
Unter den Wissenschaftlern gibt es viele Holivars, und einer davon betrifft wettbewerbsfähiges maschinelles Lernen. Zeigt der Erfolg von Kaggle wirklich die Fähigkeit eines Spezialisten, typische Arbeitsaufgaben zu lösen? Arseny
arseny_info (F & E-Teamleiter @
WANNABY ,
Kaggle Master , später in
A. ) und Arthur
n01z3 (Leiter Computer Vision @
X5 Retail Group ,
Kaggle Grandmaster , später in
N. ) haben den Holivar auf eine neue Ebene skaliert: anstelle einer weiteren Diskussion in Sie nahmen Mikrofone in den Chatraum und führten
während des Treffens eine
öffentliche Diskussion , auf deren Grundlage dieser Artikel geboren wurde.
Metriken, Kernel, Bestenliste
A:Ich möchte mit dem erwarteten Argument beginnen, dass Kaggle nicht das Wichtigste in der Arbeit eines typischen Wissenschaftlerdatums lehrt - die Erklärung des Problems. Eine korrekt eingestellte Aufgabe enthält bereits die Hälfte der Lösung, und oft ist diese Hälfte die schwierigste, und es ist viel einfacher, ein Modell zu codieren und zu trainieren. Kaggle bietet eine Aufgabe aus einer idealen Welt - die Daten sind bereit, die Metrik ist bereit, nehmen und trainieren.
Überraschenderweise treten auch hier Probleme auf. Es ist nicht schwer, viele Beispiele zu finden, wenn „Kagglers“ verwirrt sind, wenn sie eine unbekannte / unverständliche Metrik sehen.
N:Ja, das ist die Essenz von Kaggle. Die Organisatoren dachten nach, formalisierten die Aufgabe, sammelten den Datensatz und bestimmten die Metrik. Wenn eine Person jedoch die Anfänge des kritischen Denkens hat, wird sie zuerst darüber nachdenken, warum sie entschieden hat, dass die gewählte Metrik oder das vorgeschlagene Ziel optimal ist.
Starke Teilnehmer definieren die Aufgabe oft selbst neu und finden ein besseres Ziel.
Und wenn sie die Metrik herausgefunden, das Ziel bestimmt und die Daten gesammelt haben, ist die Optimierung der Metrik das, was Kagglers am besten können. Nach jedem Wettbewerb kann der Kunde mit großer Zuversicht glauben, dass die Teilnehmer die „Obergrenze“ für den idealen Algorithmus mit einer Höchstgeschwindigkeit gezeigt haben. Und um dies zu erreichen, probieren Kaggler viele verschiedene Ansätze und Ideen aus und validieren sie mit schnellen Iterationen.
Dieser Ansatz wird direkt in eine erfolgreiche Arbeit an realen Aufgaben umgesetzt. Darüber hinaus können erfahrene Jongleure sofort und intuitiv oder aus früheren Erfahrungen eine Liste von Ideen auswählen, die es wert sind, zunächst einmal ausprobiert zu werden, um maximalen Gewinn zu erzielen. Und hier kommt das ganze Arsenal der Kaggle-Community zur Rettung: Artikel, Slack, Forum, Kernel.
 A:
A:Sie haben "Kernel" erwähnt, und ich habe eine separate Beschwerde bei ihnen. Viele Wettbewerbe haben sich zu einer kerngetriebenen Entwicklung entwickelt. Ich werde mich nicht auf entartete Fälle konzentrieren, in denen eine Goldmedaille aufgrund des erfolgreichen Starts eines öffentlichen Drehbuchs erhalten werden könnte. Trotzdem können Sie auch bei Deep-Learning-Wettbewerben eine Art Medaille erhalten, fast ohne Code zu schreiben. Sie können mehrere öffentliche Entscheidungen treffen, insbesondere wenn Sie die Wendung einiger Parameter nicht verstehen, sich in der Rangliste testen, die Ergebnisse mitteln und eine gute Metrik erhalten.
Zuvor zeigten selbst moderate Erfolge bei „Bild“ -Wettbewerben (zum Beispiel eine Bronzemedaille, dh das Erreichen der besten 10% der Endbewertung), dass eine Person zu etwas fähig ist - man musste zumindest von Anfang bis Ende eine normale Pipeline schreiben , verhindern Sie kritische Fehler. Jetzt wurden diese Erfolge abgewertet: Kaggle bewirbt seine Kernplattform mit Macht und Kraft, die die Eintrittsschwelle senken und es Ihnen ermöglichen, irgendwie zu experimentieren, ohne zu wissen, was was ist.
 N:
N:Die Bronzemedaille wurde nie zitiert. Dies ist die Stufe von "Ich habe dort etwas gestartet und es hat gelernt." Und es ist nicht so schlimm.
Das Verringern des Eingangspegels aufgrund von Kerneln und des Vorhandenseins von GPUs in diesen schafft Wettbewerb und erhöht den allgemeinen Wissensstand. Wenn es vor einem Jahr möglich war, mit Vanilla Unet Gold zu erhalten, können Sie jetzt nicht auf mehr als 5 Modifikationen und Tricks verzichten. Und diese Tricks funktionieren nicht nur bei Kaggle, sondern auch darüber hinaus. Zum Beispiel sind unsere Jungs von ods.ai bei
Aerial-Inria aufgestanden und haben einfach mit ihren von Kaggle entwickelten leistungsstarken Segmentierungspipelines den neuesten Stand der Technik gezeigt. Dies zeigt die Anwendbarkeit solcher Ansätze in der realen Arbeit.
 A:
A:Das Problem ist, dass es
bei realen Aufgaben keine Rangliste gibt . Normalerweise gibt es keine einzige Zahl, die anzeigt, dass alles schief gelaufen ist oder umgekehrt alles in Ordnung ist. Oft gibt es mehrere Zahlen, sie widersprechen sich, die Verknüpfung zu einem System ist eine weitere Herausforderung.
N:Aber Metriken sind irgendwie wichtig. Sie zeigen eine objektive Leistung des Algorithmus. Ohne Algorithmen mit Metriken über einem verwendbaren Schwellenwert ist es unmöglich, ML-basierte Dienste zu erstellen.
A:Aber nur, wenn sie ehrlich den Zustand des Produkts widerspiegeln, was nicht immer der Fall ist. Es kommt vor, dass Sie die Metrik auf ein hygienisches Minimum ziehen müssen und
weitere Verbesserungen der „technischen“ Metrik nicht mehr den Produktverbesserungen entsprechen (der Benutzer bemerkt diese +0,01 IoU nicht), die Korrelation zwischen der Metrik und den Empfindungen des Benutzers geht verloren.
Darüber hinaus sind die klassischen Kaggle-Methoden zum Erhöhen der Metrik bei normaler Arbeit nicht anwendbar. Keine Notwendigkeit, nach „Gesichtern“ zu suchen, keine Notwendigkeit, das Markup zu reproduzieren und die richtigen Antworten durch Hashes von Dateien zu finden.

Zuverlässige Validierung und Ensembles mutiger Modelle
N:Kaggle lehrt Sie, korrekt zu validieren, auch aufgrund des Vorhandenseins von Gesichtern. Sie müssen sich ganz klar darüber sein, wie sich die Geschwindigkeit in der Rangliste verbessert hat. Es ist auch
notwendig, eine repräsentative lokale Validierung zu erstellen , die den privaten Teil der Rangliste oder die Verteilung von Daten in der Produktion widerspiegelt, wenn es sich um echte Arbeit handelt.
Eine andere Sache, für die Kagglers oft verantwortlich gemacht werden, sind Ensembles. Eine Kaggle-Lösung besteht normalerweise aus einer Reihe von Modellen, und es ist unmöglich, das Produkt hineinzuziehen. Sie vergessen jedoch, dass es ohne starke Einzelmodelle unmöglich ist, eine starke Lösung zu finden. Und um zu gewinnen, braucht man nicht nur ein Ensemble, sondern ein Ensemble aus verschiedenen und starken Einzelmodellen.
Der Ansatz „Alles in einer Reihe mischen“ liefert niemals ein anständiges Ergebnis. A:
A:Das Konzept des „einfachen Einzelmodells“ im Kaggle-Get-together und für die Produktionsumgebung kann sehr unterschiedlich sein. Im Rahmen des Wettbewerbs wird dies eine Architektur sein, die 5/10-fach mit einem Spread-Encoder trainiert wurde, und Sie können mit einer Verlängerung der Testzeit rechnen. Für Wettbewerbsstandards ist dies eine wirklich einfache Lösung.
Die Produktion
benötigt jedoch häufig
Lösungen, die um einige Größenordnungen einfacher sind , insbesondere wenn es um mobile Anwendungen oder IoT geht. In meinem Fall belegen Kaggle-Modelle beispielsweise normalerweise mehr als 100 Megabyte, und in der Arbeit des Modells werden oft mehr als einige Megabyte nicht einmal berücksichtigt. Es gibt eine ähnliche Lücke in den Anforderungen an die Inferenzrate.
N:Wenn der Wissenschaftler jedoch weiß, wie man ein schweres Gitter trainiert, eignen sich dieselben Techniken auch für das Training leichter Modelle. In erster Näherung können Sie nur ein ähnliches Netz einfacher oder eine mobile Version derselben Architektur verwenden. Quantisierung von Skalen und Beschneiden außerhalb der Kompetenz von Kagglers - hier kein Zweifel. Dies sind jedoch bereits sehr spezifische Fähigkeiten, die bei der Herstellung von Produkten bei weitem nicht immer dringend benötigt werden.
Eine viel häufigere Situation bei echten Problemen ist jedoch, dass es einen kleinen
(wie Ihre Hose) gekennzeichneten Datensatz gibt und entweder die meisten nicht zugewiesenen Daten oder einen kontinuierlichen Strom neuer Daten. Und hier ist die Fähigkeit, ein großes und genaues Ensemble zu schweißen, perfekt geeignet. Mit ihm können Sie Pseudodimmen oder Destillieren durchführen, um ein leichtes Modell zu trainieren. Wenn Sie den Datensatz auf diese Weise vergrößern, wird die Leistung jedes Modells garantiert verbessert.
A:Pseudo-Tupfen ist nützlich, wird aber in Wettbewerben nicht für ein gutes Leben verwendet - nur weil es unmöglich ist, die Größe der Daten zu ändern. Die mit Pseudo-Dimmen erhaltenen Daten sind zwar die Metrik verbessern, aber nicht so nützlich wie das manuelle erneute Markieren der fehlenden Daten.
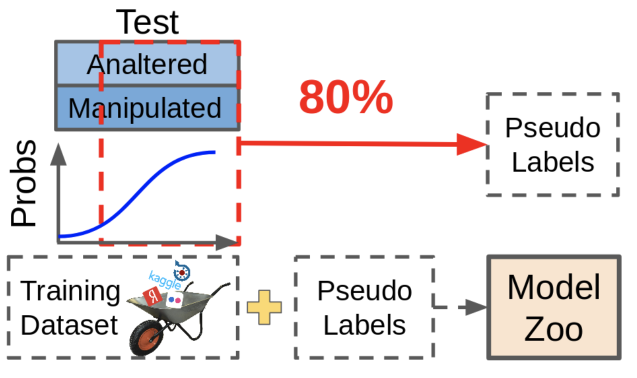
Was ist Pseudo-Tupfen? Wir nehmen vorhandene Modelle, schauen, wo sie zuverlässige Vorhersagen liefern, und werfen diese Stichproben zusammen mit Vorhersagen in unseren Datensatz. In diesem Fall bleiben für das Modell schwierige Proben unbeschriftet, weil Diese Vorhersagen sind jetzt nicht gut genug. Teufelskreis!
In der Praxis ist es viel nützlicher, diejenigen Stichproben zu finden, die dazu führen, dass das Netzwerk unsichere Vorhersagen erstellt, und sie in der Größe zu ändern. Es erfordert viel Handarbeit, aber der Effekt ist es wert.
Über die Schönheit von Code und Teamwork
A:Ein weiteres Problem ist die Codequalität und die Entwicklungskultur. Kaggle bringt Ihnen nicht nur das Schreiben von Code bei, sondern bietet auch viele schlechte Beispiele. Die meisten Kernel sind schlecht strukturierter, unlesbarer und ineffizienter Code, der gedankenlos kopiert wird. Einige beliebte Kaggle-Persönlichkeiten üben sogar das Hochladen ihres Codes auf Google Drive anstelle des Repositorys.

Menschen können gut unbeaufsichtigt lernen. Wenn Sie sich viel mit schlechtem Code beschäftigen, können Sie sich an die Idee gewöhnen, dass dies so sein sollte. Dies ist besonders gefährlich für Anfänger, die auf Kaggle ziemlich viel sind.
N:Die Qualität des Codes ist ein strittiger Punkt beim Kämpfen, da stimme ich zu. Ich habe jedoch auch Leute getroffen, die sehr wertvolle Pipelines geschrieben haben, die für andere Aufgaben wiederverwendet werden können. Dies ist jedoch eher die Ausnahme: In der Hitze des Kampfes wird die Qualität des Codes zugunsten einer schnellen Überprüfung neuer Ideen geopfert, insbesondere gegen Ende des Wettbewerbs.
Aber Kaggle lehrt Teamwork. Und nichts verbindet Menschen so sehr wie eine gemeinsame Sache, ein gemeinsames verständliches Ziel. Sie können versuchen, mit einer Reihe verschiedener Menschen zu konkurrieren, sich zu engagieren und Soft Skills zu entwickeln.
 A:
A:Teams im Kaggle-Stil sind ebenfalls sehr unterschiedlich. Es ist gut, wenn es wirklich eine Art Aufgabentrennung nach Rollen, konstruktive Interaktion gibt und jeder einen Beitrag leistet. Nichtsdestotrotz reichen auch die Teams aus, in denen jeder seinen eigenen großen Schlammball macht, und in den letzten Tagen des Wettbewerbs ist all dies hektisch gemischt, und dies lehrt auch nichts Gutes - die echte Softwareentwicklung (einschließlich Datenwissenschaft) ist so schon sehr lange nicht mehr gemacht.
Zusammenfassung
Fassen wir zusammen.
Zweifellos bietet die Teilnahme an Wettbewerben Vorteile, die für die tägliche Arbeit nützlich sind: Erstens ist es die Fähigkeit, im Rahmen der Metrik schnell zu iterieren, alles aus den Daten herauszupressen und nicht zu zögern, modernste Ansätze zu verwenden.
Andererseits führt der Missbrauch von Kaggle-Ansätzen oft zu suboptimalem unlesbarem Code, zweifelhaften Arbeitsprioritäten und ein bisschen Bling.
Zu jedem Zeitpunkt, an dem der Wissenschaftler weiß, dass Sie eine Vielzahl von Modellen kombinieren müssen, um ein Ensemble erfolgreich zu erstellen. In einem Team
lohnt es sich also, Menschen mit unterschiedlichen Fähigkeiten zu kombinieren , und ein oder zwei erfahrene Kagglers sind für fast jedes Team nützlich.