Bei der Auswahl eines Tools zur Verarbeitung von Big Data haben wir verschiedene Optionen in Betracht gezogen - sowohl proprietäre als auch Open Source-Optionen. Wir haben die Möglichkeiten einer schnellen Anpassung, Zugänglichkeit und Flexibilität von Technologien bewertet. Einschließlich Migration zwischen Versionen. Aus diesem Grund haben wir uns für die Open-Source-Greenplum-Lösung entschieden, die unsere Anforderungen am besten erfüllt, jedoch die Lösung eines wichtigen Problems erfordert.

Tatsache ist, dass die Greenplum-Datenbankdateien der Versionen 4 und 5 nicht miteinander kompatibel sind und daher ein einfaches Upgrade von einer Version auf eine andere nicht möglich ist. Die Datenmigration kann nur durch Hoch- und Herunterladen von Daten erfolgen. In diesem Beitrag werde ich über die möglichen Optionen für diese Migration sprechen.
Migrationsoptionen bewerten
pg_dump & psql (oder pg_restore)
Dies ist zu langsam, wenn es um Dutzende von Terabyte geht, da alle Daten über die Masterknoten hochgeladen und heruntergeladen werden. Aber schnell genug, um DDL und kleine Tabellen zu migrieren. Sie können beide in eine Datei hochladen und pg_dump und psql gleichzeitig über eine Pipe in einem Quellcluster und einem Zielcluster ausführen. pg_dump lädt einfach in eine einzelne Datei hoch, die sowohl DDL-Befehle als auch COPY-Datenbefehle enthält. Die erhaltenen Daten können bequem verarbeitet werden, was unten gezeigt wird.
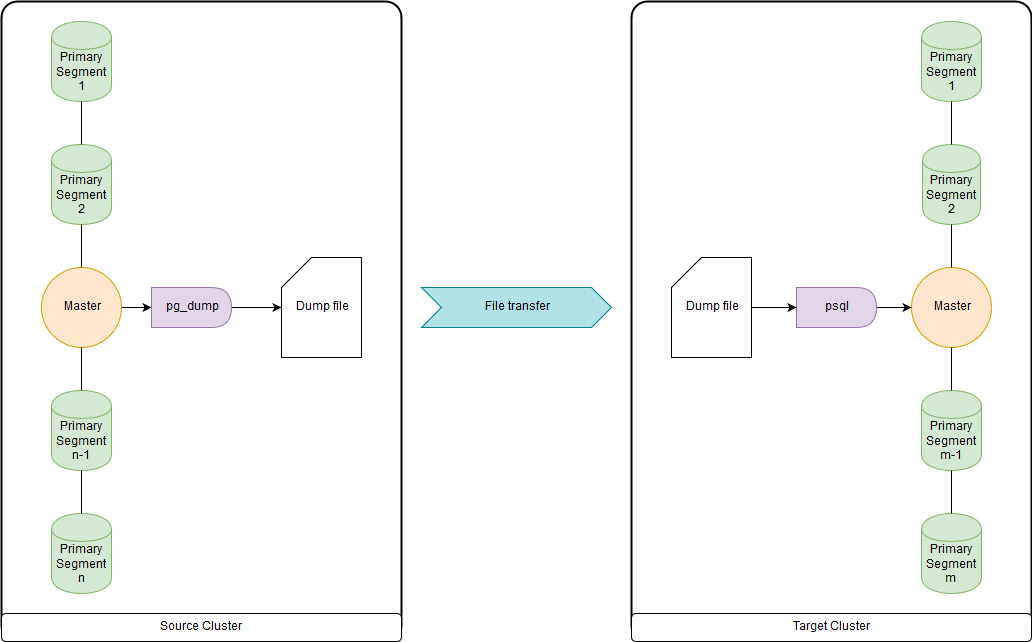
gptransfer
Benötigt Version Greenplum 4.2 oder höher. Es ist erforderlich, dass sowohl der Quellcluster als auch der Zielcluster gleichzeitig arbeiten. Der schnellste Weg, um große Datentabellen für die Open Source-Version zu migrieren. Diese Methode ist jedoch aufgrund des hohen Overheads sehr langsam für die Übertragung leerer und kleiner Tabellen.
gptransfer verwendet pg_dump zum Übertragen von DDL und gpfdist zum Übertragen von Daten. Die Anzahl der primären Segmente im Zielcluster darf nicht geringer sein als das Hostsegment im Quellcluster. Dies ist wichtig, wenn Sie Sandbox-Cluster erstellen, wenn Daten von den Hauptclustern an diese übertragen werden und die Verwendung des Dienstprogramms gptransfer geplant ist. Selbst wenn es nur wenige Segmenthosts gibt, können Sie die erforderliche Anzahl von Segmenten auf jedem von ihnen bereitstellen. Die Anzahl der Segmente im Zielcluster ist möglicherweise geringer als im Quellcluster. Dies
wirkt sich jedoch
nachteilig auf die Datenübertragungsgeschwindigkeit aus. Zwischen den Clustern muss die SSH-Authentifizierung für Zertifikate konfiguriert werden.
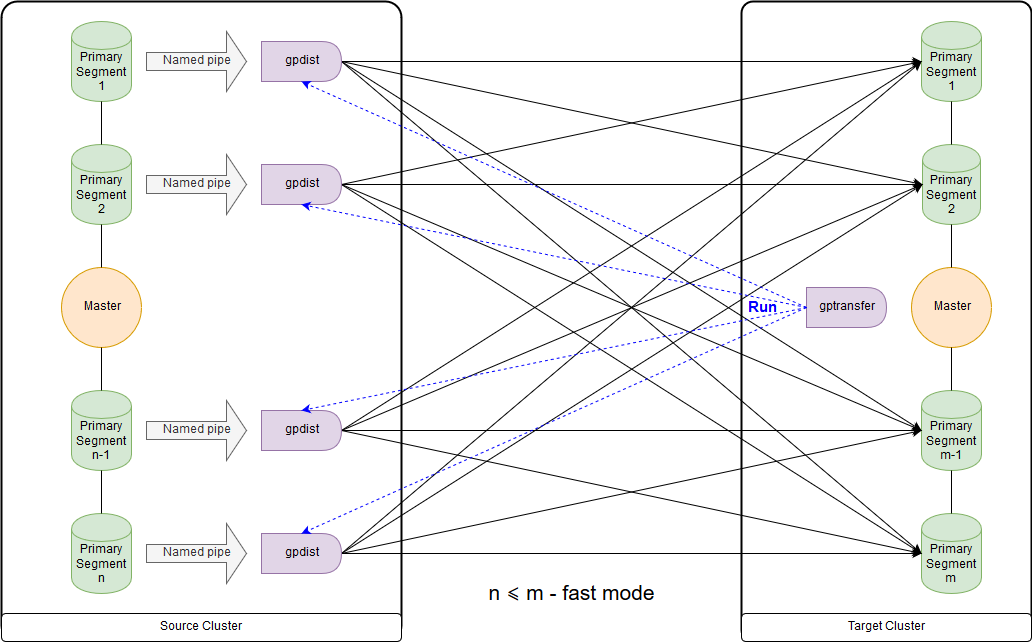
Dies ist das Schema für den Schnellmodus, wenn die Anzahl der Segmente im Zielcluster größer oder gleich der Anzahl im Quellcluster ist. Der Start des Dienstprogramms selbst ist in der Abbildung auf dem Hauptknoten des Empfängerclusters dargestellt. In diesem Modus wird im Quellcluster eine externe Schreibtabelle erstellt, die Daten zu jedem Segment in die Named Pipe schreibt. Der Befehl INSERT INTO writable_external_table SELECT * FROM source_table wird ausgeführt. Daten aus der Named Pipe werden von gpfdist gelesen. Im Zielcluster wird auch eine externe Tabelle nur zum Lesen erstellt. Die Tabelle gibt die Daten an, die gpfdist über
das gleichnamige Protokoll bereitstellt. Der Befehl INSERT INTO target_table SELECT * FROM external_gpfdist_table wird ausgeführt. Die Daten werden automatisch zwischen den Segmenten des Zielclusters neu verteilt.
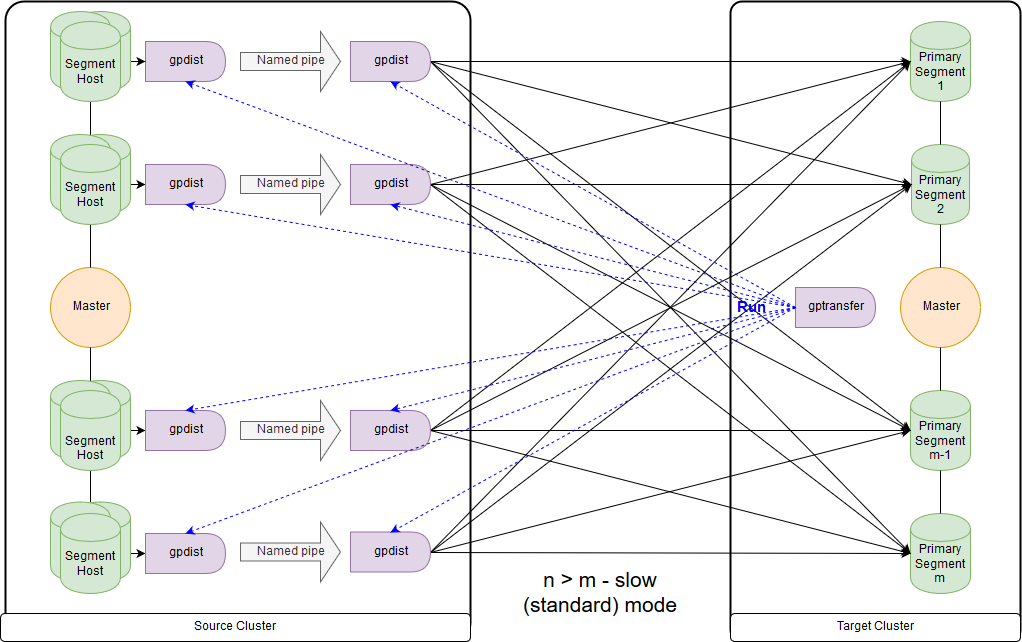
Und dies ist das Schema für den langsamen Modus oder, wie gptransfer selbst herausgibt, den Standardmodus. Der Hauptunterschied besteht darin, dass auf jedem Segmenthost des Quellclusters ein gpfdist-Paar für alle Segmente dieses Segmenthosts gestartet wird. Eine externe Datensatztabelle bezieht sich auf gpfdist, der als Datenempfänger fungiert. Wenn im Parameter LOCATION der externen Tabelle mehrere Werte zum Schreiben angegeben sind, werden die Segmente beim Schreiben von Daten von gpfdist gleichmäßig verteilt. Daten zwischen gpfdist auf dem Hostsegment werden über Named Pipe übertragen. Aus diesem Grund ist die Datenübertragungsgeschwindigkeit geringer, sie ist jedoch immer noch schneller als bei der Datenübertragung nur über den Masterknoten.
Bei der Migration von Daten von Greenplum 4 nach Greenplum 5 muss gptransfer auf dem Masterknoten des Zielclusters ausgeführt werden. Wenn wir gptransfer auf dem Quellcluster ausführen, wird der Fehler
san_mounts Feld
san_mounts in der Tabelle
pg_catalog.gp_segment_configuration :
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
Sie müssen auch die GPHOME-Variablen überprüfen, damit sie zwischen dem Quellcluster und dem Zielcluster übereinstimmen. Andernfalls wird ein ziemlich seltsamer
Fehler angezeigt (das Dienstprogramm gptransfer schlägt fehl, wenn Quelle und Ziel unterschiedliche GPHOME-Pfade haben).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
Sie können einfach den entsprechenden Symlink erstellen und die GPHOME-Variable in der Sitzung überschreiben, in der gptransfer gestartet wird.
Wenn gptransfer auf dem Zielcluster gestartet wird, sollte die Option "--source-map-file" auf eine Datei verweisen, die eine Liste von Hosts und deren IP-Adressen mit primären Segmenten des Quellclusters enthält. Zum Beispiel:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
Mit der Option "--full" können nicht nur Tabellen, sondern die gesamte Datenbank übertragen werden. Benutzerdatenbanken sollten jedoch nicht im Zielcluster erstellt werden. Beachten Sie auch, dass beim Verschieben externer Tabellen Probleme aufgrund von Syntaxänderungen auftreten.
Lassen Sie uns den zusätzlichen Overhead bewerten, indem wir beispielsweise 10 leere Tabellen (Tabellen von big_db.public.test_table_2 nach big_db.public.test_table_11) mit gptarnsfer kopieren:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
Infolgedessen dauerte die Übertragung von 10 leeren Tabellen ungefähr 16 Sekunden (14: 40-15: 02), dh eine Tabelle - 1,6 Sekunden. In dieser Zeit können in unserem Fall mit pg_dump & psql ca. 100 MB Daten heruntergeladen werden.
gp_dump & gp_restore
Optional: Verwenden Sie Add-Ons über ihnen, gpcrondump & gpdbrestore, da gp_dump & gp_restore als veraltet deklariert sind. Obwohl gpcrondump & gpdbrestore selbst gp_dump & gp_restore verwenden. Dies ist der universellste Weg, aber nicht der schnellste. Die mit gp_dump erstellten Sicherungsdateien stellen eine Reihe von DDL-Befehlen auf dem Masterknoten und auf den primären Segmenten dar, hauptsächlich Sätze von COPY-Befehlen und -Daten. Geeignet für Fälle, in denen der gleichzeitige Betrieb des Zielclusters und des Quellclusters nicht möglich ist. Es gibt sowohl alte als auch neue Versionen von Greenplum:
gp_dump ,
gp_restore .
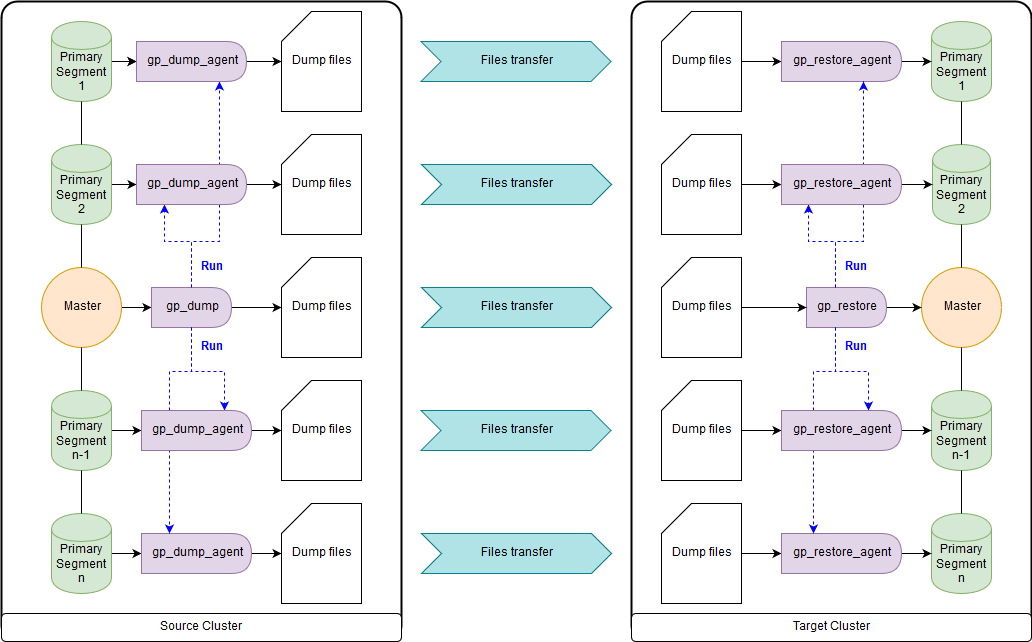
Gpbackup & gprestore Dienstprogramme
Erstellt als Ersatz für gp_dump & gp_restore. Für ihre Arbeit ist mindestens die Greenplum-Version 4.3.17 erforderlich (
const MINIMUM_GPDB4_VERSION = "4.3.17" ). Das Arbeitsschema ähnelt gpbackup & gprestore, während die Arbeitsgeschwindigkeit viel schneller ist. Der schnellste Weg, um DDL-Befehle für große Datenbanken zu erhalten. Standardmäßig werden globale Objekte übertragen. Für die Wiederherstellung müssen Sie "gprestore --with-globals" angeben. Der optionale Parameter "--jobs" kann die Anzahl der Jobs (und Sitzungen in der Datenbank) beim Erstellen einer Sicherung festlegen. Aufgrund der Tatsache, dass mehrere Sitzungen erstellt werden, ist es wichtig, die Konsistenz der Daten sicherzustellen, bis alle Sperren empfangen wurden. Es gibt auch eine nützliche Option "--with-stats", mit der Sie Statistiken zu Objekten übertragen können, die zum Erstellen von Ausführungsplänen verwendet werden. Weitere Informationen
hier .
Gpcopy-Dienstprogramm
Zum Kopieren von Datenbanken gibt es ein Dienstprogramm gpcopy - ein Ersatz für gptansfer. Es ist jedoch nur in der proprietären Version von Greenplum von Pivotal ab 4.3.26 enthalten - in der Open Source-Version ist
dies bei diesem Dienstprogramm nicht der Fall . Während der Arbeit am Quellcluster wird der Befehl COPY source_table TO PROGRAM 'gpcopy_helper ...' ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS ausgeführt. Auf der Seite des empfangenden Clusters wird eine temporäre externe Tabelle CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' erstellt und der Befehl INSERT INTO target_table SELECT * FROM external_temp_table ausgeführt. Infolgedessen wird gpcopy_helper mit dem Parameter –listen für jedes Segment des Zielclusters gestartet, das Daten von gpcopy_helper von Segmenten des Quellclusters empfängt. Aufgrund eines solchen Datenübertragungsschemas sowie der Komprimierung ist die Übertragungsgeschwindigkeit viel höher. Zwischen Clustern muss auch die SSH-Authentifizierung für Zertifikate konfiguriert werden. Ich möchte auch darauf hinweisen, dass gpcopy eine praktische Option "--truncate-source-after" (und "--validate") für Fälle hat, in denen sich die Quell- und Zielcluster auf denselben Servern befinden.
Datenübertragungsstrategie
Um die Übertragungsstrategie zu bestimmen, müssen wir bestimmen, was für uns wichtiger ist: Daten schnell übertragen, aber mit mehr Arbeit und möglicherweise weniger zuverlässig (gpbackup, gptransfer oder eine Kombination davon) oder mit weniger Arbeit, aber langsamer (gpbackup oder gptransfer ohne Kombination).
Der schnellste Weg zum Übertragen von Daten - wenn es einen Quellcluster und einen Zielcluster gibt - ist der folgende:
- Holen Sie sich DDL mit gpbackup --metadata-only, konvertieren Sie und laden Sie mit psql durch die Pipeline
- Indizes löschen
- Übertragen Sie Tabellen mit einer Größe von 100 MB oder mehr mit gptransfer
- Übertragen Sie Tabellen mit einer Größe von weniger als 100 MB mit pg_dump | psql wie im ersten absatz
- Erstellen Sie gelöschte Indizes zurück
Diese Methode erwies sich in unseren Messungen als mindestens zweimal schneller als gp_dump & gp_restore. Alternative Methoden: Übertragen aller Datenbanken mit gptransfer –full, gpbackup & gprestore oder gp_dump & gp_restore.
Tabellengrößen können durch die folgende Abfrage erhalten werden:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
Notwendige Umbauten
Sicherungsdateien in den Greenplum-Versionen 4 und 5 sind ebenfalls nicht vollständig kompatibel. In Greenplum 5 haben die Befehle CREATE EXTERNAL TABLE und COPY aufgrund einer Änderung der Syntax nicht den Parameter INTO ERROR TABLE, und Sie müssen den SET-Parameter gp_ignore_error_table auf true setzen, damit die Wiederherstellung der Sicherung nicht versehentlich fehlschlägt. Mit dem Parametersatz erhalten wir nur eine Warnung.
Darüber hinaus wurde in der fünften Version ein anderes Protokoll für die Interaktion mit externen pxf-Tabellen eingeführt. Um es zu verwenden, müssen Sie den Parameter LOCATION ändern und den pxf-Dienst konfigurieren.
Es ist auch erwähnenswert, dass in den Sicherungsdateien gp_dump & gp_restore sowohl auf dem Masterknoten als auch auf jedem primären Segment der Parameter SET gp_strict_xml_parse auf false gesetzt ist. In Greenplum 5 gibt es keinen solchen Parameter, und als Ergebnis erhalten wir eine Fehlermeldung.
Wenn das gphdfs-Protokoll für externe Tabellen verwendet wurde, müssen Sie in den Sicherungsdateien die Liste der Quellen im Parameter LOCATION für externe Tabellen in der Zeile 'gphdfs: //' überprüfen. Zum Beispiel sollte es nur 'gphdfs: //hadoop.local: 8020' geben. Wenn andere Zeilen vorhanden sind, müssen diese analog zum Ersatzskript auf dem Masterknoten hinzugefügt werden.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
Wir ersetzen den Masterknoten (am Beispiel der Datendatei gp_dump):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
In neueren Versionen wurde der Profilname von HdfsTextSimple
als veraltet deklariert . Der neue Name lautet hdfs: text.
Zusammenfassung
Außerhalb des Artikels bestand weiterhin die Notwendigkeit einer expliziten Konvertierung in Text (
Implicit Text Casting ), einem neuen Cluster-Ressourcenverwaltungsmechanismus für Ressourcengruppen, der Resource Queues (
GPORCA- Optimierer) ersetzte, der standardmäßig in Greenplum 5 enthalten ist, kleinere Probleme mit Clients.
Ich freue mich auf die Veröffentlichung der sechsten Version von Greenplum, die für das Frühjahr 2019 geplant ist: Kompatibilitätsstufe mit PostgreSQL 9.4, Volltextsuche, Unterstützung des GIN-Index, Bereichstypen, JSONB, zStd-Komprimierung. Außerdem wurden vorläufige Pläne für Greenplum 7 bekannt: Kompatibilitätsstufe mit PostgreSQL mindestens 9.6, Sicherheit auf Zeilenebene, automatisiertes Master-Failover. Die Entwickler versprechen auch die Verfügbarkeit von Dienstprogrammen zur Datenbankaktualisierung für die Aktualisierung zwischen Hauptversionen, damit das Leben einfacher wird.
Dieser Artikel wurde vom Datenverwaltungsteam von Rostelecom erstellt