Die Methode des koordinatenweisen Abstiegs ist eine der einfachsten Methoden der mehrdimensionalen Optimierung und eignet sich gut, um ein lokales Minimum an Funktionen mit einer relativ glatten Topographie zu finden. Daher ist es besser, sich mit den Optimierungsmethoden vertraut zu machen.
Die Suche nach dem Extremum wird in Richtung der Koordinatenachsen durchgeführt, d.h. Während des Suchvorgangs wird nur eine Koordinate geändert. Somit reduziert sich ein mehrdimensionales Problem auf ein eindimensionales.
Algorithmus
Erster Zyklus:
- x1=var , x2=x02 , x3=x03 , ..., xn=x0n .
- Auf der Suche nach extremen Funktionen f(x1) . Setzen Sie das Extremum der Funktion auf den Punkt x11 .
- x1=x11 , x2=var , x3=x03 , ..., xn=x0n . Extremum-Funktion f(x2) ist gleich x12
- ...
- x1=x11 , x2=x12 , x3=x13 , ..., xn=var .
Als Ergebnis der Durchführung von n Schritten wurde ein neuer Ansatzpunkt für das Extremum gefunden (x11,x12,...,x1n) . Als nächstes überprüfen wir das Kriterium für das Ende des Kontos: Wenn es erfüllt ist, wird die Lösung gefunden, andernfalls führen wir einen weiteren Zyklus durch.
Vorbereitung
Überprüfen Sie die Paketversionen:
(v1.1) pkg> status Status `C:\Users\User\.julia\environments\v1.1\Project.toml` [336ed68f] CSV v0.4.3 [a93c6f00] DataFrames v0.17.1 [7073ff75] IJulia v1.16.0 [47be7bcc] ORCA v0.2.1 [58dd65bb] Plotly v0.2.0 [f0f68f2c] PlotlyJS v0.12.3 [91a5bcdd] Plots v0.23.0 [ce6b1742] RDatasets v0.6.1 [90137ffa] StaticArrays v0.10.2 [8bb1440f] DelimitedFiles [10745b16] Statistics
Wir definieren eine Funktion zum Zeichnen der Oberflächen- oder Ebenenlinien, in der es zweckmäßig wäre, die Grenzen des Diagramms anzupassen:
using Plots plotly()
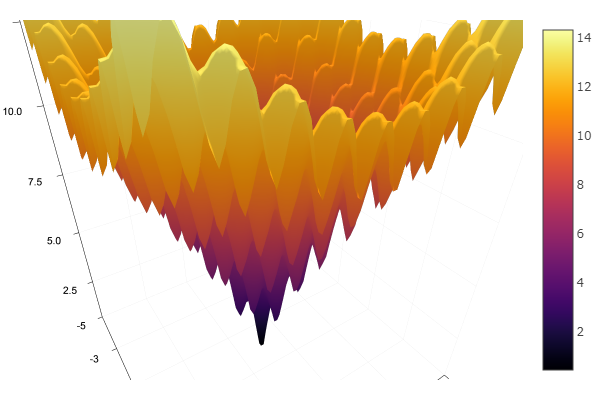
Als Modellfunktion wählen wir ein elliptisches Paraboloid
parabol(x) = sum(u->u*u, x) fun = parabol plotter(surface, low = [-1 -1], up = [1 1])
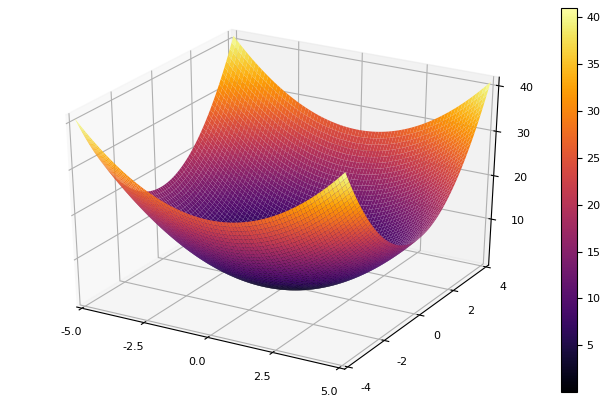
Abstieg koordinieren
Wir implementieren die Methode in eine Funktion, die den Namen der eindimensionalen Optimierungsmethode, die Dimension des Problems, den gewünschten Fehler, die anfängliche Annäherung und die Einschränkungen für das Zeichnen von Linien auf Ebenen verwendet. Alle Parameter sind auf Standardwerte eingestellt.
function ofDescent(odm; ndimes = 2, ε = 1e-4, fit = [.5 .5], low = [-1 -1], up = [1 1]) k = 1
Als nächstes werden wir verschiedene Methoden der eindimensionalen Optimierung ausprobieren.
Newtons Methode
xn+1=xn− fracf(xn)f′(xn)
Die Idee der Methode ist ebenso einfach wie die Implementierung

Newton stellt hohe Anforderungen an die anfängliche Annäherung, und ohne Einschränkung der Stufen kann er problemlos auf unbekannte Entfernungen fahren. Die Berechnung der Ableitung ist wünschenswert, auf kleine Abweichungen kann jedoch verzichtet werden. Wir ändern unsere Funktion:
function newton(i, fit, ϵ) k = 1 oldfit = Inf x = [] y = [] push!(x, fit[1]) push!(y, fit[2]) while ( abs(oldfit - fit[i]) > ϵ && k<50 ) fx = fun(fit) oldfit = fit[i] fit[i] += 0.01 dfx = fun(fit) fit[i] -= 0.01 tryfit = fx*0.01 / (dfx-fx)

Inverse parabolische Interpolation
Eine Methode, die keine Kenntnis der Ableitung erfordert und eine gute Konvergenz aufweist
function ipi(i, fit, ϵ)
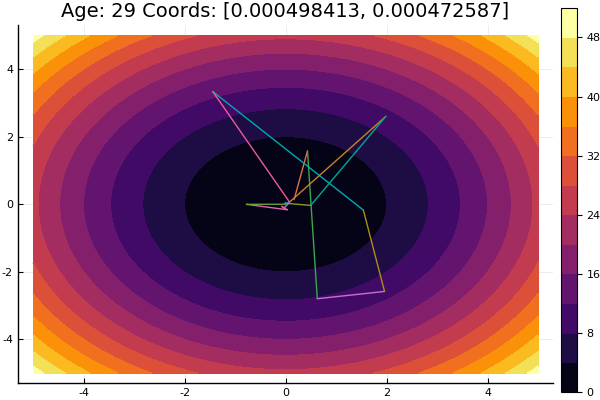
Wenn wir die anfängliche Annäherung verschlechtern, wird die Methode eine immense Anzahl von Schritten für jede Ära des Koordinatenabfalls erfordern. In dieser Hinsicht gewinnt sein Bruder
Sequentielle parabolische Interpolation
Es erfordert auch drei Startpunkte , zeigt jedoch bei vielen Testfunktionen zufriedenstellendere Ergebnisse.
function spi(i, fit, ϵ)
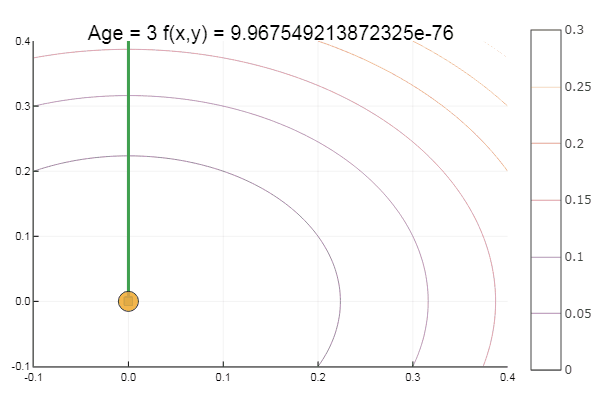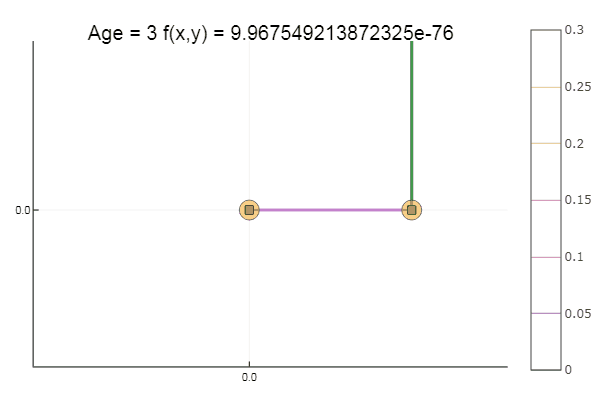
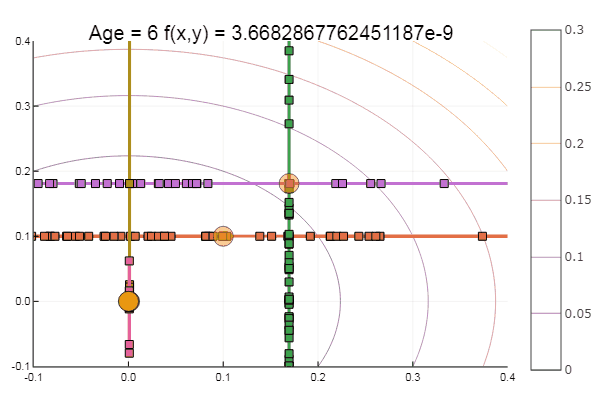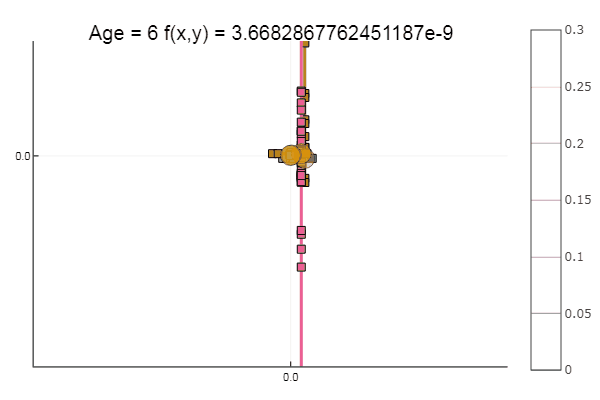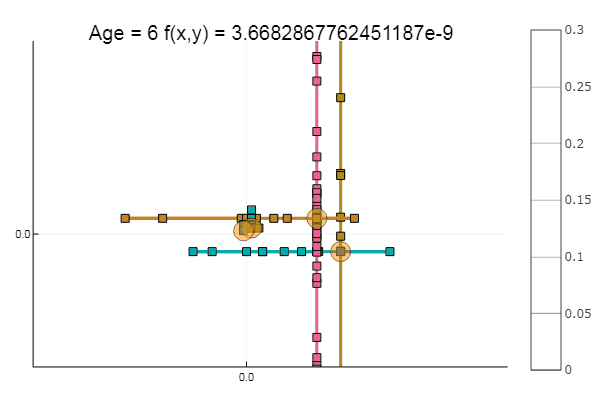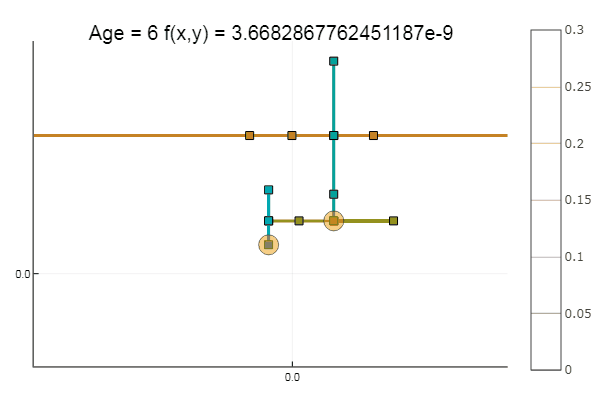
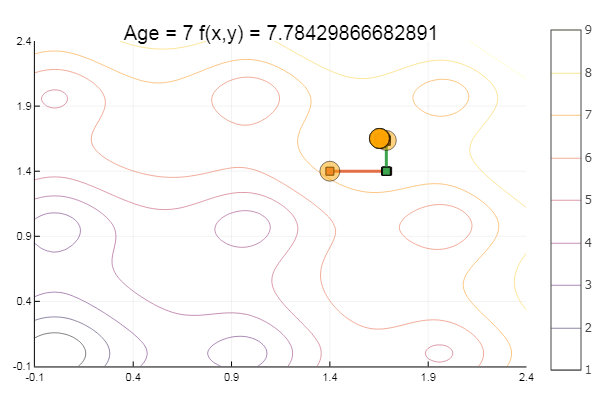
Das Verlassen eines sehr beschissenen Ausgangspunkts erfolgte in drei Schritten! Gut ... Aber alle Methoden haben einen Nachteil - sie konvergieren zu einem lokalen Minimum. Nehmen wir nun Ackleys Funktion für die Forschung
f(x,y)=−20 exp left[−0,2 sqrt0,5 left(x2+y2 right) right]− exp left[0,5 links( cos2 pix+ cos2 piy rechts) rechts]+e+20
ekly(x) = -20exp(-0.2sqrt(0.5(x[1]*x[1]+x[2]*x[2]))) - exp(0.5(cospi(2x[1])+cospi(2x[2]))) + 20 + ℯ

ofDescent(spi, fit = [1.4 1.4], low = [-.1 -.1], up = [2.4 2.4])
Goldener Schnitt-Methode
Theorie Obwohl die Implementierung kompliziert ist, zeigt sich die Methode manchmal gut, indem lokale Minima übersprungen werden
function interval(i, fit, st) d = 0. ab = zeros(2) fitc = copy(fit) ab[1] = fitc[i] Fa = fun(fitc) fitc[i] -= st Fdx = fun(fitc) fitc[i] += st if Fdx < Fa st = -st end fitc[i] += st ab[2] = fitc[i] Fb = fun(fitc) while Fb < Fa d = ab[1] ab[1] = ab[2] Fa = Fb fitc[i] += st ab[2] = fitc[i] Fb = fun(fitc)

Das ist alles mit koordiniertem Abstieg. Die Algorithmen der vorgestellten Methoden sind recht einfach, sodass die Implementierung in Ihrer bevorzugten Sprache nicht schwierig ist. In Zukunft können Sie die integrierten Tools der Julia- Sprache in Betracht ziehen, aber jetzt möchten Sie sozusagen alles mit Ihren Händen fühlen, Methoden komplizierter und effizienter betrachten, dann können Sie zur globalen Optimierung übergehen und gleichzeitig mit der Implementierung in einer anderen Sprache vergleichen.
Literatur
- Zaitsev V.V. Numerische Methoden für Physiker. Nichtlineare Gleichungen und Optimierung: ein Tutorial. - Samara, 2005 - 86er Jahre.
- Ivanov A. V. Computermethoden zur Optimierung optischer Systeme. Studienführer. –SPb: SPbSU ITMO, 2010 - 114s.
- Popova T. M. Methoden der mehrdimensionalen Optimierung: Richtlinien und Aufgaben für die Laborarbeit in der Disziplin "Methoden der Optimierung" für Studierende der Richtung "Angewandte Mathematik" / comp. T. M. Popova. - Chabarowsk: Verlag des Pazifiks. Zustand Universität, 2012 .-- 44 p.