Wie komplex ist das Thema maschinelles Lernen? Wenn Sie gut in Mathematik sind, aber das Wissen über maschinelles Lernen gegen Null geht, wie weit können Sie in einem ernsthaften Wettbewerb auf der
Kaggle- Plattform gehen?

Über die Seite und die Konkurrenz
Kaggle ist eine Community von Menschen, die sich für ML interessieren (vom Anfänger bis zum coolen Profi) und ein Veranstaltungsort für Wettbewerbe (oft mit einem beeindruckenden Preispool).
Um sofort in alle Reize von ML einzutauchen, entschied ich mich sofort für einen ernsthaften Wettbewerb. Dies war gerade verfügbar:
Two Sigma: Verwenden von Nachrichten zur Vorhersage von Aktienbewegungen . Das Wesentliche des Wettbewerbs auf den Punkt gebracht ist die Vorhersage des Aktienkurses verschiedener Unternehmen auf der Grundlage des Status des Vermögenswerts und der mit diesem Vermögenswert verbundenen Nachrichten. Der Preisfonds des Wettbewerbs beträgt 100.000 US-Dollar und wird an die Teilnehmer verteilt, die die ersten sieben Plätze gewonnen haben.
Der Wettbewerb ist aus zwei Gründen etwas Besonderes:
- Dies ist ein Nur-Kernel-Wettbewerb: Sie können Modelle nur in der Kaggle-Kernel-Cloud trainieren.
- Die endgültige Sitzverteilung wird erst sechs Monate nach Abschluss der Entscheidungsfindung bekannt sein. Während dieser Zeit werden Entscheidungen die Preise zum aktuellen Datum vorhersagen.
Über die Aufgabe
Unter bestimmten Bedingungen müssen wir das Vertrauen vorhersagen
, dass sich die Rendite des Vermögenswerts erhöht. Die Rendite eines Vermögenswerts wird im Verhältnis zur Gesamtmarktrendite betrachtet. Die
Zielmetrik ist benutzerdefiniert - es handelt sich nicht um die bekanntere
RMSE oder
MAE , sondern um
die Sharpe-Ratio , die in diesem Fall wie folgt betrachtet wird:
wo
,
- die Kapitalrendite i im Verhältnis zum Markt für Tag t an einem 10-Tage-Horizont,
- eine boolesche Variable, die angibt, ob der i-te Vermögenswert in der Bewertung für Tag t enthalten ist,
- mittlere Bedeutung
,
- Standardabweichung
.
Die Sharpe Ratio ist die risikobereinigte Rendite, die Werte des Koeffizienten zeigen die Effektivität des Händlers:
- weniger als 1: schlechte Leistung
- 1 - 2: mittlere, normale Effizienz,
- 2 - 3: hervorragende Leistung,
- über 3: perfekt.
Marktbewegungsdaten- time (datetime64 [ns, UTC]) - aktuelle Zeit (in den Daten zur Marktbewegung in allen Zeilen um 22:00 UTC)
- AssetCode (Objekt) - Asset- ID
- AssetName (Kategorie) - Eine Kennung einer Asset-Gruppe für die Kommunikation mit Nachrichtendaten
- Universum (float64) - Ein boolescher Wert, der angibt, ob dieser Vermögenswert bei der Berechnung der Punktzahl berücksichtigt wird
- Volumen (float64) - tägliches Handelsvolumen
- close (float64) - Schlusskurs für diesen Tag
- open (float64) - offener Preis für diesen Tag
- ReturnsClosePrevRaw1 (float64) - Rendite vom Abschluss zum Abschluss des Vortages
- returnOpenPrevRaw1 (float64) - Rentabilität von Eröffnung zu Eröffnung für den Vortag
- ReturnsClosePrevMktres1 (float64) - Rentabilität vom Abschluss bis zum Abschluss des Vortages, angepasst an die Bewegung des gesamten Marktes
- ReturnsOpenPrevMktres1 (float64) - Rentabilität von Eröffnung zu Eröffnung für den Vortag, angepasst an die Bewegung des gesamten Marktes
- ReturnsClosePrevRaw10 (float64) - Rendite von nahe an Schluss für die letzten 10 Tage
- returnOpenPrevRaw10 (float64) - Rentabilität von Eröffnung zu Eröffnung für die letzten 10 Tage
- ReturnsClosePrevMktres10 (float64) - Rendite von nahe an Schluss für die letzten 10 Tage, angepasst an die Bewegung des gesamten Marktes
- ReturnsOpenPrevMktres10 (float64) - Rendite von Eröffnung zu Eröffnung für die letzten 10 Tage, angepasst an die Bewegung des gesamten Marktes
- returnOpenNextMktres10 (float64) - Rendite von offen bis offen in den nächsten 10 Tagen, angepasst an die Bewegung des gesamten Marktes. Wir werden diesen Wert vorhersagen.
Nachrichtendaten- time (datetime64 [ns, UTC]) - Zeit für die Verfügbarkeit von UTC-Daten
- sourceTimestamp (datetime64 [ns, UTC]) - Zeit in UTC-Veröffentlichungsnachrichten
- firstCreated (datetime64 [ns, UTC]) - Zeit in UTC der ersten Version der Daten
- sourceId (Objekt) - Datensatzkennung
- Überschrift (Objekt) - Titel
- Dringlichkeit (int8) - Arten von Nachrichten (1: Alarm, 3: Artikel)
- takeSequence (int16) - nicht ganz klarer Parameter, Nummer in einer bestimmten Reihenfolge
- Anbieter (Kategorie) - Kennung des Nachrichtenanbieters
- Themen (Kategorie) - Eine Liste der Codes für Nachrichtenthemen (kann ein geografisches Zeichen, ein Ereignis, ein Industriesektor usw. sein).
- Zielgruppen (Kategorie) - Liste der Nachrichten zu Zielgruppencodes
- bodySize (int32) - Anzahl der Zeichen im Nachrichtentext
- companyCount (int8) - Anzahl der Unternehmen, die in den Nachrichten ausdrücklich erwähnt werden
- headlineTag (Objekt) - ein bestimmtes Titel-Tag von Thomson Reuters
- marketCommentary (bool) - ein Zeichen dafür, dass sich die Nachrichten auf die allgemeinen Marktbedingungen beziehen
- Satzzahl (int16) - Anzahl der Angebote in den Nachrichten
- wordCount (int32) - Anzahl der Wörter und Satzzeichen in den Nachrichten
- AssetCodes (Kategorie) - Liste der in den Nachrichten genannten Assets
- AssetName (Kategorie) - Asset-Gruppencode
- firstMentionSentence (int16) - ein Satz, der zuerst einen Vermögenswert erwähnt:
- Relevanz (float32) - eine Zahl von 0 bis 1, die die Relevanz der Nachrichten in Bezug auf den Vermögenswert anzeigt
- sentimentClass (int8) - Nachrichten-Tonalitätsklasse
- sentimentNegative (float32) - Wahrscheinlichkeit, dass die Tonalität negativ ist
- sentimentNeutral (float32) - Wahrscheinlichkeit, dass der Ton neutral ist
- sentimentPositive (float32) - Wahrscheinlichkeit, dass der Schlüssel positiv ist
- sentimentWordCount (int32) - Die Anzahl der Wörter im Text, die sich auf das Asset beziehen
- noveltyCount12H (int16) - Neuheitsnachrichten in 12 Stunden, berechnet im Vergleich zu früheren Nachrichten zu diesem Vermögenswert
- noveltyCount24H (int16) - gleich, in 24 Stunden
- noveltyCount3D (int16) - gleich, in 3 Tagen
- noveltyCount5D (int16) - gleich, in 5 Tagen
- noveltyCount7D (int16) - gleich, in 7 Tagen
- volumeCounts12H (int16) - Die Anzahl der Nachrichten zu diesem Asset in 12 Stunden
- volumeCounts24H (int16) - gleich in 24 Stunden
- volumeCounts3D (int16) - gleich in 3 Tagen
- volumeCounts5D (int16) - 5 Tage lang gleich
- volumeCounts7D (int16) - gleich, in 7 Tagen
Die Aufgabe ist im Wesentlichen die Aufgabe der binären Klassifizierung, dh wir sagen ein binäres Vorzeichen voraus, wird die Ausbeute steigen (1 Klasse) oder abnehmen (0 Klasse).
Informationen zu Tools
Kaggle Kernels ist eine Cloud-Computing-Plattform, die die Zusammenarbeit unterstützt. Die folgenden Kerneltypen werden unterstützt:
- Python-Skript
- R-Skript
- Jupyter Notizbuch
- RMarkdown
Jeder Kernel wird in seinem Docker-Container ausgeführt. Eine große Anzahl von Paketen ist im Container installiert, eine Liste für Python finden Sie
hier . Technische Spezifikationen sind wie folgt:
- CPU: 4 Kerne,
- RAM: 17 GB,
- Laufwerk: 5 GB permanent und 16 GB temporär,
- Maximale Skriptlaufzeit: 9 Stunden (zu Beginn des Wettbewerbs waren es 6 Stunden).
GPUs sind auch in Kerneln verfügbar, jedoch war die GPU in diesem Wettbewerb verboten.
Keras ist ein neuronales Netzwerk-Framework auf hoher Ebene, das auf
TensorFlow ,
CNTK oder
Theano ausgeführt wird . Es ist eine sehr praktische und verständliche API, und es ist möglich, Ihre Netzwerktopologien, Verlustfunktionen und mehr mithilfe der Backend-API hinzuzufügen.
Scikit-learn ist eine große Bibliothek von Algorithmen für maschinelles Lernen. Eine nützliche Quelle für Datenvorverarbeitungs- und Datenanalysealgorithmen zur Verwendung mit spezielleren Frameworks.
Modellvalidierung
Bevor Sie ein Modell zur Bewertung einreichen, müssen Sie lokal überprüfen, wie gut es funktioniert - das heißt, einen Weg zur lokalen Validierung finden. Ich habe folgende Ansätze ausprobiert:
- Kreuzvalidierung vs. einfache proportionale Aufteilung in Trainings- / Testsätze;
- lokale Berechnung des Sharpe-Verhältnisses gegenüber der ROC- AUC .
Infolgedessen zeigten die Ergebnisse, die der Wettbewerbsbewertung am nächsten kamen, seltsamerweise eine Kombination aus der proportionalen Partition (empirisch ausgewählte Partition 0,85 / 0,15) und der AUC. Eine Kreuzvalidierung ist wahrscheinlich nicht sehr geeignet, da das Marktverhalten in den frühen Phasen der Trainingsdaten und im Evaluierungszeitraum sehr unterschiedlich ist. Warum die AUC besser funktionierte als die Sharpe Ratio - kann ich überhaupt nicht sagen.
Erste Versuche
Da die Aufgabe darin besteht, die Zeitreihen vorherzusagen, wurde zunächst die klassische Lösung getestet - ein wiederkehrendes neuronales Netzwerk (
RNN ) bzw. seine Varianten
LSTM und
GRU .
Das Hauptprinzip wiederkehrender Netzwerke besteht darin, dass für jeden Ausgabewert nicht eine Stichprobe eingegeben wird, sondern eine ganze Sequenz. Daraus folgt:
- Wir brauchen eine Vorverarbeitung der Anfangsdaten - die Erzeugung genau dieser Sequenzen mit einer Länge von t Tagen für jedes Asset.
- Ein Modell, das auf einem wiederkehrenden Netzwerk basiert, kann den Ausgabewert nicht vorhersagen, wenn für die letzten t Tage keine Daten vorliegen.
Ich habe Sequenzen für jeden Tag generiert, beginnend mit t, sodass für ziemlich große t (von 20) der gesamte Satz von Trainingsmustern nicht mehr in den Speicher passte. Das Problem wurde mithilfe von Generatoren gelöst, da Keras Generatoren als Eingabe- und Ausgabedatensätze für Training und Vorhersage verwenden kann.
Die anfängliche Aufbereitung der Daten war so naiv wie möglich: Wir nehmen die gesamten Marktdaten und fügen einige Funktionen hinzu (Wochentag, Monat, Wochennummer des Jahres), und wir berühren die Nachrichtendaten überhaupt nicht.
Das erste Modell verwendete t = 10 und sah folgendermaßen aus:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
Aus diesem Modell wurde nichts Angemessenes herausgedrückt, die Punktzahl lag nahe Null (sogar ein kleines Minus).
Zeitliche Faltungsnetzwerke
Eine modernere neuronale Netzwerklösung für die Vorhersage von Zeitreihen ist TCN. Das Wesen dieser Topologie ist sehr einfach: Wir nehmen ein eindimensionales Faltungsnetzwerk und wenden es auf unsere Sequenz der Länge t an. Fortgeschrittenere Optionen verwenden mehrere Faltungsschichten mit unterschiedlicher Dilatation. Die TCN-Implementierung wurde teilweise
von hier kopiert (manchmal auf
Ideenebene ) (TCN-Stack-Visualisierung aus
dem Wavenet-Artikel ).
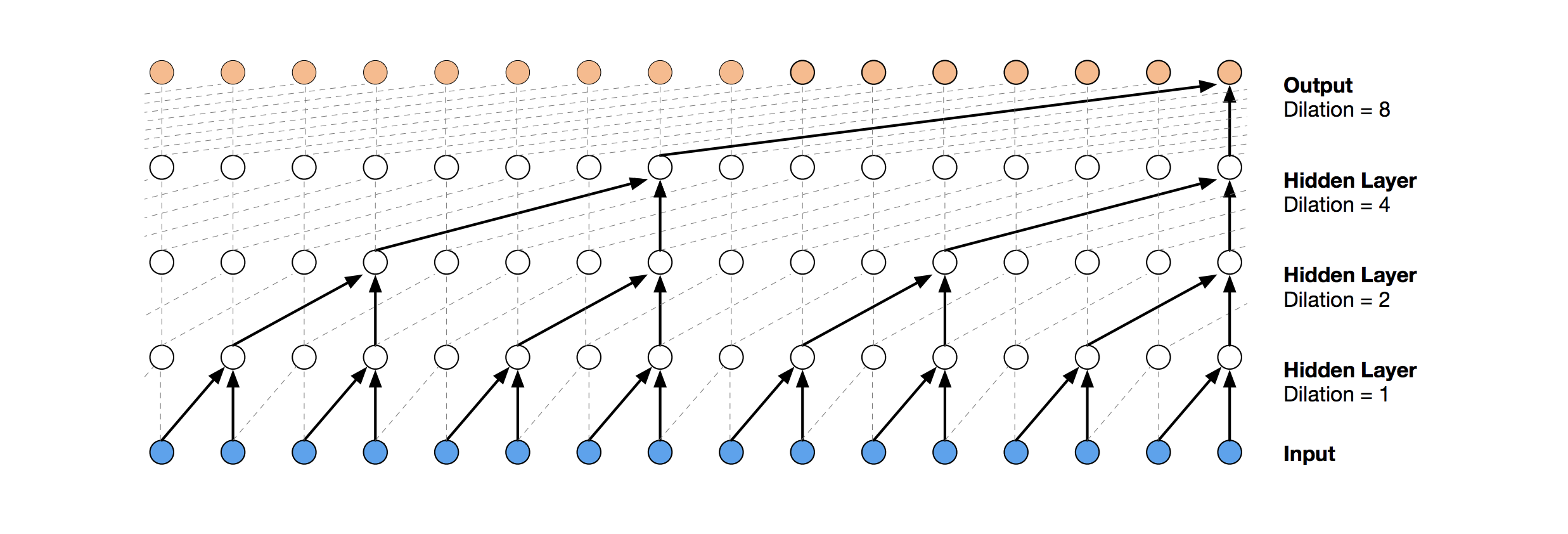
Die erste relativ erfolgreiche Lösung war dieses Modell, das eine GRU-Schicht über TCN enthält:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
Ein solches Modell ergibt eine Punktzahl von 0,27668. Mit ein wenig Abstimmung (Anzahl der TCN-Filter, Chargengröße) und einer Erhöhung von t auf 100 erhalten wir bereits 0,41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
Als nächstes fügen wir Normalisierung und Dropout hinzu:
Code batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
Bei Anwendung dieses Modells, auch in den ersten Schritten (mit t = 1), erhalten wir eine Punktzahl von 0,53578.
Gradientenverstärkungsmaschinen
Zu diesem Zeitpunkt endeten die Ideen und ich beschloss, das zu tun, was am Anfang getan werden musste: die öffentlichen Entscheidungen anderer Teilnehmer zu sehen. Die meisten guten Lösungen verwendeten überhaupt keine neuronalen Netze und bevorzugten GBM.
Gradient Boosting ist eine ML-Methode, an deren Ausgabe wir ein Ensemble einfacher Modelle (meistens Entscheidungsbäume) erhalten. Aufgrund der Vielzahl solcher einfachen Modelle wird die Verlustfunktion optimiert. Hier können Sie beispielsweise mehr über Gradient Boosting lesen.
Als Implementierung von GBM wurde
lightgbm verwendet - ein ziemlich bekanntes Framework von Microsoft.
Die hier vorgenommene Modell- und Datenvorverarbeitung ergibt sofort eine Punktzahl von ca. 0,64:
Code def prepare_data(marketdf, newsdf):
Die Vorverarbeitung umfasst hier bereits Nachrichtendaten, die mit Marktdaten kombiniert werden (dabei wird jedoch eher naiv nur ein Asset-Code von allen in den Nachrichten genannten berücksichtigt). Ich habe diese Vorverarbeitungsoption als Grundlage für alle nachfolgenden Entscheidungen genommen.
Durch Hinzufügen einer kleinen Funktion (firstMentionSentence, marketCommentary, sentimentClass) und Ersetzen der Metrik durch
ROC AUC erhalten wir eine Punktzahl von 0,65389.
Ensemble
Die nächste erfolgreiche Entscheidung war die Verwendung eines Ensembles, das aus einem neuronalen Netzwerkmodell und GBM besteht (obwohl „Ensemble“ ein großer Name für zwei Modelle ist). Die resultierende Vorhersage wird erhalten, indem die Vorhersagen der beiden Modelle gemittelt werden, wodurch der Mechanismus der weichen Abstimmung angewendet wird. Diese Entscheidung erlaubte es, eine Punktzahl von 0,66879 zu erhalten.
Explorative Datenanalyse und Feature Engineering
Eine andere Sache war EDA. Nachdem wir gelesen haben, dass es wichtig ist, die Korrelation zwischen Features zu verstehen, erstellen wir ein solches Bild (die Bilder in diesem Abschnitt können angeklickt werden):
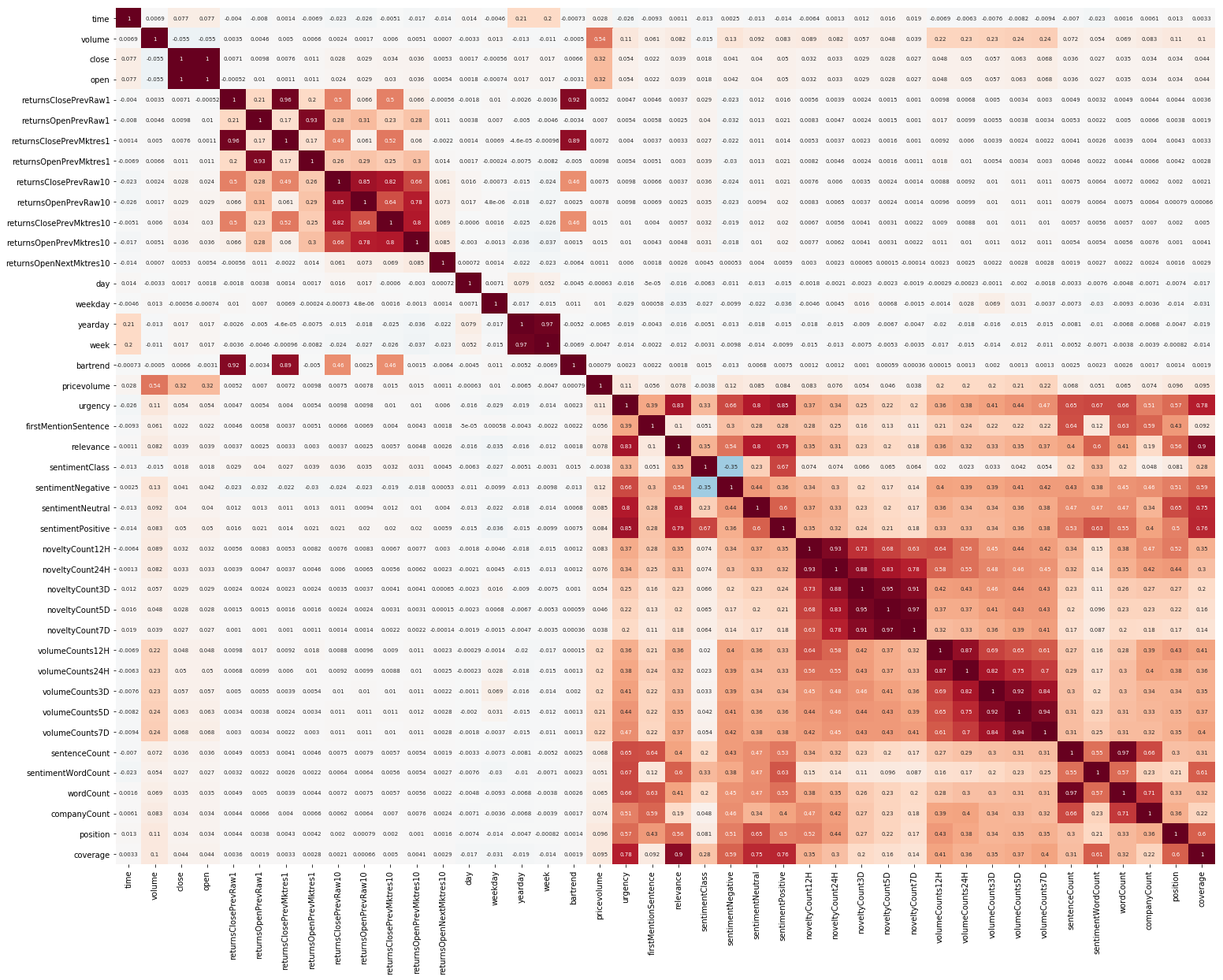
Hier ist deutlich zu sehen, dass die Korrelation innerhalb der Markt- und Nachrichtendaten ziemlich hoch ist, jedoch korrelieren nur die Werte der Renditen zumindest irgendwie mit dem Zielwert. Da die Daten eine Zeitreihe darstellen, ist es sinnvoll, auch die Autokorrelation des Zielwerts zu betrachten:
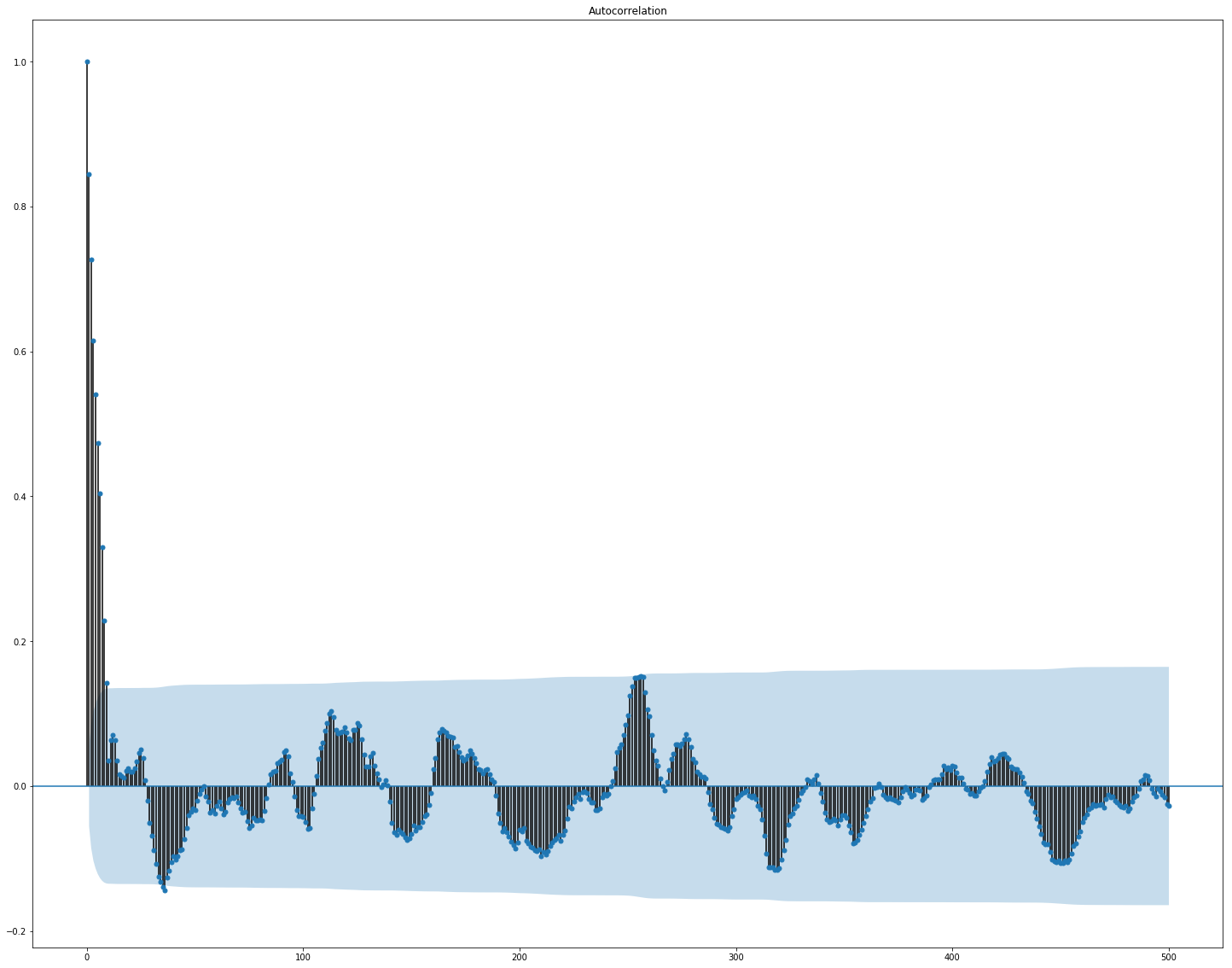
Es ist ersichtlich, dass nach einem Zeitraum von 10 Tagen die Abhängigkeit signifikant abnimmt. Dies ist wahrscheinlich der Grund dafür, dass GBM gut funktioniert, wenn nur Funktionen mit einer Verzögerung von 10 Tagen berücksichtigt werden (die bereits im Originaldatensatz enthalten sind).
Die Auswahl und Vorverarbeitung von Merkmalen ist für alle ML-Algorithmen von entscheidender Bedeutung. Versuchen wir, automatische Methoden zum Extrahieren von Features zu verwenden, nämlich
die Hauptkomponentenanalyse (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
Mal sehen, welche Funktionen die PCA generiert:

Wir sehen, dass die Methode bei unseren Daten nicht sehr gut funktioniert, da die endgültige Korrelation neuer Features mit dem Zielwert gering ist.
Feinabstimmung und ob es benötigt wird
Viele ML-Modelle haben eine ziemlich große Anzahl von Hyperparametern, dh die „Einstellungen“ des Algorithmus selbst. Sie können manuell ausgewählt werden, es gibt jedoch auch automatische Auswahlmechanismen. Für letztere gibt es eine
Hyperopt- Bibliothek, die zwei Übereinstimmungsalgorithmen implementiert - die Zufallssuche und den
baumstrukturierten Parzen Estimator (TPE) . Ich habe versucht zu optimieren:
- lightgbm-Parameter (Art des Algorithmus, Anzahl der Blätter, Lernrate und andere),
- Parameter neuronaler Netzwerkmodelle (Anzahl der TCN- Filter, Anzahl der GRU- Speicherblöcke, Dropout-Rate, Lernrate, Solver-Typ).
Infolgedessen ergaben alle mit dieser Optimierung gefundenen Lösungen eine niedrigere Punktzahl, obwohl sie bei den Testdaten besser funktionierten. Wahrscheinlich liegt der Grund in der Tatsache, dass die Daten, für die die Punktzahl berücksichtigt wird, den aus dem Training ausgewählten Validierungsdaten nicht sehr ähnlich sind. Daher ist eine Feinabstimmung für diese Aufgabe nicht sehr geeignet, da sie zu einer Umschulung des Modells führt.
Endgültige Entscheidung
Gemäß den Wettbewerbsregeln können die Teilnehmer zwei Lösungen für die Endphase auswählen. Meine endgültigen Entscheidungen sind fast gleich und enthalten ein Ensemble aus zwei Modellen -
GBM und Multilayer
GRU . Der einzige Unterschied besteht darin, dass eine Lösung überhaupt keine Nachrichtendaten verwendet und die andere, sondern nur für das neuronale Netzwerkmodell.
News Data Solution:
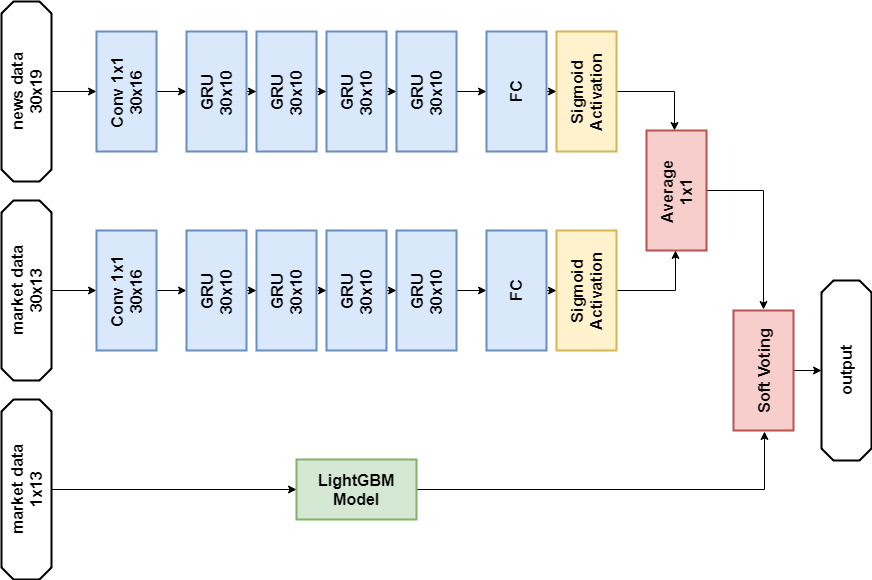
Importe import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
Neuronales Netzwerkmodell def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
GBM-Modell def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
Schulung n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
Vorhersage def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
Lösung ohne Nachrichtendaten:

Code (nur eine andere Methode) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Beide Entscheidungen ergaben in der ersten Phase des Wettbewerbs ein ähnliches Ergebnis (ca. 0,69), das 566 von 2.927 Plätzen entsprach. Nach dem ersten Monat mit neuen Daten wurden die Positionen in der Teilnehmerliste verwechselt, und die Lösung mit Nachrichtendaten lag auf dem 65. Platz der verbleibenden 697 Teams mit dem Ergebnis von 3,19251. und was in den nächsten fünf Monaten passieren wird, weiß niemand.
Was habe ich noch versucht?
Benutzerdefinierte Metriken
Da Entscheidungen anhand des Sharpe-Verhältnisses bewertet werden, ist es logisch, es als Messgröße für die vorzeitige Beendigung des Trainings zu verwenden.
Metrik für lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
Die Überprüfung ergab, dass eine solche Metrik bei diesem Problem schlechter funktioniert als die AUC.
Aufmerksamkeitsmechanismus
Der Aufmerksamkeitsmechanismus ermöglicht es dem neuronalen Netzwerk, sich auf die „wichtigsten“ Merkmale in den Quelldaten zu konzentrieren. Technisch gesehen wird die Aufmerksamkeit durch einen Vektor von Gewichten dargestellt (am häufigsten unter Verwendung einer vollständig verbundenen Schicht mit
Softmax- Aktivierung), die mit der Ausgabe einer anderen Schicht multipliziert werden. Ich habe eine Implementierung verwendet, bei der die Zeitachse berücksichtigt wird:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Dieses Modell sieht ziemlich hübsch aus, aber dieser Ansatz ergab keine Erhöhung der Punktzahl, es stellte sich heraus, dass es ungefähr 0,67 war.
Was hatte keine Zeit zu tun
Einige Bereiche, die vielversprechend aussehen:
Schlussfolgerungen
Unser Abenteuer ist zu Ende, können Sie zusammenfassen. Die Konkurrenz stellte sich als schwierig heraus, aber wir konnten uns dem Dreck nicht stellen. Dies deutet darauf hin, dass die Schwelle für den Eintritt in die ML nicht so hoch ist, aber wie in jedem Unternehmen steht Fachleuten bereits echte Magie zur Verfügung (und es gibt viel davon beim maschinellen Lernen).
Ergebnisse in Zahlen:
- Die maximale Punktzahl in der ersten Stufe: ~ 0,69 gegen ~ 1,5 in erster Linie. So etwas wie der Durchschnitt für das Krankenhaus, ein Wert von 0,7 wurde von einigen überwunden, die maximale Punktzahl der öffentlichen Entscheidung war ebenfalls ~ 0,69, etwas mehr als meine.
- Platz in der ersten Stufe: 566 von 2927.
- Ergebnis in der zweiten Phase: 3.19251 nach dem ersten Monat.
- Platz in der zweiten Stufe: 65 von 697 nach dem ersten Monat.
Ich mache Sie darauf aufmerksam, dass die Zahlen in der zweiten Stufe nichts Besonderes aussagen, da für eine qualitative Beurteilung von Entscheidungen noch sehr wenige Daten vorliegen.
Referenzen
Die endgültige Lösung mit NachrichtenTwo Sigma: Verwenden von Nachrichten zur Vorhersage von Aktienbewegungen - Wettbewerbsseite
Keras - Neuronales
Netzwerk-FrameworkLightGBM - GBM-Framework
Scikit-learn - Bibliothek für Algorithmen für maschinelles Lernen
Hyperopt - Bibliothek zur Optimierung von Hyperparametern
Artikel über WaveNet