Während wir dieses Jahr an dem Jahresbericht arbeiten, haben wir uns entschlossen, die Schlagzeilen des Vorjahres nicht noch einmal zu erzählen, und obwohl es fast unmöglich ist, Erinnerungen absolut zu ignorieren, möchten wir Ihnen das Ergebnis eines klaren Gedankens und einer strategischen Sichtweise mitteilen der Punkt, an dem wir alle in der nächsten Zeit ankommen werden - die Gegenwart.
Hier sind unsere wichtigsten Erkenntnisse:
- Die durchschnittliche DDoS-Angriffsdauer sank auf 2,5 Stunden.
- Im Jahr 2018 erschien die Fähigkeit für Angriffe mit Hunderten von Gigabit pro Sekunde innerhalb eines Landes oder einer Region, was uns an den Rand der „Quantentheorie der Bandbreitenrelativität“ brachte.
- Die Häufigkeit von DDoS-Angriffen nimmt weiter zu.
- Das anhaltende Wachstum von HTTPS-fähigen (SSL) Angriffen;
- PC ist tot: Der größte Teil des legitimen Datenverkehrs kommt heute von Smartphones. Dies ist heute eine Herausforderung für DDoS-Akteure und die nächste Herausforderung für DDoS-Minderungsunternehmen.
- BGP wurde schließlich ein Angriffsvektor, 2 Jahre später als wir erwartet hatten;
- Die DNS-Manipulation ist zum schädlichsten Angriffsvektor geworden.
- Andere neue Amplifikationsvektoren sind möglich, wie memcached & CoAP;
- Es gibt keine „sicheren Branchen“ mehr, die für Cyberangriffe jeglicher Art unverwundbar sind.
In diesem Artikel haben wir versucht, die interessantesten Teile unseres Berichts auszuwählen. Wenn Sie jedoch die Vollversion auf Englisch lesen möchten, ist das
PDF verfügbar .
Rückblick
2018 „feierte“ unser Unternehmen zwei rekordverdächtige Angriffe auf sein Netzwerk. Die Memcached-Amplification-Attacken, die wir Ende Februar 2018 ausführlich beschrieben haben, erreichten bei der Qiwi-Zahlungsplattform, einem Kunden von Qrator Labs, 500 Gbit / s. Ende Oktober erhielten wir dann einen hochkonzentrierten DNS-Verstärkungsangriff auf einen unserer Kunden in der Russischen Föderation.
Die DNS-Verstärkung ist ein alter und bekannter DDoS-Angriffsvektor, der hauptsächlich volumetrisch ist und zwei Probleme aufwirft. Bei einem Angriff mit Hunderten von Gigabit pro Sekunde besteht eine hohe Wahrscheinlichkeit, dass unser Upstream-Kanal überlastet wird. Wie kann man das bekämpfen? Offensichtlich müssen wir diese Last auf viele Kanäle verteilen, was zum zweiten Problem führt - der zusätzlichen Latenz, die sich aus der Änderung des Verkehrsflusses zu unserem Verarbeitungspunkt ergibt. Glücklicherweise haben wir diesen bestimmten Angriff nur durch Lastausgleich erfolgreich abgewehrt.
Hier zeigt der flexible Lastausgleich seinen wahren Wert. Da Qrator Labs ein Anycast-BGP-Netzwerk verwaltet, modelliert Radar die Verteilung des Datenverkehrs in unserem Netzwerk, nachdem wir den Lastausgleich angepasst haben. BGP ist ein Distanzvektorprotokoll, und wir kennen diese Zustände, weil der Distanzgraph statisch bleibt. Wenn wir diese Entfernungen analysieren und LCPs und Equal-Cost Multipath berücksichtigen, können wir den AS_path von Punkt A nach Punkt B mit hoher Sicherheit schätzen.
Dies bedeutet nicht, dass die Verstärkung die gefährlichste Bedrohung darstellt. Nein, Angriffe auf Anwendungsebene bleiben die effektivste, nervöseste und unsichtbarste, da die meisten von ihnen eine geringe Bandbreite aufweisen.
Dies ist der Hauptgrund, warum Qrator Labs die Verbindungen zu Betreibern basierend auf Präsenzpunkten verbessert und gleichzeitig die Präsenzbereiche erweitert. Dies ist heutzutage ein natürlicher Schritt für jeden Netzbetreiber, vorausgesetzt, seine Zahl wächst. Aus der Sicht der Angreifer glauben wir jedoch, dass es üblich ist, ein mittelmäßiges Botnetz zu sammeln und sich erst danach darauf zu konzentrieren, nach der reichhaltigsten Auswahl an verfügbaren Verstärkern zu suchen, die von allen möglichen Waffen mit der höchstmöglichen Nachladerate getroffen werden können. Hier gibt es hybride Angriffe, deren Bandbreite, Paketrate und Frequenz zunehmen.
Botnets haben sich 2018 erheblich weiterentwickelt und ihre Meister haben einen neuen Job für sie gefunden - Klickbetrug. Mit dem Aufkommen von maschinellem Lernen und kopflosen Browser-Engines wurde Klickbetrug viel einfacher als noch vor ein paar Jahren.
Eine durchschnittliche Website von heute erhält etwa 50% bis 65% ihres Datenverkehrs von Mobilgeräten, Smartphone-Browsern und Anwendungen. Bei einigen Webdiensten liegt diese Zahl nahe bei 90% oder 100%, während eine reine Desktop-Website heutzutage nur noch selten in Unternehmensumgebungen oder in einigen Grenzfällen anzutreffen ist.
Der PC ist im Jahr 2019 im Grunde genommen tot, was einige der bisher üblichen Ansätze, wie das Verfolgen von Mausbewegungen, für das Verfolgen und Filtern von Bots völlig unbrauchbar macht. Tatsächlich ist nicht nur der PC (mit all den glänzenden Laptops und All-in-One-Desktop-Computern) selten eine Quelle für einen großen Verkehrsanteil bei bestimmten Websites, sondern wird häufig eher zu einem Täter. Manchmal reicht es aus, nur den Zugriff auf einen nicht geeigneten Smartphone-Browser zu verweigern, um einen Botnet-Angriff vollständig abzuschwächen, der gleichzeitig keine negativen Auswirkungen auf die wichtigsten Leistungsindikatoren des Unternehmens hat.
Botnet-Autoren werden verwendet, um das Verhalten von Desktop-Browsern in ihrem Schadcode zu implementieren oder zu imitieren, genauso wie die Website-Besitzer glauben, dass PC-Browser wirklich wichtig sind. Letzteres hat sich in letzter Zeit geändert, so dass innerhalb weniger Jahre auch bei ersteren eine Änderung eintreten sollte.
Wir haben bereits festgestellt, dass sich im Jahr 2018 nichts wesentlich geändert hat, aber die Veränderungen und Fortschritte haben sich stetig fortgesetzt. Eines der wichtigsten Beispiele ist das maschinelle Lernen, bei dem Verbesserungen insbesondere im Bereich der generativen kontradiktorischen Netzwerke besonders deutlich wurden. Langsam aber stetig erreicht ML den Massenmarkt. Die Welt des maschinellen Lernens ist zugänglicher geworden und bis Ende des Jahres nicht mehr auf Akademiker beschränkt.
Wir haben erwartet, dass es Anfang 2019 die ersten ML-basierten (oder anderweitig verwandten) DDoS-Angriffe geben wird, aber es ist immer noch nicht geschehen. Wir erwarten eine solche Entwicklung aufgrund der geringen Kosten für ML-generierte Daten, die jedoch derzeit nicht niedrig genug sind.
Wenn Sie an den aktuellen Stand der „automatisierten menschlichen“ Industrie denken, ist es keine schlechte Idee, das Neuronetzwerk darüber zu stellen. Ein solches Netzwerk würde echtes menschliches Verhalten im Zusammenhang mit der Verwaltung von Webseiteninhalten lernen. Das würde jeder als "KI-Benutzererfahrung" bezeichnen, und natürlich könnte ein solches Netzwerk, das mit einer Browser-Engine ausgestattet ist, ein sehr interessantes Arsenal für beide Seiten, Angriff und Verteidigung, hervorbringen.
Sicher, das Unterrichten des Netzwerks ist teuer, aber das Verteilen und Auslagern eines solchen Systems kann sehr erschwinglich und möglicherweise kostenlos sein, insbesondere wenn Malware, gehackte Anwendungen usw. in Betracht gezogen werden. Möglicherweise könnte eine solche Änderung die gesamte Branche betreffen, genauso wie GANs das, was wir von „visueller Realität“ und „Vertrauenswürdigkeit“ halten, verändert haben.
Da dies auch ein Wettlauf zwischen Suchmaschinen ist, bei denen Google an erster Stelle steht, und allen anderen, die versuchen, die Algorithmen rückzuentwickeln, könnte dies zu einer Situation führen, in der ein Bot nicht einen zufälligen Menschen, sondern eine bestimmte Person nachahmt, wie dies normalerweise der Fall ist hinter einem ausgewählten anfälligen Computer sitzen. Versionen von Captcha und Recaptcha könnten als Beispiele dafür dienen, wie Angreifer ihre Werkzeuge und Angriffstechniken verbessern.
Nach dem Memcaching wurde viel über die Möglichkeit einer neuen Klasse von DDoS-Angriffswaffen gesprochen - eine Sicherheitslücke, ein Bot, ein kompromittierter Dienst, der bestimmte Daten für immer an eine bestimmte vom Angreifer gewählte Adresse senden könnte. Ein Befehl des Angreifers könnte einen kontinuierlichen Verkehrsfluss wie Syslog oder eine massive Flut auslösen. Das ist nur eine Theorie. Wir können nicht sagen, ob solche Server oder Geräte tatsächlich existieren, aber wenn sie es tun, wäre es eine Untertreibung zu sagen, dass sie eine äußerst gefährliche Waffe in den falschen Händen darstellen könnten.
Im Jahr 2018 sahen wir auch ein verstärktes Interesse aller Arten von Regierungen und gemeinnützigen Organisationen auf der ganzen Welt an der Steuerung des Internets und der damit verbundenen Dienstleistungen. Wir betrachten dies als eine neutrale Entwicklung bis zu dem Punkt, an dem die Grundfreiheiten unterdrückt werden könnten, was wir hoffentlich nicht tun werden, insbesondere in Industrienationen.
Nach Jahren des Sammelns und Analysierens von weltweit angreifendem Datenverkehr implementiert Qrator Labs nun den ersten Anforderungsblock. Mit den Modellen, mit denen wir böswilliges Verhalten vorhersagen, können wir mit hoher Sicherheit feststellen, ob ein Benutzer legitim ist oder nicht. Wir halten an unserer zentralen Philosophie der ununterbrochenen Benutzererfahrung ohne JavaScript-Herausforderungen oder Captchas fest und hoffen, 2019 die Fähigkeit zu erreichen, die erste böswillige Anfrage daran zu hindern, unsere Abwehrmechanismen zu verletzen.
Mellanox
Wir haben uns aufgrund unserer internen Tests in den vergangenen Jahren für 100G Mellanox-Switches entschieden. Wir wählen immer noch Geräte aus, die unsere Anforderungen in bestimmten Situationen erfüllen. Erstens sollten Switches keine kleinen Pakete verwerfen, während sie mit Leitungsrate arbeiten - es kann überhaupt keine Verschlechterung geben. Zweitens hat uns der Preis gefallen. Das ist jedoch noch nicht alles. Die Kosten werden immer dadurch gerechtfertigt, wie der Anbieter auf Ihre Spezifikationen reagiert.
Mellanox-Switches arbeiten unter Switchdev und verwandeln ihre Ports in normale Linux-Schnittstellen. Switchdev ist Teil des Mainstream-Linux-Kernels und wird in der Dokumentation als „Kernel-Treibermodell für Switch-Geräte, die die Weiterleitungsdatenebene vom Kernel auslagern“ beschrieben. Dieser Ansatz ist sehr praktisch, da alle Tools, die wir bisher verwendet haben, unter einer API verfügbar sind, die für jeden modernen Programmierer, Entwickler und Netzwerktechniker äußerst natürlich ist. Jedes Programm, das die Standard-Linux-Netzwerk-API verwendet, kann auf dem Switch ausgeführt werden. Alle für Linux-Server entwickelten Netzwerküberwachungs- und -steuerungstools, einschließlich hausgemachter, sind verfügbar. Zum Beispiel ist das Implementieren von Änderungen an der Routentabelle viel komfortabler als vor Switchdev. Bis zur Ebene des Netzwerkchips ist der gesamte Code sichtbar und transparent, sodass Sie lernen und Änderungen vornehmen können, bis Sie genau wissen müssen, wie der Chip aufgebaut ist, oder zumindest die externe Schnittstelle.
Ein Mellanox-Gerät unter Switchdev-Kontrolle ist die Kombination, die wir für unsere Anforderungen am besten geeignet fanden, da das Unternehmen das bereits robuste Open-Source-Betriebssystem sofort unterstützt.
Beim Testen der Geräte vor dem Betrieb haben wir festgestellt, dass ein Teil des weitergeleiteten Datenverkehrs unterbrochen wurde. Unsere Untersuchung ergab, dass der Datenverkehr auf einer Schnittstelle über den Steuerprozessor geleitet wurde, der natürlich keine großen Mengen davon verarbeiten konnte. Wir kannten die genaue Ursache eines solchen Verhaltens nicht, aber wir nahmen an, dass es an die Behandlung von ICMP-Weiterleitungen gebunden war. Mellanox bestätigte die Ursache des Problems und wir baten sie, etwas dagegen zu unternehmen. Mellanox reagierte schnell und bot uns kurzfristig eine funktionierende Lösung.
Großartige Arbeit, Mellanox!
Protokolle und Open Source
DNS-over-HTTPS ist eine komplexere Technologie als DNS-over-TLS. Wir sehen, wie das erstere blüht und das letztere langsam vergessen wird. Es ist ein klares Beispiel, in dem „komplexer“ „effizienter“ bedeutet, da der DoH-Verkehr von keinem anderen HTTPS zu unterscheiden ist. Wir haben dies bereits bei der RPKI-Datenintegration gesehen, als sie ursprünglich als Anti-Hijack-Lösung positioniert war und nicht gut endete, dann aber als leistungsstarke Waffe gegen Fehler wie statische Lecks und falsche Routing-Einstellungen wieder auftauchte. Rauschen in Signal umgewandelt und jetzt wird RPKI auf den größten IX unterstützt, was eine großartige Nachricht ist.
TLS 1.3 ist angekommen. Qrator Labs sowie die IT-Branche insgesamt haben den Entwicklungsprozess vom ersten Entwurf bis zu jeder Phase innerhalb der IETF genau beobachtet, um ein verständliches und verwaltbares Protokoll zu werden, das wir 2019 unterstützen können. Die Unterstützung ist bereits auf dem Markt erkennbar Wir möchten mit der Implementierung dieses robusten, bewährten Sicherheitsprotokolls Schritt halten. Wir wissen nicht, wie sich die Hersteller von DDoS-Schadensbegrenzungshardware an die Realität von TLS 1.3 anpassen werden, aber aufgrund der technischen Komplexität der Protokollunterstützung kann dies einige Zeit dauern.
Wir folgen auch HTTP / 2. Derzeit unterstützt Qrator Labs die neuere Version des HTTP-Protokolls aufgrund der vorhandenen Codebasis um dieses Protokoll nicht. Fehler und Schwachstellen sind im neuen Code immer noch recht häufig zu finden. Als Sicherheitsdienstleister sind wir noch nicht bereit, ein solches Protokoll im Rahmen des SLA zu unterstützen, das wir mit unseren Verbrauchern vereinbaren.
Die eigentliche Frage von 2018 für Qrator Labs lautete: „Warum wollen die Leute so sehr HTTP / 2? Und es war das ganze Jahr über Gegenstand heißer Debatten. Die Leute neigen immer noch dazu, die "2" -Ziffer als die "schnellere, stärkere, bessere" Version zu betrachten, was nicht unbedingt in jedem Aspekt dieses bestimmten Protokolls der Fall ist. DoH empfiehlt jedoch HTTP / 2, und hier könnten beide Protokolle viel Schwung bekommen.
Ein Problem bei der Entwicklung der Protokollsuiten und -funktionen der nächsten Generation besteht darin, dass sie in der Regel stark von der akademischen Forschung abhängen und der Stand der DDoS-Minderungsbranche recht schlecht ist. Abschnitt 4.4 des IETF-Entwurfs „QUIC-Verwaltbarkeit“, der Teil der zukünftigen QUIC-Protokollsuite ist, könnte als perfektes Beispiel dafür angesehen werden: Es heißt, dass „derzeitige Praktiken zur Erkennung und Abschwächung von [DDoS-Angriffen] im Allgemeinen passiv sind Messung mit Netzwerkflussdaten “, wobei letzteres in realen Unternehmensumgebungen (und nur teilweise für ISP-Setups) sehr selten der Fall ist - und in der Praxis in keiner Weise ein„ allgemeiner Fall “-, aber definitiv ein allgemeiner Fall in akademische Forschungsarbeiten, die die meiste Zeit nicht durch ordnungsgemäße Implementierungen und Tests in der Praxis gegen die gesamte Bandbreite potenzieller DDoS-Angriffe, einschließlich der Angriffe auf Anwendungsebene (die aufgrund des Fortschritts bei der weltweiten TLS-Bereitstellung offensichtlich nicht möglich sind), unterstützt werden mit jeder Art von passiver Messung behandelt werden). Die Festlegung eines angemessenen akademischen Forschungstrends ist eine weitere Herausforderung für die DDoS-Minderungsbetreiber im Jahr 2019.
Switchdev hat die Erwartungen, die wir vor einem Jahr geäußert haben, voll erfüllt. Wir hoffen, dass die kontinuierliche Arbeit, um Switchdev noch besser zu machen, in den kommenden Jahren verstärkt wird, da die Community stark ist und wächst.
Qrator Labs setzt die Aktivierung von Linux XDP fort, um die Effizienz der Paketverarbeitung weiter zu steigern. Das Auslagern einiger Muster der böswilligen Verkehrsfiltration von der CPU auf die Netzwerkkarte und sogar auf den Netzwerk-Switch erscheint vielversprechend, und wir freuen uns darauf, unsere Forschung und Entwicklung in diesem Bereich fortzusetzen.
Tief tauchen mit Bots
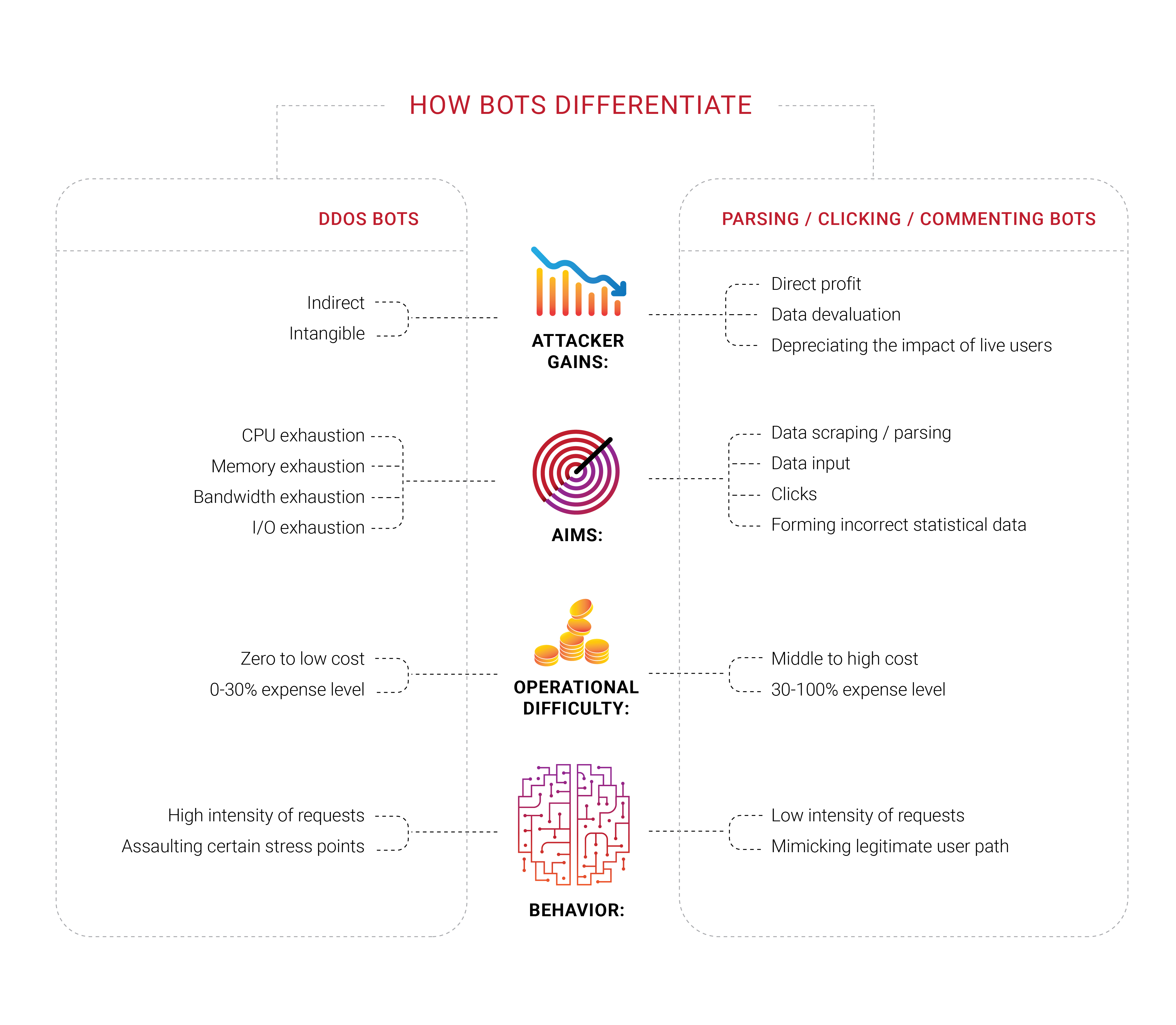
Viele Unternehmen suchen Bot-Schutz, und es ist keine Überraschung, dass wir 2018 Gruppen in verschiedenen Bereichen dieses Bereichs gesehen haben. Was wir interessant fanden, ist, dass ein großer Teil dieser Unternehmen nie einen gezielten DDoS-Angriff erlebt hat, zumindest eine typische Ablehnung von Service versuchen, endliche Ressourcen wie Bandbreite oder CPU-Kapazität zu entleeren. Sie fühlen sich von den Bots bedroht, können sie jedoch nicht von tatsächlichen Benutzern unterscheiden oder feststellen, was sie tatsächlich tun. Sie wissen nur, dass sie die wahrgenommenen Bots loswerden wollen.
Die Probleme mit Bots und Scrapern haben auch eine wichtige wirtschaftliche Komponente. Wenn 30% des Verkehrs unzulässig sind und von Maschinen stammen, werden 30% der Kosten für die Unterstützung dieses Verkehrs verschwendet. Dies kann heute als zusätzliche unvermeidliche Steuer für Internetunternehmen angesehen werden. Es ist schwer, die Zahl genau auf Null zu senken, aber Geschäftsinhaber würden es vorziehen, sie so niedrig wie möglich zu halten.
Die Identifizierung wird im heutigen Internet zu einem wichtigen Thema, da die besten Bots keine Menschen mehr imitieren müssen - sie nehmen denselben Raum ein wie Parasiten. Wir wiederholen seit einiger Zeit, dass öffentlich verfügbare Informationen ohne Autorisierung oder Authentifizierung als gemeinsames Eigentum enden und enden würden - niemand könnte dies verhindern.
Im Jahr 2018 haben wir uns auf Fragen des Identitäts- und Bot-Managements konzentriert. Der breitere Anwendungsbereich ist hier jedoch unterschiedlich. Wir leben in einer Zeit, in der es keine genaue Möglichkeit gibt, den Grund zu ermitteln, warum ein Client die Antwort des Servers anfordert. Sie haben es richtig gelesen: Letztendlich möchte jedes Unternehmen, dass ein Kunde etwas kauft. Dies ist der Grund für das Bestehen und das Ziel. Einige Unternehmen möchten daher genauer untersuchen, wer was vom Server anfordert - wenn eine echte Person dahinter steht.
Es ist kein Wunder, dass Geschäftsinhaber häufig von den Technikern erfahren, dass ein erheblicher Teil ihres Website-Verkehrs von Bots und nicht von Kunden stammt.
Die zuvor erwähnten automatisierten Menschen könnten auch auf eine bestimmte Netzwerkressource mit einem installierten Browser-Add-On abzielen - und wir glauben, dass die meisten dieser Erweiterungen absichtlich installiert werden, um ein bestimmtes Ziel zu verfolgen, das nur den Erstellern dieser Netzwerke bekannt ist. Klickbetrug, Anzeigenmanipulation, Analyse - solche Aufgaben werden mit Hilfe realer Menschen an dem Punkt effizient ausgeführt, an dem die Automatisierung fehlschlägt. Stellen Sie sich vor, wie sich die Situation ändern würde, wenn maschinelles Lernen auf das richtige Glied in der Kette angewendet würde.
Parser und Schaber, die Teil des umfassenderen Bot-Problems sind, wurden zu einem Thema, mit dem wir uns im Jahr 2018 befasst haben, zum einen dank unserer Kunden, die sich mit ihren Erfahrungen an uns wandten und die Möglichkeit boten, weiter zu untersuchen, was mit ihren Ressourcen geschah. Solche Bots registrieren sich möglicherweise nicht einmal bei typischen Metriken wie der Bandbreite oder der CPU-Auslastung des Servers. Wir testen derzeit verschiedene Ansätze, aber letztendlich ist klar, was Kunden brauchen - um solche Eindringlinge bei ihrer ersten Anfrage zu blockieren.
Während der Scraping-Epidemie in Russland und den GUS-Staaten wurde deutlich, dass die beteiligten Bots verschlüsselt werden können. Eine Anfrage pro Minute ist eine Rate, die ohne Anforderungsanalyse des eingehenden Datenverkehrs leicht unbemerkt bleiben kann. Nach unserer bescheidenen Meinung sollte der Kunde den nächsten Schritt entscheiden, nachdem er unsere Analyse und unser Markup erhalten hat. Ob wir sie blockieren, durchlassen oder fälschen (irreführen) - wir müssen nicht entscheiden.

Es gibt jedoch bestimmte Probleme mit reinen Automatisierungen oder „Bots“, wie wir sie gewohnt sind. Wenn Sie sicher sind, dass der böswillige Bot eine bestimmte Anfrage generiert hat, entscheiden Sie sich zunächst dafür, diese zu blockieren und keine Antwort vom Server zu senden. Wir sind zu dem Schluss gekommen, dass dies sinnlos ist, da solche Aktionen der Automatisierung nur mehr Feedback geben und sie in die Lage versetzen, sich anzupassen und eine Problemumgehung zu finden. Sofern die Bots nicht versuchen, einen Denial-of-Service-Angriff durchzuführen, empfehlen wir, solche Automatisierungen nicht sofort zu blockieren, da das Ergebnis solcher Katz- und Mausspiele nichts anderes als eine große Zeit- und Arbeitsverschwendung sein kann.
Dies ist der Hauptgrund, warum Qrator Labs verdächtigen und / oder böswilligen Datenverkehr markiert und die Entscheidung über die nächsten Schritte dem Ressourcenbesitzer unter Berücksichtigung seiner Zielgruppe, seines Service und seiner Geschäftsziele überlässt. Ein solches Beispiel ist die Werbeblocker-Browsererweiterung. Die meisten Anzeigen sind Skripte. Wenn Sie Skripte blockieren, blockieren Sie nicht unbedingt Anzeigen, und Sie könnten etwas anderes blockieren, z. B. eine Javascript-Herausforderung. Es ist leicht vorstellbar, wie dies eskalieren könnte, was zu Einkommensverlusten für eine große Gruppe von Internetunternehmen führen könnte.
Wenn Angreifer blockiert sind und das benötigte Feedback erhalten, können sie sich schnell anpassen, lernen und erneut angreifen. Die Technologien von Qrator Labs basieren auf der einfachen Philosophie, dass die Automatisierung kein Feedback erhalten kann, das sie verwenden kann: Sie sollten sie weder blockieren noch weiterleiten, sondern nur markieren. Nachdem solche Markierungen vorgenommen wurden, sollten Sie über ihr eigentliches Ziel nachdenken - Was wollen sie? und warum besuchen sie diese bestimmte Ressource oder Webseite? Vielleicht könnten Sie den Inhalt der Webseite so verändern, dass kein Mensch den Unterschied spürt, aber die Realität des Bots auf den Kopf gestellt wird? Wenn sie Parser sind, können sie irreführende Parsing-Informationen in Form falscher Daten erhalten.
Bei der Erörterung dieser Probleme im Laufe des Jahres 2018 haben wir solche Angriffe als unkomplizierten Angriff auf Geschäftsmetriken bezeichnet. Ihre Website und Ihre Server scheinen in Ordnung zu sein, ohne dass sich Benutzer beschweren, aber Sie spüren, dass sich etwas ändert ... wie der CPA-Preis einer Anzeige, die Sie von einer programmgesteuerten Plattform langsam nehmen, aber Werbetreibende an anderer Stelle stetig steuern.
Der Anreiz der Angreifer zu töten, ist der einzige Weg, dem entgegenzuwirken. Der Versuch, Bots zu stoppen, führt nur zu Zeit- und Geldverschwendung. Wenn sie auf etwas klicken, von dem Sie profitieren, machen Sie diese Klicks ineffizient. Wenn sie Sie analysieren, geben Sie unzuverlässige Informationen an, die sie nicht von legitimen, vertrauenswürdigen Daten unterscheiden.
Clickhouse
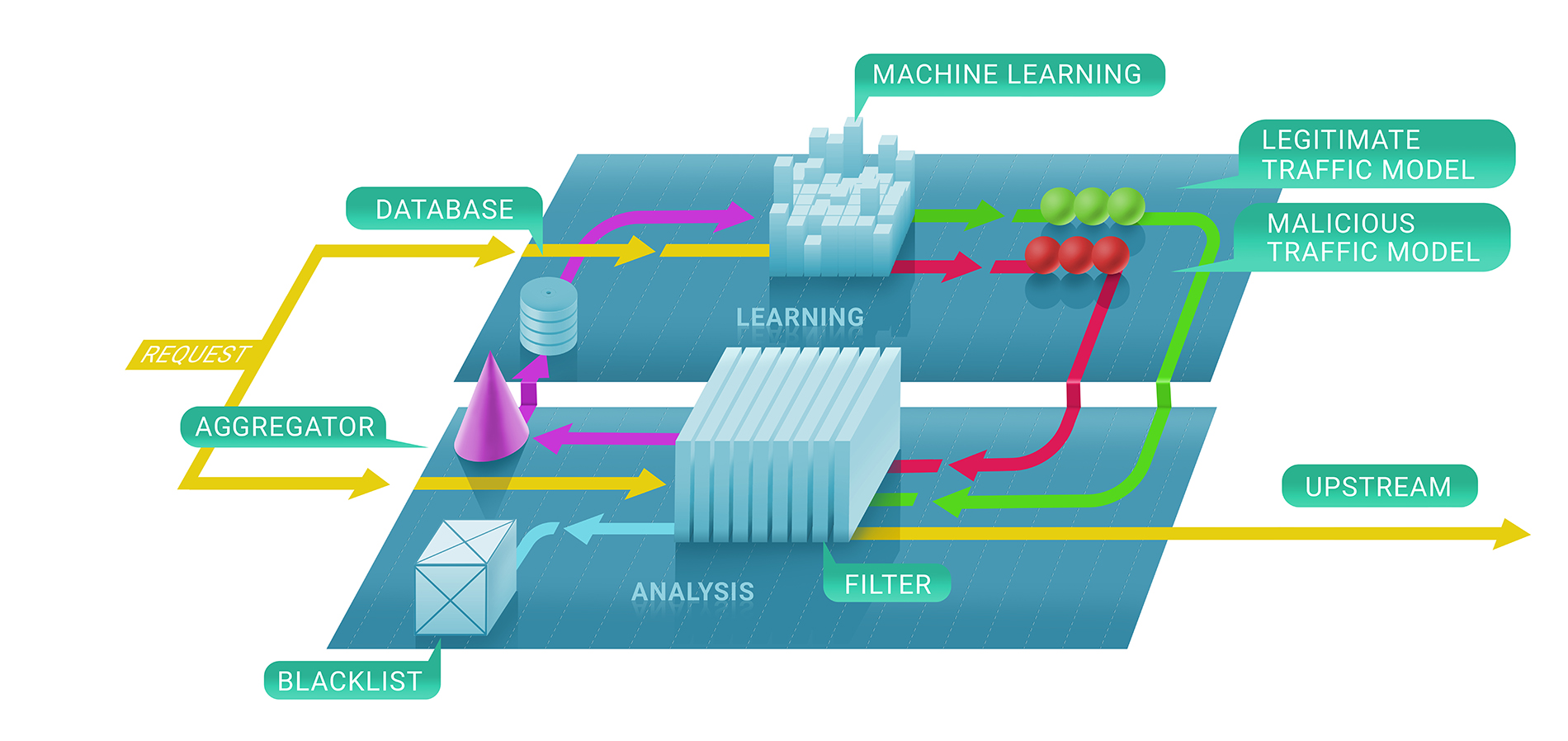
Im Allgemeinen umfasst der Filterdienst von Qrator Labs zwei Phasen: Erstens bewerten wir sofort, ob eine Anfrage böswillig ist, mithilfe von zustandslosen und zustandsbehafteten Überprüfungen, und zweitens entscheiden wir, ob und wie lange die Quelle auf der schwarzen Liste bleibt. Die resultierende Blacklist könnte als Liste eindeutiger IP-Adressen dargestellt werden.
In der ersten Phase dieses Prozesses setzen wir Techniken des maschinellen Lernens ein, um den natürlichen Verkehrsfluss für eine bestimmte Ressource besser zu verstehen, da wir den Service für jeden Kunden individuell anhand der von uns gesammelten Daten parametrisieren.
Hier kommt Clickhouse ins Spiel. Um genau zu verstehen, warum die Kommunikation einer IP-Adresse mit einer Ressource verboten wurde, müssen wir dem Modell des maschinellen Lernens für Clickhouse DB folgen. Es funktioniert sehr schnell mit großen Datenmengen (betrachten Sie einen DDoS-Angriff mit 500 Gbit / s, der zwischen den Pausen einige Stunden andauert) und speichert sie auf eine Weise, die natürlich mit den von uns bei Qrator Labs verwendeten Frameworks für maschinelles Lernen kompatibel ist. Mehr Protokolle und mehr Angriffsverkehr führen zu besseren und robusteren Ergebnissen unserer Modelle, mit denen der Dienst unter den gefährlichsten Angriffen in Echtzeit weiter verfeinert werden kann.
Wir verwenden die Clickhouse-Datenbank, um alle (unzulässigen) Angriffsprotokolle und Bot-Verhaltensmuster zu speichern. Wir haben diese spezielle Lösung implementiert, da sie eine beeindruckende Kapazität für die schnelle Verarbeitung großer Datenmengen in einem Datenbankstil versprach. Wir verwenden diese Daten zur Analyse und zum Erstellen der Muster, die wir bei der DDoS-Filterung verwenden, und zum Anwenden von maschinellem Lernen, um die Filteralgorithmen zu verbessern.
Ein wesentlicher Vorteil von Clickhouse im Vergleich zu anderen DBs besteht darin, dass nicht die gesamte Datenfolge gelesen wird. Es kann nur das erforderliche, viel kleinere Segment benötigt werden, wenn Sie alles gemäß den Richtlinien speichern.
Fazit

Seit geraumer Zeit leben wir mit Multifaktor-Angriffen, bei denen mehrere Angriffsprotokolle untersucht werden, um ein Ziel nicht mehr verfügbar zu machen.
Digitale Hygiene und aktuelle Sicherheitsmaßnahmen sollten und könnten 99% der tatsächlichen Risiken abdecken, denen ein einzelnes Unternehmen wahrscheinlich ausgesetzt ist, mit Ausnahme extremer oder gezielter Fälle, und verhindern, dass bei einem „durchschnittlichen“ Internetdienst Probleme auftreten.
Auf der anderen Seite können DDoS-Angriffe die Internetverbindung eines Landes auf der Welt unterbrechen, obwohl nur wenige von außen effektiv gezielt angegriffen werden können. Dies ist im BGP nicht der Fall, wo es möglich ist, nur eine Reihe von Punkten auf einer Karte zu schließen, die Sie zeichnen möchten.
Das Wissen über Netzwerksicherheit wächst weiter, was ausgezeichnet ist. Wenn Sie sich jedoch die Zahlen ansehen, die an Verstärker in Netzwerken gebunden sind, oder Optionen, um andere zu fälschen, werden sie nicht sinken! Dies liegt daran, dass die Zeit, die Schüler jedes Jahr in der Internet-Sicherheitsschule verbringen, d. H. Die Leute, die anfangen, sich darum zu kümmern, wie sie Code schreiben und ihre Anwendungen erstellen, nicht der Zeit entspricht, die erforderlich ist, um sicherzustellen, dass sie keine Schwachstellen machen, die dies tun Erlauben Sie jemandem, solche Ressourcen für die Organisation eines erfolgreichen DDoS-Angriffs oder noch schlimmer zu verwenden.
Eine der wichtigsten Erkenntnisse des Jahres 2018 war, dass die meisten Menschen immer noch wesentlich mehr von der Technologie erwarten, als derzeit geliefert werden kann. Dies war nicht immer der Fall, aber im Moment sehen wir eine starke Tendenz, unabhängig von den Software- oder Hardwarefunktionen zu viel zu verlangen. Die Leute erwarten immer mehr, was sich aufgrund der in Marketingkampagnen gemachten Versprechen wahrscheinlich nicht ändern wird. Die Leute kaufen diese Versprechen jedoch und die Unternehmen sind der Meinung, dass sie daran arbeiten sollten, sie zu erfüllen.
Vielleicht ist das die Natur des Fortschritts und der Evolution. Heutzutage sind die Menschen frustriert und enttäuscht darüber, dass sie nicht das haben, was ihnen „garantiert“ wurde und wofür sie bezahlt haben. Hier entstehen also die aktuellen Probleme, bei denen wir ein Gerät und seine gesamte Software, die das tun, was wir wollen, nicht „vollständig“ kaufen können oder bei denen „kostenlose“ Dienste in Bezug auf personenbezogene Daten einen hohen Preis haben .
Der Konsumismus sagt uns, dass wir etwas wollen und wir sollten es mit unserem Leben bezahlen. Benötigen wir die Arten von Produkten oder Dienstleistungen, die sich selbst aktualisieren, um uns in Zukunft bessere Angebote zu verkaufen, basierend auf Daten, die sie auf eine Weise über uns gesammelt haben, die wir vielleicht nicht mögen? Wir können davon ausgehen, dass es 2019 nach den Fällen Equifax und Cambridge Analytica zu einer endgültigen Explosion der Erfassung und des Missbrauchs personenbezogener Daten kommen wird.
Nach zehn Jahren haben wir unsere Grundüberzeugungen über die Architektur des miteinander verbundenen Netzwerks nicht geändert. Aus diesem Grund stehen wir weiterhin hinter den grundlegendsten Prinzipien des Qrator Labs-Filternetzwerks - BGP-Anycast, der Fähigkeit, verschlüsselten Datenverkehr zu verarbeiten, der Vermeidung von Captchas und anderen Hindernissen und einer besseren Sichtbarkeit für legitime Benutzer im Vergleich zu angreifenden Bots.
Wenn wir uns ansehen, was mit Cybersicherheitsexperten und Unternehmen auf diesem Gebiet weiterhin passiert, möchten wir ein weiteres Problem hervorheben: Wenn es um Sicherheit geht, ist kein naiver, einfacher oder schneller Ansatz anwendbar.
Dies ist der Hauptgrund, warum Qrator Labs im Vergleich zu CDNs nicht über Hunderte oder sogar Dutzende von Präsenzpunkten verfügt. Durch die Aufrechterhaltung einer geringeren Anzahl von Scrubbing-Centern, die alle mit den ISPs der Tier-1-Klasse verbunden sind, erreichen wir eine echte Dezentralisierung des Datenverkehrs. Dies ist auch der Grund, warum wir nicht versuchen, Firewalls zu erstellen, die sich grundlegend von denen von Qrator Labs unterscheiden - der Konnektivität.
Wir erzählen seit einiger Zeit Geschichten über Captchas und Javascript-Tests und -Überprüfungen, und hier sind wir - neuronale Netze werden bei der Lösung der ersteren äußerst nützlich, und die letzteren waren für den erfahrenen und hartnäckigen Angreifer nie ein Problem.
In diesem Jahr haben wir auch eine ziemlich aufregende Veränderung erlebt: Jahrelang war DDoS nur für eine begrenzte Anzahl von Geschäftsbereichen ein Problem, normalerweise für diejenigen, in denen das Geld über dem Wasserspiegel liegt: E-Commerce, Handel / Aktien, Bank- / Zahlungssysteme. Mit dem kontinuierlichen Wachstum des Internets beobachten wir jedoch, dass DDoS-Angriffe jetzt auf alle anderen verfügbaren Internetdienste angewendet werden. Die DDoS-Ära begann mit einer Zunahme der Bandbreite und der Anzahl der weltweit verwendeten PCs. Es ist keine Überraschung, dass sich die Angriffslandschaft 2018 mit Silizium-Mikrochips in jedem Gerät um uns herum so schnell entwickelt.
Wenn jemand erwartet, dass sich diese Tendenz jemals ändert, irrt er sich wahrscheinlich. So wie wir es vielleicht auch sind. Niemand kann sagen, wie sich das Internet in den kommenden Jahren tatsächlich entwickeln und seine Wirkung und Kraft verbreiten wird, aber nach dem, was wir 2018 gesehen und 2019 weiter beobachtet haben, wird sich alles vervielfachen. Bis 2020 wird die Anzahl der im Internet verbundenen Geräte voraussichtlich 30 Milliarden überschreiten, abgesehen von der Tatsache, dass wir bereits den Punkt überschritten haben, an dem die Menschheit mehr Verkehr erzeugt hat als die von ihr geschaffene Automatisierung. Wir müssen uns also bald entscheiden, wie wir mit all dieser „Intelligenz“ umgehen sollen, ob künstlich oder nicht, da wir immer noch in einer Welt leben, in der nur ein Mensch dafür verantwortlich sein kann, dass etwas richtig und falsch ist.
2018 war ein Jahr der Chancen für diejenigen, die auf der dunklen Seite stehen. Wir sehen eine Zunahme von Angriffen und Hacks in Bezug auf Komplexität, Volumen und Häufigkeit. Crooks erhielt einige mächtige Werkzeuge und lernte, wie man sie benutzt. Die Guten haben kaum mehr getan, als nur diese Entwicklungen zu beobachten. Wir hoffen, dass sich dies in diesem Jahr ändert, zumindest bei den schmerzhaftesten Fragen.