Wir alle wissen, wie die Heimat beginnt, und tiefes Lernen beginnt mit Daten. Ohne sie ist es unmöglich, ein Modell zu trainieren, zu bewerten und tatsächlich zu verwenden. Wir forschen, erweitern den Hirsch-Index mit Artikeln über neue neuronale Netzwerkarchitekturen und experimentieren und verlassen uns auf die einfachsten lokalen Datenquellen. normalerweise Dateien in verschiedenen Formaten. Es funktioniert, aber es wäre schön, sich an ein Kampfsystem zu erinnern, das Terabyte ständig wechselnder Daten enthält. Dies bedeutet, dass Sie die Datenübertragung in der Produktion vereinfachen und beschleunigen sowie mit Big Data arbeiten müssen. Hier kommt Apache Ignite ins Spiel.
Apache Ignite ist eine verteilte speicherzentrierte Datenbank sowie eine Plattform für das Zwischenspeichern und Verarbeiten von Vorgängen in Bezug auf Transaktionen, Analysen und Stream-Ladevorgänge. Das System ist in der Lage, Petabytes an Daten mit RAM-Geschwindigkeit zu mahlen. Der Artikel konzentriert sich auf die Integration zwischen Apache Ignite und TensorFlow, mit der Sie Apache Ignite als Datenquelle für das Training des neuronalen Netzwerks und der Inferenz sowie als Repository für trainierte Modelle und ein Cluster-Management-System für verteiltes Lernen verwenden können.
Verteilte RAM-Datenquelle
Mit Apache Ignite können Sie so viele Daten speichern und verarbeiten, wie Sie in einem verteilten Cluster benötigen. Verwenden Sie
Ignite Dataset , um diese Apache Ignite beim Training neuronaler Netze in TensorFlow zu nutzen.
Hinweis: Apache Ignite ist nicht nur eine der Verbindungen in der ETL-Pipeline zwischen einer Datenbank oder einem Data Warehouse und TensorFlow. Apache Ignite an sich ist
HTAP (ein Hybridsystem für die Verarbeitung von Transaktions- und Analysedaten). Wenn Sie sich für Apache Ignite und TensorFlow entscheiden, erhalten Sie ein einziges System für die Transaktions- und Analyseverarbeitung und gleichzeitig die Möglichkeit, Betriebs- und Verlaufsdaten zum Trainieren des neuronalen Netzwerks und der Inferenz zu verwenden.
Die folgenden Benchmarks zeigen, dass Apache Ignite gut für Szenarien geeignet ist, in denen Daten auf einem einzelnen Host gespeichert werden. Mit einem solchen System können Sie einen Durchsatz von mehr als 850 Mbit / s erzielen, wenn sich Data Warehouse und Client auf demselben Knoten befinden. Befindet sich der Speicher auf einem Remote-Host, beträgt der Durchsatz ca. 800 Mbit / s.
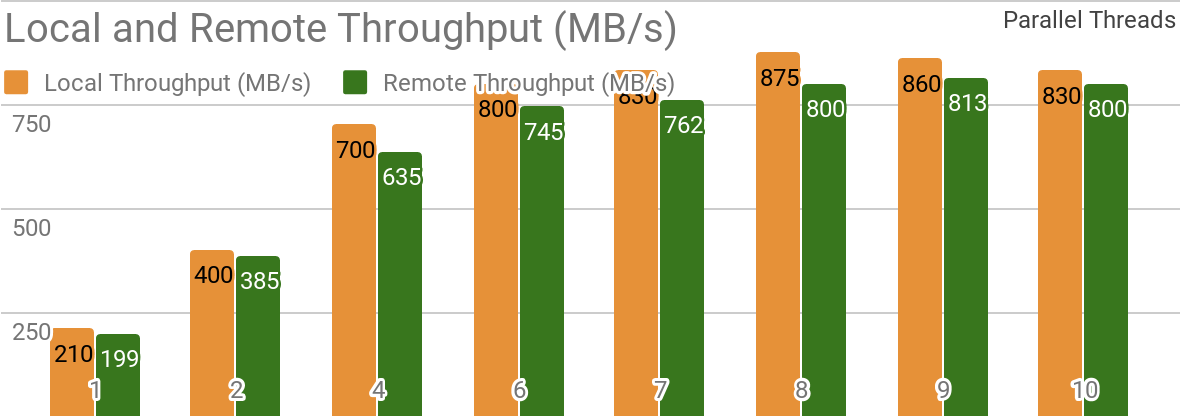
Das Diagramm zeigt die Bandbreite für Ignite Dataset für einen einzelnen lokalen Apache Ignite-Knoten. Diese Ergebnisse wurden auf einem 2x Xeon E5-2609 v4 1,7-GHz-Prozessor mit 16 GB RAM und in einem Netzwerk mit einer Bandbreite von 10 GB / s erhalten (jeder Datensatz hat eine Größe von 1 MB, Seitengröße - 20 MB).
Ein weiterer Benchmark zeigt, wie Ignite Dataset mit einem verteilten Apache Ignite-Cluster funktioniert. Diese Konfiguration wird standardmäßig ausgewählt, wenn Sie Apache Ignite als HTAP-System verwenden und es Ihnen ermöglichen, eine Bandbreite für einen einzelnen Client von mehr als 1 GB / s in einem Cluster mit einer Bandbreite von 10 Gbit / s zu erreichen.
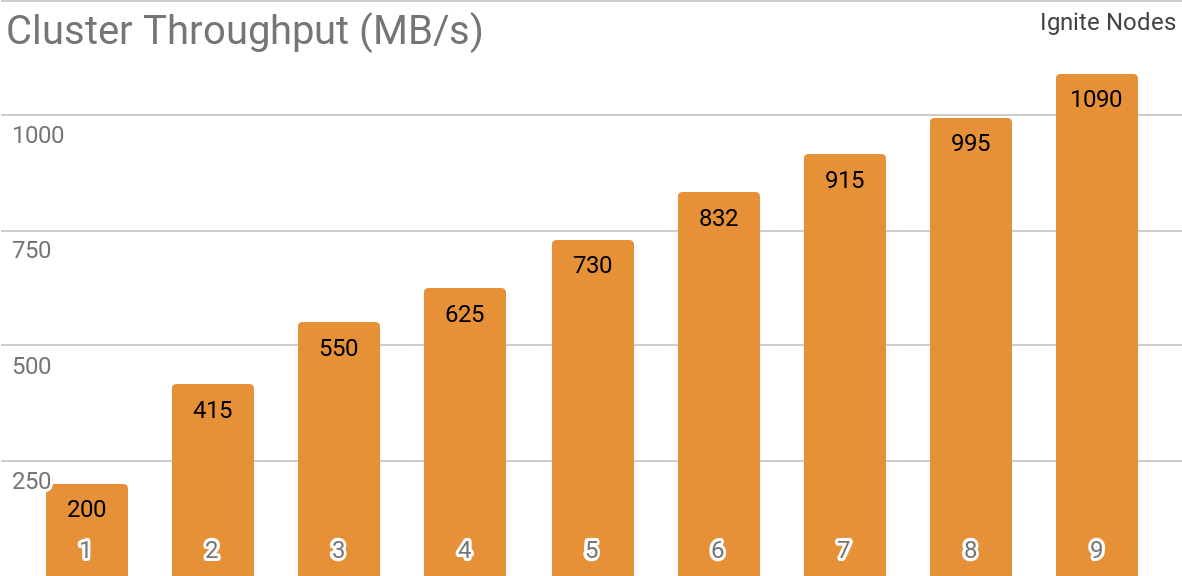
Die Grafik zeigt den Ignite-Dataset-Durchsatz für einen verteilten Apache Ignite-Cluster mit einer anderen Anzahl von Knoten (von 1 bis 9). Diese Ergebnisse wurden auf einem 2x Xeon E5-2609 v4 1,7-GHz-Prozessor mit 16 GB RAM und in einem Netzwerk mit einer Bandbreite von 10 GB / s erhalten (jeder Datensatz hat eine Größe von 1 MB, Seitengröße - 20 MB).
Das folgende Szenario wurde getestet: Der Apache Ignite-Cache (mit einer variablen Anzahl von Partitionen in der ersten Testgruppe und mit 2048 Partitionen in der zweiten) wird mit 10 KB Zeilen mit jeweils 1 MB gefüllt. Anschließend liest der TensorFlow-Client Daten mithilfe von Ignite Dataset. Der Cluster wurde aus Maschinen mit 2 x Xeon E5-2609 v4 1,7 GHz und 16 GB Speicher erstellt und über ein Netzwerk mit einer Geschwindigkeit von 10 GB / s verbunden. Auf jedem Knoten arbeitete Apache Ignite in der
Standardkonfiguration .
Apache Ignite ist einfach als klassische Datenbank mit SQL-Schnittstelle und gleichzeitig als Datenquelle für TensorFlow zu verwenden.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Strukturierte Objekte
Mit Apache Ignite können Sie Objekte eines beliebigen Typs speichern, die in einer beliebigen Hierarchie erstellt werden können. Sie können damit über Ignite Dataset arbeiten.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
Neuronales Netzwerktraining und andere Berechnungen erfordern eine Vorverarbeitung, die als Teil der
tf.data- Pipeline durchgeführt werden kann, wenn Sie Ignite Dataset verwenden.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Verteiltes Training
TensorFlow ist ein Framework
für maschinelles Lernen,
das verteiltes Lernen, Inferenz und andere Computer in neuronalen Netzen
unterstützt . Wie Sie wissen, basiert das neuronale Netzwerktraining auf der Berechnung von Gradienten der Verlustfunktion. Im Fall eines verteilten Trainings können wir diese Gradienten auf jeder Partition berechnen und dann aggregieren. Mit dieser Methode können Sie Gradienten für einzelne Knoten berechnen, auf denen Daten gespeichert sind, diese zusammenfassen und schließlich die Modellparameter aktualisieren. Und da wir die Übertragung von Trainingsbeispieldaten zwischen Knoten beseitigt haben, wird das Netzwerk nicht zum „Engpass“ des Systems.
Apache Ignite verwendet horizontale Partitionierung (Sharding), um Daten in einem verteilten Cluster zu speichern. Durch Erstellen des Apache Ignite-Caches (oder einer Tabelle in Bezug auf SQL) können Sie die Anzahl der Partitionen angeben, zwischen denen die Daten verteilt werden. Wenn ein Apache Ignite-Cluster beispielsweise aus 100 Computern besteht und wir einen Cache mit 1000 Partitionen erstellen, ist jeder Computer für etwa 10 Partitionen mit Daten verantwortlich.
Mit Ignite Dataset können Sie diese beiden Aspekte für das verteilte Training neuronaler Netze verwenden. Ignite Dataset ist der
Rechengraphenknoten , der die Grundlage der TensorFlow-Architektur bildet. Und wie jeder Knoten in einem Diagramm kann er auf einem Remote-Knoten im Cluster ausgeführt werden. Ein solcher Remote-Knoten kann Ignite Dataset-Parameter (z. B.
host ,
port oder
part ) überschreiben und die entsprechenden Umgebungsvariablen für den Workflow
IGNITE_DATASET_HOST (z. B.
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT oder
IGNITE_DATASET_PART ). Mit einer solchen Überschreibung können Sie jedem Clusterknoten eine bestimmte Partition zuweisen. Dann ist ein Knoten für eine Partition verantwortlich und gleichzeitig erhält der Benutzer eine einzelne Fassade der Arbeit mit dem Datensatz.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
Apache Ignite ermöglicht auch verteiltes Lernen mithilfe der TensorFlow-
API- Bibliothek auf hoher Ebene. Diese Funktionalität basiert auf dem sogenannten
Standalone-Client-Modus des verteilten Lernens in TensorFlow, bei dem Apache Ignite als Datenquellen- und Cluster-Management-System fungiert. Der nächste Artikel widmet sich ausschließlich diesem Thema.
Kontrollpunktspeicherung lernen
Zusätzlich zu den Datenbankfunktionen verfügt Apache Ignite über ein verteiltes
IGFS- Dateisystem. Funktionell ähnelt es dem Hadoop HDFS-Dateisystem, jedoch nur im RAM. Zusammen mit seinen eigenen APIs implementiert das IGFS-Dateisystem die Hadoop FileSystem-API und kann eine transparente Verbindung zu bereitgestelltem Hadoop oder Spark herstellen. Die TensorFlow-Bibliothek unter Apache Ignite bietet eine Integration zwischen IGFS und TensorFlow. Die Integration basiert auf dem TensorFlow-eigenen
Dateisystem- Plugin und der
nativen IGFS-API von Apache Ignite. Es gibt verschiedene Szenarien für die Verwendung, zum Beispiel:
- Statusprüfpunkte werden in IGFS für Zuverlässigkeit und Fehlertoleranz gespeichert.
- Lernprozesse interagieren mit TensorBoard, indem sie Ereignisdateien in ein von TensorBoard überwachtes Verzeichnis schreiben. IGFS stellt sicher, dass diese Kommunikation auch dann funktioniert, wenn TensorBoard in einem anderen Prozess oder auf einem anderen Computer ausgeführt wird.
Diese Funktionalität wurde in der Version von TensorFlow 1.13.0.rc0 veröffentlicht und wird auch Teil von
Tensorflow / io in der Version von TensorFlow 2.0 sein.
SSL-Verbindung
Mit Apache Ignite können Sie Datenkanäle mithilfe von
SSL und Authentifizierung sichern. Ignite Dataset unterstützt SSL-Verbindungen mit und ohne Authentifizierung. Weitere Informationen finden Sie in der
Apache Ignite SSL / TLS- Dokumentation.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Windows-Unterstützung
Ignite Dataset ist vollständig kompatibel mit Windows. Es kann als Teil von TensorFlow auf einer Windows-Workstation sowie auf Linux / MacOS-Systemen verwendet werden.
Probieren Sie es selbst aus
Die folgenden Beispiele helfen Ihnen beim Einstieg in das Modul.
Datensatz entzünden
Der einfachste Weg, um mit Ignite Dataset zu beginnen, besteht darin, den
Docker- Container mit Apache Ignite und heruntergeladenen
MNIST- Daten zu starten und dann mit Ignite Dataset damit zu arbeiten. Ein solcher Container ist im Docker Hub verfügbar:
dmitrievanthony / ignite-with-mnist . Sie müssen den Container auf Ihrem Computer ausführen:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
Danach können Sie wie folgt damit arbeiten:
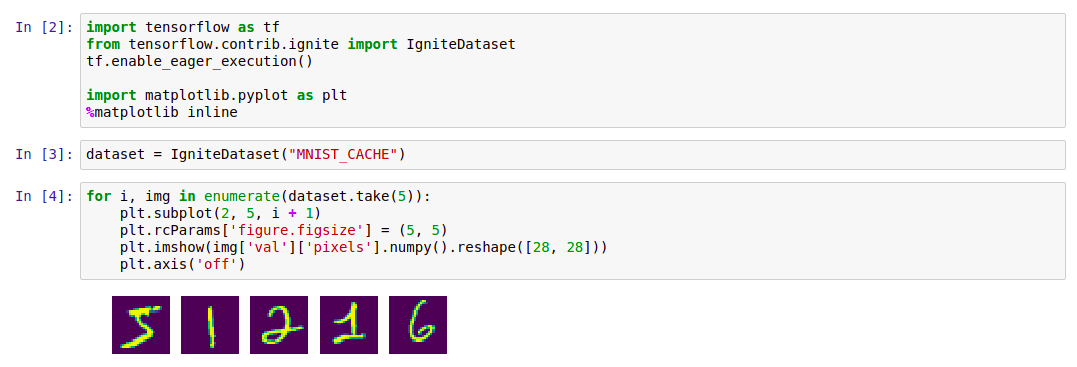
Code import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
Die Unterstützung von TensorFlow IGFS wurde in der Version TensorFlow 1.13.0rc0 veröffentlicht und wird auch Teil der
Version Tensorflow / io in TensorFlow 2.0 sein. Um IGFS mit TensorFlow zu testen, können Sie einen
Docker- Container am einfachsten mit Apache Ignite + IGFS starten und dann mit TensorFlow
tf.gfile damit arbeiten . Ein solcher Container ist im Docker Hub verfügbar:
dmitrievanthony / ignite-with-igfs . Dieser Container kann auf Ihrem Computer ausgeführt werden:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Dann können Sie so damit arbeiten:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Einschränkungen
Derzeit wird bei der Arbeit mit Ignite Dataset davon ausgegangen, dass alle Objekte im Cache dieselbe Struktur haben (homogene Objekte) und dass der Cache mindestens ein Objekt enthält, das zum Abrufen des Schemas erforderlich ist. Eine weitere Einschränkung betrifft strukturierte Objekte: Ignite Dataset unterstützt keine UUIDs, Maps und Object-Arrays, die Teil eines Objekts sein können. Das Entfernen dieser Einschränkungen sowie das Stabilisieren und Synchronisieren von Versionen von TensorFlow und Apache Ignite ist eine der Aufgaben der laufenden Entwicklung.
Erwartete TensorFlow 2.0-Version
Bevorstehende Änderungen an TensorFlow 2.0 werden diese Funktionen im
Tensorflow / Io- Modul
hervorheben . Danach kann die Arbeit mit ihnen flexibler aufgebaut werden. Die Beispiele werden sich ein wenig ändern, und dies wird sich im Gihab und in der Dokumentation widerspiegeln.