Dank der Echtzeitanalyse erhalten wir als Uber-Mitarbeiter eine Vorstellung vom Stand der Dinge und der Arbeitseffizienz. Auf der Grundlage der Daten entscheiden wir, wie die Qualität der Arbeit auf der Uber-Plattform verbessert werden kann. Das Projektteam überwacht beispielsweise die Marktlage und identifiziert potenzielle Probleme auf unserer Plattform. Software, die auf maschinellen Lernmodellen basiert, prognostiziert Passagierangebote und die Nachfrage nach Fahrern; Datenverarbeitungsspezialisten verbessern Modelle für maschinelles Lernen, um die Qualität der Prognosen zu verbessern.

In der Vergangenheit haben wir für Echtzeitanalysen Datenbanklösungen anderer Unternehmen verwendet, aber keine hat alle unsere Kriterien hinsichtlich Funktionalität, Skalierbarkeit, Effizienz, Kosten und Betriebsanforderungen erfüllt.
AresDB wurde im November 2018 veröffentlicht und ist ein Open-Source-Echtzeitanalysetool. Es verwendet ein unkonventionelles Netzteil, Grafikprozessoren (GPU), mit denen Sie den Umfang der Analyse erhöhen können. Die GPU-Technologie, ein vielversprechendes Echtzeit-Analysetool, hat in den letzten Jahren erhebliche Fortschritte gemacht und ist daher ideal für paralleles Echtzeit-Computing und Datenverarbeitung geeignet.
In den folgenden Abschnitten beschreiben wir die Struktur von AresDB und wie diese interessante Lösung für die Echtzeitanalyse es uns ermöglichte, Uber-Datenbanklösungen für die Echtzeitanalyse effizienter und rationaler zu vereinheitlichen, zu vereinfachen und zu verbessern. Wir hoffen, dass Sie nach dem Lesen dieses Artikels AresDB als Teil Ihrer eigenen Projekte ausprobieren und auch dessen Nützlichkeit sicherstellen!
Uber Echtzeit-Analyseanwendungen
Die Datenanalyse ist entscheidend für den Erfolg von Uber. Unter anderem werden Analysewerkzeuge verwendet, um die folgenden Aufgaben zu lösen:
- Erstellen von Dashboards zur Überwachung von Geschäftsmetriken.
- Treffen automatischer Entscheidungen (z. B. Ermittlung der Reisekosten und Ermittlung von Betrugsfällen ) auf der Grundlage der gesammelten zusammenfassenden Messdaten.
- Erstellen Sie zufällige Abfragen zur Diagnose, Fehlerbehebung und Fehlerbehebung von Geschäftsvorgängen.
Wir kategorisieren diese Funktionen mit unterschiedlichen Anforderungen wie folgt:

Dashboards und Entscheidungssysteme verwenden Echtzeitanalysesysteme, um ähnliche Abfragen für relativ kleine, aber sehr wichtige Teilmengen von Daten (mit der höchsten Datenrelevanz) mit hohem QPS und geringer Latenz zu erstellen.
Benötigen Sie ein anderes Analysemodul
Das häufigste Problem, das Uber mithilfe von Echtzeitanalyse-Tools löst, ist die Berechnung von Zeitreihenpopulationen. Diese Berechnungen geben eine Vorstellung von Benutzerinteraktionen, damit wir die Qualität der Dienste entsprechend verbessern können. Basierend darauf fordern wir Indikatoren für bestimmte Parameter (z. B. Tag, Stunde, Stadtkennung und Reisestatus) für einen bestimmten Zeitraum für zufällig gefilterte (oder manchmal kombinierte) Daten an. Im Laufe der Jahre hat Uber mehrere Systeme eingesetzt, um dieses Problem auf verschiedene Weise zu lösen.
Hier sind einige Lösungen von Drittanbietern, mit denen wir diese Art von Problem gelöst haben:
- Apache Pinot , eine in Java geschriebene verteilte Open-Source-Analysedatenbank, eignet sich für umfangreiche Datenanalysen. Pinot verwendet eine interne Lambda-Architektur, um Paketdaten und Echtzeitdaten im Spaltenspeicher abzufragen, einen invertierten Bitindex zum Filtern und einen Sternbaum, um aggregierte Ergebnisse zwischenzuspeichern. Es unterstützt jedoch keine schlüsselbasierte Deduplizierung, Aktualisierung oder Einfügung, Zusammenführung oder erweiterte Abfragefunktionen wie die Geodatenfilterung. Da Pinot eine JVM-basierte Datenbank ist, ist das Abfragen im Hinblick auf die Speichernutzung sehr teuer.
- Elasticsearch wird von Uber verwendet, um verschiedene Streaming-Analyseaufgaben zu lösen. Es basiert auf der Apache Lucene- Bibliothek, in der Dokumente gespeichert sind, für die Volltext-Schlüsselwortsuche und einen invertierten Index. Das System ist weit verbreitet und erweitert, um aggregierte Daten zu unterstützen. Ein invertierter Index bietet Filterung, ist jedoch nicht für das Speichern und Filtern von Daten basierend auf Zeitbereichen optimiert. Datensätze werden in Form von JSON-Dokumenten gespeichert, was zusätzliche Kosten für den Zugriff auf das Repository und die Anforderungen verursacht. Wie Pinot ist Elasticsearch eine JVM-basierte Datenbank und unterstützt dementsprechend die Join-Funktion nicht, und die Ausführung von Abfragen nimmt viel Speicherplatz in Anspruch.
Obwohl diese Technologien ihre Stärken haben, fehlten ihnen einige der für unseren Anwendungsfall erforderlichen Funktionen. Wir brauchten eine einheitliche, vereinfachte und optimierte Lösung, und bei der Suche arbeiteten wir in einer nicht standardmäßigen Richtung (genauer gesagt innerhalb der GPU).
Verwendung der GPU für die Echtzeitanalyse
Für ein realistisches Rendern von Bildern mit einer hohen Bildrate verarbeiten GPUs gleichzeitig eine große Anzahl von Formen und Pixeln mit hoher Geschwindigkeit. Obwohl die Tendenz, die Taktfrequenz von Datenverarbeitungseinheiten in den letzten Jahren zu erhöhen, abgenommen hat, hat die Anzahl der Transistoren im Chip nur nach dem Moore'schen Gesetz zugenommen. Infolgedessen steigt die GPU-Rechengeschwindigkeit, gemessen in Gigaflops pro Sekunde (Gflops / s), schnell an. Abbildung 1 zeigt einen Vergleich des theoretischen Geschwindigkeitstrends (Gflops / s) der NVIDIA-GPU und der Intel-CPU über die Jahre:
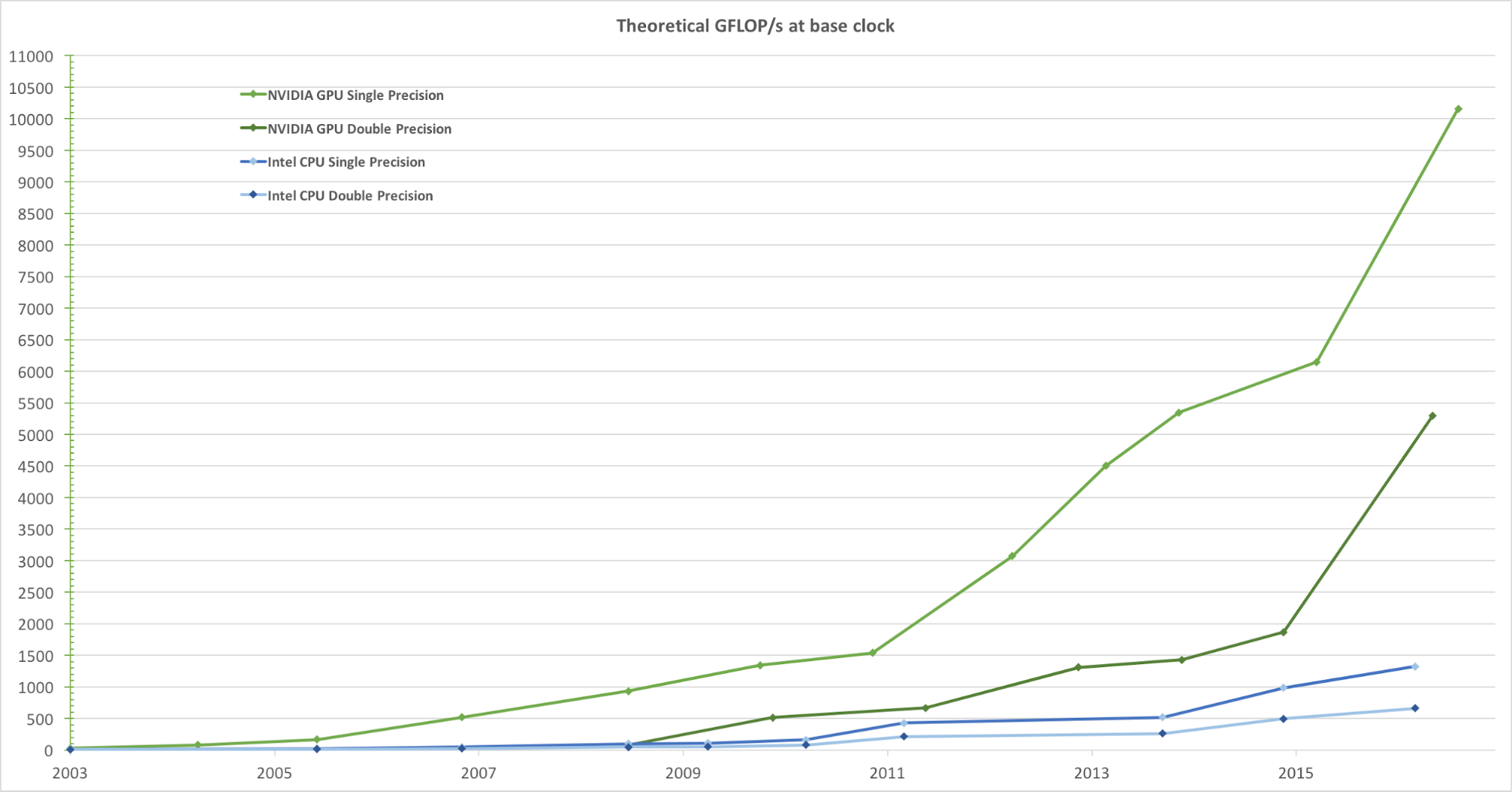
Abbildung 1. Vergleich der Gleitkomma-CPU- und GPU-Leistung mit einfacher Genauigkeit über mehrere Jahre. Bild aus dem CUDA C-Programmierhandbuch von Nvidia.
Bei der Entwicklung des Echtzeitanalyseanforderungsmechanismus war die Entscheidung zur Integration der GPU selbstverständlich. In Uber erfordert eine typische Echtzeitanalyseanforderung, dass Daten in wenigen Tagen mit Millionen oder sogar Milliarden von Datensätzen verarbeitet, dann gefiltert und in kurzer Zeit zusammengefasst werden. Diese Rechenaufgabe passt perfekt in das Allzweck-GPU-Parallelverarbeitungsmodell, weil sie:
- Sie verarbeiten Daten parallel mit sehr hoher Geschwindigkeit.
- Sie bieten eine höhere Rechengeschwindigkeit (Gflops / s), wodurch sie sich hervorragend für die Ausführung komplexer Rechenaufgaben (in Datenblöcken) eignen, die parallelisiert werden können.
- Sie bieten eine höhere Leistung (ohne Verzögerung) beim Datenaustausch zwischen der Recheneinheit und dem Speicher (ALU und globale Speicher-GPU) im Vergleich zu Zentraleinheiten (CPUs), was sie ideal für die Verarbeitung von parallelen Speicher-E / A-Aufgaben macht, die erfordert eine erhebliche Datenmenge.
Wir konzentrierten uns auf die Verwendung einer GPU-basierten Analysedatenbank und bewerteten - vom Standpunkt unserer Anforderungen aus - mehrere vorhandene Analyselösungen, die GPUs verwenden:
- Kinetica , ein GPU-basiertes Analysetool, kam 2009 auf den Markt, zunächst für den Einsatz in der US-Armee und bei Geheimdiensten. Obwohl es das hohe Potenzial der GPU-Technologie in der Analytik demonstriert, haben wir festgestellt, dass für unsere Nutzungsbedingungen viele Schlüsselfunktionen fehlen, einschließlich Ändern des Schemas, teilweises Einfügen oder Aktualisieren, Datenkomprimierung, Festplatten- und Speicherkonfiguration auf Spaltenebene und Verbindung durch räumliche Beziehungen.
- OmniSci , ein Open-Source-SQL-Abfragemodul, schien eine vielversprechende Option zu sein. Bei der Bewertung des Produkts stellten wir jedoch fest, dass einige wichtige Funktionen für die Verwendung in Uber fehlten, z. B. die Deduplizierung. Obwohl OminiSci 2017 den Open-Source-Code seines Projekts einführte, kamen wir nach der Analyse der auf C ++ basierenden Lösung zu dem Schluss, dass eine Änderung oder Verzweigung der Codebasis praktisch nicht möglich ist.
- GPU-basierte Echtzeit-Analysetools wie GPUQP , CoGaDB , GPUDB , Ocelot , OmniDB und Virginian werden häufig in Forschungs- und Bildungseinrichtungen eingesetzt. Angesichts ihrer akademischen Ziele konzentrieren sich diese Entscheidungen jedoch eher auf die Entwicklung von Algorithmen und Testkonzepten als auf die Lösung realer Probleme. Aus diesem Grund haben wir sie nicht berücksichtigt - unter den Bedingungen unseres Volumens und Umfangs.
Im Allgemeinen zeigen diese Systeme den enormen Vorteil und das Potenzial der Datenverarbeitung mithilfe der GPU-Technologie und haben uns dazu inspiriert, eine eigene Echtzeit-Analyselösung auf Basis der GPU zu entwickeln, die an die Anforderungen von Uber angepasst ist. Basierend auf diesen Konzepten haben wir den Quellcode für AresDB entwickelt und geöffnet.
AresDB-Architekturübersicht
Auf hoher Ebene speichert AresDB die meisten Daten im Hostspeicher (RAM, der mit der CPU verbunden ist), verwendet die CPU zur Verarbeitung empfangener Daten und Festplatten zur Wiederherstellung von Daten. Während des Anforderungszeitraums überträgt AresDB Daten vom Hostspeicher zum GPU-Speicher zur parallelen Verarbeitung in der GPU. Wie in Abbildung 2 unten gezeigt, enthält AresDB Speicher, Metadatenspeicher und Festplatte:

Abbildung 2. Die einzigartige Architektur von AresDB umfasst Speicher-, Festplatten- und Metadatenspeicher.
Tabellen
Im Gegensatz zu den meisten relationalen Datenbankverwaltungssystemen (RDBMS) verfügt AresDB nicht über einen Datenbank- oder Schemabereich. Alle Tabellen gehören zum selben Bereich in einem Cluster / einer Instanz von AresDB, sodass Benutzer direkt darauf zugreifen können. Benutzer speichern ihre Daten in Form von Faktentabellen und Dimensionstabellen.
Faktentabelle
Die Faktentabelle speichert einen endlosen Strom von Zeitreihenereignissen. Benutzer verwenden eine Faktentabelle, um Ereignisse / Fakten zu speichern, die in Echtzeit auftreten. Jedes Ereignis ist mit dem Zeitpunkt des Ereignisses verknüpft, und die Tabelle wird häufig zum Zeitpunkt des Ereignisses abgefragt. Als Beispiel für die Art der Informationen, die in der Faktentabelle gespeichert sind, können wir Reisen benennen, bei denen jede Reise ein Ereignis ist, und die Zeit der Reiseanforderung wird häufig als die Zeit des Ereignisses bezeichnet. Wenn einem Ereignis mehrere Zeitstempel zugeordnet sind, wird nur ein Zeitstempel als Uhrzeit des Ereignisses angezeigt und in der Faktentabelle angezeigt.
Messtabelle
In der Messtabelle werden die aktuellen Merkmale der Einrichtungen (einschließlich Städte, Kunden und Fahrer) gespeichert. Beispielsweise können Benutzer Informationen über die Stadt, insbesondere den Namen der Stadt, die Zeitzone und das Land, in der Messtabelle speichern. Im Gegensatz zu Faktentabellen, die ständig wachsen, sind Dimensionstabellen immer in ihrer Größe begrenzt (beispielsweise ist bei Uber die Stadttabelle durch die tatsächliche Anzahl von Städten auf der Welt begrenzt). Maßtabellen erfordern keine spezielle Zeitspalte.
Datentypen
Die folgende Tabelle zeigt die aktuellen Datentypen, die von AresDB unterstützt werden:
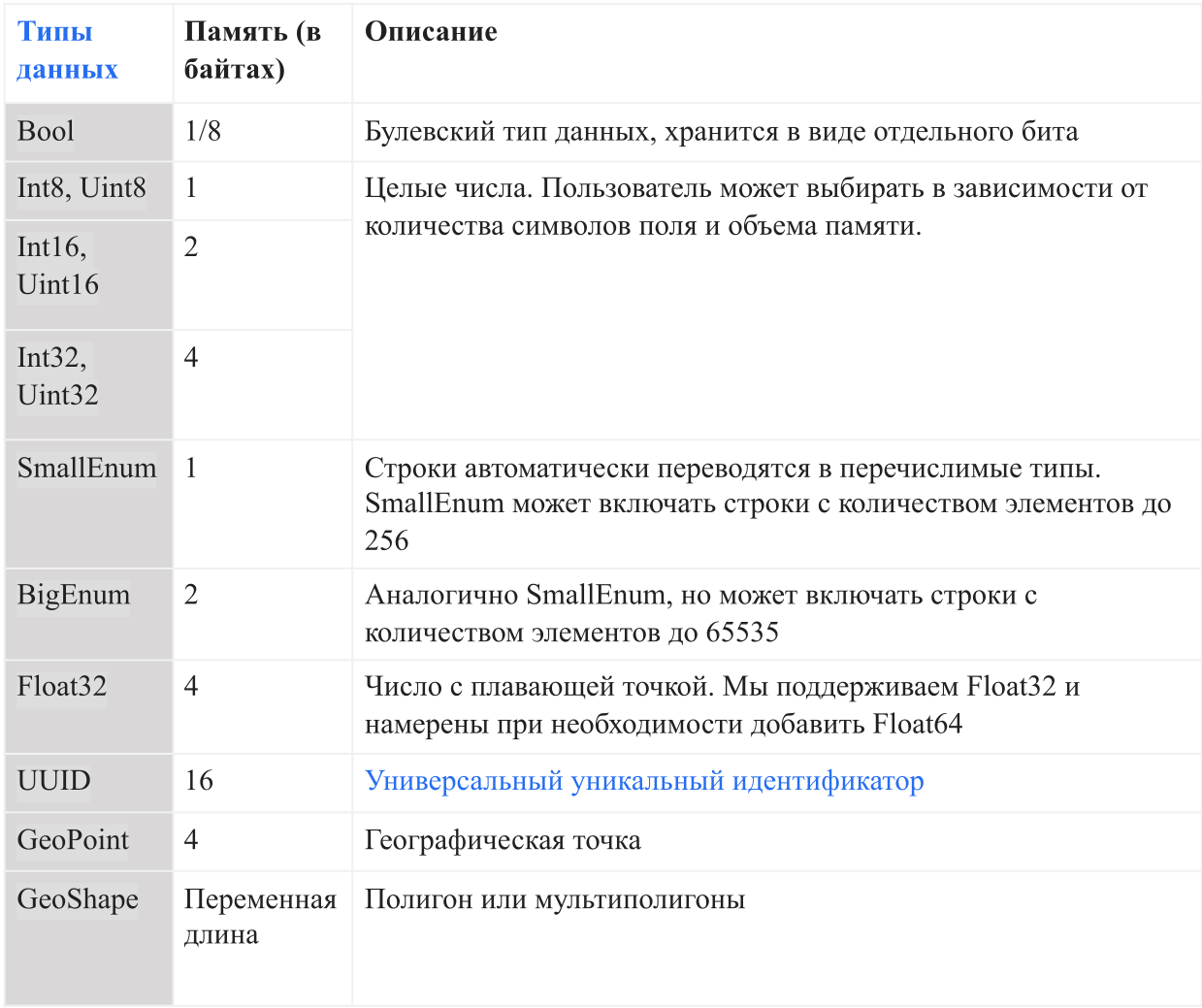
In AresDB werden Zeichenfolgen automatisch in Aufzählungen konvertiert, bevor sie in die Datenbank eingegeben werden, um das Speichern und die Abfrageeffizienz zu vereinfachen . Dies ermöglicht die Überprüfung der Gleichheit zwischen Groß- und Kleinschreibung, unterstützt jedoch keine erweiterten Vorgänge wie Verkettung, Teilzeichenfolgen, Masken und den Abgleich regulärer Ausdrücke. In Zukunft beabsichtigen wir, die Volllinien-Support-Option hinzuzufügen.
Hauptfunktionen
Die AresDB-Architektur unterstützt die folgenden Funktionen:
- Spaltenbasierter Speicher mit Komprimierung zur Steigerung der Speichereffizienz (weniger Speicher in Byte zum Speichern von Daten) und der Abfrageeffizienz (weniger Datenaustausch zwischen CPU-Speicher und GPU-Speicher bei der Verarbeitung einer Anforderung)
- Echtzeit-Aktualisierung oder Einfügung mit Primärschlüsseldeduplizierung , um die Datengenauigkeit und Echtzeit-Datenaktualisierungen in wenigen Sekunden zu verbessern
- GPU-Anforderungsverarbeitung für hochparallele GPU -Datenverarbeitung mit geringer Anforderungslatenz (von Sekundenbruchteilen bis zu mehreren Sekunden)
Spaltenspeicherung
Vektor
AresDB speichert alle Daten in einem Spaltenformat. Die Werte jeder Spalte werden als Spaltenwertvektor gespeichert. Der Konfidenz- / Unsicherheitsmarker der Werte in jeder Spalte wird in einem separaten Nullvektor gespeichert, während der Konfidenzmarker jedes Werts als ein Bit dargestellt wird.
Aktiver Speicher
AresDB speichert unkomprimierte und unsortierte Spaltendaten (aktive Vektoren) im aktiven Speicher. Datensätze im aktiven Speicher werden in (aktive) Pakete eines bestimmten Volumes unterteilt. Beim Empfang von Daten werden neue Pakete erstellt, während alte Pakete nach der Archivierung von Datensätzen gelöscht werden. Der Primärschlüsselindex wird zum Auffinden von Deduplizierungs- und Aktualisierungsdatensätzen verwendet. Abbildung 3 unten zeigt, wie wir aktive Datensätze organisieren und den Primärschlüsselwert verwenden, um ihren Speicherort zu bestimmen:
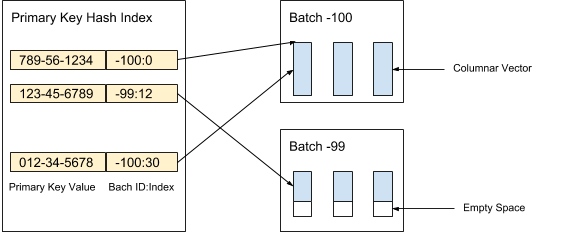
Abbildung 3. Wir verwenden den Primärschlüsselwert, um den Speicherort des Pakets und die Position jedes Datensatzes innerhalb des Pakets zu bestimmen.
Die Werte jeder Spalte im Paket werden als Spaltenvektor gespeichert. Der Zuverlässigkeits- / Unsicherheitsmarker von Werten in jedem Wertvektor wird als separater Nullvektor gespeichert, und der Zuverlässigkeitsmarker jedes Werts wird als ein Bit dargestellt. In Abbildung 4 unten bieten wir ein Beispiel mit fünf Werten für die Spalte city_id :
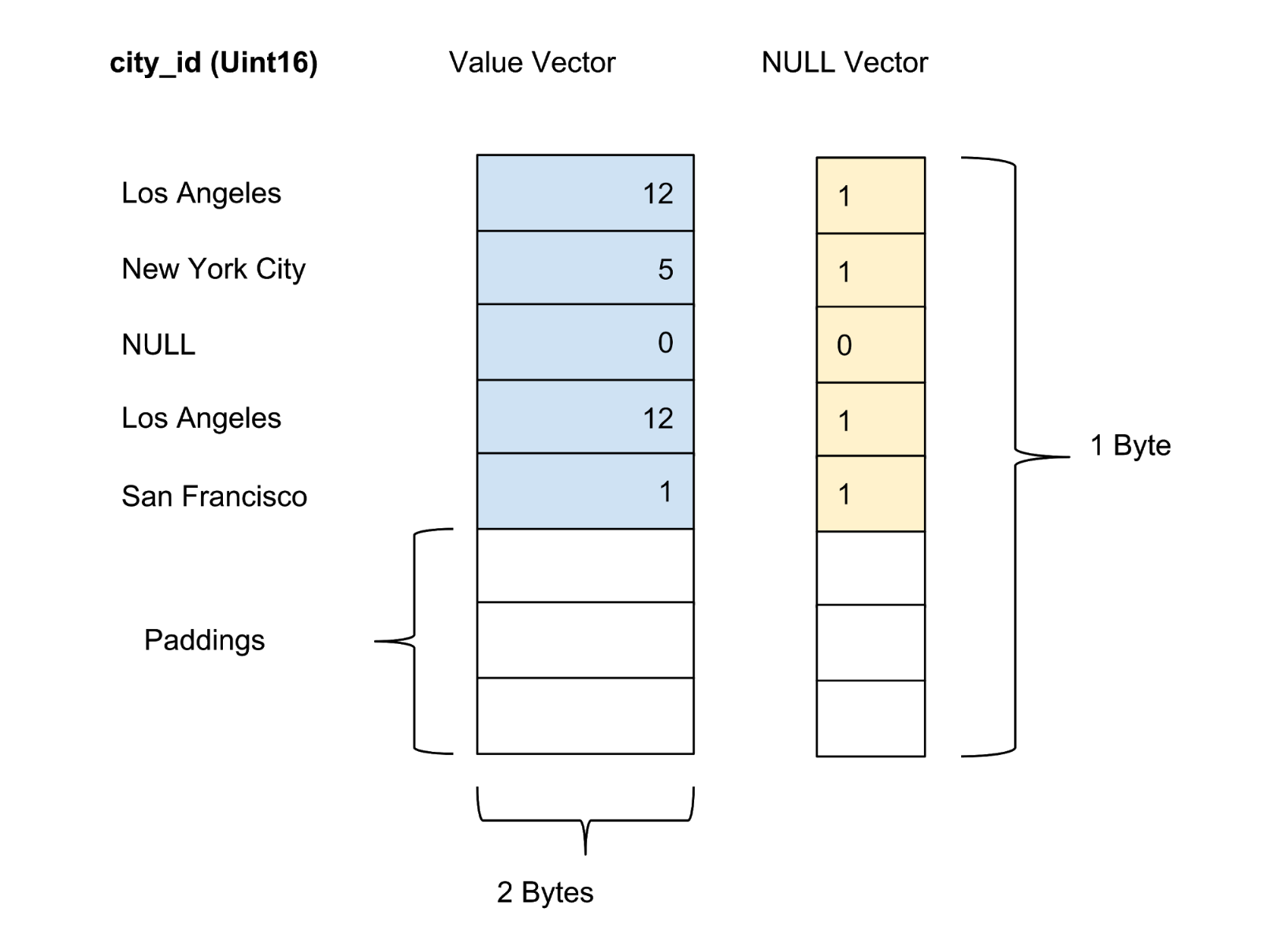
Abbildung 4. Wir speichern Werte (Istwert) und Nullvektoren (Konfidenzmarker) von nicht komprimierten Spalten in der Datentabelle.
Archivspeicher
AresDB speichert auch fertige, sortierte und komprimierte Spaltendaten (Archivvektoren) im Archivspeicher über Faktentabellen. Datensätze im Archivspeicher werden ebenfalls stapelweise verteilt. Im Gegensatz zu aktiven Paketen speichert das Archivpaket Datensätze pro Tag gemäß der koordinierten Weltzeit (UTC). Ein Archivpaket verwendet seit Unix Epoch die Anzahl der Tage als Paketkennung.
Datensätze werden in sortierter Form gemäß einer benutzerdefinierten Spaltensortierreihenfolge gespeichert. Wie in Abbildung 5 unten gezeigt, sortieren wir zuerst nach der Spalte city_id und dann nach der city_id :
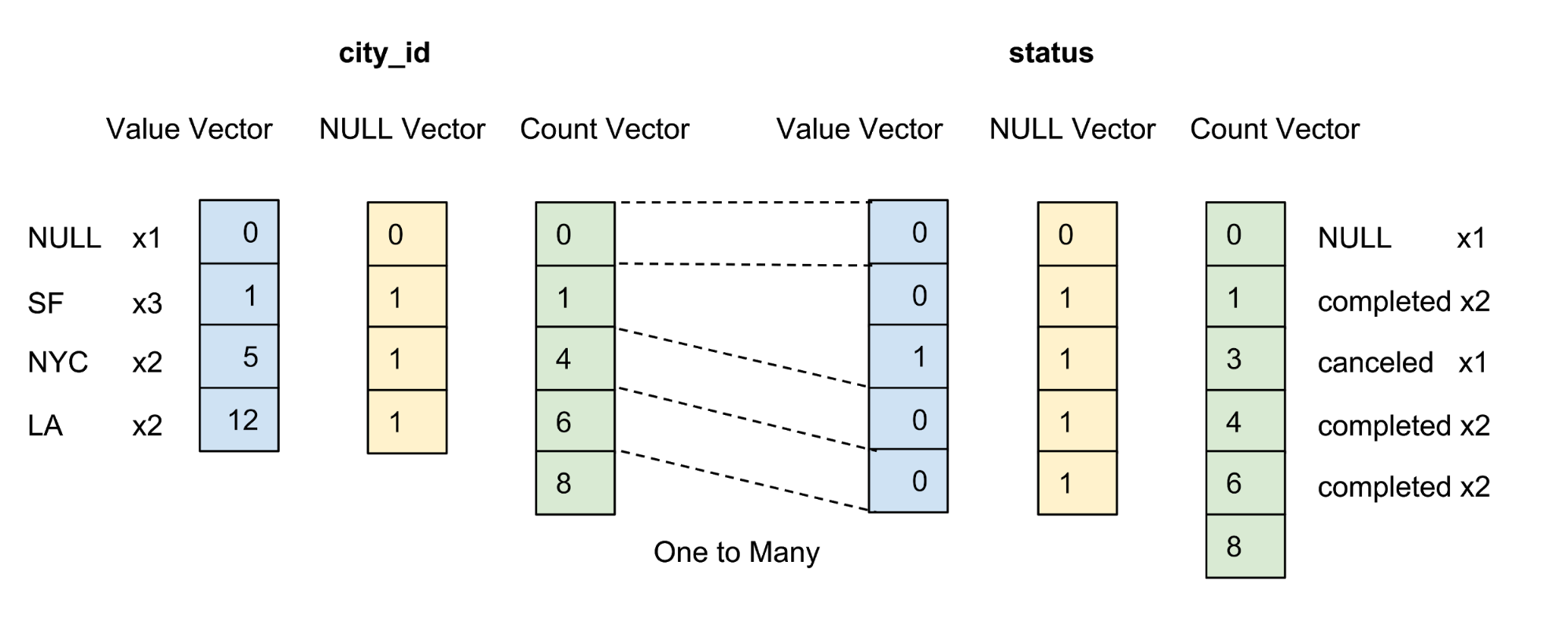
Abbildung 5. Wir sortieren alle Zeilen nach city_id, dann nach state und komprimieren dann jede Spalte nach Gruppencodierung. Nach dem Sortieren und Komprimieren erhält jede Spalte einen Abrechnungsvektor.
Das Ziel beim Festlegen der Benutzersortierreihenfolge für Spalten lautet wie folgt:
- Maximierung des Komprimierungseffekts durch Sortieren von Spalten mit einer kleinen Anzahl von Elementen. Die maximale Komprimierung verbessert die Speichereffizienz (zum Speichern von Daten sind weniger Bytes erforderlich) und die Abfrageeffizienz (weniger Bytes werden zwischen dem CPU-Speicher und dem GPU-Speicher übertragen).
- Bereitstellen einer bequemen bereichsbasierten Vorfilterung für gängige äquivalente Filter, z. B. city_id = 12. Durch die Vorfilterung wird die Anzahl der Bytes minimiert, die zum Übertragen von Daten zwischen dem CPU-Speicher und dem GPU-Speicher erforderlich sind, wodurch die Abfrageeffizienz maximiert wird.
Eine Spalte wird nur komprimiert, wenn sie in der vom Benutzer angegebenen Sortierreihenfolge vorhanden ist. Wir versuchen nicht, Spalten mit einer großen Anzahl von Elementen zu komprimieren, da dies wenig Speicherplatz spart.
Nach dem Sortieren werden die Daten für jede qualifizierte Spalte mithilfe einer bestimmten Gruppencodierungsoption komprimiert. Zusätzlich zum Wertvektor und zum Nullvektor führen wir einen Abrechnungsvektor ein, um denselben Wert erneut darzustellen.
Echtzeit-Datenempfang mit Unterstützung für Aktualisierungs- und Einfügefunktionen
Clients erhalten Daten über die HTTP-API, indem sie ein Service Pack veröffentlichen. Ein Service Pack ist ein speziell geordnetes Binärformat, das die Speicherplatznutzung minimiert und gleichzeitig den zufälligen Zugriff auf Daten gewährleistet.
Wenn AresDB das Service Pack empfängt, schreibt es zuerst das Service Pack in das Wiederherstellungsvorgangsprotokoll. Wenn ein Service Pack am Ende des Ereignisprotokolls hinzugefügt wird, identifiziert und überspringt AresDB späte Einträge in den Faktentabellen zur Verwendung im aktiven Speicher. Ein Datensatz wird als "spät" betrachtet, wenn die Ereigniszeit vor der archivierten Zeit des Trennungsereignisses liegt. Für Datensätze, die nicht als "spät" eingestuft werden, verwendet AresDB den Primärschlüsselindex, um das Paket im aktiven Speicher zu suchen, in den Sie sie einfügen möchten. Wie in Abbildung 6 unten gezeigt, werden neue Datensätze (die zuvor aufgrund des Primärschlüsselwerts nicht gefunden wurden) in den leeren Bereich eingefügt und vorhandene Datensätze direkt aktualisiert:
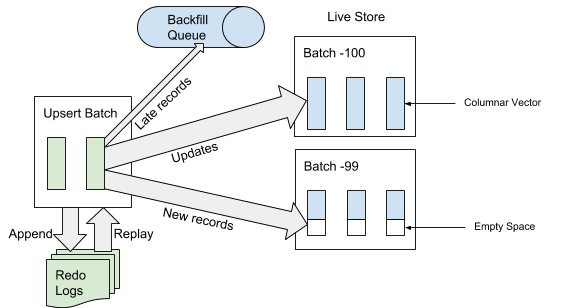
Abbildung 6. Wenn Daten empfangen werden, werden nach dem Hinzufügen des Service Packs zum Ereignisprotokoll die „späten“ Einträge zur umgekehrten Warteschlange und andere Einträge zum aktiven Speicher hinzugefügt.
Archivierung
Wenn Daten empfangen werden, werden Datensätze entweder im aktiven Speicher hinzugefügt / aktualisiert oder der umgekehrten Warteschlange hinzugefügt und warten auf die Platzierung im Archivspeicher.
Wir starten regelmäßig einen geplanten Prozess, der als Archivierung bezeichnet wird, in Bezug auf die Datensätze des aktiven Speichers, um neue Datensätze (Datensätze, die noch nie archiviert wurden) an den Archivspeicher anzuhängen. Der Archivierungsprozess verarbeitet nur die Datensätze im aktiven Speicher mit der Ereigniszeit im Bereich zwischen der alten Abschaltzeit (Abschaltzeit vom letzten Archivierungsprozess) und der neuen Abschaltzeit (neue Abschaltzeit basierend auf dem Parameter für die Archivierungsverzögerung im Tabellenlayout).
Die Datensatzereigniszeit wird verwendet, um zu bestimmen, in welchen Archivpaketdatensätzen kombiniert werden sollen, wenn Archivdaten in tägliche Pakete gepackt werden. Die Archivierung erfordert keine Deduplizierung des Index des Primärschlüsselwerts während des Zusammenführens, da nur Datensätze im Bereich zwischen der alten und der neuen Abschaltzeit archiviert werden.
Abbildung 7 unten zeigt ein Diagramm nach dem Zeitpunkt des Ereignisses eines bestimmten Datensatzes.
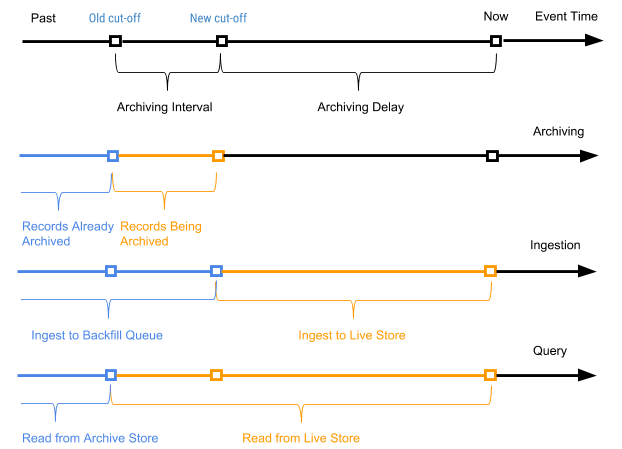
Abbildung 7. Wir verwenden die Ereigniszeit und die Auslösezeit, um die Datensätze als neu (aktiv) und alt zu definieren (die Ereigniszeit ist früher als die archivierte Zeit des Auslöseereignisses).
In diesem Fall ist das Archivierungsintervall das Zeitintervall zwischen den beiden Archivierungsprozessen, und die Archivierungsverzögerung ist der Zeitraum nach dem Zeitpunkt des Ereignisses, jedoch bis zur Archivierung des Ereignisses. Beide Parameter sind in den Einstellungen des AresDB-Tabellenschemas definiert.
Verfüllung
Wie in Abbildung 7 oben gezeigt, werden alte Datensätze (deren Ereigniszeit vor der archivierten Zeit des Herunterfahrereignisses liegt) für Faktentabellen zur umgekehrten Warteschlange hinzugefügt und schließlich als Teil des Auffüllprozesses verarbeitet. Die Auslöser dieses Prozesses sind auch die Zeit oder Größe der umgekehrten Warteschlange, wenn sie einen Schwellenwert erreicht. Im Vergleich zum Hinzufügen von Daten zum aktiven Speicher ist das Auffüllen asynchron und im Hinblick auf CPU- und Speicherressourcen relativ teuer. Das Auffüllen wird in den folgenden Szenarien verwendet:
- Verarbeitung zufälliger, sehr später Daten
- Manuelle Erfassung historischer Daten aus einem vorgelagerten Datenstrom
- Eingabe historischer Daten in kürzlich hinzugefügte Spalten
Im Gegensatz zur Archivierung ist der Backfill-Prozess idempotent und erfordert eine Deduplizierung basierend auf dem Wert des Primärschlüssels. Füllbare Daten sind letztendlich für Abfragen sichtbar.
Die umgekehrte Warteschlange wird mit einer vordefinierten Größe im Speicher gehalten, und bei einer großen Menge an Auffüllung wird der Prozess für den Client blockiert, bis die Warteschlange durch Starten des Auffüllprozesses gelöscht wird.
Anfrage bearbeiten
In der aktuellen Implementierung muss der Benutzer die von Uber erstellte Ares Query Language (AQL) verwenden, um Abfragen in AresDB auszuführen. AQL ist eine effektive Sprache für analytische Zeitreihenabfragen und folgt nicht der Standard-SQL-Syntax wie "SELECT FROM WHERE GROUP BY" wie andere SQL-ähnliche Sprachen. Stattdessen wird AQL in strukturierten Feldern verwendet und kann in JSON-, YAML- und Go-Objekten enthalten sein. Anstelle der /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 wird die entsprechende AQL-Variante in JSON wie folgt geschrieben:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
Im JSON-Format bietet AQL Entwicklern eines Dashboards und eines Entscheidungsfindungssystems einen bequemeren Programmabfragealgorithmus als SQL, mit dem sie Abfragen einfach erstellen und mithilfe von Code bearbeiten können, ohne sich um Dinge wie SQL-Injection kümmern zu müssen. Es fungiert als universelles Abfrageformat für typische Architekturen von Webbrowsern, externen und internen Servern bis zur Datenbank (AresDB). Darüber hinaus bietet AQL eine praktische Syntax zum Filtern nach Zeit und Batching mit Unterstützung für die eigene Zeitzone. Darüber hinaus unterstützt die Sprache eine Reihe von Funktionen, z. B. implizite Unterabfragen, um häufige Fehler bei Abfragen zu vermeiden, und erleichtert Entwicklern der internen Schnittstelle das Analysieren und Umschreiben von Abfragen.
Trotz der vielen Vorteile, die AQL bietet, sind wir uns bewusst, dass die meisten Ingenieure mit SQL besser vertraut sind. Die Bereitstellung einer SQL-Schnittstelle zum Ausführen von Abfragen ist einer der nächsten Schritte, die wir im Rahmen unserer Bemühungen zur Verbesserung der Interaktion mit AresDB-Benutzern betrachten werden.
Das Flussdiagramm für die Ausführung von AQL-Abfragen ist in Abbildung 8 dargestellt:
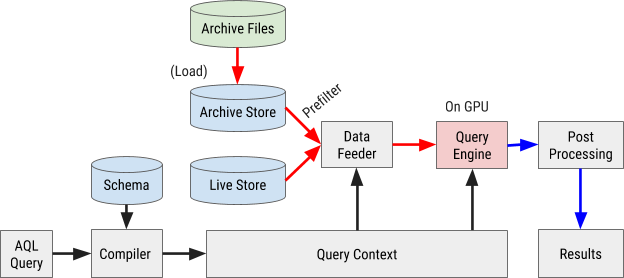
Abbildung 8. Das AresDB-Abfrageflussdiagramm verwendet unsere eigene AQL-Abfragesprache, um Daten schnell und effizient zu verarbeiten und abzurufen.
Abfragekompilierung
Eine AQL-Abfrage wird in den internen Abfragekontext kompiliert. Ausdrücke in Filtern, Messungen und Parametern werden in abstrakten Syntaxbäumen (AST) zur weiteren Verarbeitung durch einen Grafikprozessor (GPU) analysiert.
Laden von Daten
AresDB verwendet Vorfilter, um Archivdaten kostengünstig zu filtern, bevor sie zur parallelen Verarbeitung an die GPU gesendet werden. Da archivierte Daten nach der konfigurierten Spaltenreihenfolge sortiert sind, können einige Filter diese Sortierreihenfolge und die binäre Suchmethode verwenden, um den geeigneten Übereinstimmungsbereich zu bestimmen. Insbesondere können äquivalente Filter für alle anfänglich sortierten X-Spalten und ein optionaler Bereichsfilter für sortierte Spalten X + 1 als vorläufige Filter verwendet werden, wie in Abbildung 9 unten gezeigt.

Abbildung 9. AresDB filtert die Spaltendaten vor, bevor sie zur Verarbeitung an die GPU gesendet werden.
Nach der Vorfilterung sollten nur grüne Werte (die die Filterbedingung erfüllen) zur parallelen Verarbeitung an die GPU gesendet werden. Eingabedaten werden in die GPU geladen und jeweils paketweise verarbeitet. Dies umfasst sowohl aktive Pakete als auch Archivpakete.
AresDB verwendet CUDA-Streams für Pipelining und Datenverarbeitung. Für jede Anforderung werden zwei Ströme abwechselnd zur Verarbeitung in zwei überlappenden Stufen angewendet. In Abbildung 10 unten bieten wir ein Diagramm an, das diesen Prozess veranschaulicht.
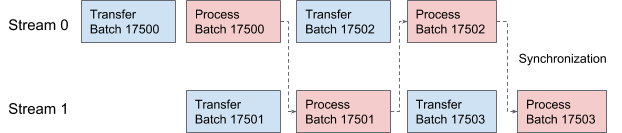
Abbildung 10. In AresDB übertragen und verarbeiten zwei CUDA-Threads abwechselnd Daten.
Abfrageausführung
Der Einfachheit halber verwendet AresDB die Thrust-Bibliothek zum Implementieren von Abfrageausführungsprozeduren, die Blöcke eines fein abgestimmten parallelen Algorithmus für die schnelle Implementierung von Abfragen im aktuellen Tool bietet.
In Thrust werden Eingabe- und Ausgabevektordaten unter Verwendung von Iteratoren mit wahlfreiem Zugriff ausgewertet. Jeder GPU-Thread sucht an seiner Arbeitsposition nach Eingabe-Iteratoren, liest die Werte und führt Berechnungen durch und schreibt das Ergebnis an die entsprechende Position im Ausgabe-Iterator.
Zur Auswertung von AresDB-Ausdrücken folgt das OOPK-Modell (One Operator Per Core).
In Abbildung 11 unten wird diese Prozedur anhand des AST-Beispiels demonstriert, das aus dem Dimensionsausdruck request_at – request_at % 86400 in der Phase der Anforderungskompilierung generiert wurde:
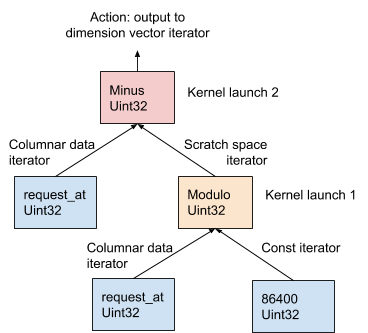
Abbildung 11. AresDB verwendet das OOPK-Modell zur Auswertung von Ausdrücken.
Im OOPK-Modell umgeht die AresDB-Abfrage-Engine jeden Blattknoten des AST-Baums und gibt einen Iterator für den Quellknoten zurück. Wenn der Wurzelknoten ebenfalls endlich ist, wird die Wurzelaktion direkt auf dem Eingabe-Iterator ausgeführt.
Für jeden Nicht-Root-Nicht-End-Knoten (in diesem Beispiel Modulo-Operation ) wird ein temporärer Arbeitsbereichsvektor zugewiesen, um das Zwischenergebnis zu speichern, das aus dem Ausdruck request_at% 86400 . Mit Thrust wird eine Kernelfunktion gestartet, um das Ergebnis dieser Anweisung in der GPU zu berechnen. Die Ergebnisse werden im Arbeitsbereich-Iterator gespeichert.
Bei einem Root-Knoten wird die Kernelfunktion auf dieselbe Weise ausgeführt wie bei einem nicht-root-Knoten, der nicht endlich ist. Abhängig von der Art des Ausdrucks, der im Folgenden ausführlich beschrieben wird, werden verschiedene Ausgabeaktionen ausgeführt:
- Filtern, um die Anzahl der Eingabevektorelemente zu reduzieren
- Aufzeichnen von Messausgangsdaten in einem Messvektor für die anschließende Zusammenführung von Daten
- Notieren Sie die Ausgabe der Parameter im Parametervektor für die anschließende Zusammenführung der Daten
Nach der Auswertung des Ausdrucks werden Sortierung und Transformation durchgeführt, um die Daten endgültig zu kombinieren. Bei Sortier- und Transformationsoperationen verwenden wir die Werte des Dimensionsvektors als Schlüsselwerte für das Sortieren und Transformieren und die Werte des Parametervektors als Werte zum Kombinieren von Daten. Somit werden Zeilen mit ähnlichen Dimensionswerten gruppiert und kombiniert. Abbildung 12 zeigt diesen Sortier- und Konvertierungsprozess.
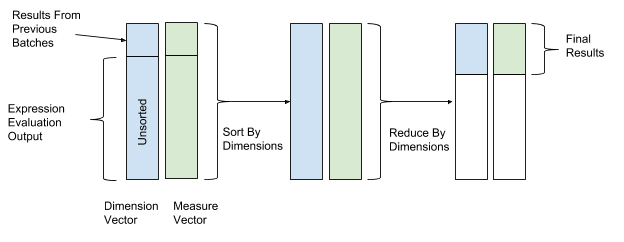
Abbildung 12. Nach der Auswertung des Ausdrucks sortiert und konvertiert AresDB die Daten gemäß den Schlüsselwerten der Messvektoren (Schlüsselwert) und Parameter (Wert).
AresDB unterstützt auch die folgenden erweiterten Abfragefunktionen:
- Join : AresDB unterstützt derzeit eine Hash-Join-Option zwischen der Faktentabelle und der Dimensionstabelle
- Schätzen der Anzahl der Hyperloglog-Elemente : AresDB verwendet den Hyperloglog-Algorithmus
- Geo Intersect : AresDB unterstützt derzeit nur miteinander verbundene Vorgänge zwischen GeoPoint und GeoShape
Ressourcenmanagement
Als Datenbank, die auf internem Speicher basiert, muss AresDB die folgenden Arten der Speichernutzung verwalten:
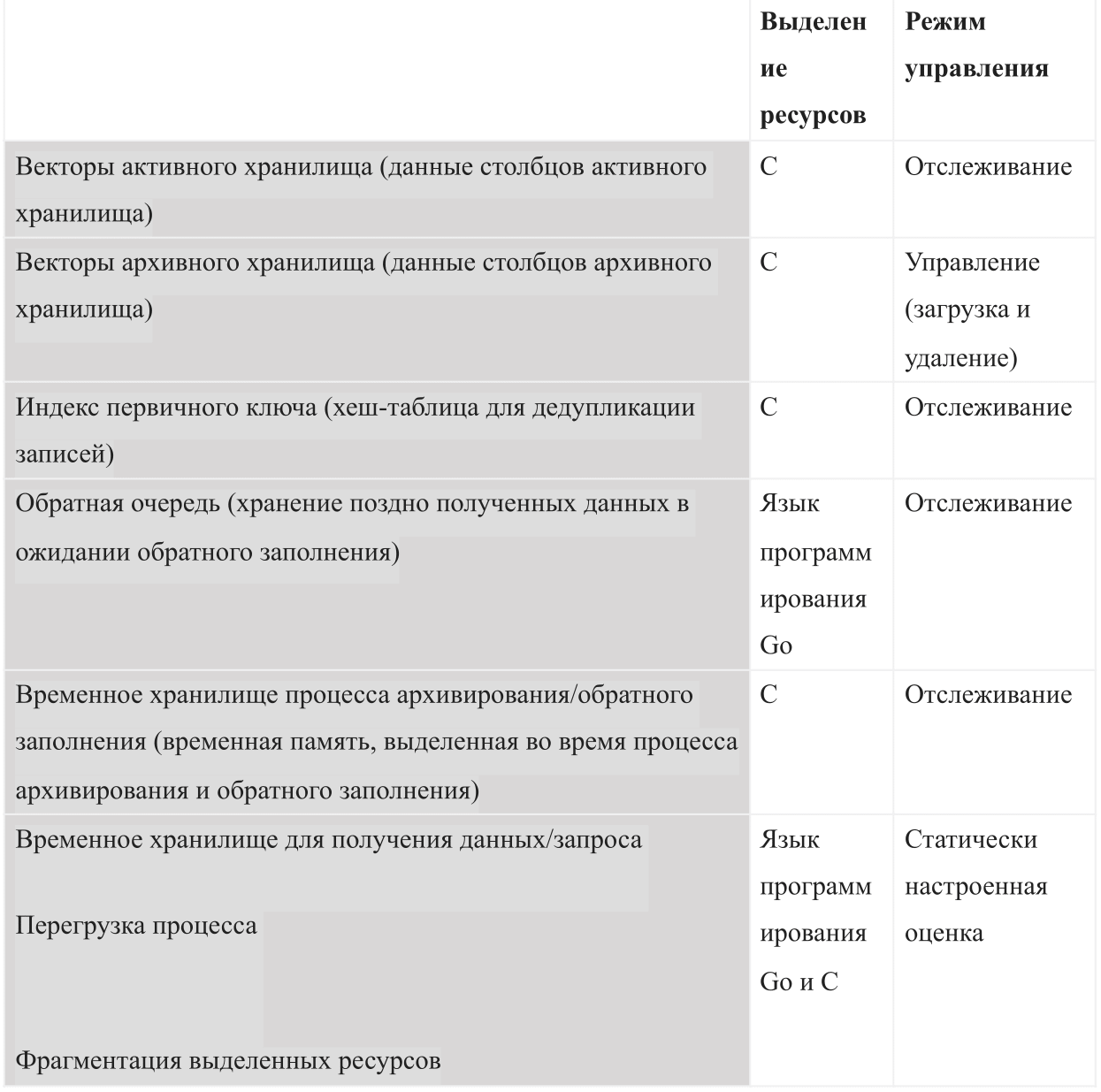
Beim Start von AresDB wird das konfigurierte Budget für gemeinsam genutzten Speicher verwendet. Das Budget ist in alle sechs Speichertypen unterteilt und sollte auch genügend Platz für das Betriebssystem und andere Prozesse lassen. Dieses Budget enthält auch eine statisch konfigurierte Überlastungsschätzung, einen vom Server überwachten aktiven Datenspeicher und archivierte Daten, die der Server je nach verbleibendem Speicherbudget herunterladen und löschen möchte.
Abbildung 13 zeigt das AresDB-Hostspeichermodell.
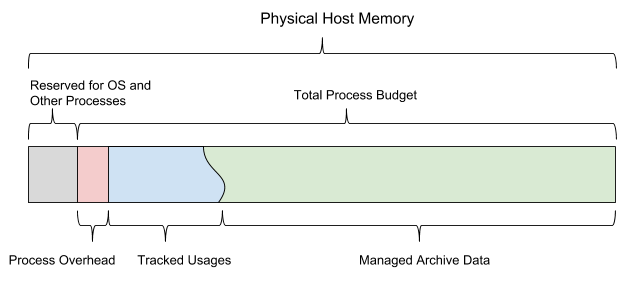
Abbildung 13. AresDB verwaltet seine eigene Speichernutzung so, dass das konfigurierte Gesamtprozessbudget nicht überschritten wird.
Mit AresDB können Benutzer Preload-Tage und Prioritäten auf Spaltenebene für Faktentabellen festlegen und archivierte Daten nur an Preload-Tagen vorab laden. Daten, die zuvor nicht heruntergeladen wurden, werden bei Bedarf von der Festplatte in den Speicher geladen. Beim Auffüllen löscht AresDB auch archivierte Daten aus dem Hostspeicher. Die Prinzipien der AresDB-Entfernung basieren auf den folgenden Parametern: Anzahl der Tage des Vorladens, Prioritäten der Spalten, Tag der Kompilierung des Pakets und Größe der Spalte.
AresDB verwaltet auch mehrere GPU-Geräte und simuliert Geräteressourcen als GPU-Threads und Gerätespeicher, um die Verwendung des GPU-Speichers für die Verarbeitung von Anforderungen zu verfolgen. AresDB verwaltet GPU-Geräte über einen Geräte-Manager, der GPU-Geräteressourcen in zwei Dimensionen (GPU-Threads und Gerätespeicher) modelliert und die Speichernutzung bei der Verarbeitung von Anforderungen verfolgt. Nach dem Kompilieren der Anforderung können Benutzer mit AresDB die Menge an Ressourcen schätzen, die zum Abschließen der Anforderung erforderlich sind. Die Speicheranforderungen des Geräts müssen erfüllt sein, bevor die Anforderung gelöst wird. Wenn auf einem Gerät derzeit nicht genügend Speicher vorhanden ist, sollte die Anforderung warten. Derzeit kann AresDB eine oder mehrere Anforderungen gleichzeitig auf demselben GPU-Gerät ausführen, wenn das Gerät alle Ressourcenanforderungen erfüllt.
In der aktuellen Implementierung speichert AresDB keine Eingaben im Gerätespeicher für die Wiederverwendung in mehreren Anforderungen. AresDB zielt darauf ab, Abfragen für Datensätze zu unterstützen, die ständig in Echtzeit aktualisiert und schlecht zwischengespeichert werden. In zukünftigen Versionen von AresDB beabsichtigen wir, Funktionen zum Zwischenspeichern von Daten im GPU-Speicher zu implementieren, um die Abfrageleistung zu optimieren.
Bei Uber verwenden wir AresDB, um Dashboards zum Abrufen von Geschäftsinformationen in Echtzeit zu erstellen. AresDB ist dafür verantwortlich, primäre Ereignisse mit ständigen Aktualisierungen zu speichern und kritische Metriken in Sekundenbruchteilen zu berechnen, dank GPU-Ressourcen zu geringen Kosten, sodass Benutzer Dashboards interaktiv verwenden können. Beispielsweise werden anonymisierte Reisedaten mit einer langen Gültigkeitsdauer im Data Warehouse von mehreren Diensten aktualisiert, darunter unser Versandsystem, Zahlungs- und Preissysteme. Um Reisedaten effizient zu nutzen, teilen Benutzer Daten in verschiedene Dimensionen auf und teilen sie auf, um Einblicke in Echtzeitlösungen zu erhalten.
Bei Verwendung von AresDB ist das Uber-Dashboard ein weit verbreitetes Analyse-Dashboard, das von Teams im Unternehmen verwendet wird, um relevante Metriken und Echtzeitantworten zur Verbesserung der Benutzererfahrung zu erstellen.
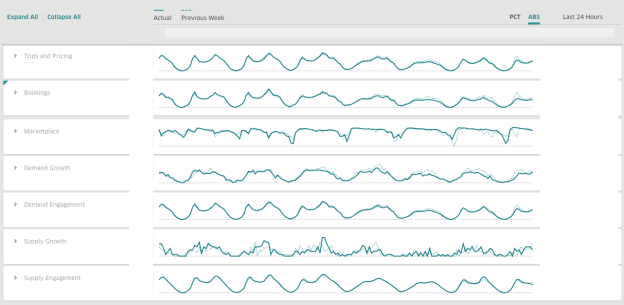
Abbildung 14. Im Stundenmodus verwendet das Uber-Dashboard AresDB, um Echtzeitdatenanalysen für bestimmte Zeiträume anzuzeigen.
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
Danksagung
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !