Hallo an alle.
Ich beschloss, meiner Meinung nach eine einfache und geräumige Lösung eines neuronalen Netzwerks in C ++ zu teilen.
Warum sollten diese Informationen interessant sein?Antwort: Ich habe versucht, die Arbeit des mehrschichtigen Perzeptrons in einem minimalen Satz so zu programmieren, dass es in nur wenigen Codezeilen nach Belieben konfiguriert werden kann. Durch die Implementierung der grundlegenden Algorithmen für die Arbeit an „C“ können Sie orientierte Sprachen einfach auf „C“ (in) übertragen und zu anderen)
ohne Verwendung von Bibliotheken von Drittanbietern!Bitte schauen Sie sich an, was daraus geworden ist
Ich werde Ihnen nichts über den
Zweck neuronaler Netze erzählen. Ich hoffe, Sie wurden nicht von
Google ausgeschlossen und finden die Informationen, an denen Sie interessiert sind (Zweck, Funktionen, Anwendungen usw.).
Sie finden den
Quellcode am Ende des Artikels, aber vorerst in Ordnung.
Beginnen wir mit der Analyse
1) Architektur und technische Details
-
Mehrschichtiges Perzeptron mit der Fähigkeit, eine beliebige Anzahl von Schichten mit einer bestimmten Breite zu konfigurieren. Unten wird vorgestellt
KonfigurationsbeispielmyNeuero.cppinputNeurons = 100;
Bitte beachten Sie, dass das Einstellen der Breite der Eingabe und Ausgabe für jede Ebene gemäß einer bestimmten Regel erfolgt - die Eingabe der aktuellen Ebene = die Ausgabe der vorherigen Ebene. Eine Ausnahme bildet die Eingabeebene.
Somit haben Sie die Möglichkeit, jede Konfiguration vor dem Kompilieren oder nach dem Kompilieren manuell oder nach einer bestimmten Regel zu konfigurieren, um Daten aus Quelldateien zu lesen.
- Implementierung des Mechanismus der
Rückausbreitung von Fehlern mit der Fähigkeit, die Lerngeschwindigkeit einzustellen
myNeuero.h #define learnRate 0.1
- Installation der
AnfangsgewichtemyNeuero.h #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
Hinweis : Wenn mehr als drei Schichten vorhanden sind (nlCount> 4), muss pow (out, -0,5) erhöht werden, damit sich die Energie beim direkten Durchgang des Signals nicht auf 0 verringert. Beispiel pow (out, -0,2)
- die
Basis des Codes in C. Die grundlegenden Algorithmen und die Speicherung von Gewichtungskoeffizienten sind als Struktur in C implementiert, alles andere ist die Hülle der aufrufenden Funktion dieser Struktur, es ist auch eine Reflexion einer der Schichten, die separat betrachtet werden
SchichtstrukturmyNeuero.h struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; };
2) Anwendung
Das Testen des Projekts mit dem Mnist-Set war erfolgreich. Es gelang uns, eine bedingte Handschrifterkennungswahrscheinlichkeit von 0,9795 (nlCount = 4, learnRate = 0,03 und mehrere Epochen) zu erreichen. Der Hauptzweck des Tests bestand darin, die Leistung des neuronalen Netzwerks zu testen, mit dem es fertig wurde.
Nachfolgend betrachten wir die Arbeit an der
"bedingten Aufgabe" .
Ausgangsdaten:-2 zufällige Eingabevektoren mit 100 Werten
neuronales Netzwerk mit zufälliger Erzeugung von Gewichten
-2 Ziele setzen
Der Code in der Funktion main ()
{
Das Ergebnis des neuronalen Netzes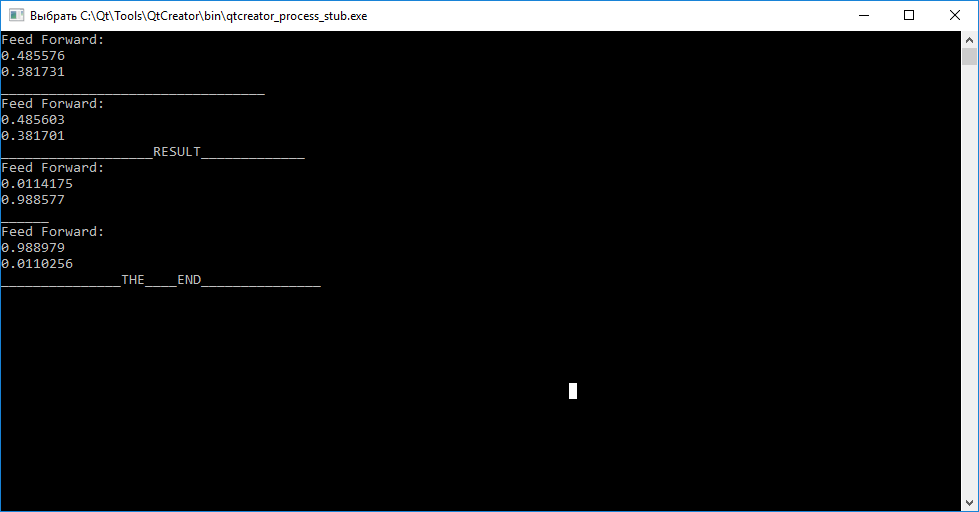
Zusammenfassung
Wie Sie sehen können, können wir durch Aufrufen der Abfragefunktion (Eingaben) vor dem Training für jeden der Vektoren deren Unterschiede nicht beurteilen. Ferner durch Aufrufen der Zugfunktion (Eingabe, Ziel) zum Training mit dem Ziel, Gewichtskoeffizienten so anzuordnen, dass das neuronale Netzwerk anschließend zwischen Eingabevektoren unterscheiden kann.
Nach Abschluss des Trainings stellen wir fest, dass der Versuch, den Vektor "abc" auf "tar1" und "cba" auf "tar2" abzubilden, fehlgeschlagen ist.
Sie haben die Möglichkeit, mithilfe des Quellcodes die Leistung unabhängig zu testen und mit der Konfiguration zu experimentieren!PS: Dieser Code wurde von QtCreator geschrieben. Ich hoffe, Sie können die Ausgabe einfach ersetzen, Ihre Kommentare und Kommentare hinterlassen.
PPS: Wenn jemand an einer detaillierten Analyse der Arbeit von struct nnLay {} write interessiert ist, wird es einen neuen Beitrag geben.
PPPS: Ich hoffe, jemand kann den C-orientierten Code für die Portierung auf andere Tools verwenden.
Quellcodemain.cpp #include <QCoreApplication> #include <QDebug> #include <QTime> #include "myneuro.h" int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); qDebug()<<"_______________THE____END_______________"; return a.exec(); }
myNeuro.cpp #include "myneuro.h" #include <QDebug> myNeuro::myNeuro() { //-------- inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //----------------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); } void myNeuro::feedForwarding(bool ok) { list[0].makeHidden(inputs); for (int i =1; i<nlCount; i++) list[i].makeHidden(list[i-1].getHidden()); if (!ok) { qDebug()<<"Feed Forward: "; for(int out =0; out < outputNeurons; out++) { qDebug()<<list[nlCount-1].hidden[out]; } return; } else { // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); } } void myNeuro::backPropagate() { //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); } void myNeuro::train(float *in, float *targ) { inputs = in; targets = targ; feedForwarding(true); } void myNeuro::query(float *in) { inputs=in; feedForwarding(false); } void myNeuro::printArray(float *arr, int s) { qDebug()<<"__"; for(int inp =0; inp < s; inp++) { qDebug()<<arr[inp]; } }
myNeuro.h #ifndef MYNEURO_H #define MYNEURO_H #include <iostream> #include <math.h> #include <QtGlobal> #include <QDebug> #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro { public: myNeuro(); struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; }; #endif // MYNEURO_H
UPD:
Quellen für die Überprüfung von mnist sind von
der Link1) Projekt
"
Github.com/mamkin-itshnik/simple-neuro-network "
Es gibt auch eine grafische Beschreibung der Arbeit. Kurz gesagt, wenn Sie das Netzwerk mit Testdaten abfragen, erhalten Sie den Wert jedes der Ausgangsneuronen (10 Neuronen entsprechen Zahlen von 0 bis 9). Um eine Entscheidung über die abgebildete Figur zu treffen, müssen Sie den Index des maximalen Neurons kennen. Ziffer = Index + 1 (nicht vergessen, woher die Zahlen in Arrays nummeriert sind))
2) MNIST
"
Www.kaggle.com/oddrationale/mnist-in-csv " (wenn Sie einen kleineren Datensatz verwenden müssen, begrenzen Sie einfach den while-Zähler beim Lesen der CSV-Datei des PS: Es gibt ein Beispiel für git)