Hinweis perev. : Tinder-Mitarbeiter haben kürzlich einige technische Details zur Migration ihrer Infrastruktur auf Kubernetes mitgeteilt. Der Prozess dauerte fast zwei Jahre und führte auf K8 zum Start einer sehr großen Plattform, die aus 200 Diensten besteht, die auf 48.000 Containern gehostet werden. Welche interessanten Schwierigkeiten hatten die Tinder-Ingenieure und zu welchen Ergebnissen kamen sie - lesen Sie in dieser Übersetzung.
Warum?
Vor fast zwei Jahren beschloss Tinder, seine Plattform auf Kubernetes umzustellen. Kubernetes würde es dem Tinder-Team ermöglichen, durch
unveränderliche Bereitstellung mit minimalem Aufwand zu containerisieren und in den Betrieb zu wechseln. In diesem Fall wird die Zusammenstellung von Anwendungen, deren Bereitstellung und die Infrastruktur selbst eindeutig durch den Code bestimmt.
Wir haben auch nach einer Lösung für das Problem der Skalierbarkeit und Stabilität gesucht. Wenn die Skalierung kritisch wurde, mussten wir oft einige Minuten warten, um neue EC2-Instanzen zu starten. Daher wurde die Idee, Container zu starten und den Verkehr in Sekunden statt Minuten zu bedienen, für uns sehr attraktiv.
Der Prozess war nicht einfach. Während der Migration Anfang 2019 erreichte der Kubernetes-Cluster eine kritische Masse, und aufgrund des Datenverkehrs, der Clustergröße und des DNS traten verschiedene Probleme auf. Auf dieser Reise haben wir viele interessante Probleme im Zusammenhang mit der Übertragung von 200 Diensten und der Wartung des Kubernetes-Clusters gelöst, der aus 1000 Knoten, 15.000 Pods und 48.000 Arbeitscontainern besteht.
Wie?
Seit Januar 2018 haben wir verschiedene Migrationsphasen durchlaufen. Wir haben zunächst alle unsere Services containerisiert und in Kubernetes-Testumgebungen bereitgestellt. Im Oktober begann der Prozess der methodischen Übertragung aller vorhandenen Dienste an Kubernetes. Im März des folgenden Jahres war der „Umzug“ abgeschlossen und nun läuft die Tinder-Plattform ausschließlich auf Kubernetes.
Erstellen Sie Bilder für Kubernetes
Wir haben über 30 Quellcode-Repositorys für Microservices, die in einem Kubernetes-Cluster ausgeführt werden. Der Code in diesen Repositorys ist in verschiedenen Sprachen (z. B. Node.js, Java, Scala, Go) mit vielen Laufzeitumgebungen für dieselbe Sprache geschrieben.
Das Build-System bietet einen vollständig anpassbaren "Build-Kontext" für jeden Microservice. Es besteht normalerweise aus einer Docker-Datei und einer Liste von Shell-Befehlen. Ihre Inhalte sind vollständig anpassbar und gleichzeitig werden alle diese Build-Kontexte in einem standardisierten Format geschrieben. Durch die Standardisierung von Build-Kontexten kann ein einzelnes Build-System alle Microservices verwalten.
 Abbildung 1-1. Standardisierter Build-Prozess durch den Container-Builder (Builder)
Abbildung 1-1. Standardisierter Build-Prozess durch den Container-Builder (Builder)Um eine maximale Konsistenz zwischen den Laufzeiten zu erreichen, wird während der Entwicklung und des Testens derselbe Erstellungsprozess verwendet. Wir standen vor einem sehr interessanten Problem: Wir mussten einen Weg entwickeln, um die Konsistenz der Montageumgebung auf der gesamten Plattform zu gewährleisten. Zu diesem Zweck werden alle Montageprozesse in einem speziellen
Builder- Container ausgeführt.
Die Implementierung erforderte fortgeschrittene Techniken für die Arbeit mit Docker. Builder erbt die lokale Benutzer-ID und die Geheimnisse (wie den SSH-Schlüssel, die AWS-Anmeldeinformationen usw.), die für den Zugriff auf die privaten Tinder-Repositorys erforderlich sind. Es stellt lokale Verzeichnisse bereit, die die Quelle enthalten, um Assembly-Artefakte auf natürliche Weise zu speichern. Dieser Ansatz verbessert die Leistung, da keine Assembly-Artefakte zwischen dem Builder-Container und dem Host kopiert werden müssen. Gespeicherte Baugruppenartefakte können ohne zusätzliche Konfiguration wiederverwendet werden.
Für einige Dienste mussten wir einen anderen Container erstellen, um die Kompilierungsumgebung mit der Laufzeit abzugleichen (beispielsweise generiert die bcrypt-Bibliothek von Node.js während des Installationsprozesses plattformspezifische binäre Artefakte). Während der Kompilierung können die Anforderungen für verschiedene Dienste variieren, und die endgültige Docker-Datei wird im laufenden Betrieb kompiliert.
Kubernetes Cluster Architektur und Migration
Clustergrößenverwaltung
Wir haben uns für die Verwendung von
kube-aws entschieden , um den Cluster automatisch auf Amazon EC2-Instanzen
bereitzustellen . Am Anfang funktionierte alles in einem gemeinsamen Knotenpool. Wir haben schnell erkannt, dass Workloads nach Größe und Art der Instanzen getrennt werden müssen, um Ressourcen effizienter nutzen zu können. Die Logik war, dass sich herausstellte, dass der Start mehrerer geladener Multithread-Pods hinsichtlich der Leistung vorhersehbarer war als ihre Koexistenz mit einer großen Anzahl von Single-Threaded-Pods.
Infolgedessen haben wir uns entschieden für:
- m5.4xlarge - zur Überwachung (Prometheus);
- c5.4xlarge - für Node.js Workload (Single-Threaded-Workload);
- c5.2xlarge - für Java und Go (Multithread-Workload);
- c5.4xlarge - für das Bedienfeld (3 Knoten).
Die Migration
Einer der vorbereitenden Schritte für die Migration von der alten Infrastruktur zu Kubernetes bestand darin, die vorhandene direkte Interaktion zwischen Diensten auf die neuen Load Balancer (ELB, Elastic Load Balancers) umzuleiten. Sie wurden in einem bestimmten VPC-Subnetz (Virtual Private Cloud) erstellt. Dieses Subnetz war mit Kubernetes VPC verbunden. Dadurch konnten wir die Module schrittweise migrieren, ohne die spezifische Reihenfolge der Dienstabhängigkeiten zu berücksichtigen.
Diese Endpunkte wurden unter Verwendung gewichteter Sätze von DNS-Einträgen erstellt, wobei CNAMEs auf jede neue ELB verweisen. Zum Umschalten haben wir einen neuen Datensatz hinzugefügt, der auf eine neue Kubernetes-Dienst-ELB mit einer Gewichtung von 0 verweist. Anschließend haben wir die Time To Live (TTL) des Recordset auf 0 gesetzt. Danach wurden die alten und neuen Gewichte langsam angepasst und schließlich 100% der Last gesendet auf den neuen Server. Nach Abschluss der Umschaltung wird der TTL-Wert auf ein angemesseneres Niveau zurückgesetzt.
Unsere vorhandenen Java-Module handhabten DNS mit niedrigem TTL-Wert, Knotenanwendungen jedoch nicht. Einer der Ingenieure hat einen Teil des Verbindungspoolcodes neu geschrieben und ihn in einen Manager eingeschlossen, der die Pools alle 60 Sekunden aktualisiert. Der gewählte Ansatz funktionierte sehr gut und ohne merklichen Leistungsabfall.
Der Unterricht
Einschränkungen für Netzwerkgeräte
In den frühen Morgenstunden des 8. Januar 2019 stürzte die Tinder-Plattform plötzlich ab. Als Reaktion auf eine nicht damit verbundene Zunahme der Plattformlatenz am frühen Morgen nahm die Anzahl der Pods und Knoten im Cluster zu. Dies führte zur Erschöpfung des ARP-Cache auf allen unseren Knoten.
Dem ARP-Cache sind drei Linux-Optionen zugeordnet:

(
Quelle )
gc_thresh3 ist eine harte Grenze. Das Erscheinen von Einträgen des Formulars „Nachbartabellenüberlauf“ im Protokoll führte dazu, dass selbst nach der synchronen Speicherbereinigung (GC) im ARP-Cache nicht genügend Speicherplatz zum Speichern des benachbarten Datensatzes vorhanden war. In diesem Fall hat der Kernel das Paket einfach vollständig verworfen.
Wir verwenden
Flanell als
Netzwerkstruktur in Kubernetes. Pakete werden über VXLAN übertragen. VXLAN ist ein L2-Tunnel, der über ein L3-Netzwerk gehoben wird. Die Technologie verwendet die MAC-in-UDP-Kapselung (MAC Address-in-User Datagram Protocol) und ermöglicht das Erweitern der Netzwerksegmente der 2. Ebene. Das Transportprotokoll im physischen Netzwerk des Rechenzentrums lautet IP plus UDP.
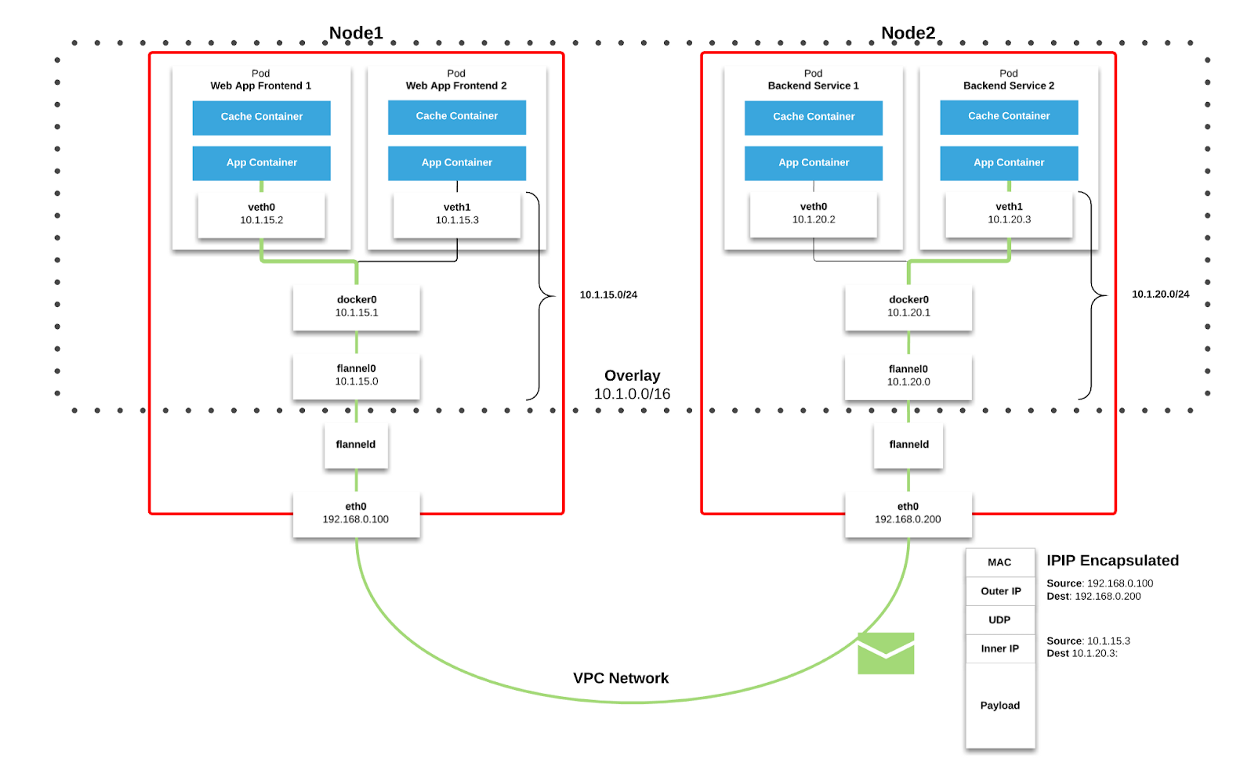 Abbildung 2–1. Flanell-Diagramm ( Quelle )
Abbildung 2–1. Flanell-Diagramm ( Quelle ) Abbildung 2–2. VXLAN-Paket ( Quelle )
Abbildung 2–2. VXLAN-Paket ( Quelle )Jeder Kubernetes-Arbeitsknoten weist einen virtuellen Adressraum mit Maske / 24 aus dem größeren Block / 9 zu. Für jeden Knoten
bedeutet dies einen Eintrag in der Routing-Tabelle, einen Eintrag in der ARP-Tabelle (auf der
Flannel.1- Schnittstelle) und einen Eintrag in der Switching-Tabelle (FDB). Sie werden hinzugefügt, wenn der Arbeitsknoten zum ersten Mal gestartet wird oder wenn jeder neue Knoten erkannt wird.
Darüber hinaus wird die Node-
Pod- (oder Pod-
Pod- ) Verbindung letztendlich über die
eth0- Schnittstelle geleitet (wie im obigen
Flanelldiagramm gezeigt). Dies führt zu einem zusätzlichen Eintrag in der ARP-Tabelle für jede entsprechende Quelle und jedes Ziel des Knotens.
In unserer Umgebung ist diese Art der Kommunikation sehr verbreitet. Für Diensttypobjekte in Kubernetes wird eine ELB erstellt, und Kubernetes registriert jeden Knoten in der ELB. ELB weiß nichts über Pods und der ausgewählte Knoten ist möglicherweise nicht das endgültige Ziel des Pakets. Tatsache ist, dass ein Knoten, der ein Paket von ELB empfängt, dies unter Berücksichtigung der
iptables- Regeln für einen bestimmten Dienst berücksichtigt und zufällig einen Pod auf einem anderen Knoten auswählt.
Zum Zeitpunkt des Ausfalls hatte der Cluster 605 Knoten. Aus den oben genannten Gründen war dies ausreichend, um den
Standardwert gc_thresh3 zu überwinden. In diesem Fall werden nicht nur Pakete verworfen, sondern der gesamte virtuelle Flanell-Adressraum mit der / 24-Maske verschwindet aus der ARP-Tabelle. Node-Pod-Kommunikation und DNS-Abfragen werden unterbrochen (DNS wird in einem Cluster gehostet; Einzelheiten finden Sie im Rest dieses Artikels).
Um dieses Problem zu lösen, erhöhen Sie die Werte von
gc_thresh1 ,
gc_thresh2 und
gc_thresh3 und starten Sie Flannel neu, um die fehlenden Netzwerke neu zu registrieren.
Unerwartete DNS-Skalierung
Während des Migrationsprozesses haben wir DNS aktiv verwendet, um den Datenverkehr zu verwalten und die Dienste schrittweise von der alten Infrastruktur auf Kubernetes zu übertragen. Wir legen in Route53 relativ niedrige TTL-Werte für verwandte RecordSets fest. Als die alte Infrastruktur auf EC2-Instanzen ausgeführt wurde, zeigte unsere Resolver-Konfiguration auf Amazon DNS. Wir hielten dies für selbstverständlich und die Auswirkungen niedriger TTL auf unsere Amazon-Dienste (wie DynamoDB) blieben fast unbemerkt.
Bei der Migration von Diensten zu Kubernetes haben wir festgestellt, dass DNS 250.000 Abfragen pro Sekunde verarbeitet. Infolgedessen kam es bei Anwendungen zu konstanten und schwerwiegenden Zeitüberschreitungen bei DNS-Abfragen. Dies geschah trotz unglaublicher Bemühungen, den DNS-Anbieter zu optimieren und auf CoreDNS umzustellen (der 1000 Pods erreichte, die bei Spitzenlast auf 120 Kernen ausgeführt wurden).
Wir haben andere mögliche Ursachen und Lösungen untersucht und
einen Artikel gefunden , der die Rennbedingungen beschreibt, die sich auf das
Netfilter- Paketfilter-Framework unter Linux auswirken. Die beobachteten Zeitüberschreitungen entsprachen zusammen mit dem zunehmenden Zähler
insert_failed in der
Flanellschnittstelle den Schlussfolgerungen des Artikels.
Das Problem tritt in der
Phase der Quell- und Zielnetzwerk-Adressübersetzung (SNAT und DNAT) und dem anschließenden Eintrag in die
Conntrack- Tabelle auf. Eine der im Unternehmen diskutierten und von der Community vorgeschlagenen Problemumgehungen war die Übertragung von DNS an den Arbeitsknoten selbst. In diesem Fall:
- SNAT wird nicht benötigt, da der Datenverkehr innerhalb des Knotens verbleibt. Es muss nicht über die eth0- Schnittstelle geleitet werden.
- DNAT wird nicht benötigt, da die Ziel-IP lokal für den Host ist und kein zufällig ausgewählter Pod gemäß den iptables- Regeln.
Wir haben uns entschlossen, an diesem Ansatz festzuhalten. CoreDNS wurde als DaemonSet in Kubernetes bereitgestellt und wir haben einen lokalen Host-DNS-Server in der
resolv.conf jedes Pods implementiert, indem wir das
Flag --cluster-dns des Befehls
kubelet konfiguriert haben . Diese Lösung hat sich bei DNS-Zeitüberschreitungen als wirksam erwiesen.
Wir beobachteten jedoch immer noch einen Paketverlust und eine Zunahme des
Zählers insert_failed in der
Flanellschnittstelle . Diese Situation setzte sich nach Einführung der Problemumgehung fort, da wir SNAT und / oder DNAT nur für den DNS-Verkehr ausschließen konnten. Die Rennbedingungen für andere Verkehrsarten blieben bestehen. Glücklicherweise sind die meisten unserer Pakete TCP, und wenn ein Problem auftritt, werden sie einfach erneut übertragen. Wir versuchen immer noch, eine geeignete Lösung für alle Arten von Verkehr zu finden.
Verwenden von Envoy für einen besseren Lastausgleich
Als wir Backend-Services nach Kubernetes migrierten, litten wir unter einer unausgeglichenen Last zwischen den Pods. Wir haben festgestellt, dass aufgrund von HTTP Keepalive ELB-Verbindungen an den ersten vorgefertigten Pods jeder Rollout-Bereitstellung hängen. Somit ging der Großteil des Verkehrs durch einen kleinen Prozentsatz der verfügbaren Pods. Die erste von uns getestete Lösung bestand darin, den MaxSurge-Parameter bei neuen Bereitstellungen im schlimmsten Fall auf 100% zu setzen. Der Effekt war unbedeutend und in Bezug auf größere Bereitstellungen nicht vielversprechend.
Eine andere von uns verwendete Lösung bestand darin, die Ressourcenanforderungen für unternehmenskritische Dienste künstlich zu erhöhen. In diesem Fall hätten benachbarte Pods mehr Handlungsspielraum als andere schwere Pods. Auf lange Sicht würde es auch aufgrund der Verschwendung von Ressourcen nicht funktionieren. Darüber hinaus waren unsere Knotenanwendungen Single-Threaded-Anwendungen und konnten dementsprechend nur einen Kern verwenden. Die einzige wirkliche Lösung bestand darin, einen besseren Lastausgleich zu verwenden.
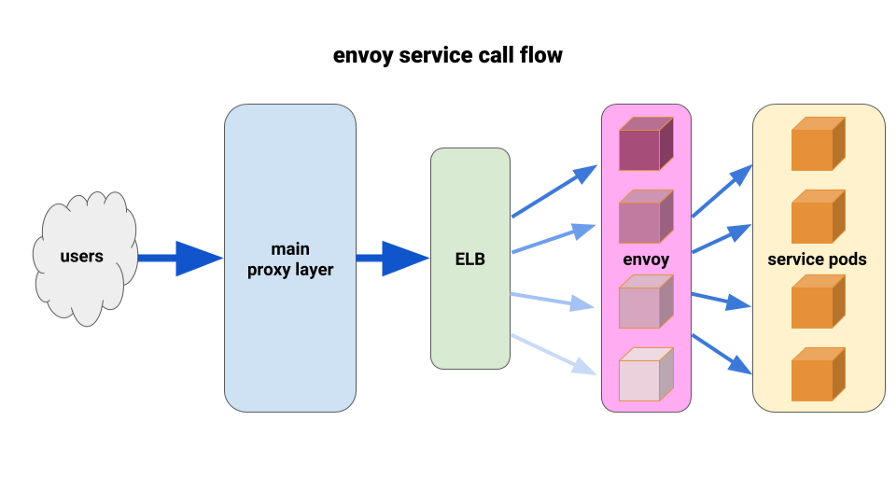
Wir wollten
Envoy schon lange voll und ganz schätzen. Die aktuelle Situation ermöglichte es uns, es auf sehr begrenzte Weise einzusetzen und sofortige Ergebnisse zu erzielen. Envoy ist ein Open-Source-Proxy der siebten Ebene mit hoher Leistung, der für große SOA-Anwendungen entwickelt wurde. Er ist in der Lage, fortschrittliche Lastausgleichstechniken anzuwenden, einschließlich automatischer Wiederholungsversuche, Leistungsschalter und globaler Geschwindigkeitsbegrenzungen.
( Anmerkung Übersetzung : Weitere Informationen finden Sie im aktuellen Artikel über Istio - das Service-Netz, das auf Envoy basiert.)Wir haben die folgende Konfiguration entwickelt: Envoy-Beiwagen für jeden Pod und eine einzelne Route sowie den Cluster - lokale Verbindung zum Container über den Port. Um mögliche Kaskadierungen zu minimieren und einen kleinen „Schadensradius“ beizubehalten, haben wir den Envoy-Front-Proxy-Pod-Park verwendet, einen für jede Verfügbarkeitszone (AZ) für jeden Dienst. Sie wandten sich einem einfachen Service Discovery-Mechanismus zu, der von einem unserer Ingenieure geschrieben wurde und der einfach eine Liste der Pods in jedem AZ für einen bestimmten Service zurückgab.
Dann verwendeten die Service-Front-Envoys diesen Service-Erkennungsmechanismus mit einem Upstream-Cluster und einer Route. Wir haben angemessene Zeitüberschreitungen festgelegt, alle Einstellungen für Leistungsschalter erhöht und eine minimale Wiederholungskonfiguration hinzugefügt, um bei einzelnen Fehlern zu helfen und nahtlose Bereitstellungen sicherzustellen. Vor jedem dieser Service-Front-Gesandten haben wir eine TCP-ELB platziert. Selbst wenn das Keepalive von unserer Haupt-Proxy-Schicht an einigen Envoy-Pods hängen würde, könnten sie die Last noch viel besser bewältigen und wären so konfiguriert, dass sie mindestens_request im Backend ausgleichen.
Für die Bereitstellung haben wir den preStop-Hook sowohl für Anwendungs-Pods als auch für Sidecar-Pods verwendet. Der Hook hat einen Fehler beim Überprüfen des Status des Administrator-Endpunkts auf dem Sidecar-Container ausgelöst und eine Weile "geschlafen", damit aktive Verbindungen hergestellt werden können.
Einer der Gründe, warum wir bei der Lösung von Problemen so schnell Fortschritte erzielen konnten, sind detaillierte Metriken, die wir problemlos in eine Standard-Prometheus-Installation integrieren konnten. Mit ihnen wurde es möglich, genau zu sehen, was geschah, während wir die Konfigurationsparameter auswählten und den Verkehr neu verteilten.
Die Ergebnisse waren sofort und offensichtlich. Wir haben mit den unausgewogensten Diensten begonnen und im Moment funktioniert es bereits vor den 12 wichtigsten Diensten im Cluster. In diesem Jahr planen wir die Umstellung auf ein vollwertiges Service-Mesh mit fortschrittlicherer Serviceerkennung, Schaltkreisunterbrechung, Ausreißererkennung, Geschwindigkeitsbegrenzung und Nachverfolgung.
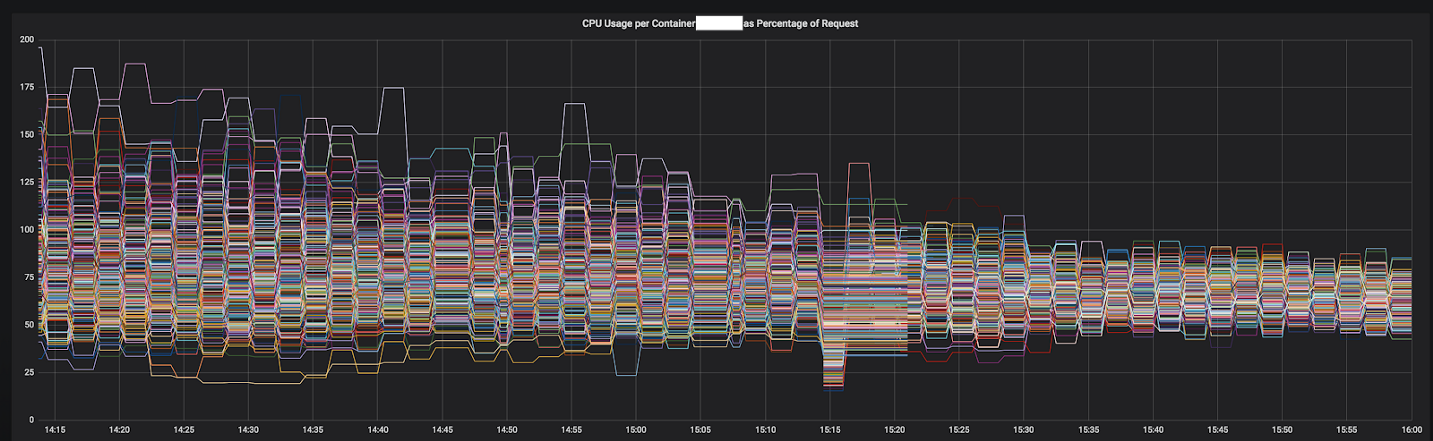 Abbildung 3–1. CPU-Konvergenz eines Dienstes während des Übergangs zu Envoy
Abbildung 3–1. CPU-Konvergenz eines Dienstes während des Übergangs zu Envoy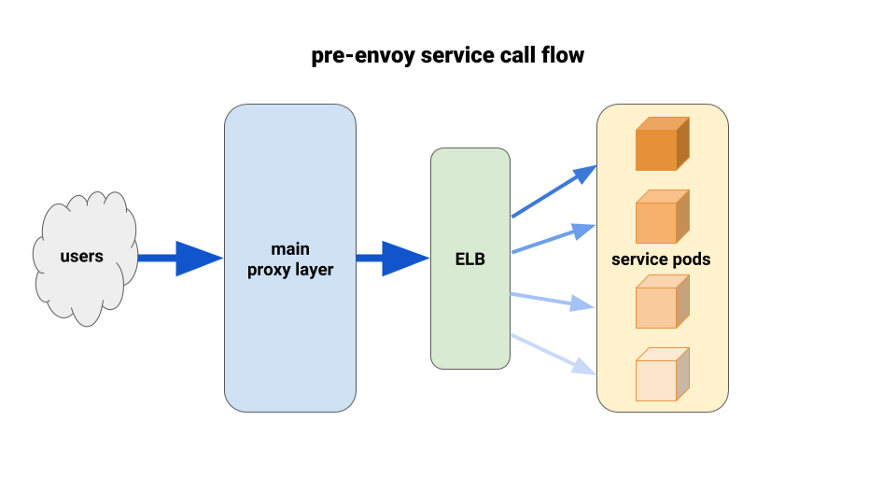
Endergebnis
Dank unserer Erfahrung und zusätzlicher Forschung haben wir ein starkes Infrastruktur-Team mit guten Fähigkeiten beim Entwerfen, Bereitstellen und Betreiben großer Kubernetes-Cluster aufgebaut. Jetzt verfügen alle Tinder-Ingenieure über das Wissen und die Erfahrung, wie Container gepackt und Anwendungen in Kubernetes bereitgestellt werden.
Als der Bedarf an zusätzlichen Kapazitäten für die alte Infrastruktur entstand, mussten wir einige Minuten warten, um neue EC2-Instanzen zu starten. Jetzt starten die Container und beginnen, den Datenverkehr für einige Sekunden anstatt für Minuten zu verarbeiten. Das Planen mehrerer Container auf einer einzelnen Instanz von EC2 bietet auch eine verbesserte horizontale Konzentration. Infolgedessen prognostizieren wir für 2019 eine deutliche Reduzierung der EC2-Kosten im Vergleich zum Vorjahr.
Die Migration dauerte fast zwei Jahre, aber wir haben sie im März 2019 abgeschlossen. Derzeit läuft die Tinder-Plattform ausschließlich auf dem Kubernetes-Cluster, der aus 200 Diensten, 1000 Knoten, 15.000 Pods und 48.000 laufenden Containern besteht. Die Infrastruktur liegt nicht mehr in der alleinigen Verantwortung der Betriebsteams. Alle unsere Ingenieure teilen diese Verantwortung und steuern den Prozess der Erstellung und Bereitstellung ihrer Anwendungen nur mit Code.
PS vom Übersetzer
Lesen Sie auch unsere Artikelserie in unserem Blog: