Bei der letzten internen Kundgebung von Pyrus sprachen wir über modernen verteilten Speicher, und Maxim Nalsky, CEO und Gründer von Pyrus, teilte seinen ersten Eindruck von FoundationDB. In diesem Artikel sprechen wir über die technischen Nuancen, mit denen Sie bei der Auswahl einer Technologie zur Skalierung der Speicherung strukturierter Daten konfrontiert sind.
Wenn der Dienst für Benutzer für einige Zeit nicht verfügbar ist, ist er äußerst unangenehm, aber immer noch nicht tödlich. Der Verlust von Kundendaten ist jedoch absolut inakzeptabel. Daher bewerten wir jede Technologie zum Speichern von Daten sorgfältig anhand von zwei bis drei Dutzend Parametern.
Einige von ihnen bestimmen die aktuelle Auslastung des Dienstes.
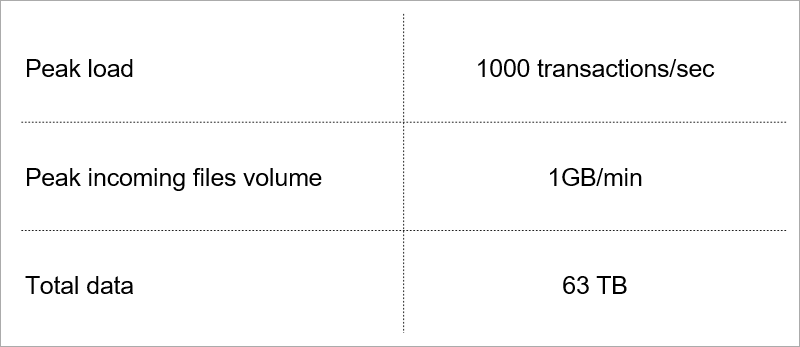 Aktuelle Last. Wir wählen die Technologie unter Berücksichtigung des Wachstums dieser Indikatoren aus.
Aktuelle Last. Wir wählen die Technologie unter Berücksichtigung des Wachstums dieser Indikatoren aus.Client-Server-Architektur
Das klassische Client-Server-Modell ist das einfachste Beispiel für ein verteiltes System. Ein Server ist ein Synchronisationspunkt, mit dem mehrere Clients koordiniert etwas gemeinsam tun können.
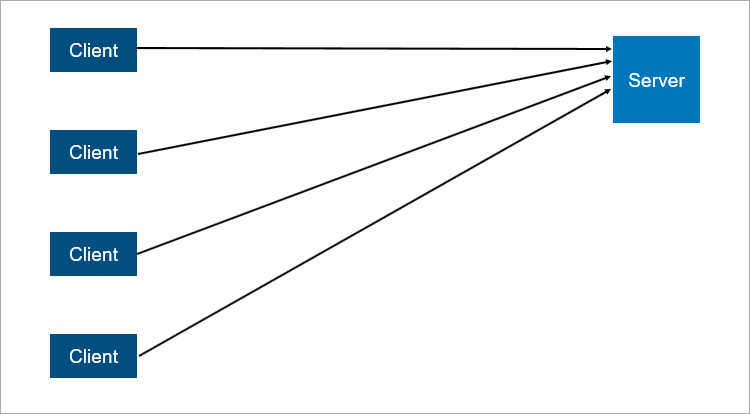 Ein sehr vereinfachtes Schema der Client-Server-Interaktion.
Ein sehr vereinfachtes Schema der Client-Server-Interaktion.Was ist in der Client-Server-Architektur unzuverlässig? Offensichtlich kann der Server abstürzen. Und wenn der Server abstürzt, können nicht alle Clients arbeiten. Um dies zu vermeiden, haben sich die Leute eine Master-Slave-Verbindung ausgedacht (die jetzt
politisch korrekt ist und als Leader-Follower bezeichnet wird ). Unter dem Strich gibt es zwei Server, alle Clients kommunizieren mit dem Hauptserver, und auf dem zweiten Server werden alle Daten einfach repliziert.
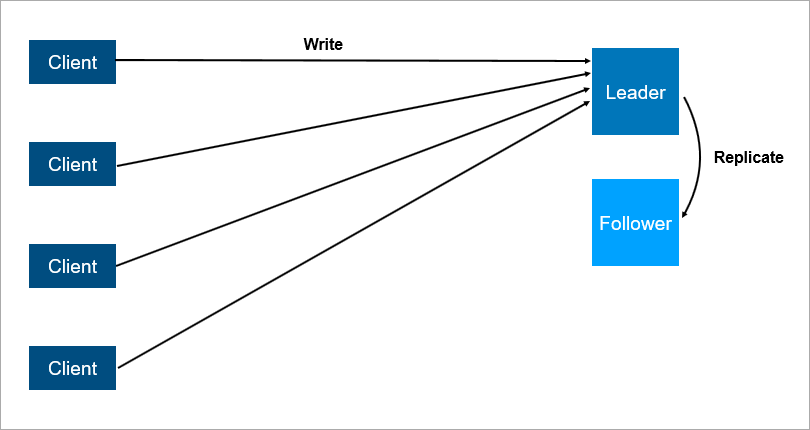 Client-Server-Architektur mit Datenreplikation für Follower.
Client-Server-Architektur mit Datenreplikation für Follower.Es ist klar, dass dies ein zuverlässigeres System ist: Wenn der Hauptserver abstürzt, befindet sich eine Kopie aller Daten auf dem Follower und kann schnell ausgelöst werden.
Es ist wichtig zu verstehen, wie die Replikation funktioniert. Wenn es synchron ist, muss die Transaktion gleichzeitig auf dem Leader und auf dem Follower gespeichert werden. Dies kann langsam sein. Wenn die Replikation asynchron ist, können Sie nach einem Failover einige Daten verlieren.
Und was passiert, wenn der Anführer nachts fällt, wenn alle schlafen? Es gibt Daten über den Follower, aber niemand hat ihm gesagt, dass er jetzt ein Anführer ist und Kunden keine Verbindung zu ihm herstellen. OK, lassen Sie uns den Anhänger mit der Logik ausstatten, dass er beginnt, sich als Hauptsache zu betrachten, wenn die Verbindung zum Anführer verloren geht. Dann können wir leicht ein gespaltenes Gehirn bekommen - ein Konflikt, wenn die Verbindung zwischen dem Anführer und dem Anhänger unterbrochen wird und beide denken, dass sie die wichtigsten sind. Dies geschieht wirklich auf vielen Systemen,
wie z. B. RabbitMQ , der heute beliebtesten Warteschlangentechnologie.
Um diese Probleme zu lösen, organisieren Sie das automatische Failover. Fügen Sie einen dritten Server hinzu (Zeuge, Zeuge). Es stellt sicher, dass wir nur einen Führer haben. Und wenn der Leader abfällt, schaltet sich der Follower automatisch mit einer minimalen Ausfallzeit ein, die auf einige Sekunden reduziert werden kann. Natürlich müssen Kunden in diesem Schema die Adressen des Leiters und des Nachfolgers im Voraus kennen und die Logik der automatischen Wiederverbindung zwischen ihnen implementieren.
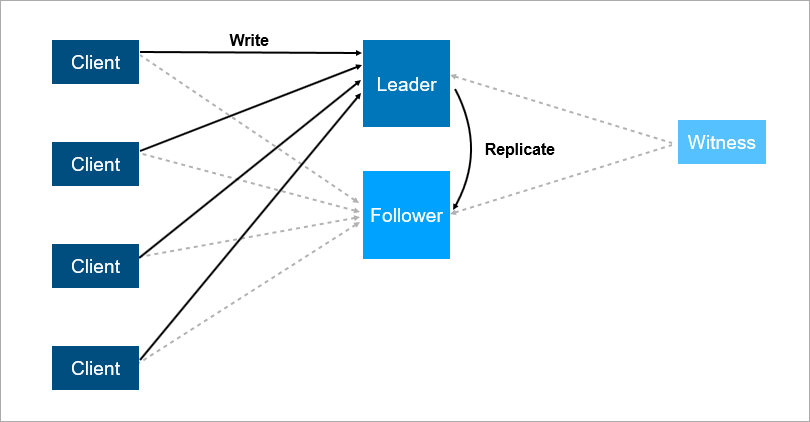 Der Zeuge garantiert, dass es nur einen Führer gibt. Wenn der Anführer abfällt, schaltet sich der Follower automatisch ein.
Der Zeuge garantiert, dass es nur einen Führer gibt. Wenn der Anführer abfällt, schaltet sich der Follower automatisch ein.Ein solches System funktioniert jetzt bei uns. Es gibt eine Hauptdatenbank, eine Ersatzdatenbank, einen Zeugen und ja - manchmal kommen wir morgens und sehen, dass der Wechsel nachts stattgefunden hat.
Dieses Schema hat aber auch Nachteile. Stellen Sie sich vor, Sie installieren Service Packs oder aktualisieren das Betriebssystem auf einem Leader-Server. Vorher haben Sie die Last des Mitnehmers manuell umgeschaltet und dann ... fällt sie! Katastrophe, Ihr Dienst ist nicht verfügbar. Was tun, um sich davor zu schützen? Fügen Sie einen dritten Sicherungsserver hinzu - einen weiteren Follower. Drei ist eine Art magische Zahl. Wenn das System zuverlässig funktionieren soll, reichen zwei Server nicht aus, Sie benötigen drei. Einer für die Wartung, der zweite fällt, der dritte bleibt.
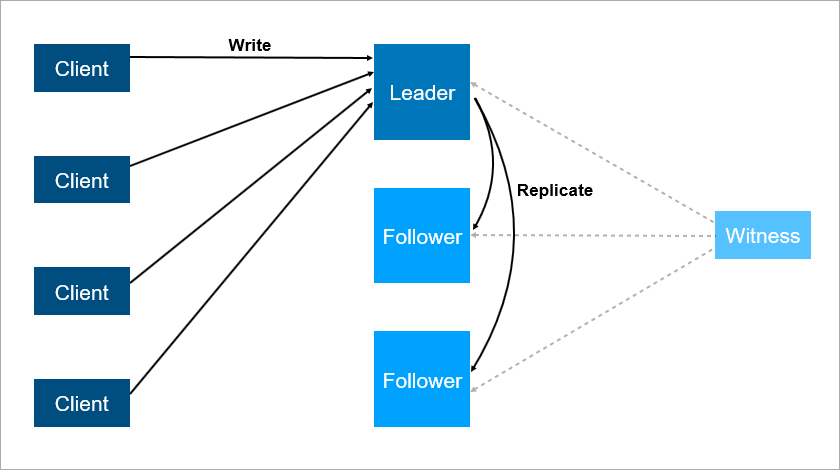 Der dritte Server bietet einen zuverlässigen Betrieb, wenn die ersten beiden nicht verfügbar sind.
Der dritte Server bietet einen zuverlässigen Betrieb, wenn die ersten beiden nicht verfügbar sind.Zusammenfassend sollte die Redundanz gleich zwei sein. Eine Redundanz von eins reicht nicht aus. Aus diesem Grund wurde in Festplatten-Arrays das RAID6-Schema anstelle von RAID5 verwendet, um den Ausfall von zwei Festplatten zu überstehen.
Transaktionen
Vier grundlegende Anforderungen für Transaktionen sind bekannt: Atomizität, Konsistenz, Isolation und Haltbarkeit (Atomizität, Konsistenz, Isolation, Haltbarkeit - ACID).
Wenn wir über verteilte Datenbanken sprechen, meinen wir, dass die Daten skaliert werden müssen. Das Lesen lässt sich sehr gut skalieren - Tausende von Transaktionen können problemlos Daten parallel lesen. Wenn jedoch andere Transaktionen gleichzeitig mit dem Lesen Daten schreiben, sind verschiedene unerwünschte Effekte möglich. Es ist sehr einfach, eine Situation zu erhalten, in der eine Transaktion unterschiedliche Werte derselben Datensätze liest. Hier sind einige Beispiele.
Dirty liest. In der ersten Transaktion senden wir dieselbe Anfrage zweimal: Nehmen Sie alle Benutzer mit der ID = 1. Wenn die zweite Transaktion diese Zeile ändert und dann ein Rollback durchführt, werden in der Datenbank einerseits keine Änderungen angezeigt, andererseits Bei der ersten Transaktion werden unterschiedliche Alterswerte für Joe gelesen.
 Nicht wiederholbare Lesevorgänge.
Nicht wiederholbare Lesevorgänge. Ein anderer Fall ist, wenn die Schreibtransaktion erfolgreich abgeschlossen wurde und die Lesetransaktion während der Ausführung derselben Anforderung unterschiedliche Daten empfangen hat.

Im ersten Fall las der Client Daten, die im Allgemeinen in der Datenbank nicht vorhanden waren. Im zweiten Fall liest der Client beide Male die Daten aus der Datenbank, sie sind jedoch unterschiedlich, obwohl das Lesen innerhalb derselben Transaktion erfolgt.
Phantom-Lesevorgänge sind, wenn wir einen Bereich innerhalb derselben Transaktion erneut lesen und einen anderen Satz von Zeilen erhalten. Irgendwo in der Mitte hat eine andere Transaktion Datensätze eingegeben und eingefügt oder gelöscht.

Um diese unerwünschten Effekte zu vermeiden, implementieren moderne DBMS Sperrmechanismen (eine Transaktion beschränkt den Zugriff auf die Daten, mit denen sie gerade arbeitet, auf andere Transaktionen) oder die Multiversion-Versionskontrolle
MVCC (eine Transaktion ändert niemals zuvor aufgezeichnete Daten und erstellt immer eine neue Version).
Der ANSI / ISO-SQL-Standard definiert 4 Isolationsstufen für Transaktionen, die sich auf den Grad der gegenseitigen Blockierung auswirken. Je höher der Isolationsgrad, desto weniger unerwünschte Wirkungen. Der Preis dafür besteht darin, die Anwendung zu verlangsamen (da Transaktionen häufiger darauf warten, die benötigten Daten freizuschalten) und die Wahrscheinlichkeit von Deadlocks zu erhöhen.
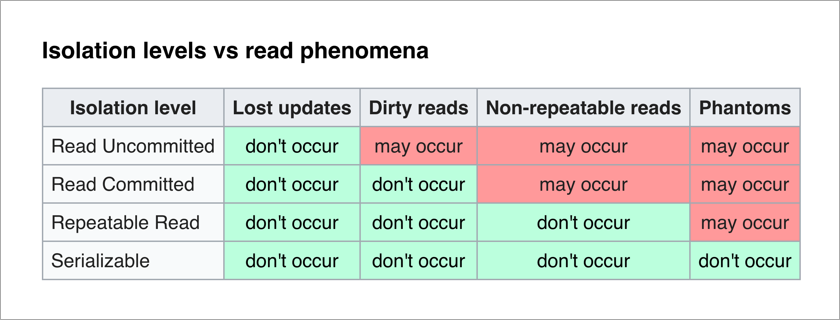
Für einen Anwendungsprogrammierer ist die serialisierbare Ebene am angenehmsten - es gibt keine unerwünschten Auswirkungen und die gesamte Komplexität der Sicherstellung der Datenintegrität wird auf das DBMS verlagert.
Lassen Sie uns über die naive Implementierung der serialisierbaren Ebene nachdenken - mit jeder Transaktion blockieren wir einfach alle anderen. Jede Schreibtransaktion kann theoretisch in 50 µs ausgeführt werden (die Zeit einer Schreiboperation auf modernen SSD-Festplatten). Und wir wollen Daten auf drei Maschinen speichern, erinnerst du dich? Befinden sie sich im selben Rechenzentrum, dauert die Aufzeichnung 1-3 ms. Wenn sie sich aus Gründen der Zuverlässigkeit in verschiedenen Städten befinden, kann die Aufzeichnung problemlos 10 bis 12 ms dauern (die Reisezeit eines Netzwerkpakets von Moskau nach St. Petersburg und umgekehrt). Das heißt, mit einer naiven Implementierung der serialisierbaren Ebene durch sequentielle Aufzeichnung können wir nicht mehr als 100 Transaktionen pro Sekunde ausführen. Mit einer separaten SSD können Sie ungefähr 20.000 Schreibvorgänge pro Sekunde ausführen!
Fazit: Schreibtransaktionen müssen parallel ausgeführt werden. Um sie zu skalieren, benötigen Sie einen guten Konfliktlösungsmechanismus.
Scherben
Was tun, wenn die Daten nicht mehr auf einem Server gespeichert werden? Es gibt zwei Standard-Zoommechanismen:
- Aufrecht, wenn wir diesem Server nur Speicher und Festplatten hinzufügen. Dies hat seine Grenzen - in Bezug auf die Anzahl der Kerne pro Prozessor, die Anzahl der Prozessoren und die Speichermenge.
- Horizontal, wenn wir viele Maschinen verwenden und Daten zwischen ihnen verteilen. Sätze solcher Maschinen werden Cluster genannt. Um Daten in einen Cluster zu stellen, müssen sie gespalten werden. Das heißt, für jeden Datensatz wird festgelegt, auf welchem Server sie sich befinden.
Ein Sharding-Schlüssel ist ein Parameter, mit dem Daten zwischen Servern verteilt werden, z. B. eine Client- oder Organisationskennung.
Stellen Sie sich vor, Sie müssen Daten über alle Bewohner der Erde in einem Cluster aufzeichnen. Als Shard-Schlüssel können Sie beispielsweise das Geburtsjahr der Person verwenden. Dann reichen 116 Server aus (und jedes Jahr muss ein neuer Server hinzugefügt werden). Oder Sie können das Land, in dem die Person lebt, als Schlüssel nehmen, dann benötigen Sie ungefähr 250 Server. Die erste Option ist jedoch vorzuziehen, da sich das Geburtsdatum der Person nicht ändert und Sie niemals Daten über sie zwischen den Servern übertragen müssen.
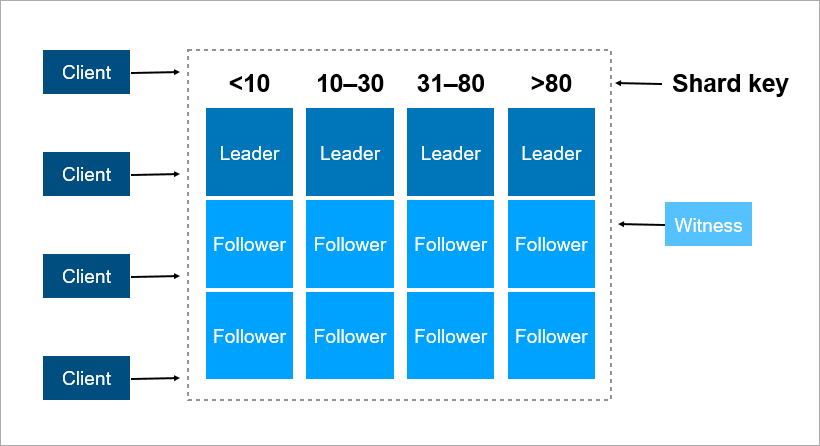
In Pyrus können Sie eine Organisation als Sharding-Schlüssel verwenden. Ihre Größe ist jedoch sehr unterschiedlich: Es gibt sowohl eine riesige Sovcombank (mehr als 15.000 Benutzer) als auch Tausende kleiner Unternehmen. Wenn Sie einer Organisation einen bestimmten Server zuweisen, wissen Sie nicht im Voraus, wie dieser wachsen wird. Wenn die Organisation groß ist und den Dienst aktiv nutzt, werden die Daten früher oder später nicht mehr auf einem Server gespeichert, und Sie müssen erneut ein Hardharding durchführen. Und das ist nicht einfach, wenn die Daten Terabyte sind. Stellen Sie sich vor: Bei einem geladenen System werden Transaktionen jede Sekunde ausgeführt, und unter diesen Bedingungen müssen Sie Daten von einem Ort an einen anderen verschieben. Sie können das System nicht stoppen, ein solches Volumen kann mehrere Stunden lang gepumpt werden, und Geschäftskunden werden eine so lange Ausfallzeit nicht überleben.
Als Sharding-Schlüssel ist es besser, Daten auszuwählen, die sich selten ändern. Eine angewandte Aufgabe macht dies jedoch bei weitem nicht immer einfach.
Konsens im Cluster
Wenn sich viele Computer im Cluster befinden und einige den Kontakt zu anderen verlieren, wie kann dann entschieden werden, wer die neueste Version der Daten speichert? Das Zuweisen eines Zeugenservers reicht nicht aus, da dadurch auch der Kontakt zum gesamten Cluster verloren gehen kann. Darüber hinaus können in einer Situation mit geteiltem Gehirn mehrere Maschinen unterschiedliche Versionen derselben Daten aufzeichnen - und Sie müssen irgendwie herausfinden, welche am relevantesten ist. Um dieses Problem zu lösen, wurden Konsensalgorithmen entwickelt. Sie ermöglichen es mehreren identischen Maschinen, durch Abstimmung zu einem einzigen Ergebnis zu gelangen. 1989 wurde der erste derartige Algorithmus,
Paxos , veröffentlicht, und 2014 entwickelten die Jungs von Stanford ein einfacher zu implementierendes
Floß . Streng genommen reicht es aus, wenn ein Cluster von (2N + 1) Servern einen Konsens erzielt, dass gleichzeitig nicht mehr als N Fehler auftreten. Um 2 Fehler zu überleben, muss der Cluster über mindestens 5 Server verfügen.
Relationale DBMS-Skalierung
Die meisten Datenbanken, mit denen Entwickler arbeiten, unterstützen relationale Algebra. Die Daten werden in Tabellen gespeichert, und manchmal müssen Sie die Daten aus verschiedenen Tabellen mithilfe der Operation JOIN verknüpfen. Betrachten Sie ein Beispiel für eine Datenbank und eine einfache Abfrage.
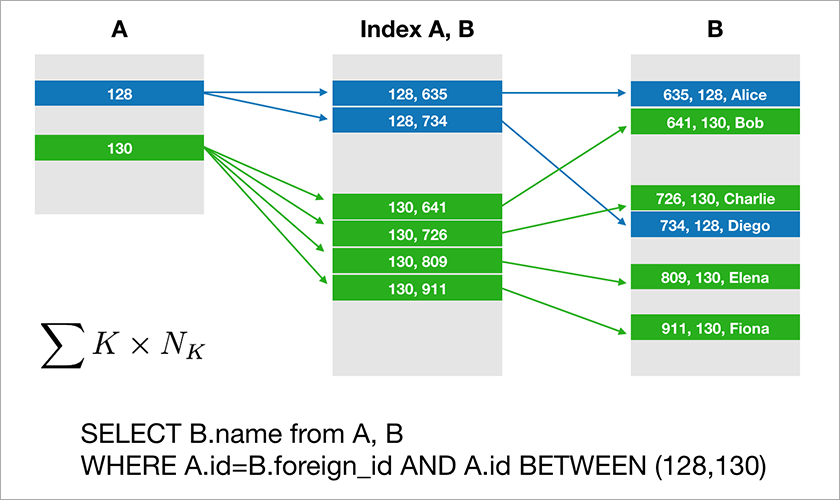
Angenommen, A.id ist ein Primärschlüssel mit einem Clustered-Index. Anschließend erstellt der Optimierer einen Plan, der höchstwahrscheinlich zuerst die erforderlichen Datensätze aus Tabelle A auswählt und dann die entsprechenden Links zu den Datensätzen in Tabelle B aus einem geeigneten Index (A, B) entnimmt. Die Ausführungszeit dieser Abfrage wächst logarithmisch aus der Anzahl der Datensätze in den Tabellen.
Stellen Sie sich nun vor, dass die Daten auf vier Server im Cluster verteilt sind und Sie dieselbe Abfrage ausführen müssen:
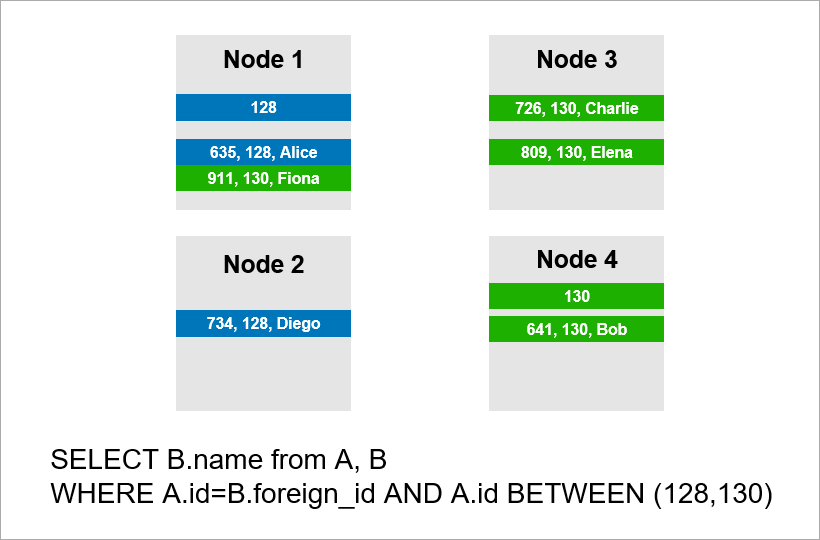
Wenn das DBMS nicht alle Datensätze des gesamten Clusters anzeigen möchte, wird es wahrscheinlich versuchen, Datensätze mit einer A.id von 128, 129 oder 130 zu finden und die entsprechenden Datensätze aus Tabelle B zu finden. Wenn A.id jedoch kein Shard-Schlüssel ist, wird das DBMS im Voraus ausgeführt Ich kann nicht wissen, auf welchem Server sich die Daten von Tabelle A befinden. Ich muss mich trotzdem an alle Server wenden, um herauszufinden, ob für unseren Zustand geeignete A.id-Datensätze vorhanden sind. Dann kann jeder Server einen JOIN in sich selbst erstellen, aber das reicht nicht aus. Sie sehen, wir brauchen den Datensatz auf Knoten 2 im Beispiel, aber es gibt keinen Datensatz mit A.id = 128? Wenn die Knoten 1 und 2 unabhängig voneinander JOIN ausführen, ist das Abfrageergebnis unvollständig - wir erhalten keinen Teil der Daten.
Um diese Anforderung zu erfüllen, muss sich jeder Server an alle anderen wenden. Die Laufzeit wächst quadratisch mit der Anzahl der Server. (Sie haben Glück, wenn Sie alle Tabellen mit demselben Schlüssel sharden können, müssen Sie nicht alle Server umgehen. In der Praxis ist dies jedoch unrealistisch. Es wird immer Abfragen geben, bei denen das Abrufen nicht auf dem Shard-Schlüssel basiert.)
Daher sind JOIN-Operationen grundsätzlich schlecht skalierbar, und dies ist ein grundlegendes Problem des relationalen Ansatzes.
NoSQL-Ansatz
Schwierigkeiten bei der Skalierung klassischer DBMS haben dazu geführt, dass Benutzer NoSQL-Datenbanken ohne JOIN-Operationen entwickelt haben. Keine Joins - kein Problem. Es gibt jedoch keine ACID-Eigenschaften, die jedoch in Marketingmaterialien nicht erwähnt wurden. Schnell
gefundene Handwerker, die die Stärke verschiedener verteilter Systeme testen und
die Ergebnisse öffentlich veröffentlichen . Es stellte sich heraus, dass es Szenarien gibt, in denen der
Redis-Cluster 45% der gespeicherten Daten verliert, der RabbitMQ-Cluster - 35% der Nachrichten ,
MongoDB - 9% der Datensätze ,
Cassandra - bis zu 5% . Und wir sprechen
über den Verlust, nachdem der Cluster den Client über das erfolgreiche Speichern informiert hat. Normalerweise erwarten Sie von der gewählten Technologie ein höheres Maß an Zuverlässigkeit.
Google hat die
Spanner- Datenbank entwickelt, die weltweit tätig ist. Spanner garantiert ACID-Eigenschaften, Serialisierbarkeit und mehr. Sie verfügen über Atomuhren in Rechenzentren, die eine genaue Zeit liefern. Auf diese Weise können Sie eine globale Reihenfolge von Transaktionen erstellen, ohne Netzwerkpakete zwischen Kontinenten weiterleiten zu müssen. Die Idee von Spanner ist, dass es für Programmierer besser ist, mit Leistungsproblemen umzugehen, die bei einer großen Anzahl von Transaktionen auftreten, als mit dem Mangel an Transaktionen. Spanner ist jedoch eine geschlossene Technologie. Sie passt nicht zu Ihnen, wenn Sie aus irgendeinem Grund nicht von einem Anbieter abhängig sein möchten.
Die Eingeborenen von Google entwickelten ein Open-Source-Analogon von Spanner und nannten es CockroachDB ("Kakerlake" auf Englisch "Kakerlake", was die Überlebensfähigkeit der Datenbank symbolisieren sollte). On Habré
schrieb bereits über die Nichtverfügbarkeit des Produkts für die Produktion, da der Cluster Daten verlor. Wir haben uns für die neuere Version 2.0 entschieden und sind zu einem ähnlichen Ergebnis gekommen. Wir haben die Daten nicht verloren, aber einige der einfachsten Abfragen wurden unangemessen lange ausgeführt.
Infolgedessen gibt es heute relationale Datenbanken, die nur vertikal gut skaliert werden können, was teuer ist. Und es gibt NoSQL-Lösungen ohne Transaktionen und ohne ACID-Garantien (wenn Sie ACID möchten, schreiben Sie Krücken).
Wie erstelle ich geschäftskritische Anwendungen, bei denen Daten nicht auf einen Server passen? Neue Lösungen erscheinen auf dem Markt, und über eine davon -
FoundationDB - werden wir Ihnen im nächsten Artikel mehr erzählen.