
Hallo Habr! Mein Name ist Stanislav Semenov, ich arbeite an Technologien zum Extrahieren von Daten aus Dokumenten in R & D ABBYY. In diesem Artikel werde ich auf die grundlegenden Ansätze zur Verarbeitung von halbstrukturierten Dokumenten (Rechnungen, Geldeingänge usw.) eingehen, die wir kürzlich verwendet haben und die wir derzeit verwenden. Wir werden darüber sprechen, wie Methoden des maschinellen Lernens zur Lösung dieses Problems anwendbar sind.
Wir werden Rechnungen als Dokumente betrachten, weil In der Welt sind sie sehr verbreitet und in Bezug auf die Datenextraktion am gefragtesten. Die automatische Bearbeitung von Rechnungen ist übrigens eines der beliebtesten Szenarien bei unseren ausländischen Kunden. Mit Hilfe von ABBYY FlexiCapture
reduzierte die amerikanische PepsiCo Imaging-Technologie beispielsweise
die Zeit für die Verarbeitung von Rechnungen und die Anzahl der Fehler aufgrund der manuellen Eingabe, und der europäische Einzelhändler Sportina
begann, Daten von Konten
zweimal schneller in Buchhaltungssysteme
einzugeben .
Rechnungen sind Dokumente, die in der internationalen Geschäftspraxis verwendet werden und für das Geschäft von großer Bedeutung sind. Ähnlich wie bei einer Rechnung in Russland handelt es sich beispielsweise um einen Frachtbrief. Daten aus solchen Dokumenten fallen in verschiedene Buchhaltungssysteme, und Fehler dort sind, gelinde gesagt, nicht erwünscht.
Eine gewöhnliche Rechnung kann als ziemlich strukturiert betrachtet werden und enthält zwei Hauptklassen von Objekten:
- verschiedene Felder aus der Kopfzeile (Belegnummer, Datum, Absender, Empfänger, Gesamtsumme usw.),
- Tabellarische Daten sind eine Liste von Waren und Dienstleistungen (Menge, Preis, Beschreibung usw.).
So sieht es aus:
Jährlich werden Millionen von Arbeitsstunden für die Bearbeitung von Rechnungen aufgewendet. Und es ist sehr teuer. Nach verschiedenen Schätzungen kostet die Bearbeitung einer Papierrechnung für ein Unternehmen zwischen 10 und 40 US-Dollar, wobei ein wesentlicher Teil dieser Kosten manuelle Arbeit für die Eingabe und den Abgleich von Daten ist.
Es gibt Unternehmen, die monatlich Millionen von Rechnungen bearbeiten. Zu diesem Zweck beschäftigen sie Hunderte und manchmal Tausende von Menschen. Es ist leicht abzuschätzen, dass eine Steigerung der Erkennungsgenauigkeit oder der Datenextraktionseffizienz von nur 1% die Kosten großer Unternehmen jährlich um Hunderttausende und sogar Millionen Dollar senken kann.
Auf der anderen Seite gibt es eine katastrophale Menge an Dokumenten. Im Jahr 2017
schätzte Billentis
die Gesamtzahl der weltweit pro Jahr generierten Rechnungen auf 400 Milliarden. Von diesen waren nur etwa 10% elektronisch, und der Rest erfordert eine vollständig manuelle Eingabe oder eine intensive menschliche Beteiligung. Wenn Sie 400 Milliarden Dokumente auf Standard-A4-Papier drucken, sind es Tausende von Papierwagen pro Tag oder ein Stapel Papier, der jede Sekunde etwa eine menschliche Größe hat!
Ein paar Worte zur Entwicklung der Technologie

Viele Unternehmen entwickeln spezielle Software, die Dokumente erkennen und Daten daraus extrahieren kann. Die Qualität der Rechnungsverarbeitung ist jedoch immer noch nicht perfekt. "Was ist das Problem?" - Du fragst.
Es geht um eine Vielzahl von Rechnungen. Es gibt keine Standards für Rechnungen, und jedes Unternehmen kann seine eigene Version des Dokuments erstellen: Art, Struktur und Position der Felder.
Suchen Sie Felder nach Schlüsselwörtern
Die ersten Versuche, Daten zu extrahieren, bestanden darin, unter allen erkannten Wörtern spezielle Schlüsselwörter zu finden, wie z. B. Rechnungsnummer oder Summe, und dann in der kleinen Nachbarschaft dieser Wörter, beispielsweise rechts oder unten, die Bedeutungen selbst zu finden.
Position der Rechnungsnummer in verschiedenen Rechnungen (anklickbar):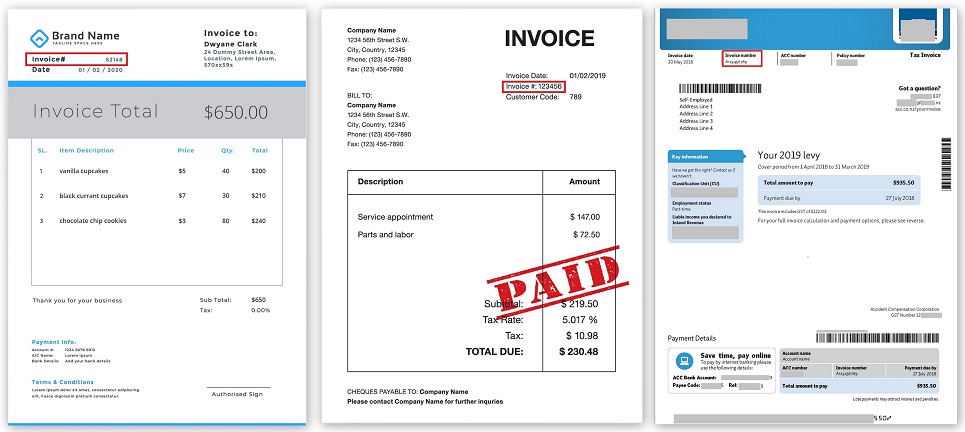
Die ganze Logik wurde so programmiert, dass es solche und solche Felder gibt, sie sich an solchen und solchen Stellen des Dokuments befinden, um sie herum gibt es andere Felder in einigen Entfernungen. Und das funktionierte irgendwie, bis eine andere Firma auftauchte, die begann, ihre Dokumente in einer völlig anderen Form zu versenden. Oder die vorherige Firma hat plötzlich das Format geändert und alles hat aufgehört zu funktionieren.
Muster
Dies zu bekämpfen, jedes Mal etwas neu zu programmieren, war irrational. Daher kam ein neues Paradigma zur Rettung - die Verwendung von Vorlagen.
Eine Vorlage besteht aus einer Reihe von Feldern, die in einem Dokument gefunden werden müssen, und einer Reihe von Regeln zum Auffinden dieser Felder. Der Hauptvorteil dabei ist, dass Vorlagen visuell erstellt werden. Zum Beispiel möchten wir nach Rechnungsnummer und Gesamtsumme suchen, diese Felder auswählen und die Parameter konfigurieren, dass ein und dasselbe Feld unmittelbar nach einem solchen und einem solchen Schlüsselwort kommt. Es befindet sich oben im Dokument und enthält Zahlen und Satzzeichen.
Es wurden spezielle Tools entwickelt, die sogenannten Template-Editoren, mit denen bereits fortgeschrittene Benutzer ohne die Hilfe von Programmierern schnell manuell eine Art Logik einstellen konnten. Sobald ein Dokument eines neuen Formulars eintraf, wurde eine Vorlage dafür erstellt und alles begann mehr oder weniger zu funktionieren.
Beispielvorlage (anklickbar):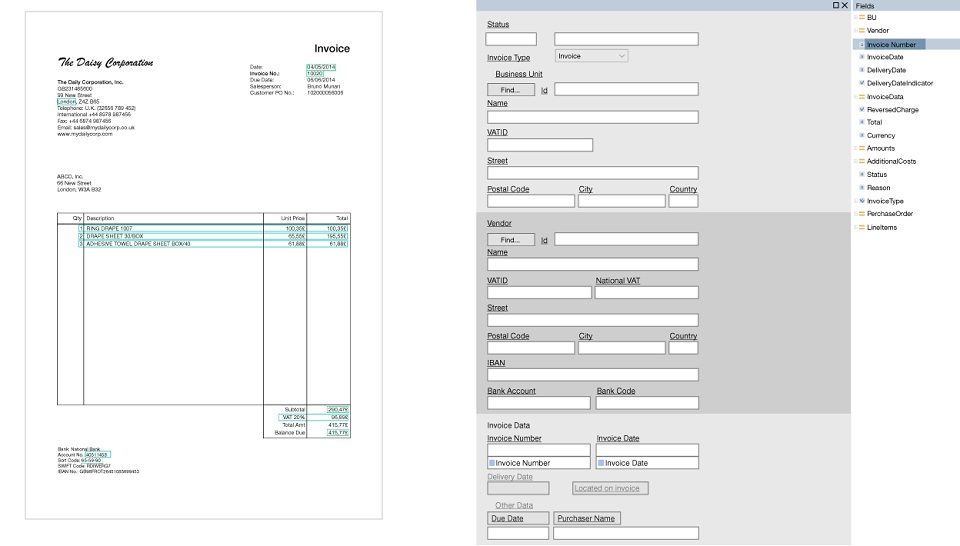
Aber um eine Vorlage zu erstellen, reicht es nicht aus, sie müssen zu Hunderten und sogar Tausenden erstellt werden. Daher kann das Einrichten eines Produkts für jeden Kunden manchmal viel Zeit in Anspruch nehmen. Es ist unmöglich, im Voraus „universelle“ Vorlagen zu erstellen, die die gesamte Vielfalt der Rechnungen abdecken.
Mithilfe von Vorlagen können Sie die Qualität des Tabellenabrufs erheblich verbessern. Oft werden jedoch komplexe Tabellenstrukturen mit nicht standardmäßiger Datendarstellung, mehreren Verschachtelungsebenen gefunden, und Vorlagen sind in diesen Fällen nicht immer gut. Sie müssen also wieder einige Skripte schreiben, die viele manuell ausgewählte Parameter, Bedingungen, Ausnahmen usw. enthalten.
Maschinelles Lernen verwenden
Die heutige Technologie steht nicht still und mit der Entwicklung des maschinellen Lernens wurde es möglich, die Aufgabe des Extrahierens von Daten aus Dokumenten in neuronale Netze zu übertragen.
Heutzutage gibt es mehrere grundlegende Ansätze, die in der Praxis verwendet werden:
- Der erste Ansatz besteht darin, direkt mit dem Eingabebild des Dokuments zu arbeiten. Das heißt, ein Bild (Bild) oder Fragment wird dem Netzwerkeingang zugeführt, und das Netzwerk lernt, kleine Bereiche zu finden, in denen sich die erforderlichen Felder befinden. Anschließend wird der Text in diesen Bereichen mithilfe der klassischen OCR-Technologie (Optical Character Recognition) erkannt. Dies ist eine End-to-End-Lösung, die schnell implementiert werden kann. Sie können ein vorgefertigtes Netzwerk für die Suche nach Objekten in Bildern verwenden, z. B. YOLO oder Faster R-CNN, und es in markierten Bildern von Dokumenten trainieren.
Der Nachteil dieses Ansatzes ist nicht die beste Qualität der extrahierten Daten und die Schwierigkeit, Tabellen zu extrahieren. Tatsächlich ähnelt dieser Ansatz in gewisser Weise der Aufgabe, die richtigen Wörter im Bild zu finden (Worterkennung), ein grundlegendes Problem aus dem Bereich der Bildverarbeitung, aber hier suchen wir nicht nach Wörtern, sondern nach den erforderlichen Feldern. - Der zweite Ansatz besteht darin, den aus dem Dokument extrahierten Text zu verarbeiten. Dies kann entweder Text aus einer PDF-Datei oder ein ganzseitiges OCR-Dokument sein. Es verwendet die NLP- Technologie (Natural Language Processing) . Zeilen werden aus einzelnen Wörtern zusammengesetzt, verschiedene Textfragmente, Absätze oder Spalten werden aus Zeilen gebildet, und in ihnen lernt das Netzwerk bereits, verschiedene benannte Entitäten NER (Named-Entity Recognition) zu unterscheiden.
Es gibt verschiedene Möglichkeiten, Textfragmente zu bilden. Sie können den ersten und den zweiten Ansatz kombinieren, ein Netzwerk trainieren, um große Blöcke mit bestimmten Informationen in den Bildern zu finden, z. B. Daten über den Absender oder Daten über den Empfänger, die sofort den Namen, die Adresse, Details usw. enthalten, und dann den Text jedes solchen Blocks übertragen zum zweiten NER-Netzwerk.
Die Qualität dieses Ansatzes mag sich als höher herausstellen als nur beim ersten Ansatz, aber es ist ziemlich schwierig, ein effektives Modell zu erstellen. Heutzutage gibt es ziemlich fortgeschrittene Modelle, zum Beispiel LSTM-CRF für NER, mit denen Wörter im Text markiert und Entitäten definiert werden können. - Der dritte Ansatz besteht darin, eine semantische Darstellung des Dokuments ohne Bezugnahme auf den Dokumenttyp zu erstellen, d. H. wenn wir nicht wissen, was das Dokument vor uns liegt, aber wir versuchen, es während der Verarbeitung zu verstehen. Ein Satz von Dokumentwörtern mit ihren verschiedenen Attributen (enthält das Wort beispielsweise nur Buchstaben oder ist es eine Zahl), die geometrische Anordnung von Wörtern (Koordinaten, Einrückungen) und mit verschiedenen Begrenzern und Verbindungen, die während der Bildanalyse identifiziert wurden, wird der Netzwerkeingabe zugeführt und die Ausgabe wird für erhalten Jedes Wort hat seine eigenen spezifischen Merkmale. Basierend auf den erhaltenen Merkmalen werden verschiedene Sätze von Hypothesen möglicher Felder oder Tabellen gebildet, die durch einen zusätzlichen Klassifizierer weiter sortiert und bewertet werden. Dann wird die zuverlässigste Hypothese der Struktur und des Inhalts des Dokuments ausgewählt.
Dies ist technisch bereits die schwierigste Lösung, aber Sie können das Problem des Extrahierens von Daten aus Dokumenten auf allgemeine Weise lösen.
Wie nutzen wir neuronale Netze?
Wir bei ABBYY überwachen nicht nur die Errungenschaften von Wissenschaft und Technologie genau, sondern entwickeln auch unsere eigenen fortschrittlichen Technologien und implementieren sie in verschiedene Produkte.
Die folgende Abbildung zeigt die allgemeine Architektur unserer Lösung unter Verwendung neuronaler Netze.
Klickbares Bild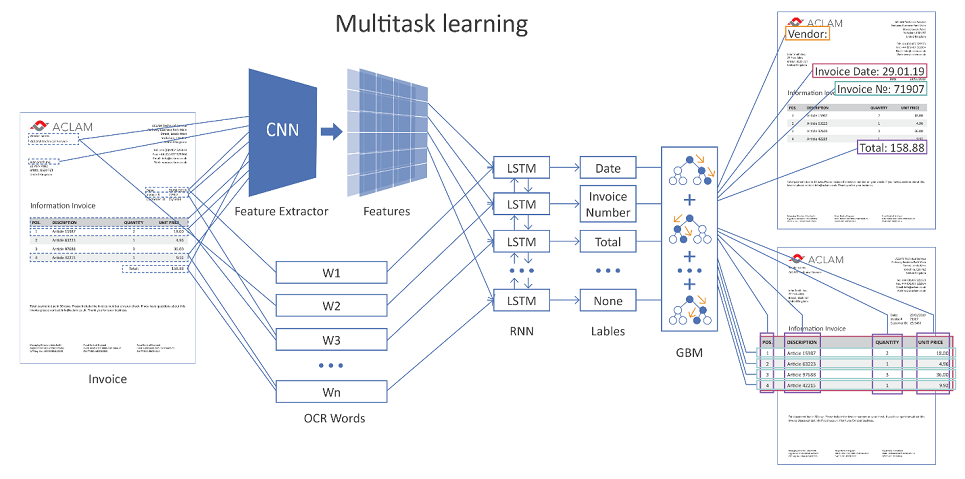
Die gesamte Dokumentseite wird dem Netzwerkeingang zugeführt. Unter Verwendung von Faltungsschichten (CNN) werden verschiedene geometrische Merkmale gebildet, beispielsweise die relative Position von Wörtern relativ zueinander. Ferner werden diese Zeichen mit der Vektordarstellung erkannter Wörter (Worteinbettungen) kombiniert und auf wiederkehrenden (LSTM) und vollständig verbundenen Schichten bereitgestellt. Es gibt verschiedene Ausgabeebenen (Multitasking-Lernen), wobei jede Ausgabe ihr eigenes Problem löst:
- Bestimmung der Art des Feldes, dem das Wort entsprechen kann,
- Hypothesen von Tabellengrenzen,
- Hypothesen von Tabellenzeilen, Spaltengrenzen usw.
Wenn das Dokument mehrseitig ist, macht das Netzwerk seine Vorhersage für jede einzelne Seite, dann werden die Ergebnisse kombiniert.
Als nächstes werden Hypothesen über die mögliche Anordnung von Feldern und Tabellen mit Hilfe einer separat trainierten Regressionsfunktion gebildet, sie werden bewertet und die sicherste Hypothese gewinnt.
Um die Genauigkeit der Datenextraktion zu erhöhen, erfolgt zusätzlich zur Trennung der Dokumente nach Typ (Scheck, Rechnung, Vertrag usw.) eine zusätzliche Clusterbildung innerhalb des Typs nach zusätzlichen Merkmalen.
Bei Rechnungen kann es sich beispielsweise um einen Lieferanten oder nur um ein Erscheinungsbild handeln (je nach Ähnlichkeitsgrad der Position der Felder). Und dann werden abhängig von einer bestimmten Gruppe (Cluster) bestimmte Algorithmuseinstellungen angewendet. Technisch gesehen ist es auf der Benutzerseite möglich, anhand von Beispielen für korrekt markierte Rechnungen für verschiedene Gruppen die Mechanismen zur Bewertung und Auswahl der richtigen Hypothesen neu zu trainieren.
Um alle Arten von Parametern unserer Algorithmen und neuronalen Netze zu konfigurieren, verwenden wir die Differential-Evolution-Methode, die sich in der Praxis sehr gut bewährt hat.
Unsere Ergebnisse des maschinellen Lernens

- Die entwickelte Methode zum Extrahieren von Daten aus strukturierten Dokumenten mithilfe von maschinellem Lernen zeigt in vielen Fällen bessere Ergebnisse als programmierte Lösungen, die auf Heuristiken basieren. Der Qualitätsgewinn bei verschiedenen Metriken reicht von mehreren Einheiten bis zu zehn Prozent bei verschiedenen extrahierbaren Einheiten.
- Es gibt einen unbestreitbaren Vorteil gegenüber dem klassischen Ansatz - die Fähigkeit, das Netzwerk auf neue Daten umzuschulen. Bei einer Vielzahl von Dokumentenformen ist dies nun kein Problem, sondern eine Notwendigkeit. Je mehr von ihnen, desto besser; Je stärker die Fähigkeit des Netzwerks zur Verallgemeinerung ist und je höher die Qualität.
- Es gab die Möglichkeit, die sogenannte Lösung "out of the box" freizugeben, wenn der Benutzer das Produkt (tatsächlich ein geschultes Netzwerk) einfach installiert und alles sofort mit einem akzeptablen Ergebnis arbeitet. Sie müssen nichts programmieren, die Vorlagen lange und schmerzhaft anpassen und alle Arten von Parametern auswählen.
Ein wichtiges Detail, das ich auch erwähnen möchte, sind Daten. Ohne Qualitätsdaten kann kein maschinelles Lernen stattfinden. Maschinelles Lernen liefert nur dann bessere Ergebnisse als Knowledge Engineering, wenn eine ausreichende Menge an markierten Daten vorhanden ist. Bei Rechnungen handelt es sich um Zehntausende von manuell beschrifteten Dokumenten, und diese Zahl wächst ständig.
Darüber hinaus verwenden wir erweiterte Datenerweiterungsmechanismen, ändern die Namen von Organisationen, Adressen, Warenlisten und Arten von Dienstleistungen in Tabellen, Daten, verschiedenen quantitativen Merkmalen wie Preis, Menge, Kosten usw. Wir ändern auch die Reihenfolge verschiedener Entitäten in Dokumenten, wodurch wir letztendlich Millionen völlig unterschiedlicher Dokumente für die Schulung generieren können.
Anstelle einer Schlussfolgerung
Zusammenfassend können wir sagen, dass die Programmierung natürlich nicht verschwunden ist, sondern ihre Rolle allmählich ändert. Mit jedem neuen Tag beginnt das maschinelle Lernen, die ihm zugewiesenen Aufgaben in einer Vielzahl von Branchen immer besser zu bewältigen, und verdrängt klassische Ansätze. Der unbestreitbare Vorteil des maschinellen Lernens in Bezug auf Effizienz: Dutzende von Mannjahren intellektueller Arbeit kosten jetzt Dutzende von maschinellen Lernstunden. Daher sehen wir in naher Zukunft eine noch stärkere Entwicklung und Anwendbarkeit von Netzwerken in all unseren Entwicklungen. Und wenn Sie interessiert sind, sind wir immer offen für Vorschläge und
Zusammenarbeit .