Hallo Habr!
Viele regelmäßige Leser und Autoren der Website haben wahrscheinlich über den Lebenszyklus der hier veröffentlichten Artikel nachgedacht. Und obwohl dies intuitiv mehr oder weniger klar ist (es ist zum Beispiel offensichtlich, dass der Artikel auf der ersten Seite die maximale Anzahl von Ansichten hat), aber wie viel konkret?
Um Statistiken zu sammeln, verwenden wir Python, Pandas, Matplotlib und Raspberry Pi.
Diejenigen, die daran interessiert sind, was daraus wurde, bitte unter Katze.
Datenerfassung
Lassen Sie uns zunächst die Metriken festlegen - was wir wissen wollen. Alles ist einfach, jeder Artikel hat 4 Hauptparameter, die auf der Seite angezeigt werden - dies ist die Anzahl der Ansichten, Likes, Lesezeichen und Kommentare. Wir werden sie analysieren.
Wer die Ergebnisse sofort sehen möchte, kann zum dritten Teil übergehen, aber im Moment geht es um die Programmierung.
Allgemeiner Plan: Wir analysieren die erforderlichen Daten von der Webseite, speichern sie mit CSV und sehen, was wir für einen Zeitraum von mehreren Tagen erhalten. Laden Sie zunächst den Text des Artikels (aus Gründen der Übersichtlichkeit wurde die Ausnahmebehandlung weggelassen):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
Jetzt müssen wir Daten aus der Zeile data_str extrahieren (natürlich in HTML). Öffnen Sie den Quellcode im Browser (nicht prinzipielle Elemente entfernt):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
Es ist leicht zu erkennen, dass sich der benötigte Text innerhalb des Blocks '<ul class = "post-stats post-stats_post js-user_>' befindet und die erforderlichen Elemente in Blöcken mit den Namen abstimmen-wjt__counter, bookmark__counter, post-stats__views-count und post- stehen stats__comments-count. Beim Namen ist alles ganz offensichtlich.
Wir werden die Klasse str erben und die Methode zum Extrahieren der Teilzeichenfolge zwischen den beiden Tags hinzufügen:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
Sie könnten auf Vererbung verzichten, aber dies ermöglicht es Ihnen, präziseren Code zu schreiben. Damit passt die gesamte Datenextraktion in 4 Zeilen:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Das ist aber noch nicht alles. Wie Sie sehen können, kann die Anzahl der Kommentare oder Ansichten als Zeichenfolge wie "12.1k" gespeichert werden, die nicht direkt in int übersetzt wird.
Fügen Sie eine Funktion hinzu, um eine solche Zeichenfolge in eine Zahl umzuwandeln:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
Es bleibt nur noch Zeitstempel hinzuzufügen, und Sie können die Daten in csv speichern:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Da wir an der Analyse mehrerer Artikel interessiert sind, können wir einen Link über die Befehlszeile angeben. Wir werden auch den Namen der Protokolldatei anhand der Artikel-ID generieren:
link = sys.argv[1]
Und der allerletzte Schritt. Wir nehmen den Code in der Funktion heraus, fragen in der Schleife die Daten ab und schreiben die Ergebnisse in das Protokoll.
delay_s = 5*60 while True:
Wie Sie sehen, wurden die Daten alle 5 Minuten aktualisiert, um den Server nicht zu belasten. Ich habe die Programmdatei unter dem Namen habr_parse.py gespeichert. Beim Start werden Daten gespeichert, bis das Programm geschlossen wird.
Außerdem ist es ratsam, die Daten mindestens einige Tage lang zu speichern. Weil Wir zögern, den Computer mehrere Tage lang eingeschaltet zu lassen. Wir nehmen den Raspberry Pi - er hat genug Strom für eine solche Aufgabe, und im Gegensatz zu einem PC macht der Raspberry Pi keine Geräusche und verbraucht fast keinen Strom. Wir gehen über SSH und führen unser Skript aus:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
Der Befehl nohup lässt das Skript nach dem Schließen der Konsole im Hintergrund.
Als Bonus können Sie einen http-Server im Hintergrund ausführen, indem Sie den Befehl "nuhup python -m SimpleHTTPServer 8000 &" eingeben. Auf diese Weise können Sie die Ergebnisse jederzeit direkt im Browser anzeigen und einen Link des Formulars
http://192.168.1.101:8000 öffnen (die Adresse kann natürlich abweichen).
Jetzt können Sie den Raspberry Pi eingeschaltet lassen und in wenigen Tagen zum Projekt zurückkehren.
Datenanalyse
Wenn alles richtig gemacht wurde, sollte die Ausgabe ungefähr so aussehen wie dieses Protokoll:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Mal sehen, wie es verarbeitet werden kann. Laden Sie zunächst csv in einen Pandas-Datenrahmen:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Fügen Sie Funktionen für die Konvertierung und Mittelwertbildung hinzu und extrahieren Sie die erforderlichen Daten:
def to_float(s):
Eine Mittelwertbildung ist erforderlich, da die Anzahl der Ansichten auf der Site in Schritten von 100 angezeigt wird, was zu einem "zerrissenen" Zeitplan führt. Im Prinzip ist dies nicht notwendig, aber mit der Mittelung sieht es besser aus. Die Moskauer Zeitzone wird ebenfalls in den Code aufgenommen (die Zeit auf dem Raspberry Pi stellte sich als GMT heraus).
Schließlich können Sie die Grafiken anzeigen und sehen, was passiert ist.
import matplotlib.pyplot as plt
Ergebnisse
Am Anfang jedes Diagramms befindet sich ein leerer Bereich, der einfach erklärt wird. Beim Start des Skripts wurden die Artikel bereits veröffentlicht, sodass die Daten nicht von Grund auf neu erfasst wurden. Der Nullpunkt wurde manuell aus der Beschreibung der Veröffentlichungszeit des Artikels hinzugefügt.
Alle angelegten Diagramme werden von matplotlib und dem obigen Code generiert.
Entsprechend den Ergebnissen habe ich die untersuchten Artikel in 3 Gruppen eingeteilt. Die Aufteilung ist bedingt, obwohl sie noch einen Sinn hat.
Heißer Artikel
In diesem Artikel geht es um ein beliebtes und relevantes Thema mit einem Titel wie „Wie MTS Geld abzieht“ oder „Roskomnadzor blockiert Pornogit Hub“.
Solche Artikel haben eine große Anzahl von Ansichten und Kommentaren, aber der "Hype" dauert maximal mehrere Tage. Sie können auch einen leichten Unterschied in der Zunahme der Anzahl der Ansichten während des Tages und der Nacht feststellen (aber nicht so signifikant wie erwartet - anscheinend wird Habr aus fast allen Zeitzonen gelesen).
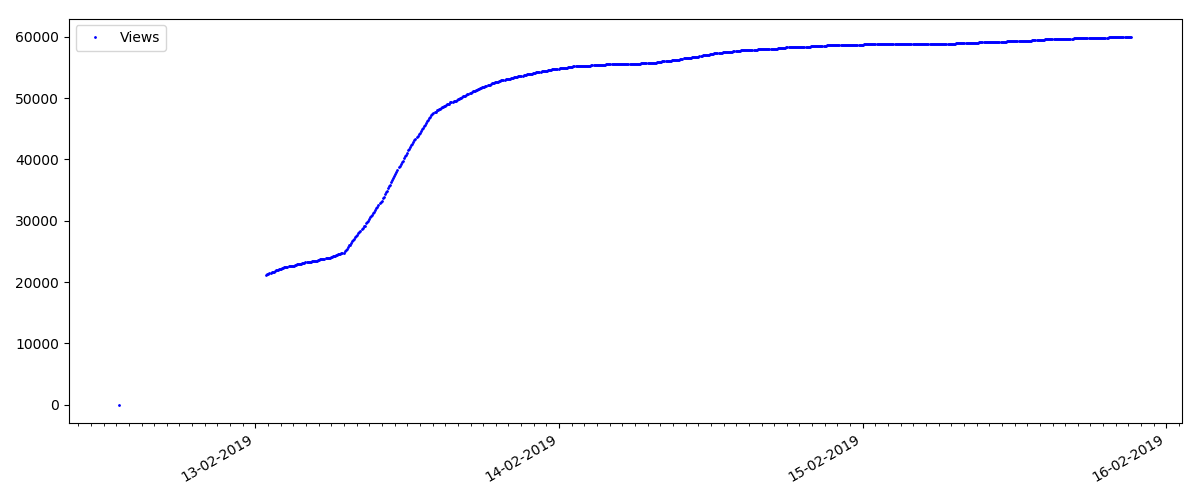
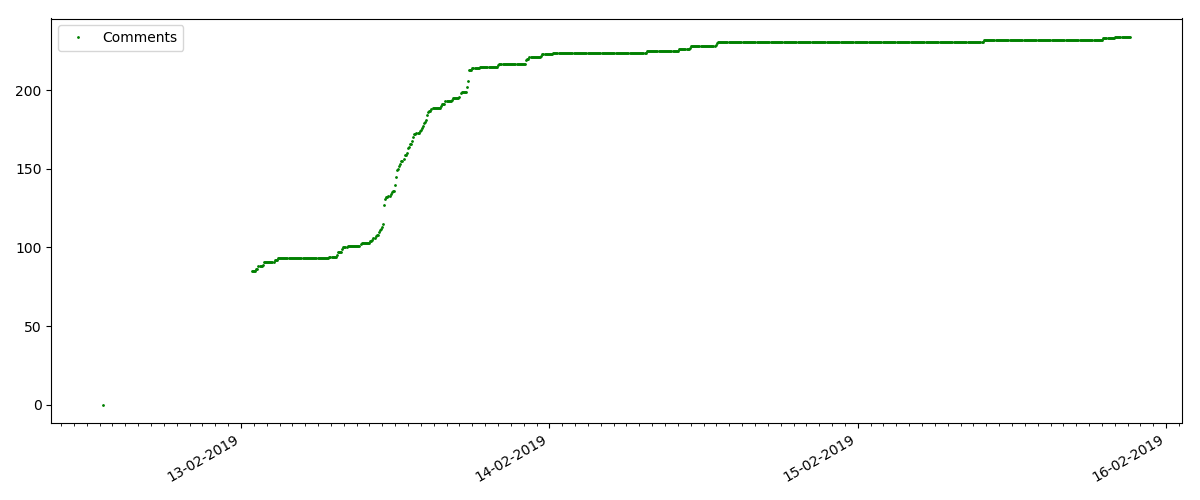
Die Anzahl der "Likes" nimmt erheblich zu, während die Anzahl der Lesezeichen spürbar langsamer zunimmt. Das ist logisch, weil Jemand mag den Artikel vielleicht, aber die Spezifität des Textes ist so, dass er einfach nicht benötigt wird, um ihn mit einem Lesezeichen zu versehen.
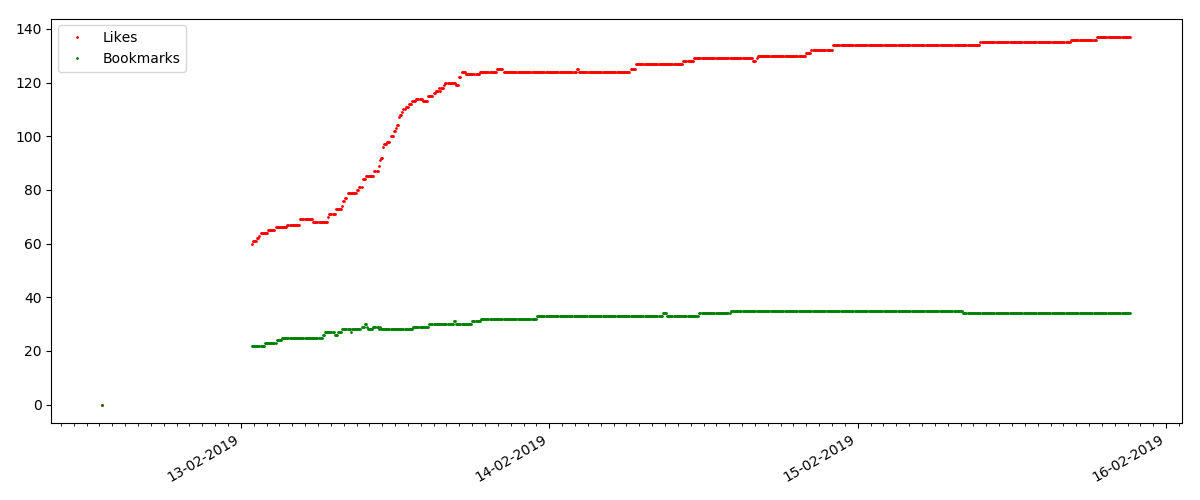
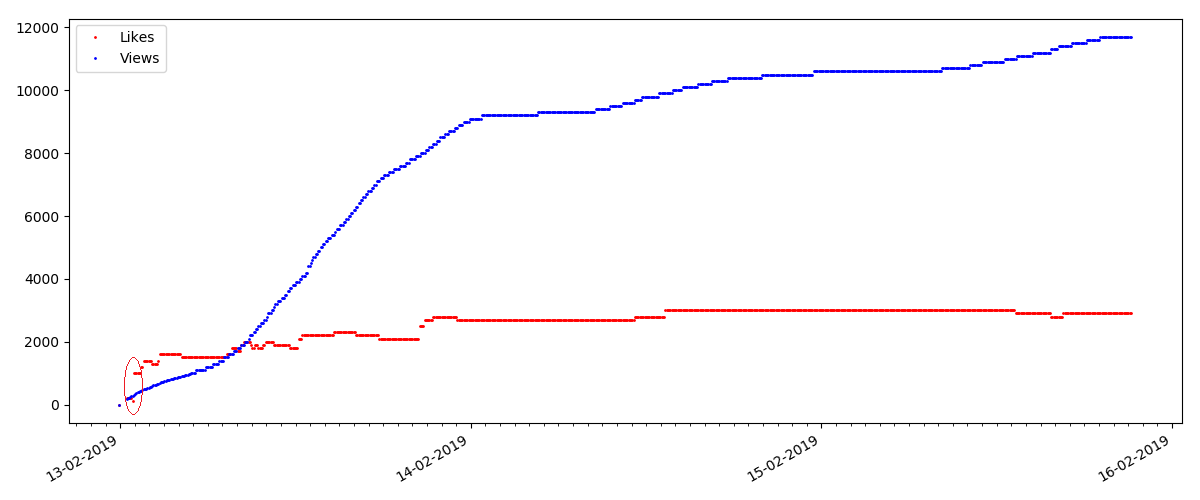
Das Verhältnis von Ansichten und Likes bleibt ungefähr gleich und beträgt ungefähr 400: 1:
"Technischer" Artikel
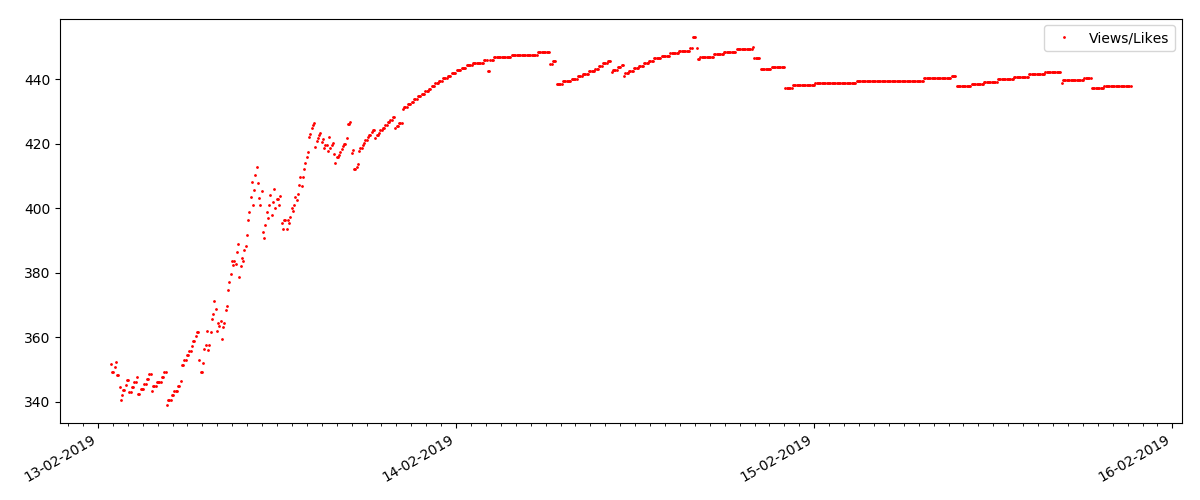
Dies ist ein speziellerer Artikel, z. B. "Einrichten von Skripten für Node JS". Ein solcher Artikel erhält natürlich um ein Vielfaches weniger Aufrufe als der „heiße“, die Anzahl der Kommentare ist auch merklich geringer (in diesem Fall waren es nur 4).
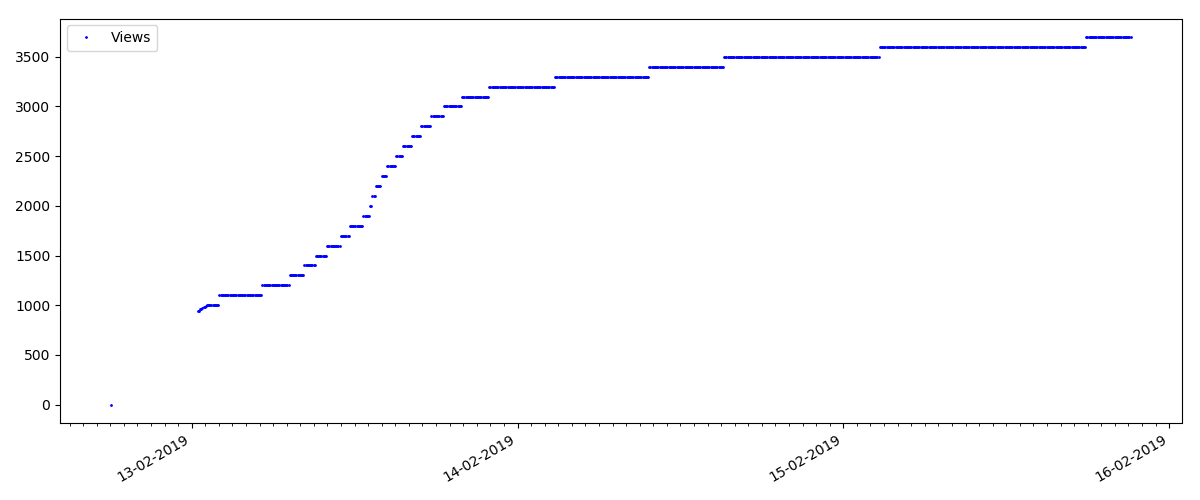
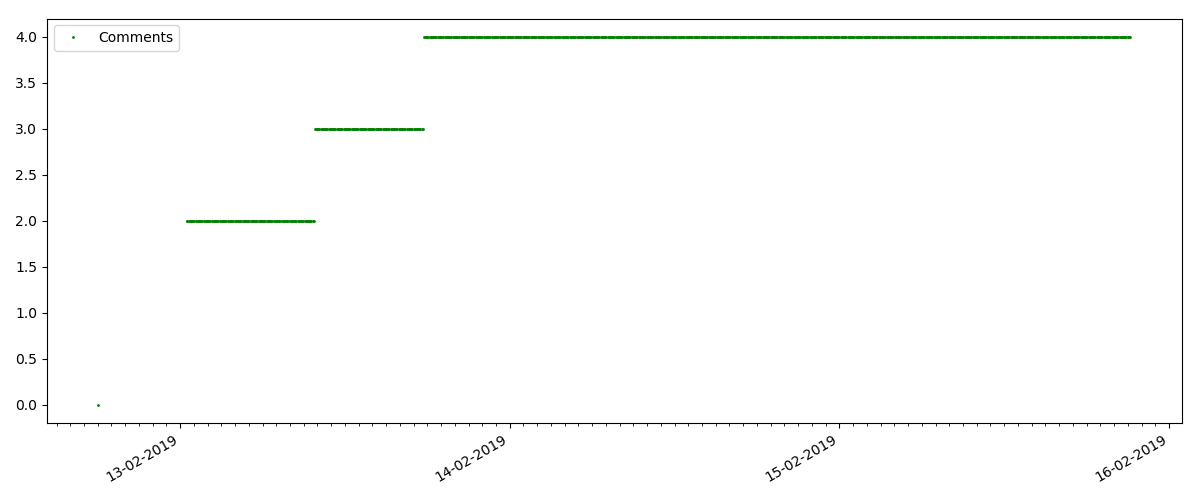
Der nächste Punkt ist jedoch interessanter: Die Anzahl der "Likes" für solche Artikel wächst merklich langsamer als die Anzahl der "Lesezeichen". Hier ist es umgekehrt im Vergleich zur vorherigen Version - viele finden den Artikel nützlich, um ihn für die Zukunft zu speichern, aber der Leser muss überhaupt nicht auf "Gefällt mir" klicken.
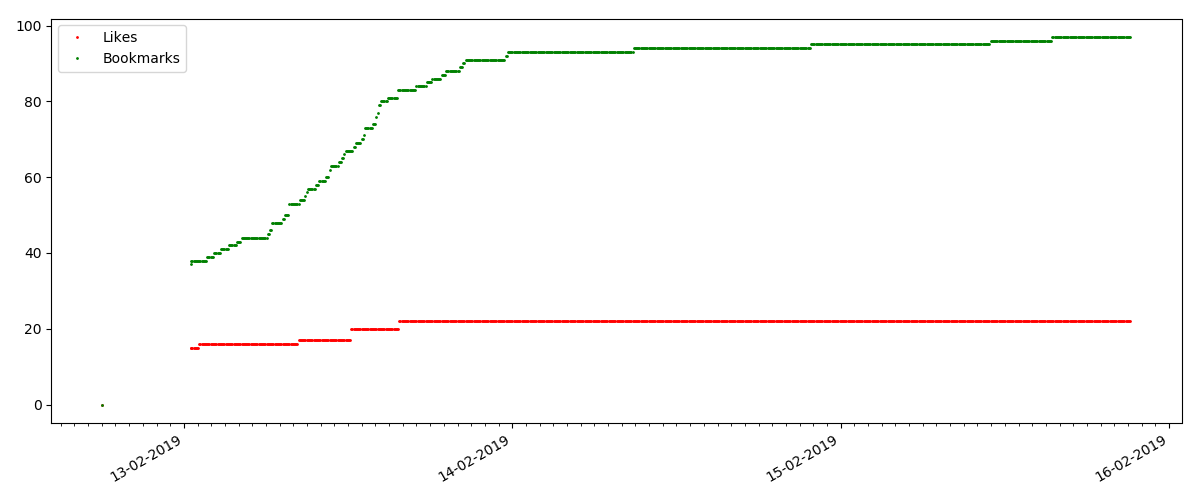
Übrigens möchte ich an dieser Stelle die Aufmerksamkeit der Site-Administratoren auf sich ziehen - bei der Berechnung von Artikelbewertungen sollten Sie Lesezeichen parallel zu Likes zählen (z. B. Kombinieren von Sets nach ODER). Andernfalls führt dies zu einer Verzerrung der Bewertung, wenn ein bekannter Artikel viele Lesezeichen enthält (dh den Lesern hat es definitiv gefallen), diese Personen jedoch vergessen haben oder zu faul waren, um auf „Gefällt mir“ zu klicken.
Und schließlich das Verhältnis von Ansichten und Likes: Sie können sehen, dass es merklich höher als in der ersten Ausführungsform ist und ungefähr 150: 1 beträgt, d. H. Die Qualität des Inhalts kann auch indirekt als höher angesehen werden.
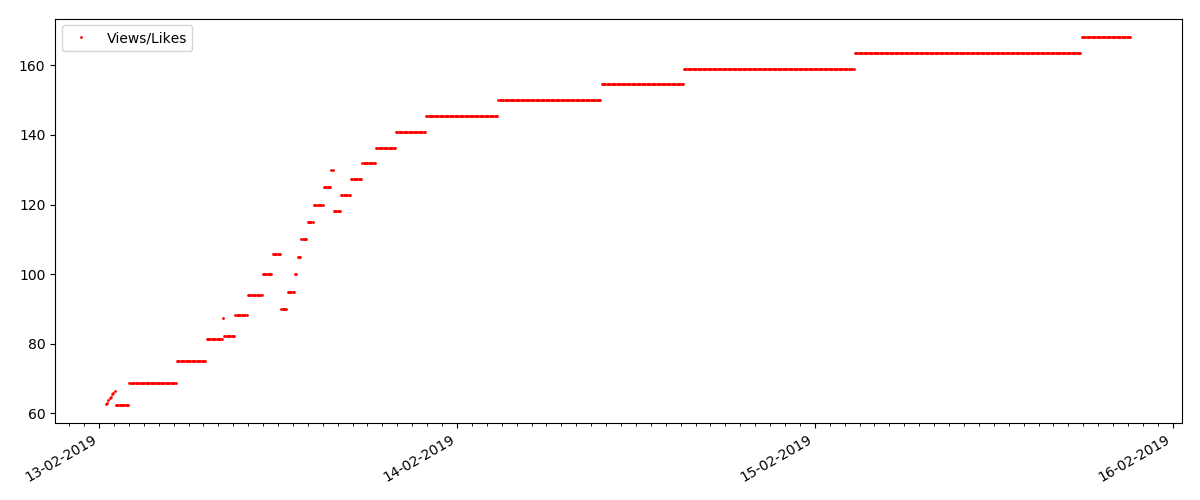
"Verdächtiger" Artikel (aber das ist nicht korrekt)
Für den nächsten untersuchten Artikel erhöhte sich die Anzahl der "Likes" in einem 5-Minuten-Intervall um ein Drittel (sofort um 10, wobei insgesamt 30 für alle Tage erzielt wurden).
Man könnte einen Betrug vermuten, aber die "Warteschlangentheorie" erlaubt im Prinzip solche Spannungsspitzen. Oder vielleicht hat der Autor den Link einfach an alle seine 10 Freunde gesendet, was natürlich nicht durch die Regeln verboten ist.
Schlussfolgerungen
Die Hauptschlussfolgerung ist, dass alles Verfall und Maya ist. Selbst das beliebteste Material, das Tausende von Ansichten erhält, wird in nur 3-4 Tagen "in der Vergangenheit" sein. Dies sind leider die Besonderheiten des modernen Internets und wahrscheinlich der gesamten modernen Medienbranche insgesamt. Und ich bin sicher, dass die gezeigten Zahlen nicht nur für Habr, sondern auch für ähnliche Internetquellen spezifisch sind.
Andernfalls handelt es sich bei dieser Analyse eher um „Freitag“, und sie gibt natürlich nicht vor, eine ernsthafte Studie zu sein. Ich hoffe auch, dass jemand etwas Neues in der Verwendung von Pandas und Matplotlib gefunden hat.
Vielen Dank für Ihre Aufmerksamkeit.