Hallo Habr! In diesem Beitrag werden wir eine Anwendung auf Spring Boot 2 unter Verwendung von Apache Kafka unter Linux schreiben, von der Installation der JRE bis zu einer funktionierenden Microservice-Anwendung.
Kollegen aus der Front-End-Entwicklungsabteilung, die den Artikel gesehen haben, beklagen, dass ich nicht erkläre, was Apache Kafka und Spring Boot sind. Ich glaube, dass jeder, der ein fertiges Projekt mit den oben genannten Technologien zusammenstellen muss, weiß, was es ist und warum er es braucht. Wenn für den Leser die Frage nicht untätig ist, hier sind ausgezeichnete Artikel über Habr, was
Apache Kafka und
Spring Boot sind .
Wir können auf langwierige Erklärungen zu Kafka, Spring Boot und Linux verzichten und stattdessen den Kafka-Server auf einem Linux-Computer von Grund auf neu ausführen, zwei Microservices schreiben und einen von ihnen Nachrichten an den anderen senden lassen - im Allgemeinen konfigurieren vollständige Microservice-Architektur.

Der Beitrag besteht aus zwei Abschnitten. Im ersten konfigurieren und führen wir Apache Kafka auf einem Linux-Computer aus, im zweiten schreiben wir zwei Microservices in Java.
In dem Startup, in dem ich meine berufliche Laufbahn als Programmierer begann, gab es Microservices auf Kafka, und einer meiner Microservices arbeitete auch mit anderen über Kafka zusammen, aber ich wusste nicht, wie der Server selbst funktionierte, ob er als Anwendung geschrieben wurde oder bereits vollständig verpackt ist Produkt. Was war meine Überraschung und Enttäuschung, als sich herausstellte, dass Kafka immer noch ein Box-Produkt war und meine Aufgabe nicht nur darin bestand, einen Client in Java zu schreiben (was ich gerne mache), sondern die fertige Anwendung als devOps bereitzustellen (was ich auch tue) hasse es zu tun). Selbst wenn ich es in weniger als einem Tag auf dem virtuellen Kafka-Server hochfahren könnte, ist dies wirklich recht einfach. Also.
Unsere Anwendung hat die folgende Interaktionsstruktur:
Am Ende des Beitrags gibt es wie üblich Links zu Git mit Arbeitscode.
Stellen Sie Apache Kafka + Zookeeper auf einer virtuellen Maschine bereit
Ich habe versucht, Kafka unter lokalem Linux, auf einer Mohnblume und unter Remote-Linux zu starten. In zwei Fällen (Linux) gelang es mir recht schnell. Mit Mohn ist noch nichts passiert. Deshalb werden wir Kafka unter Linux erhöhen. Ich habe Ubuntu 18.04 gewählt.
Damit Kafka arbeiten kann, braucht sie einen Tierpfleger. Dazu müssen Sie es herunterladen und ausführen, bevor Sie Kafka starten.
Also.
0. Installieren Sie JRE
Dies erfolgt mit den folgenden Befehlen:
sudo apt-get update sudo apt-get install default-jre
Wenn alles in Ordnung war, können Sie den Befehl eingeben
java -version
und stellen Sie sicher, dass Java installiert ist.
1. Laden Sie Zookeeper herunter
Ich mag keine magischen Teams unter Linux, besonders wenn sie nur ein paar Befehle geben und nicht klar ist, was sie tun. Deshalb werde ich jede Aktion beschreiben - was genau sie tut. Wir müssen also Zookeeper herunterladen und in einen praktischen Ordner entpacken. Es ist ratsam, wenn alle Anwendungen im Ordner / opt gespeichert sind, in unserem Fall also / opt / zookeeper.
Ich habe den folgenden Befehl verwendet. Wenn Sie andere Linux-Befehle kennen, mit denen Sie dies Ihrer Meinung nach rassistisch korrekter ausführen können, verwenden Sie sie. Ich bin ein Entwickler, kein Entwickler, und ich kommuniziere mit Servern auf der Ebene der "Ziege selbst". Laden Sie also die Anwendung herunter:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
Die Anwendung wird in den von Ihnen angegebenen Ordner heruntergeladen. Ich habe den Ordner / home / xpendence / downloads erstellt, um dort alle benötigten Anwendungen herunterzuladen.
2. Packen Sie Zookeeper aus
Ich habe den Befehl verwendet:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
Dieser Befehl entpackt das Archiv in den Ordner, in dem Sie sich befinden. Möglicherweise müssen Sie die Anwendung dann an / opt / zookeeper übertragen. Und Sie können sofort darauf zugreifen und von dort aus das Archiv bereits auspacken.
3. Bearbeiten Sie die Einstellungen
Im Ordner / zookeeper / conf / befindet sich eine Datei zoo-sample.cfg. Ich schlage vor, sie in zoo.conf umzubenennen. Diese Datei wird von der JVM beim Start gesucht. Folgendes sollte dieser Datei am Ende hinzugefügt werden:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
Erstellen Sie außerdem das Verzeichnis / var / zookeeper.
4. Starten Sie Zookeeper
Gehen Sie zum Ordner / opt / zookeeper und starten Sie den Server mit dem folgenden Befehl:
bin/zkServer.sh start
"STARTED" sollte erscheinen.
Danach schlage ich vor, zu überprüfen, ob der Server funktioniert. Wir schreiben:
telnet localhost 2181
Es sollte eine Meldung angezeigt werden, dass die Verbindung erfolgreich war. Wenn Sie einen schwachen Server haben und die Meldung nicht angezeigt wurde, versuchen Sie es erneut. Selbst wenn STARTED angezeigt wird, beginnt die Anwendung viel später, den Port abzuhören. Wenn ich das alles auf einem schwachen Server versuchte, passierte es mir jedes Mal. Wenn alles verbunden ist, geben Sie den Befehl ein
ruok
Was bedeutet es: "Geht es dir gut?" Der Server sollte antworten:
imok ( !)
und trennen. Also läuft alles nach Plan. Wir starten Apache Kafka.
5. Erstellen Sie einen Benutzer unter Kafka
Um mit Kafka arbeiten zu können, benötigen wir einen separaten Benutzer.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6. Laden Sie Apache Kafka herunter
Es gibt zwei Verteilungen - Binär und Quellen. Wir brauchen eine Binärdatei. Das Archiv mit der Binärdatei ist unterschiedlich groß. Die Binärdatei wiegt 59 MB und 6,5 MB.
Laden Sie die Binärdatei über den folgenden Link in das dortige Verzeichnis herunter:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7. Packen Sie Apache Kafka aus
Das Auspacken unterscheidet sich nicht von dem für Zookeeper. Wir entpacken das Archiv auch in das Verzeichnis / opt und benennen es in kafka um, sodass der Pfad zum Ordner / bin / opt / kafka / bin lautet
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8. Bearbeiten Sie die Einstellungen
Die Einstellungen befinden sich in /opt/kafka/config/server.properties. Fügen Sie eine Zeile hinzu:
delete.topic.enable = true
Diese Einstellung scheint optional zu sein, sie funktioniert ohne sie. Mit dieser Einstellung können Sie Themen löschen. Andernfalls können Sie Themen einfach nicht über die Befehlszeile löschen.
9. Wir gewähren Zugriff auf die Benutzer-Kafka-Verzeichnisse Kafka
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10. Der lang erwartete Start von Apache Kafka
Wir geben den Befehl ein, nach dem Kafka starten soll:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Wenn die üblichen Aktionen (Kafka ist in Java und Scala geschrieben) nicht in das Protokoll übernommen wurden, hat alles funktioniert und Sie können unseren Service testen.
10.1. Schwache Serverprobleme
Für Experimente mit Apache Kafka habe ich einen schwachen Server mit einem Kern und 512 MB RAM (für nur 99 Rubel) verwendet, was sich für mich als mehrere Probleme herausstellte.
Nicht genügend Speicher. Natürlich können Sie nicht mit 512 MB übertakten, und der Server konnte Kafka aufgrund von Speichermangel nicht bereitstellen. Tatsache ist, dass Kafka standardmäßig 1 GB Speicher belegt. Kein Wunder, dass er vermisst wurde :)
Wir gehen zu kafka-server-start.sh, zookeeper-server-start.sh. Es gibt bereits eine Zeile, die das Gedächtnis reguliert:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
Ändern Sie es in:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
Dies reduziert den Appetit von Kafka und ermöglicht es Ihnen, den Server zu starten.
Das zweite Problem mit einem schwachen Computer ist der Zeitmangel, um eine Verbindung zu Zookeeper herzustellen. Standardmäßig sind dies 6 Sekunden. Wenn das Eisen schwach ist, reicht dies natürlich nicht aus. In server.properties erhöhen wir die Verbindungszeit zum zukipper:
zookeeper.connection.timeout.ms=30000
Ich habe eine halbe Minute eingestellt.
11. Testen Sie den Kafka-Server
Zu diesem Zweck werden wir zwei Terminals eröffnen, auf einem den Produzenten und auf dem anderen den Verbraucher.
Geben Sie in der ersten Konsole eine Zeile ein:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Dieses Symbol sollte angezeigt werden und zeigt an, dass der Produzent bereit ist, Spam-Nachrichten zu versenden:
>
Geben Sie in der zweiten Konsole den folgenden Befehl ein:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Wenn Sie nun in die Produzenten-Konsole eingeben und die Eingabetaste drücken, wird diese in der Consumer-Konsole angezeigt.
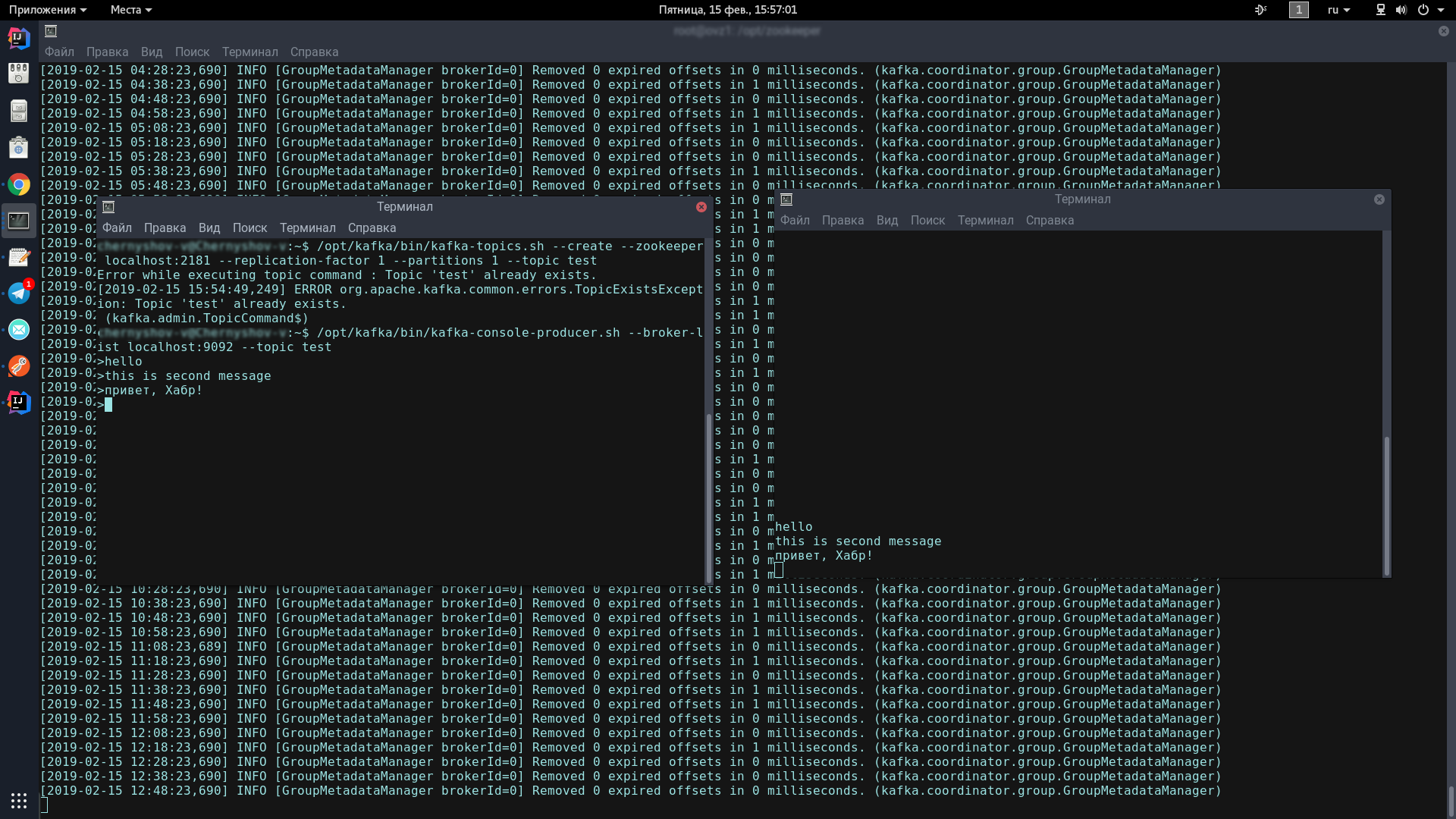
Wenn Sie auf dem Bildschirm ungefähr dasselbe sehen wie ich - herzlichen Glückwunsch, das Schlimmste ist vorbei!
Jetzt müssen wir nur noch ein paar Clients auf Spring Boot schreiben, die über Apache Kafka miteinander kommunizieren.
Schreiben einer Anwendung auf Spring Boot
Wir werden zwei Anwendungen schreiben, die Nachrichten über Apache Kafka austauschen. Die erste Nachricht heißt kafka-server und enthält sowohl den Produzenten als auch den Konsumenten. Der zweite wird als Kafka-Tester bezeichnet und ist so konzipiert, dass wir eine Microservice-Architektur haben.
Kafka-Server
Für unsere Projekte, die mit dem Spring Initializr erstellt wurden, benötigen wir das Kafka-Modul. Ich habe Lombok und Web hinzugefügt, aber das ist Geschmackssache.
Der Kafka-Client besteht aus zwei Komponenten - dem Produzenten (er sendet Nachrichten an den Kafka-Server) und dem Verbraucher (er hört auf den Kafka-Server und nimmt von dort neue Nachrichten zu den Themen entgegen, die er abonniert hat). Unsere Aufgabe ist es, beide Komponenten zu schreiben und zum Laufen zu bringen.
Verbraucher:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
Wir benötigen 2 Felder, die mit statischen Daten aus kafka.properties initialisiert wurden.
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server ist die Adresse, an der unser Server hängt, in diesem Fall lokal. Standardmäßig überwacht Kafka Port 9092.
kafka.group.id ist eine Gruppe von Verbrauchern, innerhalb derer eine Instanz der Nachricht zugestellt wird. Sie haben beispielsweise drei Kuriere in einer Gruppe, die alle dasselbe Thema hören. Sobald auf dem Server eine neue Nachricht mit diesem Thema angezeigt wird, wird sie an eine Person in der Gruppe gesendet. Die verbleibenden zwei Verbraucher erhalten die Nachricht nicht.
Als nächstes schaffen wir eine Fabrik für Verbraucher - ConsumerFactory.
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
Initialisiert mit den Eigenschaften, die wir benötigen, wird es in Zukunft als Standardfabrik für Verbraucher dienen.
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
ConsumerConfigs sind nur Map-Konfigurationen. Wir stellen die Serveradresse, Gruppe und Deserializer zur Verfügung.
Darüber hinaus einer der wichtigsten Punkte für einen Verbraucher. Der Verbraucher kann sowohl einzelne Objekte als auch Sammlungen empfangen, z. B. StarshipDto und List. Und wenn wir StarshipDto als JSON erhalten, erhalten wir List grob gesagt als JSON-Array. Daher haben wir mindestens zwei Nachrichtenfabriken - für einzelne Nachrichten und für Arrays.
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
Wir instanziieren ConcurrentKafkaListenerContainerFactory, geben Long (Nachrichtenschlüssel) und AbstractDto (abstrakter Nachrichtenwert) ein und initialisieren seine Felder mit Eigenschaften. Wir initialisieren die Factory natürlich mit unserer Standard-Factory (die bereits Map-Konfigurationen enthält), markieren dann, dass wir keine Pakete abhören (dieselben Arrays) und geben einen einfachen JSON-Konverter als Konverter an.
Wenn wir eine Factory für Pakete / Arrays (Batch) erstellen, besteht der Hauptunterschied (abgesehen von der Tatsache, dass wir markieren, dass wir Pakete abhören) darin, dass wir als Konverter einen speziellen Paketkonverter angeben, der Pakete konvertiert, die aus bestehen von JSON-Strings.
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
Und noch etwas. Bei der Initialisierung der Spring Beans wird der Bin unter dem Namen kafkaListenerContainerFactory möglicherweise nicht gezählt und die Anwendung wird ruiniert. Sicher gibt es elegantere Möglichkeiten, um das Problem zu lösen. Schreiben Sie darüber in den Kommentaren. Im Moment habe ich gerade einen Behälter mit Funktionen mit demselben Namen erstellt:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
Der Verbraucher ist eingerichtet. Wir gehen zum Produzenten.
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
Von den statischen Variablen benötigen wir die Adresse des Kafka-Servers und die Produzenten-ID. Er kann alles sein.
Wie wir sehen, gibt es in den Konfigurationen nichts Besonderes. Fast das Gleiche. In Bezug auf Fabriken gibt es jedoch einen signifikanten Unterschied. Wir müssen für jede Klasse eine Vorlage registrieren, deren Objekte wir an den Server senden, sowie eine Factory dafür. Wir haben ein solches Paar, aber es kann Dutzende von ihnen geben.
In der Vorlage markieren wir, dass wir Objekte in JSON serialisieren, und dies ist möglicherweise ausreichend.
Wir haben einen Verbraucher und einen Produzenten. Es bleibt ein Dienst zu schreiben, der Nachrichten sendet und empfängt.
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
Es gibt nur zwei Methoden in unserem Service, die ausreichen, um die Arbeit des Kunden zu erklären. Wir verdrahten automatisch die Muster, die wir brauchen:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
Erzeugermethode:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
Um eine Nachricht an den Server zu senden, müssen Sie lediglich die Sendemethode für die Vorlage aufrufen und das Thema (Betreff) und unser Objekt dorthin übertragen. Das Objekt wird in JSON serialisiert und fliegt unter dem angegebenen Thema zum Server.
Die Hörmethode sieht folgendermaßen aus:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
Wir kennzeichnen diese Methode mit der Annotation @KafkaListener, in der wir eine beliebige ID, abgehörte Themen und eine Factory angeben, die die empfangene Nachricht in das konvertiert, was wir benötigen. In diesem Fall benötigen wir eine einzelne Fabrik, da wir ein Objekt akzeptieren. Geben Sie für Liste <?> BatchFactory an. Infolgedessen senden wir das Objekt mithilfe der send-Methode an den kafka-Server und rufen es mithilfe der konsum-Methode ab.
Sie können in 5 Minuten einen Test schreiben, der die volle Leistung von Kafka demonstriert, aber wir werden noch weiter gehen - verbringen Sie 10 Minuten damit, eine andere Anwendung zu schreiben, die Nachrichten an den Server sendet, den unsere erste Anwendung abhört.
Kafka-Tester
Mit der Erfahrung, die erste Anwendung zu schreiben, können wir die zweite leicht schreiben, insbesondere wenn wir das Einfügen und das dto-Paket kopieren, nur den Produzenten registrieren (wir senden nur Nachrichten) und dem Dienst die einzige Sendemethode hinzufügen. Über den folgenden Link können Sie den Projektcode einfach herunterladen und sicherstellen, dass dort nichts Kompliziertes ist.
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
Nach den ersten 10 Sekunden sendet der Kafka-Tester alle 5 Sekunden Nachrichten mit den Namen der Raumschiffe an den Kafka-Server (das Bild kann angeklickt werden).
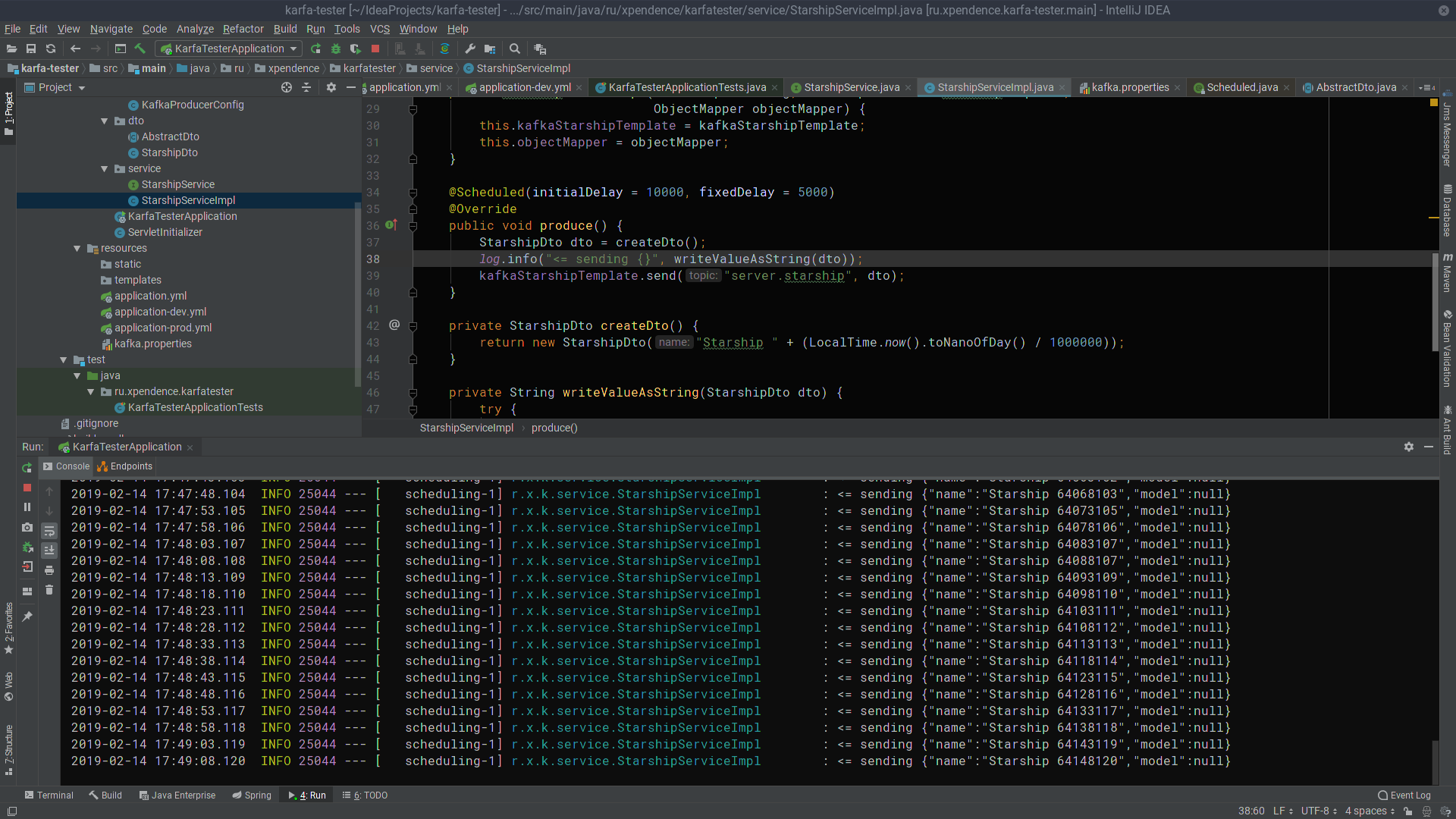
Dort werden sie vom Kafka-Server abgehört und empfangen (das Bild ist auch anklickbar).

Ich hoffe, dass diejenigen, die davon träumen, bei Kafka mit dem Schreiben von Microservices zu beginnen, genauso erfolgreich sein werden wie ich. Und hier sind die Links zu den Projekten:
→
Kafka-Server→
Kafka-Tester