Hallo habrozhiteli!
Wir haben uns entschlossen, die Übersetzung des Kapitels „Systeme basierend auf Aufgabenwarteschlangen“ aus der kommenden Neuheit „Verteilte Systeme. Design Patterns “(bereits in der Druckerei).
Die einfachste Form der Stapelverarbeitung ist die Aufgabenwarteschlange. In einem System mit einer Aufgabenwarteschlange müssen eine Reihe von Aufgaben ausgeführt werden. Jede Aufgabe ist völlig unabhängig von den anderen und kann ohne Interaktion mit ihnen bearbeitet werden. Im allgemeinen Fall besteht das Ziel eines Systems mit einer Aufgabenwarteschlange darin, sicherzustellen, dass jede Arbeitsphase innerhalb eines bestimmten Zeitraums abgeschlossen ist. Die Anzahl der Workflows nimmt entsprechend der Laständerung zu oder ab. Das Schema der verallgemeinerten Aufgabenwarteschlange ist in Fig. 4 dargestellt. 10.1.
Ein System, das auf einer allgemeinen Aufgabenwarteschlange basiert
Die Taskzeile ist ein ideales Beispiel, das die volle Leistungsfähigkeit verteilter Systemdesignmuster demonstriert. Der größte Teil der Logik der Aufgabenwarteschlange hängt nicht von der Art der ausgeführten Arbeit ab. In vielen Fällen gilt das Gleiche für die Erbringung der Aufgaben selbst.
Lassen Sie uns diese Aussage anhand der in Abb. 10.1. Stellen Sie nach erneutem Betrachten fest, welche Funktionen von einem gemeinsam genutzten Satz von Containern bereitgestellt werden können. Es wird deutlich, dass der größte Teil der Implementierung einer Container-Task-Warteschlange von einer Vielzahl von Benutzern verwendet werden kann.
Für die Container-basierte Task-Warteschlange müssen Schnittstellen zwischen Bibliothekscontainern und Containern mit der Benutzerlogik abgeglichen werden. Innerhalb der Container-Task-Warteschlange werden zwei Schnittstellen unterschieden: die Quellcontainer-Schnittstelle, die einen Stream von Aufgaben bereitstellt, die verarbeitet werden müssen, und die ausführende Container-Schnittstelle, die weiß, wie sie zu handhaben sind.
Quellcontainer-Schnittstelle
Jede Aufgabenwarteschlange basiert auf einer Reihe von Aufgaben, die verarbeitet werden müssen. Abhängig von der spezifischen Anwendung, die auf der Grundlage der Aufgabenwarteschlange implementiert wird, fallen viele Aufgabenquellen in diese. Nach dem Empfang einer Reihe von Aufgaben ist das Warteschlangenoperationsschema jedoch recht einfach. Daher können wir die anwendungsspezifische Logik der Aufgabenquelle vom allgemeinen Schema der Verarbeitung der Aufgabenwarteschlange trennen. Unter Hinweis auf die zuvor diskutierten Muster von Containergruppen können Sie hier die Implementierung des Ambassador-Musters sehen. Der verallgemeinerte Aufgabenwarteschlangencontainer ist der Hauptanwendungscontainer, und der anwendungsspezifische Quellcontainer ist ein Botschafter, der Anforderungen vom Warteschlangenverteilercontainer an bestimmte Aufgabenausführende sendet. Diese Gruppe von Behältern ist in Abb. 1 dargestellt. 10.2.

Obwohl der Container-Botschafter anwendungsspezifisch ist (was offensichtlich ist), gibt es übrigens auch eine Reihe allgemeiner Implementierungen der Task-Quell-API. Die Quelle kann beispielsweise eine Liste von Fotos sein, die sich in einem Cloud-Speicher befinden, eine Reihe von Dateien auf einem Netzlaufwerk oder sogar eine Warteschlange in Systemen, die nach dem Prinzip "Veröffentlichen / Abonnieren" arbeiten, wie z. B. Kafka oder Redis. Trotz der Tatsache, dass Benutzer die für ihre Aufgabe am besten geeigneten Container-Botschafter auswählen können, sollten sie eine verallgemeinerte "Bibliotheks" -Implementierung des Containers selbst verwenden. Dies minimiert den Arbeitsaufwand und maximiert die Wiederverwendung von Code.
Task Queue API Angesichts des Interaktionsmechanismus zwischen der Task-Warteschlange und dem anwendungsspezifischen Container-Botschafter sollten wir eine formale Definition der Schnittstelle zwischen den beiden Containern formulieren. Es gibt viele verschiedene Protokolle, aber die HTTP-RESTful-APIs sind einfach zu implementieren und der De-facto-Standard für solche Schnittstellen. Die Task-Warteschlange erwartet, dass die folgenden URLs im After-Container implementiert werden:
Warum sollten Sie Ihrer API-Definition v1 hinzufügen? Wird es jemals eine zweite Version der Schnittstelle geben? Es sieht unlogisch aus, aber die Kosten für die Versionierung der API bei der anfänglichen Definition sind minimal. Die Durchführung des entsprechenden Refactorings später ist äußerst teuer. Machen Sie es sich zur Regel, allen APIs Versionen hinzuzufügen, auch wenn Sie nicht sicher sind, ob sie sich jemals ändern werden. Gott rettet den Safe.
URL / items / gibt eine Liste aller Aufgaben zurück:
{ kind: ItemList, apiVersion: v1, items: [ "item-1", "item-2", …. ] }
Die URL / items / <Elementname> enthält detaillierte Informationen zu einer bestimmten Aufgabe:
{ kind: Item, apiVersion: v1, data: { "some": "json", "object": "here", } }
Bitte beachten Sie, dass die API keine Mechanismen zum Beheben der Tatsache der Aufgabe bietet. Man könnte eine komplexere API entwickeln und den größten Teil der Implementierung auf einen Container-Botschafter verlagern. Denken Sie jedoch daran, dass unser Ziel darin besteht, die Gesamtimplementierung so weit wie möglich auf den Task Queue Manager zu konzentrieren. In diesem Zusammenhang muss der Task-Warteschlangenmanager selbst überwachen, welche Tasks bereits verarbeitet wurden und welche noch verarbeitet werden müssen.
Über diese API erhalten wir Informationen zu einer bestimmten Aufgabe und übergeben dann den Wert des Felds item.data der Containerschnittstelle des Executors.
Container-Schnittstelle ausführen
Sobald der Warteschlangenmanager die nächste Aufgabe erhalten hat, sollte er sie einem Testamentsvollstrecker anvertrauen. Dies ist die zweite Schnittstelle in der allgemeinen Aufgabenwarteschlange. Der Container selbst und seine Schnittstelle unterscheiden sich aus mehreren Gründen geringfügig von der Quellcontainerschnittstelle. Erstens ist es eine einmalige API. Die Arbeit des Executors beginnt mit einem einzigen Anruf, und während des Lebenszyklus des Containers werden keine Anrufe mehr getätigt. Zweitens befinden sich der ausführende Container und der Task-Warteschlangenmanager in verschiedenen Containergruppen. Der Container Executor wird über die Container Orchestrator-API in einer eigenen Gruppe gestartet. Dies bedeutet, dass der Task-Warteschlangenmanager einen Remote-Aufruf ausführen muss, um den Ausführungscontainer zu initiieren. Dies bedeutet auch, dass Sie bei Sicherheitsproblemen vorsichtiger sein müssen, da ein böswilliger Benutzer des Clusters ihn mit unnötiger Arbeit laden kann.
Im Quellcontainer haben wir einen einfachen HTTP-Aufruf verwendet, um die Aufgabenliste an den Aufgabenmanager zu senden. Dies geschah unter der Annahme, dass dieser API-Aufruf mehrmals durchgeführt werden musste und Sicherheitsprobleme nicht berücksichtigt wurden, da alles innerhalb des localhost-Frameworks funktionierte. Die Container-API darf nur einmal aufgerufen werden, und es ist wichtig sicherzustellen, dass andere Benutzer des Systems den Ausführenden auch aus Versehen oder aus böswilliger Absicht keine Arbeit hinzufügen können. Daher verwenden wir für den ausführenden Container die Datei-API. Bei der Erstellung übergeben wir dem Container eine Umgebungsvariable namens WORK_ITEM_FILE, deren Wert sich auf eine Datei im internen Dateisystem des Containers bezieht. Diese Datei enthält Daten zur auszuführenden Aufgabe. Diese Art von API kann, wie unten gezeigt, vom ConfigMap Kubernetes-Objekt implementiert werden. Es kann in einer Gruppe von Containern als Datei bereitgestellt werden (Abb. 10.3).
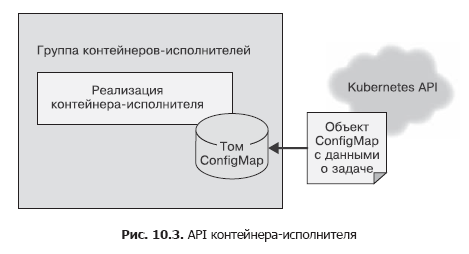
Ein solcher Datei-API-Mechanismus ist mithilfe eines Containers einfacher zu implementieren. Ein Executor in einer Task-Warteschlange ist häufig ein einfaches Shell-Skript, das auf mehrere Tools zugreift. Es ist unpraktisch, einen gesamten Webserver für die Aufgabenverwaltung einzurichten - dies führt zu einer Komplikation der Architektur. Wie bei den Aufgabenquellen handelt es sich bei den meisten Container-Executoren um spezialisierte Container für bestimmte Aufgaben. Es gibt jedoch auch allgemeine Executoren, die zum Lösen mehrerer verschiedener Aufgaben geeignet sind.
Betrachten Sie das Beispiel eines ausführenden Containers, der eine Datei aus dem Cloud-Speicher herunterlädt, ein Shell-Skript darauf ausführt und das Ergebnis dann zurück in den Cloud-Speicher kopiert. Ein solcher Container kann größtenteils allgemein sein, es kann jedoch ein bestimmtes Szenario als Parameter an ihn übergeben werden. Daher kann der größte Teil des Dateiverarbeitungscodes von vielen Benutzern / Task-Warteschlangen wiederverwendet werden. Der Endbenutzer muss nur ein Skript bereitstellen, das die Besonderheiten der Dateiverarbeitung enthält.
Allgemeine Taskwarteschlangeninfrastruktur
Was muss in einer wiederverwendbaren Warteschlangenimplementierung noch implementiert werden, wenn Sie bereits Implementierungen der beiden zuvor beschriebenen Containerschnittstellen haben? Der grundlegende Algorithmus der Task-Warteschlange ist recht einfach.
- Laden Sie die aktuell verfügbaren Aufgaben aus dem Quellcontainer herunter.
- Klären Sie den Status der Aufgabenwarteschlange für die Aufgaben, die bereits abgeschlossen wurden oder noch ausgeführt werden.
- Erstellen Sie für jede der ungelösten Aufgaben Container-Container mit einer geeigneten Schnittstelle.
- Notieren Sie nach erfolgreichem Abschluss des ausführenden Containers, dass die Aufgabe abgeschlossen wurde.
Dieser Algorithmus ist in Worten einfach, aber in Wirklichkeit ist er nicht so einfach zu implementieren. Glücklicherweise verfügt das Kubernetes-Orchester über mehrere Funktionen, die seine Implementierung erheblich vereinfachen. Nämlich: Kubernetes verfügt über ein Job-Objekt, das einen zuverlässigen Betrieb der Task-Warteschlange gewährleistet. Sie können das Job-Objekt so konfigurieren, dass es den entsprechenden ausführenden Container entweder einmal oder bis zum erfolgreichen Abschluss der Aufgabe startet. Wenn Sie den ausführenden Container so konfigurieren, dass er ausgeführt wird, bevor die Aufgabe abgeschlossen ist, wird die Aufgabe auch dann erfolgreich abgeschlossen, wenn der Computer im Cluster ausfällt.
Dadurch wird die Warteschlange für Aufgaben erheblich vereinfacht, da das Orchester die Verantwortung für die zuverlässige Ausführung von Aufgaben übernimmt.
Darüber hinaus können Sie mit Kubernetes Aufgaben mit Anmerkungen versehen, sodass wir jedes Aufgabenobjekt mit dem Namen des verarbeiteten Aufgabenwarteschlangenelements markieren können. Es wird immer einfacher, zwischen Aufgaben zu unterscheiden, die sowohl erfolgreich als auch fehlerhaft verarbeitet und ausgeführt werden.
Dies bedeutet, dass wir die Task-Warteschlange über dem Kubernetes-Orchestrator implementieren können, ohne unser eigenes Repository zu verwenden. All dies vereinfacht die Aufgabe des Aufbaus der Infrastruktur der Aufgabenwarteschlange erheblich.
Daher lautet ein detaillierter Algorithmus für den Betrieb des Containers, der Taskwarteschlangenmanager, wie folgt.
Endlos wiederholen.
- Rufen Sie die Liste der Aufgaben über die Schnittstelle des Containers ab - die Quelle der Aufgaben.
- Rufen Sie eine Liste der Aufgaben ab, die diese Aufgabenwarteschlange bedienen.
- Wählen Sie anhand dieser Listen eine Liste unverarbeiteter Aufgaben aus.
- Erstellen Sie für jede unverarbeitete Aufgabe ein Jobobjekt, das den entsprechenden ausführenden Container erzeugt.
Hier ist ein Python-Skript, das diese Warteschlange implementiert:
import requests import json from kubernetes import client, config import time namespace = "default" def make_container(item, obj): container = client.V1Container() container.image = "my/worker-image" container.name = "worker" return container def make_job(item): response = requests.get("http://localhost:8000/items/{}".format(item)) obj = json.loads(response.text) job = client.V1Job() job.metadata = client.V1ObjectMeta() job.metadata.name = item job.spec = client.V1JobSpec() job.spec.template = client.V1PodTemplate() job.spec.template.spec = client.V1PodTemplateSpec() job.spec.template.spec.restart_policy = "Never" job.spec.template.spec.containers = [ make_container(item, obj) ] return job def update_queue(batch): response = requests.get("http://localhost:8000/items") obj = json.loads(response.text) items = obj['items'] ret = batch.list_namespaced_job(namespace, watch=False) for item in items: found = False for i in ret.items: if i.metadata.name == item: found = True if not found: # Job, # job = make_job(item) batch.create_namespaced_job(namespace, job) config.load_kube_config() batch = client.BatchV1Api() while True: update_queue(batch) time.sleep(10)
Werkstatt Implementierung eines Thumbnail-Generators für Videodateien
Betrachten Sie als Beispiel für die Verwendung der Aufgabenwarteschlange die Aufgabe, Miniaturansichten von Videodateien zu generieren. Anhand dieser Miniaturansichten entscheiden Benutzer, welche Videos sie ansehen möchten.
Zum Implementieren der Miniaturansichten benötigen Sie zwei Container. Der erste ist für die Quelle der Aufgaben. Es ist am einfachsten, Aufgaben auf einem gemeinsam genutzten Netzwerklaufwerk zu platzieren, das beispielsweise über NFS (Network File System, Network File System) verbunden ist. Die Aufgabenquelle empfängt eine Liste der Dateien in diesem Verzeichnis und leitet sie an den Aufrufer weiter.
Ich werde ein einfaches Programm auf NodeJS geben:
const http = require('http'); const fs = require('fs'); const port = 8080; const path = process.env.MEDIA_PATH; const requestHandler = (request, response) => { console.log(request.url); fs.readdir(path + '/*.mp4', (err, items) => { var msg = { 'kind': 'ItemList', 'apiVersion': 'v1', 'items': [] }; if (!items) { return msg; } for (var i = 0; i < items.length; i++) { msg.items.push(items[i]); } response.end(JSON.stringify(msg)); }); } const server = http.createServer(requestHandler); server.listen(port, (err) => { if (err) { return console.log(' ', err); } console.log(` ${port}`) });
Diese Quelle definiert die Liste der zu verarbeitenden Filme. Das Dienstprogramm ffmpeg wird zum Extrahieren von Miniaturansichten verwendet.
Sie können einen Container erstellen, der den folgenden Befehl ausführt:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.png
Der Befehl extrahiert einen von 100 Frames (Parameter -frames: v 100) und speichert ihn im PNG-Format (z. B. thumb1.png, thumb2.png usw.).
Diese Art der Verarbeitung kann basierend auf dem vorhandenen ffmpeg Docker-Image implementiert werden. Das
Bild von jrottenberg / ffmpeg ist beliebt.
Durch die Definition eines einfachen Quellcontainers und eines noch einfacheren Container-Executors können Sie die Vorteile eines generischen, containerorientierten Warteschlangenverwaltungssystems leicht erkennen. Dies verkürzt die Zeit zwischen Entwurf und Implementierung der Task-Warteschlange erheblich.
Dynamische Skalierung von Künstlern
Die zuvor betrachtete Aufgabenwarteschlange eignet sich gut für die Verarbeitung von Aufgaben, sobald diese verfügbar sind, kann jedoch zu einer plötzlichen Belastung der Ressourcen des Containercluster-Orchestrators führen. Dies ist gut, wenn Sie viele verschiedene Arten von Aufgaben haben, die zu unterschiedlichen Zeiten Lastspitzen erzeugen und dadurch die Last auf den Cluster gleichmäßig über die Zeit verteilen.
Wenn Sie jedoch nicht über genügend Lasttypen verfügen, müssen für den Ansatz "Dann dick, dann leer" zum Skalieren der Aufgabenwarteschlange möglicherweise zusätzliche Ressourcen reserviert werden, um Laststöße zu unterstützen. In der restlichen Zeit werden die Ressourcen leer sein und Ihren Geldbeutel unnötig leeren.
Um dieses Problem zu lösen, können Sie die Gesamtzahl der von der Taskwarteschlange generierten Jobobjekte begrenzen. Dies begrenzt natürlich die Anzahl der parallel verarbeiteten Jobs und reduziert folglich den Ressourcenverbrauch bei Spitzenlasten. Andererseits erhöht sich die Dauer jeder einzelnen Aufgabe mit einer hohen Belastung des Clusters.
Wenn die Last krampfhaft ist, ist dies nicht beängstigend, da Ausfallzeitintervalle verwendet werden können, um akkumulierte Aufgaben zu erledigen. Wenn die Dauerlast jedoch zu hoch ist, hat die Aufgabenwarteschlange keine Zeit, eingehende Aufgaben zu verarbeiten, und es wird immer mehr Zeit für deren Implementierung aufgewendet.
In einer solchen Situation müssen Sie die maximale Anzahl paralleler Aufgaben und entsprechend die verfügbaren Rechenressourcen dynamisch anpassen, um das erforderliche Leistungsniveau aufrechtzuerhalten. Glücklicherweise gibt es mathematische Formeln, mit denen Sie bestimmen können, wann die Aufgabenwarteschlange skaliert werden muss, um mehr Anforderungen zu verarbeiten.
Stellen Sie sich eine Aufgabenwarteschlange vor, in der eine neue Aufgabe durchschnittlich einmal pro Minute angezeigt wird und deren Abschluss durchschnittlich 30 Sekunden dauert. Eine solche Warteschlange ist in der Lage, den darin enthaltenen Aufgabenfluss zu bewältigen. Selbst wenn ein großes Paket von Aufgaben gleichzeitig eintrifft und einen Stau verursacht, wird der Stau im Laufe der Zeit beseitigt, da die Warteschlange vor dem Eintreffen der nächsten Aufgabe durchschnittlich zwei Aufgaben verarbeiten kann.
Wenn jede Minute eine neue Aufgabe eintrifft und die Bearbeitung einer Aufgabe durchschnittlich 1 Minute dauert, ist ein solches System ideal ausbalanciert, reagiert jedoch nicht gut auf Änderungen der Last. Sie ist in der Lage, Laststöße zu bewältigen, aber es wird ziemlich viel Zeit in Anspruch nehmen. Das System wird nicht inaktiv sein, aber es wird keine Computerzeitreserve vorhanden sein, um die langfristige Erhöhung der Empfangsgeschwindigkeit neuer Aufgaben auszugleichen. Um die Systemstabilität aufrechtzuerhalten, ist eine Reserve für den Fall eines langfristigen Lastwachstums oder unvorhergesehener Verzögerungen bei den Verarbeitungsaufgaben erforderlich.
Stellen Sie sich schließlich ein System vor, in dem eine Aufgabe pro Minute eintrifft und die Aufgabenverarbeitung zwei Minuten dauert. Ein solches System verliert ständig an Leistung. Die Länge der Aufgabenwarteschlange nimmt mit der Verzögerung zwischen dem Empfang und der Verarbeitung von Aufgaben (und dem Grad der Irritation der Benutzer) zu.
Die Werte dieser beiden Indikatoren müssen ständig überwacht werden. Durch Mittelung der Zeit zwischen dem Empfang von Aufgaben über einen langen Zeitraum, beispielsweise basierend auf der Anzahl der Aufgaben pro Tag, erhalten wir eine Schätzung des Intervalls zwischen Aufgaben. Es ist auch erforderlich, die durchschnittliche Verarbeitungszeit der Aufgabe zu überwachen (mit Ausnahme der in der Warteschlange verbrachten Zeit). In einer stabilen Aufgabenwarteschlange sollte die durchschnittliche Aufgabenverarbeitungszeit kürzer als das Intervall zwischen Aufgaben sein. Um sicherzustellen, dass diese Bedingung erfüllt ist, muss die Anzahl der verfügbaren Warteschlangen für Computerressourcen dynamisch angepasst werden. Wenn Jobs parallel verarbeitet werden, sollte die Verarbeitungszeit durch die Anzahl der parallel verarbeiteten Jobs geteilt werden. Wenn beispielsweise eine Aufgabe pro Minute verarbeitet wird, aber vier Aufgaben parallel verarbeitet werden, beträgt die effektive Verarbeitungszeit einer Aufgabe 15 Sekunden. Dies bedeutet, dass das Intervall zwischen den Aufgaben mindestens 16 Sekunden betragen sollte.
Mit diesem Ansatz können Sie auf einfache Weise ein Modul zum Skalieren der Aufgabenwarteschlange nach oben erstellen. Das Verkleinern ist etwas problematischer. Es ist jedoch möglich, dieselben Berechnungen wie zuvor zu verwenden und zusätzlich die durch heuristische Methoden bestimmte Reserve an Rechenressourcen zu legen. Sie können beispielsweise die Anzahl der parallelen Aufgaben reduzieren, bis die Verarbeitungszeit für eine Aufgabe 90% des Intervalls zwischen Aufgaben beträgt.
Multi-Worker-Muster
Eines der Hauptthemen dieses Buches ist die Verwendung von Containern zum Einkapseln und Wiederverwenden von Code. Dies ist auch für die in diesem Kapitel beschriebenen Aufgabenwarteschlangenmuster relevant. Zusätzlich zu den Containern, die die Warteschlange selbst verwalten, können Sie Gruppen von Containern wiederverwenden, aus denen die Implementierung der Darsteller besteht. Angenommen, Sie müssen jede Aufgabe in einer Warteschlange auf drei verschiedene Arten verarbeiten. Um beispielsweise Gesichter auf einem Foto zu erkennen, ordnen Sie sie bestimmten Personen zu und verwischen Sie dann die entsprechenden Teile des Bildes. Sie können die gesamte Verarbeitung in einem ausführenden Container ablegen. Dies ist jedoch eine einmalige Lösung, die nicht wiederverwendet werden kann. Um etwas anderes, wie z. B. Autos, auf dem Foto zu vertuschen, müssen Sie einen Containerkünstler von Grund auf neu erstellen.
Die Möglichkeit dieser Art der Wiederverwendung kann durch Anwenden des Multi-Worker-Musters erreicht werden, das eigentlich ein Sonderfall des am Anfang des Buches beschriebenen Adaptermusters ist. Das Multi-Worker-Muster konvertiert einen Satz von Containern mit der Softwareschnittstelle des ausführenden Containers in einen gemeinsamen Container. Dieser gemeinsam genutzte Container delegiert die Verarbeitung an mehrere separate, wiederverwendbare Container. Dieser Vorgang ist in Abb. 1 schematisch dargestellt. 10.4.
Durch die Wiederverwendung des Codes durch Kombinieren ausführender Container wird der Arbeitsaufwand für die Entwicklung verteilter Stapelverarbeitungssysteme verringert.
»Weitere Informationen zum Buch finden Sie auf
der Website des Herausgebers»
Inhalt»
AuszugFür habrozhitelami 20% Rabatt auf den Gutschein -
Verteilte Systeme .