Moderne Hardware und Compiler sind bereit, unseren Code auf den Kopf zu stellen, wenn er nur schneller funktioniert. Und ihre Hersteller verstecken sorgfältig ihre innere Küche. Und alles ist in Ordnung, solange der Code in einem Thread ausgeführt wird.
In einer Multithread-Umgebung können Sie zwangsläufig interessante Dinge beobachten. Beispielsweise erfolgt die Ausführung von Programmanweisungen nicht in der Reihenfolge, die im Quellcode angegeben ist. Stimmen Sie zu, es ist unangenehm zu erkennen, dass die zeilenweise Ausführung des Quellcodes nur unsere Vorstellung ist.
Aber jeder hat es schon gemerkt, denn irgendwie muss man damit leben. Und Java-Programmierer leben sogar gut. Weil Java ein Speichermodell hat - das Java Memory Model (JMM), das ziemlich einfache Regeln zum Schreiben des richtigen Multithread-Codes bietet.
Und diese Regeln reichen für die meisten Programme aus. Wenn Sie sie nicht kennen, aber Multithread-Programme in Java schreiben oder schreiben möchten, sollten Sie
sich so schnell wie möglich mit
ihnen vertraut machen. Und wenn Sie es wissen, aber nicht genug Kontext haben oder es interessant ist zu wissen, woher JMMs Beine wachsen, kann Ihnen dieser Artikel helfen.
Und der Abstraktion nachjagen
Meiner Meinung nach gibt es einen Kuchen oder besser einen Eisberg. JMM ist die Spitze des Eisbergs. Der Eisberg selbst ist eine Theorie der Multithread-Programmierung unter Wasser. Unter dem Eisberg ist die Hölle.

Ein Eisberg ist eine Abstraktion, wenn er leckt, werden wir mit Sicherheit die Hölle sehen. Obwohl dort viele interessante Dinge passieren, werden wir im Übersichtsartikel nicht darauf eingehen.
In dem Artikel interessieren mich mehr folgende Themen:
- Theorie und Terminologie
- Wie spiegelt sich die Theorie der Multithread-Programmierung in JMM wider?
- Wettbewerbsfähige Programmiermodelle
Die Theorie der Multithread-Programmierung ermöglicht es Ihnen, sich von der Komplexität moderner Prozessoren und Compiler zu lösen, die Ausführung von Multithread-Programmen zu simulieren und deren Eigenschaften zu untersuchen. Roman Elizarov hat einen ausgezeichneten
Bericht verfasst , dessen Zweck es ist, eine theoretische Grundlage für das Verständnis von JMM zu schaffen. Ich empfehle den Bericht jedem, der sich für dieses Thema interessiert.
Warum ist es wichtig, die Theorie zu kennen? Meiner Meinung nach hoffe ich nur für mich, dass einige Programmierer der Meinung sind, dass JMM eine Komplikation der Sprache und das Patchen einiger Plattformprobleme mit Multithreading ist. Die Theorie zeigt, dass Java die sehr komplexe Multithread-Programmierung nicht kompliziert, sondern vereinfacht und vorhersehbarer gemacht hat.
Wettbewerb und Parallelität
Schauen wir uns zunächst die Terminologie an. Leider gibt es keinen Konsens in der Terminologie. Wenn Sie verschiedene Materialien studieren, stoßen Sie möglicherweise auf unterschiedliche Definitionen von Wettbewerb und Parallelität.
Das Problem ist, dass selbst wenn wir der Wahrheit auf den Grund gehen und die genauen Definitionen dieser Konzepte finden, es kaum die Erwartung wert ist, dass jeder mit diesen Konzepten dasselbe bedeutet.
Die Enden finden Sie hier nicht.
Roman Elizarov legt in einem Bericht die Theorie der parallelen Programmierung für Praktiker nahe, dass diese Konzepte manchmal gemischt sind. Parallele Programmierung wird manchmal als allgemeines Konzept unterschieden, das in wettbewerbsorientierte und verteilte unterteilt ist.
Es scheint mir, dass Sie im Kontext von JMM immer noch Wettbewerb und Parallelität trennen müssen oder vielmehr verstehen müssen, dass es zwei verschiedene Paradigmen gibt, egal wie sie genannt werden.
Oft zitiert von Rob Pike, der Konzepte wie folgt unterscheidet:
- Wettbewerb ist ein Weg, um viele Probleme gleichzeitig zu lösen
- Parallelität ist eine Möglichkeit, verschiedene Teile einer einzelnen Aufgabe auszuführen.
Die Meinung von Rob Pike ist kein Standard, aber meiner Meinung nach ist es zweckmäßig, darauf aufzubauen, um das Problem weiter zu untersuchen. Lesen Sie hier mehr über die Unterschiede.
Höchstwahrscheinlich wird sich ein besseres Verständnis des Problems ergeben, wenn wir die Hauptmerkmale eines wettbewerbsorientierten und parallelen Programms hervorheben. Es gibt viele Anzeichen, die als die bedeutendsten gelten.
Zeichen des Wettbewerbs.
- Das Vorhandensein mehrerer Kontrollflüsse (z. B. Thread in Java, Coroutine in Kotlin): Wenn nur ein Kontrollfluss vorhanden ist, kann keine wettbewerbsfähige Ausführung erfolgen
- Nicht deterministisches Ergebnis. Das Ergebnis hängt von zufälligen Ereignissen, der Implementierung und der Durchführung der Synchronisierung ab. Selbst wenn jeder Stream vollständig deterministisch ist, ist das Endergebnis nicht deterministisch
Ein paralleles Programm verfügt über andere Funktionen.
- Optional gibt es mehrere Kontrollabläufe
- Dies kann zu einem deterministischen Ergebnis führen. Beispielsweise ändert sich das Ergebnis der Multiplikation jedes Elements des Arrays mit einer Zahl nicht, wenn Sie es in Teilen parallel multiplizieren
Seltsamerweise ist eine parallele Ausführung in einem einzelnen Steuerungsfluss und sogar in einer Single-Core-Architektur möglich. Tatsache ist, dass Parallelität auf der Ebene der Aufgaben (oder Kontrollflüsse), an die wir gewöhnt sind, nicht die einzige Möglichkeit ist, Berechnungen parallel durchzuführen.
Parallelität ist möglich auf der Ebene von:
- Bits (auf 32-Bit-Computern erfolgt die Addition beispielsweise in einer Aktion, wobei alle 4 Bytes einer 32-Bit-Zahl parallel verarbeitet werden).
- Anweisungen (auf einem Kern, in einem Thread kann der Prozessor Anweisungen parallel ausführen, obwohl der Code sequentiell ist)
- Daten (es gibt Architekturen mit paralleler Datenverarbeitung (Single Instruction Multiple Data), die einen Befehl für einen großen Datensatz ausführen können)
- Aufgaben (impliziert das Vorhandensein mehrerer Prozessoren oder Kerne)
Die Parallelität auf Befehlsebene ist ein Beispiel für Optimierungen bei der Codeausführung, die dem Programmierer verborgen bleiben.
Es wird garantiert, dass der optimierte Code im Rahmen eines Threads dem Original entspricht, da es unmöglich ist, angemessenen und vorhersehbaren Code zu schreiben, wenn er nicht das tut, was der Programmierer beabsichtigt hat.
Nicht alles, was parallel läuft, ist für JMM von Bedeutung. Die gleichzeitige Ausführung auf Befehlsebene innerhalb eines einzelnen Threads wird in JMM nicht berücksichtigt.
Die Terminologie ist sehr wackelig, mit einer Rede von Roman Elizarov namens "Theorie der
parallelen Programmierung für Praktiker", obwohl es mehr über wettbewerbsfähige Programmierung gibt, wenn Sie sich an das oben Gesagte halten.
Im Zusammenhang mit JMM werde ich mich in dem Artikel an den Begriff Wettbewerb halten, da es beim Wettbewerb häufig um den allgemeinen Zustand geht. Aber hier muss man aufpassen, dass man sich nicht an Begriffe klammert, sondern versteht, dass es verschiedene Paradigmen gibt.
Modelle mit einem gemeinsamen Zustand: "Rotation von Operationen" und "vorher passiert"
In seinem
Artikel schreibt Maurice Herlichi (Autor von The Art Of Multiprocessor Programming), dass ein Wettbewerbssystem eine Sammlung sequentieller Prozesse enthält (in theoretischen Arbeiten bedeutet dies dasselbe wie ein Thread), die über das gemeinsame Gedächtnis kommunizieren.
Das allgemeine Zustandsmodell umfasst Berechnungen mit Nachrichten, wobei der gemeinsam genutzte Zustand eine Nachrichtenwarteschlange ist, und Berechnungen mit gemeinsamem Speicher, wobei der gemeinsame Zustand Strukturen im Speicher sind.
Jede der Berechnungen kann simuliert werden.
Das Modell basiert auf einer Finite-State-Maschine. Das Modell konzentriert sich ausschließlich auf den gemeinsam genutzten Status und die lokalen Daten jedes Flusses werden vollständig ignoriert. Jede Aktion von Flüssen über einen gemeinsam genutzten Zustand ist eine Funktion des Übergangs in einen neuen Zustand.
Wenn beispielsweise 4 Threads Daten in eine gemeinsam genutzte Variable schreiben, gibt es 4 Funktionen für den Übergang in einen neuen Status. Welche dieser Funktionen angewendet werden, hängt von der Chronologie der Ereignisse im System ab.
Nachrichtenübermittlungsberechnungen werden auf ähnliche Weise modelliert, nur die Status- und Übergangsfunktionen hängen vom Senden oder Empfangen von Nachrichten ab.
Wenn Ihnen das Modell kompliziert erschien, werden wir es im Beispiel beheben. Es ist wirklich sehr einfach und intuitiv. So sehr, dass die meisten Menschen das Programm, ohne über die Existenz dieses Modells Bescheid zu wissen, immer noch analysieren, wie es das Modell vorschlägt.
Ein solches Modell wird
durch den Wechsel der Operationen als
Leistungsmodell bezeichnet (der Name wurde in einem Bericht von Roman Elizarov gehört).
In die Intuitivität und Natürlichkeit können Sie die Vorteile des Modells sicher aufschreiben. Sie können mit den Schlüsselwörtern
Sequentielle Konsistenz und der
Arbeit von Leslie Lamport in die Wildnis gehen.
Es gibt jedoch eine wichtige Klarstellung zu diesem Modell. Das Modell hat die Einschränkung, dass alle Aktionen in einem gemeinsam genutzten Status sofort ausgeführt werden müssen und gleichzeitig Aktionen nicht gleichzeitig ausgeführt werden können. Sie sagen, dass ein solches System eine
lineare Reihenfolge hat - alle Aktionen im System sind geordnet.
In der Praxis passiert dies nicht. Die Operation erfolgt nicht sofort, sondern wird in einem Intervall ausgeführt. Auf Mehrkernsystemen können sich diese Intervalle überschneiden. Dies bedeutet natürlich nicht, dass das Modell in der Praxis unbrauchbar ist. Sie müssen lediglich bestimmte Bedingungen für seine Verwendung erstellen.
Betrachten Sie in der Zwischenzeit ein anderes
Modell - „Vorher passiert“ -, das sich nicht auf den Status konzentriert, sondern auf die Menge der Lese- und Schreibspeicherzellen während der Ausführung (Verlauf) und deren Beziehungen.
Das Modell besagt, dass Ereignisse in verschiedenen Flüssen nicht augenblicklich und atomar sind, sondern parallel, und es ist nicht möglich, eine Ordnung zwischen ihnen aufzubauen. Ereignisse (Schreiben und Lesen gemeinsam genutzter Daten) in Streams auf einer Multiprozessor- oder Multi-Core-Architektur treten tatsächlich parallel auf. Es gibt kein Konzept der globalen Zeit im System, wir können nicht verstehen, wann eine Operation beendet und eine andere gestartet wurde.
In der Praxis bedeutet dies, dass wir einen Wert in eine Variable in einem Thread schreiben und dies beispielsweise am Morgen tun und den Wert dieser Variablen in einem anderen Thread am Abend lesen können, und wir können nicht sagen, dass wir den am Morgen geschriebenen Wert sicher lesen werden. Theoretisch finden diese Operationen parallel statt und es ist nicht klar, wann eine endet und eine andere beginnt.
Es ist schwer vorstellbar, wie sich herausstellt, dass einfache Lese- und Schreibvorgänge, die zu verschiedenen Tageszeiten ausgeführt werden, gleichzeitig stattfinden. Aber wenn Sie darüber nachdenken, ist es uns wirklich egal, wann die Ereignisse des Schreibens und Lesens eintreten, wenn wir nicht garantieren können, dass wir das Ergebnis der Aufnahme sehen werden.
Und wir können das Ergebnis der Aufnahme wirklich nicht sehen, d.h. In eine Variable, deren Wert in Strom
P 0 ist
, schreiben wir
1 , und in Strom
Q lesen wir diese Variable. Egal wie viel physische Zeit nach der Aufnahme vergeht, wir können immer noch
0 lesen.
So funktionieren Computer und das Modell spiegelt dies wider.Das Modell ist vollständig abstrakt und benötigt eine bequeme Visualisierung für bequemes Arbeiten. Zur Visualisierung und nur dafür wird ein Modell mit globaler Zeit verwendet, mit dem Vorbehalt, dass beim Nachweis der Eigenschaften von Programmen keine globale Zeit verwendet wird. In der Visualisierung wird jedes Ereignis als Intervall mit einem Anfang und einem Ende dargestellt.
Die Veranstaltungen finden parallel statt, wie wir herausgefunden haben. Dennoch hat das System eine
Teilreihenfolge , da es spezielle Ereignispaare gibt, die eine Reihenfolge haben. In diesem Fall sagen sie, dass diese Ereignisse eine Beziehung haben, die vorher passiert ist. Wenn Sie zum ersten Mal von der Beziehung „Vorher passiert“ hören, hilft es Ihnen wahrscheinlich nicht viel, wenn Sie wissen, dass diese Beziehung Ereignisse arrangiert.
Versuch, ein Java-Programm zu analysieren
Wir haben ein theoretisches Minimum betrachtet. Versuchen wir, ein Multithread-Programm in einer bestimmten Sprache - Java - aus zwei Threads mit einem gemeinsamen veränderlichen Status zu betrachten.
Ein klassisches Beispiel.
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
Wir müssen die Ausführung dieses Programms simulieren und alle möglichen Ergebnisse erhalten - die Werte der Variablen x und y. Wie wir uns aus der Theorie erinnern, wird es mehrere Ergebnisse geben, ein solches Programm ist nicht deterministisch.
Wie werden wir modellieren? Ich möchte sofort das Interleaving-Modell von Operationen verwenden. Das Modell "Vorher passiert" sagt uns jedoch, dass Ereignisse in einem Thread parallel zu Ereignissen aus einem anderen Thread sind. Daher ist das Modell alternierender Operationen hier nicht geeignet, wenn zwischen den Operationen keine Beziehung besteht, die zuvor aufgetreten ist.
Das Ergebnis der Ausführung jedes Threads ist immer deterministisch, da die Ereignisse in einem Thread immer geordnet sind. Beachten Sie, dass sie kostenlos eine Beziehung erhalten, die zuvor aufgetreten ist. Es ist jedoch nicht ganz offensichtlich, wie Ereignisse in verschiedenen Flüssen zu einer Beziehung führen können, die vorher passiert ist. Natürlich ist diese Beziehung im Modell formalisiert, das gesamte Modell ist in mathematischer Sprache geschrieben. Was damit in der Praxis in einer bestimmten Sprache zu tun ist, wird jedoch nicht sofort verstanden.
Welche Möglichkeiten gibt es?
Ignorieren Sie Einschränkungen und simulieren Sie Interleaving. Sie können es versuchen, vielleicht passiert nichts Schlimmes.
Um zu verstehen, welche Ergebnisse erzielt werden können, zählen wir einfach alle möglichen Ausführungsvarianten auf.
Alle möglichen Programmausführungen können als endliche Zustandsmaschine dargestellt werden.
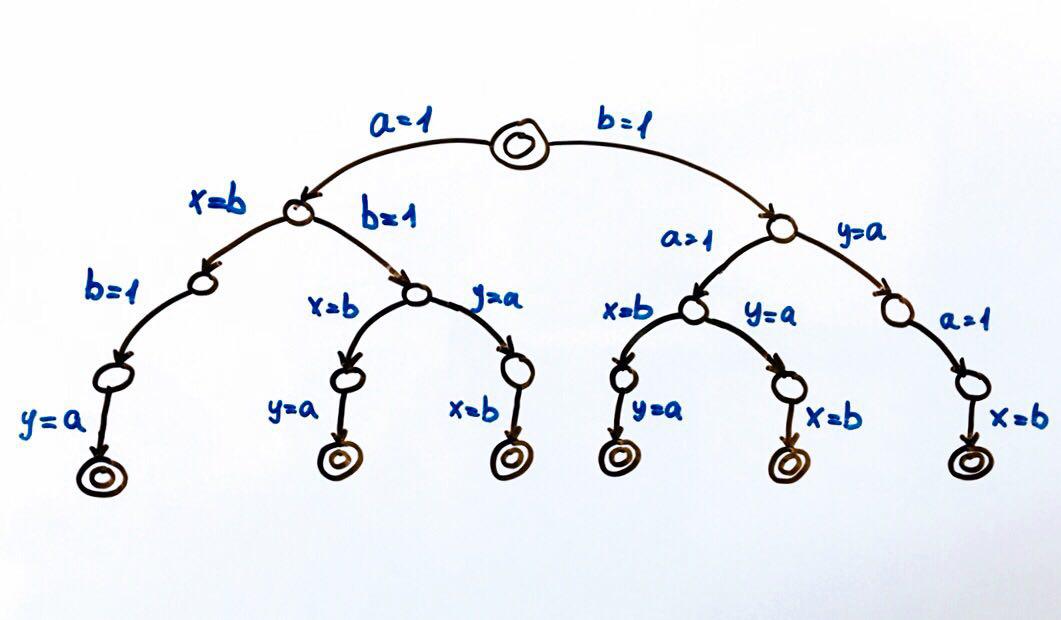
Jeder Kreis ist ein Zustand des Systems, in unserem Fall die Variablen
a, b, x, y . Eine Übergangsfunktion ist eine Aktion für einen Zustand, die das System in einen neuen Zustand versetzt. Da zwei Flüsse Aktionen für den allgemeinen Zustand ausführen können, gibt es zwei Übergänge von jedem Zustand. Doppelkreise sind der End- und Anfangszustand des Systems.
Insgesamt sind 6 verschiedene Ausführungen möglich, die zu Paaren von x, y-Werten führen:
(1, 1), (1, 0), (0, 1)
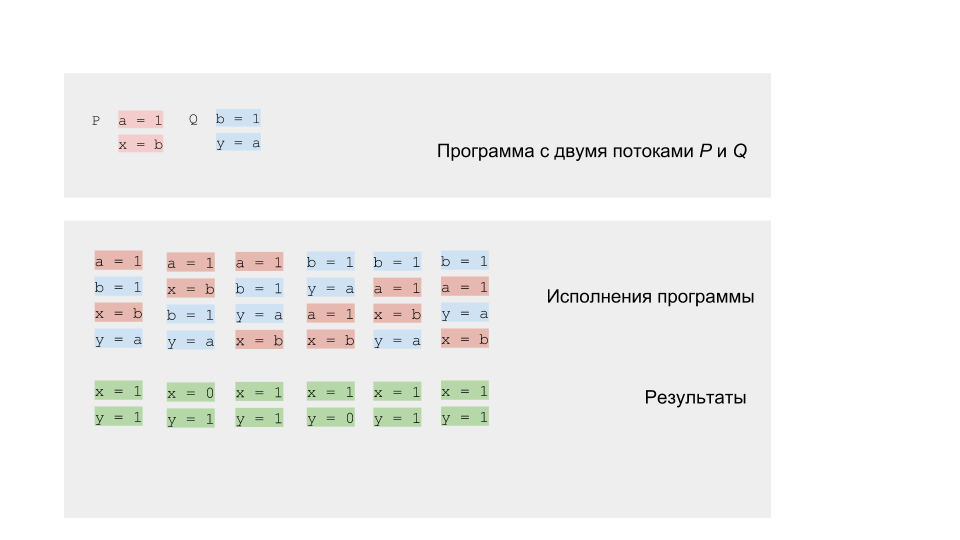
Wir können das Programm ausführen und die Ergebnisse überprüfen. Wie es sich für ein Wettbewerbsprogramm gehört, wird es ein nicht deterministisches Ergebnis haben.
Zum Testen wettbewerbsfähiger Programme ist es besser, spezielle Tools (
Tool ,
Bericht ) zu verwenden.
Sie können jedoch versuchen, das Programm mehrere Millionen Mal auszuführen, oder noch besser, einen Zyklus schreiben, der dies für uns erledigt.
Wenn wir den Code auf einer Single-Core- oder Single-Prozessor-Architektur ausführen, sollten wir das Ergebnis aus der erwarteten Menge erhalten. Das Rotationsmodell funktioniert einwandfrei. Bei einer Multi-Core-Architektur, z. B. x86, kann das Ergebnis uns überraschen - wir können das Ergebnis (0,0) erhalten, das nicht unserer Modellierung entspricht.
Die Erklärung hierfür finden Sie im Internet unter dem Schlüsselwort -
Neuordnung . Jetzt ist es wichtig zu verstehen, dass
Interleaving-Modellierung in einer Situation, in der wir die Reihenfolge des Zugriffs auf den gemeinsam genutzten Status nicht bestimmen können, wirklich nicht geeignet ist .
Theorie der kompetitiven Programmierung und JMM
Es ist Zeit, sich die Beziehung „Vorher passiert“ genauer anzusehen und wie sie mit JMM befreundet ist. Die ursprüngliche Definition der Beziehung „Vorher passiert“ finden Sie unter Zeit, Uhren und Reihenfolge der Ereignisse in einem verteilten System.
Das Sprachspeichermodell hilft beim Schreiben von Wettbewerbscode, da es bestimmt, welche Operationen mit „zuvor geschehen“ zusammenhängen. Eine Liste solcher Vorgänge finden Sie in der
Spezifikation im Abschnitt Happens-before-Order. In diesem Abschnitt wird die Frage beantwortet: Unter welchen Bedingungen wird das Ergebnis der Aufzeichnung in einem anderen Stream angezeigt?
Es gibt verschiedene Bestellungen in JMM. Alexei Shipilev spricht in einem seiner
Berichte sehr energisch über die Regeln.
Im globalen Zeitmodell sind alle Operationen im selben Thread in Ordnung. Beispielsweise können die Ereignisse beim Schreiben und Lesen einer Variablen als zwei Intervalle dargestellt werden. Das Modell garantiert dann, dass sich diese Intervalle niemals im Rahmen eines einzelnen Streams überschneiden. In JMM wird diese Reihenfolge als Programmreihenfolge (
PO ) bezeichnet.
PO bindet Aktionen in einem einzelnen Thread und sagt nichts über die Ausführungsreihenfolge aus, sondern spricht nur über die Reihenfolge im Quellcode. Dies reicht völlig aus, um den
Determinismus für jeden Stream separat zu gewährleisten.
PO kann als Rohdaten betrachtet werden.
PO ist immer einfach in einem Programm anzuordnen - alle Operationen (lineare Reihenfolge) im Quellcode innerhalb eines einzelnen Streams haben
PO .
In unserem Beispiel erhalten wir ungefähr Folgendes:
P: a = 1 PO x = b - Schreiben in a und Lesen von b hat eine PO-Reihenfolge
Q: b = 1 PO y = a - schreibe in b und lese a hat eine PO-Reihenfolge
Ich habe diese Form des Schreibens ausspioniert
w (a, 1) PO r (b): 0. Ich hoffe wirklich, dass niemand sie für Berichte patentiert hat. Die Spezifikation hat jedoch eine ähnliche Form.
Aber jeder Thread einzeln ist für uns nicht besonders interessant, da die Threads einen gemeinsamen Zustand haben, sind wir mehr an der Interaktion der Flüsse interessiert. Wir möchten nur sicherstellen, dass wir eine Aufzeichnung von Variablen in anderen Threads sehen.
Ich möchte Sie daran erinnern, dass dies für uns nicht funktioniert hat, da die Operationen zum Schreiben und Lesen von Variablen in verschiedenen Streams nicht sofort erfolgen (dies sind Segmente, die sich überschneiden). Es ist unmöglich zu analysieren, wo der Beginn und das Ende von Operationen liegen.
Die Idee ist einfach: In dem Moment, in dem wir die Variable a im Stream
Q lesen, endet die Aufzeichnung derselben Variablen im Stream
P möglicherweise noch nicht. Und egal wie viel physische Zeit diese Ereignisse gemeinsam haben - eine Nanosekunde oder einige Stunden.
Um Ereignisse zu bestellen, benötigen wir die Beziehung „Vorher passiert“. JMM definiert diese Beziehung. Die Spezifikation legt die Reihenfolge in einem Thread fest:
Wenn sich die Operation x und y im selben Thread befinden und in PO zuerst x und dann y auftritt, ist x vor y aufgetreten.
Mit Blick auf die Zukunft können wir sagen, dass wir alle
Bestellungen durch Happens-before (
HB ) ersetzen können:
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
Aber wir kehren wieder im Rahmen eines Stroms zurück.
HB ist zwischen Operationen in verschiedenen Threads möglich. Um diese Fälle zu behandeln, werden wir uns mit anderen Aufträgen vertraut machen.
Synchronisationsreihenfolge (
SO ) - Links Synchronisationsaktionen (
SA ). Eine vollständige Liste der
SA finden Sie in der Spezifikation in Abschnitt 17.4.2. Aktionen Hier sind einige davon:
- Flüchtige Variable lesen
- Flüchtige Variable schreiben
- Monitorschloss
- Monitor entsperren
SO ist für uns interessant, weil es die Eigenschaft hat, dass alle Messwerte in der
SO- Reihenfolge die letzten Einträge in
SO sehen . Und ich erinnere Sie daran, dass wir dies nur erreichen.
An dieser Stelle werde ich wiederholen, wonach wir streben. Wir haben ein Multithread-Programm, wir wollen alle möglichen Ausführungen simulieren und alle Ergebnisse erhalten, die es liefern kann. Es gibt Modelle, mit denen dies ganz einfach möglich ist. Sie erfordern jedoch, dass alle Aktionen für den gemeinsam genutzten Status angeordnet werden.
Laut der
SO- Eigenschaft - wenn alle Aktionen im Programm
SA sind, werden wir unser Ziel erreichen. Das heißt, Wir können den
flüchtigen Modifikator für alle Variablen einstellen und das Wechselmodell verwenden. Wenn Ihnen die Intuition sagt, dass sich das nicht lohnt, dann haben Sie absolut Recht. Mit diesen Aktionen verbieten wir einfach die Optimierung des Codes. Manchmal ist dies natürlich eine gute Option, aber dies ist definitiv kein allgemeiner Fall.
Betrachten Sie eine andere Synchronizes-With Order (
SW ) - SO-Reihenfolge für bestimmte flüchtige Paare zum Entsperren / Sperren, Schreiben / Lesen. Es spielt keine Rolle, in welchen Flüssen sich diese Aktionen befinden. Hauptsache, sie befinden sich auf derselben flüchtigen Monitorvariablen.
SW bietet eine Brücke zwischen Threads.
Und jetzt kommen wir zu der interessantesten Reihenfolge - Happens-before (
HB ).
HB ist eine transitive Schließung der Vereinigung von
SW und
PO .
PO gibt eine lineare Ordnung innerhalb des Stroms an, und
SW stellt eine Brücke zwischen den Strömen bereit.
HB ist transitiv, d.h. wenn
x HB y y HB z, x HB z
Die Spezifikation enthält eine Liste von
HB- Beziehungen, mit denen Sie sich genauer vertraut machen können. Hier einige Beispiele aus der Liste:
Innerhalb eines einzelnen Threads wird jede Operation ausgeführt, bevor eine Operation im Quellcode darauf folgt.
Das Beenden eines synchronisierten Blocks / einer synchronisierten Methode erfolgt, bevor ein synchronisierter Block / eine synchronisierte Methode auf demselben Monitor eingegeben wird.
Das Schreiben eines
flüchtigen Feldes erfolgt, bevor dasselbe
flüchtige Feld gelesen wird.
Kehren wir zu unserem Beispiel zurück:
P: a = 1 PO x = b Q: b = 1 PO y = a
Kehren wir zu unserem Beispiel zurück und versuchen, das Programm unter Berücksichtigung der Bestellungen zu analysieren.
Die Analyse des Programms mit JMM basiert darauf, Hypothesen aufzustellen und diese zu bestätigen oder zu widerlegen.
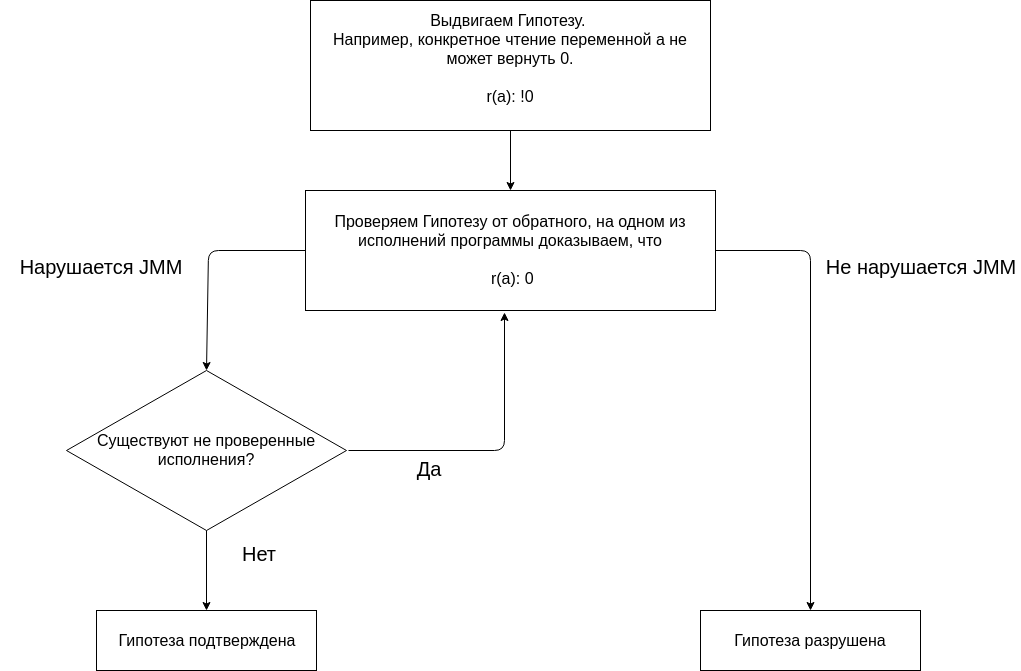
Wir beginnen unsere Analyse mit der Hypothese, dass keine einzige Programmausführung das Ergebnis liefert (0, 0). Das Fehlen eines Ergebnisses (0, 0) bei allen Ausführungen ist eine vermeintliche Eigenschaft des Programms.
Wir testen die Hypothese, indem wir verschiedene Ausführungen erstellen.
Ich habe die Nomenklatur
hier entdeckt (manchmal erscheint sie anstelle von
… Wort
race mit einem Pfeil, Alexey selbst verwendet den Pfeil und das Wort Rennen in seinen Berichten, warnt jedoch davor, dass diese Reihenfolge in JMM nicht vorhanden ist, und verwendet diese Notation aus Gründen der Klarheit).
Wir machen eine kleine Reservierung.
Da alle Aktionen für gemeinsame Variablen für uns wichtig sind und im Beispiel gemeinsame Variablen
a, b, x, y sind . Dann muss zum Beispiel die Operation x = b als r (b) und w (x, b) betrachtet werden, und
r(b) HB w(x,b) (basierend auf
PO ). Da die Variable x jedoch nirgendwo in den Threads gelesen wird (das Lesen in gedruckter Form am Ende des Codes ist nicht interessant, da nach der Verknüpfungsoperation im Thread der Wert x angezeigt wird), können wir die Aktion w (x, b) nicht berücksichtigen.
Überprüfen Sie die erste Leistung.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
Im Strom
Q lesen wir die Variable a, schreiben in diese Variable im Strom
P. Es gibt keine Reihenfolge zwischen Schreiben und Lesen
(PO, SW, HB) .
Wenn die Variable in einen Thread geschrieben ist und der Lesevorgang in einem anderen Thread erfolgt und keine
HB- Beziehung zwischen Operationen besteht, wird angegeben, dass die Variable unter Race gelesen wird. Und unter dem Rennen nach JMM können wir entweder den zuletzt aufgezeichneten Wert in
HB oder einen anderen Wert lesen.
Eine solche Leistung ist möglich. Die Ausführung
verstößt nicht gegen JMM . Wenn Sie die Variable a lesen, können Sie einen beliebigen Wert sehen, da das Lesen unter dem Rennen erfolgt und es keine Garantie gibt, dass die Aktion w (a, 1) angezeigt wird. Dies bedeutet nicht, dass das Programm korrekt funktioniert, sondern lediglich, dass ein solches Ergebnis erwartet wird.
Es macht keinen Sinn, den Rest der Ausführung zu berücksichtigen, da die
Hypothese bereits zerstört ist .
JMM sagt, wenn das Programm keine Datenrennen hat, können alle Ausführungen als sequentiell betrachtet werden. Lassen Sie uns das Rennen loswerden, dafür müssen wir die Lese- und Schreibvorgänge in verschiedenen Threads optimieren. Es ist wichtig zu verstehen, dass ein Multithread-Programm im Gegensatz zu einem sequentiellen Programm mehrere Ausführungen hat. Und um zu sagen, dass ein Programm eine Eigenschaft hat, muss nachgewiesen werden, dass das Programm diese Eigenschaft nicht bei einer der Ausführungen, sondern bei allen Ausführungen hat.
Um zu beweisen, dass das Programm kein Rennen ist, müssen Sie dies für alle Aufführungen tun. Versuchen wir,
SA zu
erstellen und die Variable a mit einem
flüchtigen Modifikator zu markieren.
Flüchtigen Variablen wird v vorangestellt.
Wir stellen
eine neue Hypothese auf . Wenn die Variable a
flüchtig gemacht wird, ergibt keine Ausführung des Programms das Ergebnis (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
Die Ausführung
verstößt nicht gegen JMM . Das Lesen von Va geschieht unter dem Rennen. Jede Rasse zerstört die Transitivität von HB.
Wir stellen eine
andere Hypothese auf . Wenn die Variable b
flüchtig gemacht wird, ergibt keine Ausführung des Programms das Ergebnis (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
Die Ausführung verstößt nicht gegen JMM. Das Lesen von a erfolgt unter dem Rennen.
Testen wir
die Hypothese, dass, wenn die Variablen a und b
flüchtig sind , keine Programmausführung das Ergebnis (0, 0) ergibt.
Überprüfen Sie die erste Leistung.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Da alle Aktionen im
SA- Programm (insbesondere das Lesen oder Schreiben einer
flüchtigen Variablen), erhalten wir die vollständige
SO- Reihenfolge zwischen allen Aktionen. Dies bedeutet, dass r (va) w (va, 1) sehen sollte. Diese
Ausführung verstößt gegen JMM .
Es ist notwendig, mit der nächsten Ausführung fortzufahren, um die Hypothese zu bestätigen. Da es jedoch für jede Ausführung
SO gibt, können Sie vom Formalismus abweichen - es ist offensichtlich, dass das Ergebnis (0, 0) das JMM für jede Ausführung verletzt.
Um das Rotationsmodell zu verwenden, müssen Sie für die Variablen a und b
flüchtig hinzufügen. Ein solches Programm liefert die Ergebnisse (1,1), (1,0) oder (0,1).
Am Ende können wir sagen, dass sehr einfache Programme recht einfach zu analysieren sind.
Komplexe Programme mit einer großen Anzahl von Ausführungen und gemeinsam genutzten Daten sind jedoch schwer zu analysieren, da Sie alle Ausführungen überprüfen müssen.
Andere wettbewerbsfähige Ausführungsmodelle
Warum andere wettbewerbsfähige Programmiermodelle in Betracht ziehen?
Die Verwendung von Threads und Synchronisationsprimitiven kann alle Probleme lösen. Dies ist alles wahr, aber das Problem ist, dass wir ein Beispiel für ein Dutzend Codezeilen untersucht haben, bei denen 4 Codezeilen nützliche Arbeit leisten.
Und dort stießen wir auf eine Reihe von Fragen, bis zu dem Punkt, dass wir ohne die Spezifikation nicht einmal alle möglichen Ergebnisse korrekt berechnen könnten. Threads und Synchronisationsprimitive sind eine sehr schwierige Sache, deren Verwendung in einigen Fällen sicherlich gerechtfertigt ist. Grundsätzlich beziehen sich diese Fälle auf die Leistung.
Entschuldigung, ich beziehe mich viel auf Elizarov, aber was kann ich tun, wenn eine Person wirklich Erfahrung auf diesem Gebiet hat? Also hat er einen weiteren wunderbaren
Bericht, "Millionen von Zitaten pro Sekunde in reinem Java", in dem er sagt, dass ein unveränderlicher Zustand gut ist, aber ich werde meine Millionen von Zitaten nicht in jeden Stream kopieren, sorry. Aber nicht alle haben Millionen von Zitaten, viele haben natürlich bescheidenere Aufgaben. Gibt es wettbewerbsfähige Programmiermodelle, mit denen Sie JMM vergessen und dennoch sicheren, wettbewerbsfähigen Code schreiben können?
Wenn Sie sich wirklich für diese Frage interessieren, empfehle ich Paul Butchers Buch „Sieben Modelle des Wettbewerbs in sieben Wochen. Wir enthüllen die Geheimnisse der Flüsse. “ Leider war es nicht möglich, genügend Informationen über den Autor zu finden, aber das Buch sollte Ihre Augen für neue Paradigmen öffnen. Leider habe ich keine Erfahrung mit vielen anderen Wettbewerbsmodellen, daher habe ich die Rezension aus diesem Buch erhalten.
Beantwortung der obigen Frage. Soweit ich weiß, gibt es wettbewerbsfähige Programmiermodelle, die den Bedarf an Kenntnissen über die Nuancen von JMM zumindest erheblich reduzieren können. Wenn es jedoch einen veränderlichen Zustand und Flüsse gibt, dann vermasseln Sie keine Abstraktionen darüber, es wird immer noch einen Ort geben, an dem diese Flüsse den Zugriff auf den Zustand synchronisieren sollten. Eine andere Frage ist, dass Sie den Zugriff wahrscheinlich nicht selbst synchronisieren müssen. Ein Framework kann dies beispielsweise beantworten. Aber wie gesagt, früher oder später kann es zu einer Abstraktion kommen.
Sie können den veränderlichen Status überhaupt ausschließen. In der Welt der funktionalen Programmierung ist dies übliche Praxis. Wenn es keine veränderlichen Strukturen gibt, gibt es per Definition wahrscheinlich keine Probleme mit dem gemeinsam genutzten Speicher. In der JVM gibt es Vertreter funktionaler Sprachen wie Clojure. Clojure ist eine hybride Funktionssprache, da Sie damit weiterhin Datenstrukturen ändern können, aber effizientere und sicherere Tools dafür bereitstellen.
Funktionale Sprachen sind ein großartiges Werkzeug für die Arbeit mit wettbewerbsfähigem Code. Persönlich benutze ich es nicht, weil mein Tätigkeitsbereich die mobile Entwicklung ist und es dort einfach nicht zum Mainstream gehört. Obwohl bestimmte Ansätze übernommen werden können.
Eine andere Möglichkeit, mit veränderlichen Daten zu arbeiten, besteht darin, die gemeinsame Nutzung von Daten zu verhindern. Schauspieler sind ein solches Programmiermodell. Akteure vereinfachen die Programmierung, indem sie den gleichzeitigen Zugriff auf Daten nicht zulassen. Dies wird durch die Tatsache erreicht, dass eine Funktion, die zu einem bestimmten Zeitpunkt Arbeit ausführt, nur in einem Thread arbeiten kann.
Ein Akteur kann jedoch den internen Status ändern. Da zum nächsten Zeitpunkt derselbe Akteur in einem anderen Thread ausgeführt werden kann, kann dies ein Problem sein. Das Problem kann auf verschiedene Arten gelöst werden. In Programmiersprachen wie Erlang oder Elixir, in denen das Akteurmodell ein integraler Bestandteil der Sprache ist, können Sie mithilfe der Rekursion einen Akteur mit einem neuen Status aufrufen.
In Java können Rekursionen zu teuer sein. In Java gibt es jedoch Frameworks für die bequeme Arbeit mit diesem Modell. Das wahrscheinlich beliebteste ist Akka. Akka-Entwickler haben sich um alles gekümmert. Sie können im Dokumentationsabschnitt von
Akka und im Java-Speichermodell zwei Fälle lesen, in denen der Zugriff auf einen gemeinsam genutzten Status von verschiedenen Threads aus erfolgen kann. Noch wichtiger ist jedoch, dass in der Dokumentation angegeben ist, welche Ereignisse sich auf „zuvor geschehen“ beziehen. Das heißt, Dies bedeutet, dass wir den Status des Akteurs beliebig ändern können. Wenn wir jedoch die nächste Nachricht erhalten und möglicherweise in einem anderen Thread verarbeiten, werden garantiert alle Änderungen in einem anderen Thread angezeigt.
Warum ist das Threading-Modell so beliebt?
Wir haben zwei Modelle wettbewerbsfähiger Programmierung untersucht. Tatsächlich gibt es noch mehr, die wettbewerbsfähige Programmierung einfacher und sicherer machen.
Aber warum sind Threads und Schlösser dann immer noch so beliebt?
Ich denke, der Grund ist die Einfachheit des Ansatzes. Natürlich ist es einerseits einfach, viele nicht offensichtliche Fehler mit Streams zu machen, sich in den Fuß zu schießen usw. Auf der anderen Seite
gibt es nichts Kompliziertes in den Flüssen, besonders wenn Sie nicht über die Konsequenzen nachdenken .
Zu einem bestimmten Zeitpunkt kann der Kernel einen Befehl ausführen (eigentlich nicht, Parallelität besteht auf Befehlsebene, aber jetzt spielt es keine Rolle), aber aufgrund von Multitasking können selbst auf Single-Core-Computern mehrere Programme gleichzeitig ausgeführt werden (natürlich Pseudo gleichzeitig).
Damit Multitasking funktioniert, brauchen Sie Wettbewerb. Wie wir bereits herausgefunden haben, ist Wettbewerb ohne mehrere Managementflüsse nicht möglich.
Wie viele Threads muss Ihrer Meinung nach ein Programm, das auf einem Quad-Core-Handyprozessor ausgeführt wird, so schnell und reaktionsschnell wie möglich sein?
Es kann mehrere Dutzend geben. Die Frage ist nun, warum wir so viele Threads für ein Programm benötigen, das auf Hardware ausgeführt wird, mit der Sie jeweils nur 2-4 Threads ausführen können.
Um diese Frage zu beantworten, nehmen wir an, dass nur unser Programm auf dem Gerät ausgeführt wird und sonst nichts. Wie würden wir die uns zur Verfügung gestellten Ressourcen verwalten?
Sie können einen Kern für die Benutzeroberfläche und den Rest des Kernels für alle anderen Aufgaben angeben.
Wenn beispielsweise einer der Threads blockiert ist, kann der Thread zum Speichercontroller gehen und auf eine Antwort warten, dann erhalten wir einen blockierten Kernel.Welche Technologien gibt es, um das Problem zu lösen?Es gibt Threads in Java, wir können viele Threads erstellen, und dann können andere Threads Operationen ausführen, während ein Thread blockiert ist. Mit einem Werkzeug wie Threads können wir unser Leben vereinfachen.Der Ansatz mit Threads ist nicht kostenlos, das Erstellen von Threads benötigt normalerweise Zeit (dies wird von den Thread-Pools festgelegt), ihnen wird Speicher zugewiesen, das Wechseln zwischen Threads ist eine teure Operation. Es ist jedoch relativ einfach, mit ihnen zu programmieren. Dies ist eine massive Technologie, die in allgemeinen Sprachen wie Java so häufig verwendet wird.Java liebt Streams im Allgemeinen. Es ist nicht erforderlich, für jede Aktion einen Stream zu erstellen. Es gibt übergeordnete Dinge wie Executors, mit denen Sie mit Pools arbeiten und skalierbareren und flexibleren Code schreiben können. Streams sind sehr praktisch. Sie können eine Blockierungsanforderung an das Netzwerk senden und die Ergebnisverarbeitung in die nächste Zeile schreiben. Selbst wenn wir einige Sekunden auf das Ergebnis warten, können wir dennoch andere Aufgaben ausführen, da das Betriebssystem die Verteilung der Prozessorzeit zwischen den Threads übernimmt.Streams sind nicht nur in der Backend-Entwicklung beliebt. In der mobilen Entwicklung wird es als ganz normal angesehen, Dutzende von Streams zu erstellen, damit Sie einen Stream für einige Sekunden blockieren und darauf warten können, dass Daten über das Netzwerk oder Daten aus dem Socket heruntergeladen werden.Sprachen wie Erlang oder Clojure sind immer noch eine Nische, und daher sind die von ihnen verwendeten wettbewerbsfähigen Programmiermodelle nicht so beliebt. Die Prognosen für sie sind jedoch am optimistischsten.Schlussfolgerungen
Wenn Sie auf der JVM-Plattform entwickeln, müssen Sie die von der Plattform angegebenen Spielregeln akzeptieren. Dies ist die einzige Möglichkeit, normalen Multithread-Code zu schreiben. Es ist sehr wünschenswert, den Kontext von allem zu verstehen, was passiert, damit es einfacher ist, die Spielregeln zu akzeptieren. Es ist noch besser, sich umzuschauen und sich mit anderen Paradigmen vertraut zu machen, obwohl Sie vom U-Boot aus nichts erreichen können, aber neue Ansätze und Werkzeuge entdecken können.Zusätzliche Materialien
Ich habe versucht, im Text des Artikels Links zu Quellen zu platzieren, aus denen ich Informationen erhalten habe.Im Allgemeinen ist JMM-Material im Internet leicht zu finden. Hier werde ich Links zu zusätzlichem Material veröffentlichen, das mit JMM in Verbindung steht und möglicherweise nicht sofort auffällt.Lesen- Alexey Shipilevs Blog - Ich weiß, was offensichtlich ist, aber es ist nur eine Sünde, ganz zu schweigen davon
- Cheremin Ruslans Blog - er hat in letzter Zeit nicht aktiv geschrieben, Sie müssen nach seinen alten Einträgen im Blog suchen, glauben Sie mir, es lohnt sich - es gibt eine Quelle
- Habr Gleb Smirnov - es gibt ausgezeichnete Artikel über Multithreading und das Speichermodell
- Roman Elizarovs Blog wird aufgegeben, aber archäologische Ausgrabungen müssen durchgeführt werden. Im Allgemeinen hat Roman viel getan, um die Menschen in der Theorie der Multithread-Programmierung zu unterrichten. Suchen Sie in den Medien danach.
PodcastsThemen, die ich besonders interessant fand. Es geht nicht um JMM, es geht um die Hölle, die in der Drüse geschieht. Aber nachdem ich ihnen zugehört habe, möchte ich die Schöpfer von JMM küssen, die uns vor all dem geschützt haben.VideoAchten Sie neben den Reden der oben genannten Personen auch auf das akademische Video.