Dieser Artikel ist eine autorisierte Übersetzung des ursprünglichen Beitrags . Die Übersetzung wurde mit freundlicher Unterstützung der Jungs von PVS-Studio gemacht. Danke Jungs!Was mich dazu ermutigt hat, diesen Artikel zu schreiben, ist eine beträchtliche Menge an Materialien zur statischen Analyse, die in letzter Zeit zunehmend aufgetaucht sind. Erstens ist dies ein
Blog von PVS-Studio , das sich aktiv dafür einsetzt, dass Habr Bewertungen von Fehlern veröffentlicht, die von seinem Tool in Open-Source-Projekten gefunden wurden. PVS-Studio hat kürzlich die
Java-Unterstützung implementiert, und natürlich konnten sich Entwickler von IntelliJ IDEA, dessen integrierter Analysator heute wahrscheinlich der fortschrittlichste für Java ist,
nicht fernhalten .
Wenn ich diese Bewertungen lese, habe ich das Gefühl, dass es sich um ein magisches Elixier handelt: Klicken Sie auf die Schaltfläche, und hier ist es - die Liste der Fehler direkt vor Ihren Augen. Es scheint, dass mit zunehmender Weiterentwicklung der Analysegeräte immer mehr Fehler gefunden werden und Produkte, die von diesen Robotern gescannt werden, ohne unser Zutun immer besser werden.
Nun, aber es gibt keine magischen Elixiere. Ich möchte darüber sprechen, was in Posts wie "Hier sind Dinge, die unser Roboter finden kann" normalerweise nicht gesprochen wird: Was Analysatoren nicht können, was ihr eigentlicher Teil und Platz im Prozess der Softwarebereitstellung ist und wie sie implementiert werden die Analyse richtig.
 Ratsche (Quelle: Wikipedia ).
Ratsche (Quelle: Wikipedia ).Was statische Analysatoren niemals können
Was ist die Analyse des Quellcodes aus praktischer Sicht? Wir nehmen die Quelldateien und erhalten in kurzer Zeit einige Informationen über die Systemqualität (viel kürzer als ein Testlauf). Die hauptsächliche und mathematisch unüberwindbare Einschränkung besteht darin, dass wir auf diese Weise nur eine sehr begrenzte Teilmenge von Fragen zum analysierten System beantworten können.
Das bekannteste Beispiel für eine Aufgabe, die mit statischer Analyse nicht lösbar ist, ist ein
Halteproblem : Dies ist ein Theorem, das beweist, dass man keinen allgemeinen Algorithmus ausarbeiten kann, der definiert, ob ein Programm mit einem bestimmten Quellcode für immer geloopt oder abgeschlossen ist das letzte Mal. Die Erweiterung dieses Theorems ist ein
Rice-Theorem , das behauptet, dass für jede nicht triviale Eigenschaft berechenbarer Funktionen die Frage, ob ein gegebenes Programm eine Funktion mit dieser Eigenschaft berechnet, eine algorithmisch unlösbare Aufgabe ist. Beispielsweise können Sie keinen Analysator schreiben, der anhand des Quellcodes bestimmt, ob das analysierte Programm eine Implementierung eines bestimmten Algorithmus ist, beispielsweise eines, der das Quadrieren einer Ganzzahl berechnet.
Somit weist die Funktionalität von statischen Analysatoren unüberwindbare Einschränkungen auf. Der statische Analysator kann niemals alle Fälle von beispielsweise "Nullzeiger-Ausnahme" in Sprachen ohne die
Leersicherheit erkennen . Oder erkennen Sie alle Vorkommen von "Attribut nicht gefunden" in dynamisch typisierten Sprachen. Alles, was der perfekteste statische Analysator tun kann, ist, bestimmte Fälle zu erfassen. Die Anzahl von ihnen unter allen möglichen Problemen mit Ihrem Quellcode ist ohne Übertreibung ein Tropfen auf den heißen Stein.
Statische Analyse ist keine Suche nach Fehlern
Hier ist eine Schlussfolgerung, die sich aus dem Obigen ergibt: Eine statische Analyse ist nicht der Weg, um die Anzahl der Fehler in einem Programm zu verringern. Ich würde Folgendes behaupten: Wenn es zuerst auf Ihr Projekt angewendet wird, findet es "amüsante" Stellen im Code, findet aber höchstwahrscheinlich keine Mängel, die die Qualität Ihres Programms beeinträchtigen.
Beispiele für Fehler, die von Analysatoren automatisch gefunden werden, sind beeindruckend. Wir sollten jedoch nicht vergessen, dass diese Beispiele durch Scannen einer großen Anzahl von Codebasen anhand relativ einfacher Regeln gefunden wurden. Auf die gleiche Weise finden Hacker, die die Möglichkeit haben, mehrere einfache Passwörter für eine große Anzahl von Konten auszuprobieren, die Konten schließlich mit einem einfachen Passwort.
Bedeutet dies, dass keine statische Analyse erforderlich ist? Natürlich nicht! Es sollte aus demselben Grund angewendet werden, aus dem Sie möglicherweise jedes neue Kennwort in der Stoppliste nicht sicherer Kennwörter überprüfen möchten.
Statische Analyse ist mehr als die Suche nach Fehlern
Tatsächlich sind die Aufgaben, die durch die Analyse in der Praxis gelöst werden können, viel umfassender. Da die statische Analyse im Allgemeinen jede Überprüfung des Quellcodes darstellt, die vor der Ausführung durchgeführt wird. Hier sind einige Dinge, die Sie tun können:
- Eine Überprüfung des Codierungsstils im weitesten Sinne dieses Wortes. Es umfasst sowohl eine Überprüfung der Formatierung als auch eine Suche nach der Verwendung leerer / unnötiger Klammern, die Festlegung von Schwellenwerten für Metriken wie die Anzahl der Zeilen / die zyklomatische Komplexität einer Methode usw. - alles Dinge, die die Lesbarkeit und Wartbarkeit von Code erschweren. In Java repräsentiert Checkstyle ein Tool mit einer solchen Funktionalität, in Python -
flake8 . Solche Programme werden üblicherweise als "Linters" bezeichnet. - Es kann nicht nur ausführbarer Code analysiert werden. Ressourcen wie JSON-, YAML-, XML- und
.properties Dateien können (und müssen!) Automatisch auf ihre Gültigkeit überprüft werden. Der Grund dafür ist, dass es besser ist, herauszufinden, dass beispielsweise die JSON-Struktur aufgrund der ungepaarten Anführungszeichen in der frühen Phase der automatisierten Überprüfung einer Pull-Anforderung beschädigt ist, als dies während der Testausführung oder zur Laufzeit nicht der Fall ist es? Es gibt einige relevante Tools, zum Beispiel YAMLlint , JSONLint und xmllint . - Das Kompilieren (oder Parsen für dynamische Programmiersprachen) ist auch eine Art statische Analyse. Normalerweise können Compiler Warnungen ausgeben, die auf Probleme mit der Qualität des Quellcodes hinweisen, und sie sollten nicht ignoriert werden.
- Manchmal wird die Kompilierung nicht nur auf ausführbaren Code angewendet. Wenn Sie beispielsweise über eine Dokumentation im AsciiDoctor- Format verfügen und diese dann in HTML / PDF kompilieren, kann das AsciiDoctor ( Maven-Plugin ) Warnungen ausgeben, z. B. bei fehlerhaften internen Links. Dies ist ein wichtiger Grund, eine Pull-Anforderung mit Dokumentationsänderungen nicht zu akzeptieren.
- Die Rechtschreibprüfung ist auch eine Art statische Analyse. Das Dienstprogramm aspell kann die Rechtschreibung nicht nur in der Dokumentation, sondern auch im Quellcode von Programmen (Kommentare und Literale) in verschiedenen Programmiersprachen wie C / C ++, Java und Python überprüfen. Ein Rechtschreibfehler in der Benutzeroberfläche oder Dokumentation ist ebenfalls ein Fehler!
- Konfigurationstests stellen tatsächlich eine Form der statischen Analyse dar, da sie während des Ausführungsprozesses keinen Quellcode ausführen, obwohl Konfigurationstests als
pytest ausgeführt werden.
Wie wir sehen können, spielt die Suche nach Fehlern in dieser Liste die geringste Rolle, und alles andere ist verfügbar, wenn kostenlose Open-Source-Tools verwendet werden.
Welcher dieser statischen Analysetypen sollte in Ihrem Projekt verwendet werden? Klar, je mehr desto besser! Wichtig ist hier eine ordnungsgemäße Implementierung, auf die weiter eingegangen wird.
Eine Bereitstellungspipeline als mehrstufiger Filter und statische Analyse als erste Stufe
Eine Pipeline mit einem Fluss von Änderungen (von Änderungen des Quellcodes bis zur Lieferung in der Produktion) ist eine klassische Metapher für die kontinuierliche Integration. Die Standardsequenz der Stufen dieser Pipeline sieht wie folgt aus:
- statische Analyse
- Zusammenstellung
- Unit-Tests
- Integrationstests
- UI-Tests
- manuelle Überprüfung
Änderungen, die in der N-ten Stufe der Pipeline abgelehnt wurden, werden in Stufe N + 1 nicht weitergeleitet.
Warum so und nicht anders? In dem Teil der Pipeline, der sich mit Tests befasst, erkennen Tester die bekannte Testpyramide:
 Testpyramide. Quelle: der Artikel von Martin Fowler.
Testpyramide. Quelle: der Artikel von Martin Fowler.Am Ende dieser Pyramide befinden sich Tests, die einfacher zu schreiben sind, schneller ausgeführt werden und nicht dazu neigen, falsch positive Ergebnisse zu erzielen. Daher sollte es mehr davon geben, sie sollten den größten Teil des Codes abdecken und zuerst ausgeführt werden. An der Spitze der Pyramide ist die Situation ganz anders, daher sollte die Anzahl der Integrations- und UI-Tests auf das erforderliche Minimum reduziert werden. Menschen in dieser Kette sind die teuerste, langsamste und unzuverlässigste Ressource. Sie befinden sich also ganz am Ende und erledigen die Arbeit nur, wenn in den vorherigen Schritten keine Fehler festgestellt wurden. In den Teilen, die nicht mit dem Testen zusammenhängen, wird die Pipeline nach denselben Prinzipien gebaut!
Ich möchte die Analogie in Form eines mehrstufigen Systems der Wasserfiltration vorschlagen. Schmutziges Wasser (Änderungen mit Defekten) wird im Eingang zugeführt, und als Ausgang benötigen wir sauberes Wasser, das nicht alle unerwünschten Verunreinigungen enthält.
 Mehrstufiger Filter. Quelle: Wikimedia Commons
Mehrstufiger Filter. Quelle: Wikimedia CommonsWie Sie vielleicht wissen, sind Reinigungsfilter so konzipiert, dass in jeder nachfolgenden Stufe Verunreinigungspartikel kleinerer Größe entfernt werden können. Eingangsstufen der Grobreinigung haben einen höheren Durchsatz und niedrigere Kosten. In unserer Analogie bedeutet dies, dass Gates mit Eingangsqualität eine höhere Leistung aufweisen, weniger Startaufwand erfordern und weniger Betriebskosten verursachen. Die Rolle der statischen Analyse, die (wie wir jetzt verstehen) nur die schwerwiegendsten Mängel beseitigen kann, ist die Rolle des Sumpffilters als erste Stufe der mehrstufigen Reiniger.
Die statische Analyse verbessert nicht die Qualität des Endprodukts an sich, genauso wie der "Sumpf" das Wasser nicht trinkbar macht. In Verbindung mit anderen Pipeline-Elementen ist seine Bedeutung jedoch offensichtlich. Obwohl in einem mehrstufigen Filter die Ausgangsstufen möglicherweise alles entfernen können, was die Eingangsstufen können, sind wir uns der Konsequenzen bewusst, die sich ergeben, wenn versucht wird, nur mit Stufen der Feinreinigung ohne Eingangsstufen auszukommen.
Der Zweck des "Sumpfes" besteht darin, nachfolgende Stufen von der Erfassung sehr grober Defekte zu entlasten. Beispielsweise sollte eine Person, die eine Codeüberprüfung durchführt, nicht durch falsch formatierte Verstöße gegen Code- und Codestandards (wie redundante Klammern oder zu tief verschachtelte Verzweigungen) abgelenkt werden. Fehler wie NPE sollten von den Komponententests erfasst werden. Wenn der Analysator jedoch zuvor anzeigt, dass ein Fehler unvermeidlich auftreten soll, beschleunigt dies die Behebung erheblich.
Ich nehme an, es ist jetzt klar, warum statische Analysen die Qualität des Produkts bei gelegentlicher Anwendung nicht verbessern und kontinuierlich angewendet werden müssen, um Änderungen mit schwerwiegenden Fehlern zu filtern. Die Frage, ob die Anwendung eines statischen Analysegeräts die Qualität Ihres Produkts verbessert, entspricht in etwa der Frage: "Wenn wir Wasser aus schmutzigen Teichen entnehmen, wird sich die Trinkqualität verbessern, wenn wir es durch ein Sieb passieren?"
Einführung in ein Legacy-Projekt
Ein wichtiges praktisches Thema: Wie kann eine statische Analyse im kontinuierlichen Integrationsprozess als "Qualitätsgatter" implementiert werden? Bei automatisierten Tests ist alles klar: Es gibt eine Reihe von Tests. Ein Fehler bei einem dieser Tests ist ein ausreichender Grund zu der Annahme, dass ein Build kein Qualitätsgatter passiert hat. Der Versuch, das Gate anhand der Ergebnisse der statischen Analyse auf die gleiche Weise festzulegen, schlägt fehl: Es gibt zu viele Analysewarnungen für Legacy-Code. Sie möchten nicht alle ignorieren. Andererseits ist es unmöglich, die Produktlieferung zu stoppen, nur weil Es enthält Warnungen des Analysators.
Für jedes Projekt gibt der Analysator eine große Anzahl von Warnungen aus, die beim ersten Mal angewendet werden. Die meisten Warnungen haben nichts mit der ordnungsgemäßen Funktion des Produkts zu tun. Es wird unmöglich sein, alle zu reparieren, und viele von ihnen müssen überhaupt nicht repariert werden. Am Ende wissen wir, dass unser Produkt bereits vor Einführung der statischen Analyse funktioniert!
Infolgedessen beschränken sich viele Entwickler darauf, gelegentlich statische Analysen zu verwenden oder diese nur im informativen Modus zu verwenden, bei dem beim Erstellen eines Projekts ein Analysebericht abgerufen wird. Dies ist gleichbedeutend mit dem Fehlen jeglicher Analyse, denn wenn wir bereits viele Warnungen haben, bleibt das Auftreten einer anderen (wie schwerwiegend auch immer) beim Ändern des Codes unbemerkt.
Hier sind die bekannten Methoden zur Einführung von Qualitätstoren:
- Festlegen der Begrenzung der Gesamtzahl der Warnungen oder der Anzahl der Warnungen, geteilt durch die Anzahl der Codezeilen. Es funktioniert schlecht, da ein solches Tor Änderungen mit neuen Fehlern durchlässt, bis deren Grenze überschritten wird.
- Markieren Sie alle alten Warnungen im Code als in einem bestimmten Moment ignoriert und erstellen Sie einen Fehler, wenn neue Warnungen angezeigt werden. Solche Funktionen können von PVS-Studio und einigen anderen Tools bereitgestellt werden, z. B. Codacy. Ich habe noch nicht mit PVS-Studio gearbeitet. Meine Erfahrung mit Codacy besteht darin, dass die Unterscheidung zwischen einem alten und einem neuen Fehler ein komplizierter und nicht immer funktionierender Algorithmus ist, insbesondere wenn sich Dateien erheblich ändern oder umbenannt werden. Meines Wissens könnte Codacy neue Warnungen in einer Pull-Anfrage übersehen und gleichzeitig eine Pull-Anfrage aufgrund von Warnungen behindern, die nicht mit Änderungen im Code dieser PR zusammenhängen.
- Meiner Meinung nach ist die effektivste Lösung die im Buch " Continuous Delivery " beschriebene "Ratschen" -Methode. Die Grundidee ist, dass die Anzahl der Warnungen zur statischen Analyse eine Eigenschaft jeder Version ist und nur solche Änderungen zulässig sind, die die Gesamtzahl der Warnungen nicht erhöhen.
Ratsche
Es funktioniert folgendermaßen:
- In der Anfangsphase wird in den Release-Metadaten ein Eintrag zu einer Reihe von Warnungen hinzugefügt, die von den Codeanalysatoren gefunden wurden. Daher wird beim Erstellen des Hauptzweigs nicht nur "Release 7.0.2" in Ihren Repository-Manager geschrieben, sondern auch "Release 7.0.2, das 100500 Checkstyle-Warnungen enthält". Wenn Sie den erweiterten Repositorys-Manager (z. B. Artifactory) verwenden, können Sie solche Metadaten zu Ihrer Version problemlos aufbewahren.
- Beim Erstellen vergleicht jede Pull-Anforderung die Anzahl der resultierenden Warnungen mit ihrer Anzahl in einer aktuellen Version. Wenn ein PR zu einem Wachstum dieser Zahl führt, besteht der Code bei der statischen Analyse kein Qualitätsgatter. Wenn die Anzahl der Warnungen reduziert oder nicht geändert wird, ist sie erfolgreich.
- Bei der nächsten Veröffentlichung wird die neu berechnete Nummer erneut in die Metadaten geschrieben.
Daher wird die Anzahl der Warnungen langsam aber sicher gegen Null konvergieren. Natürlich kann das System getäuscht werden, indem eine neue Warnung eingeführt und die einer anderen Person korrigiert wird. Dies ist normal, da es auf lange Sicht das Ergebnis ergibt: Warnungen werden behoben, normalerweise nicht einzeln, sondern nach Gruppen eines bestimmten Typs, und alle leicht zu lösenden Warnungen werden relativ schnell behoben.
Diese Grafik zeigt die Gesamtzahl der Checkstyle-Warnungen für sechs Monate einer solchen "Ratsche" in
einem unserer OpenSource-Projekte . Die Anzahl der Warnungen wurde erheblich reduziert, und dies geschah natürlich parallel zur Entwicklung des Produkts!
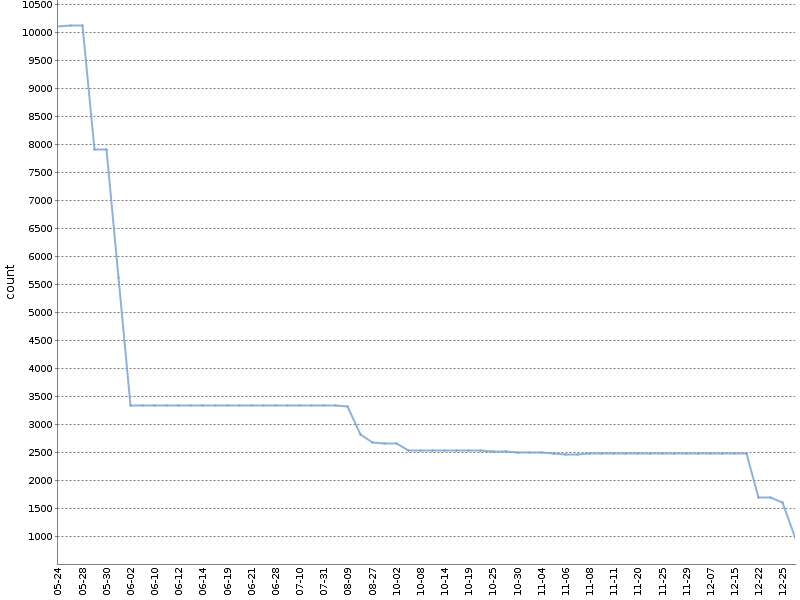
Ich wende die geänderte Version dieser Methode an. Ich zähle die Warnungen für verschiedene Projektmodule und Analysetools separat. Die dabei gebildete YAML-Datei mit Metadaten zum Build sieht folgendermaßen aus:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
In jedem fortschrittlichen CI-System kann eine "Ratsche" für alle statischen Analysetools implementiert werden, ohne auf Plugins und Tools von Drittanbietern angewiesen zu sein. Jeder der Analysatoren gibt seinen Bericht in einem einfachen Text- oder XML-Format aus, das leicht analysiert werden kann. Danach müssen Sie nur noch die erforderliche Logik in ein CI-Skript schreiben. Sie können
hier oder
hier sehen, wie es in unseren auf Jenkins und Artifactory basierenden Quellprojekten implementiert wird. Beide Beispiele hängen von der Bibliothek
ratchetlib ab : Die Methode
countWarnings() in üblicher Weise XML-Tags in Dateien, die von Checkstyle und Spotbugs generiert wurden, und
compareWarningMaps() implementiert
compareWarningMaps() diese Ratsche und gibt einen Fehler aus, falls die Anzahl der Warnungen in einer der
compareWarningMaps() Die Kategorien nehmen zu.
Eine interessante Art der "Ratschen" -Implementierung ist möglich, um die Rechtschreibung von Kommentaren, Textliteralen und Dokumentationen mit Aspell zu analysieren. Wie Sie vielleicht wissen, sind bei der Überprüfung der Rechtschreibung nicht alle im Standardwörterbuch unbekannten Wörter falsch, sondern können dem benutzerdefinierten Wörterbuch hinzugefügt werden. Wenn Sie ein benutzerdefiniertes Wörterbuch zu einem Teil des Quellcode-Projekts machen, kann das Qualitätsgatter für die Rechtschreibung wie folgt formuliert werden: Wenn Sie aspell mit einem Standardwörterbuch und einem benutzerdefinierten Wörterbuch ausführen,
sollten keine Rechtschreibfehler gefunden werden.
Die Wichtigkeit des Fixierens der Analyzer-Version
Abschließend muss Folgendes beachtet werden: Unabhängig davon, wie Sie die Analyse in Ihre Lieferpipeline einführen, muss die Analysatorversion festgelegt werden. Wenn Sie den Analysator sich spontan aktualisieren lassen, können beim Erstellen einer weiteren Pull-Anforderung neue Fehler auftreten, die sich nicht auf geänderten Code beziehen, sondern auf die Tatsache, dass der neue Analysator einfach mehr Fehler erkennen kann. Dies unterbricht Ihren Prozess der Überprüfung von Pull-Anforderungen. Das Upgrade des Analysators muss eine bewusste Aktion sein. Auf jeden Fall ist die starre Versionsfixierung jeder Build-Komponente eine allgemeine Anforderung und ein Thema für ein anderes Thema.
Schlussfolgerungen
- Bei der statischen Analyse werden keine Fehler gefunden und die Qualität Ihres Produkts durch einen einzelnen Durchlauf nicht verbessert. Nur die kontinuierliche Ausführung im Lieferprozess wirkt sich positiv aus.
- Die Fehlersuche ist überhaupt nicht das Hauptziel der Analyse. Die überwiegende Mehrheit der nützlichen Funktionen ist in OpenSource-Tools verfügbar.
- Führen Sie Qualitätsgatter anhand der Ergebnisse der statischen Analyse in der ersten Phase der Lieferpipeline ein, indem Sie die "Ratsche" für Legacy-Code verwenden.
Referenzen
- Kontinuierliche Lieferung
- Alexey Kudryavtsev: Programmanalyse: Sind Sie ein guter Entwickler? Bericht über verschiedene Analysemethoden von Code, nicht nur statisch!
Auszüge aus der Diskussion des Originalartikels
Evgeniy RyzhkovIvan, danke für den Artikel und dafür, dass er uns bei unserer Arbeit geholfen hat, die Technologie der statischen Code-Analyse bekannt zu machen. Sie haben absolut Recht, dass Artikel aus dem PVS-Studio-Blog bei unreifen Köpfen diese beeinflussen und zu Schlussfolgerungen wie "Ich werde den Code nur einmal überprüfen, die Fehler beheben und das wird reichen" führen können. Dies ist mein persönlicher Schmerz, den ich schon seit einigen Jahren nicht mehr überwinden kann. Tatsache ist, dass Artikel über Projektprüfungen:
- Verursacht Wow-Effekt bei Menschen. Die Leute lesen gerne, wie Entwickler solcher Unternehmen wie Google, Epic Games, Microsoft und anderer Unternehmen manchmal scheitern. Die Leute denken gerne, dass jeder falsch liegen kann, selbst Branchenführer machen Fehler. Leute lesen gerne solche Artikel.
- Darüber hinaus können Autoren Artikel über den Ablauf schreiben, ohne sich Gedanken machen zu müssen. Natürlich möchte ich unsere Leute, die diese Artikel schreiben, nicht beleidigen. Es ist jedoch viel schwieriger, jedes Mal einen neuen Artikel zu verfassen, als einen Artikel über eine Projektprüfung zu schreiben (ein Dutzend Fehler, ein paar Witze, verwechseln Sie ihn mit Einhornbildern).
Sie haben einen sehr guten Artikel geschrieben. Ich habe auch ein paar Artikel zu diesem Thema. Haben Sie auch andere Kollegen. Darüber hinaus besuche ich verschiedene Unternehmen mit einem Bericht zum Thema "Philosophie der statischen Code-Analyse", in dem ich über den Prozess selbst spreche, aber nicht über bestimmte Fehler.
Es ist jedoch nicht möglich, 10 Artikel über den Prozess zu schreiben. Um für unser Produkt zu werben, müssen wir regelmäßig viel schreiben. Ich möchte ein paar weitere Punkte aus dem Artikel mit einem separaten Kommentar kommentieren, um die Diskussion bequemer zu gestalten.
In diesem kurzen
Artikel geht es um die „Philosophie der statischen Code-Analyse“, die mein Thema beim Besuch verschiedener Unternehmen ist.
Ivan PonomarevEvgeniy, vielen Dank für die informative Bewertung des Artikels! Ja, Sie haben meine Besorgnis in der Post über die Auswirkungen auf die "unreifen Köpfe" absolut richtig bekommen!
Hier ist niemand schuld, da die Autoren der Artikel / Berichte über
Analysegeräte nicht darauf abzielen, Artikel / Berichte über die
Analyse zu erstellen. Aber nach ein paar kürzlich veröffentlichten Beiträgen von
Andrey2008 und
lany entschied ich, dass ich nicht mehr schweigen konnte.
Evgeniy RyzhkovIvan, wie oben geschrieben, werde ich drei Punkte des Artikels kommentieren. Es bedeutet, dass ich denen zustimme, die ich nicht kommentiere.
1.
Die Standardsequenz der Stufen dieser Pipeline sieht wie folgt aus ...Ich stimme nicht zu, dass der erste Schritt die statische Analyse ist und nur der zweite die Kompilierung. Ich glaube, dass die Überprüfung der Kompilierung im Durchschnitt schneller und logischer ist als eine sofortige "schwerere" statische Analyse. Wir können diskutieren, wenn Sie anders denken.
2.
Ich habe noch nicht mit PVS-Studio gearbeitet. Meine Erfahrung mit Codacy besteht darin, dass die Unterscheidung zwischen einem alten und einem neuen Fehler ein komplizierter und nicht immer funktionierender Algorithmus ist, insbesondere wenn sich Dateien erheblich ändern oder umbenannt werden.In PVS-Studio ist es unglaublich praktisch. Dies ist eines der Hauptmerkmale des Produkts, das in den Artikeln leider nur schwer zu beschreiben ist. Deshalb sind die Leute mit dem Produkt nicht sehr vertraut. Wir sammeln Informationen über die vorhandenen Fehler in einer Basis. Und nicht nur "der Dateiname und die Zeile", sondern auch zusätzliche Informationen (Raute von drei Zeilen - aktuell, vorher, weiter), damit wir sie im Falle einer Verschiebung des Codefragments immer noch finden können. Daher verstehen wir bei geringfügigen Änderungen immer noch, dass es sich um einen alten Fehler handelt. Und der Analysator beschwert sich nicht darüber. Jetzt kann jemand sagen: "Nun, was ist, wenn sich der Code stark geändert hat, dann würde dies nicht funktionieren, und Sie beschweren sich darüber, als wäre es der neu geschriebene?" Ja Wir beschweren uns. Aber eigentlich ist das neuer Code. Wenn sich der Code stark geändert hat, ist dies jetzt ein neuer Code und nicht mehr der alte.
Dank dieser Funktion haben wir persönlich an der Implementierung des Projekts mit 10 Millionen Zeilen C ++ - Code teilgenommen, der jeden Tag von einer Reihe von Entwicklern "berührt" wird. Alles verlief ohne Probleme. Daher empfehlen wir die Verwendung dieser Funktion von PVS-Studio jedem, der statische Analysen in seinen Prozess einführt. Die Option, die Anzahl der Warnungen gemäß einer Veröffentlichung festzulegen, scheint mir weniger sympathisch zu sein.
3.
Unabhängig davon, wie Sie Ihre Lieferpipeline-Analyse einführen, muss die Analysatorversion festgelegt werdenDem kann ich nicht zustimmen. Ein definitiver Gegner eines solchen Ansatzes. Ich empfehle, den Analysator im automatischen Modus zu aktualisieren. Da fügen wir neue Diagnosen hinzu und verbessern die alten. Warum? Zunächst erhalten Sie Warnungen vor neuen echten Fehlern. Zweitens könnten einige alte Fehlalarme verschwinden, wenn wir sie überwinden.
Das Nicht-Aktualisieren des Analysators entspricht dem Nicht-Aktualisieren von Antiviren-Datenbanken („Was passiert, wenn sie über Viren benachrichtigt werden“). Wir werden hier nicht auf die wahre Nützlichkeit von Antivirensoftware als Ganzes eingehen.
Wenn Sie nach dem Upgrade der Analyzer-Version viele neue Warnungen haben, unterdrücken Sie diese, wie oben beschrieben, über diese Funktion. Aber nicht um die Version zu aktualisieren ... In der Regel aktualisieren solche Clients (sicher gibt es einige) die Analyseversion jahrelang nicht. Keine Zeit dafür. Sie zahlen für die Lizenzverlängerung, verwenden jedoch nicht die neuen Versionen. Warum? Denn einmal haben sie beschlossen, eine Version zu reparieren. Das Produkt heute und vor drei Jahren ist Tag und Nacht. Es stellt sich heraus wie "Ich werde das Ticket kaufen, aber nicht kommen".
Ivan Ponomarev1. Hier hast du recht. Ich bin bereit, am Anfang einem Compiler / Parser zuzustimmen, und dies sollte sogar im Artikel geändert werden! Zum Beispiel können die berüchtigten
spotbugs nicht anders handeln, da sie kompilierten Bytecode analysieren. Es gibt exotische Fälle, zum Beispiel in der Pipeline für Ansible-Playbooks. Eine statische Analyse sollte besser vor dem Parsen festgelegt werden, da sie dort leichter ist. Aber das ist das Exotische selbst)
2.
Die Option, die Anzahl der Warnungen gemäß einer Veröffentlichung festzulegen, scheint für mich weniger sympathisch zu sein ... -
Nun ja, es ist weniger sympathisch, weniger technisch, aber sehr praktisch :-) Hauptsache, es ist eine Allgemeine Methode, mit der ich statische Analysen überall effektiv implementieren kann, selbst im gruseligsten Projekt, mit jeder Codebasis und jedem Analysator (nicht unbedingt Ihrer), unter Verwendung von Groovy- oder Bash-Skripten auf CI. Übrigens zählen wir jetzt die Warnungen für verschiedene Projektmodule und Tools separat, aber wenn wir sie granulierter (für Dateien) aufteilen, ist dies viel näher an der Methode zum Vergleichen neuer / alter. Aber wir haben uns so gefühlt und ich mochte dieses Ratschen, weil es Entwickler dazu anregt, die Gesamtzahl der Warnungen zu überwachen und diese Anzahl langsam zu verringern. Wenn wir die Methode der alten / neuen hätten, würde dies die Entwickler motivieren, die Kurve der Warnzahl zu überwachen? - wahrscheinlich ja, vielleicht nein.
Was Punkt 3 betrifft, so ist hier ein echtes Beispiel aus meiner Erfahrung. Schauen Sie sich
dieses Commit an . Woher kam es? Wir setzen Linters im TravisCI-Skript. Sie arbeiteten dort als Qualitätstore. Aber plötzlich, als eine neue Version von Ansible-lint mehr Warnungen fand, scheiterten einige Pull-Request-Builds aufgrund von Warnungen im Code, die sie nicht geändert hatten !!! Am Ende war der Prozess unterbrochen und dringende Pull-Anfragen wurden zusammengeführt, ohne die Qualitätstore zu passieren.
Niemand sagt, dass es nicht notwendig ist, die Analysatoren zu aktualisieren. Natürlich ist es das! Wie alle anderen Build-Komponenten. Aber es muss ein bewusster Prozess sein, der sich im Quellcode widerspiegelt. Und jedes Mal hängen die Aktionen von den Umständen ab (ob wir die erkannten Warnungen erneut beheben oder nur die "Ratsche" zurücksetzen).
Evgeniy RyzhkovWenn ich gefragt werde: "Gibt es eine Möglichkeit, jedes Commit in PVS-Studio zu überprüfen?", Antworte ich, dass dies der Fall ist. Und dann füge hinzu: "Nur um Gottes willen, scheitere nicht am Build, wenn PVS-Studio etwas findet!" Denn sonst wird PVS-Studio früher oder später als störend empfunden. Und es gibt Situationen, in denen es notwendig ist, schnell ein Commit durchzuführen, anstatt mit den Tools zu kämpfen, die das Commit nicht passieren lassen.
Meiner Meinung nach ist es in diesem Fall schlecht, den Build nicht zu bestehen. Es ist gut, Nachrichten an die Autoren des Problemcodes zu senden.
Ivan PonomarevMeiner Meinung nach gibt es kein "wir müssen uns schnell festlegen". Dies ist alles nur ein schlechter Prozess. Ein guter Prozess erzeugt Geschwindigkeit, nicht weil wir ein Prozess- / Qualitätsgatter durchbrechen, wenn wir es „schnell erledigen“ müssen.
Dies widerspricht nicht der Tatsache, dass wir auf einigen Klassen statischer Analyseergebnisse nicht scheitern können. Es bedeutet nur, dass das Tor so eingerichtet ist, dass bestimmte Arten von Befunden ignoriert werden, und für andere Befunde haben wir eine Nulltoleranz.
Mein Lieblings-Commitstrip zum Thema "schnell".Evgeniy RyzhkovIch bin definitiv ein Gegner des Ansatzes, die alte Analysatorversion zu verwenden. Was ist, wenn ein Benutzer einen Fehler in dieser Version gefunden hat? Er schreibt an einen Werkzeugentwickler und ein Werkzeugentwickler wird es sogar reparieren. Aber in der neuen Version. Für einige Clients wird niemand die alte Version unterstützen. Wenn wir nicht über Verträge im Wert von Millionen von Dollar sprechen.
Ivan PonomarevEvgeniy, wir reden überhaupt nicht darüber. Niemand sagt, wir müssen sie alt halten. Es geht darum, Versionen von Build-Komponenten-Abhängigkeiten für ihr kontrolliertes Update zu korrigieren - es ist eine gängige Disziplin, die für alles gilt, einschließlich Bibliotheken und Tools.
Evgeniy RyzhkovIch verstehe, wie "es theoretisch gemacht werden sollte". Aber ich sehe nur zwei Entscheidungen der Kunden. Bleib entweder beim neuen oder beim alten. Wir haben also FAST keine solchen Situationen, in denen „wir Disziplin haben und bei zwei Veröffentlichungen hinter der aktuellen Version zurückbleiben“. Es ist nicht wichtig für mich zu sagen, ob es gut oder schlecht ist. Ich sage nur, was ich sehe.
Ivan PonomarevIch habe es verstanden Auf jeden Fall hängt alles stark davon ab, über welche Tools / Prozesse Ihre Kunden verfügen und wie sie diese verwenden. Zum Beispiel weiß ich nichts darüber, wie das alles in der C ++ - Welt funktioniert.