Vor einigen Monaten veranstalteten unsere Kollegen von Google bei Kaggle einen Wettbewerb, um einen Klassifikator für Bilder zu erstellen, die im gefeierten
Spiel „Quick, Draw!“ Erhalten wurden. Das Team, an dem der Yandex-Entwickler Roman Vlasov teilnahm, belegte den vierten Platz im Wettbewerb. Während der maschinellen Lernsitzung im Januar teilte Roman die Ideen seines Teams, die endgültige Implementierung des Klassifikators und interessante Praktiken der Rivalen mit.
- Hallo allerseits! Mein Name ist Roma Vlasov, heute werde ich Ihnen von Quick, Draw! Doodle Recognition Challenge.

Unser Team bestand aus fünf Personen. Ich bin direkt vor dem Fusionsschluss zu ihr gekommen. Wir hatten Pech, wir waren ein bisschen erschüttert, aber wir waren vom Geld beschattet, und sie waren von der Position des Goldes. Und wir haben einen ehrenwerten vierten Platz belegt.
(Während des Wettbewerbs beobachteten sich die Teams in der Bewertung, die gemäß den in einem Teil des vorgeschlagenen Datensatzes gezeigten Ergebnissen gebildet wurde. Die endgültige Bewertung wurde wiederum im anderen Teil des Datensatzes gebildet. Dies geschieht, damit die Teilnehmer des Wettbewerbs ihre Algorithmen nicht an bestimmte Daten anpassen. Daher sind die Positionen im Finale beim Wechsel zwischen den Bewertungen ein wenig "sheikap" (vom englischen Aufrütteln bis zum Mischen): Bei anderen Daten kann das Ergebnis anders ausfallen. Romans Team war das erste unter den ersten drei. AU-Troika - ist Geld, Geld-Rankings Zone, da nur die ersten drei Stellen Preis Nach dem „Shake apa‚Team war bereits auf dem vierten Platz die gleiche Art und Weise das andere Team den Sieg verloren, die Position Gold -... Ed) verlassen ..
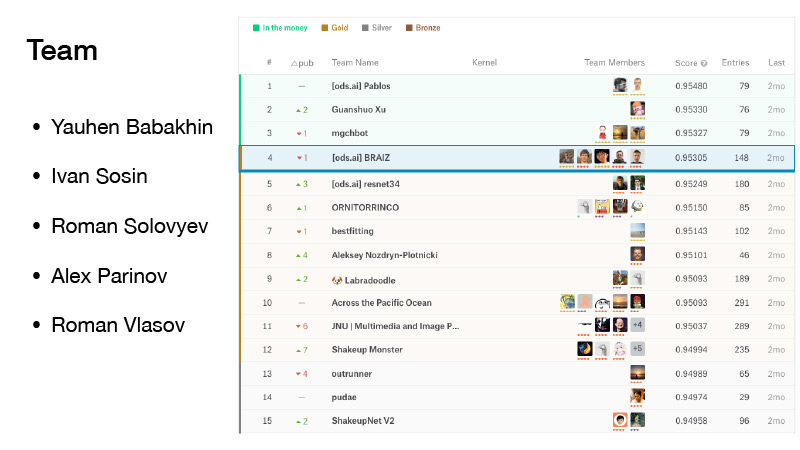
Der Wettbewerb war auch deshalb bedeutsam, weil Jewgeni Babachnin Großmeister für ihn empfing, Ivan Sosin - Meister, Roman Solovyov blieb Großmeister, Alex Parinov erhielt einen Meister, ich wurde Experte und jetzt bin ich bereits Meister.
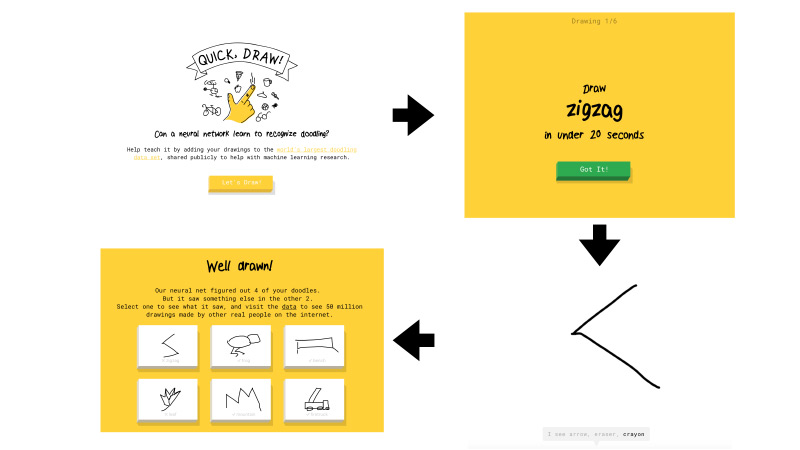
Was ist das schnell, zeichnen? Dies ist ein Dienst von Google. Google wollte die KI bekannt machen und wollte mit diesem Dienst zeigen, wie neuronale Netze funktionieren. Wenn Sie dorthin gehen, klicken Sie auf Lassen Sie uns zeichnen, und eine neue Seite wird angezeigt, auf der Sie aufgefordert werden: Zeichnen Sie einen Zickzack. Sie haben 20 Sekunden Zeit, dies zu tun. Sie versuchen, wie hier in 20 Sekunden einen Zickzack zu zeichnen. Wenn alles für Sie funktioniert, sagt das Netzwerk, dass es ein Zickzack ist und Sie weitermachen. Es gibt nur sechs solcher Bilder.
Wenn das Netzwerk von Google nicht erkennen konnte, was Sie gezeichnet haben, wurde die Aufgabe mit einem Kreuz versehen. Später werde ich Ihnen sagen, was in Zukunft bedeuten wird, ob die Zeichnung vom Netzwerk erkannt wird oder nicht.
Dieser Dienst versammelte eine ziemlich große Anzahl von Benutzern, und alle von Benutzern gezeichneten Bilder wurden protokolliert.

Es konnten fast 50 Millionen Bilder gesammelt werden. Daraus wurden der Zug- und Testtermin für unseren Wettbewerb gebildet. Übrigens sind die Datenmenge im Test und die Anzahl der Klassen nicht umsonst fett gedruckt. Ich werde etwas später darüber sprechen.
Das Datenformat war wie folgt. Dies sind nicht nur RGB-Bilder, sondern grob gesagt das Protokoll von allem, was der Benutzer getan hat. Wort ist unser Ziel, Ländercode ist, woher das Gekritzel kommt, Zeitstempel ist Zeit. Das erkannte Etikett zeigt nur an, ob das Netzwerk von Google das Bild erkannt hat oder nicht. Und das Zeichnen selbst ist eine Sequenz, eine Annäherung an die Kurve, die der Benutzer mit Punkten zeichnet. Und Timings. Dies ist die Zeit ab dem Beginn des Zeichnens des Bildes.
Die Daten wurden in zwei Formaten dargestellt. Dies ist das erste Format und das zweite ist vereinfacht. Von dort aus sägten sie Timings aus und näherten diese Punktmenge mit einer kleineren Punktmenge an. Dazu verwendeten sie
den Douglas-Pecker-Algorithmus . Sie haben eine große Anzahl von Punkten, die sich einfach einer geraden Linie annähern, aber Sie können diese Linie tatsächlich mit nur zwei Punkten approximieren. Dies ist die Idee des Algorithmus.
Die Daten wurden wie folgt verteilt. Alles ist einheitlich, aber es gibt einige Ausreißer. Als wir das Problem gelöst haben, haben wir es uns nicht angesehen. Die Hauptsache ist, dass es keine Klassen gab, die wirklich wenige sind. Wir mussten keine gewichteten Sampler und Daten-Oversampling durchführen.

Wie sahen die Bilder aus? Dies ist die Flugzeugklasse, und Beispiele davon sind als erkannt und nicht erkannt gekennzeichnet. Ihr Verhältnis lag irgendwo zwischen 1 und 9. Wie Sie sehen können, sind die Daten ziemlich verrauscht. Ich würde vorschlagen, dass dies ein Flugzeug ist. Wenn Sie nicht erkannt betrachten, ist es in den meisten Fällen nur Rauschen. Jemand hat sogar versucht, "Flugzeug" zu schreiben, aber anscheinend auf Französisch.
Die meisten Teilnehmer nahmen einfach Raster, renderten Daten aus dieser Zeilenfolge als RGB-Bilder und warfen sie in das Netzwerk. Ich habe ungefähr auf die gleiche Weise gemalt: Ich habe eine Farbpalette genommen, ich habe die erste Zeile mit einer Farbe gemalt, die am Anfang dieser Palette stand, die letzte, mit einer anderen, die am Ende der Palette war, und überall dazwischen auf dieser Palette interpoliert. Dies ergab übrigens ein besseres Ergebnis als beim Zeichnen wie auf der ersten Folie - nur schwarz.
Andere Teammitglieder wie Ivan Sosin versuchten etwas andere Ansätze zum Zeichnen. Mit einem Kanal zeichnete er einfach ein graues Bild, mit einem anderen Kanal zeichnete er jeden Strich mit einem Farbverlauf von Anfang bis Ende von 32 bis 255, und der dritte Kanal zeichnete einen Farbverlauf in allen Strichen von 32 bis 255.
Eine weitere interessante Sache ist, dass Alex Parinov Informationen per Ländercode in das Netzwerk geworfen hat.
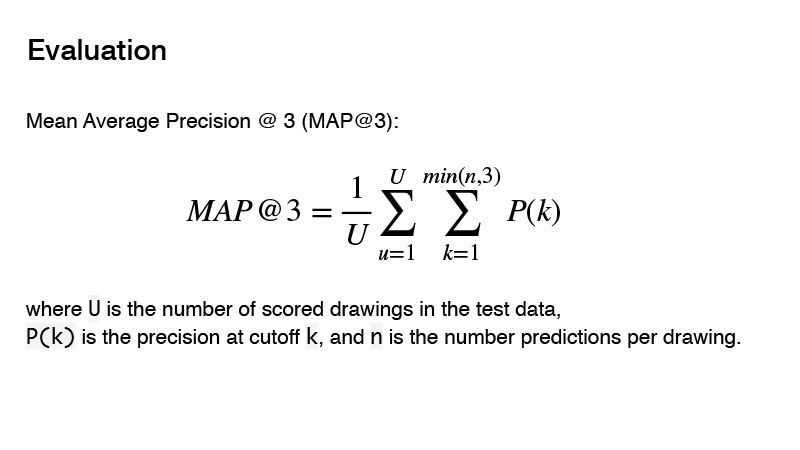
Die im Wettbewerb verwendete Metrik ist Mean Average Precision. Was ist das Wesentliche dieser Metrik für den Wettbewerb? Sie können drei Prädiktoren angeben. Wenn diese drei Prädiktoren nicht korrekt sind, erhalten Sie 0. Wenn es einen korrekten gibt, wird dessen Reihenfolge berücksichtigt. Das Ergebnis für das Ziel wird als 1 betrachtet, geteilt durch die Reihenfolge Ihrer Vorhersage. Zum Beispiel haben Sie drei Vorhersagen gemacht, und die erste ist die richtige, dann teilen Sie 1 durch 1 und erhalten 1. Wenn der Prädiktor korrekt ist und seine Reihenfolge 2 ist, dann erhalten Sie 1 durch 2, erhalten Sie 0,5. Nun, etc.

Mit der Datenvorverarbeitung - wie man Bilder zeichnet und so weiter - haben wir uns ein wenig entschieden. Welche Architekturen haben wir verwendet? Wir haben versucht, mutige Architekturen wie PNASNet, SENet und bereits klassische Architekturen wie SE-Res-NeXt zu verwenden. Sie treten zunehmend in neue Wettbewerbe ein. Es gab auch ResNet und DenseNet.



Wie haben wir das gelehrt? Alle Modelle, die wir genommen haben, haben wir auf Imagenet vorab trainiert. Es gibt zwar viele Daten, 50 Millionen Bilder, aber wenn Sie ein auf Imagenet vorab geschultes Netzwerk verwenden, zeigt es ein besseres Ergebnis, als wenn Sie es nur von Grund auf neu trainieren.
Welche Trainingstechniken haben wir angewendet? Dies ist Cosing Annealing mit Warm Restarts, ich werde etwas später darüber sprechen. Dies ist eine Technik, die ich in fast allen meinen letzten Wettbewerben verwende, und mit ihnen stellt sich heraus, dass es ziemlich gut ist, die Netze zu trainieren, um ein gutes Minimum zu erreichen.

Weiter Reduzieren Sie die Lernrate auf dem Plateau. Sie beginnen, das Netzwerk zu trainieren, legen eine bestimmte Lernrate fest, lernen sie dann und Ihr Verlust konvergiert allmählich zu einem bestimmten Wert. Sie überprüfen dies, zum Beispiel über zehn Epochen, der Verlust hat sich nicht geändert. Sie reduzieren Ihre Lernrate um einen gewissen Wert und lernen weiter. Es fällt wieder ein wenig ab, konvergiert bei einem bestimmten Minimum, und Sie senken erneut die Lernrate und so weiter, bis Ihr Netzwerk schließlich konvergiert.
Weitere interessante Technik: Verringern Sie nicht die Lernrate, sondern erhöhen Sie die Stapelgröße. Es gibt einen gleichnamigen Artikel. Wenn Sie das Netzwerk trainieren, müssen Sie die Lernrate nicht verringern, sondern können nur die Stapelgröße erhöhen.
Diese Technik wurde übrigens von Alex Parinov verwendet. Er begann mit einem Stapel von 408, und als das Netzwerk auf sein Plateau kam, verdoppelte er einfach die Stapelgröße usw.
Eigentlich erinnere ich mich nicht, welchen Wert die Chargengröße erreicht hat, aber interessanterweise gab es Teams auf Kaggle, die dieselbe Technik verwendeten. Ihre Chargengröße betrug ungefähr 10.000. Übrigens, moderne Frameworks für Deep Learning, wie z Mit PyTorch können Sie dies beispielsweise ganz einfach tun. Sie generieren Ihren Stapel und senden ihn nicht so wie er ist in seiner Gesamtheit an das Netzwerk, sondern teilen ihn in Blöcke auf, sodass er in Ihre Grafikkarte passt, zählen die Farbverläufe und aktualisieren nach Berechnung des Verlaufs für den gesamten Stapel die Skalen.
Übrigens kamen in diesem Wettbewerb immer noch große Chargengrößen hinzu, da die Daten ziemlich verrauscht waren und eine große Chargengröße Ihnen dabei half, den Gradienten genauer zu approximieren.
Pseudo-Tupfen wurde ebenfalls verwendet, größtenteils von Roman Soloviev. Er hat irgendwo die Hälfte der Daten aus dem Test abgetastet und auf solchen Chargen das Raster trainiert.
Die Größe der Bilder spielte eine Rolle, aber Tatsache ist, dass Sie viele Daten haben, lange trainieren müssen und wenn Ihre Bildgröße ziemlich groß ist, werden Sie sehr lange trainieren. Dies hat jedoch nicht so viel zur Qualität Ihres endgültigen Klassifikators beigetragen, sodass es sich gelohnt hat, einen Kompromiss einzugehen. Und sie versuchten nur Bilder von nicht sehr großer Größe.
Wie hat das alles gelernt? Zuerst wurden Bilder von geringer Größe aufgenommen, mehrere Epochen wurden darauf ausgeführt, es dauerte schnell einige Zeit. Dann wurden große Bilder gegeben, das Netzwerk lernte, dann noch mehr, noch mehr, um es nicht von Grund auf zu trainieren und nicht viel Zeit zu verbringen.
Über Optimierer. Wir haben SGD und Adam benutzt. Auf diese Weise war es möglich, ein einzelnes Modell mit einer Geschwindigkeit von 0,941 bis 0,946 in einer öffentlichen Rangliste zu erhalten, was ziemlich gut ist.
Wenn Sie Modelle auf irgendeine Weise zusammenstellen, erhalten Sie irgendwo 0,951. Wenn Sie eine andere Technik anwenden, erhalten Sie die Endgeschwindigkeit auf dem öffentlichen Brett 0,954, wie wir erhalten haben. Aber dazu später mehr. Als nächstes werde ich Ihnen erzählen, wie wir die Modelle zusammengebaut haben und wie eine solche Endgeschwindigkeit erreicht wurde.
Als nächstes möchte ich über das Schließen des Glühens mit warmen Neustarts oder den stochastischen Gradientenabstieg mit warmen Neustarts sprechen. Grundsätzlich kann man im Prinzip jeden Optimierer verwenden, aber das Fazit lautet: Wenn Sie nur ein Netzwerk trainieren und es allmählich auf ein Minimum konvergiert, ist alles in Ordnung, Sie erhalten ein Netzwerk, es macht bestimmte Fehler. aber du kannst sie ein bisschen anders unterrichten. Sie werden eine anfängliche Lernrate festlegen und diese gemäß dieser Formel schrittweise senken. Sie unterschätzen es, Ihr Netzwerk erreicht ein bestimmtes Minimum, dann sparen Sie Gewichte und stellen erneut die Lernrate ein, die zu Beginn des Trainings lag, wodurch Sie von diesem Minimum irgendwo nach oben gehen und Ihre Lernrate erneut unterschätzen.
Auf diese Weise können Sie mehrere Tiefs gleichzeitig besuchen, bei denen Sie den Verlust plus oder minus des gleichen haben. Tatsache ist jedoch, dass Netzwerke mit diesen Gewichten bei Ihrem Datum unterschiedliche Fehler verursachen. Wenn Sie sie mitteln, erhalten Sie eine bestimmte Annäherung und Ihre Geschwindigkeit ist höher.
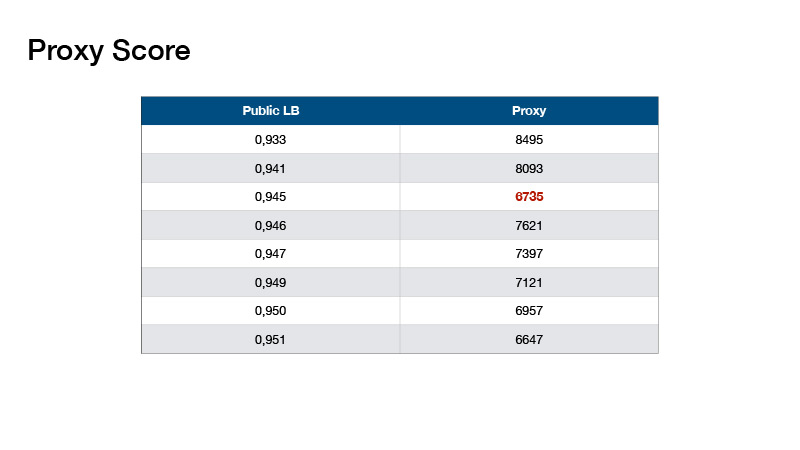
Wie wir unsere Modelle zusammengebaut haben. Zu Beginn der Präsentation sagte ich, ich solle auf die Datenmenge im Test und die Anzahl der Klassen achten. Wenn Sie der Anzahl der Ziele im Testsatz 1 hinzufügen und durch die Anzahl der Klassen dividieren, erhalten Sie die Nummer 330, und darüber wurde im Forum geschrieben - dass die Klassen im Test ausgeglichen sind. Dies könnte verwendet werden.
Auf dieser Grundlage erfand Roman Solovyov die Metrik, wir nannten sie den Proxy Score, der recht gut mit der Rangliste korrelierte. Das Fazit lautet: Sie machen eine Vorhersage, nehmen die Top-1 Ihrer Vorhersagen und zählen die Anzahl der Objekte für jede Klasse. Subtrahieren Sie 330 von jedem Wert und addieren Sie die resultierenden absoluten Werte.
Solche Werte stellten sich heraus. Dies hat uns geholfen, keine Test-Bestenliste zu erstellen, sondern lokal zu validieren und Koeffizienten für unsere Ensembles auszuwählen.
Mit dem Ensemble könnte man eine solche Geschwindigkeit erreichen. Was noch zu tun? Angenommen, Sie haben die Information verwendet, dass die Klassen in Ihrem Test ausgeglichen sind.
Das Gleichgewicht war anders.
Ein Beispiel für einen von ihnen ist das Ausbalancieren der Jungs, die den ersten Platz gewonnen haben.
Was haben wir gemacht Unser Ausgleich war recht einfach, es wurde von Evgeny Babakhnin vorgeschlagen. Wir haben unsere Vorhersagen zuerst nach Top-1 sortiert und Kandidaten aus ihnen ausgewählt - so dass die Anzahl der Klassen 330 nicht überschritt. Bei einigen Klassen stellt sich jedoch heraus, dass es weniger Vorhersagen als 330 gibt. Okay, lassen Sie uns nach Top-2 sortieren und Top 3, und wählen Sie auch Kandidaten.
Inwiefern unterschied sich unser Ausgleich vom ersten Ausgleich? Sie verwendeten einen iterativen Ansatz, nahmen die beliebteste Klasse und reduzierten die Wahrscheinlichkeiten für diese Klasse um eine kleine Anzahl - bis diese Klasse nicht mehr die beliebteste wurde. Sie nahmen an der nächstbeliebtesten Klasse teil. Also weiter und abgesenkt, bis die Anzahl aller Klassen gleich wurde.
Jeder benutzte einen Plus- oder Minus-Ansatz für Trainingsnetzwerke, aber nicht jeder benutzte das Balancieren. Mit Balancing könnten Sie in Gold gehen, und wenn Sie Glück hatten, dann in Mani.
Wie kann ich ein Datum vorverarbeiten? Alle haben das Plus-Minus-Datum auf die gleiche Weise vorverarbeitet - sie haben handgefertigte Funktionen erstellt, Timings mit verschiedenen Strichfarben codiert usw. Alexey Nozdrin-Plotnitsky, der den 8. Platz belegte, sprach darüber.

Er hat es anders gemacht. Er sagte, dass all diese handgefertigten Funktionen nicht funktionieren. Sie müssen dies nicht tun. Ihr Netzwerk muss dies alles selbst lernen. Stattdessen entwickelte er Lernmodule, mit denen Ihre Daten vorverarbeitet wurden. Er warf ihnen die Quelldaten ohne Vorverarbeitung ein - die Koordinaten von Punkten und Zeitpunkten.
Außerdem nahm er den Unterschied in den Koordinaten und mittelte ihn über die Zeitpunkte. Und er hat eine ziemlich lange Matrix. Er verwendete 1D-Faltung mehrmals, um eine 64xn-Matrix zu erhalten, wobei n die Gesamtzahl der Punkte ist, und 64 wird gemacht, um die resultierende Matrix einer Schicht eines Faltungsnetzwerks zuzuführen, das 64 Kanäle akzeptiert. Es stellte sich heraus, dass es sich um eine 64xn-Matrix handelte. Daraus musste ein Tensor von einiger Größe zusammengesetzt werden, so dass die Anzahl der Kanäle 64 betrug. Er normalisierte alle Punkte X, Y im Bereich von 0 bis 32, um einen Tensor der Größe 32x32 zu erhalten. Ich weiß nicht, warum er 32x32 wollte, es ist passiert. Und in diese Koordinate legte er ein Fragment dieser Matrix der Größe 64xn. So erhielt er einfach den 32x32x64-Tensor, der weiter in Ihr Faltungs-Neuronales Netzwerk integriert werden könnte. Ich habe alles