Hallo Habr! Ich präsentiere Ihnen die Übersetzung des Artikels
„Alles, was Sie über Streudiagramme für die Datenvisualisierung wissen müssen“ von George Seif.
Wenn Sie sich mit der Analyse und Visualisierung von Daten beschäftigen, müssen Sie sich höchstwahrscheinlich mit Streudiagrammen befassen. Trotz seiner Einfachheit sind Streudiagramme ein leistungsstarkes Werkzeug zur Visualisierung von Daten. Durch die Manipulation von Farben, Größen und Formen kann die Flexibilität und Repräsentativität von Streudiagrammen sichergestellt werden.
In diesem Artikel erfahren Sie fast alles, was Sie über die Datenvisualisierung mithilfe von Streudiagrammen wissen müssen. Wir werden versuchen, alle notwendigen Parameter für ihre Verwendung im Python-Code zu analysieren. Sie können auch einige praktische Tricks finden.
Regressionsgebäude
Selbst die primitivste Verwendung eines Streudiagramms gibt bereits einen fairen Überblick über unsere Daten. In Abbildung 1 sehen wir bereits Inseln mit kombinierten Daten und können Ausreißer schnell identifizieren.
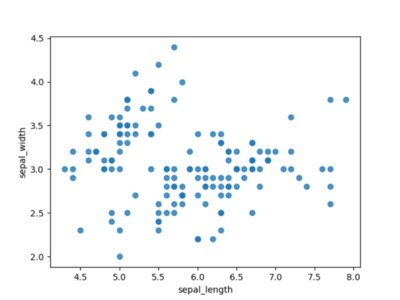 Abbildung 1
Abbildung 1
Geeignete Regressionslinien vereinfachen visuell die Identifizierung von Punkten nahe der Mitte. In Abbildung 2 haben wir ein Liniendiagramm dargestellt. Es ist ziemlich leicht zu erkennen, dass in diesem Fall die lineare Funktion nicht repräsentativ ist, da viele Punkte ziemlich weit von der Linie entfernt sind.
 Abbildung 2
Abbildung 2
Abbildung 3 verwendet ein Polynom der Ordnung 4 und sieht vielversprechender aus. Es scheint, dass wir zur Modellierung dieses Datensatzes definitiv ein Polynom der Ordnung 4 benötigen.
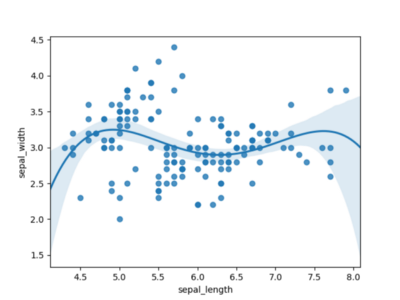 Abbildung 3
Abbildung 3
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Farbe und Form der Punkte
Farbe und Form können verwendet werden, um die verschiedenen Kategorien in Ihrem Datensatz zu visualisieren. Farbe und Form sind optisch sehr klar. Wenn Sie sich ein Diagramm ansehen, in dem Punktgruppen unterschiedliche Farben unserer Formen haben, wird sofort klar, dass die Punkte zu verschiedenen Gruppen gehören.
Abbildung 4 zeigt die nach Farben gruppierten Klassen. Abbildung 5 zeigt die Klassen, getrennt nach Farbe und Form. In beiden Fällen ist die Gruppierung viel einfacher zu erkennen. Jetzt wissen wir, dass es einfach sein wird, die
Setosa- Klasse zu trennen und worauf wir uns konzentrieren sollten. Es ist auch klar, dass ein einzelnes Liniendiagramm die grünen und orangefarbenen Punkte nicht trennen kann. Daher müssen wir etwas hinzufügen, um mehr Dimensionen anzuzeigen.
Die Wahl zwischen Farbe und Form wird bevorzugt. Persönlich finde ich die Farbe etwas klarer und intuitiver, aber die Wahl liegt immer bei Ihnen.
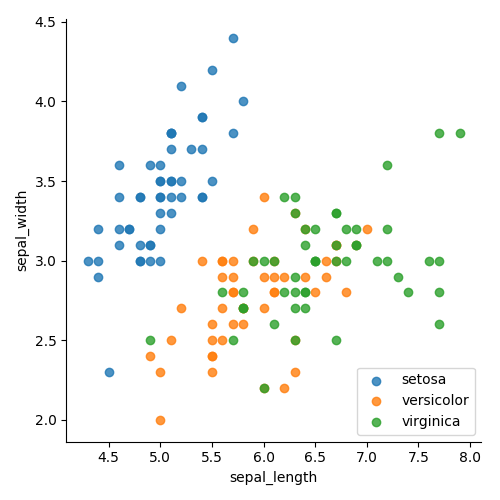 Abbildung 4
Abbildung 4
 Abbildung 5
Abbildung 5
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Randhistogramm
Ein Beispiel für ein Diagramm mit Randhistogrammen ist in Abbildung 6 dargestellt. Randhistogramme sind oben und seitlich überlagert und repräsentieren die Verteilung der Punkte für Objekte entlang der Abszisse und der Ordinate. Diese kleine Ergänzung eignet sich hervorragend zur Ermittlung der Punktverteilung und der Ausreißer.
In Abbildung 6 sehen wir beispielsweise offensichtlich eine hohe Konzentration von Punkten um das 3.0-Markup. Und dank dieses Histogramms können Sie den Konzentrationsgrad bestimmen. Auf der rechten Seite sehen Sie, dass es um das 3.0-Markup mindestens dreimal so viele Punkte gibt wie für jeden anderen diskreten Bereich. Anhand des Histogramms auf der rechten Seite kann man auch deutlich erkennen, dass die offensichtlichen Ausreißer über der Marke von 3,75 liegen. Das obere Diagramm zeigt, dass die Verteilung der Punkte entlang der X-Achse mit Ausnahme der Ausreißer in der rechten Ecke gleichmäßiger ist.
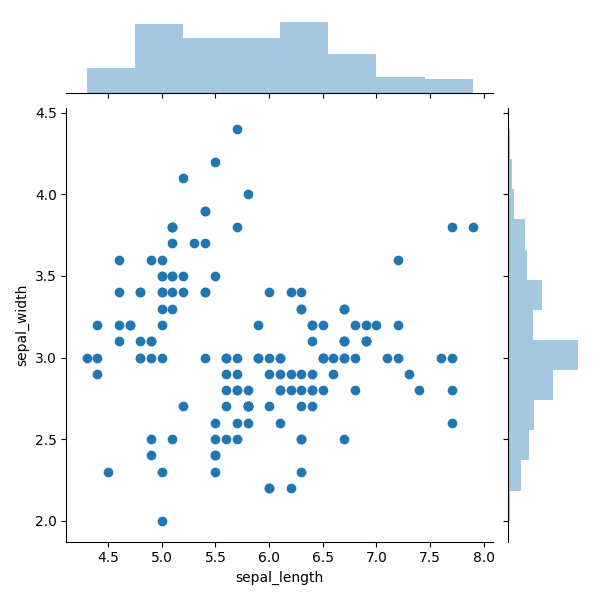 Abbildung 6
Abbildung 6
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter') plt.show()
Blasendiagramme
Bei Verwendung von Blasendiagrammen müssen mehrere Variablen zum Codieren von Informationen verwendet werden. Der neue Parameter für diese Art der Visualisierung ist die Größe. In Abbildung 7 zeigen wir die Menge der Pommes Frites nach Größe und Gewicht der Personen, die gegessen haben. Bitte beachten Sie, dass ein Streudiagramm nur ein zweidimensionales Visualisierungswerkzeug ist. Bei Verwendung von Blasendiagrammen können wir jedoch Informationen mit drei Dimensionen geschickt anzeigen.
Hier verwenden wir
Farbe, Position und Größe , wobei die Position der Blasen die Größe und das Gewicht der Person bestimmt, die Farbe das Geschlecht bestimmt und die Größe durch die Menge der verzehrten Pommes bestimmt wird. Das Blasendiagramm ermöglicht es uns, alle Attribute bequem in einem Diagramm zu kombinieren, sodass wir große Informationen in zweidimensionaler Form sehen können.
 Abbildung 7
Abbildung 7
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches x = np.array([100, 105, 110, 124, 136, 155, 166, 177, 182, 196, 208, 230, 260, 294, 312]) y = np.array([54, 56, 60, 60, 60, 72, 62, 64, 66, 80, 82, 72, 67, 84, 74]) z = (x*y) / 60 for index, val in enumerate(z): if index < 10: color = 'g' else: color = 'r' plt.scatter(x[index], y[index], s=z[index]*5, alpha=0.5, c=color) red_patch = mpatches.Patch(color='red', label='Male') green_patch = mpatches.Patch(color='green', label='Female') plt.legend(handles=[green_patch, red_patch]) plt.title("French fries eaten vs height and weight") plt.xlabel("Weight (pounds)") plt.ylabel("Height (inches)") plt.show()