Dodo IS ist ein globales System, mit dem Sie Ihr Geschäft bei Dodo Pizza effektiv verwalten können. Es schließt Probleme bei der Bestellung von Pizza, hilft dem Franchisenehmer, den Überblick über das Geschäft zu behalten, verbessert die Effizienz der Mitarbeiter und fällt manchmal ab. Das Letzte ist das Schlimmste für uns. Jede Minute solcher Stürze führt zu Gewinneinbußen, Unzufriedenheit der Benutzer und schlaflosen Nächten der Entwickler.
Aber jetzt schlafen wir besser. Wir haben gelernt, systemische Apokalypse-Szenarien zu erkennen und zu verarbeiten. Im Folgenden werde ich Ihnen erklären, wie wir für Systemstabilität sorgen.

Eine Reihe von Artikeln über den Zusammenbruch des Dodo IS * -Systems :
1. Der Tag, an dem Dodo aufgehört hat. Synchrones Skript.
2. Der Tag, an dem Dodo aufgehört hat. Asynchrones Skript.
* Die Materialien wurden basierend auf meiner Leistung bei DotNext 2018 in Moskau geschrieben .
Dodo ist
Das System ist ein großer Wettbewerbsvorteil unserer Franchise, da Franchisenehmer ein vorgefertigtes Geschäftsmodell erhalten. Dies sind ERP, HRM und CRM in einem.
Das System erschien einige Monate nach der Eröffnung der ersten Pizzeria. Es wird von Managern, Kunden, Kassierern, Köchen, Testkäufern und Call-Center-Mitarbeitern verwendet - das ist alles. Herkömmlicherweise ist Dodo IS in zwei Teile unterteilt. Der erste ist für Kunden. Dazu gehören eine Website, eine mobile Anwendung und ein Contact Center. Das zweite für Franchisenehmer-Partner ist die Verwaltung von Pizzerien. Über das System werden Rechnungen von Lieferanten, Personalmanagement, Schichtarbeitern, automatischer Lohn- und Gehaltsabrechnung, Online-Schulungen für Personal, Zertifizierung von Managern, einem Qualitätskontrollsystem und Testkäufern durchlaufen.
Systemleistung
Systemleistung Dodo IS = Zuverlässigkeit = Fehlertoleranz / Wiederherstellung. Lassen Sie uns auf jeden der Punkte eingehen.
Zuverlässigkeit
Wir haben keine großen mathematischen Berechnungen: Wir müssen eine bestimmte Anzahl von Bestellungen bedienen, es gibt bestimmte Lieferzonen. Die Anzahl der Kunden variiert nicht besonders. Natürlich werden wir glücklich sein, wenn es wächst, aber dies passiert selten in großen Stößen. Für uns läuft die Leistung darauf hinaus, wie wenige Fehler auftreten, und auf die Zuverlässigkeit des Systems.
Fehlertoleranz
Eine Komponente kann von einer anderen Komponente abhängig sein. Wenn in einem System ein Fehler auftritt, darf das andere Subsystem nicht fallen.
Belastbarkeit
Täglich treten Ausfälle einzelner Komponenten auf. Es ist in Ordnung. Es ist wichtig, wie schnell wir uns von einem Fehler erholen können.
Synchrones Systemausfallszenario
Was ist das?
Der Instinkt eines großen Unternehmens besteht darin, viele Kunden gleichzeitig zu bedienen. So wie es unmöglich ist, für eine Küchenpizzeria zu arbeiten, die wie eine Hausfrau in einer Küche zu Hause für die Lieferung arbeitet, kann ein Code für die synchrone Ausführung für den Massenkundenservice auf einem Server nicht erfolgreich funktionieren.
Es gibt einen grundlegenden Unterschied zwischen der Ausführung eines Algorithmus in einer einzelnen Instanz und der Ausführung desselben Algorithmus wie ein Server in einem Massendienst.
Schauen Sie sich das Bild unten an. Links sehen wir, wie Anforderungen zwischen zwei Diensten auftreten. Dies sind RPC-Aufrufe. Die nächste Anfrage endet nach der vorherigen. Offensichtlich ist dieser Ansatz nicht skalierbar - zusätzliche Aufträge stehen an.
Um viele Bestellungen bedienen zu können, benötigen wir die richtige Option:
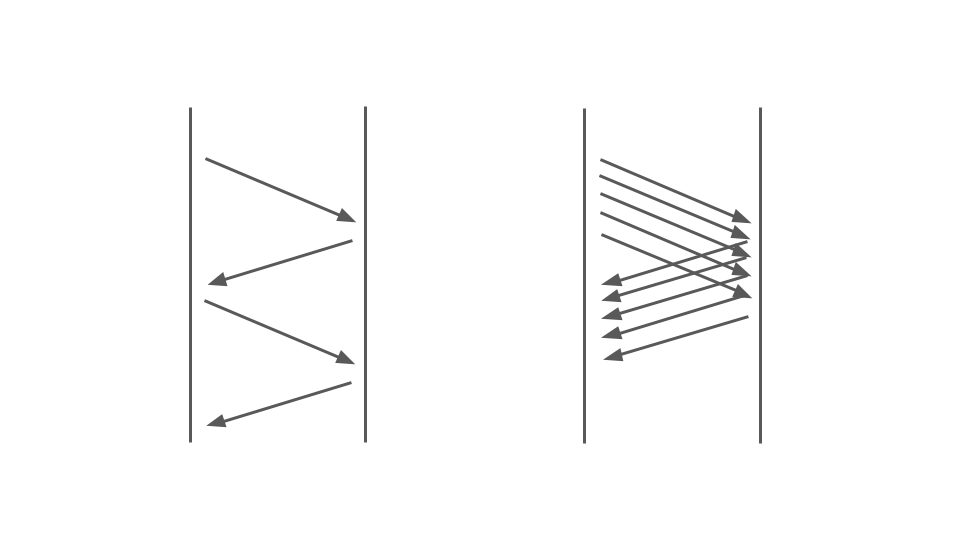
Der Vorgang des Blockierens von Code in einer synchronen Anwendung wird stark von dem verwendeten Multithreading-Modell beeinflusst, nämlich dem präemptiven Multitasking. Dies allein kann zu Fehlern führen.
Vereinfachtes präventives Multitasking könnte wie folgt dargestellt werden:

Farbblöcke sind die eigentliche Arbeit, die die CPU leistet, und wir sehen, dass die nützliche Arbeit, die im Diagramm durch Grün angezeigt wird, vor dem allgemeinen Hintergrund recht gering ist. Wir müssen den Fluss wecken, ihn einschläfern, und das ist Overhead. Ein solches Schlafen / Aufwachen tritt während der Synchronisation auf irgendwelchen Synchronisationsprimitiven auf.
Offensichtlich nimmt die CPU-Leistung ab, wenn Sie die nützliche Arbeit mit einer großen Anzahl von Synchronisierungen verwässern. Wie stark kann präventives Multitasking die Leistung beeinflussen?
Betrachten Sie die Ergebnisse eines synthetischen Tests:
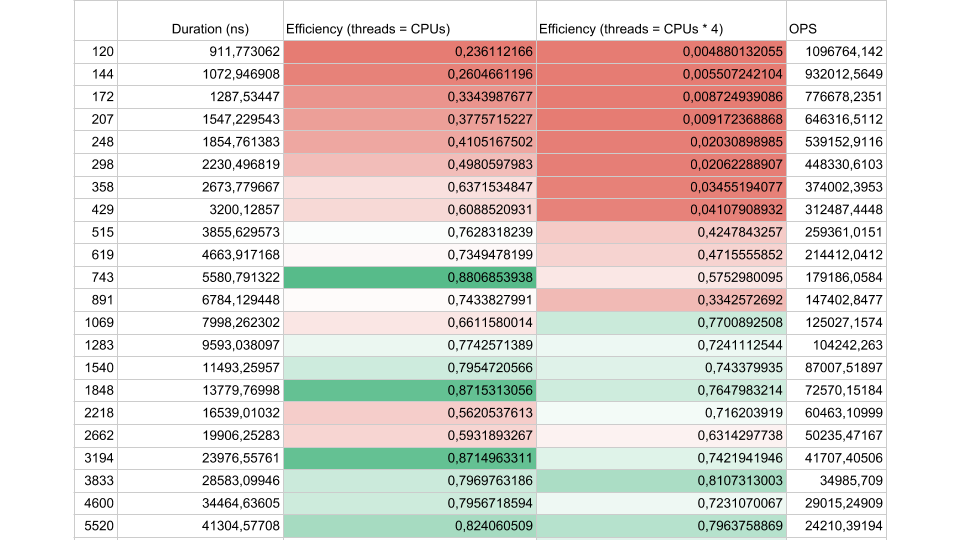
Wenn das Flussintervall zwischen den Synchronisationen etwa 1000 Nanosekunden beträgt, ist der Wirkungsgrad recht gering, selbst wenn die Anzahl der Threads gleich der Anzahl der Kerne ist. In diesem Fall beträgt der Wirkungsgrad etwa 25%. Wenn die Anzahl der Threads viermal höher ist, sinkt der Wirkungsgrad dramatisch auf 0,5%.
Denken Sie darüber nach, in der Cloud haben Sie eine virtuelle Maschine mit 72 Kernen bestellt. Es kostet Geld und Sie verwenden weniger als die Hälfte eines Kerns. Genau dies kann in einer Multithread-Anwendung passieren.
Wenn weniger Aufgaben vorhanden sind, deren Dauer jedoch länger ist, erhöht sich die Effizienz. Wir sehen, dass bei 5.000 Operationen pro Sekunde in beiden Fällen der Wirkungsgrad 80-90% beträgt. Für ein Multiprozessorsystem ist dies sehr gut.
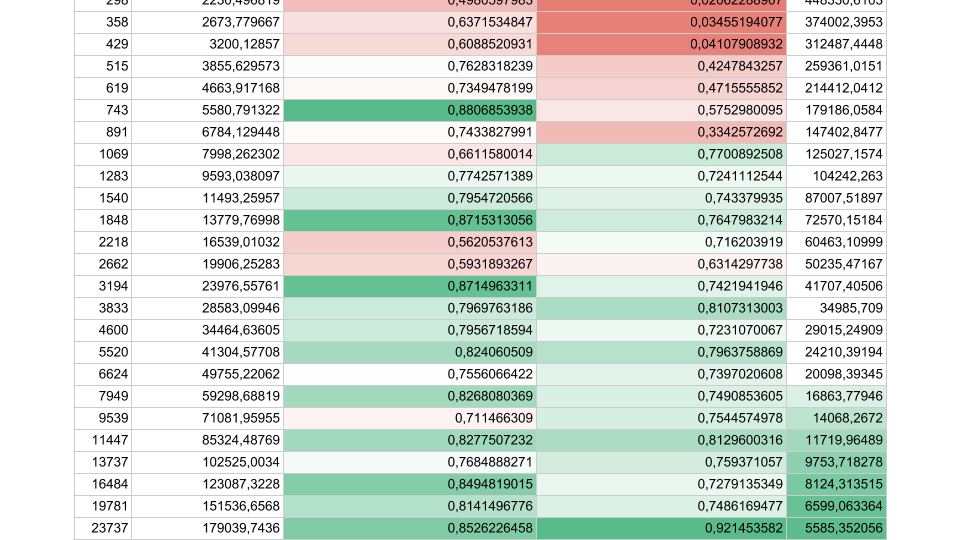
In unseren realen Anwendungen liegt die Dauer einer Operation zwischen den Synchronisierungen irgendwo dazwischen, daher ist das Problem dringend.
Was ist los?
Achten Sie auf das Ergebnis von Stresstests. In diesem Fall handelte es sich um das sogenannte "Extrusionstest".
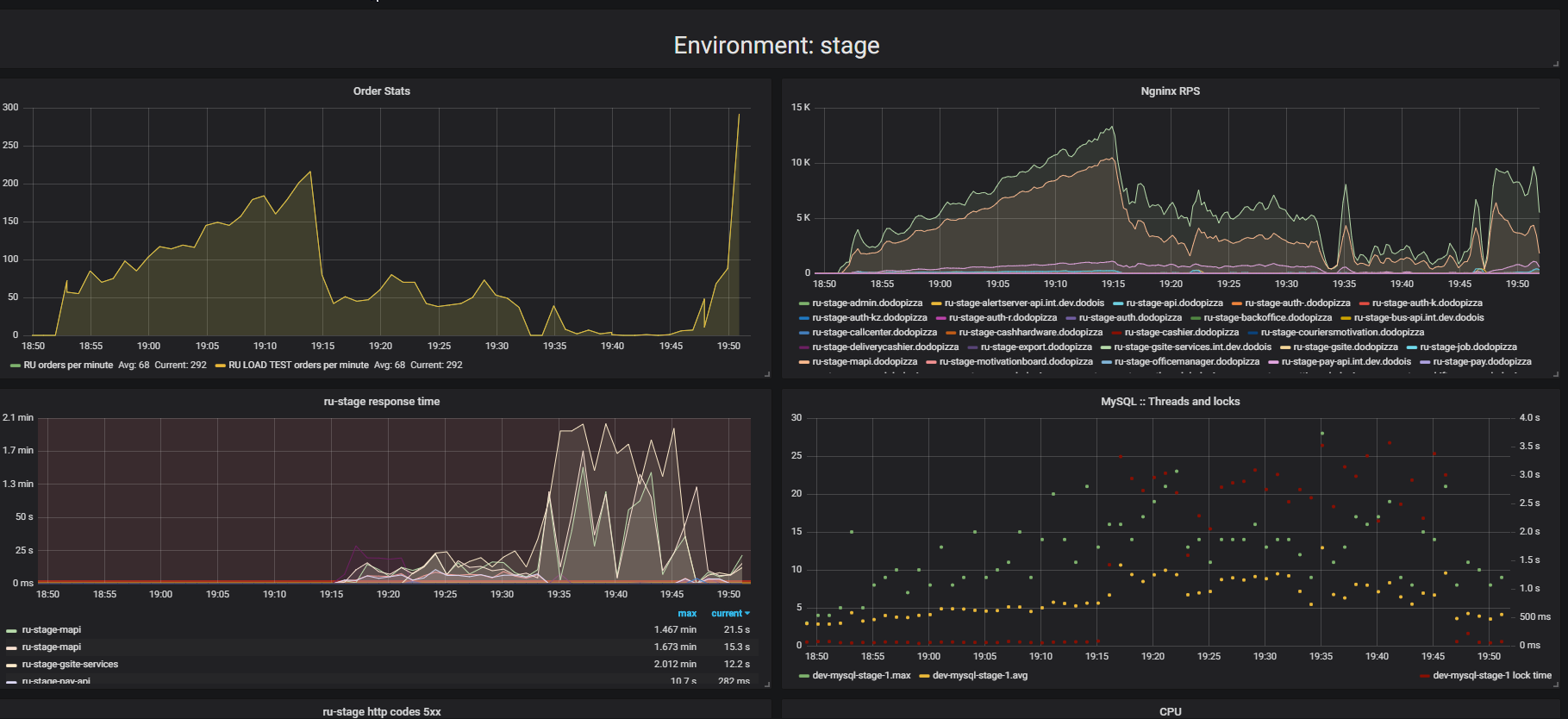
Das Wesentliche des Tests ist, dass wir mit einem Ladeständer immer mehr künstliche Anfragen an das System senden und versuchen, so viele Bestellungen wie möglich pro Minute aufzugeben. Wir versuchen, das Limit zu finden, nach dem sich die Anwendung weigert, Anfragen zu bearbeiten, die über ihre Fähigkeiten hinausgehen. Intuitiv erwarten wir, dass das System bis zum Limit läuft und zusätzliche Anforderungen verwirft. Genau das würde zum Beispiel im wirklichen Leben passieren - wenn man in einem Restaurant serviert, das voller Kunden ist. Aber noch etwas passiert. Kunden machten mehr Bestellungen und das System begann weniger zu bedienen. Das System begann so wenige Aufträge zu bedienen, dass es als völliger Ausfall oder Ausfall angesehen werden kann. Dies passiert bei vielen Anwendungen, aber sollte es sein?
In der zweiten Grafik nimmt die Zeit für die Verarbeitung einer Anforderung zu, während dieses Intervalls werden weniger Anforderungen bedient. Anfragen, die früher eingegangen sind, werden viel später bearbeitet.
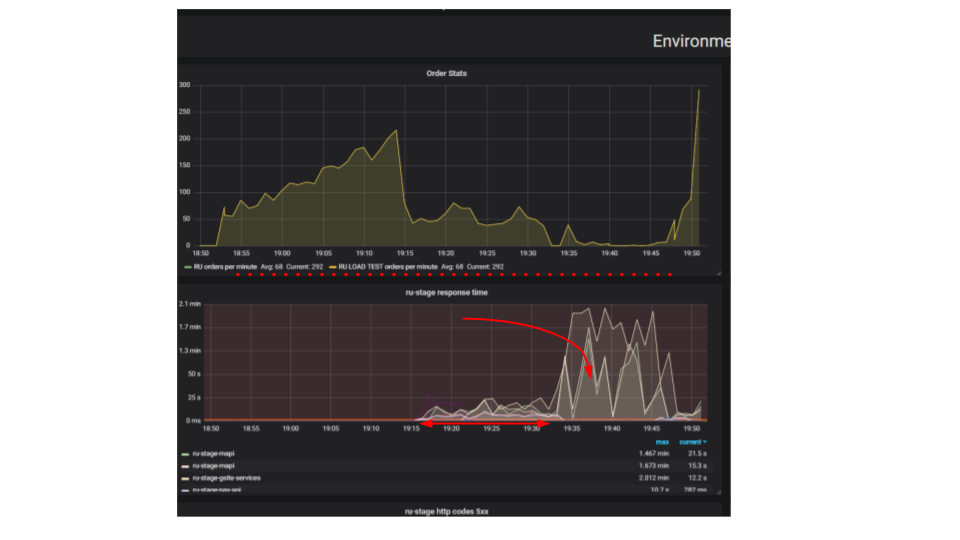
Warum wird die Anwendung gestoppt? Es gab einen Algorithmus, der funktionierte. Wir starten es von unserer lokalen Maschine, es funktioniert sehr schnell. Wir denken, wenn wir eine hundertmal leistungsstärkere Maschine nehmen und hundert identische Anforderungen ausführen, sollten diese gleichzeitig ausgeführt werden. Es stellt sich heraus, dass Anforderungen von verschiedenen Clients kollidieren. Zwischen ihnen kommt es zu Konflikten, und dies ist ein grundlegendes Problem bei verteilten Anwendungen. Separate Anfragen kämpfen um Ressourcen.
Möglichkeiten, ein Problem zu finden
Wenn der Server nicht funktioniert, werden wir zunächst versuchen, die trivialen Probleme von Sperren in der Anwendung, in der Datenbank und während der Datei-E / A zu finden und zu beheben. Es gibt immer noch eine ganze Reihe von Problemen bei der Netzwerkinteraktion, aber bis jetzt werden wir uns auf diese drei beschränken. Dies reicht aus, um zu lernen, ähnliche Probleme zu erkennen, und wir sind hauptsächlich an den Problemen interessiert, die Streit verursachen - dem Kampf um Ressourcen.
In-Process-Sperren
Hier ist eine typische Anforderung in einer blockierenden Anwendung.
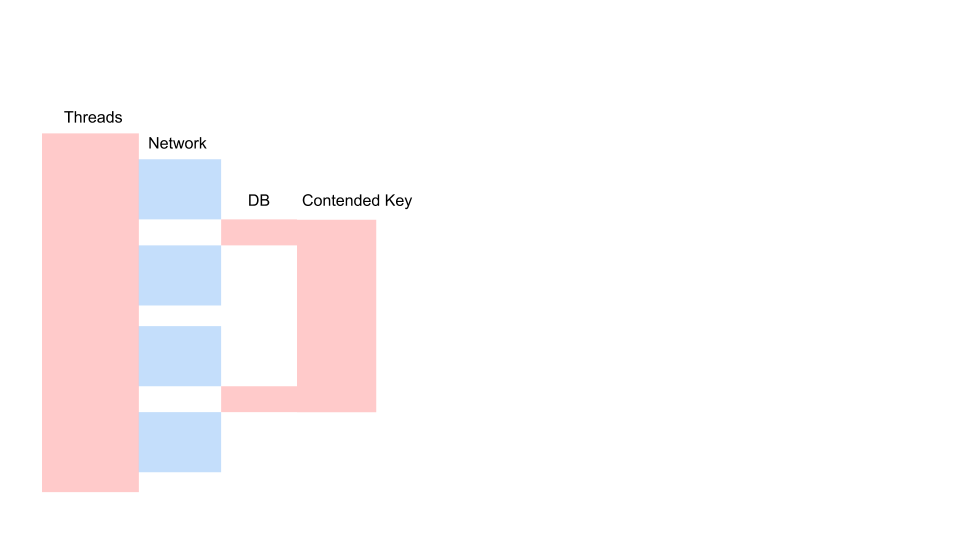
Dies ist eine Variation des Sequenzdiagramms, das den Algorithmus für die Interaktion des Anwendungscodes und der Datenbank als Ergebnis einer bedingten Operation beschreibt. Wir sehen, dass ein Netzwerkanruf getätigt wird, dann passiert etwas in der Datenbank - die Datenbank wird leicht verwendet. Dann wird eine weitere Anfrage gestellt. Für den gesamten Zeitraum werden eine Transaktion in der Datenbank und ein Schlüssel verwendet, der allen Anforderungen gemeinsam ist. Es können zwei verschiedene Kunden oder zwei verschiedene Bestellungen sein, aber ein und dasselbe Restaurantmenüobjekt, das in derselben Datenbank wie Kundenbestellungen gespeichert ist. Wir arbeiten aus Gründen der Konsistenz mit einer Transaktion. Zwei Abfragen haben Konflikte um den Schlüssel des gemeinsamen Objekts.
Mal sehen, wie es skaliert.
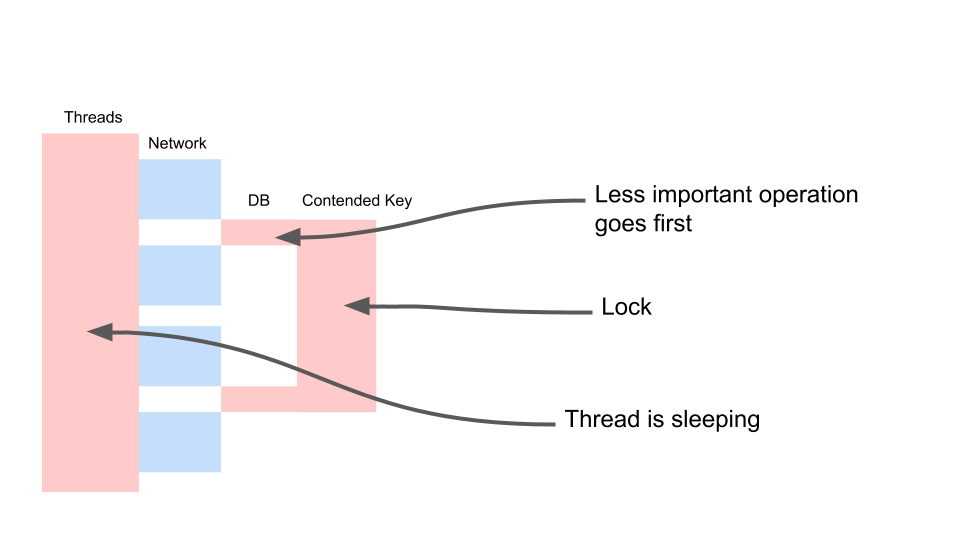
Thread schläft die meiste Zeit. Er tut tatsächlich nichts. Wir haben eine Sperre, die andere Prozesse stört. Das Ärgerlichste ist, dass die am wenigsten nützliche Operation in einer Transaktion, die einen Schlüssel gesperrt hat, ganz am Anfang stattfindet. Es verlängert die Umfangstransaktionen rechtzeitig.
Wir werden auf diese Weise kämpfen.
var fallback = FallbackPolicy<OptionalData> .Handle<OperationCancelledException>() .FallbackAsync<OptionalData>(OptionalData.Default); var optionalDataTask = fallback .ExecuteAsync(async () => await CalculateOptionalDataAsync());
Dies ist eventuelle Konsistenz. Wir gehen davon aus, dass einige unserer Daten möglicherweise weniger aktuell sind. Dazu müssen wir anders mit dem Code arbeiten. Wir müssen akzeptieren, dass die Daten von anderer Qualität sind. Wir werden uns nicht ansehen, was vorher passiert ist - der Manager hat etwas im Menü geändert oder der Kunde hat auf die Schaltfläche "Kasse" geklickt. Für uns spielt es keine Rolle, welcher von ihnen zwei Sekunden zuvor den Knopf gedrückt hat. Und für das Geschäft gibt es keinen Unterschied.
Es gibt keinen Unterschied, wir können so etwas tun. Nennen Sie es bedingt optionalData. Das heißt, ein Wert, auf den wir verzichten können. Wir haben einen Fallback - den Wert, den wir aus dem Cache nehmen oder einen Standardwert übergeben. Und für die wichtigste Operation (die erforderliche Variable) werden wir warten. Wir werden fest auf ihn warten und erst dann auf eine Antwort auf Anfragen nach optionalen Daten warten. Dadurch können wir die Arbeit beschleunigen. Es gibt noch einen weiteren wichtigen Punkt: Dieser Vorgang wird aus irgendeinem Grund möglicherweise überhaupt nicht ausgeführt. Angenommen, der Code für diese Operation ist nicht optimal, und im Moment liegt ein Fehler vor. Wenn der Vorgang fehlgeschlagen ist, führen Sie einen Fallback durch. Und dann arbeiten wir damit wie mit der üblichen Bedeutung.
DB-Sperren
Wir erhalten ungefähr das gleiche Layout, wenn wir asynchron umschreiben und das Konsistenzmodell ändern.
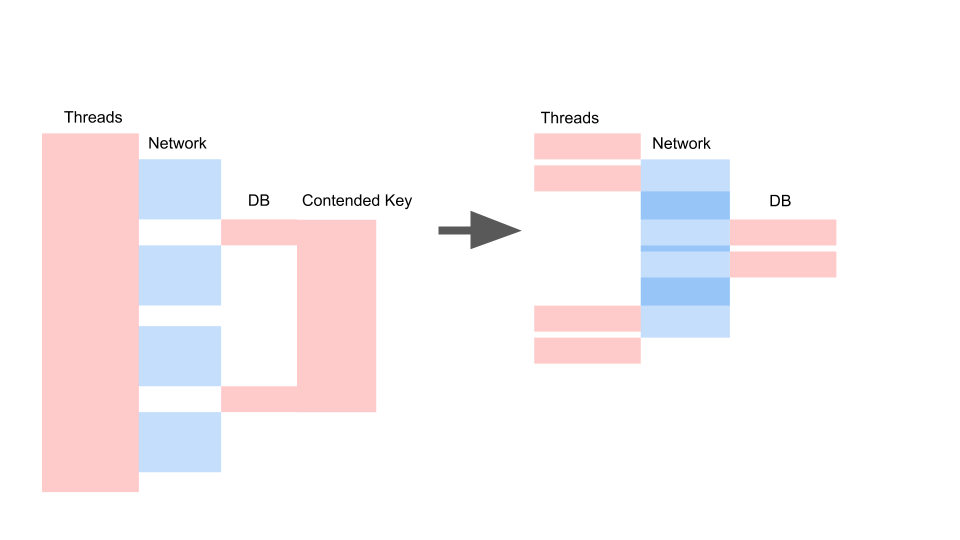
Was hier zählt, ist nicht, dass die Anfrage mit der Zeit schneller geworden ist. Wichtig ist, dass wir keinen Streit haben. Wenn wir Anfragen hinzufügen, ist nur die linke Seite des Bildes mit uns gesättigt.
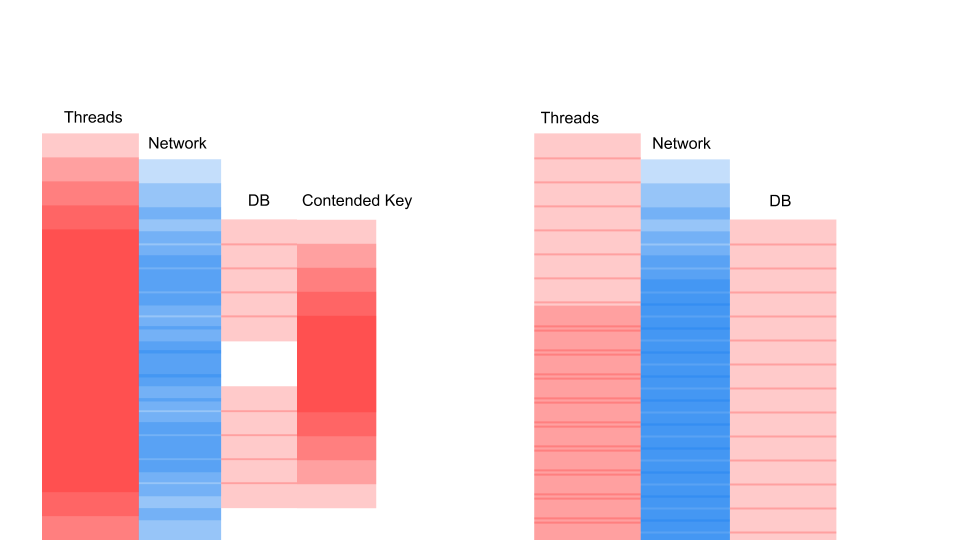
Dies ist eine Blockierungsanforderung. Hier überlappen sich die Threads und die Schlüssel, auf denen Konflikte auftreten. Rechts haben wir überhaupt keine Transaktionen in der Datenbank und sie werden leise ausgeführt. Der richtige Fall kann in diesem Modus unbegrenzt funktionieren. Links führt zum Absturz des Servers.
Synchronisieren Sie io
Manchmal brauchen wir Dateiprotokolle. Überraschenderweise kann das Protokollierungssystem solche unangenehmen Fehler verursachen. Latenz auf der Festplatte in Azure - 5 Millisekunden. Wenn wir eine Datei hintereinander schreiben, sind es nur 200 Anfragen pro Sekunde. Das war's, die Anwendung wurde gestoppt.

Es ist nur so, dass Ihre Haare zu Berge stehen, wenn Sie dies sehen - mehr als 2000 Fäden wurden in der Anwendung gezüchtet. 78% aller Threads sind der gleiche Aufrufstapel. Sie hielten an derselben Stelle an und versuchen, den Monitor zu betreten. Dieser Monitor begrenzt den Zugriff auf die Datei, in der wir alle protokollieren. Natürlich muss dies geschnitten werden.

Folgendes müssen Sie in NLog tun, um es zu konfigurieren. Wir machen ein asynchrones Ziel und schreiben darauf. Und asynchrones Ziel schreibt in die reale Datei. Natürlich können wir eine bestimmte Anzahl von Nachrichten im Protokoll verlieren, aber was ist für das Geschäft wichtiger? Als das System 10 Minuten lang ausfiel, verloren wir eine Million Rubel. Es ist wahrscheinlich besser, mehrere Nachrichten im Dienstprotokoll zu verlieren, die fehlgeschlagen sind und neu gestartet wurden.
Alles ist sehr schlecht
In Multithread-Anwendungen ist der Konflikt ein großes Problem, sodass Sie eine Single-Thread-Anwendung nicht einfach skalieren können. Streitquellen müssen identifizieren und beseitigen können. Eine große Anzahl von Threads ist für Anwendungen katastrophal, und blockierende Aufrufe müssen asynchron umgeschrieben werden.
Ich musste viel Vermächtnis umschreiben, indem ich asynchrone Anrufe blockierte. Ich selbst habe oft ein solches Upgrade initiiert. Sehr oft kommt jemand und fragt: "Hören Sie, wir schreiben jetzt seit zwei Wochen um, fast alle asynchron. Und wie viel wird es schneller funktionieren? " Leute, ich werde dich verärgern - es wird nicht schneller funktionieren. Es wird noch langsamer. Schließlich ist TPL ein Wettbewerbsmodell über dem anderen - kooperatives Multitasking gegenüber präemptivem Multitasking, und dies ist ein Overhead. In einem unserer Projekte - ca. + 5% auf die CPU-Auslastung und die Auslastung von GC.
Es gibt noch eine weitere schlechte Nachricht: Die Anwendung kann nach dem Umschreiben in Async viel schlechter funktionieren, ohne die Funktionen des Wettbewerbsmodells zu kennen. Ich werde im nächsten Artikel ausführlich auf diese Funktionen eingehen.
Dies wirft die Frage auf - ist es notwendig, neu zu schreiben?
Der synchrone Code wird asynchron umgeschrieben, um das Parallelitätsmodell zu entsperren und das präemptive Multitasking-Modell zu entfernen. Wir haben festgestellt, dass die Anzahl der Threads die Leistung beeinträchtigen kann. Sie müssen sich also von der Notwendigkeit befreien, die Anzahl der Threads zu erhöhen, um die Parallelität zu erhöhen. Auch wenn wir Legacy haben und diesen Code nicht neu schreiben möchten, ist dies der Hauptgrund, ihn neu zu schreiben.
Die gute Nachricht am Ende ist, dass wir jetzt etwas darüber wissen, wie wir die trivialen Probleme von Contention of Blocking Code beseitigen können. Wenn Sie solche Probleme in Ihrer blockierenden Anwendung finden, ist es Zeit, sie zu beseitigen, bevor Sie sie in asynchron umschreiben, da sie dort nicht von selbst verschwinden.