Die Autoren sind John Hennessey und David Patterson, Gewinner des Turing Award 2017 "für einen innovativen systematischen und messbaren Ansatz zum Entwurf und zur Verifizierung von Computerarchitekturen, die die gesamte Mikroprozessorindustrie nachhaltig beeinflusst haben". Artikel veröffentlicht in Mitteilungen der ACM, Februar 2019, Band 62, Nr. 2, S. 48-60, doi: 10.1145 / 3282307 "Diejenigen, die sich nicht an die Vergangenheit erinnern, sind dazu verdammt, sie zu wiederholen"
"Diejenigen, die sich nicht an die Vergangenheit erinnern, sind dazu verdammt, sie zu wiederholen" - George Santayana, 1905
Wir haben unseren
Turing-Vortrag am 4. Juni 2018 mit einem Überblick über die Computerarchitektur ab den 60er Jahren begonnen. Zusätzlich zu ihm heben wir aktuelle Themen hervor und versuchen, zukünftige Möglichkeiten zu identifizieren, die ein neues goldenes Zeitalter auf dem Gebiet der Computerarchitektur im nächsten Jahrzehnt versprechen. Genauso wie in den 1980er Jahren, als wir unsere Forschungen zur Verbesserung der Kosten, Energieeffizienz, Sicherheit und Leistung von Prozessoren durchgeführt haben, für die wir diese ehrenvolle Auszeichnung erhalten haben.
Schlüsselideen
- Software-Fortschritt kann architektonische Innovation vorantreiben
- Die Erhöhung der Software- und Hardwareschnittstellen bietet Möglichkeiten für architektonische Innovationen
- Der Markt bestimmt letztendlich den Gewinner im Architekturstreit
Die Software "spricht" mit dem Gerät über ein Wörterbuch, das als "Befehlssatzarchitektur" (ISA) bezeichnet wird. In den frühen 1960er Jahren verfügte IBM über vier inkompatible Computerserien mit jeweils eigenem ISA, Software-Stack, E / A-System und Marktnische, die auf kleine Unternehmen, große Unternehmen, wissenschaftliche Anwendungen bzw. Echtzeitsysteme ausgerichtet waren. IBM-Ingenieure, darunter der Turing-Preisträger Frederick Brooks Jr., beschlossen, eine einzige ISA zu schaffen, die alle vier effektiv vereint.
Sie brauchten eine technische Lösung, um gleich schnelle ISA für Computer mit 8-Bit- und 64-Bit-Bussen bereitzustellen. In gewisser Weise sind die Busse die "Muskeln" von Computern: Sie erledigen ihre Arbeit, lassen sich aber relativ leicht "komprimieren" und "erweitern". Die größte Herausforderung für Designer war damals und heute das "Gehirn" der Prozessorsteuergeräte. Inspiriert von der Programmierung schlug der Pionier der Informatik und Turing-Preisträger Maurice Wilkes Optionen zur Vereinfachung dieses Systems vor. Die Kontrolle wurde als zweidimensionales Array dargestellt, das er als "Kontrollspeicher" (Kontrollspeicher) bezeichnete.
Jede Spalte des Arrays entsprach einer Steuerzeile, jede Zeile war Mikrobefehl, und die Aufzeichnung von Mikrobefehlen wurde Mikroprogrammierung genannt . Der Steuerspeicher enthält einen ISA-Interpreter, der durch Mikrobefehle geschrieben wurde, so dass die Ausführung eines normalen Befehls mehrere Mikrobefehle erfordert. Der Steuerspeicher ist tatsächlich im Speicher implementiert und viel billiger als Logikelemente.
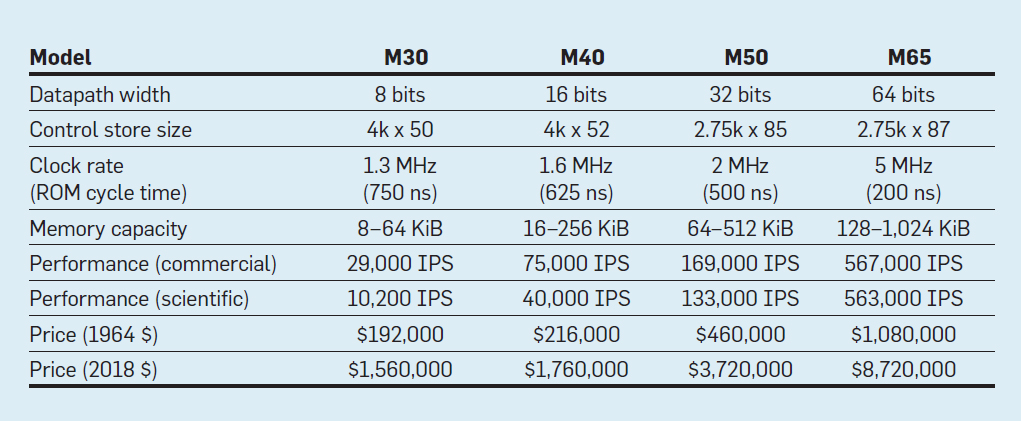 Merkmale der vier Modelle der IBM System / 360-Familie; IPS bedeutet Operationen pro Sekunde
Merkmale der vier Modelle der IBM System / 360-Familie; IPS bedeutet Operationen pro SekundeDie Tabelle zeigt vier Modelle des neuen ISA in System / 360 von IBM, das am 7. April 1964 eingeführt wurde. Die Busse unterscheiden sich um das 8-fache, die Speicherkapazität beträgt 16, die Taktrate beträgt fast 4, die Leistung beträgt 50 und die Kosten betragen fast 6. Die teuersten Computer verfügen über den umfangreichsten Steuerspeicher, da komplexere Datenbusse mehr Steuerleitungen verwenden . Die billigsten Computer haben aufgrund der einfacheren Hardware weniger Steuerspeicher, benötigten jedoch mehr Mikrobefehle, da sie mehr Taktzyklen benötigten, um den System / 360-Befehl auszuführen.
Dank der Mikroprogrammierung hat IBM darauf gewettet, dass der neue ISA die Computerbranche revolutionieren wird - und die Wette gewonnen. IBM dominierte seine Märkte, und die Nachkommen der alten 55-jährigen IBM-Mainframes erwirtschaften immer noch einen Jahresumsatz von 10 Milliarden US-Dollar.
Wie wiederholt erwähnt, ist der Markt zwar ein unvollkommener Schiedsrichter als Technologie, aber angesichts der engen Verbindung zwischen Architektur und kommerziellen Computern bestimmt er letztendlich den Erfolg von Architekturinnovationen, die häufig erhebliche technische Investitionen erfordern.
Integrated Circuits, CISC, 432, 8086, IBM PC
Als Computer auf integrierte Schaltkreise umstellten, bedeutete das Gesetz von Moore, dass der Steuerspeicher viel größer werden konnte. Dies ermöglichte wiederum eine viel komplexere ISA. Zum Beispiel der VAX-11/780-Steuerspeicher von Digital Equipment Corp. 1977 waren es 5120 Wörter in 96 Bit, während sein Vorgänger nur 256 Wörter in 56 Bit verwendete.
Einige Hersteller haben die Firmware für ausgewählte Kunden aktiviert, die möglicherweise benutzerdefinierte Funktionen hinzugefügt haben. Dies wird als beschreibbarer Kontrollspeicher (WCS) bezeichnet. Der bekannteste WCS-Computer war
Alto , den die Turing-Preisträger Chuck Tucker und Butler Lampson sowie Kollegen 1973 für das Xerox Palo Alto Research Center entwickelten. Es war wirklich der erste Personal Computer: Hier ist das erste Display mit Element-für-Element-Bildgebung und das erste lokale Ethernet-Netzwerk. Die Steuerungen für das innovative Display und die Netzwerkkarte waren Mikroprogramme, die im WCS mit einer Kapazität von 4096 Wörtern in 32 Bit gespeichert sind.
In den 70er Jahren blieben Prozessoren noch 8-Bit (zum Beispiel Intel 8080) und wurden hauptsächlich in Assembler programmiert. Die Wettbewerber fügten neue Anweisungen hinzu, um sich gegenseitig zu übertreffen, und zeigten ihre Erfolge anhand von Assembler-Beispielen.
Gordon Moore glaubte, dass die nächste ISA von Intel für das Unternehmen für immer Bestand haben würde. Deshalb stellte er viele intelligente Ärzte in der Informatik ein und schickte sie in eine neue Einrichtung in Portland, um die nächste große ISA zu erfinden. Der 8800-Prozessor, wie Intel ihn ursprünglich nannte, hat sich zu einem absolut ehrgeizigen Computerarchitekturprojekt für jede Epoche entwickelt. Natürlich war er das aggressivste Projekt der 80er Jahre. Es enthielt eine auf Funktionen basierende 32-Bit-Adressierung, eine objektorientierte Architektur, Anweisungen variabler Länge und ein eigenes Betriebssystem in der neuen Programmiersprache Ada.
Leider erforderte dieses ehrgeizige Projekt mehrere Jahre Entwicklungszeit, was Intel zwang, ein Notfall-Backup-Projekt in Santa Clara zu starten, um 1979 schnell einen 16-Bit-Prozessor freizugeben. Intel gab dem neuen Team 52 Wochen Zeit, um den neuen ISA "8086" zu entwickeln, den Chip zu entwerfen und zu bauen. Angesichts eines engen Zeitplans dauerte das ISA-Design für drei reguläre Kalenderwochen nur 10 Personenwochen, hauptsächlich aufgrund der Erweiterung von 8-Bit-Registern und eines Satzes von 8080-Befehlen auf 16 Bit. Das Team beendete 8086 termingerecht, aber dieser von einem Absturz verursachte Prozessor wurde ohne große Fanfare angekündigt.
Intel hatte großes Glück, dass IBM einen PC entwickelte, der mit dem Apple II konkurrieren konnte, und einen 16-Bit-Mikroprozessor benötigte. IBM hat das Motorola 68000 mit einem ISA im Auge behalten, der dem IBM 360 ähnelt, aber hinter dem aggressiven Zeitplan von IBM steckt. Stattdessen wechselte IBM zur 8-Bit-Version des 8086-Busses. Als IBM am 12. August 1981 den PC ankündigte, hoffte das Unternehmen, bis 1986 250.000 Computer verkaufen zu können. Stattdessen verkaufte das Unternehmen weltweit 100 Millionen, was eine vielversprechende Zukunft für Intels Notfall-ISA darstellt.
Das ursprüngliche Intel 8800-Projekt wurde in iAPX-432 umbenannt. Schließlich wurde es 1981 angekündigt, benötigte jedoch mehrere Chips und hatte ernsthafte Leistungsprobleme. Es wurde 1986 fertiggestellt, ein Jahr nachdem Intel den 16-Bit-ISA 8086 auf 80386 erweitert und die Register von 16 Bit auf 32 Bit erhöht hatte. Somit erwies sich Moores Vorhersage bezüglich der ISA als richtig, aber der Markt entschied sich für den 8086, der in zwei Hälften hergestellt wurde, anstatt für den gesalbten iAPX-432. Wie die Architekten der Prozessoren Motorola 68000 und iAPX-432 erkannten, kann der Markt selten Geduld zeigen.
Vom komplexen zum abgekürzten Befehlssatz
In den frühen 1980er Jahren wurden mehrere Studien an Computern mit einer Reihe komplexer Anweisungen (CISC) durchgeführt: Sie haben große Mikroprogramme in einem großen Steuerspeicher. Als Unix demonstrierte, dass sogar das Betriebssystem in einer höheren Sprache geschrieben werden kann, lautete die Hauptfrage: "Welche Anweisungen werden Compiler generieren?" anstelle des früheren "Welchen Assembler werden Programmierer verwenden?" Eine signifikante Erhöhung des Niveaus der Hardware-Software-Schnittstelle hat eine Gelegenheit für Innovationen in der Architektur geschaffen.
Der Turing-Preisträger John Kokk und seine Kollegen haben einfachere ISAs und Minicomputer-Compiler entwickelt. Als Experiment haben sie ihre Research-Compiler auf die Verwendung des IBM 360 ISA umgestellt, um nur einfache Operationen zwischen Registern und das Laden mit Speicher zu verwenden und komplexere Anweisungen zu vermeiden. Sie stellten fest, dass Programme dreimal schneller ausgeführt werden, wenn sie eine einfache Teilmenge verwenden. Emer und Clark stellten
fest, dass 20% der VAX-Anweisungen 60% des Mikrocodes und nur 0,2% der Ausführungszeit beanspruchen. Ein Autor dieses Artikels (Patterson) verbrachte einen kreativen Urlaub bei DEC, um Fehler im VAX-Mikrocode zu reduzieren. Wenn Mikroprozessorhersteller ISA-Entwürfen mit einer Reihe komplexer CISC-Befehle in großen Computern folgen wollten, erwarteten sie eine große Anzahl von Mikrocodefehlern und wollten einen Weg finden, diese zu beheben. Er schrieb einen
solchen Artikel , aber das
Computer- Magazin lehnte ihn ab. Die Gutachter schlugen vor, dass die schreckliche Idee, Mikroprozessoren mit ISA zu bauen, so komplex ist, dass sie vor Ort repariert werden müssen. Dieser Fehler ließ den Wert von CISC für Mikroprozessoren in Frage stellen. Ironischerweise enthalten moderne CISC-Mikroprozessoren Mechanismen zur Wiederherstellung von Mikrocodes, aber die Weigerung, den Artikel zu veröffentlichen, inspirierte den Autor, eine weniger komplexe ISA für Mikroprozessoren zu entwickeln - Computer mit einem reduzierten Befehlssatz (RISC).
Diese Kommentare und der Übergang zu Hochsprachen ermöglichten den Übergang von CISC zu RISC. Erstens werden RISC-Anweisungen vereinfacht, sodass kein Interpreter erforderlich ist. RISC-Anweisungen sind normalerweise einfach wie Mikrobefehle und können direkt von der Hardware ausgeführt werden. Zweitens wurde der schnelle Speicher, der zuvor für den CISC-Mikrocode-Interpreter verwendet wurde, in den RISC-Anweisungscache umgestaltet (der Cache ist ein kleiner, schneller Speicher, der kürzlich ausgeführte Anweisungen puffert, da solche Anweisungen wahrscheinlich in naher Zukunft wiederverwendet werden). Drittens erleichterten
Registerzuordnungen, die auf dem Farbschema des Graphen von Gregory Chaitin basierten, die effiziente Verwendung von Registern für Compiler, die von diesen ISAs mit Registerregisteroperationen profitierten. Schließlich führte Moores Gesetz dazu, dass in den 1980er Jahren genügend Transistoren auf einem Chip vorhanden waren, um einen vollständigen 32-Bit-Bus auf einem einzelnen Chip zusammen mit Caches für Anweisungen und Daten aufzunehmen.
Zum Beispiel in Abb. Abbildung 1 zeigt die 1982 und 1983 an der University of California in Berkeley und der Stanford University entwickelten
RISC-I- und
MIPS- Mikroprozessoren, die die Vorteile von RISC demonstrierten. Infolgedessen wurden diese Prozessoren 1984 auf der führenden Konferenz zum Schaltungsdesign, der IEEE International Solid-State Circuits Conference (
1 ,
2 ), vorgestellt. Es war ein wunderbarer Moment, als mehrere Doktoranden in Berkeley und Stanford Mikroprozessoren entwickelten, die die Fähigkeiten der Industrie dieser Zeit übertrafen.
 Abb. 1. RISC-I-Prozessoren der University of California in Berkeley und MIPS der Stanford University
Abb. 1. RISC-I-Prozessoren der University of California in Berkeley und MIPS der Stanford UniversityDiese akademischen Chips haben viele Unternehmen dazu inspiriert, RISC-Mikroprozessoren zu entwickeln, die in den nächsten 15 Jahren die schnellsten waren. Die Erklärung bezieht sich auf die folgende Prozessorleistungsformel:
Zeit / Programm = (Anweisungen / Programm) × (Maßnahmen / Anweisungen) × (Zeit / Maßnahme)DEC-Ingenieure
zeigten später
, dass für ein Programm komplexere CISCs 75% der Anzahl der RISC-Anweisungen erfordern (der erste Term in der Formel), aber in einer ähnlichen Technologie (dritter Term) benötigt jeder CISC-Befehl 5-6 Zyklen mehr (zweiter Term) macht RISC-Mikroprozessoren etwa viermal schneller.
In der Computerliteratur der 80er Jahre gab es keine solchen Formeln, weshalb wir 1989 das Buch
Computer Architecture: A Quantitective Approach schrieben . Der Untertitel erklärt das Thema des Buches: Verwenden von Messungen und Benchmarks, um Kompromisse zu quantifizieren, anstatt sich wie in der Vergangenheit auf die Intuition und Erfahrung des Designers zu verlassen. Unser quantitativer Ansatz wurde auch von dem inspiriert, was
das Buch von
Turing Laureate Donald Knuth für Algorithmen getan hat.
VLIW, EPIC, Itanium
Die nächste innovative ISA sollte den Erfolg von RISC und CISC übertreffen. Die sehr lange
VLIW- Maschinenbefehlsarchitektur und ihr Cousin EPIC (Computing mit expliziter Maschinenbefehlsparallelität) von Intel und Hewlett-Packard verwendeten lange Befehle, die jeweils aus mehreren unabhängigen Operationen bestanden, die miteinander verbunden waren. Die damaligen Befürworter von VLIW und EPIC waren der Ansicht, dass ein Befehl beispielsweise sechs unabhängige Operationen anzeigen könnte - zwei Datenübertragungen, zwei ganzzahlige Operationen und zwei Gleitkommaoperationen - und die Compilertechnologie Operationen effizient sechs Befehlsschlitzen zuweisen könnte. dann kann die Ausrüstung vereinfacht werden. Ähnlich wie bei RISC haben VLIW und EPIC die Arbeit von der Hardware auf den Compiler übertragen.
Intel und Hewlett-Packard haben gemeinsam einen 64-Bit-EPIC-basierten Prozessor entwickelt, der die 32-Bit-Architektur x86 ersetzt. An den ersten EPIC-Prozessor namens Itanium wurden große Erwartungen gestellt, aber die Realität entsprach nicht den frühen Aussagen der Entwickler. Obwohl der EPIC-Ansatz für hochstrukturierte Gleitkomma-Programme gut funktionierte, konnte er für ganzzahlige Programme mit weniger vorhersehbaren Verzweigungs- und Cache-Fehlern keine hohe Leistung erzielen. Wie Donald Knuth später
bemerkte : "Itanium sollte ... großartig sein - bis sich herausstellte, dass die gewünschten Compiler im Grunde unmöglich zu schreiben waren." Kritiker bemerkten Verzögerungen bei der Veröffentlichung von Itanium und nannten es Itanik zu Ehren des unglücklichen Passagierschiffs Titanic. Der Markt zeigte erneut keine Geduld und übernahm die 64-Bit-Version von x86 und nicht Itanium als Nachfolger.
Die gute Nachricht ist, dass VLIW immer noch für speziellere Anwendungen geeignet ist, die kleine Programme mit einfacheren Verzweigungen ohne Cache-Fehler ausführen, einschließlich digitaler Signalverarbeitung.
RISC vs. CISC in der PC- und Post-PC-Ära
AMD und Intel benötigten 500 Designteams und überlegene Halbleitertechnologie, um die Leistungslücke zwischen x86 und RISC zu schließen. Um die Leistung durch Pipelining zu verbessern, übersetzt ein On-the-Fly-Befehlsdecoder komplexe x86-Befehle in interne RISC-ähnliche Mikrobefehle. AMD und Intel erstellen dann eine Pipeline für ihre Implementierung. Alle Ideen, die RISC-Designer zur Verbesserung der Leistung verwendeten - separate Befehls- und Datencaches, Caches der zweiten Ebene auf dem Chip, eine tiefe Pipeline und das gleichzeitige Empfangen und Ausführen mehrerer Befehle - wurden dann in x86 aufgenommen. Auf dem Höhepunkt des PC-Zeitalters im Jahr 2011 haben AMD und Intel jährlich rund 350 Millionen x86-Mikroprozessoren ausgeliefert. Hohe Volumina und niedrige Branchenmargen bedeuteten auch niedrigere Preise als bei RISC-Computern.
Mit Hunderten von Millionen verkauften Computern pro Jahr ist Software zu einem riesigen Markt geworden. Während Unix-Softwareanbieter unterschiedliche Softwareversionen für unterschiedliche RISC-Architekturen - Alpha, HP-PA, MIPS, Power und SPARC - veröffentlichen mussten, verfügten PCs über eine ISA, sodass die Entwickler "geschrumpfte" Software veröffentlichten, die nur mit Architektur binär kompatibel war x86. Aufgrund seiner viel größeren Softwarebasis, ähnlichen Leistung und niedrigeren Preise dominierte die x86-Architektur im Jahr 2000 den Desktop- und den kleinen Servermarkt.
Apple hat 2007 mit dem iPhone die Post-PC-Ära eingeläutet. Anstatt Mikroprozessoren zu kaufen, stellten Smartphone-Unternehmen ihre eigenen Systems-on-a-Chip (SoC) unter Verwendung der Entwicklungen anderer her, einschließlich RISC-Prozessoren von ARM. Hier sind Designer nicht nur wichtig für die Leistung, sondern auch für den Stromverbrauch und die Chipfläche, was die CISC-Architektur benachteiligt. Darüber hinaus hat das Internet der Dinge sowohl die Anzahl der Prozessoren als auch die notwendigen Kompromisse bei Chipgröße, Leistung, Kosten und Leistung erheblich erhöht. Dieser Trend hat die Bedeutung von Entwurfszeit und -kosten erhöht und die Position von CISC-Prozessoren weiter verschlechtert. In der heutigen Post-PC-Ära sind die x86-jährlichen Lieferungen seit dem Höhepunkt 2011 um fast 10% gesunken, während die RISC-Chips auf 20 Milliarden gestiegen sind. Heute sind 99% der 32- und 64-Bit-Prozessoren weltweit RISC.
Abschließend können wir sagen, dass der Markt den Streit zwischen RISC und CISC beigelegt hat. Obwohl CISC die späteren Phasen der PC-Ära gewonnen hat, gewinnt RISC jetzt, da die Post-PC-Ära angebrochen ist. Es gibt seit Jahrzehnten keine neuen ISAs bei CISC. Zu unserer Überraschung spricht der allgemeine Konsens über die besten ISA-Prinzipien für Allzweckprozessoren auch heute noch für RISC, 35 Jahre nach seiner Erfindung.
Moderne Herausforderungen für die Prozessorarchitektur
"Wenn ein Problem keine Lösung hat, ist es vielleicht kein Problem, sondern eine Tatsache, mit der man leben lernen sollte" - Shimon Peres
Obwohl sich der vorherige Abschnitt auf die Entwicklung einer Befehlssatzarchitektur (ISA) konzentrierte, entwickeln die meisten Designer in der Branche keine neuen ISAs, sondern integrieren vorhandene ISAs in vorhandene Fertigungstechnologien.
Seit den späten 70er Jahren sind die vorherrschenden Technologien integrierte Schaltkreise auf MOS-Strukturen (MOS), zuerst n-Typ (nMOS) und dann komplementär (CMOS). Das erstaunliche Tempo der Verbesserung der MOS-Technologie - erfasst von Gordon Moores Vorhersagen - war die treibende Kraft, die es Designern ermöglichte, aggressivere Methoden zur Erzielung von Leistung für eine bestimmte ISA zu entwickeln. Moores anfängliche Vorhersage von 1965 sah eine jährliche Verdoppelung der Transistordichte vor; 1975 überarbeitete er es und prognostizierte eine Verdoppelung alle zwei Jahre. Am Ende wurde diese Prognose als Moores Gesetz bezeichnet. Da die Dichte der Transistoren quadratisch und die Geschwindigkeit linear zunimmt, kann die Verwendung von mehr Transistoren die Produktivität steigern.Das Ende von Moores Gesetz und Dennards Skalierungsgesetz
Obwohl das Moore'sche Gesetz seit vielen Jahrzehnten in Kraft ist (siehe Abbildung 2), begann es sich um das Jahr 2000 herum zu verlangsamen, und bis 2018 hat sich die Kluft zwischen Moores Vorhersage und den gegenwärtigen Fähigkeiten auf das 15-fache vergrößert. Im Jahr 2003 schlug Moore vor, dass dies unvermeidlich sei . Derzeit wird erwartet, dass sich die Kluft weiter vergrößert, wenn die CMOS-Technologie an grundlegende Grenzen stößt.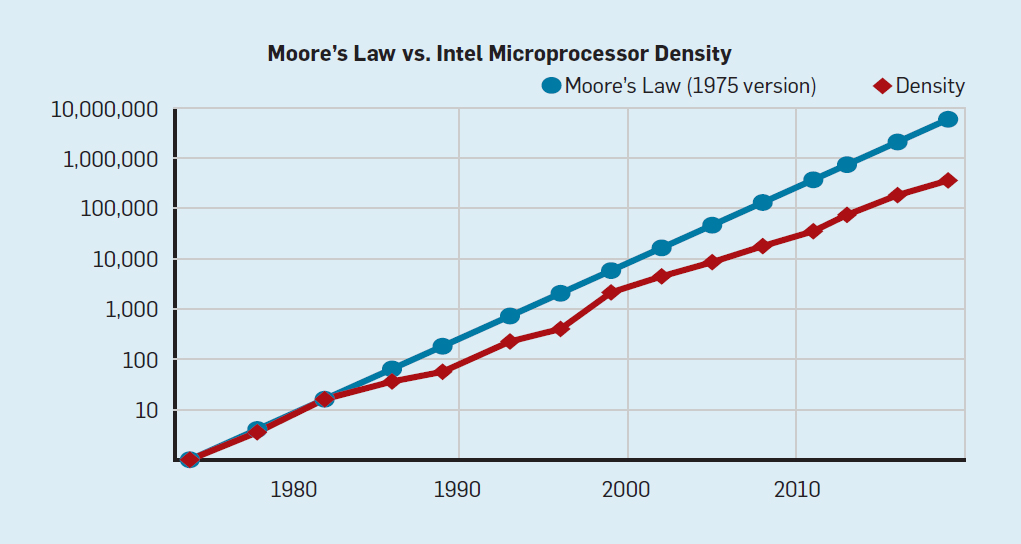 Abb. 2. Die Anzahl der Transistoren auf einem Intel-Chip im Vergleich zum Moore'schenGesetz. Das Moore'sche Gesetz wurde von einer Projektion von Robert Dennard mit dem Titel "Dennard Scaling" begleitet.Wenn die Dichte der Transistoren zunimmt, sinkt der Energieverbrauch des Transistors, so dass der Verbrauch pro mm² Silizium nahezu konstant bleibt. Als die Rechenleistung eines Siliziummillimeters mit jeder neuen Technologiegeneration zunahm, wurden Computer energieeffizienter. Dennards Skalierung begann sich 2007 erheblich zu verlangsamen und war bis 2012 praktisch umsonst (siehe Abb. 3).
Abb. 2. Die Anzahl der Transistoren auf einem Intel-Chip im Vergleich zum Moore'schenGesetz. Das Moore'sche Gesetz wurde von einer Projektion von Robert Dennard mit dem Titel "Dennard Scaling" begleitet.Wenn die Dichte der Transistoren zunimmt, sinkt der Energieverbrauch des Transistors, so dass der Verbrauch pro mm² Silizium nahezu konstant bleibt. Als die Rechenleistung eines Siliziummillimeters mit jeder neuen Technologiegeneration zunahm, wurden Computer energieeffizienter. Dennards Skalierung begann sich 2007 erheblich zu verlangsamen und war bis 2012 praktisch umsonst (siehe Abb. 3).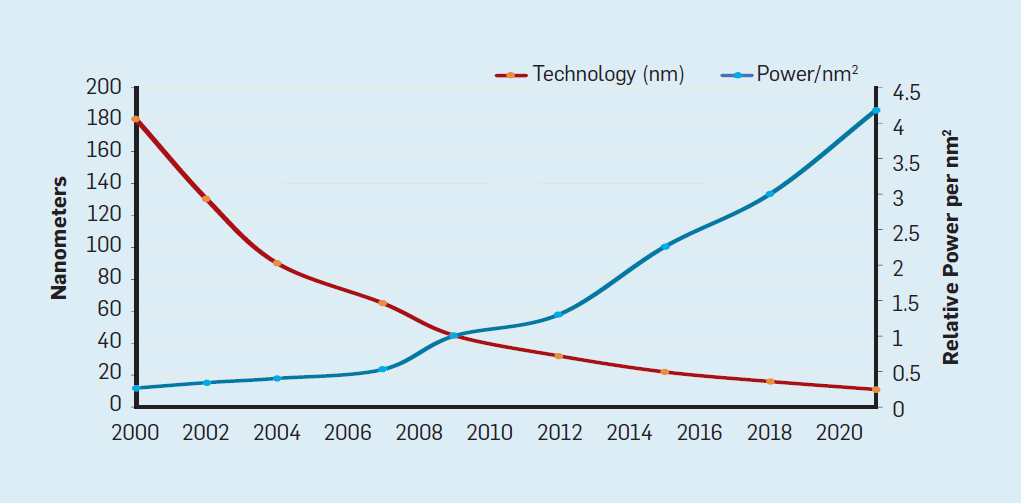 Abb. 3. Die Anzahl der Transistoren pro Chip und der Energieverbrauch pro mm²Von 1986 bis 2002 war die Parallelität auf Befehlsebene (ILP) die wichtigste Architekturmethode zur Steigerung der Produktivität. Zusammen mit der Erhöhung der Geschwindigkeit von Transistoren ergab dies eine jährliche Produktivitätssteigerung von etwa 50%. Das Ende von Dennards Skalierung bedeutete, dass Architekten bessere Wege finden mussten, um Parallelität zu nutzen.Um zu verstehen, warum eine Erhöhung des ILP die Effizienz verringert, betrachten Sie den Kern moderner ARM-, Intel- und AMD-Prozessoren. Angenommen, er hat eine 15-stufige Pipeline und vier Anweisungen pro Uhr. Somit befinden sich zu jeder Zeit auf dem Förderer bis zu 60 Anweisungen, einschließlich ungefähr 15 Zweige, da sie ungefähr 25% der ausgeführten Anweisungen ausmachen. Um die Pipeline zu füllen, werden Verzweigungen vorhergesagt und der Code wird spekulativ zur Ausführung in die Pipeline gestellt. Spekulative Prognosen sind sowohl die Ursache für die ILP-Leistung als auch für die Ineffizienz. Wenn die Verzweigungsvorhersage ideal ist, verbessert die Spekulation die Leistung und erhöht den Stromverbrauch nur geringfügig - und kann sogar Energie sparen. Wenn Verzweigungen jedoch nicht korrekt vorhergesagt werden, muss der Prozessor die falschen Berechnungen wegwerfen.und all die Arbeit und Energie verschwendet. Der interne Zustand des Prozessors muss ebenfalls in den Zustand zurückversetzt werden, der vor dem missverstandenen Zweig bestand, was zusätzliche Zeit und Energie kostet.Um zu verstehen, wie komplex ein solches Design ist, stellen Sie sich die Schwierigkeit vor, die Ergebnisse von 15 Zweigen korrekt vorherzusagen. Wenn der Konstruktor des Prozessors eine Grenze von 10% der Verluste festlegt, muss der Prozessor jeden Zweig mit einer Genauigkeit von 99,3% korrekt vorhersagen. Es gibt nicht viele Allzweck-Verzweigungsprogramme, die so genau vorhergesagt werden können.Um zu bewerten, woraus diese verschwendete Arbeit besteht, betrachten Sie die Daten in Abb. Fig. 4 zeigt den Anteil der Befehle, die effizient ausgeführt, aber verschwendet werden, weil der Prozessor die Verzweigung falsch vorhergesagt hat. In SPEC-Tests auf Intel Core i7 werden durchschnittlich 19% der Anweisungen verschwendet. Der Energieaufwand ist jedoch größer, da der Prozessor zusätzliche Energie verwenden muss, um den Zustand wiederherzustellen, wenn er falsch vorhergesagt wird.
Abb. 3. Die Anzahl der Transistoren pro Chip und der Energieverbrauch pro mm²Von 1986 bis 2002 war die Parallelität auf Befehlsebene (ILP) die wichtigste Architekturmethode zur Steigerung der Produktivität. Zusammen mit der Erhöhung der Geschwindigkeit von Transistoren ergab dies eine jährliche Produktivitätssteigerung von etwa 50%. Das Ende von Dennards Skalierung bedeutete, dass Architekten bessere Wege finden mussten, um Parallelität zu nutzen.Um zu verstehen, warum eine Erhöhung des ILP die Effizienz verringert, betrachten Sie den Kern moderner ARM-, Intel- und AMD-Prozessoren. Angenommen, er hat eine 15-stufige Pipeline und vier Anweisungen pro Uhr. Somit befinden sich zu jeder Zeit auf dem Förderer bis zu 60 Anweisungen, einschließlich ungefähr 15 Zweige, da sie ungefähr 25% der ausgeführten Anweisungen ausmachen. Um die Pipeline zu füllen, werden Verzweigungen vorhergesagt und der Code wird spekulativ zur Ausführung in die Pipeline gestellt. Spekulative Prognosen sind sowohl die Ursache für die ILP-Leistung als auch für die Ineffizienz. Wenn die Verzweigungsvorhersage ideal ist, verbessert die Spekulation die Leistung und erhöht den Stromverbrauch nur geringfügig - und kann sogar Energie sparen. Wenn Verzweigungen jedoch nicht korrekt vorhergesagt werden, muss der Prozessor die falschen Berechnungen wegwerfen.und all die Arbeit und Energie verschwendet. Der interne Zustand des Prozessors muss ebenfalls in den Zustand zurückversetzt werden, der vor dem missverstandenen Zweig bestand, was zusätzliche Zeit und Energie kostet.Um zu verstehen, wie komplex ein solches Design ist, stellen Sie sich die Schwierigkeit vor, die Ergebnisse von 15 Zweigen korrekt vorherzusagen. Wenn der Konstruktor des Prozessors eine Grenze von 10% der Verluste festlegt, muss der Prozessor jeden Zweig mit einer Genauigkeit von 99,3% korrekt vorhersagen. Es gibt nicht viele Allzweck-Verzweigungsprogramme, die so genau vorhergesagt werden können.Um zu bewerten, woraus diese verschwendete Arbeit besteht, betrachten Sie die Daten in Abb. Fig. 4 zeigt den Anteil der Befehle, die effizient ausgeführt, aber verschwendet werden, weil der Prozessor die Verzweigung falsch vorhergesagt hat. In SPEC-Tests auf Intel Core i7 werden durchschnittlich 19% der Anweisungen verschwendet. Der Energieaufwand ist jedoch größer, da der Prozessor zusätzliche Energie verwenden muss, um den Zustand wiederherzustellen, wenn er falsch vorhergesagt wird.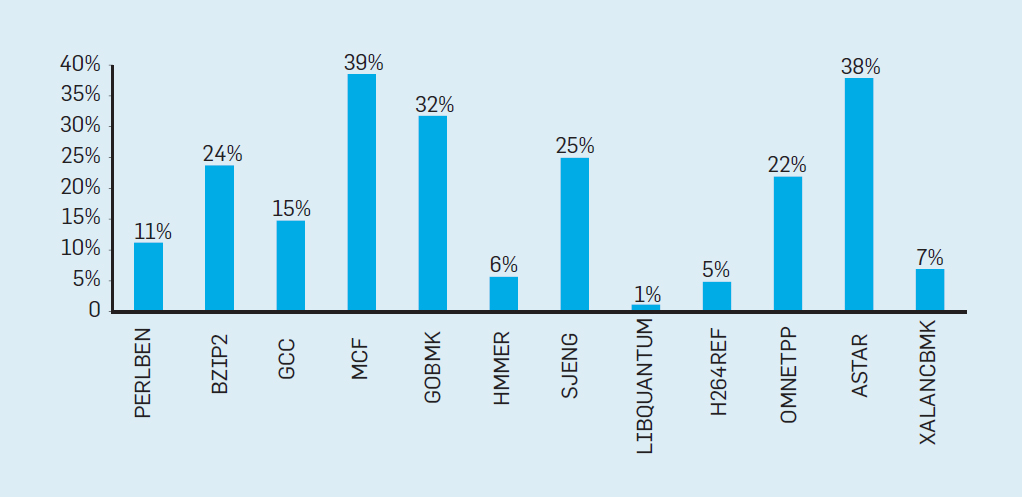 Abb. 4. Verschwendete Anweisungen als Prozentsatz aller Anweisungen, die auf Intel Core i7 für verschiedene ganzzahlige SPEC-Tests ausgeführt wurden.Solche Messungen führten viele zu dem Schluss, dass ein anderer Ansatz gesucht werden sollte, um eine bessere Leistung zu erzielen. So wurde die Multicore-Ära geboren.In diesem Konzept wird die Verantwortung für die Identifizierung der Parallelität und die Entscheidung über deren Verwendung auf den Programmierer und das Sprachsystem übertragen. Multicore löst nicht das Problem des energieeffizienten Rechnens, das durch das Ende der Dennard-Skalierung noch verschärft wurde. Jeder aktive Kern verbraucht Energie, unabhängig davon, ob er an effizienten Berechnungen beteiligt ist. Das Haupthindernis ist eine alte Beobachtung namens Amdahls Gesetz. Es heißt, dass die Vorteile des parallelen Rechnens durch den Anteil des sequentiellen Rechnens begrenzt sind. Um die Wichtigkeit dieser Beobachtung zu beurteilen, betrachten Sie Abbildung 5. Sie zeigt, wie viel schneller die Anwendung mit 64 Kernen im Vergleich zu einem Kern arbeitet, wobei ein anderer Anteil der sequentiellen Berechnungen angenommen wird, wenn nur ein Prozessor aktiv ist. Zum BeispielWenn die Berechnung in 1% der Fälle nacheinander durchgeführt wird, beträgt der Vorteil der 64-Prozessor-Konfiguration nur 35%. Leider ist der Stromverbrauch proportional zu 64 Prozessoren, sodass ungefähr 45% der Energie verschwendet werden.
Abb. 4. Verschwendete Anweisungen als Prozentsatz aller Anweisungen, die auf Intel Core i7 für verschiedene ganzzahlige SPEC-Tests ausgeführt wurden.Solche Messungen führten viele zu dem Schluss, dass ein anderer Ansatz gesucht werden sollte, um eine bessere Leistung zu erzielen. So wurde die Multicore-Ära geboren.In diesem Konzept wird die Verantwortung für die Identifizierung der Parallelität und die Entscheidung über deren Verwendung auf den Programmierer und das Sprachsystem übertragen. Multicore löst nicht das Problem des energieeffizienten Rechnens, das durch das Ende der Dennard-Skalierung noch verschärft wurde. Jeder aktive Kern verbraucht Energie, unabhängig davon, ob er an effizienten Berechnungen beteiligt ist. Das Haupthindernis ist eine alte Beobachtung namens Amdahls Gesetz. Es heißt, dass die Vorteile des parallelen Rechnens durch den Anteil des sequentiellen Rechnens begrenzt sind. Um die Wichtigkeit dieser Beobachtung zu beurteilen, betrachten Sie Abbildung 5. Sie zeigt, wie viel schneller die Anwendung mit 64 Kernen im Vergleich zu einem Kern arbeitet, wobei ein anderer Anteil der sequentiellen Berechnungen angenommen wird, wenn nur ein Prozessor aktiv ist. Zum BeispielWenn die Berechnung in 1% der Fälle nacheinander durchgeführt wird, beträgt der Vorteil der 64-Prozessor-Konfiguration nur 35%. Leider ist der Stromverbrauch proportional zu 64 Prozessoren, sodass ungefähr 45% der Energie verschwendet werden.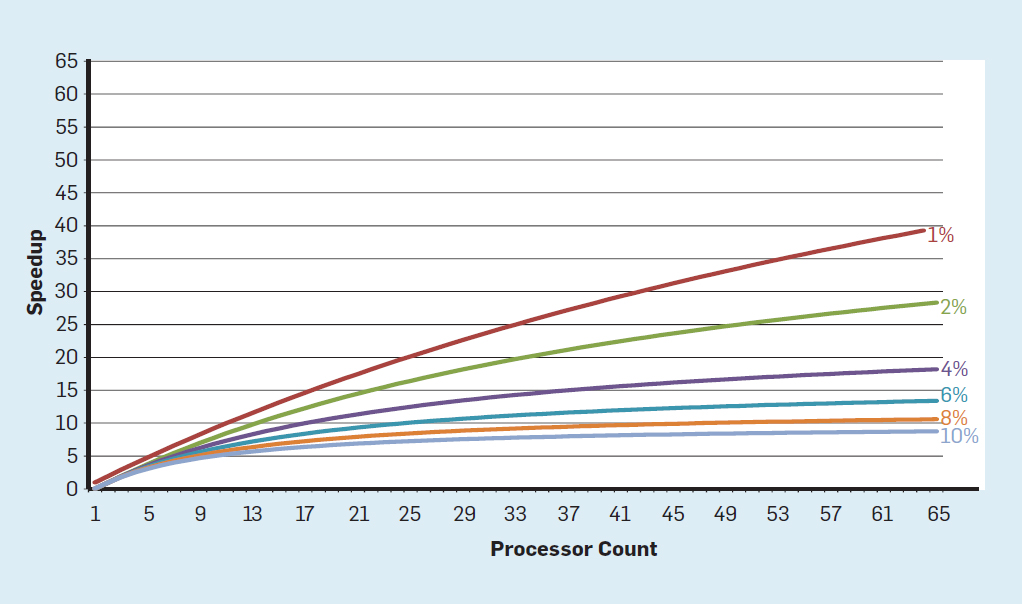 Abb. 5. Die Auswirkung des Amdahlschen Gesetzes auf die Geschwindigkeitssteigerung unter Berücksichtigung des Anteils der Maßnahmen im sequentiellen Modus.Natürlich haben reale Programme eine komplexere Struktur. Es gibt Fragmente, mit denen Sie zu einem bestimmten Zeitpunkt eine andere Anzahl von Prozessoren verwenden können. Die Notwendigkeit, sie regelmäßig zu interagieren und zu synchronisieren, bedeutet jedoch, dass die meisten Anwendungen einige Teile haben, die nur einen Teil der Prozessoren effizient nutzen können. Obwohl Amdahls Gesetz über 50 Jahre alt ist, bleibt es ein schwieriges Hindernis.Mit dem Ende der Dennard-Skalierung führte eine Erhöhung der Anzahl der Kerne auf dem Chip dazu, dass auch die Leistung fast gleich schnell anstieg. Leider sollte die dem Prozessor zugeführte Spannung dann als Wärme abgeführt werden. Mehrkernprozessoren sind daher durch die thermische Ausgangsleistung (TDP) oder die durchschnittliche Leistung begrenzt, die das Gehäuse und das Kühlsystem entfernen können. Obwohl einige High-End-Rechenzentren fortschrittlichere Kühltechnologien verwenden, sollte kein Benutzer einen kleinen Wärmetauscher auf den Tisch stellen oder einen Heizkörper auf dem Rücken tragen, um das Mobiltelefon zu kühlen. Die TDP-Grenze führte zur Ära des dunklen Siliziums, als Prozessoren die Taktrate verlangsamten und Leerlaufkerne ausschalteten, um eine Überhitzung zu verhindern. Eine andere Möglichkeit, diesen Ansatz zu berücksichtigen, besteht darin,dass einige Mikroschaltungen ihre kostbare Kraft von inaktiven auf aktive Kerne umverteilen können.Die Ära ohne Dennards Skalierung führt zusammen mit der Reduzierung des Moore'schen Gesetzes und des Amdahl'schen Gesetzes dazu, dass Ineffizienz die Produktivitätsverbesserung auf nur wenige Prozent pro Jahr begrenzt (siehe Abbildung 6).
Abb. 5. Die Auswirkung des Amdahlschen Gesetzes auf die Geschwindigkeitssteigerung unter Berücksichtigung des Anteils der Maßnahmen im sequentiellen Modus.Natürlich haben reale Programme eine komplexere Struktur. Es gibt Fragmente, mit denen Sie zu einem bestimmten Zeitpunkt eine andere Anzahl von Prozessoren verwenden können. Die Notwendigkeit, sie regelmäßig zu interagieren und zu synchronisieren, bedeutet jedoch, dass die meisten Anwendungen einige Teile haben, die nur einen Teil der Prozessoren effizient nutzen können. Obwohl Amdahls Gesetz über 50 Jahre alt ist, bleibt es ein schwieriges Hindernis.Mit dem Ende der Dennard-Skalierung führte eine Erhöhung der Anzahl der Kerne auf dem Chip dazu, dass auch die Leistung fast gleich schnell anstieg. Leider sollte die dem Prozessor zugeführte Spannung dann als Wärme abgeführt werden. Mehrkernprozessoren sind daher durch die thermische Ausgangsleistung (TDP) oder die durchschnittliche Leistung begrenzt, die das Gehäuse und das Kühlsystem entfernen können. Obwohl einige High-End-Rechenzentren fortschrittlichere Kühltechnologien verwenden, sollte kein Benutzer einen kleinen Wärmetauscher auf den Tisch stellen oder einen Heizkörper auf dem Rücken tragen, um das Mobiltelefon zu kühlen. Die TDP-Grenze führte zur Ära des dunklen Siliziums, als Prozessoren die Taktrate verlangsamten und Leerlaufkerne ausschalteten, um eine Überhitzung zu verhindern. Eine andere Möglichkeit, diesen Ansatz zu berücksichtigen, besteht darin,dass einige Mikroschaltungen ihre kostbare Kraft von inaktiven auf aktive Kerne umverteilen können.Die Ära ohne Dennards Skalierung führt zusammen mit der Reduzierung des Moore'schen Gesetzes und des Amdahl'schen Gesetzes dazu, dass Ineffizienz die Produktivitätsverbesserung auf nur wenige Prozent pro Jahr begrenzt (siehe Abbildung 6).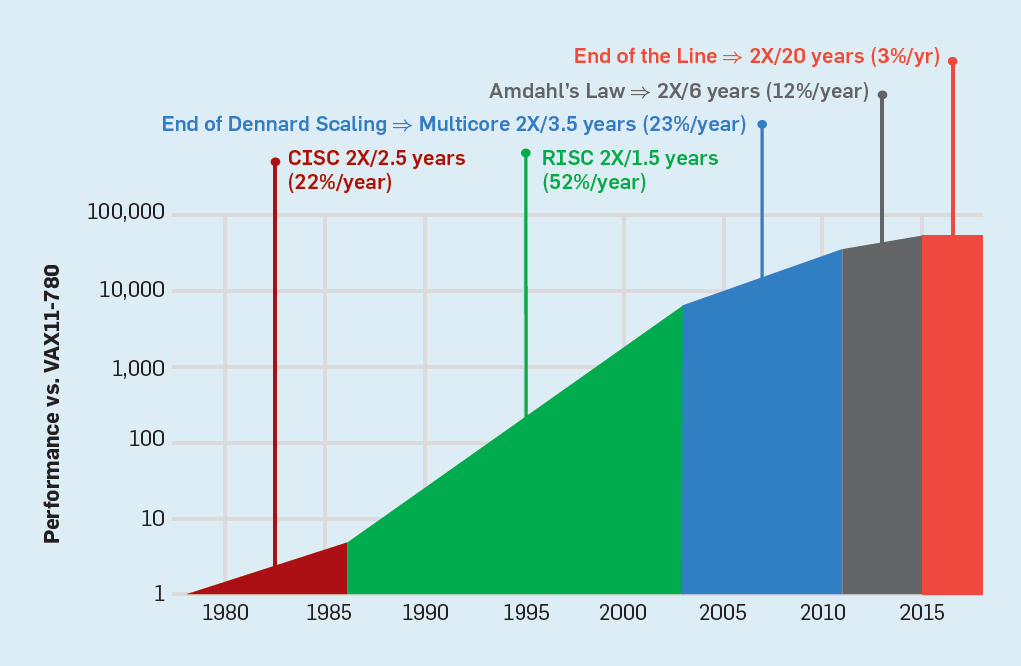 Abb. 6. Wachstum der Computerleistung durch ganzzahlige Tests (SPECintCPU) Umhöhere Leistungssteigerungsraten zu erzielen, wie in den 80er und 90er Jahren festgestellt wurde, sind neue Architekturansätze erforderlich, die integrierte Schaltkreise wesentlich effizienter nutzen. Wir werden auf die Diskussion potenziell wirksamer Ansätze zurückkommen und einen weiteren schwerwiegenden Nachteil moderner Computer erwähnen - die Sicherheit.
Abb. 6. Wachstum der Computerleistung durch ganzzahlige Tests (SPECintCPU) Umhöhere Leistungssteigerungsraten zu erzielen, wie in den 80er und 90er Jahren festgestellt wurde, sind neue Architekturansätze erforderlich, die integrierte Schaltkreise wesentlich effizienter nutzen. Wir werden auf die Diskussion potenziell wirksamer Ansätze zurückkommen und einen weiteren schwerwiegenden Nachteil moderner Computer erwähnen - die Sicherheit.Vergessene Sicherheit
In den 70er Jahren sorgten Prozessorentwickler mit Hilfe verschiedener Konzepte, von Schutzringen bis hin zu speziellen Funktionen, sorgfältig für Computersicherheit. Sie verstanden gut, dass die meisten Fehler in der Software enthalten sein würden, glaubten jedoch, dass die Unterstützung der Architektur helfen könnte. Diese Funktionen wurden von Betriebssystemen, die in vermeintlich sicheren Umgebungen (wie PCs) arbeiteten, meist nicht verwendet. Daher wurden die mit einem erheblichen Overhead verbundenen Funktionen eliminiert. In der Software-Community glaubten viele, dass formale Tests und Methoden wie die Verwendung eines Mikrokerns effektive Mechanismen für die Erstellung hochsicherer Software bieten würden. Leider führten die Größe unserer gängigen Softwaresysteme und das Streben nach Leistung dazu, dass solche Methoden nicht mit der Leistung mithalten konnten. Infolgedessen weisen große Softwaresysteme immer noch viele Sicherheitslücken auf, und der Effekt wird durch die große und wachsende Menge an persönlichen Informationen im Internet und die Verwendung von Cloud Computing verstärkt, bei dem Benutzer dieselbe physische Ausrüstung mit einem potenziellen Angreifer teilen.
Obwohl Prozessorentwickler und andere die wachsende Bedeutung der Sicherheit möglicherweise nicht sofort erkannt haben, haben sie begonnen, Hardware-Unterstützung für virtuelle Maschinen und Verschlüsselung aufzunehmen. Leider führte die Zweigvorhersage bei vielen Prozessoren zu einer unbekannten, aber signifikanten Sicherheitslücke. Insbesondere die
Sicherheitslücken Meltdown und Spectre nutzen die Funktionen der Mikroarchitektur und ermöglichen den Verlust geschützter Informationen . Beide verwenden die sogenannten Angriffe auf Kanäle von Drittanbietern, wenn Informationen entsprechend dem Zeitunterschied für die Aufgabe herauskommen. Im Jahr 2018 zeigten Forscher,
wie mit einer der Spectre-Optionen Informationen über das Netzwerk extrahiert werden können, ohne dass Code auf den Zielprozessor heruntergeladen werden muss . Obwohl dieser Angriff, NetSpectre genannt, Informationen langsam überträgt, führt die Tatsache, dass Sie jeden Computer im selben lokalen Netzwerk (oder im selben Cluster in der Cloud) angreifen können, zu vielen neuen Angriffsmethoden. Anschließend wurden zwei weitere Schwachstellen in der Architektur virtueller Maschinen gemeldet (
1 ,
2 ). Mit einem davon, Foreshadow, können Sie in Intel SGX-Sicherheitsmechanismen eindringen, die zum Schutz der wertvollsten Daten (z. B. Verschlüsselungsschlüssel) entwickelt wurden. Monatlich werden neue Schwachstellen gefunden.
Angriffe auf Kanäle von Drittanbietern sind nicht neu, aber in den meisten Fällen waren Softwarefehler früher der Fehler. Bei Meltdown-, Spectre- und anderen Angriffen ist dies ein Fehler in der Hardware-Implementierung. Es gibt eine grundlegende Schwierigkeit, wie Prozessorarchitekten die korrekte Implementierung von ISA bestimmen, da die Standarddefinition nichts über die Leistungseffekte der Ausführung einer Folge von Anweisungen aussagt, sondern nur über den sichtbaren Architekturausführungsstatus der ISA. Architekten sollten ihre Definition der korrekten Implementierung von ISA überdenken, um solche Sicherheitslücken zu vermeiden. Gleichzeitig müssen sie die Aufmerksamkeit überdenken, die sie der Computersicherheit widmen, und wie Architekten mit Softwareentwicklern zusammenarbeiten können, um sicherere Systeme zu implementieren. Architekten (und alle anderen) sollten Sicherheit nur als primäres Bedürfnis betrachten.
Zukünftige Möglichkeiten in der Computerarchitektur
"Wir haben erstaunliche Möglichkeiten, die als unlösbare Probleme getarnt sind." - John Gardner, 1965
Die inhärenten Ineffizienzen von Allzweckprozessoren, sei es ILP-Technologie oder Mehrkernprozessoren, in Kombination mit der Vervollständigung der Dennard-Skalierung und des Moore-Gesetzes machen es unwahrscheinlich, dass Architekten und Prozessorentwickler in der Lage sein werden, die Leistung von Allzweckprozessoren erheblich zu verbessern. Angesichts der Bedeutung der Verbesserung der Produktivität von Software müssen wir uns die Frage stellen: Welche anderen vielversprechenden Ansätze gibt es?
Es gibt zwei offensichtliche Möglichkeiten sowie eine dritte, die durch die Kombination der beiden entsteht. Erstens verwenden vorhandene Softwareentwicklungsmethoden in hohem Maße Hochsprachen mit dynamischer Typisierung. Leider werden solche Sprachen normalerweise äußerst ineffizient interpretiert und ausgeführt. Um diese Ineffizienz zu veranschaulichen,
gaben Leiserson und Kollegen
ein kleines Beispiel: Matrixmultiplikation .
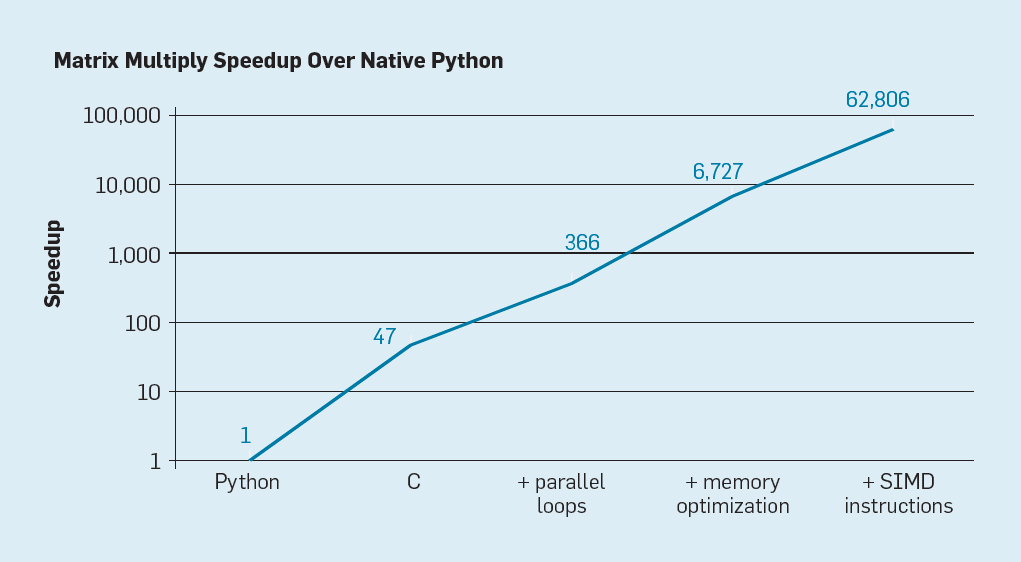 Abb. 7. Mögliche Beschleunigung der Multiplikation von Python-Matrizen nach vier Optimierungen
Abb. 7. Mögliche Beschleunigung der Multiplikation von Python-Matrizen nach vier OptimierungenWie in Abb. 7, einfaches Umschreiben von Code von Python nach C verbessert die Leistung um das 47-fache. Die Verwendung von parallelen Schleifen auf vielen Kernen ergibt einen zusätzlichen Faktor von etwa 7. Die Optimierung der Speicherstruktur für die Verwendung von Caches ergibt einen Faktor von 20, und der letzte Faktor von 9 ergibt sich aus der Verwendung von Hardwareerweiterungen zur Ausführung paralleler SIMD-Operationen, die 16 32-Bit-Befehle ausführen können. Danach läuft die endgültige, hochoptimierte Version auf dem Intel Multi-Core-Prozessor 62.806-mal schneller als die ursprüngliche Python-Version. Dies ist natürlich ein kleines Beispiel. Es ist davon auszugehen, dass Programmierer eine optimierte Bibliothek verwenden. Obwohl die Leistungslücke übertrieben ist, gibt es wahrscheinlich viele Programme, die 100-1000-mal optimiert werden können.
Ein interessantes Forschungsgebiet ist die Frage, ob es möglich ist, einige Leistungslücken mit der neuen Compilertechnologie zu schließen, möglicherweise mit architektonischen Verbesserungen. Obwohl es schwierig ist, hochrangige Skriptsprachen wie Python effizient zu übersetzen und zu kompilieren, ist der potenzielle Gewinn enorm. Schon eine kleine Optimierung kann dazu führen, dass Python-Programme zehn- bis hundertmal schneller ausgeführt werden. Dieses einfache Beispiel zeigt, wie groß die Kluft zwischen modernen Sprachen, die sich auf die Leistung von Programmierern konzentrieren, und traditionellen Ansätzen ist, bei denen die Leistung im Vordergrund steht.
Spezialisierte Architekturen
Ein hardwareorientierterer Ansatz ist das Entwerfen von Architekturen, die an einen bestimmten Themenbereich angepasst sind und dort eine erhebliche Effizienz aufweisen. Hierbei handelt es sich um spezialisierte domänenspezifische Architekturen (domänenspezifische Architekturen, DSAs). Dies sind normalerweise programmierbare und vollständig arbeitende Prozessoren, die jedoch eine bestimmte Klasse von Aufgaben berücksichtigen. In diesem Sinne unterscheiden sie sich von anwendungsspezifischen integrierten Schaltkreisen (ASICs), die häufig für dieselbe Funktion wie Code verwendet werden, der sich selten ändert. DSAs werden häufig als Beschleuniger bezeichnet, da sie einige Anwendungen beschleunigen, verglichen mit der Ausführung der gesamten Anwendung auf einer Allzweck-CPU. Darüber hinaus können DSAs eine bessere Leistung bieten, da sie genauer auf die Anforderungen der Anwendung zugeschnitten sind. Beispiele für DSAs sind Grafikprozessoren (GPUs), neuronale Netzwerkprozessoren für Deep Learning und Prozessoren für softwaredefinierte Netzwerke (SDNs). DSAs erzielen aus vier Hauptgründen eine höhere Leistung und eine höhere Energieeffizienz.
Erstens verwenden DSAs eine effizientere Form der Parallelität für einen bestimmten Themenbereich. Beispielsweise ist SIMD (Einzelbefehlsstrom, Mehrfachdatenstrom)
effizienter als MIMD (Mehrfachbefehlsstrom, Mehrfachdatenstrom). Obwohl SIMD weniger flexibel ist, eignet es sich gut für viele DSAs. Spezialisierte Prozessoren können anstelle schlecht spekulativer Mechanismen auch die ILP-Ansätze von VLIW verwenden. Wie bereits erwähnt, sind
VLIW-Prozessoren für Allzweckcode schlecht geeignet , für enge Bereiche jedoch viel effizienter, da die Steuerungsmechanismen einfacher sind. Insbesondere sind die meisten Allzweckprozessoren der Spitzenklasse übermäßig vielfach Pipeline-fähig, was eine komplexe Steuerlogik erfordert, um Anweisungen zu starten und zu vervollständigen. Im Gegensatz dazu führt VLIW die erforderliche Analyse und Planung zur Kompilierungszeit durch, was für ein eindeutig paralleles Programm gut funktionieren kann.
Zweitens nutzen DSA-Dienste die Speicherhierarchie besser. Der Zugriff auf den Speicher ist viel teurer geworden als arithmetische Berechnungen,
wie Horowitz feststellte . Der Zugriff auf einen Block in einem 32-KB-Cache erfordert beispielsweise etwa 200-mal mehr Energie als das Hinzufügen von 32-Bit-Ganzzahlen. Ein solch großer Unterschied macht die Optimierung des Speicherzugriffs entscheidend für die Erzielung einer hohen Energieeffizienz. Allzweckprozessoren führen Code aus, in dem Speicherzugriffe normalerweise eine räumliche und zeitliche Lokalität aufweisen, ansonsten aber zur Kompilierungszeit nicht sehr vorhersehbar sind. Um den Durchsatz zu erhöhen, verwenden CPUs daher mehrstufige Caches und verbergen die Verzögerung in relativ langsamen DRAMs außerhalb des Chips. Diese mehrstufigen Caches verbrauchen häufig etwa die Hälfte der Energie des Prozessors, verhindern jedoch fast alle Aufrufe des DRAM, der etwa zehnmal mehr Energie benötigt als der Zugriff auf den Cache der letzten Ebene.
Caches weisen zwei bemerkenswerte Mängel auf.
Wenn die Datensätze sehr groß sind . Caches funktionieren einfach nicht gut, wenn die Datensätze sehr groß sind und eine geringe zeitliche oder räumliche Lokalität aufweisen.
Wenn Caches gut funktionieren . Wenn Caches gut funktionieren, ist die Lokalität sehr hoch, dh per Definition ist der größte Teil des Caches die meiste Zeit inaktiv.
In Anwendungen, in denen Speicherzugriffsmuster zur Kompilierungszeit gut definiert und verständlich sind, was für typische domänenspezifische Sprachen (DSLs) gilt, können Programmierer und Compiler die Speichernutzung besser optimieren als dynamisch zugewiesene Caches. Daher verwenden DSAs normalerweise eine bewegte Speicherhierarchie, die explizit von der Software gesteuert wird, ähnlich wie Vektorprozessoren funktionieren. In den entsprechenden Anwendungen können Sie mit der „manuellen“ Benutzerspeichersteuerung viel weniger Energie als mit dem Standardcache verbrauchen.
Drittens kann DSA die Genauigkeit von Berechnungen verringern, wenn keine hohe Genauigkeit erforderlich ist. Allzweck-CPUs unterstützen normalerweise 32-Bit- und 64-Bit-Ganzzahlberechnungen sowie Gleitkommadaten (FP). Für viele maschinelle Lern- und Grafikanwendungen ist dies eine redundante Genauigkeit. In tiefen neuronalen Netzen werden beispielsweise bei der Berechnung häufig 4-, 8- oder 16-Bit-Zahlen verwendet, wodurch sowohl der Datendurchsatz als auch die Verarbeitungsleistung verbessert werden. In ähnlicher Weise sind Gleitkommaberechnungen zum Trainieren neuronaler Netze nützlich, aber 32 Bit und oft 16 Bit sind ausreichend.
Schließlich profitieren DSAs von Programmen, die in domänenspezifischen Sprachen geschrieben sind, die mehr Parallelität ermöglichen, die Struktur verbessern, den Speicherzugriff darstellen und die effiziente Anwendungsüberlagerung auf einem dedizierten Prozessor vereinfachen.
Fachorientierte Sprachen
DSAs erfordern, dass übergeordnete Vorgänge an die Prozessorarchitektur angepasst werden. In einer Allzwecksprache wie Python, Java, C oder Fortran ist dies jedoch sehr schwierig. Domain-spezifische Sprachen (DSLs) helfen dabei und ermöglichen es Ihnen, DSAs effektiv zu programmieren. Beispielsweise können DSLs explizite Vektor-, Dichtematrix- und Sparse-Matrix-Operationen explizit machen, sodass der DSL-Compiler Operationen effizient dem Prozessor zuordnen kann. Zu den domänenspezifischen Sprachen gehören Matlab, eine Sprache zum Arbeiten mit Matrizen, TensorFlow zum Programmieren neuronaler Netze, P4 zum Programmieren softwaredefinierter Netze und Halide zum Verarbeiten von Bildern mit Transformationen auf hoher Ebene.
Das Problem von DSL besteht darin, eine ausreichende Architekturunabhängigkeit aufrechtzuerhalten, damit die darauf befindliche Software auf verschiedene Architekturen portiert werden kann, während beim Vergleich von Software mit einem Basis-DSA eine hohe Effizienz erzielt wird. Beispielsweise
übersetzt ein XLA-System Tensorflow- Code in heterogene Systeme mit Nvidia-GPUs oder Tensor-Prozessoren (TPUs). Das Gleichgewicht zwischen Portabilität zwischen DSAs und die Aufrechterhaltung der Effizienz ist eine interessante Forschungsaufgabe für Sprachentwickler, Compiler und DSAs.
DSA-Beispiel: TPU v1
Betrachten Sie als Beispiel für DSA Google TPU v1, mit dem der Betrieb eines neuronalen Netzwerks beschleunigt werden soll (
1 ,
2 ). Diese TPU wird seit 2015 hergestellt und viele Anwendungen wurden darauf ausgeführt: von Suchanfragen über Textübersetzung bis hin zur Bilderkennung in AlphaGo und AlphaZero, DeepMind-Programme zum Spielen von Go and Chess. Ziel war es, die Produktivität und Energieeffizienz tiefer neuronaler Netze um das Zehnfache zu steigern.
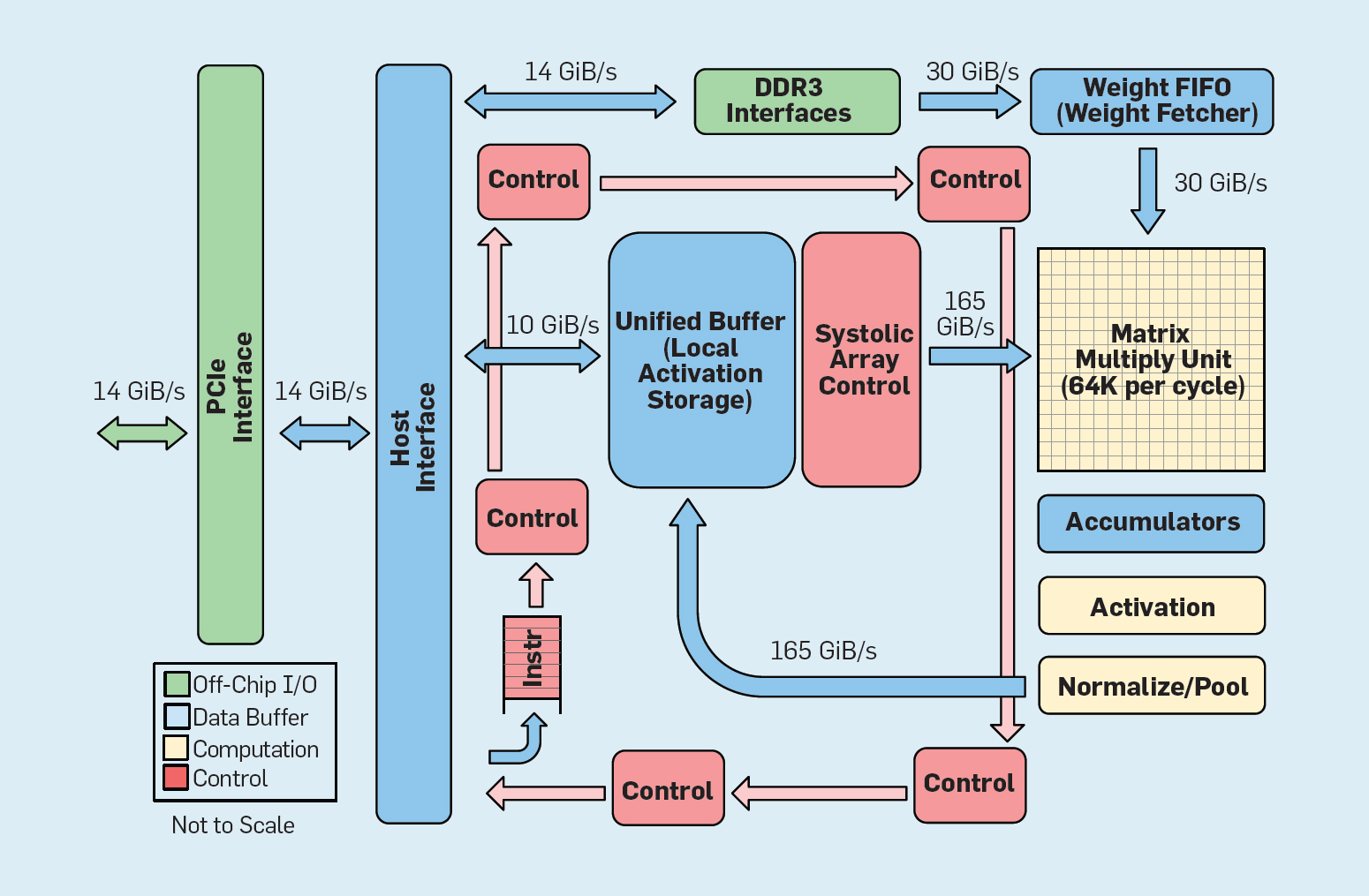 Abb. 8. Funktionale Organisation Google Tensor Processing Unit (TPU v1)
Abb. 8. Funktionale Organisation Google Tensor Processing Unit (TPU v1)Wie in Abbildung 8 dargestellt, unterscheidet sich die TPU-Organisation grundlegend von einem Allzweckprozessor. Die Hauptberechnungseinheit ist die Matrixeinheit, die
Struktur von systolischen Arrays , die in jedem Zyklus 256 × 256 Multiplikationsakkumulationen erzeugt. Die Kombination aus 8-Bit-Genauigkeit, einer hocheffizienten systolischen Struktur, SIMD-Steuerung und der Zuweisung eines wesentlichen Teils des Chips für diese Funktion trägt dazu bei, etwa 100-mal mehr Akkumulationsmultiplikationsoperationen pro Zyklus durchzuführen als ein Allzweck-CPU-Kern. Anstelle von Caches verwendet TPU 24 MB lokalen Speicher, was etwa doppelt so viel ist wie die Allzweck-CPU-Caches von 2015 mit derselben TDP. Schließlich sind sowohl der Neuronenaktivierungsspeicher als auch der neuronale Netzwerkausgleichsspeicher (einschließlich der FIFO-Struktur, in der die Gewichte gespeichert sind) über vom Benutzer gesteuerte Hochgeschwindigkeitskanäle verbunden. Die gewichtete durchschnittliche TPU-Leistung für sechs typische Probleme der logischen Ausgabe neuronaler Netze in Google-Rechenzentren ist 29-mal höher als die von Allzweckprozessoren. Da TPUs weniger als die Hälfte der Leistung benötigen, beträgt ihre Energieeffizienz für diese Arbeitslast mehr als das 80-fache der von Allzweckprozessoren.
Zusammenfassung
Wir haben zwei verschiedene Ansätze zur Verbesserung der Programmleistung untersucht, indem wir die Effizienz des Einsatzes von Hardwaretechnologien erhöht haben. Erstens durch Steigerung der Produktivität moderner Hochsprachen, die normalerweise interpretiert werden. Zweitens durch die Erstellung von Architekturen für bestimmte Themenbereiche, die die Leistung und Effizienz im Vergleich zu Allzweckprozessoren erheblich verbessern. Domänenspezifische Sprachen sind ein weiteres Beispiel für die Verbesserung der Hardware-Software-Schnittstelle, die Architekturinnovationen wie DSA ermöglicht. Um mit solchen Ansätzen einen signifikanten Erfolg zu erzielen, ist ein vertikal integriertes Projektteam erforderlich, das sich mit Anwendungen, fachorientierten Sprachen und verwandten Kompilierungstechnologien, Computerarchitektur sowie grundlegenden Implementierungstechnologien auskennt. Die Notwendigkeit der vertikalen Integration und der Entscheidungsfindung auf verschiedenen Abstraktionsebenen war typisch für die meisten frühen Arbeiten auf dem Gebiet der Computertechnologie, bevor die Branche horizontal strukturiert wurde. In dieser neuen Ära hat die vertikale Integration an Bedeutung gewonnen. Teams, die komplexe Kompromisse und Optimierungen finden und akzeptieren können, erhalten Vorteile.
Diese Gelegenheit hat bereits zu einem Anstieg der architektonischen Innovation geführt und viele konkurrierende Architekturphilosophien angezogen:
GPU Nvidia-GPUs
verwenden mehrere Kerne mit jeweils großen Registerdateien, mehreren Hardwarestreams und Caches.
TPU Google
TPUs basieren auf großen zweidimensionalen systolischen Arrays und programmierbarem On-Chip-Speicher.
FPGA Die Microsoft Corporation
implementiert in ihren Rechenzentren benutzerprogrammierbare Gate-Arrays (FPGAs), die in neuronalen Netzwerkanwendungen verwendet werden.
CPU Intel bietet Prozessoren mit vielen Kernen, einem großen mehrstufigen Cache und eindimensionalen SIMD-Anweisungen an, ähnlich wie das FPGA von Microsoft, und der
neue Neuroprozessor ist näher an der TPU als an der CPU .
Zusätzlich zu diesen Hauptakteuren setzen
Dutzende von Startups ihre eigenen Ideen um . Um der wachsenden Nachfrage gerecht zu werden, kombinieren Designer Hunderte und Tausende von Chips, um Supercomputer für neuronale Netze zu erstellen.
Diese Lawine neuronaler Netzwerkarchitekturen weist auf eine interessante Zeit in der Geschichte der Computerarchitektur hin. Im Jahr 2019 ist es schwierig vorherzusagen, welcher dieser vielen Bereiche gewinnen wird (wenn überhaupt jemand gewinnt), aber der Markt wird das Ergebnis definitiv bestimmen, so wie er die Architekturdebatte der Vergangenheit beigelegt hat.
Offene Architektur
Nach dem Vorbild erfolgreicher Open Source-Software bietet Open ISA eine alternative Möglichkeit in der Computerarchitektur. Sie werden benötigt, um eine Art „Linux für Prozessoren“ zu erstellen, damit die Community neben einzelnen Unternehmen, die proprietäre Kernel besitzen, auch Open-Source-Kernel erstellen kann. Wenn viele Unternehmen Prozessoren mit derselben ISA entwerfen, kann mehr Wettbewerb zu noch schnelleren Innovationen führen. Ziel ist es, eine Architektur für Prozessoren bereitzustellen, deren Kosten zwischen einigen Cent und 100 US-Dollar liegen.
Das erste Beispiel ist RISC-V (RISC Five), die
fünfte RISC-Architektur, die an der University of California in Berkeley entwickelt wurde . Sie wird von einer Community unterstützt, die von
der RISC-V Foundation geleitet wird .
Die Offenheit der Architektur ermöglicht die Entwicklung von ISA in der Öffentlichkeit unter Einbeziehung von Experten, bis eine endgültige Entscheidung getroffen wird. Ein zusätzlicher Vorteil eines offenen Fonds besteht darin, dass ISA wahrscheinlich nicht hauptsächlich aus Marketinggründen expandieren wird, da dies manchmal die einzige Erklärung für die Erweiterung ihrer eigenen Befehlssätze ist.RISC-V ist ein modularer Befehlssatz. Eine kleine Anweisungsbasis startet einen vollständigen Open-Source-Software-Stack, gefolgt von zusätzlichen Standarderweiterungen, die Designer je nach Bedarf aktivieren oder deaktivieren können. Diese Datenbank enthält 32-Bit- und 64-Bit-Versionen von Adressen. RISC-V kann nur durch optionale Erweiterungen wachsen. Der Software-Stack funktioniert weiterhin einwandfrei, auch wenn Architekten keine neuen Erweiterungen akzeptieren. Proprietäre Architekturen erfordern normalerweise Aufwärtskompatibilität auf Binärebene: Wenn das Prozessorunternehmen eine neue Funktion hinzufügt, sollten diese auch von allen zukünftigen Prozessoren enthalten sein. RISC-V nicht, hier sind alle Verbesserungen optional und können entfernt werden, wenn die Anwendung sie nicht benötigt.Hier sind die aktuellen Standarderweiterungen mit den Anfangsbuchstaben des vollständigen Namens:- M. Multiplikation / Division einer ganzen Zahl.
- A. Atomspeicheroperationen.
- F / d. Gleitkommaoperationen mit einfacher oder doppelter Genauigkeit.
- C. Komprimierte Anweisungen.
Das dritte Kennzeichen von RISC-V ist die Einfachheit von ISA. Obwohl dieser Indikator nicht quantifizierbar ist, gibt es hier zwei Vergleiche mit der ARMv8-Architektur, die parallel von ARM entwickelt wurde:- Weniger Anweisungen . RISC-V hat viel weniger Anweisungen. Es gibt 50 in der Datenbank, und sie sind in Anzahl und Charakter überraschend ähnlich wie das ursprüngliche RISC-I . Die übrigen Standarderweiterungen (M, A, F und D) fügen 53 Anweisungen hinzu, und C fügt 34 weitere hinzu, sodass die Gesamtzahl 137 beträgt. Zum Vergleich verfügt ARMv8 über mehr als 500 Anweisungen.
- . RISC-V : , ARMv8 14.
Die Einfachheit vereinfacht sowohl das Design von Prozessoren als auch die Überprüfung ihrer Richtigkeit. Da sich RISC-V auf alles konzentriert, von Rechenzentren bis hin zu IoT-Geräten, kann die Entwurfsvalidierung einen erheblichen Teil der Entwicklungskosten ausmachen.Viertens ist RISC-V nach 25 Jahren ein Clean-Sheet-Design, bei dem Architekten aus den Fehlern ihrer Vorgänger lernen. Im Gegensatz zur RISC-Architektur der ersten Generation werden Mikroarchitekturen oder Funktionen vermieden, die von der Technologie (z. B. verzögerte Verzweigungen und verzögerte Downloads) oder Innovationen (z. B. Registerfenster) abhängen, die durch Compiler-Fortschritte ersetzt wurden.Schließlich unterstützt RISC-V DSA und reserviert einen umfangreichen Opcode-Speicherplatz für benutzerdefinierte Beschleuniger.Neben RISC-V gab Nvidia auch bekannt (2017)Sie ist eine freie und offene Architektur und nennt sie Nvidia Deep Learning Accelerator (NVDLA). Es ist ein skalierbarer, anpassbarer DSA für Rückschlüsse auf maschinelles Lernen. Zu den Konfigurationsparametern gehören der Datentyp (int8, int16 oder fp16) und die Größe der zweidimensionalen Multiplikationsmatrix. Der Maßstab des Siliziumsubstrats variiert zwischen 0,5 mm² und 3 mm², und der Energieverbrauch liegt zwischen 20 mW und 300 mW. ISA, Software Stack und Implementierung sind offen.Offene, einfache Architekturen passen gut zur Sicherheit. Erstens glauben Sicherheitsexperten nicht an Sicherheit durch Dunkelheit, weshalb Open Source-Implementierungen attraktiv sind und Open Source-Implementierungen eine offene Architektur erfordern. Ebenso wichtig ist die Zunahme der Anzahl von Personen und Organisationen, die im Bereich sicherer Architekturen innovativ sein können. Proprietäre Architekturen schränken die Beteiligung der Mitarbeiter ein, aber offene Architekturen ermöglichen es den besten Köpfen in Wissenschaft und Industrie, bei der Sicherheit zu helfen. Schließlich vereinfacht die Einfachheit von RISC-V die Überprüfung seiner Implementierungen. Darüber hinaus ermöglichen offene Architekturen, Implementierungen und Software-Stacks sowie die Flexibilität von FPGAs, dass Architekten neue Lösungen online mit wöchentlichen statt jährlichen Release-Zyklen bereitstellen und bewerten können. Obwohl FPGAs zehnmal langsamer sind als benutzerdefinierte Chips,Ihre Leistung reicht jedoch aus, um online zu arbeiten und Sicherheitsinnovationen vor echten Angreifern zur Überprüfung zu präsentieren. Wir erwarten, dass offene Architekturen Beispiele für kollaboratives Hardware- und Software-Design von Architekten und Sicherheitsexperten sind.Flexible Hardwareentwicklung
Das Manifest für flexible Softwareentwicklung (2001) Beck et al. Revolutionierten die Softwareentwicklung, indem sie die Probleme eines traditionellen Wasserfallsystems auf der Grundlage von Planung und Dokumentation beseitigten. Kleine Teams von Programmierern erstellen schnell funktionierende, aber unvollständige Prototypen und erhalten Kundenfeedback, bevor mit der nächsten Iteration begonnen wird. Die Scrum-Version von Agile versammelt Teams von fünf bis zehn Programmierern, die pro Iteration zwei bis vier Wochen lang sprinten.Nachdem die Idee wieder aus der Softwareentwicklung übernommen wurde, ist es möglich, eine flexible Hardwareentwicklung zu organisieren. Die gute Nachricht ist, dass moderne ECAD-Tools (Electronic Computer Aided Design) den Abstraktionsgrad erhöht haben und eine flexible Entwicklung ermöglichen. Diese höhere Abstraktionsebene erhöht auch die Wiederverwendung von Arbeit zwischen verschiedenen Entwürfen.Vierwöchige Sprints erscheinen den Verarbeitern angesichts der Monate zwischen der Erstellung des Designs und der Chipherstellung unplausibel. In Abb.
Abbildung 9 zeigt, wie eine flexible Methode funktionieren kann, indem ein Prototyp auf einer geeigneten Ebene geändert wird .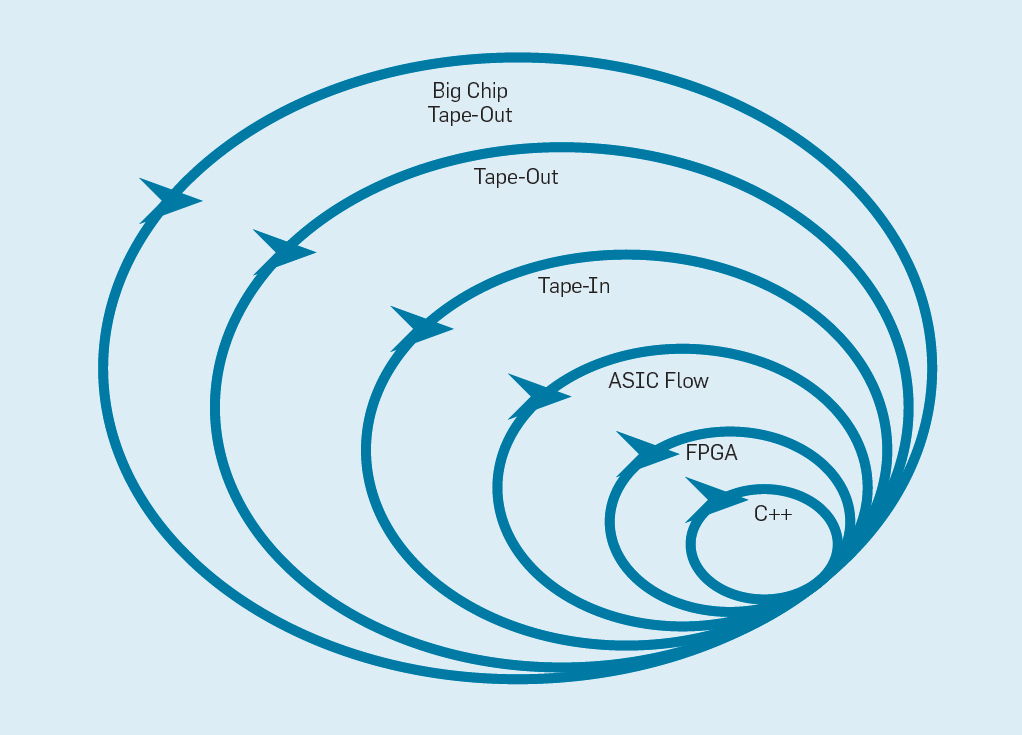 Abb. 9. Flexible Methoden zur GeräteentwicklungDie innerste Ebene ist ein Software-Simulator, der einfachste und schnellste Ort, um Änderungen vorzunehmen. Die nächste Stufe sind FPGA-Chips, die hunderte Male schneller arbeiten können als ein detaillierter Software-Simulator. FPGAs können mit Betriebssystemen und vollständigen Benchmarks wie der Standard Performance Evaluation Corporation (SPEC) arbeiten, die eine viel genauere Bewertung von Prototypen ermöglicht. Amazon Web Services bietet FPGAs in der Cloud an, sodass Architekten FPGAs verwenden können, ohne zuerst Geräte kaufen und ein Labor einrichten zu müssen. Die nächste Ebene verwendet ECAD-Tools, um eine Chipschaltung zu generieren und die Größe und den Stromverbrauch zu dokumentieren. Auch nachdem die Werkzeuge funktionieren, müssen einige manuelle Schritte ausgeführt werden, um die Ergebnisse zu verfeinern, bevor der neue Prozessor an die Produktion gesendet wird.Prozessorentwickler nennen dies die nächste Stufe.Band ein . Diese ersten vier Level unterstützen vierwöchige Sprints.Zu Forschungszwecken könnten wir auf Stufe vier aufhören, da die Schätzungen von Fläche, Energie und Leistung sehr genau sind. Aber es ist, als wäre ein Läufer einen Marathon gelaufen und hätte 5 Meter vor dem Ziel angehalten, weil seine Zielzeit bereits klar ist. Trotz der schwierigen Vorbereitung auf den Marathon wird er den Nervenkitzel und das Vergnügen vermissen, die Ziellinie tatsächlich zu überqueren. Einer der Vorteile von Hardware-Ingenieuren gegenüber Software-Ingenieuren besteht darin, dass sie physische Dinge erstellen. Chips aus der Fabrik holen: Messen, echte Programme ausführen, sie Freunden und der Familie zeigen, ist eine große Freude für den Designer.Viele Forscher glauben, sie sollten aufhören, weil die Chipherstellung zu erschwinglich ist. Aber wenn das Design klein ist, ist es überraschend günstig. Ingenieure können 100 Mikrochips von 1 mm² für nur 14.000 US-Dollar bestellen. Bei 28 nm enthält ein 1 mm²-Chip Millionen von Transistoren: Dies reicht für den RISC-V-Prozessor und den NVLDA-Beschleuniger. Die äußerste Ebene ist teuer, wenn der Designer einen großen Chip erstellen möchte, aber viele neue Ideen können auf kleinen Chips demonstriert werden.
Abb. 9. Flexible Methoden zur GeräteentwicklungDie innerste Ebene ist ein Software-Simulator, der einfachste und schnellste Ort, um Änderungen vorzunehmen. Die nächste Stufe sind FPGA-Chips, die hunderte Male schneller arbeiten können als ein detaillierter Software-Simulator. FPGAs können mit Betriebssystemen und vollständigen Benchmarks wie der Standard Performance Evaluation Corporation (SPEC) arbeiten, die eine viel genauere Bewertung von Prototypen ermöglicht. Amazon Web Services bietet FPGAs in der Cloud an, sodass Architekten FPGAs verwenden können, ohne zuerst Geräte kaufen und ein Labor einrichten zu müssen. Die nächste Ebene verwendet ECAD-Tools, um eine Chipschaltung zu generieren und die Größe und den Stromverbrauch zu dokumentieren. Auch nachdem die Werkzeuge funktionieren, müssen einige manuelle Schritte ausgeführt werden, um die Ergebnisse zu verfeinern, bevor der neue Prozessor an die Produktion gesendet wird.Prozessorentwickler nennen dies die nächste Stufe.Band ein . Diese ersten vier Level unterstützen vierwöchige Sprints.Zu Forschungszwecken könnten wir auf Stufe vier aufhören, da die Schätzungen von Fläche, Energie und Leistung sehr genau sind. Aber es ist, als wäre ein Läufer einen Marathon gelaufen und hätte 5 Meter vor dem Ziel angehalten, weil seine Zielzeit bereits klar ist. Trotz der schwierigen Vorbereitung auf den Marathon wird er den Nervenkitzel und das Vergnügen vermissen, die Ziellinie tatsächlich zu überqueren. Einer der Vorteile von Hardware-Ingenieuren gegenüber Software-Ingenieuren besteht darin, dass sie physische Dinge erstellen. Chips aus der Fabrik holen: Messen, echte Programme ausführen, sie Freunden und der Familie zeigen, ist eine große Freude für den Designer.Viele Forscher glauben, sie sollten aufhören, weil die Chipherstellung zu erschwinglich ist. Aber wenn das Design klein ist, ist es überraschend günstig. Ingenieure können 100 Mikrochips von 1 mm² für nur 14.000 US-Dollar bestellen. Bei 28 nm enthält ein 1 mm²-Chip Millionen von Transistoren: Dies reicht für den RISC-V-Prozessor und den NVLDA-Beschleuniger. Die äußerste Ebene ist teuer, wenn der Designer einen großen Chip erstellen möchte, aber viele neue Ideen können auf kleinen Chips demonstriert werden.Fazit
„Die dunkelste Stunde ist vor dem Morgengrauen“ - Thomas Fuller, 1650Um von den Lehren der Geschichte zu profitieren, müssen die Entwickler der Prozessoren verstehen, dass viel von der Softwareindustrie übernommen werden kann, dass die Erhöhung des Abstraktionsgrades der Hardware- / Softwareschnittstelle Chancen für Innovationen bietet und dass der Markt in letztendlich den Gewinner bestimmen. iAPX-432 und Itanium zeigen, wie Investitionen in Architektur nichts bewirken können, während S / 360, 8086 und ARM seit Jahrzehnten hohe Ergebnisse liefern, ohne dass ein Ende absehbar ist.Die Vervollständigung des Moore'schen Gesetzes und der Dennard'schen Skalierung sowie die Verlangsamung der Leistung von Standard-Mikroprozessoren sind keine Probleme, die gelöst werden sollten, sondern eine Selbstverständlichkeit, die, wie Sie wissen, aufregende Möglichkeiten bietet. Hochrangige fachorientierte Sprachen und Architekturen, die frei von Ketten proprietärer Befehlssätze sind, sowie die Forderung der Öffentlichkeit nach mehr Sicherheit werden ein neues goldenes Zeitalter für die Computerarchitektur eröffnen. In Open-Source-Ökosystemen werden künstlich entworfene Chips überzeugend Erfolge demonstrieren und dadurch die kommerzielle Implementierung beschleunigen. Die Allzweck-Prozessorphilosophie in diesen Chips ist wahrscheinlich RISC, das sich im Laufe der Zeit bewährt hat. Erwarten Sie die gleiche rasante Innovation wie im vergangenen goldenen Zeitalter.Aber diesmal in Bezug auf Kosten, Energie und Sicherheit, nicht nur in Bezug auf Leistung.In den nächsten zehn Jahren wird eine kambrische Explosion neuer Computerarchitekturen stattfinden, was für Computerarchitekten in Wissenschaft und Industrie aufregende Zeiten bedeutet.