
Wenn ich mich vorstelle und sage, was unser Startup tut, wirft der Gesprächspartner sofort die Frage auf: Haben Sie zuvor auf Facebook gearbeitet oder wurde Ihre Entwicklung unter dem Einfluss von Facebook erstellt? Viele sind sich der Bemühungen von Facebook bewusst, sein soziales Diagramm beizubehalten, da das Unternehmen
mehrere Artikel über die Infrastruktur dieses Diagramms veröffentlicht hat, die es sorgfältig erstellt hat.
Google sprach über
ihr Wissensdiagramm , aber nichts über die interne Infrastruktur. Das Unternehmen verfügt jedoch auch über spezialisierte Subsysteme. Tatsächlich wird dem Wissensgraphen viel Aufmerksamkeit geschenkt. Persönlich habe ich mindestens zwei meiner Werbeaktionen auf dieses Pferd gesetzt - und 2010 angefangen, an einer neuen Grafik zu arbeiten.
Google musste die Infrastruktur nicht nur für komplexe Beziehungen im Knowledge Graph
aufbauen , sondern auch alle thematischen
OneBox- Blöcke in Suchergebnissen unterstützen, die Zugriff auf strukturierte Daten haben. Die Infrastruktur ist erforderlich, um 1) die Fakten qualitativ zu umgehen, 2) eine ausreichend hohe Bandbreite und 3) eine ausreichend niedrige Verzögerung, um einen guten Anteil an Suchanfragen im Web zu erhalten. Es stellte sich heraus, dass nicht ein verfügbares System oder eine Datenbank alle drei Aktionen ausführen kann.
Als ich Ihnen erklärte, warum Infrastruktur benötigt wird, werde ich im Rest des Artikels über meine Erfahrungen beim Aufbau solcher Systeme berichten, einschließlich für
Knowledge Graph und
OneBox .
Woher weiß ich das?
Ich werde mich kurz vorstellen. Ich habe von 2006 bis 2013 bei Google gearbeitet. Zuerst als Praktikant, dann als Softwareentwickler in der Websuchinfrastruktur. Google
hat Metaweb im Jahr 2010 übernommen und mein Team hat gerade
Caffeine auf den
Markt gebracht . Ich wollte etwas anderes machen - und begann mit den Jungs von Metaweb (in San Francisco) zu arbeiten, um Zeit zwischen San Francisco und Mountain View zu verbringen. Ich wollte herausfinden, wie ich das Wissensdiagramm verwenden kann, um meine Websuche zu verbessern.
Es gab solche Projekte bei Google vor mir. Es ist bemerkenswert, dass das Projekt
Squared in einem New Yorker Büro erstellt wurde und über Wissenskarten gesprochen wurde. Dann gab es sporadische Bemühungen von Einzelpersonen / kleinen Teams, aber zu diesem Zeitpunkt gab es keine etablierte Teamkette, was mich letztendlich zwang, Google zu verlassen. Aber wir werden später darauf zurückkommen ...
Geschichte von Metaweb
Wie bereits erwähnt, hat Google Metaweb 2010 übernommen. Metaweb erstellte ein qualitativ hochwertiges Wissensdiagramm mit verschiedenen Methoden, darunter das Crawlen und Parsen von Wikipedia sowie ein Crowdsourcing-Bearbeitungssystem im Wiki-Stil mit
Freebase . All dies funktionierte auf der Grundlage der Graphd-eigenen Graph-Datenbank - dem Graph-Daemon (jetzt auf GitHub veröffentlicht).
Graphd hatte einige ziemlich typische Eigenschaften. Als Daemon funktionierte es auf einem Server, speicherte alle Daten im Speicher und konnte eine ganze Freebase-Site ausgeben. Nach dem Kauf hat Google eine der Aufgaben festgelegt, um mit Freebase weiterzuarbeiten.
Google baute ein Imperium auf Standardhardware und verteilter Software auf. Ein serverseitiges DBMS kann niemals Crawling-, Indizierungs- und Suchergebnisse bereitstellen. Zuerst wurde SSTable erstellt, dann Bigtable, das horizontal auf Hunderte oder Tausende von Computern skaliert, die Petabyte an Daten gemeinsam nutzen. Die Maschinen werden von Borg zugewiesen (
K8 kam von hier), sie kommunizieren über Stubby (gRPC kam von hier) mit der Auflösung von IP-Adressen über den Borg-Namensdienst (BNC in K8) und speichern Daten im Google-Dateisystem (
GFS , man kann sagen Hadoop FS).
Prozesse können sterben, Maschinen können kaputt gehen, aber das System als Ganzes ist unzerstörbar und summt weiter.Graphd geriet in eine solche Umgebung. Die Idee einer Datenbank, die eine ganze Website auf einem Server bereitstellt, ist Google (einschließlich mir) fremd. Insbesondere benötigte Graphd 64 GB oder mehr Speicher, um ausgeführt zu werden. Wenn es Ihnen so vorkommt, denken Sie daran: Dies ist 2010. Die meisten Google-Server waren mit maximal 32 GB ausgestattet. Tatsächlich musste Google spezielle Maschinen mit genügend RAM kaufen, um Graphd in seiner aktuellen Form zu bedienen.
Graphd Ersatz
Das Brainstorming begann damit, wie Graphd-Daten verschoben oder das System so umgeschrieben werden, dass es auf verteilte Weise funktioniert. Aber Sie sehen, die Grafiken sind kompliziert. Dies ist keine Schlüsselwertdatenbank für Sie, in der Sie einfach Daten aufnehmen, auf einen anderen Server verschieben und ausgeben können, wenn Sie einen Schlüssel anfordern. Diagramme führen effiziente Verknüpfungen und Problemumgehungen durch, für die Software auf bestimmte Weise funktionieren muss.
Eine Idee war, ein Projekt namens MindMeld (IIRC) zu verwenden. Es wurde angenommen, dass Speicher von einem anderen Server über Netzwerkgeräte viel schneller verfügbar sein würde. Es sollte schneller als normale RPCs sein und schnell genug, um den von der In-Memory-Datenbank benötigten direkten Speicherzugriff pseudo-replizieren zu können. Die Idee ging aber nicht zu weit.
Eine andere Idee, die tatsächlich zu einem Projekt wurde, war die Schaffung eines wirklich verteilten Graph-Service-Systems. Etwas, das nicht nur Graphd for Freebase ersetzen kann, sondern auch wirklich in der Produktion funktioniert.
Sie hieß Dgraph - ein verteilter Graph, der von Graphd (Graph-Daemon) invertiert wurde.Wenn Sie interessiert sind, dann ja. Mein Startup, Dgraph Labs, das Unternehmen und das Open-Source-Projekt Dgraph sind nach diesem Projekt bei Google benannt (Hinweis: Dgraph ist eine Marke von Dgraph Labs; soweit ich weiß, veröffentlicht Google keine Projekte mit Namen, die mit den internen übereinstimmen).
Wenn ich in fast dem gesamten Rest des Textes Dgraph erwähne, meine ich das interne Google-Projekt und nicht das Open-Source-Projekt, das wir erstellt haben. Aber dazu später mehr.
Die Geschichte von Cerebro: die Wissensmaschine
Versehentliche Erstellung einer Infrastruktur für DiagrammeObwohl ich allgemein wusste, dass Dgraph versucht, Graphd zu ersetzen, war mein Ziel, etwas zu schaffen, um die Websuche zu verbessern. Bei Metaweb traf ich einen DH-Forschungsingenieur, der
Cubed kreierte.
Wie bereits erwähnt, hat eine bunte Gruppe von Ingenieuren aus der New Yorker Division Google
Squared entwickelt . Aber das DH-System war
viel besser. Ich begann zu überlegen, wie ich es bei Google implementieren könnte. Google hatte Puzzleteile, die ich leicht verwenden konnte.
Der erste Teil des Puzzles ist die Suchmaschine. Auf diese Weise können Sie genau bestimmen, welche Wörter miteinander in Beziehung stehen. Wenn Sie beispielsweise eine Phrase wie [tom hanks movies] sehen, wird Ihnen möglicherweise mitgeteilt, dass [tom] und [hanks] verwandt sind. In ähnlicher Weise sehen wir aus [San Francisco Wetter] eine Verbindung zwischen [San] und [Francisco]. Dies sind offensichtliche Dinge für Menschen, aber nicht so offensichtlich für Autos.
Der zweite Teil des Puzzles ist das Verständnis der Grammatik. In der Abfrage [Bücher von französischen Autoren] kann die Maschine dies als [Bücher] von [französischen Autoren] interpretieren, dh Bücher der französischen Autoren. Sie kann dies aber auch als [französische Bücher] von [Autoren] interpretieren, dh Bücher in französischer Sprache von jedem Autor. Ich habe den POS-Tagger (
Part-Of-Speech ) der Stanford University verwendet, um die Grammatik besser zu analysieren und den Baum zu erstellen.
Der dritte Teil des Puzzles besteht darin, Entitäten zu verstehen. [französisch] kann viel bedeuten. Dies kann ein Land (eine Region), eine Nationalität (in Bezug auf das französische Volk), eine Küche (in Bezug auf Lebensmittel) oder eine Sprache sein. Dann habe ich ein anderes System angewendet, um eine Liste von Entitäten zu erhalten, denen ein Wort oder eine Phrase entsprechen kann.
Der vierte Teil des Puzzles bestand darin, die Beziehung zwischen Entitäten zu verstehen. Wenn bekannt ist, wie Wörter zu Phrasen verbunden werden, in welcher Reihenfolge Phrasen ausgeführt werden sollen, dh in welcher Grammatik und welchen Entitäten sie entsprechen können, müssen Sie die Beziehung zwischen diesen Entitäten finden, um Maschineninterpretationen zu erstellen. Zum Beispiel führen wir die Abfrage [Bücher von französischen Autoren] aus, und POS sagt, es handelt sich um [Bücher] von [französischen Autoren]. Wir haben mehrere Entitäten für [Französisch] und mehrere für [Autoren]: Der Algorithmus sollte bestimmen, wie sie zusammenhängen. Zum Beispiel können sie nach Geburtsort verwandt sein, dh nach Autoren, die in Frankreich geboren wurden (obwohl sie auf Englisch schreiben können). Oder es könnten Autoren sein, die französische Staatsbürger sind. Entweder Autoren, die Französisch sprechen oder schreiben können (aber möglicherweise nicht mit Frankreich als Land verwandt sind), oder Autoren, die einfach die französische Küche lieben.
Suche Index Graph System
Um festzustellen, ob eine Verbindung zwischen Objekten besteht und wie sie verbunden sind, benötigen Sie ein Diagrammsystem. Graphd wollte nie auf die Google-Ebene skalieren, aber Sie konnten die Suche selbst verwenden. Knowledge Graph-Daten werden im Triple-Triple-Format gespeichert,
dh jede Tatsache wird durch drei Teile dargestellt: Subjekt (Entität), Prädikat (Beziehung) und Objekt (andere Entität). Anfragen lauten wie
[SP] → [O] oder
[PO] → [S] und manchmal
[SO] → [P] .
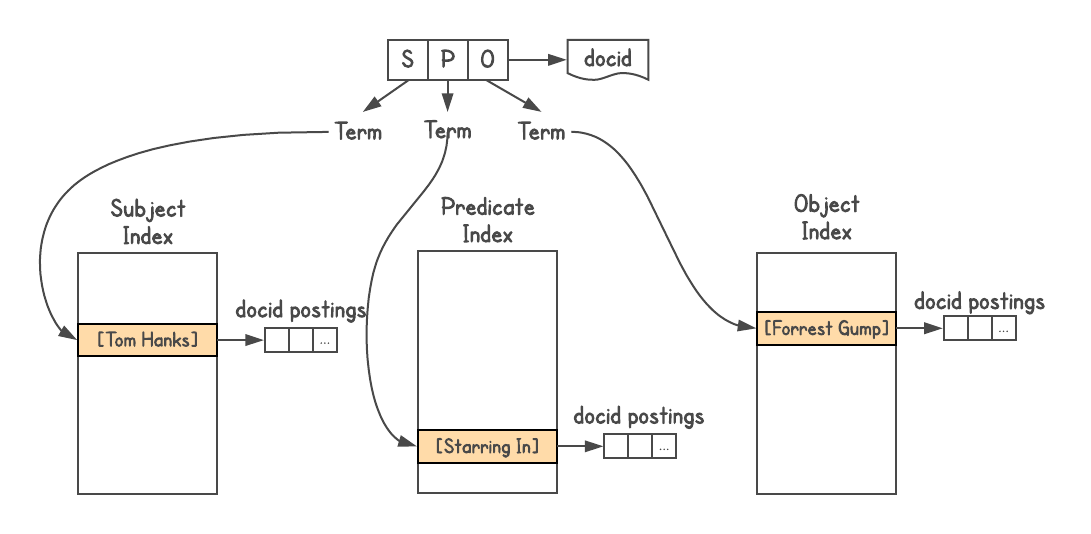 Ich habe den Google-Suchindex verwendet
Ich habe den Google-Suchindex verwendet , jedem Tripel eine Dokument-ID zugewiesen und drei Indizes erstellt, einen für S, P und O. Außerdem ist der Index verschachtelbar, sodass ich Informationen über den Typ jeder Entität (d. H. Schauspieler, Buch, Person und) hinzugefügt habe usw.).
Ich habe ein solches System erstellt, obwohl ich ein Problem mit der Tiefe der Verknüpfungen gesehen habe (das unten erläutert wird) und es nicht für komplexe Abfragen geeignet ist. Als mich jemand vom Metaweb-Team bat, ein System für Kollegen zu veröffentlichen, lehnte ich dies ab.Um die Beziehung zu bestimmen, können Sie sehen, wie viele Ergebnisse jede Abfrage liefert. Wie viele Ergebnisse geben beispielsweise [Französisch] und [Autor]? Wir nehmen diese Ergebnisse und sehen, wie sie mit [Büchern] usw. zusammenhängen. Daher erschienen viele maschinelle Interpretationen der Abfrage. Beispielsweise generiert die Abfrage [Tom Hanks-Filme] eine Vielzahl von Interpretationen, z. B. [Filme von Tom Hanks], [Filme mit Tom Hanks], [Filme von Tom Hanks], lehnt jedoch automatisch Interpretationen wie [Filme mit dem Namen Tom Hanks] ab.
Jede Interpretation generiert eine Liste der Ergebnisse - gültige Entitäten im Diagramm - und gibt auch deren Typen zurück (in Anhängen vorhanden). Dies erwies sich als äußerst leistungsfähige Funktion, da das Verständnis der Art der Ergebnisse Möglichkeiten wie Filtern, Sortieren oder weitere Erweiterung eröffnete. Sie können Filme nach Erscheinungsjahr, Länge des Films (kurz, lang), Sprache, erhaltenen Auszeichnungen usw. sortieren.
Das Projekt schien so intelligent, dass wir (DH war auch teilweise als Experte für das Wissensdiagramm beteiligt) es Cerebro nannten, zu Ehren des gleichnamigen Geräts aus dem Film
„X-Men“ .
Cerebro enthüllte oft sehr interessante Fakten , die ursprünglich nicht in der Suchanfrage enthalten waren. Zum Beispiel wird Cerebro auf Wunsch von [US-Präsidenten] erkennen, dass Präsidenten Menschen sind und Menschen Wachstum haben. Dies ermöglicht es uns, Präsidenten nach Wachstum zu sortieren und zu zeigen, dass Abraham Lincoln der höchste Präsident der Vereinigten Staaten ist. Darüber hinaus können Personen nach Nationalität gefiltert werden. In diesem Fall erscheinen Amerika und das Vereinigte Königreich auf der Liste, weil die Vereinigten Staaten einen britischen Präsidenten hatten, nämlich George Washington. (Haftungsausschluss: Die Ergebnisse basieren auf dem Stand des Wissensgraphen zum Zeitpunkt des Experiments; ich kann nicht für deren Richtigkeit bürgen).
Blaue Links versus Wissen
Cerebro konnte Benutzeranfragen wirklich verstehen. Nachdem wir Daten für das gesamte Diagramm erhalten haben, können wir maschinelle Interpretationen der Abfrage generieren, eine Ergebnisliste erstellen und aus diesen Ergebnissen viel verstehen, um das Diagramm weiter zu untersuchen. Es wurde oben erklärt: Sobald das System versteht, dass es sich um Filme, Personen oder Bücher usw. handelt, können bestimmte Filter und Sortierungen aktiviert werden. Sie können sogar die Knoten umgehen und verwandte Informationen anzeigen: von [US-Präsidenten] bis [Schulen, in die sie gegangen sind] oder [Kindern, die sie gezeugt haben]. Hier sind einige andere Fragen, die das System selbst generiert hat: [afroamerikanische Politikerinnen], [mit Politikern verheiratete Bollywood-Schauspieler], [Kinder von uns Präsidenten], [Filme mit Tom Hanks, die in den 90er Jahren veröffentlicht wurden]
DH demonstrierte diese Möglichkeit, in einem anderen Projekt namens
Parallax von einer Liste zur anderen zu wechseln.
Cerebro zeigte ein sehr beeindruckendes Ergebnis, und das Metaweb-Management unterstützte es. Auch in Bezug auf die Infrastruktur erwies es sich als effizient und funktional. Ich nannte es
die Wissensmaschine (wie eine Suchmaschine). Bei Google hat sich jedoch niemand speziell mit diesem Thema befasst. Sie war für meinen Manager von geringem Interesse, sie rieten mir, mit einer Person und dann mit einer anderen zu sprechen, und als Ergebnis hatte ich die Möglichkeit, das System einem sehr hochrangigen Suchmanager zu demonstrieren.
Die Antwort war nicht die, auf die ich gehofft hatte . Um die Ergebnisse der Wissens-Engine für [Bücher französischer Autoren] zu demonstrieren, startete er eine Google-Suche, zeigte zehn Zeilen mit blauen Links und sagte, dass Google dasselbe tun könne. Außerdem möchten sie keinen Datenverkehr von Websites aufnehmen, weil sie wütend werden.
Wenn Sie der Meinung sind, dass er Recht hat, denken Sie darüber nach: Wenn Google im Internet sucht, versteht es die Anfrage wirklich nicht. Das System sucht an der richtigen Position nach den richtigen Wörtern, wobei das Gewicht der Seite usw. berücksichtigt wird. Dies ist ein sehr komplexes System, das jedoch weder die Abfrage noch die Ergebnisse versteht. Der Benutzer selbst erledigt die gesamte Arbeit: Lesen, Analysieren, Extrahieren der erforderlichen Informationen aus den Ergebnissen und weitere Suchen, Zusammenstellen einer vollständigen Ergebnisliste usw.
Beispielsweise wird eine Person bei [Büchern französischer Autoren] zunächst versuchen, eine vollständige Liste zu finden, obwohl eine Seite mit einer solchen Liste möglicherweise nicht gefunden wird. Sortieren Sie diese Bücher dann nach Jahren der Veröffentlichung oder filtern Sie sie nach Verlagen usw. - all dies erfordert, dass eine Person eine große Menge an Informationen und zahlreiche Suchanfragen verarbeitet und die Ergebnisse verarbeitet. Cerebro ist in der Lage, diesen Aufwand zu reduzieren und die Benutzerinteraktion einfach und fehlerfrei zu gestalten.
Aber dann gab es kein vollständiges Verständnis für die Bedeutung des Wissensgraphen. Das Handbuch war sich nicht sicher, ob es nützlich war oder wie es mit der Suche in Beziehung gesetzt werden sollte.
Dieser neue Wissensansatz ist für die Organisation, die durch die Bereitstellung von Links zu Webseiten für Benutzer einen so bedeutenden Erfolg erzielt hat, nicht einfach.Im Laufe des Jahres hatte ich mit einem Missverständnis der Manager zu kämpfen und gab schließlich auf. Ein Manager aus dem Büro in Shanghai wandte sich an mich und ich gab ihm das Projekt im Juni 2011. Er stellte ihm ein Team von 15 Ingenieuren auf. Ich verbrachte eine Woche in Shanghai und gab alles, was ich geschaffen und gelernt hatte, an die Ingenieure weiter. DH war auch in dieses Geschäft involviert und leitete das Team für eine lange Zeit.
Problem mit der Verbindungstiefe
Im Cerebro-Grafiksystem gab es ein Problem mit der Tiefe der Vereinigung. Der Join wird ausgeführt, wenn das Ergebnis einer frühen Abfrage benötigt wird, um eine spätere abzuschließen. Eine typische Vereinigung enthält etwas
SELECT , d. H. Einen Filter in bestimmten Ergebnissen aus einem universellen Datensatz, und diese Ergebnisse werden dann verwendet, um nach einem anderen Teil des Datensatzes zu filtern. Ich werde mit einem Beispiel erklären.
Angenommen, Sie möchten wissen [Leute in SF, die Sushi essen]. Allen Menschen werden einige Daten zugewiesen, einschließlich wer in welcher Stadt lebt und welche Art von Essen sie essen.
Die obige Abfrage ist eine einstufige Verknüpfung. Wenn die Anwendung auf die Datenbank zugreift, wird eine Anforderung für den ersten Schritt gestellt. Dann ein paar Abfragen (eine Abfrage für jedes Ergebnis), um herauszufinden, was jede Person isst, und nur diejenigen auswählen, die Sushi essen.
Der zweite Schritt leidet unter dem Fan-Out-Problem. Wenn der erste Schritt eine Million Ergebnisse liefert (die Bevölkerung von San Francisco), sollte der zweite Schritt auf Anfrage an alle gerichtet werden, nach ihren Essgewohnheiten fragen und dann einen Filter anwenden.

Verteilte Systemingenieure lösen dieses Problem normalerweise durch
Broadcast , dh durch allgegenwärtige Verteilung. Sie sammeln die entsprechenden Ergebnisse und stellen eine Anforderung an jeden Server im Cluster. Dies stellt einen Join bereit, verursacht jedoch Probleme mit der Anforderungslatenz.
Broadcasting funktioniert in einem verteilten System nicht gut. Dieses Problem lässt sich am besten von
Jeff Dean von Google in seiner Rede „Schnelle Reaktion bei großen Online-Diensten“ (
Videos ,
Folien ) erklären. Die Gesamtverzögerung ist immer größer als die Verzögerung der langsamsten Komponente.
Kleine Blendung auf einzelnen Computern führt zu Verzögerungen, und die Einbeziehung vieler Computer in die Abfrage erhöht die Wahrscheinlichkeit von Verzögerungen erheblich.Stellen Sie sich einen Server mit einer Verzögerung von mehr als 1 ms in 50% der Fälle und mehr als 1 s in 1% der Fälle vor. Wenn die Anforderung nur an einen solchen Server gesendet wird, überschreitet nur 1% der Antworten eine Sekunde. Wenn die Anfrage jedoch an Hunderte solcher Server geht, überschreiten 63% der Antworten eine Sekunde.
Somit erhöht die Übertragung einer Anfrage die Verzögerung erheblich. Denken Sie jetzt nach, und wenn Sie zwei, drei oder mehr Assoziationen benötigen? Es ist zu langsam, um in Echtzeit ausgeführt zu werden.
Das Problem der Lüfterbereitstellung bei der Anforderungsübertragung ist den meisten nicht nativen DBs von Diagrammen inhärent, einschließlich dem
Janus-Diagramm ,
Twitter FlockDB und
Facebook TAO .
Verteilte Assoziationen sind ein komplexes Problem. Mit nativen Diagrammdatenbanken kann dieses Problem vermieden werden, indem ein universeller Datensatz auf einem Server (eigenständige Datenbank) gespeichert und alle Verknüpfungen ausgeführt werden, ohne auf andere Server zuzugreifen. Zum Beispiel macht
Neo4j dies.
Dgraph: Gewerkschaften mit beliebiger Tiefe
Nachdem ich die Arbeit an Cerebro abgeschlossen und Erfahrung im Aufbau eines Grafikmanagementsystems gesammelt hatte, nahm ich am Dgraph-Projekt teil und wurde einer der drei technischen Projektmanager. Wir haben innovative Konzepte angewendet, die das Problem der Tiefe der Gewerkschaft gelöst haben.
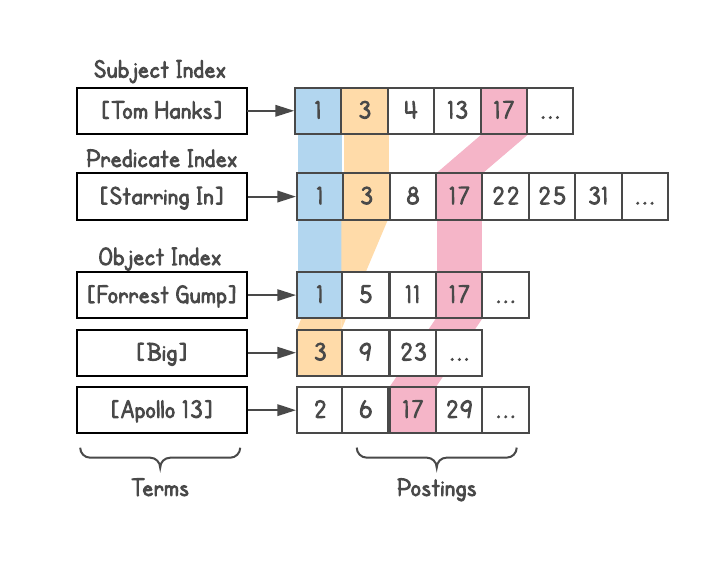
Insbesondere trennt Dgraph Diagrammdaten, sodass jeder Join vollständig von einer Maschine ausgeführt werden kann. Zurück zum SPO
subject-predicate-object (
subject-predicate-object ) enthält jede Dgraph-Instanz alle Subjekte und Objekte, die jedem Prädikat in dieser Instanz entsprechen. In einer Instanz sind mehrere Prädikate gespeichert, von denen jedes vollständig gespeichert ist.
Dies ermöglichte es uns, Anfragen mit einer beliebigen Tiefe von Assoziationen zu erfüllen , wodurch das Problem der Lüfterbereitstellung während der Übertragung beseitigt wurde. Beispielsweise generiert die Abfrage [Personen in SF, die Sushi essen] unabhängig von der Clustergröße
maximal zwei Netzwerkanrufe in der Datenbank. Die erste Herausforderung wird alle Menschen finden, die in San Francisco leben. Bei der zweiten Anfrage wird diese Liste an alle Personen gesendet, die Sushi essen. Anschließend können Sie zusätzliche Einschränkungen oder Erweiterungen hinzufügen. Jeder Schritt sieht weiterhin nicht mehr als einen Netzwerkanruf vor.

Dies führt zu dem Problem sehr großer Prädikate auf demselben Server. Es kann jedoch gelöst werden, indem die Prädikate mit zunehmender Größe weiter auf zwei oder mehr Instanzen aufgeteilt werden. Im schlimmsten Fall wird ein Prädikat über den gesamten Cluster aufgeteilt. Dies geschieht jedoch nur in einer fantastischen Situation, in der alle Daten nur einem Prädikat entsprechen. In anderen Fällen kann dieser Ansatz die Verzögerung von Anforderungen in realen Systemen erheblich reduzieren.
Sharding war nicht die einzige Innovation in Dgraph. Allen Objekten wurden ganzzahlige Bezeichner zugewiesen, sie wurden sortiert und in Form einer Liste (Buchungsliste) gespeichert, um solche Listen später schnell zu überqueren. Auf diese Weise können Sie während des Zusammenführens schnell filtern, allgemeine Links finden usw. Auch hier sind Ideen der Google-Suchmaschinen hilfreich.
Kombinieren aller OneBox-Blöcke durch Plasma
Googles dgraph war keine Datenbank . Dies war eines der Subsysteme, die auch auf Aktualisierungen reagierten. Also musste sie indizieren. Ich habe umfangreiche Erfahrung mit inkrementellen Echtzeit-Indizierungssystemen, die unter
Koffein ausgeführt werden .
Ich habe ein Projekt gestartet, um alle OneBox in diesem Diagrammindizierungssystem zu vereinheitlichen, einschließlich Wetter, Flugpläne, Ereignisse usw. Möglicherweise kennen Sie den Begriff OneBox nicht, aber Sie haben ihn definitiv gesehen. Dies ist ein separates Fenster, das angezeigt wird, wenn bestimmte Arten von Abfragen ausgeführt werden, in denen Google umfangreichere Informationen zurückgibt. Um OneBox in Aktion zu sehen, versuchen Sie [
Wetter in SF ].
Zuvor arbeitete jede OneBox an einem autonomen Backend und wurde von verschiedenen Entwicklungsgruppen unterstützt.
Es gab eine Vielzahl strukturierter Daten, aber OneBox-Einheiten tauschten keine Daten miteinander aus. Erstens haben verschiedene Backends die Arbeitskosten um ein Vielfaches erhöht. Zweitens beschränkte der Mangel an Informationsaustausch den Umfang der Anfragen, auf die Google antworten konnte.
Beispielsweise könnten [Ereignisse in SF] Ereignisse und [Wetter in SF] Wetter anzeigen. Aber wenn [Ereignisse in SF] verstanden haben, dass es jetzt
regnet , können Sie Ereignisse nach Typ „drinnen“ oder „draußen“ filtern oder sortieren (
vielleicht ist es besser, ins Kino zu gehen, als bei starkem Regen Fußball zu spielen). )
Mit Hilfe des Metaweb-Teams haben wir begonnen, alle diese Daten in das SPO-Format zu konvertieren und mit einem System zu indizieren. Ich nannte es
Plasma, eine Echtzeit-Graph-Indexierungs-Engine für die Bereitstellung von Dgraph.
Leapfrog Management
Wie Cerebro erhielt das Plasma-Projekt nur wenige Ressourcen, gewann jedoch weiter an Dynamik. Als das Management schließlich feststellte, dass OneBox-Blöcke unweigerlich Teil unseres Projekts waren, entschied es sich sofort, die
„richtigen Leute“ für die Verwaltung des Grafiksystems einzusetzen. Auf dem Höhepunkt des politischen Spiels wurden drei Führer ersetzt, von denen jeder keine Erfahrung mit Grafiken hatte.
Während dieses Sprunges von Dgraph nannten
Spanner- Projektmanager Dgraph ein
zu komplexes System. Als Referenz ist Spanner eine weltweit verteilte SQL-Datenbank, die eine eigene GPS-Uhr benötigt, um die globale Konsistenz sicherzustellen.
Die Ironie davon bläst immer noch mein Dach.Dgraph wurde abgesagt, Plasma überlebte. Und an der Spitze des Projekts stellten sie ein neues Team mit einem neuen Leiter auf, mit einer klaren Hierarchie und Berichterstattung an den CEO. Das neue Team - mit einem schlechten Verständnis der Grafiken und der damit verbundenen Probleme - hat beschlossen, ein Infrastruktur-Subsystem zu erstellen, das auf dem vorhandenen Google-Suchindex basiert (wie ich es für Cerebro getan habe). Ich schlug vor, das System zu verwenden, das ich bereits für Cerebro verwendet hatte, aber es wurde abgelehnt. Ich habe Plasma so geändert, dass jeder Wissensknoten auf mehrere Ebenen gecrawlt und erweitert wird, damit das System ihn als Webdokument anzeigen kann. Sie nannten dieses System TS (
Abkürzung ).
Dies bedeutete, dass das neue Subsystem keine tiefen Assoziationen durchführen konnte. Auch dies ist ein Fluch, den ich in vielen Unternehmen sehe, weil Ingenieure mit der falschen Vorstellung beginnen, dass „Diagramme ein einfaches Problem sind, das gelöst werden kann, indem einfach eine Ebene auf einem anderen System aufgebaut wird.“
Einige Monate später, im Mai 2013, verließ ich Google, nachdem ich ungefähr zwei Jahre an Dgraph / Plasma gearbeitet hatte.
Nachwort
- Einige Jahre später wurde der Abschnitt „Internet Search Infrastructure“ in „Internet Search Infrastructure and Knowledge Graph“ umbenannt, und der Leiter, dem ich Cerebro einmal zeigte, leitete die Richtung „Knowledge Graph“ und erklärte, wie sie Simple ersetzen wollen blaue Wissenslinks, um Benutzerfragen so oft wie möglich direkt zu beantworten.
- Als das an Cerebro arbeitende Shanghai-Team kurz davor stand, es in Produktion zu bringen, wurde das Projekt von ihnen übernommen und an die New Yorker Division übergeben. Am Ende wurde es als Knowledge Strip gestartet. Wenn Sie nach [ Tom Hanks-Filmen ] suchen, sehen Sie es oben. Es hat sich seit dem ersten Start etwas verbessert, unterstützt jedoch immer noch nicht die in Cerebro festgelegte Filter- und Sortierstufe.
- Alle drei technischen Manager, die an Dgraph gearbeitet haben (einschließlich meiner selbst), haben Google schließlich verlassen. Soweit ich weiß, arbeiten die übrigen jetzt bei Microsoft und LinkedIn.
- Ich habe es geschafft, zwei Werbeaktionen bei Google zu bekommen, und ich sollte eine dritte bekommen, als ich das Unternehmen als Senior Software Engineer (Senior Software Engineer) verließ.
- Nach einigen fragmentarischen Gerüchten zu urteilen, kommt die aktuelle Version von TS dem Design des Cerebro-Graphensystems sehr nahe, und jedes Subjekt, Prädikat und Objekt hat einen Index. Daher leidet sie immer noch unter dem Problem der Tiefe der Vereinigung.
- Plasma wurde inzwischen umgeschrieben und umbenannt, funktioniert aber weiterhin als Echtzeit-Diagrammindizierungssystem für TS. Gemeinsam veröffentlichen und verarbeiten sie weiterhin alle strukturierten Daten bei Google, einschließlich des Knowledge Graph.
- Die Unfähigkeit von Google, tiefe Gewerkschaften zu gründen, ist an vielen Stellen sichtbar. Zum Beispiel sehen wir immer noch keinen Datenaustausch zwischen OneBox-Blöcken: [Städte mit den meisten Regenfällen in Asien] gibt keine Liste der Städte an, obwohl sich alle Daten in der Wissensspalte befinden (stattdessen wird die Webseite in den Suchergebnissen zitiert); [Ereignisse in SF] können nicht nach Wetter gefiltert werden. Die Ergebnisse der [US-Präsidenten] werden nicht nach anderen Fakten sortiert, gefiltert oder erweitert: nach ihren Kindern oder den Schulen, an denen sie studiert haben. Ich glaube, dies war einer der Gründe für die Einstellung der Freebase- Unterstützung.
Dgraph: Phoenix Bird
Zwei Jahre nachdem ich Google verlassen hatte, beschloss ich
, Dgraph zu
entwickeln . In anderen Unternehmen sehe ich die gleiche Unentschlossenheit in Bezug auf Grafiken wie in Google. Es gab viele unvollendete Lösungen im Grafikbereich, insbesondere viele benutzerdefinierte Lösungen, die hastig auf relationalen oder NoSQL-Datenbanken oder als eine der vielen Funktionen von Datenbanken mit mehreren Modellen zusammengestellt wurden. Wenn es eine native Lösung gab, litt sie unter Skalierbarkeitsproblemen.
Nichts, was ich sah, hatte eine zusammenhängende Geschichte mit einem produktiven, skalierbaren Design.
Das Erstellen einer horizontal skalierbaren Diagrammdatenbank mit geringer Latenz und willkürlichen Tiefenverknüpfungen ist eine äußerst schwierige Aufgabe , und ich wollte sicherstellen, dass wir den Dgraph korrekt erstellt haben.
Das Dgraph-Team hat in den letzten drei Jahren nicht nur meine eigenen Erfahrungen studiert, sondern auch viele eigene Anstrengungen unternommen, um eine Grafikdatenbank zu erstellen, die keine Analoga auf dem Markt hat. Somit haben Unternehmen die Möglichkeit, eine zuverlässige, skalierbare und produktive Lösung anstelle einer anderen halbfertigen Lösung zu verwenden.