Ein weiteres Wochenende ist gekommen, was bedeutet, dass ich noch ein paar Dutzend Codezeilen schreibe und ein oder zwei Illustrationen mache. In früheren Artikeln habe ich erklärt, wie man
Raytracing macht und sogar
Dinge in die Luft jagt . Das mag Sie überraschen, aber Computergrafiken sind recht einfach: Selbst ein paar hundert Zeilen bloßes C ++ können einige sehr aufregende Bilder erzeugen.
Das heutige Thema ist das binokulare Sehen, und wir werden dabei nicht einmal die 100-Linien-Grenze durchbrechen. Da wir 3D-Szenen zeichnen können, wäre es dumm, Stereopaare zu ignorieren. Deshalb machen wir heute so etwas:

Der Wahnsinn der Schöpfer von
Magic Carpet macht mich immer noch wahnsinnig. Für diejenigen, die es nicht wissen, konnten Sie mit diesem Spiel ein 3D-Rendering sowohl im Anaglyphen- als auch im Stereogrammmodus
über das Haupteinstellungsmenü durchführen ! Das war wild für mich.
Parallaxe
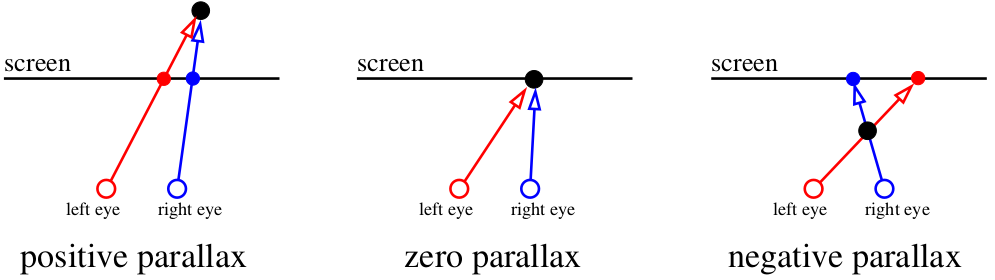
Also, lass uns beginnen. Was bewirkt zunächst, dass unser Sehapparat die Tiefe von Objekten wahrnimmt? Es gibt einen klugen Begriff "Parallaxe". Konzentrieren wir uns auf den Bildschirm. Alles, was sich in der Ebene des Bildschirms befindet, wird von unserem Gehirn als ein Objekt registriert. Wenn jedoch eine Fliege zwischen unseren Augen und dem Bildschirm fliegt, nimmt das Gehirn sie als zwei Objekte wahr. Die Spinne hinter dem Bildschirm wird ebenfalls verdoppelt.
Unser Gehirn ist sehr effizient bei der Analyse leicht unterschiedlicher Bilder. Es verwendet
binokulare Disparität , um mithilfe von
Stereopsis Informationen über die Tiefe von 2D-Bildern zu erhalten, die von der Netzhaut stammen. Nun, scheiß auf die großen Worte und lass uns einfach Bilder zeichnen!
Stellen wir uns vor, unser Monitor ist ein Fenster zur virtuellen Welt :)
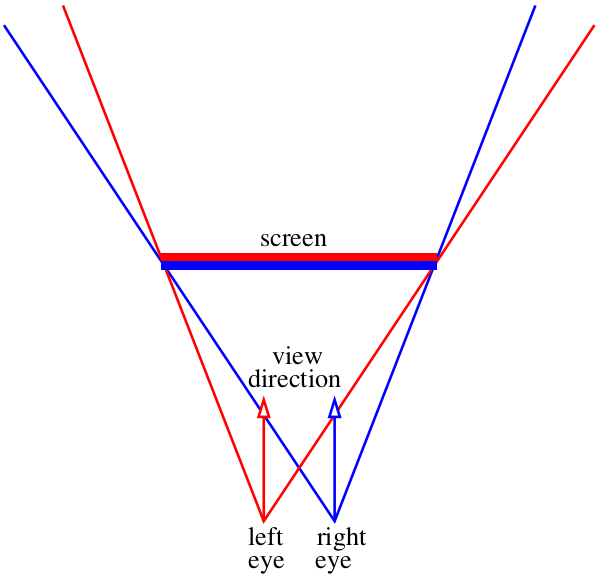
Unsere Aufgabe ist es, zwei Bilder von dem zu zeichnen, was wir durch dieses „Fenster“ sehen, eines für jedes Auge. Auf dem Bild darüber das rot-blaue „Sandwich“. Vergessen wir zunächst, wie wir diese Bilder an unser Gehirn liefern können. In diesem Stadium müssen wir nur zwei separate Dateien speichern. Insbesondere möchte ich wissen, wie ich diese Bilder mit
meinem winzigen Raytracer erhalten kann .
Nehmen wir an, der Winkel ändert sich nicht und es ist der (0,0, -1) -Vektor. Nehmen wir an, wir können die Kamera in den Bereich zwischen den Augen bewegen, aber was dann? Ein kleines Detail: Der
Kegelstumpf durch unser „Fenster“ ist asymmetrisch. Unser Raytracer kann jedoch nur einen symmetrischen Kegelstumpf erzeugen:
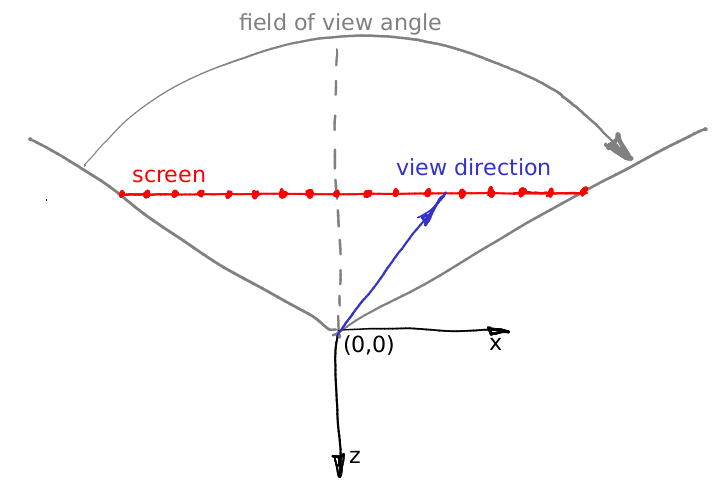
Und was machen wir jetzt? Cheat :)
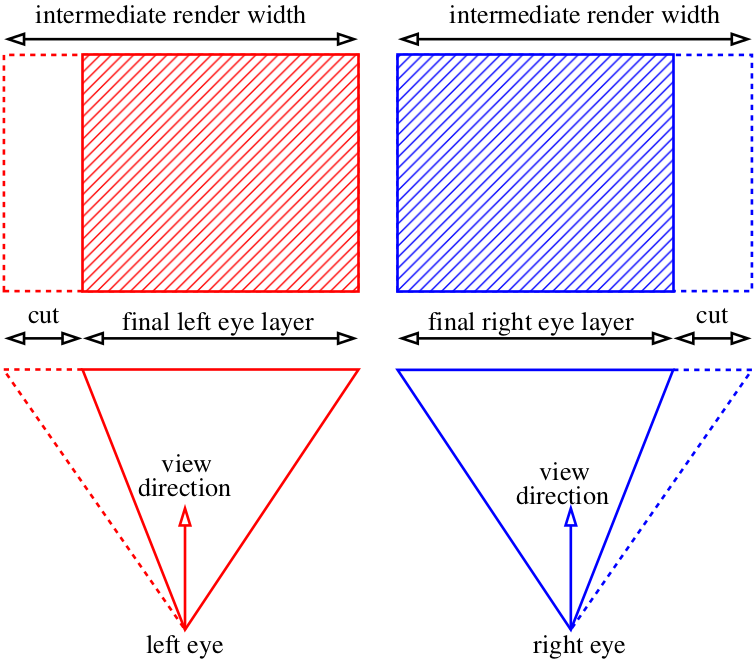
Wir können etwas breitere Bilder als nötig rendern und dann einfach die zusätzlichen Teile ausschneiden:
Anaglyphe
Ich denke, wir haben den grundlegenden Rendering-Mechanismus behandelt, und jetzt befassen wir uns mit dem Problem, das Bild an unser Gehirn zu liefern. Der einfachste Weg ist diese Art von Brille:

Wir erstellen zwei Graustufen-Renderings und weisen den roten und blauen Kanälen jeweils linke und rechte Bilder zu. Das bekommen wir:

Das rote Glas schneidet einen Kanal aus, während das blaue Glas den anderen ausschneidet. In Kombination erhalten die Augen ein anderes Bild und wir nehmen es in 3D wahr.
Hier sind die Änderungen am Haupt-Commit des tinyraytracer. Die Änderungen umfassen die Kamerapositionierung sowohl für die Augen- als auch für die Kanalmontage.
Anaglyphen-Rendering ist eine der ältesten Methoden zum Betrachten von (computergenerierten) Stereobildern. Es hat viele Nachteile, zum Beispiel eine schlechte Farbübertragung. Andererseits sind diese zu Hause sehr einfach zu erstellen.
Wenn Sie keinen Compiler auf Ihrem Computer haben, ist dies kein Problem. Wenn Sie ein Guithub-Konto haben, können Sie den Code anzeigen, bearbeiten und ausführen (sic!) Mit einem Klick in Ihrem Browser.

Wenn Sie diesen Link öffnen, erstellt gitpod eine virtuelle Maschine für Sie, startet VS Code und öffnet ein Terminal auf der Remote-Maschine. Im Befehlsverlauf (klicken Sie auf die Konsole und drücken Sie die Aufwärts-Taste) gibt es einen vollständigen Befehlssatz, mit dem Sie den Code kompilieren, starten und das resultierende Image öffnen können.
Stereoskop
Als Smartphones zum Mainstream wurden, erinnerten wir uns an die Erfindung des 19. Jahrhunderts, das Stereoskop. Vor ein paar Jahren schlug Google vor, zwei Objektive (die zu Hause leider schwer herzustellen sind, man muss sie kaufen), ein Stück Pappe (überall erhältlich) und ein Smartphone (in der Tasche) zu verwenden, um glaubwürdig zu sein VR-Brille.

Sie sind reichlich auf AliExpress und kosten etwa 3 US-Dollar pro Paar. Im Vergleich zum Anaglyphen-Rendering haben wir nicht einmal zu viel zu tun: Nehmen Sie einfach zwei Bilder auf und legen Sie sie nebeneinander.
Hier ist das Commit .

Genau genommen müssen wir je nach Objektiv möglicherweise
die Verzerrung des Objektivs korrigieren , aber das hat mich nicht gestört, da es trotzdem gut aussah. Aber wenn wir wirklich die Fassvorverzerrung anwenden müssen, die die natürliche Verzerrung des Objektivs kompensiert, sieht es für mein Smartphone und meine Brille so aus:

Hier ist der Gitpod-Link:
Autostereogramme
Und was machen wir, wenn wir keine zusätzliche Ausrüstung verwenden möchten? Dann gibt es nur noch eine Option - Schielen. Das vorige Bild ist ehrlich gesagt völlig ausreichend für die Stereoanzeige. Schielen Sie einfach die Augen (entweder kreuzen Sie die Augen oder ummauern Sie sie). Hier ist ein Schema, das uns sagt, wie wir die vorherige Abbildung sehen können. Zwei rote Linien zeigen die Bilder, wie sie von der linken Netzhaut wahrgenommen werden, zwei blaue - die rechte Netzhaut.
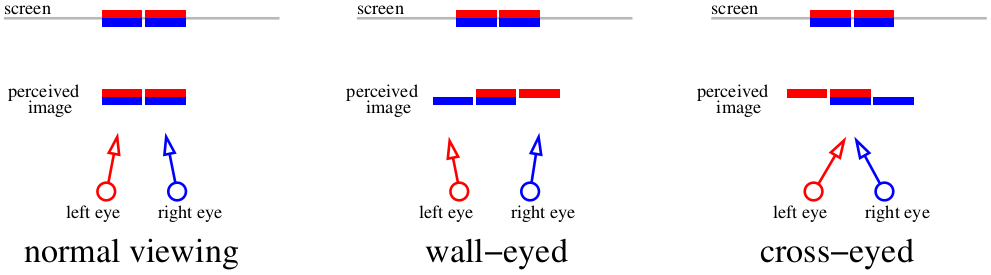
Wenn wir uns auf den Bildschirm konzentrieren, werden vier Bilder zu zwei kombiniert. Wenn wir die Augen kreuzen oder uns auf ein entferntes Objekt konzentrieren, ist es möglich, dem Gehirn „drei“ Bilder zuzuführen. Die zentralen Bilder überlappen sich, wodurch der Stereoeffekt entsteht.
Unterschiedliche Menschen wenden unterschiedliche Methoden an: Zum Beispiel kann ich meine Augen nicht kreuzen, sondern sie leicht ummauern. Es ist wichtig, dass das für eine bestimmte Methode erstellte Autostereogramm nur mit dieser Methode angezeigt wird. Andernfalls erhalten wir eine invertierte Tiefenkarte (erinnern Sie sich an positive und negative Parallaxe?). Das Problem ist, dass es schwierig ist, die Augen zu kreuzen, so dass es nur bei kleinen Bildern funktioniert. Aber was ist, wenn wir größere wollen? Lassen Sie uns die Farben vollständig opfern und uns nur auf den Teil der Tiefenwahrnehmung konzentrieren. Hier ist das Bild, das wir uns bis zum Ende des Artikels erhoffen:

Dies ist ein Autostereogramm mit Wandaugen. Für diejenigen, die die andere Methode bevorzugen,
hier ein Bild dafür . Wenn Sie nicht an Autostereogramme gewöhnt sind, probieren Sie verschiedene Bedingungen aus: Vollbild, kleineres Bild, Helligkeit, Dunkelheit. Unser Ziel ist es, unsere Augen so zu wandeln, dass sich die beiden nahe gelegenen vertikalen Streifen überlappen. Am einfachsten ist es, sich auf den oberen linken Teil des Bildes zu konzentrieren, da es einfach ist. Persönlich öffne ich das Bild im Vollbildmodus. Vergessen Sie nicht, auch den Mauszeiger zu entfernen!
Hören Sie nicht bei einem unvollständigen 3D-Effekt auf. Wenn Sie vage rundliche Formen sehen und der 3D-Effekt schwach ist, ist die Illusion unvollständig. Die Kugeln sollen vom Bildschirm zum Betrachter „springen“, der Effekt muss stabil und nachhaltig sein. Die Stereopsis hat eine Gisterese: Sobald Sie ein stabiles Bild erhalten, wird es umso detaillierter, je länger Sie es beobachten. Je weiter die Augen vom Bildschirm entfernt sind, desto größer ist der Tiefenwahrnehmungseffekt.
Dieses Stereogramm wurde mit einer Methode gezeichnet, die vor 25 Jahren in diesem Artikel vorgeschlagen wurde: "
Anzeigen von 3D-Bildern: Algorithmen für Einzelbild-Zufallspunktstereogramme ."
Lass uns anfangen
Der Ausgangspunkt für das Rendern von Autostereogrammen ist die Tiefenkarte (da wir die Farben aufgeben).
Dieses Commit zeichnet das folgende Bild:

Die näheren und weiteren Ebenen bestimmen unsere Tiefe: Der am weitesten entfernte Punkt in meiner Karte hat die Tiefe 0, während der nächstgelegene die Tiefe 1 hat.
Die Grundprinzipien
Nehmen wir an, unsere Augen befinden sich in einem Abstand vom Bildschirm. Wir platzieren unsere (imaginäre) Fernebene (z = 0) im gleichen Abstand „hinter“ dem Bildschirm. Wir wählen die μ-Variable, die den Ort der nahen Ebene (z = 1) bestimmt, die sich in μd Entfernung von der fernen Ebene befindet. Für meinen Code habe ich μ = ⅓ gewählt. Insgesamt lebt unsere gesamte „Welt“ in einer Entfernung von d-μd bis d hinter dem Bildschirm. Angenommen, wir kennen den Abstand zwischen den Augen (in Pixel habe ich 400 Pixel gewählt):
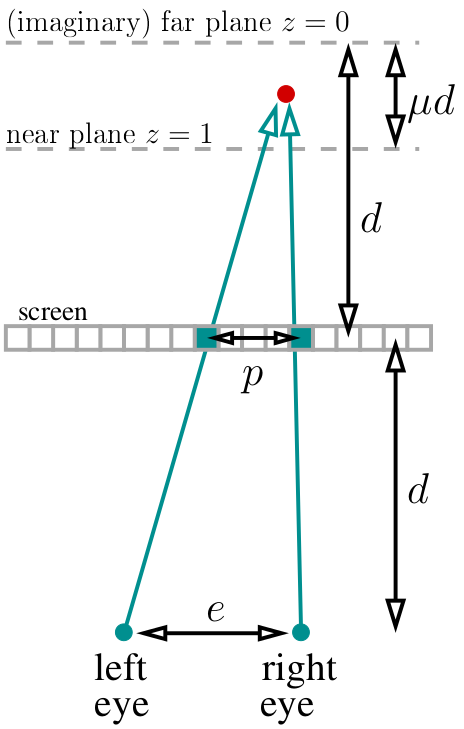
Wenn wir den roten Punkt betrachten, sollten zwei grün markierte Pixel im Stereogramm dieselbe Farbe haben. Wie berechnet man den Abstand zwischen ihnen? Einfach Wenn der aktuell projizierte Punkt die Tiefe von z hat, entspricht die Parallaxe geteilt durch den Abstand zwischen den Augen dem Bruchteil zwischen den entsprechenden Tiefen: p / e = (d-dμz) / (2d-dμz). Beachten Sie übrigens, dass d vereinfacht ist und nirgendwo anders erscheint! Dann ist p / e = (1 & mgr; z) / (2 & mgr; z), was bedeutet, dass die Parallaxe gleich p = e * (1 & mgr; z) / (2 & mgr; z) Pixel ist.
Die Hauptidee hinter dem Autostereogramm ist: Wir gehen die gesamte Tiefenkarte durch, bestimmen für jeden Tiefenwert, welche Pixel dieselbe Farbe haben, und schreiben sie in unser System von Einschränkungen. Dann gehen wir vom Zufallsbild aus und versuchen, alle zuvor festgelegten Einschränkungen zu erfüllen.
Quellbild vorbereiten
Hier bereiten wir das Bild vor, das später durch Parallaxenbeschränkungen eingeschränkt wird.
Hier ist das Commit , und es zeichnet dies:

Beachten Sie, dass die Farben größtenteils zufällig sind, abgesehen von dem roten Kanal, in den ich rand () * sin eingefügt habe, um ein periodisches Muster zu erstellen. Die Streifen sind 200 Pixel voneinander entfernt, was (bei μ = 1/3 und e = 400) der maximale Parallaxenwert in unserer Welt (der fernen Ebene) ist. Das Muster ist technisch nicht notwendig, aber es hilft, die Augen zu fokussieren.
Autostereogramm-Rendering
Tatsächlich sieht der vollständige Code, der das Autostereogramm zeichnet, folgendermaßen aus:
int parallax(const float z) { const float eye_separation = 400.;
Hier ist das Commit . Die Funktion int parallax (const float z) gibt den Abstand zwischen Pixeln derselben Farbe für den aktuellen Tiefenwert an. Wir rendern das Stereogramm zeilenweise, da die Linien unabhängig voneinander sind (wir haben keine vertikale Parallaxe). Die Hauptschleife durchläuft einfach jede Zeile. Jedes Mal, wenn mit einem unbegrenzten Satz von Pixeln begonnen wird, wird für jedes Pixel eine Gleichheitsbeschränkung hinzugefügt. Am Ende erhalten wir eine bestimmte Anzahl von Clustern gleichfarbiger Pixel. Beispielsweise sollten Pixel mit den Indizes links und rechts identisch sein.
Wie speichere ich diese Einschränkungen? Der einfachste Weg ist die
Union-Find-Datenstruktur . Ich werde nicht ins Detail gehen, gehe einfach zu Wikipedia, es sind buchstäblich drei Codezeilen. Der Hauptpunkt ist, dass für jeden Cluster ein bestimmtes "Wurzel" -Pixel für den Cluster verantwortlich ist. Das Stammpixel behält seine ursprüngliche Farbe bei, und alle anderen Pixel im Cluster müssen aktualisiert werden:
for (size_t i=0; i<width; i++) {
Fazit
Das war's wirklich. Zwanzig Codezeilen und unser Autostereogramm stehen bereit, damit Sie Ihre Augen darüber brechen können. Übrigens, wenn wir uns genug anstrengen, ist es möglich, Farbinformationen zu übertragen.
Ich habe andere stereoskopische Systeme wie
polarisierte 3D-Systeme nicht behandelt, da ihre Herstellung viel teurer ist. Wenn ich etwas verpasst habe, können Sie mich gerne korrigieren!