Die Erkennung von Angriffen ist seit Jahrzehnten Teil der Informationssicherheit. Die ersten bekannten IDS-Implementierungen (Intrusion Detection System) stammen aus den frühen 1980er Jahren.
Heutzutage gibt es eine ganze Angriffserkennungsbranche. Es gibt eine Reihe von Produkten - wie IDS-, IPS-, WAF- und Firewall-Lösungen - von denen die meisten eine regelbasierte Angriffserkennung bieten. Die Idee, eine Art statistische Anomalieerkennung zu verwenden, um Angriffe in der Produktion zu identifizieren, scheint nicht mehr so realistisch wie früher. Aber ist diese Annahme gerechtfertigt?
Erkennung von Anomalien in Webanwendungen
Die ersten Firewalls, die auf die Erkennung von Angriffen auf Webanwendungen zugeschnitten sind, wurden Anfang der neunziger Jahre auf den Markt gebracht. Sowohl die Angriffstechniken als auch die Schutzmechanismen haben sich seitdem dramatisch weiterentwickelt. Die Angreifer versuchen, einen Schritt voraus zu sein.
Die meisten aktuellen Webanwendungs-Firewalls (WAFs) versuchen, Angriffe auf ähnliche Weise zu erkennen, wobei eine regelbasierte Engine in einen Reverse-Proxy eines bestimmten Typs eingebettet ist. Das bekannteste Beispiel ist mod_security, ein WAF-Modul für den Apache-Webserver, das 2002 erstellt wurde. Die regelbasierte Erkennung hat einige Nachteile: Beispielsweise werden neuartige Angriffe (Zero-Days) nicht erkannt, obwohl dieselben Angriffe ausgeführt werden kann leicht von einem menschlichen Experten entdeckt werden. Diese Tatsache ist nicht überraschend, da das menschliche Gehirn ganz anders arbeitet als eine Reihe regulärer Ausdrücke.
Aus der Sicht einer WAF können Angriffe in sequentiell basierte (Zeitreihen) und solche unterteilt werden, die aus einer einzelnen HTTP-Anforderung oder -Antwort bestehen. Unsere Forschung konzentrierte sich auf die Erkennung der letzteren Art von Angriffen, einschließlich:
- SQL-Injection
- Cross-Site-Scripting
- XML External Entity Injection
- Pfadüberquerung
- Betriebssystembefehl
- Objektinjektion
Aber fragen wir uns zuerst: Wie würde ein Mensch das tun?
Was würde ein Mensch tun, wenn er eine einzelne Anfrage sieht?
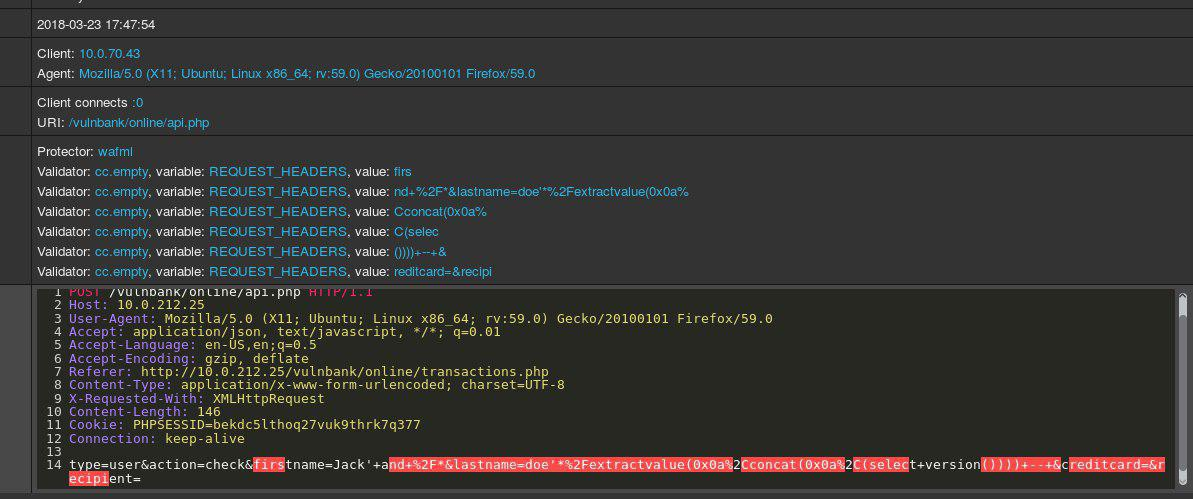
Sehen Sie sich eine reguläre HTTP-Beispielanforderung für eine Anwendung an:
Wenn Sie böswillige Anfragen erkennen müssten, die an eine Anwendung gesendet wurden, möchten Sie höchstwahrscheinlich eine Weile lang harmlose Anfragen beobachten. Nachdem Sie sich die Anforderungen für eine Reihe von Endpunkten für die Anwendungsausführung angesehen haben, haben Sie eine allgemeine Vorstellung davon, wie sichere Anforderungen strukturiert sind und was sie enthalten.
Nun wird Ihnen folgende Anfrage gestellt:

Sie ahnen sofort, dass etwas nicht stimmt. Es dauert etwas länger, bis Sie genau verstanden haben, und sobald Sie den genauen Teil der Anfrage gefunden haben, der anomal ist, können Sie darüber nachdenken, um welche Art von Angriff es sich handelt. Im Wesentlichen ist es unser Ziel, dass unsere Angriffserkennungs-KI das Problem auf eine Weise angeht, die dieser menschlichen Argumentation ähnelt.
Erschwerend kommt hinzu, dass ein Teil des Datenverkehrs für eine bestimmte Website normal sein kann, auch wenn er auf den ersten Blick böswillig erscheint.
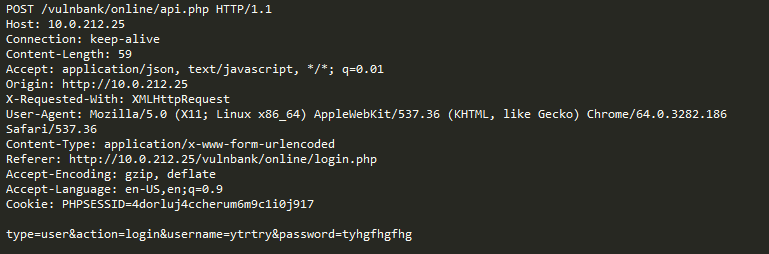
Schauen wir uns zum Beispiel die folgende Anfrage an:
Ist es eine Anomalie? Tatsächlich ist diese Anfrage harmlos: Es handelt sich um eine typische Anfrage im Zusammenhang mit der Veröffentlichung von Fehlern auf dem Jira-Bug-Tracker.
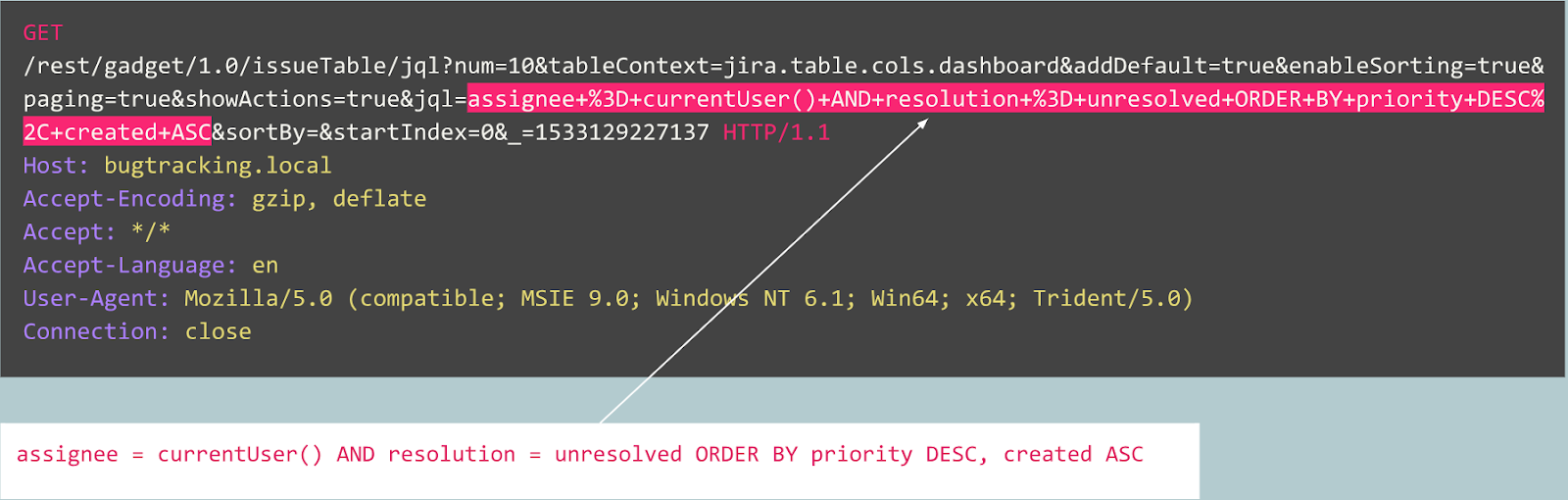
Schauen wir uns nun einen anderen Fall an:

Die Anfrage sieht zunächst wie eine typische Benutzeranmeldung auf einer Website aus, die vom Joomla CMS unterstützt wird. Die angeforderte Operation lautet jedoch "user.register" anstelle des normalen "register.register". Die erstere Option ist veraltet und enthält eine Sicherheitsanfälligkeit, mit der sich jeder als Administrator anmelden kann.
Dieser Exploit wird als "Joomla <3.6.4 Kontoerstellung / Eskalation von Berechtigungen" (CVE-2016-8869, CVE-2016-8870) bezeichnet.

Wie wir angefangen haben
Wir haben uns zunächst frühere Forschungsergebnisse angesehen, da im Laufe der Jahrzehnte viele Versuche unternommen wurden, verschiedene statistische oder maschinelle Lernalgorithmen zur Erkennung von Angriffen zu erstellen. Einer der häufigsten Ansätze besteht darin, die Aufgabe der Zuweisung zu einer Klasse zu lösen ("gutartige Anforderung", "SQL Injection", "XSS", "CSRF" usw.). Während man mit der Klassifizierung für einen bestimmten Datensatz eine anständige Genauigkeit erzielen kann, löst dieser Ansatz einige sehr wichtige Probleme nicht:
- Die Wahl der Klasse festgelegt . Was ist, wenn Ihr Modell während des Lernens mit drei Klassen ("gutartig", "SQLi", "XSS") dargestellt wird, aber in der Produktion auf einen CSRF-Angriff oder sogar eine brandneue Angriffstechnik stößt?
- Die Bedeutung dieser Klassen . Angenommen, Sie müssen 10 Kunden schützen, von denen jeder völlig andere Webanwendungen ausführt. Für die meisten von ihnen hätten Sie keine Ahnung, wie ein einzelner "SQL Injection" -Angriff gegen ihre Anwendung wirklich aussieht. Dies bedeutet, dass Sie Ihre Lerndatensätze irgendwie künstlich erstellen müssen - was eine schlechte Idee ist, da Sie am Ende aus Daten lernen, die eine völlig andere Verteilung haben als Ihre realen Daten.
- Interpretierbarkeit der Ergebnisse Ihres Modells . Großartig, also hat das Modell das Label „SQL Injection“ entwickelt - was nun? Sie und vor allem Ihr Kunde, der als erster die Warnung sieht und normalerweise kein Experte für Webangriffe ist, müssen raten, welchen Teil der Anfrage das Modell als bösartig erachtet.
Vor diesem Hintergrund haben wir uns entschlossen, die Klassifizierung trotzdem auszuprobieren.
Da das HTTP-Protokoll textbasiert ist, war es offensichtlich, dass wir uns moderne Textklassifizierer ansehen mussten. Eines der bekannten Beispiele ist die Stimmungsanalyse des IMDB-Datensatzes für Filmkritiken. Einige Lösungen verwenden wiederkehrende neuronale Netze (RNNs), um diese Überprüfungen zu klassifizieren. Wir haben uns für ein ähnliches RNN-Klassifizierungsmodell mit einigen geringfügigen Unterschieden entschieden. Beispielsweise verwenden RNNs zur Klassifizierung natürlicher Sprachen Worteinbettungen, aber es ist nicht klar, welche Wörter in einer nicht natürlichen Sprache wie HTTP vorhanden sind. Aus diesem Grund haben wir uns für die Verwendung von Zeicheneinbettungen in unserem Modell entschieden.
Vorgefertigte Einbettungen sind für die Lösung des Problems irrelevant. Aus diesem Grund haben wir einfache Zuordnungen von Zeichen zu numerischen Codes mit mehreren internen Markierungen wie
GO und
EOS verwendet .
Nachdem wir die Entwicklung und das Testen des Modells abgeschlossen hatten, traten alle zuvor vorhergesagten Probleme auf, aber zumindest war unser Team vom müßigen Nachdenken zu etwas Produktivem übergegangen.
Wie wir vorgegangen sind
Von dort aus beschlossen wir, die Ergebnisse unseres Modells interpretierbarer zu machen. Irgendwann stießen wir auf den Mechanismus der „Aufmerksamkeit“ und begannen, ihn in unser Modell zu integrieren. Und das brachte einige vielversprechende Ergebnisse: Schließlich kam alles zusammen und wir erhielten einige vom Menschen interpretierbare Ergebnisse. Jetzt begann unser Modell, nicht nur die Beschriftungen, sondern auch die Aufmerksamkeitskoeffizienten für jedes Zeichen der Eingabe auszugeben.
Wenn dies beispielsweise in einer Weboberfläche visualisiert werden könnte, könnten wir die genaue Stelle einfärben, an der ein „SQL Injection“ -Angriff gefunden wurde. Das war ein vielversprechendes Ergebnis, aber die anderen Probleme blieben weiterhin ungelöst.
Wir begannen zu erkennen, dass wir davon profitieren könnten, wenn wir in Richtung des Aufmerksamkeitsmechanismus und weg von der Klassifizierung gehen. Nachdem wir viele verwandte Forschungsergebnisse (z. B. „Aufmerksamkeit ist alles, was Sie brauchen“, Word2Vec und Encoder-Decoder-Architekturen) zu Sequenzmodellen gelesen und mit unseren Daten experimentiert haben, konnten wir ein Anomalieerkennungsmodell erstellen, das funktionieren würde mehr oder weniger so wie ein menschlicher Experte.
Autoencoder
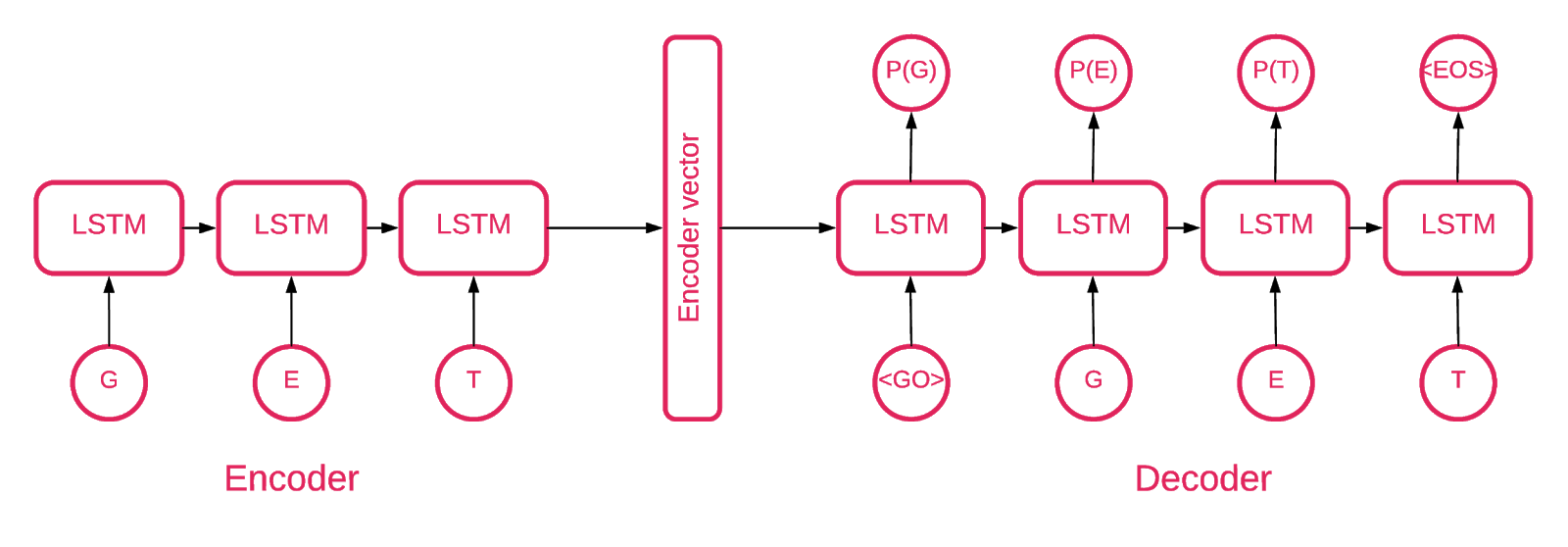
Irgendwann wurde klar, dass ein Sequenz-zu-Sequenz-Autoencoder am besten zu unserem Zweck passt.
Ein Sequenz-zu-Sequenz-Modell besteht aus zwei mehrschichtigen LSTM-Modellen (Long Short Term Memory): einem Codierer und einem Decodierer. Der Codierer ordnet die Eingabesequenz einem Vektor fester Dimensionalität zu. Der Decodierer decodiert den Zielvektor unter Verwendung dieses Ausgangs des Codierers.
Ein Autoencoder ist also ein Sequenz-zu-Sequenz-Modell, das seine Zielwerte gleich seinen Eingabewerten setzt. Die Idee ist, dem Netzwerk beizubringen, Dinge, die es gesehen hat, neu zu erschaffen oder mit anderen Worten eine Identitätsfunktion anzunähern. Wenn der trainierte Autoencoder eine anomale Probe erhält, wird er wahrscheinlich mit einem hohen Fehlergrad neu erstellt, da er zuvor noch nie eine solche Probe gesehen hat.
Der Code
Unsere Lösung besteht aus mehreren Teilen: Modellinitialisierung, Schulung, Vorhersage und Validierung.
Der größte Teil des Codes im Repository ist selbsterklärend. Wir konzentrieren uns nur auf wichtige Teile.
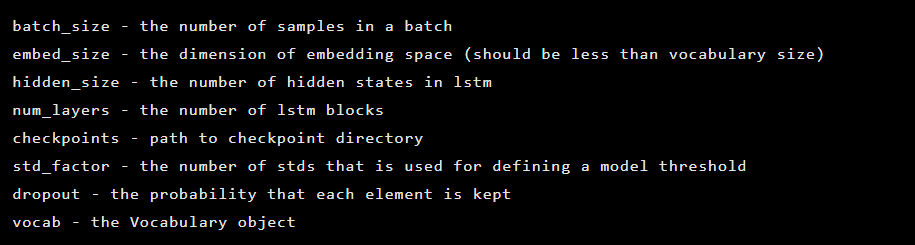
Das Modell wird als Instanz der Seq2Seq-Klasse initialisiert, die die folgenden Konstruktorargumente enthält:
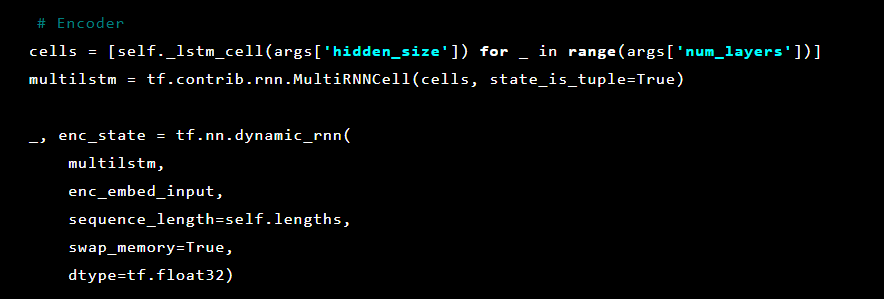
Danach werden die Autoencoder-Schichten initialisiert. Zunächst der Encoder:
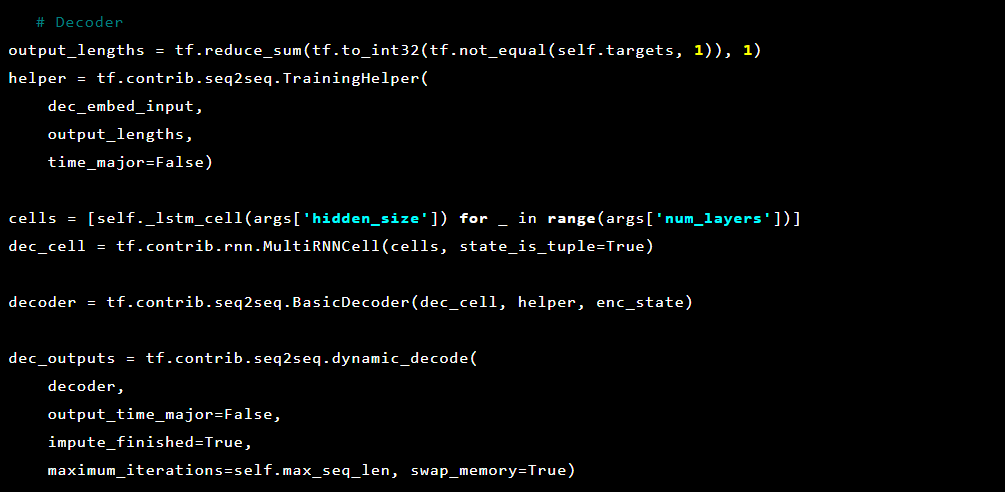
Und dann der Decoder:
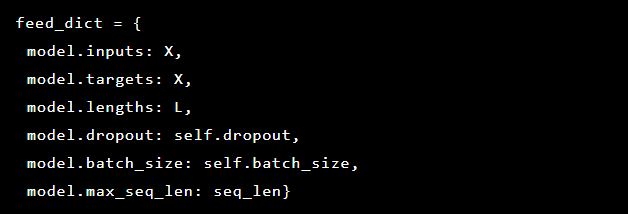
Da wir versuchen, die Erkennung von Anomalien zu lösen, sind die Ziele und Eingaben gleich. Somit sieht unser feed_dict wie folgt aus:
Nach jeder Epoche wird das beste Modell als Kontrollpunkt gespeichert, der später geladen werden kann, um Vorhersagen zu treffen. Zu Testzwecken wurde eine Live-Webanwendung eingerichtet und durch das Modell geschützt, sodass getestet werden konnte, ob echte Angriffe erfolgreich waren oder nicht.
Ausgehend vom Aufmerksamkeitsmechanismus haben wir versucht, ihn auf den Autoencoder anzuwenden, haben jedoch festgestellt, dass die von der letzten Ebene ausgegebenen Wahrscheinlichkeiten die anomalen Teile einer Anforderung besser markieren.

In der Testphase mit unseren Proben haben wir sehr gute Ergebnisse erzielt: Präzision und Rückruf lagen nahe bei 0,99. Und die ROC-Kurve war um 1. Auf jeden Fall ein schöner Anblick!
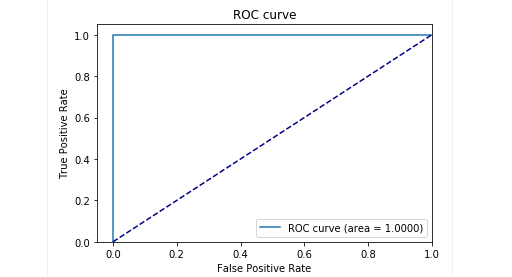
Die Ergebnisse
Unser beschriebenes Seq2Seq-Autoencoder-Modell konnte Anomalien in HTTP-Anforderungen mit hoher Genauigkeit erkennen.
Dieses Modell verhält sich wie ein Mensch: Es lernt nur die „normalen“ Benutzeranforderungen, die an eine Webanwendung gesendet werden. Es erkennt Anomalien in Anfragen und hebt die genaue Stelle in der Anfrage hervor, die als anomal angesehen wird. Wir haben dieses Modell gegen Angriffe auf die Testanwendung bewertet und die Ergebnisse scheinen vielversprechend. Der vorherige Screenshot zeigt beispielsweise, wie unser Modell die SQL-Injektion erkannt hat, die auf zwei Webformularparameter aufgeteilt ist. Solche SQL-Injections sind fragmentiert, da die Angriffsnutzlast in mehreren HTTP-Parametern bereitgestellt wird. Klassische regelbasierte WAFs erkennen fragmentierte SQL-Injection-Versuche nur schlecht, da sie normalerweise jeden Parameter einzeln untersuchen.
Der Code des Modells und die Zug- / Testdaten wurden als Jupyter-Notizbuch veröffentlicht, sodass jeder unsere Ergebnisse reproduzieren und Verbesserungen vorschlagen kann.
Fazit
Wir glauben, dass unsere Aufgabe nicht trivial war: einen Weg zu finden, um Angriffe mit minimalem Aufwand zu erkennen. Einerseits wollten wir vermeiden, die Lösung zu komplizieren, und eine Möglichkeit schaffen, Angriffe zu erkennen, die wie durch Zauberei lernen, selbst zu entscheiden, was gut und was schlecht ist. Gleichzeitig wollten wir Probleme mit dem menschlichen Faktor vermeiden, wenn ein (fehlbarer) Experte entscheidet, was auf einen Angriff hinweist und was nicht. Insgesamt scheint der Autoencoder mit Seq2Seq-Architektur unser Problem der Erkennung von Anomalien recht gut zu lösen.
Wir wollten auch das Problem der Interpretierbarkeit von Daten lösen. Bei Verwendung komplexer neuronaler Netzwerkarchitekturen ist es sehr schwierig, ein bestimmtes Ergebnis zu erklären. Wenn eine ganze Reihe von Transformationen angewendet wird, wird es nahezu unmöglich, die wichtigsten Daten hinter einer Entscheidung zu identifizieren. Nachdem wir jedoch den Ansatz zur Dateninterpretation durch das Modell überdacht hatten, konnten wir Wahrscheinlichkeiten für jedes Zeichen aus der letzten Schicht erhalten.
Es ist wichtig zu beachten, dass dieser Ansatz keine produktionsbereite Version ist. Wir können nicht offenlegen, wie dieser Ansatz in einem realen Produkt implementiert werden könnte. Wir werden Sie jedoch warnen, dass es nicht möglich ist, diese Arbeit einfach zu übernehmen und "anzuschließen". Wir machen diese Einschränkung, weil wir nach der Veröffentlichung auf GitHub einige Benutzer sahen, die versuchten, unsere aktuelle Lösung einfach in ihren eigenen Projekten zu implementieren, mit erfolglosen (und nicht überraschenden) Ergebnissen.
Proof of Concept finden Sie
hier (github.com).
Autoren: Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sacharow (
GitHub ), Arseny
Reutov (
Raz0r )
Weiterführende Literatur
- Grundlegendes zu LSTM-Netzwerken
- Aufmerksamkeit und erweiterte wiederkehrende neuronale Netze
- Aufmerksamkeit ist alles was Sie brauchen
- Aufmerksamkeit ist alles was Sie brauchen (kommentiert)
- Tutorial für neuronale maschinelle Übersetzung (seq2seq)
- Autoencoder
- Sequenz-zu-Sequenz-Lernen mit neuronalen Netzen
- Erstellen von Autoencodern in Keras