Musik hacken, um abgeleitete Inhalte zu demokratisierenHaftungsausschluss: Alle in diesem Artikel beschriebenen geistigen Eigentumsrechte, Designs und Methoden sind in US10014002B2 und US9842609B2 offenbart.
Ich wünschte, ich könnte nach 1965 zurückkehren, mit einem Pass an die Haustür des Abby Road-Studios klopfen, hineingehen und die echten Stimmen von Lennon und McCartney hören ... Nun, versuchen wir es. Input: Beatles durchschnittliche MP3-Qualität
Wir können es schaffen . Die obere Spur ist der Eingangsmix, die untere Spur ist der isolierte Gesang, den unser neuronales Netzwerk hervorgehoben hat.
Formal ist dieses Problem als
Trennung von Schallquellen oder
Trennung des Signals (Audioquellentrennung) bekannt. Es besteht darin, eines oder mehrere der ursprünglichen Signale wiederherzustellen oder zu rekonstruieren, die infolge eines
linearen oder Faltungsprozesses mit anderen Signalen gemischt werden. Dieses Forschungsgebiet hat viele praktische Anwendungen, einschließlich der Verbesserung der Klangqualität (Sprachqualität) und der Beseitigung von Rauschen, Musik-Remixen, räumlicher Klangverteilung, Remastering usw. Toningenieure nennen diese Technik manchmal Demixing. Zu diesem Thema gibt es viele Ressourcen, von der blinden Trennung von Signalen mit Analyse unabhängiger Komponenten (ICA) bis zur halbkontrollierten Faktorisierung nicht negativer Matrizen und dem Ende späterer Ansätze auf der Grundlage neuronaler Netze. Gute Informationen zu den ersten beiden Punkten finden Sie in
diesen Mini-Guides von CCRMA, die mir einmal sehr nützlich waren.
Aber bevor wir in die Entwicklung eintauchen ... einiges an angewandter Philosophie des maschinellen Lernens ...Ich habe mich bereits mit der Signal- und Bildverarbeitung beschäftigt, bevor sich der Slogan „Deep Learning löst alles“ verbreitet hat.
Daher kann ich Ihnen eine Lösung als
Feature-Engineering- Reise vorstellen und zeigen,
warum ein neuronales Netzwerk der beste Ansatz für dieses spezielle Problem ist . Warum? Sehr oft sehe ich Leute, die so etwas schreiben:
„Mit Deep Learning müssen Sie sich keine Gedanken mehr über die Auswahl von Funktionen machen. es wird es für dich tun. "oder schlimmer ...
"Der Unterschied zwischen maschinellem Lernen und tiefem Lernen [hey ... tiefes Lernen ist immer noch maschinelles Lernen!] Ist das,
dass Sie in ML selbst die Attribute extrahieren, und beim tiefen Lernen geschieht dies automatisch innerhalb des Netzwerks."Diese Verallgemeinerungen beruhen wahrscheinlich auf der Tatsache, dass DNNs sehr effektiv bei der Erkundung guter versteckter Räume sein können. Aber so ist es unmöglich zu verallgemeinern. Ich bin sehr verärgert, wenn die jüngsten Absolventen und Praktiker den oben genannten Missverständnissen erliegen und den Ansatz des „Deep-Learning-It-All“ verfolgen. Es reicht aus, eine Menge Rohdaten zu werfen (auch nach einer kleinen Vorverarbeitung) - und alles wird so funktionieren, wie es sollte. In der realen Welt müssen Sie sich um Dinge wie Leistung, Echtzeitausführung usw. kümmern. Aufgrund solcher Missverständnisse werden Sie sehr lange im Experimentiermodus stecken bleiben ...
Feature Engineering bleibt eine sehr wichtige Disziplin beim Entwurf künstlicher neuronaler Netze. Wie bei jeder anderen ML-Technik unterscheidet sie in den meisten Fällen effektive Lösungen des Produktionsniveaus von erfolglosen oder ineffektiven Experimenten. Ein tiefes Verständnis Ihrer Daten und ihrer Natur bedeutet immer noch viel ...Von A bis Z.
Ok, ich habe die Predigt beendet. Nun wollen wir sehen, warum wir hier sind! Wie bei jedem Datenverarbeitungsproblem sehen wir uns zunächst an, wie es aussieht. Schauen Sie sich das nächste Stück Gesang aus der Original-Studioaufnahme an.
Studio-Gesang 'One Last Time', Ariana GrandeNicht zu interessant, oder? Das liegt daran, dass wir das Signal
rechtzeitig visualisieren. Hier sehen wir nur Amplitudenänderungen über die Zeit. Sie können jedoch alle möglichen anderen Dinge extrahieren, z. B. Amplitudenhüllkurven (Hüllkurve), quadratische Mittelwerte (RMS), die Änderungsrate von positiven Amplitudenwerten zu negativen (Nulldurchgangsrate) usw., aber diese
Vorzeichen sind zu
primitiv und nicht ausreichend unterscheidbar. um in unserem Problem zu helfen. Wenn wir Gesang aus einem Audiosignal extrahieren wollen, müssen wir zuerst irgendwie die Struktur der menschlichen Sprache bestimmen. Glücklicherweise hilft die Window
Fourier Transform (STFT).
STFT-Amplitudenspektrum - Fenstergröße = 2048, Überlappung = 75%, logarithmische Frequenzskala [Sonic Visualizer]Obwohl ich die Sprachverarbeitung liebe und definitiv gerne mit
Eingangsfiltersimulationen, Cepstrums, Sottotami, LPC, MFCC usw.
spiele, überspringen
wir diesen ganzen Unsinn und konzentrieren
uns auf die Hauptelemente unseres Problems, damit der Artikel von möglichst vielen Menschen verstanden werden kann. nicht nur Signalverarbeitungsspezialisten.
Was sagt uns die Struktur der menschlichen Sprache?
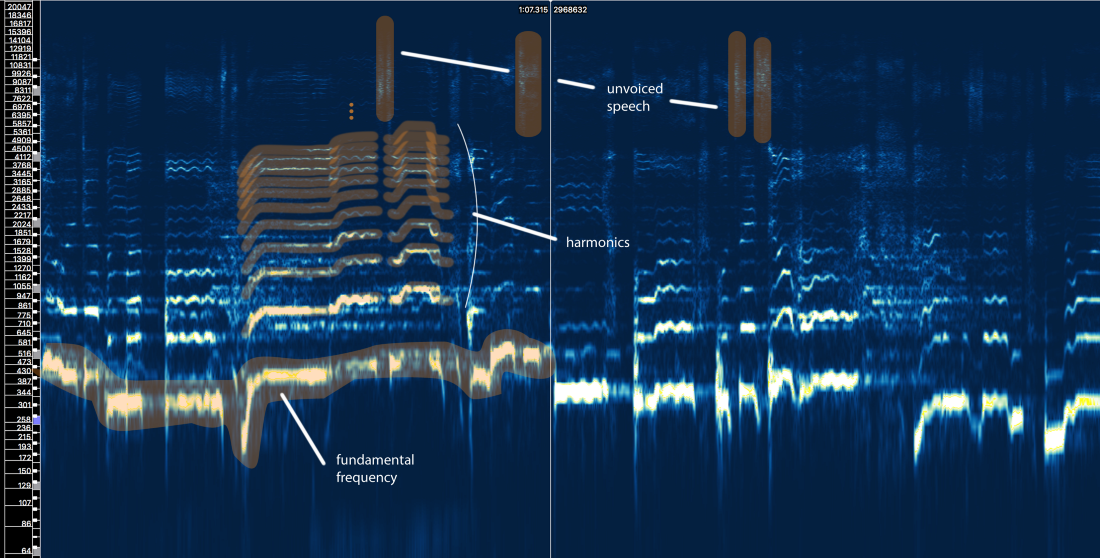
Nun, wir können hier drei Hauptelemente definieren:
- Die Grundfrequenz (f0), die durch die Schwingungsfrequenz unserer Stimmbänder bestimmt wird. In diesem Fall singt Ariana im Bereich von 300-500 Hz.
- Eine Reihe von Harmonischen über f0, die einer ähnlichen Form oder einem ähnlichen Muster folgen. Diese Harmonischen erscheinen bei Frequenzen, die ein Vielfaches von f0 sind.
- Stimmlose Sprache, die Konsonanten wie 't', 'p', 'k', 's' (die nicht durch Vibration der Stimmbänder erzeugt werden), Atmung usw. enthält. All dies äußert sich in Form kurzer Bursts im Hochfrequenzbereich.
Erster Versuch mit Regeln
Vergessen wir für eine Sekunde, was als maschinelles Lernen bezeichnet wird. Kann eine Vokalextraktionsmethode basierend auf unserer Kenntnis des Signals entwickelt werden? Lass mich versuchen ...
Naive Stimmisolation V1.0:- Identifizieren Sie Bereiche mit Gesang. Das ursprüngliche Signal enthält viele Dinge. Wir möchten uns auf die Bereiche konzentrieren, die wirklich Vokalinhalte enthalten, und alles andere ignorieren.
- Unterscheiden Sie zwischen stimmhafter und stimmloser Sprache. Wie wir gesehen haben, sind sie sehr unterschiedlich. Sie müssen wahrscheinlich anders gehandhabt werden.
- Bewerten Sie die Änderung der Grundfrequenz im Laufe der Zeit.
- Wenden Sie basierend auf Pin 3 eine Art Maske an, um Harmonische zu erfassen.
- Mach etwas mit Fragmenten stimmloser Sprache ...

Wenn wir würdig arbeiten, sollte das Ergebnis eine
weiche oder
Bitmaske sein , deren Anwendung auf die Amplitude der STFT (elementweise Multiplikation) eine ungefähre Rekonstruktion der Amplitude der STFT-Vocals ergibt. Dann kombinieren wir diese vokale STFT mit Informationen über die Phase des ursprünglichen Signals, berechnen die inverse STFT und erhalten das Zeitsignal der rekonstruierten Stimme.
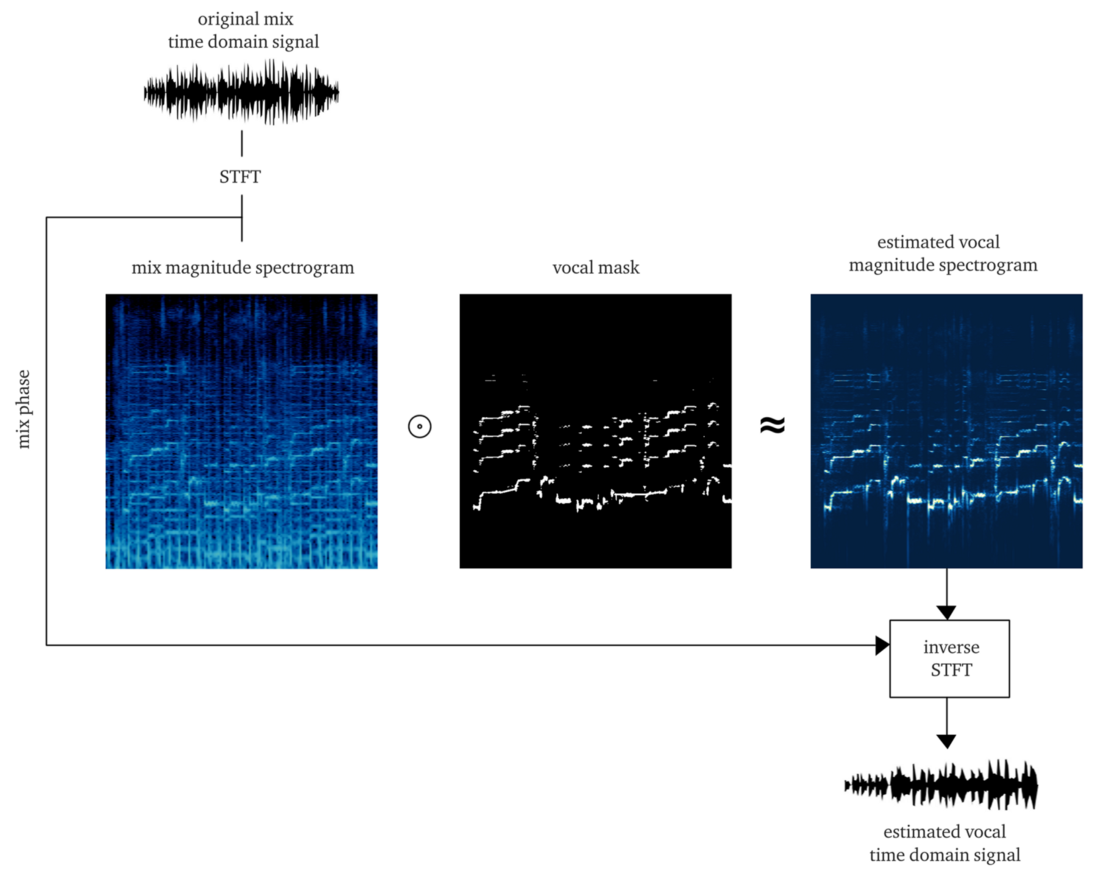
Es von Grund auf neu zu machen ist schon eine große Aufgabe.
Zur Demonstration ist jedoch die Implementierung des
pYIN-Algorithmus anwendbar . Es ist zwar beabsichtigt, Schritt 3 zu lösen, aber mit den richtigen Einstellungen führt es anständig die Schritte 1 und 2 aus und verfolgt die Stimmbasis auch bei Vorhandensein von Musik. Das folgende Beispiel enthält die Ausgabe nach der Verarbeitung dieses Algorithmus, ohne stimmlose Sprache zu verarbeiten.
Na und...? Er scheint die ganze Arbeit erledigt zu haben, aber es gibt keine gute Qualität und Nähe. Vielleicht werden wir diese Methode verbessern, indem wir mehr Zeit, Energie und Geld investieren ...
Aber lass mich dich fragen ...
Was passiert, wenn ein
paar Stimmen auf dem Track erscheinen und es dennoch häufig in mindestens 50% der modernen professionellen Tracks zu finden ist?
Was passiert, wenn der Gesang durch
Hall, Delays und andere Effekte verarbeitet wird? Werfen wir einen Blick auf den letzten Refrain von Ariana Grande aus diesem Lied.
Fühlst du schon Schmerzen ...? Ich ja.
Solche Methoden nach strengen Regeln verwandeln sich sehr schnell in ein Kartenhaus. Das Problem ist zu kompliziert. Zu viele Regeln, zu viele Ausnahmen und zu viele verschiedene Bedingungen (Effekte und Mix-Einstellungen). Ein mehrstufiger Ansatz impliziert auch, dass Fehler in einem Schritt die Probleme auf den nächsten Schritt ausweiten. Das Verbessern jedes Schritts wird sehr teuer: Es wird eine große Anzahl von Iterationen erfordern, um es richtig zu machen. Und zu guter Letzt ist es wahrscheinlich, dass wir am Ende einen sehr ressourcenintensiven Förderer bekommen, der an sich alle Anstrengungen zunichte machen kann.
In einer solchen Situation ist es an der Zeit, über einen umfassenderen Ansatz nachzudenken und ML einen Teil der grundlegenden Prozesse und Operationen herausfinden zu lassen, die zur Lösung des Problems erforderlich sind. Aber wir müssen noch unsere Fähigkeiten unter Beweis stellen und uns mit Feature-Engineering beschäftigen, und Sie werden sehen, warum.Hypothese: Verwenden Sie das neuronale Netzwerk als Übertragungsfunktion, die Mixe in Gesang übersetzt
Wenn Sie sich die Errungenschaften neuronaler Faltungsnetze bei der Verarbeitung von Fotos ansehen, warum sollten Sie hier nicht denselben Ansatz anwenden?
 Neuronale Netze lösen erfolgreich Probleme wie das Einfärben von Bildern, das Schärfen und die Auflösung.
Neuronale Netze lösen erfolgreich Probleme wie das Einfärben von Bildern, das Schärfen und die Auflösung.Am Ende können Sie sich das Tonsignal „als Bild“ mit der kurzfristigen Fourier-Transformation vorstellen, oder? Obwohl diese
Klangbilder nicht der statistischen Verteilung natürlicher Bilder entsprechen, weisen sie dennoch räumliche Muster (in Zeit und Frequenzraum) auf, auf denen das Netzwerk trainiert werden soll.
 Links: Drum Beat und Baseline unten, mehrere Synthesizer-Sounds in der Mitte, alle gemischt mit Gesang. Richtig: nur Gesang
Links: Drum Beat und Baseline unten, mehrere Synthesizer-Sounds in der Mitte, alle gemischt mit Gesang. Richtig: nur GesangDie Durchführung eines solchen Experiments wäre ein teures Unterfangen, da es schwierig ist, die erforderlichen Trainingsdaten zu erhalten oder zu generieren. In der angewandten Forschung versuche ich jedoch immer, diesen Ansatz zu verwenden: Erstens,
um ein einfacheres Problem zu identifizieren, das dieselben Prinzipien bestätigt , aber nicht viel Arbeit erfordert. Auf diese Weise können Sie die Hypothese bewerten, schneller iterieren und das Modell mit minimalen Verlusten korrigieren, wenn es nicht ordnungsgemäß funktioniert.
Die implizite Bedingung ist, dass das
neuronale Netzwerk die Struktur der menschlichen Sprache verstehen muss . Ein einfacheres Problem kann folgendes sein:
Kann ein neuronales Netzwerk das Vorhandensein von Sprache auf einem beliebigen Fragment einer Tonaufzeichnung bestimmen? Es handelt sich um einen zuverlässigen
Sprachaktivitätsdetektor (VAD) , der in Form eines binären Klassifikators implementiert ist.
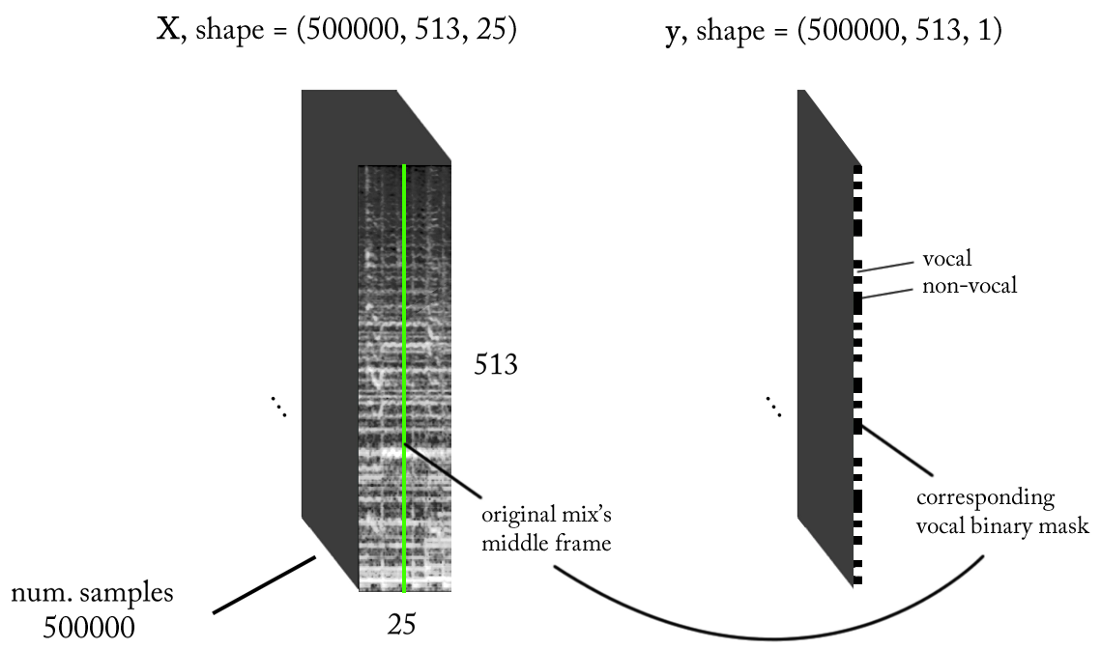
Wir gestalten den Raum der Zeichen
Wir wissen, dass Tonsignale wie Musik und menschliche Sprache auf Zeitabhängigkeiten beruhen. Einfach ausgedrückt, passiert zu einem bestimmten Zeitpunkt nichts isoliert. Wenn ich wissen möchte, ob eine bestimmte Tonaufnahme eine Stimme enthält, muss ich mir benachbarte Regionen ansehen. Ein solcher
Zeitkontext liefert gute Informationen darüber, was in dem Bereich von Interesse geschieht. Gleichzeitig ist es wünschenswert, eine Klassifizierung mit sehr kleinen Zeitschritten durchzuführen, um eine menschliche Stimme mit der höchstmöglichen Zeitauflösung zu erkennen.

Zählen wir ein wenig ...
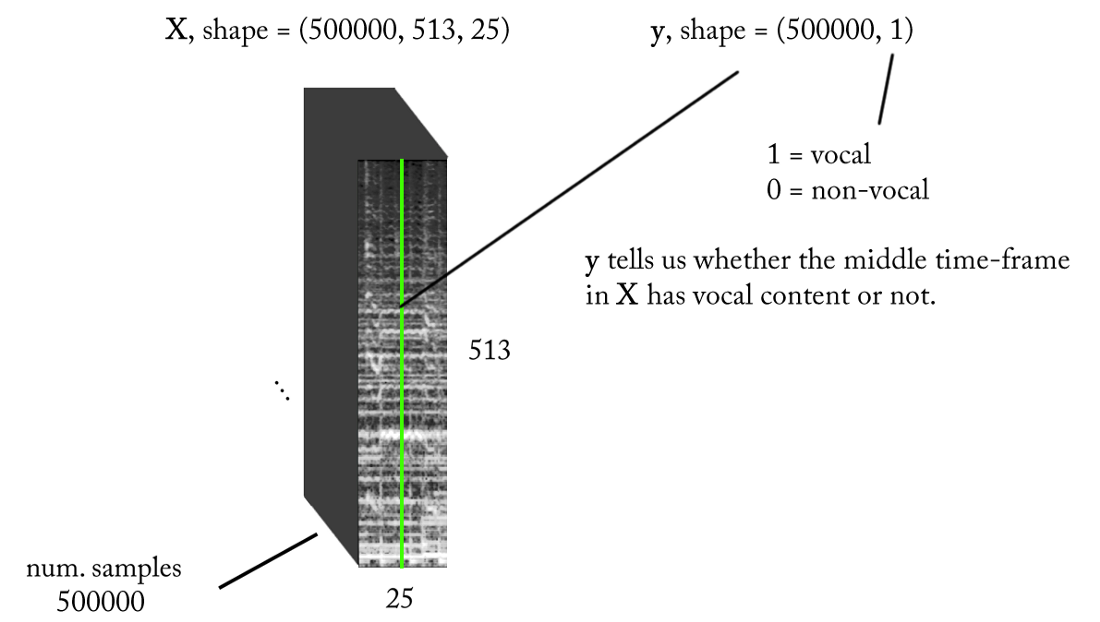
- Abtastfrequenz (fs): 22050 Hz (wir senken von 44100 auf 22050)
- STFT-Design: Fenstergröße = 1024, Sprunggröße = 256, Kreidelinieninterpolation für den Gewichtungsfilter unter Berücksichtigung der Wahrnehmung. Da unsere Eingabe real ist , können Sie mit der Hälfte der STFT arbeiten (eine Erklärung würde den Rahmen dieses Artikels sprengen ...), während Sie die DC-Komponente (optional) beibehalten, wodurch wir 513 Frequenzbereiche erhalten.
- Zielklassifizierungsauflösung: ein STFT-Rahmen (~ 11,6 ms = 256/22050)
- Zielzeitkontext: ~ 300 Millisekunden = 25 STFT-Frames.
- Die angestrebte Anzahl von Trainingsbeispielen: 500 Tausend.
- Angenommen, wir verwenden ein Schiebefenster mit einem Schritt von 1 STFT-Zeitrahmen, um Trainingsdaten zu generieren, benötigen wir ungefähr 1,6 Stunden beschrifteten Sound, um 500.000 Datenproben zu generieren
Mit den oben genannten Anforderungen sind die Ein- und Ausgabe unseres Binärklassifikators wie folgt:
Modell
Mit Keras werden wir ein kleines Modell eines neuronalen Netzwerks erstellen, um unsere Hypothese zu testen.
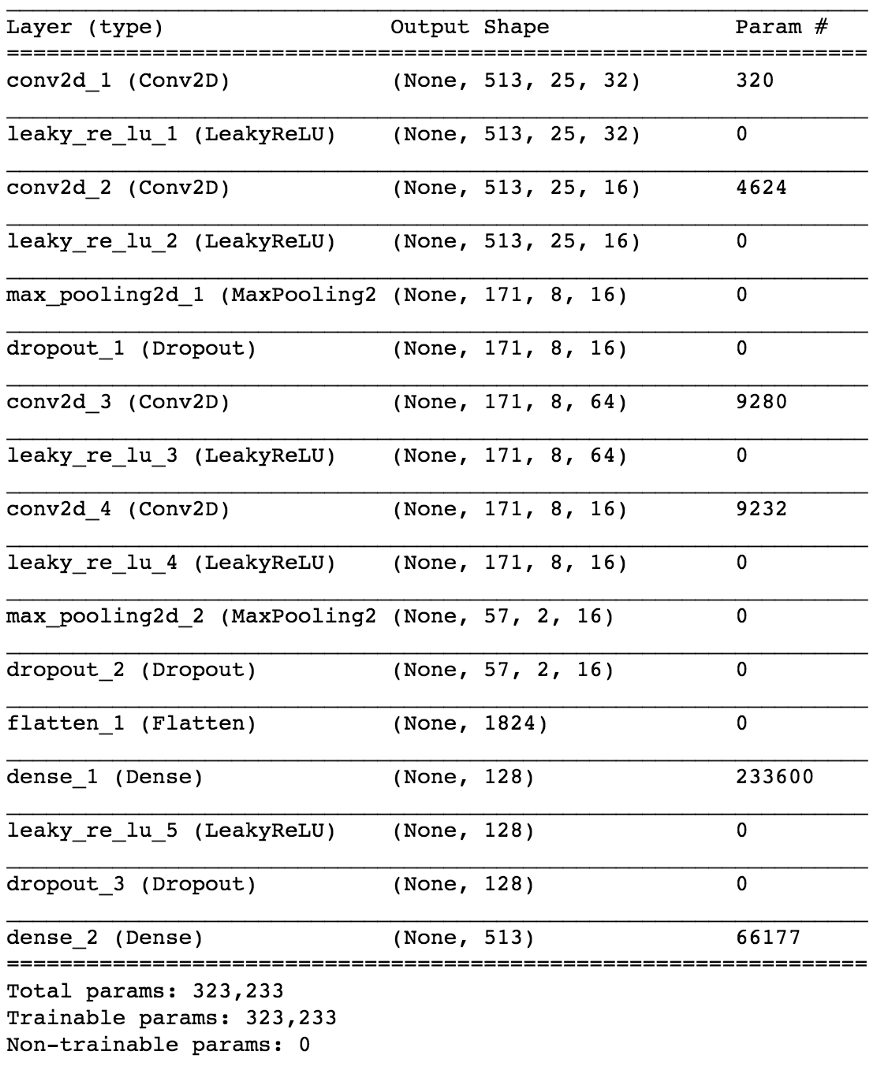
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
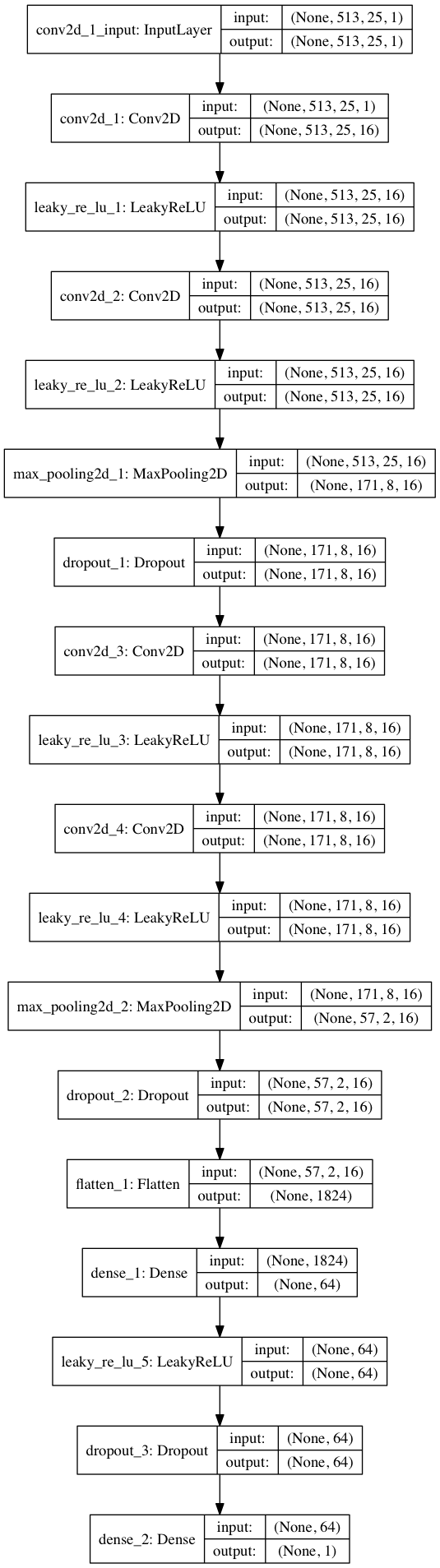
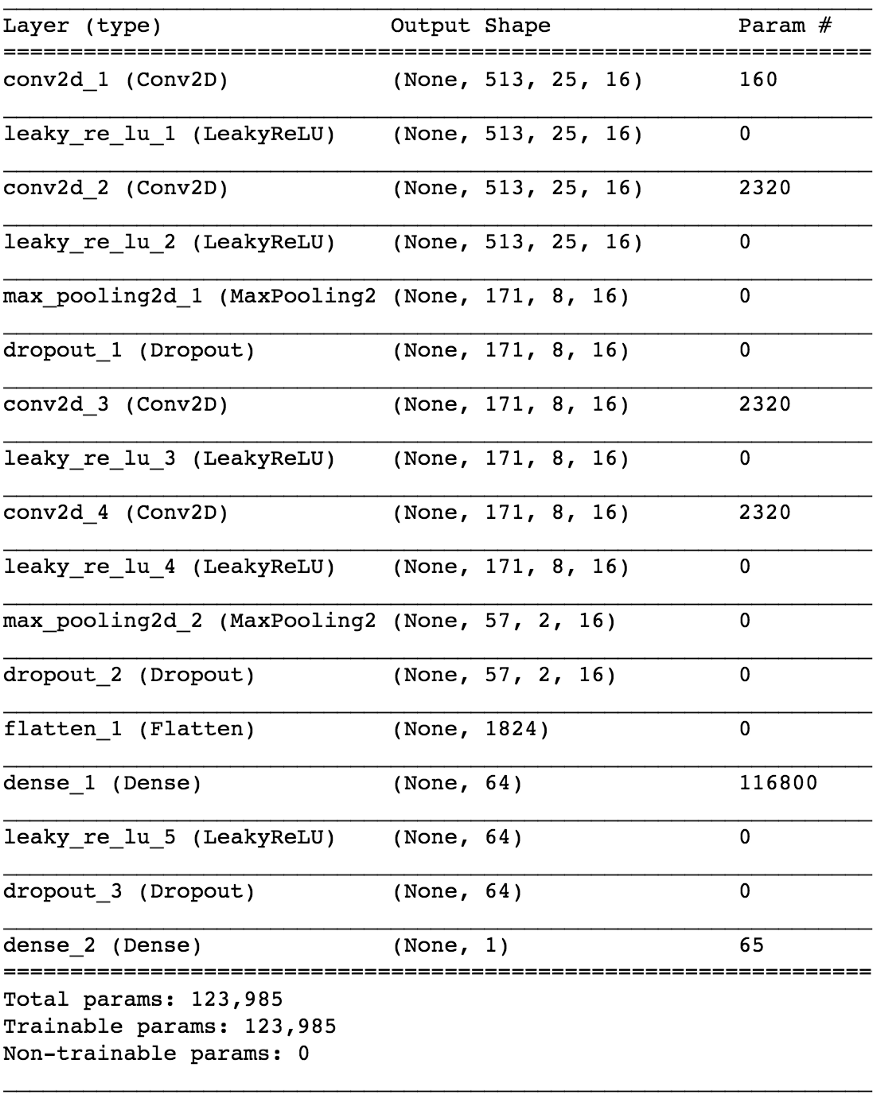
Durch die Aufteilung von 80/20 Daten in Training und Tests nach ~ 50 Epochen erhalten wir die
Genauigkeit beim Testen von ~ 97% . Dies ist ein ausreichender Beweis dafür, dass unser Modell in der Lage ist, zwischen Gesang in musikalischen Klangfragmenten (und Fragmenten ohne Gesang) zu unterscheiden. Wenn wir einige Feature-Maps aus der 4. Faltungsschicht überprüfen, können wir schließen, dass das neuronale Netzwerk seine Kernel für zwei Aufgaben optimiert zu haben scheint: Filtern von Musik und Filtern von Gesang ...
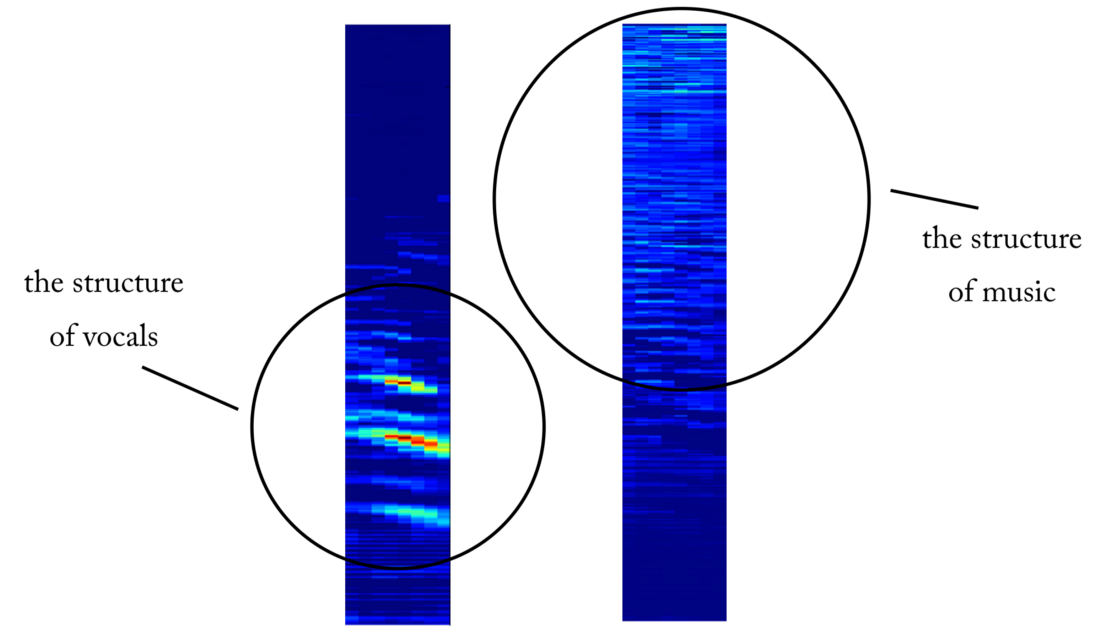 Ein Beispiel für eine Karte von Objekten am Ausgang der 4. Faltungsschicht. Anscheinend ist die Ausgabe auf der linken Seite das Ergebnis von Kerneloperationen, bei denen versucht wurde, den Sprachinhalt beizubehalten, während Musik ignoriert wurde. Hohe Werte ähneln der harmonischen Struktur der menschlichen Sprache. Die Objektkarte rechts scheint das Ergebnis der entgegengesetzten Aufgabe zu sein.
Ein Beispiel für eine Karte von Objekten am Ausgang der 4. Faltungsschicht. Anscheinend ist die Ausgabe auf der linken Seite das Ergebnis von Kerneloperationen, bei denen versucht wurde, den Sprachinhalt beizubehalten, während Musik ignoriert wurde. Hohe Werte ähneln der harmonischen Struktur der menschlichen Sprache. Die Objektkarte rechts scheint das Ergebnis der entgegengesetzten Aufgabe zu sein.Vom Sprachdetektor zur Signaltrennung
Wie können wir, nachdem wir das einfachere Klassifizierungsproblem gelöst haben, zur wirklichen Trennung von Gesang und Musik übergehen? Nun, wenn wir uns die erste
naive Methode
ansehen , wollen wir immer noch irgendwie ein Amplitudenspektrogramm für den Gesang erhalten. Dies wird nun zu einer Regressionsaufgabe. Was wir tun wollen, ist, das entsprechende Amplitudenspektrum für die Vocals in diesem Zeitrahmen aus der STFT des ursprünglichen Signals, dh aus der Mischung (mit einem ausreichenden Zeitkontext) zu berechnen.
Was ist mit dem Trainingsdatensatz? (Sie können mich in diesem Moment fragen)Verdammt ... warum so. Ich wollte dies am Ende des Artikels berücksichtigen, um nicht vom Thema abgelenkt zu werden!
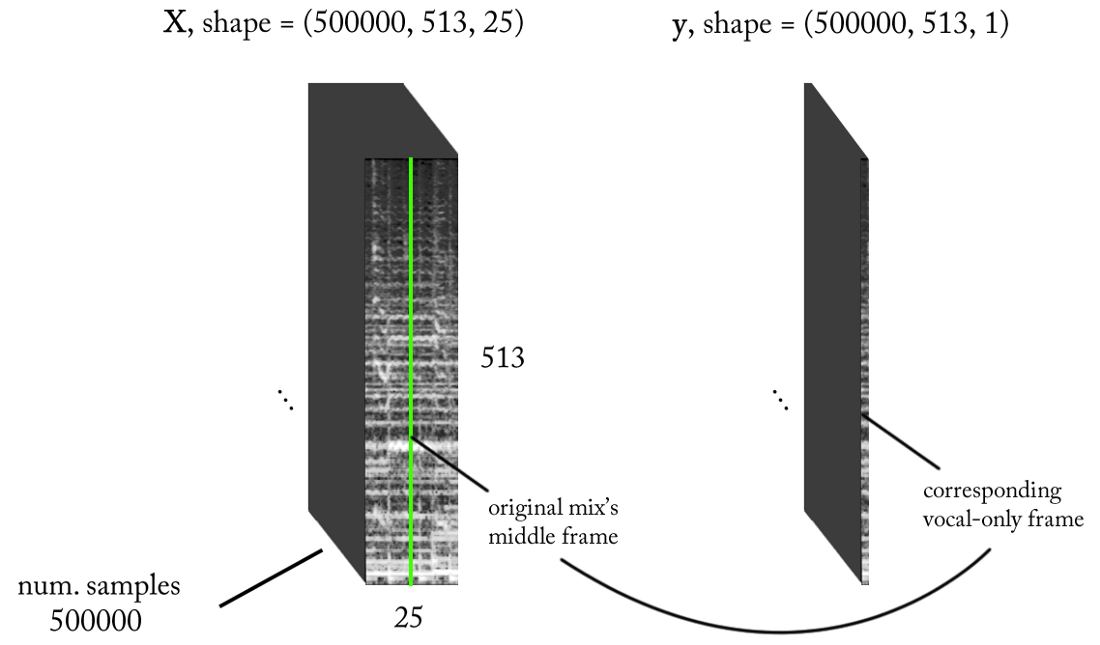
Wenn unser Modell gut ausgebildet ist, müssen Sie für eine logische Schlussfolgerung nur ein einfaches Schiebefenster für den STFT-Mix implementieren. Verschieben Sie das Fenster nach jeder Vorhersage um 1 Zeitrahmen nach rechts, sagen Sie das nächste Bild mit Gesang voraus und verknüpfen Sie es mit der vorherigen Vorhersage. Nehmen wir für das Modell dasselbe Modell, das für den Sprachdetektor verwendet wurde, und nehmen Sie kleine Änderungen vor: Die Ausgangswellenform ist jetzt (513.1), lineare Aktivierung am Ausgang, MSE als Funktion der Verluste. Jetzt beginnen wir mit dem Training.
Freue dich noch nicht ...Obwohl diese Darstellung von E / A nach mehrmaligem Training unseres Modells mit verschiedenen Parametern und Datennormalisierungen sinnvoll ist, gibt es keine Ergebnisse. Es scheint, wir fragen zu viel ...
Wir sind von einem binären Klassifikator zur
Regression eines 513-dimensionalen Vektors übergegangen. Obwohl das Netzwerk das Problem bis zu einem gewissen Grad untersucht, weisen die wiederhergestellten Vocals immer noch offensichtliche Artefakte und Störungen durch andere Quellen auf. Selbst nach dem Hinzufügen zusätzlicher Ebenen und dem Erhöhen der Anzahl der Modellparameter ändern sich die Ergebnisse nicht wesentlich. Und dann stellt sich die Frage:
Wie kann die Aufgabe für das Netzwerk durch Täuschung „vereinfacht“ und gleichzeitig die gewünschten Ergebnisse erzielt werden?Was ist, wenn wir anstelle der Schätzung der Amplitude der STFT-Vocals das Netzwerk trainieren, um eine binäre Maske zu erhalten, die bei Anwendung auf die STFT-Mischung ein vereinfachtes, aber
wahrnehmbar akzeptables Amplitudenspektrogramm der Vocals liefert?
Beim Experimentieren mit verschiedenen Heuristiken haben wir eine sehr einfache (und natürlich in Bezug auf die Signalverarbeitung unorthodoxe ...) Methode gefunden, um Vocals mithilfe von Binärmasken aus Mixes zu extrahieren. Ohne auf Details einzugehen, ist das Wesentliche wie folgt. Stellen Sie sich die Ausgabe als Binärbild vor, wobei der Wert '1' das
vorherrschende Vorhandensein von Stimminhalten bei einer bestimmten Frequenz und einem bestimmten Zeitrahmen und der Wert '0' das vorherrschende Vorhandensein von Musik an einem bestimmten Ort angibt. Wir können es die
Binarisierung der Wahrnehmung nennen , nur um einen Namen zu finden. Optisch sieht es ziemlich hässlich aus, um ehrlich zu sein, aber die Ergebnisse sind überraschend gut.
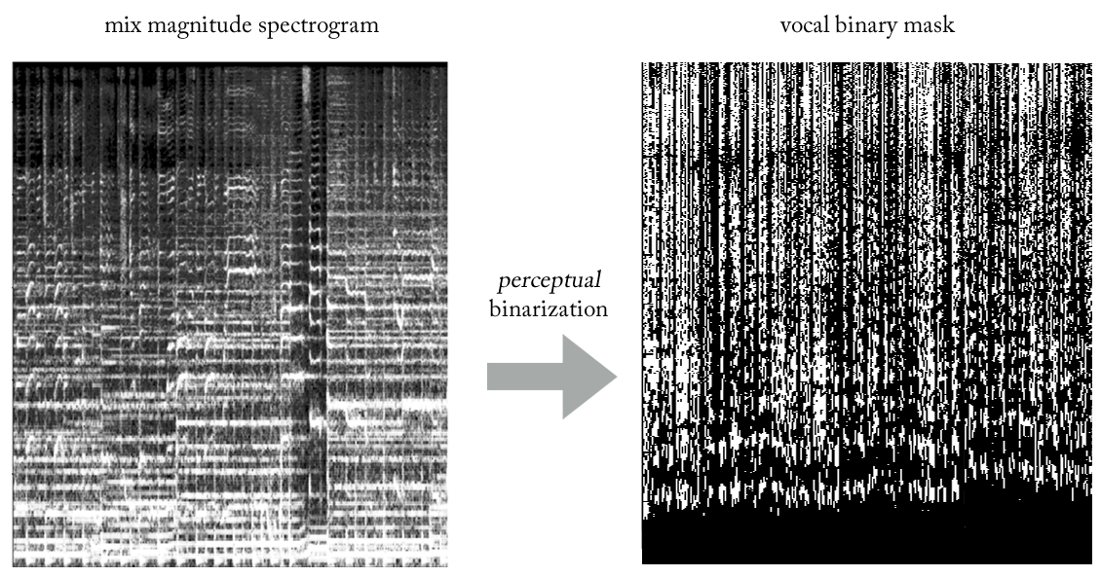
Jetzt wird unser Problem zu einer Art hybrider Regressionsklassifikation (sehr grob ...). Wir fordern das Modell auf, „Pixel“ am Ausgang als vokal oder nicht vokal zu klassifizieren, obwohl die Aufgabe konzeptionell (sowie aus Sicht der verwendeten MSE-Verlustfunktion) regressiv bleibt.
Obwohl diese Unterscheidung für einige unangemessen erscheint, ist sie für die Fähigkeit des Modells, die Aufgabe zu untersuchen, von großer Bedeutung. Die zweite ist einfacher und begrenzter. Gleichzeitig können wir so unser Modell in Bezug auf die Anzahl der Parameter angesichts der Komplexität der Aufgabe relativ klein halten, was für das Arbeiten in Echtzeit sehr wünschenswert ist, was in diesem Fall eine Entwurfsanforderung war. Nach einigen kleinen Änderungen sieht das endgültige Modell so aus.
Wie kann ein Zeitbereichssignal wiederhergestellt werden?
In der Tat wie bei der
naiven Methode . In diesem Fall sagen wir für jeden Durchgang einen Zeitrahmen der binären Vokalmaske voraus. Bei der Realisierung eines einfachen Schiebefensters mit einem Schritt von einem Zeitrahmen bewerten und kombinieren wir weiterhin aufeinanderfolgende Zeitrahmen, die letztendlich die gesamte vokale Binärmaske bilden.

Erstellen Sie ein Trainingsset
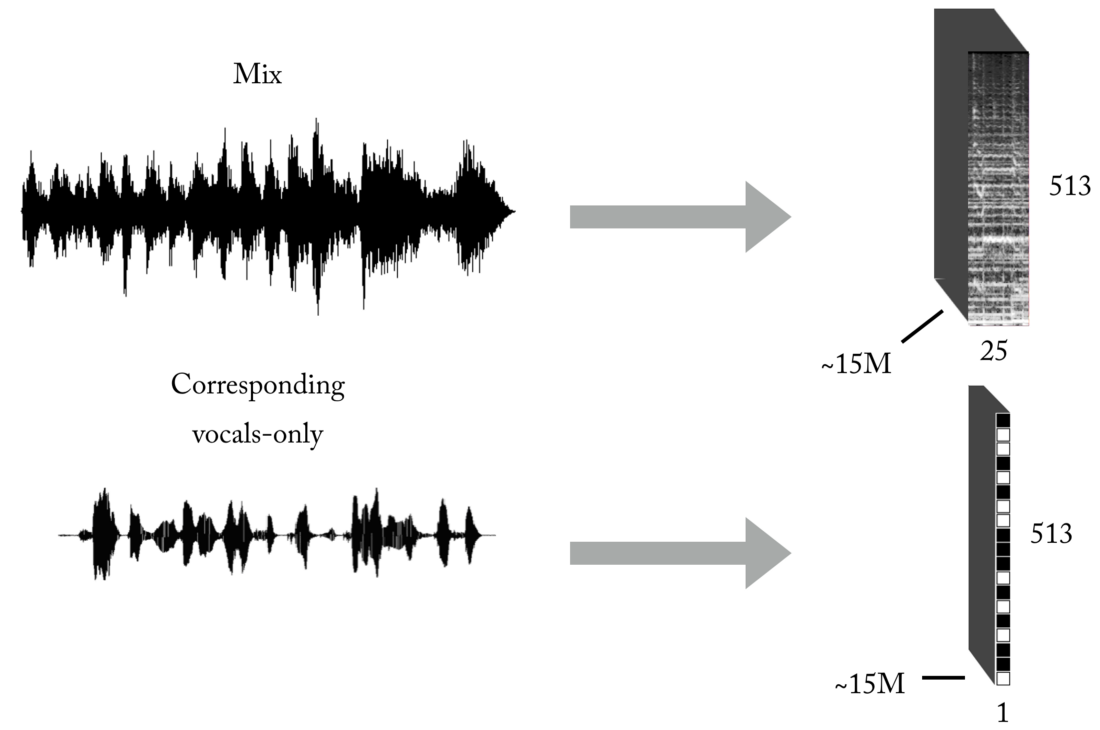
Wie Sie wissen, besteht eines der Hauptprobleme beim Unterrichten mit einem Lehrer (lassen Sie diese Spielzeugbeispiele mit vorgefertigten Datensätzen) in den richtigen Daten (in Quantität und Qualität) für das spezifische Problem, das Sie lösen möchten. Basierend auf den beschriebenen Darstellungen von Eingabe und Ausgabe benötigen Sie zum Trainieren unseres Modells zunächst eine erhebliche Anzahl von Mixes und die entsprechenden, perfekt ausgerichteten und normalisierten Gesangsspuren. Dieses Set kann auf verschiedene Arten erstellt werden, und wir haben eine Kombination von Strategien verwendet, von der manuellen Erstellung von Paaren [Mix <-> Vocals] basierend auf mehreren im Internet gefundenen Cappels bis hin zur Suche nach Rockband-Musikmaterial und Youtube-Scrapbooking. Um Ihnen eine Vorstellung davon zu geben, wie mühsam und schmerzhaft dieser Prozess ist, war Teil des Projekts die Entwicklung eines solchen Tools zum automatischen Erstellen von Paaren [Mix <-> Vocals]:

Das neuronale Netzwerk benötigt eine sehr große Datenmenge, um die Übertragungsfunktion für das Senden von Mixes an Gesang zu erlernen. Unser endgültiger Satz bestand aus ungefähr 15 Millionen Samples von 300-ms-Mixen und den entsprechenden binären Vokalmasken.
Pipeline-Architektur
Wie Sie wahrscheinlich wissen, ist das Erstellen eines ML-Modells für eine bestimmte Aufgabe nur die halbe Miete. In der realen Welt müssen Sie über die Softwarearchitektur nachdenken, insbesondere wenn Sie in Echtzeit oder in der Nähe arbeiten müssen.
In dieser speziellen Implementierung kann die Rekonstruktion im Zeitbereich unmittelbar nach der Vorhersage der vollständigen binären Gesangsmaske (Standalone-Modus) oder, was noch interessanter ist, im Multithread-Modus erfolgen, in dem wir Daten empfangen und verarbeiten, Vocals wiederherstellen und Ton wiedergeben - alles in kleinen Segmenten nahe Streaming und sogar fast in Echtzeit, Verarbeitung von Musik, die im laufenden Betrieb mit minimaler Verzögerung aufgenommen wird. Eigentlich ist dies ein separates Thema, und ich werde es für einen weiteren Artikel
über Echtzeit-ML-Pipelines belassen ...
Ich glaube, ich habe genug gesagt, warum also nicht ein paar Beispiele anhören?
Daft Punk - Get Lucky (Studioaufnahme)
Hier können Sie einige minimale Störungen durch die Trommeln hören ...Adele - Zünde den Regen an (Live-Aufnahme!)
Beachten Sie, wie unser Modell ganz am Anfang die Schreie der Menge als stimmlichen Inhalt extrahiert :). In diesem Fall treten Störungen durch andere Quellen auf. Da es sich um eine Live-Aufnahme handelt, scheint es akzeptabel, dass die extrahierten Vocals eine schlechtere Qualität aufweisen als die vorherigen.Ja und "etwas anderes" ...
Wenn das System für Gesang funktioniert, warum nicht auf andere Instrumente anwenden ...?
Der Artikel ist bereits ziemlich umfangreich, aber angesichts der geleisteten Arbeit verdienen Sie es, die neueste Demo zu hören. Mit genau der gleichen Logik wie beim Extrahieren von Gesang können wir versuchen, die Stereomusik in Komponenten (Schlagzeug, Bass, Gesang, andere) zu unterteilen, einige Änderungen an unserem Modell vorzunehmen und natürlich das entsprechende Trainingsset zu haben :).
Danke fürs Lesen. Als letzte Anmerkung: Wie Sie sehen können, ist das tatsächliche Modell unseres Faltungsnetzwerks nicht so speziell. Der Erfolg dieser Arbeit wurde durch
Feature Engineering und den übersichtlichen Hypothesentestprozess bestimmt, über den ich in zukünftigen Artikeln schreiben werde!