Hallo nochmal. Heute teilen wir weiterhin Material, das dem Start des Kurses
"Network Engineer" gewidmet ist , der bereits Anfang März beginnt. Wir sehen, dass viele an dem
ersten Teil des Artikels „Maschinensynästhetischer Ansatz zur Erkennung von Netzwerk-DDoS-Angriffen“ interessiert waren, und heute möchten wir Ihnen den zweiten Teil - den letzten Teil - mitteilen.
3.2 Bildklassifizierung im Problem der AnomalieerkennungDer nächste Schritt besteht darin, das Klassifizierungsproblem des resultierenden Bildes zu lösen. Im Allgemeinen besteht die Lösung für das Problem der Erkennung von Klassen (Objekten) in einem Bild darin, Algorithmen für maschinelles Lernen zu verwenden, um Klassenmodelle zu erstellen, und dann Algorithmen, um nach Klassen (Objekten) in einem Bild zu suchen.

Das Erstellen eines Modells besteht aus zwei Schritten:
a) Merkmalsextraktion für eine Klasse: Zeichnen Sie Merkmalsvektoren für Klassenmitglieder.

Abb. 1
b) Schulung in den erhaltenen Modellmerkmalen für nachfolgende Erkennungsaufgaben.
Das Klassenobjekt wird unter Verwendung von Merkmalsvektoren beschrieben. Vektoren werden gebildet aus:
a) Farbinformationen (orientiertes Gradientenhistogramm);
b) Kontextinformationen;
c) Daten zur geometrischen Anordnung von Teilen des Objekts.
Der Klassifizierungsalgorithmus (Prognosealgorithmus) kann in zwei Stufen unterteilt werden:
a) Extrahieren Sie Merkmale aus dem Bild. In dieser Phase werden zwei Aufgaben ausgeführt:
- Da das Bild Objekte vieler Klassen enthalten kann, müssen wir alle Vertreter finden. Dazu können Sie ein Schiebefenster verwenden, das von links oben nach rechts unten durch das Bild verläuft.
- Das Bild wird skaliert, da sich die Skalierung der Objekte im Bild ändern kann.
b) Zuordnen eines Bildes zu einer bestimmten Klasse. Als Eingabe wird eine formale Beschreibung der Klasse verwendet, dh eine Reihe von Funktionen, die durch ihre Testbilder hervorgehoben werden. Basierend auf diesen Informationen entscheidet der Klassifizierer, ob das Bild zur Klasse gehört, und bewertet den Grad der Sicherheit für die Schlussfolgerung.
Klassifizierungsmethoden. Die Klassifizierungsmethoden reichen von überwiegend heuristischen Ansätzen bis zu formalen Verfahren, die auf Methoden der mathematischen Statistik basieren. Es gibt keine allgemein akzeptierte Klassifizierung, aber verschiedene Ansätze zur Bildklassifizierung können unterschieden werden:
- Methoden der Objektmodellierung basierend auf Details;
- Methoden der "Tasche der Wörter";
- Methoden zur Anpassung räumlicher Pyramiden.
Für die in diesem Artikel vorgestellte Implementierung haben die Autoren aus folgenden Gründen den "Word Bag" -Algorithmus gewählt:
- Algorithmen zur Modellierung basierend auf Details und passenden räumlichen Pyramiden sind abhängig von der Position der Deskriptoren im Raum und ihrer relativen Position. Diese Methodenklassen sind bei der Erkennung von Objekten in einem Bild wirksam. Aufgrund der charakteristischen Merkmale der Eingabedaten sind sie jedoch für das Problem der Bildklassifizierung schlecht anwendbar.
- Der "Bag of Words" -Algorithmus wurde in anderen Wissensbereichen umfassend getestet, zeigt gute Ergebnisse und ist recht einfach zu implementieren.
Um den aus dem Verkehr projizierten Videostream zu analysieren, verwendeten wir den naiven Bayes-Klassifikator [25]. Es wird häufig verwendet, um Texte anhand des Word-Bag-Modells zu klassifizieren. In diesem Fall ähnelt der Ansatz der Textanalyse, anstelle von Wörtern werden nur Deskriptoren verwendet. Die Arbeit dieses Klassifikators kann in zwei Teile unterteilt werden: die Trainingsphase und die Prognosephase.
Lernphase . Jeder Frame (Bild) wird der Eingabe des Deskriptorsuchalgorithmus zugeführt, in diesem Fall der skalierungsinvarianten Merkmalstransformation (SIFT) [26]. Danach wird die Aufgabe der Korrelation einzelner Punkte zwischen Rahmen ausgeführt. Ein bestimmter Punkt im Bild eines Objekts ist ein Punkt, der wahrscheinlich auf anderen Bildern dieses Objekts erscheint.
Um das Problem des Vergleichs spezieller Punkte eines Objekts in verschiedenen Bildern zu lösen, wird ein Deskriptor verwendet. Ein Deskriptor ist eine Datenstruktur, eine Kennung für einen einzelnen Punkt, der ihn vom Rest unterscheidet. Es kann in Bezug auf Transformationen des Bildes des Objekts unveränderlich sein oder nicht. In unserem Fall ist der Deskriptor in Bezug auf perspektivische Transformationen, d. H. Skalierung, unveränderlich. Mit dem Handle können Sie den Feature-Punkt eines Objekts in einem Bild mit demselben Feature-Punkt in einem anderen Bild dieses Objekts vergleichen.
Dann wird der aus allen Bildern erhaltene Satz von Deskriptoren durch Ähnlichkeit unter Verwendung der k-Mittel-Clustering-Methode in Gruppen sortiert [26, 27]. Dies geschieht, um den Klassifikator zu trainieren, der eine Schlussfolgerung darüber gibt, ob das Bild ein abnormales Verhalten darstellt.
Das Folgende ist ein schrittweiser Algorithmus zum Trainieren des Bilddeskriptor-Klassifikators:
Schritt 1 Extrahieren Sie alle Deskriptoren aus Sets mit und ohne Angriff.
Schritt 2 Clustering aller Deskriptoren mit der k-means-Methode in n Clustern.
Schritt 3 Berechnung der Matrix A (m, k), wobei m die Anzahl der Bilder und k die Anzahl der Cluster ist. Das Element (i; j) speichert den Wert, wie oft Deskriptoren aus dem j-ten Cluster auf dem i-ten Bild erscheinen. Eine solche Matrix wird als Matrix der Häufigkeit des Auftretens bezeichnet.
Schritt 4 Berechnung der Gewichte der Deskriptoren nach der Formel tf idf [28]:
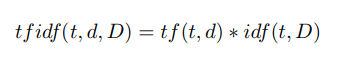
Hier ist tf ("Termfrequenz") die Häufigkeit des Auftretens des Deskriptors in diesem Bild und wird definiert als
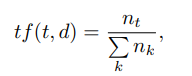
Dabei ist t der Deskriptor, k die Anzahl der Deskriptoren im Bild, nt die Anzahl der Deskriptoren t im Bild. Zusätzlich ist idf ("inverse Dokumentfrequenz") die inverse Bildfrequenz mit einem gegebenen Deskriptor in der Stichprobe und ist definiert als
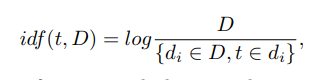
wobei D die Anzahl der Bilder mit einem gegebenen Deskriptor in der Stichprobe ist, {di ∈ D, t ∈ di} die Anzahl der Bilder in D ist, wobei t in nt ist! = 0.
Schritt 5 Einsetzen der entsprechenden Gewichte anstelle von Deskriptoren in Matrix A.
Schritt 6 Klassifizierung. Wir verwenden die Amplifikation von naiven Bayes-Klassifikatoren (Adaboost).
Schritt 7 Speichern des trainierten Modells in einer Datei.
Schritt 8 Damit ist die Trainingsphase abgeschlossen.
Vorhersagephase . Die Unterschiede zwischen der Trainingsphase und der Prognosephase sind gering: Deskriptoren werden aus dem Bild extrahiert und mit den vorhandenen Gruppen korreliert. Basierend auf diesem Verhältnis wird ein Vektor konstruiert. Jedes Element dieses Vektors ist die Häufigkeit des Auftretens von Deskriptoren aus dieser Gruppe im Bild. Durch Analyse dieses Vektors kann der Klassifizierer mit einer bestimmten Wahrscheinlichkeit eine Angriffsprognose erstellen.
Ein allgemeiner Prognosealgorithmus, der auf einem Paar von Klassifizierern basiert, wird unten dargestellt.
Schritt 1 Extrahieren Sie alle Deskriptoren aus dem Bild.
Schritt 2 Clustering der resultierenden Menge von Deskriptoren;
Schritt 3 Berechnung des Vektors [1, k];
Schritt 4 Berechnung des Gewichts für jeden Deskriptor gemäß der oben dargestellten Formel tf idf;
Schritt 5 Ersetzen der Häufigkeit des Auftretens in Vektoren durch deren Gewicht;
Schritt 6 Klassifizierung des resultierenden Vektors gemäß einem zuvor trainierten Klassifizierer;
Schritt 7 Schlussfolgerung über das Vorhandensein von Anomalien im beobachteten Netzwerk basierend auf der Prognose des Klassifikators.
4. Bewertung der DetektionseffizienzDie Aufgabe der Bewertung der Wirksamkeit der vorgeschlagenen Methode wurde experimentell gelöst. In dem Experiment wurde eine Anzahl von experimentell festgelegten Parametern verwendet. Für das Clustering wurden 1000 Cluster verwendet. Die erzeugten Bilder hatten 1000 mal 1000 Pixel.
4.1 Experimenteller DatensatzFür Experimente wurde die Installation zusammengebaut. Es besteht aus drei Geräten, die über einen Kommunikationskanal verbunden sind. Das Installationsblockdiagramm ist in Abbildung 2 dargestellt.
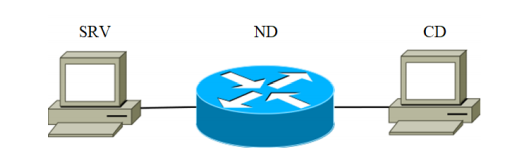
Abb. 1
Das SRV-Gerät fungiert als angreifender Server (im Folgenden als Zielserver bezeichnet). Die in Tabelle 1 aufgeführten Geräte mit dem SRV-Code wurden nacheinander als Zielserver verwendet. Das zweite ist ein Netzwerkgerät zum Übertragen von Netzwerkpaketen. Die Eigenschaften des Geräts sind in Tabelle 1 unter dem Code ND-1 aufgeführt.
Tabelle 1. Netzwerkgerätespezifikationen
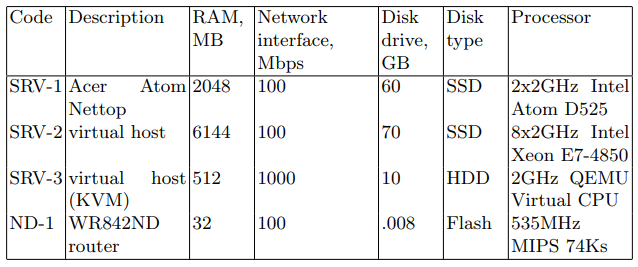
Auf den Zielservern wurden Netzwerkpakete zur späteren Verwendung in Erkennungsalgorithmen in eine PCAP-Datei geschrieben. Für diese Aufgabe wurde das Dienstprogramm tcpdump verwendet. Datensätze sind in Tabelle 2 beschrieben.
Tabelle 2. Sätze abgefangener Netzwerkpakete
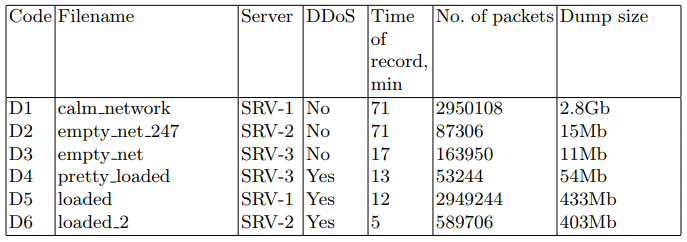
Die folgende Software wurde auf den Zielservern verwendet: Linux-Distribution, nginx 1.10.3-Webserver, postgresql 9.6 DBMS. Eine spezielle Webanwendung wurde geschrieben, um den Systemstart zu emulieren. Die Anwendung fordert eine Datenbank mit einer großen Datenmenge an. Die Anforderung soll die Verwendung verschiedener Zwischenspeicherungen minimieren. Während der Experimente wurden Anfragen für diese Webanwendung generiert.
Der Angriff wurde vom dritten Clientgerät (Tabelle 1) mit dem Dienstprogramm Apache Benchmark ausgeführt. Die Struktur des Hintergrundverkehrs während des Angriffs und der restlichen Zeit ist in Tabelle 3 dargestellt.
Tabelle 3. Hintergrundverkehrsfunktionen
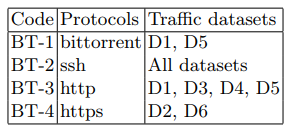
Als Angriff implementieren wir die verteilte DoS-Version der HTTP-GET-Flut. Ein solcher Angriff ist in der Tat die Erzeugung eines konstanten Stroms von GET-Anforderungen, in diesem Fall von einem CD-1-Gerät. Um es zu generieren, haben wir das Dienstprogramm ab aus dem Paket apache-utils verwendet. Als Ergebnis wurden Dateien empfangen, die Informationen über den Status des Netzwerks enthielten. Die Hauptmerkmale dieser Dateien sind in Tabelle 2 dargestellt. Die Hauptparameter des Angriffsszenarios sind in Tabelle 4 aufgeführt.
Aus dem empfangenen Netzwerkverkehrs-Dump wurden Sätze von erzeugten Bildern TD # 1 und TD # 2 erhalten, die in der Trainingsphase verwendet wurden. Probe TD # 3 wurde für die Vorhersagephase verwendet. Eine Zusammenfassung der Testdatensätze ist in Tabelle 5 dargestellt.
4.2 LeistungskriterienDie wichtigsten Parameter, die während dieser Studie bewertet wurden, waren:
Tabelle 4. Merkmale eines DDoS-Angriffs

Tabelle 5. Testbildsätze

a) DR (Erkennungsrate) - Die Anzahl der erkannten Angriffe im Verhältnis zur Gesamtzahl der Angriffe. Je höher dieser Parameter ist, desto höher ist die Effizienz und Qualität von ADS.
b) FPR (False Positive Rate) - die Anzahl der "normalen" Objekte, die fälschlicherweise als Angriff klassifiziert wurden, bezogen auf die Gesamtzahl der "normalen" Objekte. Je niedriger dieser Parameter ist, desto höher ist die Effizienz und Qualität des Anomalieerkennungssystems.
c) CR (Complex Rate) ist ein komplexer Indikator, der die Kombination von DR- und FPR-Parametern berücksichtigt. Da die Parameter DR und FPR in der Studie gleich wichtig waren, wurde der komplexe Indikator wie folgt berechnet: CR = (DR + FPR) / 2.
1000 als "abnormal" gekennzeichnete Bilder wurden an den Klassifizierer gesendet. Basierend auf den Erkennungsergebnissen wurde DR in Abhängigkeit von der Größe der Trainingsprobe berechnet. Die folgenden Werte wurden erhalten: für TD # 1 DR = 9,5% und für TD # 2 DR = 98,4%. Ferner wurde die zweite Hälfte der Bilder ("normal") klassifiziert. Basierend auf dem Ergebnis wurde der FPR berechnet (für TD # 1 FPR = 3,2% und für TD # 2 FPR = 4,3%). Somit wurden die folgenden umfassenden Leistungsindikatoren erhalten: für TD # 1 CR = 53,15% und für TD # 2 CR = 97,05%.
5. Schlussfolgerungen und zukünftige ForschungAus den experimentellen Ergebnissen ist ersichtlich, dass das vorgeschlagene Verfahren zum Erkennen von Anomalien hohe Ergebnisse beim Erkennen von Angriffen zeigt. Beispielsweise erreicht in einer großen Stichprobe der Wert eines umfassenden Leistungsindikators 97%. Diese Methode weist jedoch einige Einschränkungen bei der Anwendung auf:
1. Die Werte von DR und FPR zeigen die Empfindlichkeit des Algorithmus gegenüber der Größe des Trainingssatzes, was ein konzeptionelles Problem für Algorithmen für maschinelles Lernen darstellt. Das Erhöhen der Probe verbessert die Nachweisleistung. Es ist jedoch nicht immer möglich, einen ausreichend großen Trainingssatz für ein bestimmtes Netzwerk zu implementieren.
2. Der entwickelte Algorithmus ist deterministisch, jedes Mal wird das gleiche Bild mit dem gleichen Ergebnis klassifiziert.
3. Die Wirksamkeitsindikatoren des Ansatzes sind gut genug, um das Konzept zu bestätigen, aber auch die Anzahl der falsch positiven Ergebnisse ist groß, was zu Schwierigkeiten bei der praktischen Umsetzung führen kann.
Um die oben beschriebene Einschränkung (Punkt 3) zu überwinden, soll der naive Bayes'sche Klassifikator in ein Faltungs-Neuronales Netzwerk umgewandelt werden, was nach Ansicht der Autoren die Genauigkeit des Anomalieerkennungsalgorithmus erhöhen sollte.
Referenzen1. Mohiuddin A., Abdun NM, Jiankun H .: Eine Übersicht über Techniken zur Erkennung von Netzwerkanomalien. In: Journal of Network and Computer Applications. Vol. 60, p. 21 (2016)
2. Afontsev E .: Netzwerkanomalien, 2006
nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov AA: Architektur intelligenter Agenten basierend auf einem Produktionssystem zum Schutz vor Virenangriffen im Internet. In: XV Allrussische Wissenschaftskonferenz Probleme der Informationssicherheit im Hochschulsystem “, pp. 180-276 (2008)
4. Galtsev AV: Systemanalyse des Verkehrs zur Identifizierung anomaler Netzwerkbedingungen: Die Arbeit für den Candidate Degree of Technical Sciences. Samara (2013)
5. Kornienko AA, Slyusarenko IM: Intrusion Detection-Systeme und -Methoden: Aktueller Stand und Richtung der Verbesserung, 2008
citforum.ru/security internet / ids Übersicht /
6. Kussul N., Sokolov A .: Adaptive Anomalieerkennung im Benutzerverhalten von Computersystemen unter Verwendung von Markov-Ketten variabler Ordnung. Teil 2: Methoden zur Erkennung von Anomalien und die Ergebnisse von Experimenten. In: Informatik- und Steuerungsprobleme. Ausgabe 4, S. 83-88 (2003)
7. Mirkes EM: Neurocomputer: Standardentwurf. Science, Novosibirsk, pp. 150-176 (1999)
8. Tsvirko DA Vorhersage einer Netzwerkangriffsroute mithilfe von Produktionsmodellmethoden, 2012
akademie.kaspersky.com/downloads/academycup teilnehmer / cvirko d. ppt
9. Somayaji A .: Automatisierte Antwort mit Systemanrufverzögerungen. In: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K .: USTAT: Ein Echtzeit-Intrusion Detection-System für UNIX. In: IEEE-Symposium zur Erforschung von Sicherheit und Datenschutz, University of California (1992)
11. Eskin E., Lee W. und Stolfo SJ: Das Modellierungssystem erfordert eine Intrusion Detection mit dynamischen Fenstergrößen. In: DARPA-Konferenz und Ausstellung zur Überlebensfähigkeit von Informationen (DISCEX II), Juni 2001
12. Ye N., Xu M. und Emran SM: Probabilistische Netzwerke mit ungerichteten Links zur Erkennung von Anomalien. In: 2000 IEEE-Workshop zu Informationssicherung und -sicherheit, West Point, NY (2000)
13. Michael CC und Ghosh A .: Zwei zustandsbasierte Ansätze zur programmbasierten Erkennung von Anomalien. In: ACM-Transaktionen zur Informations- und Systemsicherheit. Nein, nein. 5 (2), 2002
14. Garvey TD, Lunt TF: Modellbasierte Intrusion Detection. In: 14. Nation Computersicherheitskonferenz, Baltimore, MD (1991)
15. Theus M. und Schonlau M .: Intrusion Detection basierend auf strukturellen Nullen. In: Statistical Computing und Grafik Newsletter. Nein, nein. 9 (1), pp. 12-17 (1998)
16. Tan K .: Die Anwendung neuronaler Netze zur Unix-Computersicherheit. In: Internationale IEEE-Konferenz über neuronale Netze. Vol. 1, pp. 476-481, Perth, Australien (1995)
17. Ilgun K., Kemmerer RA, Porras PA: Zustandsübergangsanalyse: Ein regelbasiertes Intrusion Detection System. In: IEEE Trans. Software Eng. Vol. 21, nein. 3 (1995)
18. Eskin E .: Anomalieerkennung über verrauschte Daten unter Verwendung erlernter Wahrscheinlichkeitsverteilungen. In: 17. Internationale Konf. zum maschinellen Lernen, pp. 255-262. Morgan Kaufmann, San Francisco, CA (2000)
19. Ghosh K., Schwartzbard A. und Schatz M .: Verhaltensprofile des Lernprogramms zur Erkennung von Eindringlingen. In: 1. USENIX-Workshop zu Intrusion Detection und Netzwerküberwachung, pp. 51-62, Santa Clara, Kalifornien (1999)
20. Ye N .: Ein Markov-Kettenmodell des zeitlichen Verhaltens zur Erkennung von Anomalien. In: 2000 Workshop zu IEEE-Systemen, Mensch und Kybernetik, Informationssicherung und Sicherheit (2000)
21. Axelsson S.: Der Basisratenfehler und seine Auswirkungen auf die Schwierigkeit der Intrusion Detection. In: ACM-Konferenz über Computer- und Kommunikationssicherheit, pp. 1? 7 (1999)
22. Chikalov I, Moshkov M, Zielosko B .: Optimierung von Entscheidungsregeln basierend auf Methoden der dynamischen Programmierung. In Vestnik der Lobachevsky State University von Nischni Nowgorod, Nr. 6, pp. 195-200
23. Chen CH: Handbuch zur Mustererkennung und Computer Vision. Universität von Massachusetts Dartmouth, USA (2015)
24. Gantmacher FR: Theorie der Matrizen, p. 227. Science, Moskau (1968)
25. Murty MN, Devi VS: Mustererkennung: Ein Algorithmus. Pp. 93-94 (2011)
Traditionell warten wir auf Ihre Kommentare und laden alle zu einem
Tag der
offenen Tür ein , der nächsten Montag stattfinden wird.