
Als Container-Orchestratoren wie Kubernetes eintrafen, änderte sich der Ansatz zur Entwicklung und Bereitstellung von Anwendungen dramatisch. Microservices sind erschienen, und für den Entwickler ist die Anwendungslogik nicht mehr mit der Infrastruktur verbunden: Erstellen Sie Anwendungen für sich selbst und bieten Sie neue Funktionen an.
Kubernetes abstrahiert von den physischen Computern, die es steuert. Sagen Sie ihm einfach, wie viel Speicher und Rechenleistung Sie benötigen - und Sie erhalten alles. Infrastruktur? Nein, nicht gehört.
Durch die Verwaltung von Docker-Images, Kubernetes und Anwendungen wird es portabel. Nachdem Sie Containeranwendungen mit Kubernetes entwickelt haben, können Sie sie überall bereitstellen: in einer offenen Cloud, lokal oder in einer Hybridumgebung - ohne den Code zu ändern.
Wir lieben Kubernetes wegen Skalierbarkeit, Portabilität und Verwaltbarkeit, aber es speichert keinen Status. Wir haben jedoch fast alle Stateful-Anwendungen, dh sie benötigen externen Speicher.
Kubernetes hat eine sehr dynamische Architektur. Container werden abhängig von der Last und den Anweisungen der Entwickler erstellt und zerstört. Hülsen und Behälter sind selbstheilend und replizieren sich. Sie sind im Wesentlichen kurzlebig.
Die externe Speicherung ist für eine solche Variabilität zu schwierig. Es gehorcht nicht den Regeln der dynamischen Schöpfung und Zerstörung.
Sie müssen lediglich eine Stateful-Anwendung in einer anderen Infrastruktur bereitstellen: in einer anderen Cloud dort, lokal oder in einem Hybridmodell - wie es Portabilitätsprobleme gibt. Externer Speicher kann an eine bestimmte Cloud gebunden werden.
Aber nur in diesen Speichern für Cloud-Anwendungen wird sich der Teufel selbst das Bein brechen. Und verstehen Sie die fiktiven Bedeutungen und Bedeutungen der Speicherterminologie in Kubernetes . Und es gibt Kubernetes eigene Repositories, Open Source-Plattformen, verwaltete oder kostenpflichtige Dienste ...
Hier einige Beispiele für CNCF-Cloud-Speicher :

Es scheint, dass Sie die Datenbank in Kubernetes bereitstellen - Sie müssen nur die entsprechende Lösung auswählen, sie in einen Container packen, um auf der lokalen Festplatte zu arbeiten, und sie als nächste Arbeitslast im Cluster bereitstellen. Aber die Datenbank hat ihre eigenen Besonderheiten, so dass Denken kein Eis ist.
Container - sie sind so zusammengeschustert, dass sie ihren Zustand nicht bewahren. Deshalb sind sie so einfach zu starten und zu stoppen. Und da nichts gespeichert und übertragen werden muss, kümmert sich der Cluster nicht um Lese- und Kopiervorgänge.
Sie müssen den Status in der Datenbank speichern. Wenn eine Datenbank, die in einem Cluster in einem Container bereitgestellt wird, nirgendwo migriert und nicht zu oft gestartet wird, kommt die Datenspeicherphysik ins Spiel. Im Idealfall sollten sich Container, die Daten verwenden, im selben Herd wie die Datenbank befinden.
In einigen Fällen kann die Datenbank natürlich in einem Container bereitgestellt werden. In einer Testumgebung oder bei Aufgaben mit wenig Daten leben Datenbanken bequem in Clustern.
Die Produktion erfordert normalerweise eine externe Lagerung.
Kubernetes kommuniziert mit dem Repository über Schnittstellen der Steuerebene. Sie verbinden Kubernetes mit externem Speicher. An Kubernetes angeschlossener externer Speicher wird als Volume-Plugins bezeichnet. Mit ihnen können Sie Speicher abstrahieren und Speicher übertragen.
Volume-Plugins wurden früher mithilfe der Kubernetes-Codebasis erstellt , verknüpft, kompiliert und bereitgestellt. Dies hat die Entwickler stark eingeschränkt und erfordert zusätzliche Wartung: Wenn Sie neue Repositorys hinzufügen möchten, ändern Sie bitte die Kubernetes-Codebasis.
Stellen Sie jetzt Volume-Plugins für den Cluster bereit - das möchte ich nicht. Und Sie müssen sich nicht in die Codebasis vertiefen. Dank CSI und Flexvolume.
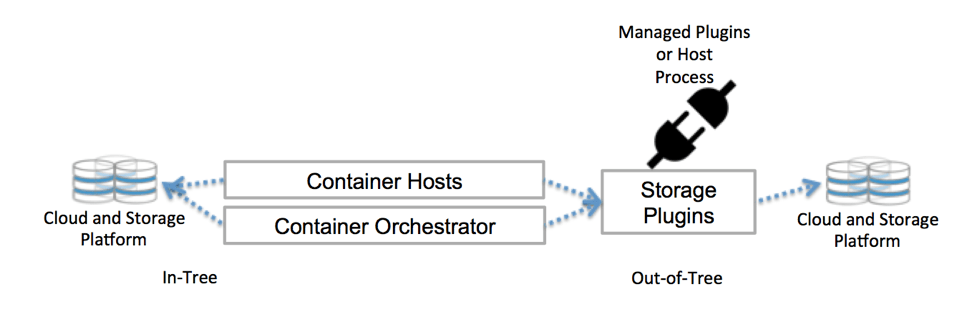
Kubernetes Native Storage
Wie löst Kubernetes Speicherprobleme? Es gibt verschiedene Lösungen: kurzlebige Optionen, persistenter Speicher in persistenten Volumes, Abfragen von persistenten Volume-Ansprüchen, Speicherklassen oder StatefulSets. Finde es im Allgemeinen heraus.
Persistent Volumes (PV) sind vom Administrator vorbereitete Speichereinheiten. Sie sind nicht abhängig von Herden und ihrem flüchtigen Leben.
Persistent Volume Claim (PVC) sind Speicheranforderungen, d. H. PV. Mit PVC können Sie Speicher an einen Knoten binden, und dieser Knoten verwendet ihn.
Sie können statisch oder dynamisch mit Speicher arbeiten.
Bei einem statischen Ansatz bereitet der Administrator PVs vor, die vor Anforderungen bereitgestellt werden sollen, und diese PVs werden mithilfe expliziter PVCs manuell an bestimmte Pods gebunden.
In der Praxis sind speziell definierte PVs nicht mit der tragbaren Struktur von Kubernetes kompatibel. Die Speicherung hängt von der Umgebung ab, z. B. AWS EBS oder ein permanentes GCE-Laufwerk. Um manuell zu binden, müssen Sie auf ein bestimmtes Repository in der YAML-Datei verweisen.
Der statische Ansatz widerspricht im Allgemeinen der Kubernetes-Philosophie: CPUs und Speicher werden nicht im Voraus zugewiesen und sind nicht an Pods oder Container gebunden. Sie werden dynamisch ausgegeben.
Für die dynamische Bereitstellung verwenden wir Speicherklassen. Der Clusteradministrator muss die PV nicht im Voraus erstellen. Es werden mehrere Speicherprofile wie Vorlagen erstellt. Wenn ein Entwickler eine PVC-Anfrage stellt, wird zum Zeitpunkt der Anfrage eines dieser Muster erstellt und an den Herd angehängt.

Im Allgemeinen arbeitet Kubernetes also mit externem Speicher. Es gibt viele andere Möglichkeiten.
CSI - Container Storage Interface
Es gibt so etwas - Container Storage Interface . CSI wurde von der CNCF-Tresor-Arbeitsgruppe erstellt, die beschlossen hat, eine Standard-Container-Speicherschnittstelle zu definieren, damit die Tresortreiber mit jedem Orchester arbeiten können.
Die CSI-Spezifikationen sind bereits für Kubernetes angepasst, und es gibt unzählige Treiber-Plugins für Bereitstellungen im Kubernetes-Cluster. Sie müssen über einen CSI-kompatiblen Volume-Treiber auf das Repository zugreifen. Verwenden Sie den Csi- Volume- Typ in Kubernetes.
Mit CSI kann Speicher als eine weitere Arbeitslast für die Containerisierung und Bereitstellung im Kubernetes-Cluster betrachtet werden.
Für weitere Informationen hören Sie, wie Jie Yu in unserem Podcast über CSI spricht .
Open Source Projekte
Tools und Projekte für Cloud-Technologien vermehren sich schnell, und ein angemessener Anteil von Open Source-Projekten - was logisch ist - löst eines der Hauptproduktionsprobleme: die Arbeit mit Speicher in der Cloud-Architektur.
Die beliebtesten von ihnen sind Ceph und Rook.
Ceph ist ein dynamisch verwalteter, verteilter Speichercluster mit horizontaler Skalierung. Ceph bietet eine logische Abstraktion für Speicherressourcen. Es hat keinen einzigen Fehlerpunkt, es verwaltet sich selbst und arbeitet auf der Basis von Software. Ceph bietet Schnittstellen zum gleichzeitigen Speichern von Blöcken, Objekten und Dateien für einen einzelnen Speichercluster.
Ceph hat eine sehr komplexe Architektur mit RADOS-, Librados-, RADOSGW-, RDB-, CRUSH-Algorithmus und verschiedenen Komponenten (Monitore, OSD, MDS). Lassen Sie uns nicht näher auf die Architektur eingehen. Es reicht zu verstehen, dass Ceph ein verteilter Speichercluster ist, der die Skalierbarkeit vereinfacht, einen einzelnen Fehlerpunkt ohne Leistungseinbußen beseitigt und einen einzelnen Speicher mit Zugriff auf Objekte, Blöcke und Dateien bereitstellt.
Natürlich ist Ceph für die Cloud angepasst. Sie können einen Ceph-Cluster auf verschiedene Arten bereitstellen, z. B. mithilfe von Ansible oder über CSI und PVC in einem Kubernetes-Cluster.
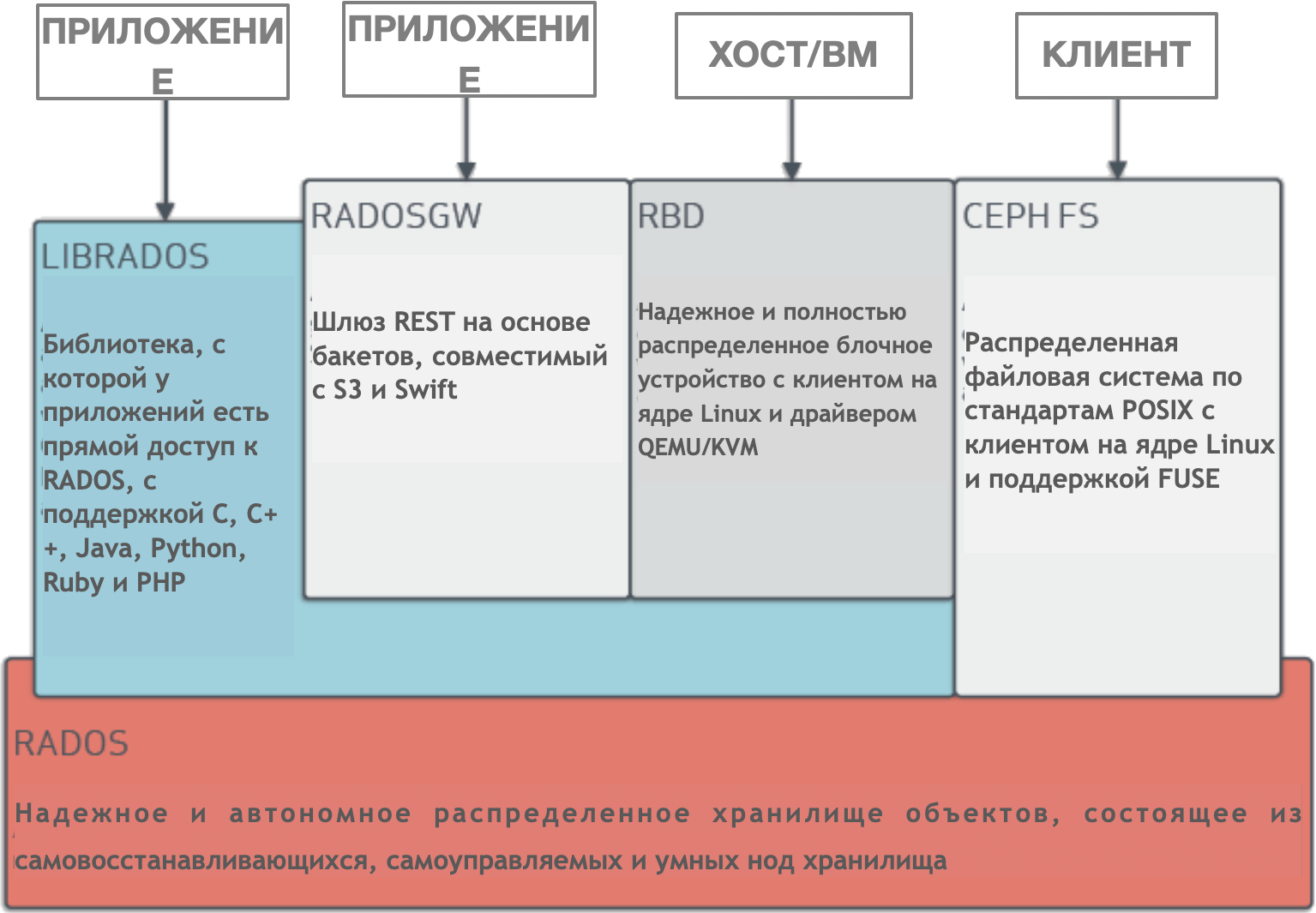
Ceph Architektur
Rook ist ein weiteres interessantes und beliebtes Projekt. Es kombiniert Kubernetes mit seinem Computing und Ceph mit seinen Repositorys in einem Cluster.
Rook ist ein Cloud-Speicher-Orchestrator, der Kubernetes ergänzt. Sie packen Ceph damit in Container und verwenden die Cluster-Management-Logik für den zuverlässigen Betrieb von Ceph in Kubernetes. Rook automatisiert Bereitstellung, Bootstrap, Optimierung, Skalierung und Neuausrichtung - im Allgemeinen alles, was der Cluster-Administrator tut.
Mit Rook kann ein Ceph-Cluster wie Kubernetes von yaml aus bereitgestellt werden. In dieser Datei beschreibt der Administrator, was er im Cluster benötigt. Rook startet einen Cluster und beginnt aktiv zu überwachen. Dies ist so etwas wie ein Bediener oder eine Steuerung - es stellt sicher, dass alle Anforderungen von yaml erfüllt werden. Rook arbeitet mit Synchronisationszyklen - es sieht den Zustand und ergreift Maßnahmen, wenn es Abweichungen gibt.
Er hat keinen dauerhaften Zustand und muss nicht kontrolliert werden. Es ist im Geiste von Kubernetes.
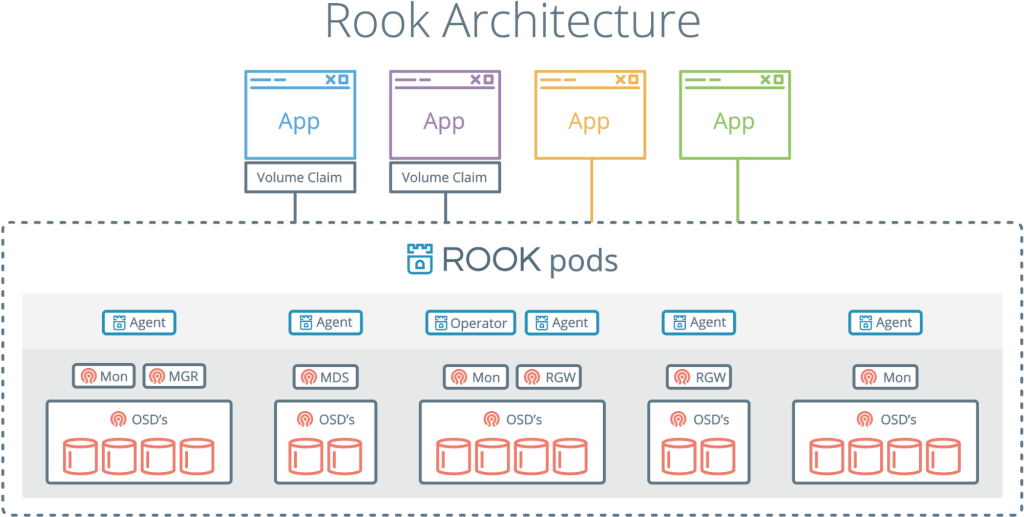
Rook kombiniert Ceph und Kubernetes und ist eine der beliebtesten Cloud-Speicherlösungen: 4.000 Sterne auf Github, 16,3 Millionen Downloads und mehr als hundert Mitwirkende.
Das Rook-Projekt wurde bereits bei CNCF angenommen und landete kürzlich in einem Inkubator .
Bassam Tabara wird Ihnen in unserer Kubernetes-Repository-Episode mehr über Rook erzählen.
Wenn die Anwendung ein Problem hat, müssen Sie die Anforderungen herausfinden und ein System erstellen oder die erforderlichen Tools verwenden. Dies gilt auch für Cloud-Speicher. Und obwohl das Problem nicht von einfachen ist, sind die Werkzeuge und Ansätze zu kurz gekommen. Die Cloud-Technologie entwickelt sich weiter und neue Lösungen werden uns sicherlich erwarten.