Vor kurzem habe ich aus Gründen der Notwendigkeit alle offenen Stellen für Go-Entwickler durchgesehen, und die Hälfte von ihnen erwähnt (zumindest) die
Apache Kafka- Nachrichtenverarbeitungsplattform und die
Redis NoSQL-Datenbank. Natürlich möchte jeder, dass der Kandidat Docker und andere wie ihn kennt. All diese Anforderungen erscheinen uns, die wir die Ansichten der Systemingenieure gesehen haben, irgendwie kleinlich oder so. Wie unterscheidet sich eine Zeile von einer anderen? Die Situation mit NoSQL-Datenbanken ist natürlich vielfältiger, aber sie scheinen immer noch einfacher zu sein als jeder MS SQL Server. All dies ist natürlich mein persönlicher, der
Mahn-Krüger-Effekt , der auf dem Habré oft erwähnt wurde.
Da alle Arbeitgeber dies verlangen, ist es notwendig, diese Technologien zu studieren. Es ist jedoch nicht sehr interessant, die gesamte Dokumentation von Anfang bis Ende zu lesen. Meiner Meinung nach ist es produktiver, die Einführung zu lesen, einen funktionierenden Prototyp zu erstellen, Fehler zu beheben, auf Probleme zu stoßen und diese zu lösen. Und nach all dem lesen Sie mit Verständnis die Dokumentation oder sogar ein separates Buch.

Wenn Sie sich in kurzer Zeit mit den grundlegenden Funktionen dieser Produkte vertraut machen möchten, lesen Sie bitte weiter.
Das Trainingsprogramm berücksichtigt die Zahlen. Es besteht aus einem großen Zahlengenerator, einem Zahlenprozessor, einer Warteschlange, einem Spaltenspeicher und einem Webserver.
Während der Entwicklung werden die folgenden Entwurfsmuster angewendet:
Die Systemarchitektur sieht folgendermaßen aus:
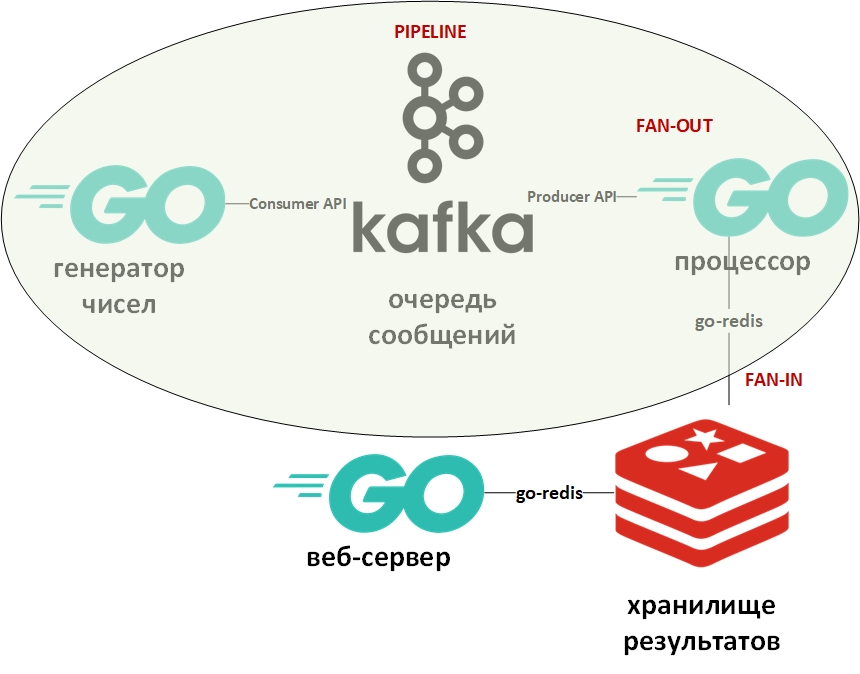
In der Abbildung zeigt das Oval das Muster des Fördererdesigns an. Ich werde näher darauf eingehen.
Die Vorlage "Förderer" geht davon aus, dass die Informationen in Form eines Streams vorliegen und schrittweise verarbeitet werden. Normalerweise gibt es einen Generator (Informationsquelle) und einen oder mehrere Prozessoren (Informationsprozessoren). In diesem Fall ist der Generator ein Go-Programm, das zufällige große Zahlen in die Warteschlange stellt. Und der Prozessor (der einzige) wird ein Programm sein, das Daten aus der Warteschlange entnimmt und die Faktorisierung durchführt. Bei Pure Go ist dieses Muster mithilfe von Kanälen (Chan) recht einfach zu implementieren. Oben gibt es einen Link zu meinem Github mit einem Beispiel. Hier spielt die Nachrichtenwarteschlange die Rolle von Kanälen.
Fan-In - Fan-Out-Vorlagen werden normalerweise zusammen verwendet und bedeuten, wie auf Go angewendet, die Parallelisierung von Berechnungen mithilfe von Goroutinen. Anschließend werden die Ergebnisse zusammengefasst und beispielsweise in die Pipeline übertragen. Ein Link zu einem Beispiel ist ebenfalls oben angegeben. Wieder wurde der Kanal durch die Warteschlange ersetzt, die Goroutinen blieben an Ort und Stelle.
Nun ein paar Worte zu Apache Kafka. Kafka ist ein Nachrichtenverwaltungssystem, das über hervorragende Clustering-Tools verfügt, ein Transaktionsprotokoll (genau wie in einem RDBMS) zum Speichern von Nachrichten verwendet und sowohl das Warteschlangenmodell als auch das Herausgeber- / Abonnentenmodell unterstützt. Letzteres wird durch Gruppen von Nachrichtenempfängern erreicht. Jede Nachricht empfängt nur ein Mitglied der Gruppe (Parallelverarbeitung), die Nachricht wird jedoch einmal an jede Gruppe übermittelt. Innerhalb jeder Gruppe kann es viele solcher Gruppen sowie Empfänger geben.
Um mit Kafka zu arbeiten, werde ich das Paket "github.com/segmentio/kafka-go" verwenden.
Redis hingegen ist eine Schlüsselwert-Spaltendatenbank im Speicher, die die Möglichkeit unterstützt, Daten dauerhaft zu speichern. Der Hauptdatentyp für Schlüssel und Werte sind Zeichenfolgen, es gibt jedoch einige andere. Redis gilt als eine der schnellsten (oder meisten) Datenbanken seiner Klasse. Es ist gut, alle Arten von Statistiken, Metriken, Nachrichtenflüssen usw. zu speichern.
Um mit Redis zu arbeiten, werde ich das Paket "github.com/go-redis/redis" verwenden.
Da dieser Artikel ein schneller Einstieg ist, werden wir beide Systeme mithilfe von Docker mithilfe von vorgefertigten Images von DockerHub bereitstellen. Ich verwende Docker-Compose unter Windows 10 im Containermodus auf einer Linux-VM (automatisch von der Docker-VM erstellt) mit dieser Datei docker-compose.yml wie folgt:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
Speichern Sie diese Datei, gehen Sie in das Verzeichnis und führen Sie Folgendes aus:
docker-compose up -d
Drei Container sollten heruntergeladen und gestartet werden: Kafka (Warteschlange), Zookeeper (Konfigurationsserver für Kafka) und (Redis).
Sie können mit dem folgenden Befehl überprüfen, ob die Container funktionieren:
docker-compose ps
Es sollte so etwas sein wie:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
Laut der yml-Datei sollten automatisch drei Warteschlangen erstellt werden, die Sie mit dem Befehl sehen können:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
Es sollten Warteschlangen (Themen - Themen in Bezug auf Kafka) generiert, gelöst und ungelöst sein.
Der Datengenerator stellt Zahlen mit einer zufälligen Verzögerung unendlich in die Warteschlange. Der Code ist sehr einfach. Sie können das Vorhandensein von Nachrichten in der generierten Warteschlange mit dem folgenden Befehl überprüfen:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
Als nächstes kommt der
Prozessor - hier sollten Sie darauf achten, die Verarbeitung von Werten aus der Warteschlange im folgenden Codeblock zu parallelisieren:
var wg sync.WaitGroup c := 0
Da das Lesen aus der Nachrichtenwarteschlange das Programm blockiert, habe ich ein context.Context-Objekt mit einer Zeitüberschreitung von 15 Sekunden erstellt. Dieses Zeitlimit beendet das Programm, wenn die Warteschlange längere Zeit leer ist.
Außerdem wird für jedes Gorutin, das die Anzahl faktorisiert, die maximale Betriebszeit festgelegt. Ich wollte, dass die Zahlen, die berücksichtigt werden konnten, in eine Datenbank geschrieben werden. Und die Zahlen, die in der zugewiesenen Zeit nicht berücksichtigt werden konnten, wurden in eine andere Datenbank übertragen.
Zur Bestimmung der ungefähren Zeit wurde der Benchmark verwendet:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Benchmarks in Go sind verschiedene Tests und werden in einer Datei mit Tests abgelegt. Basierend auf dieser Messung wurde die maximale Anzahl für den Zufallszahlengenerator ausgewählt. Auf meinem Computer hatte ein Teil der Zahlen Zeit zum Herausrechnen und ein Teil - nicht.
Die Zahlen, die zerlegt werden konnten, wurden in DB Nr. 0 geschrieben, nicht zerlegte Zahlen in DB Nr. 1.
Hier muss ich sagen, dass es in Redis keine Tische und Tische im klassischen Sinne gibt. Standardmäßig enthält das DBMS 16 Datenbanken, die dem Programmierer zur Verfügung stehen. Diese Basen unterscheiden sich in ihrer Anzahl - von 0 bis 15.
Das Zeitlimit für Goroutinen im Prozessor wurde unter Verwendung des Kontexts und der select-Anweisung angegeben:
Dies ist ein weiterer typischer Entwicklungstrick auf Go. Dies bedeutet, dass die select-Anweisung über die Kanäle iteriert und den Code ausführt, der dem ersten aktiven Kanal entspricht. In diesem Fall gibt entweder die Goroutine das Ergebnis an ihren Kanal aus oder der Kontextkanal mit einer Zeitüberschreitung wird geschlossen. Anstelle des Kontexts können Sie einen beliebigen Kanal verwenden, der als Manager fungiert und die erzwungene Beendigung von Goroutinen ermöglicht.
Die Unterprogramme zum Schreiben in die Datenbank führen den Befehl aus, um die gewünschte Datenbank (0 oder 1) auszuwählen und Paare der Form (Zahlenfaktoren) für analysierte Zahlen oder (Zahlennummern) für nicht zerlegte Zahlen zu schreiben.
func storeSolved(item data) (err error) {
Der letzte Teil wird ein
Webserver sein , der eine Liste zerlegter und nicht zerlegter Zahlen in Form von json anzeigt. Er wird zwei Endpunkte haben:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
Der http-Anforderungshandler, der Daten von Redis empfängt und als json zurückgibt, sieht folgendermaßen aus:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
Das Ergebnis der Anfrage unter:
localhost / gelöst [{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
Jetzt können Sie in die Dokumentation und Fachliteratur eintauchen. Hoffe der Artikel war hilfreich.
Ich bitte die Experten, nicht zu faul zu sein und auf meine Fehler hinzuweisen.