„Im Trace-Modus sieht der Programmierer in diesem Schritt der Programmausführung die Reihenfolge der Befehlsausführung und die Werte der Variablen, wodurch Fehler leichter erkannt werden können“, sagt Wikipedia. Als Linux-Fans stoßen wir regelmäßig auf die Frage, welche spezifischen Tools am besten für die Implementierung geeignet sind. Und wir möchten die Übersetzung eines Artikels des Programmierers Hongley Lai teilen, der bpftrace empfiehlt. Mit Blick auf die Zukunft werde ich sagen, dass der Artikel kurz und bündig endet: "bpftrace ist die Zukunft". Warum hat er Lais Kollegen so beeindruckt? Eine ausführliche Antwort unter dem Schnitt.
Unter Linux gibt es zwei Haupt-Trace-Tools:
Mit strace können Sie sehen, welche Systemaufrufe getätigt werden.
Mit ltrace können Sie sehen, welche dynamischen Bibliotheken aufgerufen werden.
Trotz ihrer Nützlichkeit sind diese Werkzeuge begrenzt. Und wenn Sie herausfinden möchten, was in einem System- oder Bibliotheksaufruf passiert? Und wenn Sie nicht nur eine Liste von Anrufen erstellen, sondern beispielsweise auch Statistiken zu bestimmten Verhaltensweisen sammeln müssen? Und wenn Sie mehrere Prozesse verfolgen und Daten aus mehreren Quellen vergleichen müssen?
Im Jahr 2019 haben wir endlich eine anständige Antwort auf diese Fragen unter Linux erhalten:
bpftrace basierend auf
eBPF- Technologie. Mit Bpftrace können Sie kleine Programme schreiben, die jedes Mal ausgeführt werden, wenn ein Ereignis auftritt.
In diesem Artikel werde ich beschreiben, wie man bpftrace installiert und seine grundlegende Anwendung lehrt. Ich werde auch einen Überblick darüber geben, wie das Spuren-Ökosystem aussieht (zum Beispiel „Was ist eBPF?“) Und wie es sich zu dem entwickelt hat, was wir heute haben.
Was ist eine Spur?
Wie bereits erwähnt, können Sie mit bpftrace kleine Programme schreiben, die jedes Mal ausgeführt werden, wenn ein Ereignis auftritt.
Was ist eine Veranstaltung? Es kann sich um einen Systemaufruf, einen Funktionsaufruf oder sogar um etwas handeln, das in solchen Anforderungen geschieht. Es kann sich auch um einen Timer oder ein Hardware-Ereignis handeln, z. B. "50 ms sind seit dem letzten der gleichen Ereignisse vergangen", "Seitenfehler aufgetreten", "Kontextwechsel aufgetreten" oder "Cashe-Miss-Prozessor aufgetreten".
Was kann als Reaktion auf ein Ereignis getan werden? Sie können etwas verpfänden, Statistiken sammeln und beliebige Shell-Befehle ausführen. Sie haben Zugriff auf verschiedene Kontextinformationen wie die aktuelle PID, die Stapelverfolgung, die Zeit, Aufrufargumente, Rückgabewerte usw.
Wann verwenden? In vielen. Sie können herausfinden, warum die Anwendung langsam ist, indem Sie eine Liste der langsamsten Aufrufe zusammenstellen. Sie können feststellen, ob und wo Speicherlecks in der Anwendung vorhanden sind. Ich benutze es, um zu verstehen, warum Ruby so viel Speicher verwendet.
Das große Plus von bpftrace ist, dass Sie die Anwendung nicht neu kompilieren müssen. Es ist nicht erforderlich, Druckaufrufe oder anderen Debugging-Code manuell in die Quellen der untersuchten Anwendung zu schreiben. Es ist nicht einmal erforderlich, Anwendungen neu zu starten. Und das alles mit sehr geringem Overhead. Dies macht bpftrace besonders nützlich für das Debuggen von Systemen direkt auf dem Produkt oder in einer anderen Situation, in der es Schwierigkeiten bei der Neukompilierung gibt.
DTrace: Vater der Spur
Das beste Tracing-Tool war lange Zeit
DTrace , ein vollständiges dynamisches Tracing-Framework, das ursprünglich von Sun Microsystems (den Herstellern von Java) entwickelt wurde. Wie bei bpftrace können Sie mit DTrace kleine Programme schreiben, die als Reaktion auf Ereignisse ausgeführt werden. Tatsächlich werden viele der Schlüsselelemente des Ökosystems größtenteils von
Brendan Gregg entwickelt , einem renommierten DTrace-Experten, der derzeit bei Netflix arbeitet. Das erklärt die Ähnlichkeiten zwischen DTrace und bpftrace.
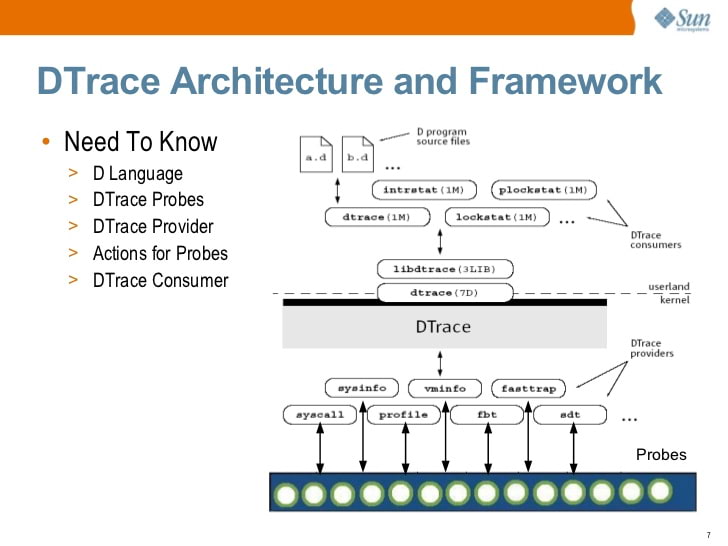 Einführung von Solaris DTrace (2009) von S. Tripathi, Sun Microsystems
Einführung von Solaris DTrace (2009) von S. Tripathi, Sun MicrosystemsIrgendwann öffnete Sun die Quelle für DTrace. Heute ist DTrace unter Solaris, FreeBSD und macOS verfügbar (obwohl die macOS-Version im Allgemeinen nicht funktionsfähig ist, da der System Integrity Protection, SIP, gegen viele der Prinzipien verstoßen hat, nach denen DTrace ausgeführt wird).
Ja, Sie haben richtig bemerkt ... Linux ist nicht in dieser Liste. Dies ist kein technisches Problem, sondern ein Lizenzproblem. DTrace wurde unter der CDDL anstelle der GPL geöffnet.
Der Linux DTrace-Port ist seit 2011 verfügbar, wurde jedoch von großen Linux-Entwicklern nie unterstützt. Anfang 2018 eröffnete
Oracle DTrace unter der GPL wieder , aber zu diesem Zeitpunkt war es bereits zu spät.
Linux-Tracing-Ökosystem
Zweifellos ist die Ablaufverfolgung sehr nützlich, und die Linux-Community hat versucht, eigene Lösungen für dieses Thema zu entwickeln. Im Gegensatz zu Solaris wird Linux jedoch nicht von einem bestimmten Anbieter reguliert, und daher wurden keine absichtlichen Anstrengungen unternommen, um einen voll funktionsfähigen Ersatz für DTrace zu entwickeln. Das Linux-Trace-Ökosystem hat sich langsam und natürlich entwickelt und auftretende Probleme gelöst. Und erst vor kurzem ist dieses Ökosystem so gewachsen, dass es ernsthaft mit DTrace konkurrieren kann.
Aufgrund des natürlichen Wachstums wirkt dieses Ökosystem möglicherweise etwas chaotisch und besteht aus vielen verschiedenen Komponenten. Glücklicherweise schrieb Julia Evans
eine Rezension dieses Ökosystems (Aufmerksamkeit, Veröffentlichungsdatum - 2017, vor dem Aufkommen von bpftrace).
 Linux-Trace-Ökosystem von Julia Evans beschrieben
Linux-Trace-Ökosystem von Julia Evans beschriebenNicht alle Elemente sind gleich wichtig. Lassen Sie mich kurz zusammenfassen, welche Elemente ich für am wichtigsten halte.
EreignisquellenEreignisdaten können entweder aus dem Kernel oder aus dem Benutzerbereich (Anwendungen und Bibliotheken) stammen. Einige von ihnen sind automatisch ohne zusätzlichen Entwickleraufwand verfügbar, während andere eine manuelle Ankündigung erfordern.
 Übersicht über die wichtigsten Quellen für verfolgte Ereignisse unter Linux
Übersicht über die wichtigsten Quellen für verfolgte Ereignisse unter LinuxAuf der Kernelseite gibt es K-
Sonden (
von „Kernel-Sonden“, „Kernel-Sensor“, ca. Per. ) - ein Mechanismus, mit dem Sie jeden Funktionsaufruf im Kernel verfolgen können. Damit können Sie nicht nur die Systemaufrufe selbst verfolgen, sondern auch, was in ihnen geschieht (da die Einstiegspunkte von Systemaufrufen andere interne Funktionen aufrufen). Sie können kprobes auch verwenden, um Kernelereignisse zu verfolgen, bei denen es sich nicht um Systemaufrufe handelt, z. B. "Gepufferte Daten werden auf die Festplatte geschrieben", "TCP-Paket wird über das Netzwerk gesendet" oder "Kontextumschaltung wird ausgeführt".
Kernel-Tracepoints ermöglichen die Verfolgung von nicht standardmäßigen Ereignissen, die von Kernel-Entwicklern definiert wurden. Diese Ereignisse befinden sich nicht auf der Ebene von Funktionsaufrufen. Um solche Punkte zu erstellen, platzieren Kernelentwickler das Makro TRACE_EVENT manuell im Kernelcode.
Beide Quellen haben Vor- und Nachteile. Kprobes arbeitet "automatisch", weil Kernel-Entwickler müssen den Code nicht manuell codieren. Kprobe-Ereignisse können sich jedoch willkürlich von einer Version des Kernels zur anderen ändern, da sich die Funktionen ständig ändern - sie werden hinzugefügt, gelöscht und umbenannt.
Kernel-Trace-Punkte sind im Allgemeinen über die Zeit stabiler und bieten möglicherweise nützliche Kontextinformationen, die möglicherweise nicht verfügbar sind, wenn kprobes verwendet wird. Mit kprobes können Sie auf Funktionsaufrufargumente zugreifen. Mithilfe von Ablaufverfolgungspunkten können Sie jedoch alle Informationen abrufen, die der Kernelentwickler manuell beschreiben möchte.
Im Benutzerraum gibt es ein Analogon von kprobes - uprobes. Es wurde entwickelt, um Funktionsaufrufe im Benutzerbereich zu verfolgen.
Die USDT-Sensoren („Statisch definierte User Space-Traces“) sind ein Analogon zu Kernel-Trace-Punkten im User Space. Anwendungsentwickler müssen ihrem Code manuell USDT-Sensoren hinzufügen.
Interessante Tatsache: DTrace bietet seit langem die C-API zur Definition eines eigenen Analogons von USDT-Sensoren (mithilfe des Makros DTRACE_PROBE). Entwickler von Trace-Ökosystemen unter Linux haben beschlossen, den Quellcode mit dieser API kompatibel zu lassen, sodass alle DTRACE_PROBE-Makros automatisch in USDT-Sensoren konvertiert werden!
Daher kann theoretisch strace unter Verwendung von kprobes implementiert werden, und ltrace kann unter Verwendung von uprobes implementiert werden. Ich bin mir nicht sicher, ob dies bereits praktiziert wird oder nicht.
SchnittstellenSchnittstellen sind Anwendungen, mit denen Benutzer Ereignisquellen einfach verwenden können.
Schauen wir uns an, wie Ereignisquellen funktionieren. Der Workflow ist wie folgt:
- Der Kernel stellt einen Mechanismus dar - normalerweise eine / proc- oder / sys-Datei, die zum Schreiben geöffnet ist -, der sowohl die Absicht aufzeichnet, das Ereignis zu verfolgen, als auch, was dem Ereignis folgen soll.
- Nach der Registrierung lokalisiert der Kernel den Kernel / die Funktion im User Space / Trace Points / USDT-Sensoren im Speicher und ändert ihren Code, sodass etwas anderes passiert.
- Das Ergebnis dieses „etwas anderen“ kann später mithilfe eines Mechanismus erfasst werden.
Ich würde das alles nicht manuell machen wollen! Daher helfen Schnittstellen: Sie erledigen das alles für Sie.
Es gibt Schnittstellen für jeden Geschmack und jede Farbe. Im Bereich der
eBPF-basierten Schnittstellen gibt es Low-Level-
Schnittstellen, die ein tiefes Verständnis der Interaktion mit Ereignisquellen und der Funktionsweise des eBPF-Bytecodes erfordern. Und es gibt hochrangige und einfach zu bedienende, obwohl sie während ihrer Existenz keine große Flexibilität zeigten.
Deshalb ist bpftrace - das neueste Interface - mein Favorit. Es ist benutzerfreundlich und flexibel wie DTrace. Aber es ist ziemlich neu und muss poliert werden.
eBPF
eBPF ist der
neue Linux-Trace-Star, auf dem bpftrace basiert. Wenn Sie ein Ereignis verfolgen, möchten Sie, dass im Kernel etwas passiert. Wie flexibel kann man feststellen, was dieses "Etwas" ist? Natürlich mit einer Programmiersprache (oder mit Maschinencode).
eBPF (erweiterte Version des Berkeley Packet Filters). Dies ist eine virtuelle Hochleistungsmaschine, die im Kernel ausgeführt wird und die folgenden Eigenschaften / Einschränkungen aufweist:
- Alle Benutzerbereichsinteraktionen erfolgen über eBPF-Karten, bei denen es sich um Schlüsselwertspeicher handelt.
- Es gibt keine Zyklen, sodass jedes eBPF-Programm zu einem bestimmten Zeitpunkt beendet wird.
- Warten Sie, wir sagten Batch Filter? Sie haben Recht: Sie wurden ursprünglich zum Filtern von Netzwerkpaketen entwickelt. Dies ist eine ähnliche Aufgabe: Wenn Sie Pakete weiterleiten (das Auftreten eines Ereignisses), müssen Sie eine Verwaltungsaktion ausführen (ein Paket akzeptieren, verwerfen, protokollieren oder umleiten usw.). Eine virtuelle Maschine wurde erfunden, um solche Aktionen zu beschleunigen (mit JIT-Funktion). Zusammenstellung). Eine "erweiterte" Version wird in Betracht gezogen, da eBPF im Vergleich zur Originalversion des Berkeley-Paketfilters außerhalb des Netzwerkkontexts verwendet werden kann.
So. Mit bpftrace können Sie festlegen, welche Ereignisse verfolgt werden sollen und was als Reaktion darauf geschehen soll. Bpftrace kompiliert Ihr übergeordnetes bpftrace-Programm in eBPF-Bytecode, verfolgt Ereignisse und lädt den Bytecode in den Kernel.
Dunkle Tage vor eBPF
Vor eBPF waren Lösungsoptionen, gelinde gesagt, umständlich.
SystemTap ist ein bisschen der "ernsteste" Vorgänger von bpftrace in der Linux-Familie. SystemTap-Skripte werden in die Sprache C übersetzt und als Module in den Kernel geladen. Das resultierende Kernelmodul wird dann geladen.
Dieser Ansatz war außerhalb von Red Hat Enterprise Linux sehr fragil und wurde nur unzureichend unterstützt. Für mich hat es unter Ubuntu nie gut funktioniert, was dazu führte, dass SystemTap bei jedem Kernel-Update aufgrund einer Änderung der Kernel-Datenstruktur beschädigt wurde. Es wird auch gesagt, dass SystemTap in den frühen Tagen seiner Existenz
leicht zu Kernel-Panik führte .
Bpftrace-Installation
Es ist Zeit, die Ärmel hochzukrempeln! In diesem Handbuch werden wir uns mit der Installation von bpftrace unter Ubuntu 18.04 befassen. Neuere Versionen der Distribution sind unerwünscht, weil Während der Installation benötigen wir Pakete, die noch nicht für sie kompiliert wurden.
AbhängigkeitsinstallationInstallieren Sie zunächst Clang 5.0, lbclang 5.0 und LLVM 5.0, einschließlich aller Header-Dateien. Wir werden die von llvm.org bereitgestellten Pakete verwenden, da die in den Ubuntu-Repositorys
problematisch sind .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
Weiter:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
Und schließlich installieren Sie libbfcc-dev vom Upstream, nicht vom Ubuntu-Repository. Das Paket in Ubuntu enthält
keine Header-Dateien . Und dieses Problem wurde auch um 18.10 Uhr nicht gelöst.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Bpftrace HauptinstallationEs ist Zeit, bpftrace selbst von der Quelle zu installieren! Lassen Sie es uns klonen, zusammenbauen und in / usr / local installieren:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
Und du bist fertig! Die ausführbare Datei wird in / usr / local / bin / bpftrace installiert. Sie können das Ziel mit dem Argument cmake ändern, das standardmäßig folgendermaßen aussieht:
DCMAKE_INSTALL_PREFIX=/usr/local.
Einzeilige BeispieleLassen Sie uns ein paar bpftrace-Single-Liner ausführen, um unsere Fähigkeiten zu verstehen. Ich habe diese aus
Brendan Greggs Führer genommen , der eine detaillierte Beschreibung von jedem von ihnen enthält.
# 1. Zeigen Sie eine Liste der Sensoren an
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2. Grüße
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3. Eine Datei öffnen
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4. Die Anzahl der Systemaufrufe pro Prozess
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5. Verteilung der read () -Aufrufe nach Anzahl der Bytes
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6. Dynamische Verfolgung von read () - Inhalten
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7. Zeitaufwand für read () -Aufrufe
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8. Ereignisse auf Prozessebene zählen
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9. Profiling Kernel Working Stacks
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. Trace-Planer
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11. Trace Blocking I / O.
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
Besuchen Sie die Website von Brendan Gregg, um herauszufinden,
welche Art von Output die oben genannten Teams generieren können .
Beispiel für Skriptsyntax und E / A-TimingDie Zeichenfolge, die über den Schalter '-e' übergeben wird, ist der Inhalt des bpftrace-Skripts. Die Syntax ist in diesem Fall bedingt eine Reihe von Konstruktionen:
<event source> /<optional filter>/ { <program body> }
Schauen wir uns das siebte Beispiel über die Zeitabläufe von Dateisystem-Lesevorgängen an:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
Wir verfolgen das Ereignis vom
kprobe- Mechanismus, d. H. Wir verfolgen den Beginn der Kernelfunktion.
Die Kernelfunktion für die Ablaufverfolgung lautet
vfs_read . Diese Funktion wird aufgerufen, wenn der Kernel eine Leseoperation aus dem Dateisystem ausführt (VFS aus „Virtual FileSystem“, Abstraktion des Dateisystems im Kernel).
Wenn die
Ausführung von vfs_read beginnt (d. H. Bevor die Funktion nützliche Arbeit geleistet hat), wird das Programm bpftrace gestartet. Es speichert den aktuellen Zeitstempel (in Nanosekunden) in einem globalen assoziativen Array namens
st art . Der Schlüssel ist
tid , ein Verweis auf die aktuelle Thread-ID.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1. Wir verfolgen das Ereignis vom
kretprobe- Mechanismus, der
kprobe ähnlich
ist , außer dass es aufgerufen wird, wenn die Funktion das Ergebnis ihrer Ausführung zurückgibt.
2. Die Kernelfunktion für die Ablaufverfolgung lautet
vfs_read .
3. Dies ist ein optionaler Filter. Es wird geprüft, ob die Startzeit zuvor aufgezeichnet wurde. Ohne diesen Filter kann das Programm beim Lesen gestartet werden und nur das Ende abfangen, was zu einer
geschätzten Zeit von
nsecs - 0 anstelle von
nsecs - start führt .
4. Der Hauptteil des Programms.
nsecs - st art [tid] berechnet, wie viel Zeit seit dem Start der Funktion vfs_read vergangen ist.
@ns [comm] = hist (...) fügt die angegebenen Daten dem in
@ns gespeicherten zweidimensionalen Histogramm
hinzu . Der
Kommunikationsschlüssel bezieht sich auf den Namen der aktuellen Anwendung. Wir werden also Befehl für Befehl ein Histogramm haben.
delete (...) löscht die Startzeit aus dem assoziativen Array, da wir sie nicht mehr benötigen.
Dies ist die endgültige Schlussfolgerung. Bitte beachten Sie, dass alle Histogramme automatisch angezeigt werden. Eine explizite Verwendung des Druckhistogrammbefehls ist nicht erforderlich.
@ns ist keine spezielle Variable, daher wird das Histogramm deswegen nicht angezeigt.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
Beispiel für einen USDT-SensorNehmen wir diesen C-Code und speichern ihn in der Datei
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
Dieses Programm wird endlos ausgeführt, indem
myclock () einmal pro Sekunde
aufgerufen wird .
myclock () fragt die aktuelle Uhrzeit ab und gibt die Anzahl der Sekunden seit Beginn der Ära zurück.
Der Aufruf von
DTRACE_PROBE1 definiert hier einen statischen USDT-
Tracepunkt .
- Das Makro DTRACE_PROBE1 stammt aus sys / sdt.h. Das offizielle USDT-Makro, das dasselbe tut, heißt STAP_PROBE1 (STAP von SystemTap, dem ersten in USDT unterstützten Linux-Mechanismus). Da USDT jedoch mit DTrace-Benutzerbereichssensoren kompatibel ist, ist DTRACE_PROBE1 nur eine Referenz auf STAP_PROBE1 .
- Der erste Parameter ist der Name des Anbieters. Ich glaube, dies ist ein Überbleibsel von DTrace, da bpftrace nichts Nützliches damit zu tun scheint. Es gibt jedoch eine Nuance ( die ich beim Debuggen des Problems auf Anforderung 328 entdeckt habe ): Der Anbietername muss mit dem Binärdateinamen der Anwendung identisch sein, andernfalls kann bpftrace den Tracepunkt nicht finden.
- Der zweite Parameter ist der Name des Trace-Punkts.
- Alle zusätzlichen Parameter sind der von den Entwicklern bereitgestellte Kontext. Die Nummer 1 in DTRACE_PROBE1 bedeutet, dass wir einen zusätzlichen Parameter übergeben möchten.
Stellen wir sicher, dass sys / sdt.h für uns verfügbar ist, und stellen Sie das Programm zusammen:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
Wir weisen bpftrace an, die PID auszugeben und "time is [number]", wenn die
Testsonde erreicht ist:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
Bpftrace funktioniert weiter, während wir Strg-C drücken. Öffnen Sie daher ein neues Terminal und führen
Sie dort den
Tracetest aus:
# Im neuen Terminal
./tracetest
Gehen Sie zurück zum ersten Terminal mit bpftrace, dort sollten Sie etwas sehen wie:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
Beispiel für eine Speicherzuordnung mit glibc ptmallocIch benutze bpftrace, um zu verstehen, warum Ruby so viel Speicher verwendet. Und im Rahmen meiner Forschung muss ich verstehen, wie der Speicherzuweiser von glibc Speicherbereiche verwendet.
Um die Multi-Core-Leistung zu optimieren, weist der glibc-Speicherzuweiser mehrere „Bereiche“ des Betriebssystems zu. Wenn die Anwendung nach einer Speicherzuweisung fragt, wählt der Zuweiser einen Bereich aus, der nicht verwendet wird, und markiert einen Teil dieses Bereichs als "verwendet". Da Threads unterschiedliche Bereiche verwenden, wird die Anzahl der Sperren verringert, was zu einer verbesserten Multithread-Leistung führt.
Dieser Ansatz erzeugt jedoch viel Müll, und es scheint, dass ein derart hoher Speicherverbrauch in Ruby genau darauf zurückzuführen ist. Um die Natur dieses Mülls besser zu verstehen, fragte ich mich: Was bedeutet es, „einen Bereich auszuwählen, der nicht genutzt wird“? Dies kann Folgendes bedeuten:
- Bei jedem Aufruf von malloc () durchläuft der Allokator alle Bereiche und findet den Bereich, der derzeit nicht gesperrt ist. Und nur wenn sie alle blockiert sind, wird er versuchen, eine neue zu erstellen.
- Wenn malloc () zum ersten Mal für einen bestimmten Thread aufgerufen wird (oder wenn der Thread gestartet wird), wählt der Allokator den Thread aus, der derzeit nicht blockiert ist. Und wenn sie alle blockiert sind, wird er versuchen, eine neue zu erstellen.
- Wenn malloc () zum ersten Mal für einen bestimmten Thread aufgerufen wird (oder wenn der Thread gestartet wird), versucht der Allokator, eine neue Region zu erstellen, unabhängig davon, ob nicht gesperrte Regionen vorhanden sind. Nur wenn kein neuer Bereich erstellt werden kann (z. B. wenn das Limit erschöpft ist), wird der vorhandene Bereich wiederverwendet.
- Es gibt wahrscheinlich mehr Optionen, die ich nicht in Betracht gezogen habe.
In der Dokumentation gibt es keine spezifische Antwort. Mit dieser Funktion können Sie einen Bereich auswählen, der nicht verwendet wird. Ich habe den Quellcode für glibc studiert, was darauf hindeutete, dass Option 3 dies tun könnte. Ich wollte jedoch experimentell überprüfen, ob ich den Quellcode richtig interpretiert habe, ohne dass Code in glibc debuggt werden muss.
Hier ist die Glibc-Speicherzuweisungsfunktion, die einen neuen Bereich erstellt. Sie können es jedoch erst nach Überprüfung des Limits aufrufen.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
Kann ich
Uprobes verwenden , um die Funktion
_int_new_arena zu verfolgen? Leider gibt es keine. Aus irgendeinem Grund ist dieses Symbol in glibc Ubuntu 18.04 nicht verfügbar. Auch nach der Installation von Debugging-Symbolen.
Glücklicherweise gibt es in dieser Funktion einen USDT-Sensor.
LIBC_PROBE ist ein
Makroalias für
STAP_PROBE .
Der Anbietername lautet libc.
Der Sensorname lautet memory_arena_new.
Die Zahl 2 bedeutet, dass vom Entwickler zwei zusätzliche Argumente angegeben wurden.
Arena ist die Adresse des Bereichs, der aus dem Betriebssystem extrahiert wurde, und Größe ist seine Größe.
Bevor wir diesen Sensor verwenden können, müssen wir das
Problem 328 umgehen . Wir müssen irgendwo mit dem Namen
libc eine symbolische Verknüpfung mit glibc erstellen, da bpftrace erwartet, dass der Bibliotheksname (der sonst
libc-2.27.so wäre ) mit dem Anbieternamen
(libc) identisch ist.
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
Jetzt weisen wir bpftrace an, sich an den USDT memory_arena_new-Sensor anzuschließen, dessen Herstellername
libc lautet:
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
In einem anderen Terminal führen wir Ruby aus, wodurch drei Threads erstellt werden, die nichts bewirken und in einer Sekunde enden. Aufgrund der globalen Blockierung des Interpreters sollte Ruby
malloc () nicht von verschiedenen Threads parallel aufgerufen werden.
ruby -e '3.times { Thread.new { } }; sleep 1'
Wenn wir mit bpftrace zum Terminal zurückkehren, werden wir sehen:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
Hier ist die Antwort auf unsere Frage! Jedes Mal, wenn Sie in Ruby einen neuen Thread erstellen, hebt glibc unabhängig von der Wettbewerbsfähigkeit einen neuen Bereich hervor.
Welche Tracepunkte sind verfügbar? Was soll ich verfolgen?Sie können alle Hardware-, Timer-, kprobe- und statischen Kernel-Tracepunkte auflisten, indem Sie den folgenden Befehl ausführen:
sudo bpftrace -l
Sie können alle Uprobe-Trace-Punkte (Funktionszeichen) einer Anwendung oder Bibliothek auflisten, indem Sie Folgendes tun:
nm /path-to-binary
Sie können alle Ablaufverfolgungspunkte der USDT-Anwendung oder -Bibliothek auflisten, indem Sie den folgenden Befehl ausführen:
/usr/share/bcc/tools/tplist -l /path-to/binary
In Bezug auf die zu verwendenden Ablaufverfolgungspunkte: Es würde nicht schaden, den Quellcode dessen zu verstehen, was Sie verfolgen werden. Ich empfehle Ihnen, den Quellcode zu studieren.
Tipp: Ein Strukturformat für Tracepunkte im KernelHier ist ein hilfreicher Tipp zu Kernel-Trace-Punkten. Sie können überprüfen, welche Argumentfelder verfügbar sind, indem Sie die Datei / sys / kernel / debug / tracing / events lesen!
Angenommen, Sie möchten Anrufe an
madvise (..., MADV_DONTNEED) verfolgen :
sudo bpftrace -l | grep madvise
- wird uns mitteilen, dass wir tracepoint verwenden können: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- gibt uns folgende Informationen:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Madvise-Signatur gemäß Handbuch:
(void * addr, size_t length, int Beratung) . Die letzten drei Felder dieser Struktur entsprechen diesen Parametern!
Was bedeutet MADV_DONTNEED? Nach grep MADV_DONTNEED / usr / include zu urteilen, entspricht dies 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
So wird unser bpftrace-Team:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
Fazit
Bpftrace ist wunderbar! Bpftrace ist die Zukunft!
Wenn Sie mehr über ihn erfahren möchten, empfehle ich Ihnen, sich mit
seiner Führung sowie dem
ersten Beitrag von 2019 auf Brendan Greggs Blog vertraut zu machen.
Gutes Debuggen!