1943 entwickelten die amerikanischen Neuropsychologen McCallock und Pitts ein Computermodell eines neuronalen Netzwerks, und 1958 erkannte das
erste funktionierende einschichtige Netzwerk einige Buchstaben. Jetzt werden neuronale Netze einfach nicht mehr für das verwendet, um den Wechselkurs vorherzusagen, Krankheiten zu diagnostizieren, Autopiloten zu erstellen und Grafiken in Computerspielen zu erstellen. Fast das letzte und reden.
Evgeni Tumanov arbeitet als Deep Learning-Ingenieur bei
NVIDIA . Basierend auf den Ergebnissen seiner Rede auf der HighLoad ++ - Konferenz haben wir eine Geschichte über die Verwendung von maschinellem Lernen und Deep Learning in Grafiken vorbereitet. Maschinelles Lernen endet nicht mit NLP, Computer Vision, Empfehlungssystemen und Suchaufgaben. Auch wenn Sie mit diesem Bereich nicht sehr vertraut sind, können Sie die Best Practices aus dem Artikel in Ihrem Bereich oder Ihrer Branche anwenden.
Die Geschichte wird aus drei Teilen bestehen. Wir werden die Aufgaben in der Grafik überprüfen, die mit Hilfe des maschinellen Lernens gelöst werden, die Hauptidee erhalten und den Fall der Anwendung dieser Idee in einer bestimmten Aufgabe und speziell beim
Rendern von Wolken beschreiben .
Betreutes DL / ML in Grafik oder Lehrerausbildung in Grafik
Lassen Sie uns zwei Gruppen von Aufgaben analysieren. Zunächst bezeichnen wir sie kurz.
Real-World oder Render-Engine :
- Erstellung glaubwürdiger Animationen: Fortbewegung, Gesichtsanimation.
- Nachbearbeitung gerenderter Bilder: Supersampling, Anti-Aliasing.
- Slowmotion: Frame-Interpolation.
- Erzeugung von Materialien.
Die zweite Gruppe von Aufgaben wird jetzt üblicherweise als "
schwerer Algorithmus " bezeichnet. Wir umfassen Aufgaben wie das Rendern komplexer Objekte wie Wolken und
physikalische Simulationen : Wasser, Rauch.
Unser Ziel ist es, den grundlegenden Unterschied zwischen den beiden Gruppen zu verstehen. Lassen Sie uns die Aufgaben genauer betrachten.
Erstellung glaubwürdiger Animationen: Fortbewegung, Gesichtsanimation
In den letzten Jahren sind viele
Artikel erschienen , in denen Forscher neue Möglichkeiten anbieten, um schöne Animationen zu generieren. Die Arbeit von Künstlern zu verwenden ist teuer, und sie durch einen Algorithmus zu ersetzen, wäre für alle sehr vorteilhaft. Vor einem Jahr arbeiteten wir bei NVIDIA an einem Projekt, bei dem wir uns mit der Gesichtsanimation von Charakteren in Spielen beschäftigten: das Synchronisieren des Gesichts des Helden mit der Audiospur der Sprache. Wir haben versucht, das Gesicht so wiederzubeleben, dass sich jeder Punkt darauf und vor allem die Lippen bewegte, da dies der schwierigste Moment in der Animation ist. Manuell ein Künstler, um dies teuer und für eine lange Zeit zu tun. Welche Möglichkeiten gibt es, um dieses Problem zu lösen und einen
Datensatz dafür zu
erstellen ?
Die erste Möglichkeit besteht darin
, Vokale zu
identifizieren: Der Mund öffnet sich auf den Vokalen, der Mund schließt sich auf den Konsonanten . Dies ist ein einfacher Algorithmus, aber zu einfach. In Spielen wollen wir mehr Qualität. Die zweite Möglichkeit besteht darin
, die Leute dazu zu bringen, verschiedene Texte zu lesen und ihre Gesichter aufzuschreiben und dann die Buchstaben, die sie aussprechen, mit den Gesichtsausdrücken zu vergleichen. Dies ist eine gute Idee, und wir haben dies in einem gemeinsamen
Projekt mit Remedy Entertainment getan. Der einzige Unterschied ist, dass wir im Spiel kein Video zeigen, sondern ein 3D-Modell von Punkten. Um einen Datensatz zusammenzustellen, müssen Sie verstehen, wie sich bestimmte Punkte auf dem Gesicht bewegen. Wir nahmen Schauspieler mit, baten darum, Texte mit unterschiedlichen Intonationen zu lesen, drehten mit sehr guten Kameras aus verschiedenen Winkeln, stellten dann das 3D-Modell der Gesichter auf jedem Bild wieder her und sagten die Position der Punkte auf dem Gesicht durch Ton voraus.
Bildnachbearbeitung rendern: Supersampling, Anti-Aliasing
Stellen Sie sich einen Fall aus einem bestimmten Spiel vor: Wir haben eine Engine, die Bilder in verschiedenen Auflösungen generiert. Wir möchten das Bild in einer Auflösung von 1000 × 500 Pixel rendern und dem Player 2000 × 1000 zeigen - dies wird schöner. Wie erstelle ich einen Datensatz für diese Aufgabe?
Rendern Sie das Bild zuerst in hoher Auflösung, verringern Sie dann die Qualität und versuchen Sie dann, das System so zu trainieren, dass das Bild von niedriger Auflösung in hohe Auflösung konvertiert wird.
Slowmotion: Frame-Interpolation
Wir haben ein Video und möchten, dass das Netzwerk Frames in der Mitte hinzufügt - um Frames zu interpolieren. Die Idee liegt auf der Hand - ein echtes Video mit einer großen Anzahl von Bildern aufzunehmen, Zwischenbilder zu entfernen und vorherzusagen, was vom Netzwerk entfernt wurde.
Materialerzeugung
Wir werden uns nicht viel mit der Erzeugung von Materialien befassen. Das Wesentliche ist, dass wir zum Beispiel ein Stück Holz in verschiedenen Beleuchtungswinkeln nehmen und die Ansicht aus anderen Winkeln interpolieren.
Wir haben die erste Gruppe von Problemen untersucht. Der zweite ist grundlegend anders. Wir werden später über das Rendern komplexer Objekte wie Wolken sprechen, aber jetzt werden wir uns mit physikalischen Simulationen befassen.
Physikalische Simulationen von Wasser und Rauch
Stellen Sie sich einen Pool vor, in dem sich bewegte feste Objekte befinden. Wir wollen die Bewegung von Flüssigkeitsteilchen vorhersagen. Zum Zeitpunkt
t befinden sich Partikel im Pool, und zum Zeitpunkt
t + Δt möchten wir ihre Position ermitteln. Für jedes Teilchen rufen wir ein neuronales Netzwerk auf und erhalten eine Antwort, wo es sich im nächsten Frame befindet.
Um das Problem zu lösen, verwenden
wir die Navier-Stokes-Gleichung , die die Bewegung einer Flüssigkeit beschreibt. Für eine plausible, physikalisch korrekte Simulation von Wasser müssen wir die Gleichung oder Annäherung daran lösen. Dies kann auf rechnerische Weise erfolgen, von denen viele in den letzten 50 Jahren erfunden wurden: der SPH-, FLIP- oder positionsbasierte Fluid-Algorithmus.
Der Unterschied zwischen der ersten Aufgabengruppe und der zweiten
In der ersten Gruppe ist der Lehrer für den Algorithmus etwas oben: eine Aufzeichnung aus dem wirklichen Leben, wie im Fall von Einzelpersonen, oder etwas aus der Engine, zum Beispiel das Rendern von Bildern. In der zweiten Gruppe von Problemen verwenden wir die Methode der Computermathematik. Aus dieser thematischen Aufteilung entsteht eine Idee.
Hauptidee
Wir haben eine rechnerisch komplexe Aufgabe, die mit der klassischen Methode der Computeruniversität lang, schwer und schwer zu lösen ist. Um es zu lösen und zu beschleunigen, vielleicht sogar ein wenig an Qualität zu verlieren, brauchen wir:
- Finden Sie den zeitaufwändigsten Ort in der Aufgabe, an dem der Code am längsten dauert.
- sehen, was diese Linie produziert;
- Versuchen Sie, das Ergebnis einer Linie mithilfe eines neuronalen Netzwerks oder eines anderen Algorithmus für maschinelles Lernen vorherzusagen.
Dies ist eine allgemeine Methodik und die Hauptidee ist ein Rezept, wie man eine Anwendung für maschinelles Lernen findet. Was sollten Sie tun, um diese Idee nützlich zu machen? Es gibt keine genaue Antwort - nutzen Sie Kreativität, schauen Sie sich Ihre Arbeit an und finden Sie sie. Ich mache Grafiken und bin mit anderen Bereichen nicht so vertraut, aber ich kann mir vorstellen, dass man im akademischen Umfeld - in Physik, Chemie, Robotik - definitiv Anwendung finden kann. Wenn Sie eine komplexe physikalische Gleichung an Ihrem Arbeitsplatz lösen, finden Sie möglicherweise auch Anwendung für diese Idee. Betrachten Sie der Klarheit halber einen bestimmten Fall.
Cloud-Rendering-Aufgabe
Wir waren vor sechs Monaten bei NVIDIA an diesem Projekt beteiligt: Die Aufgabe besteht darin, eine physikalisch korrekte Wolke zu zeichnen, die als Dichte der Flüssigkeitströpfchen im Weltraum dargestellt wird.
Eine Wolke ist ein physikalisch komplexes Objekt, eine Suspension von Flüssigkeitströpfchen, die nicht als festes Objekt modelliert werden kann.
Es wird nicht möglich sein, der Wolke eine Textur aufzuerlegen und zu rendern, da Wassertropfen im 3D-Raum nur schwer geometrisch lokalisiert und an sich komplex sind: Sie absorbieren praktisch keine Farbe, sondern reflektieren sie anisotrop - in alle Richtungen auf unterschiedliche Weise.
Wenn Sie einen Wassertropfen betrachten, auf den die Sonne scheint, und die Vektoren von Auge und Sonne auf einem Tropfen parallel sind, wird ein großer Lichtintensitätspeak beobachtet. Dies erklärt das physikalische Phänomen, das jeder gesehen hat: Bei sonnigem Wetter ist einer der Wolkenränder sehr hell, fast weiß. Wir betrachten den Rand der Wolke, und die Sichtlinie und der Vektor von diesem Rand zur Sonne sind fast parallel.

Die Wolke ist ein physikalisch komplexes Objekt und ihre Wiedergabe nach dem klassischen Algorithmus erfordert viel Zeit. Wir werden etwas später über den klassischen Algorithmus sprechen. Abhängig von den Parametern kann der Vorgang Stunden oder sogar Tage dauern. Stellen Sie sich vor, Sie sind Künstler und zeichnen einen Film mit Spezialeffekten. Sie haben eine komplizierte Szene mit unterschiedlicher Beleuchtung, mit der Sie spielen möchten. Wir haben eine Wolkentopologie gezeichnet - sie gefällt mir nicht, und Sie möchten sie neu zeichnen und genau dort eine Antwort erhalten. Es ist wichtig, so schnell wie möglich eine Antwort auf eine Parameteränderung zu erhalten. Das ist ein Problem. Versuchen wir daher, diesen Prozess zu beschleunigen.
Klassische Lösung
Um das Problem zu lösen, müssen Sie diese komplizierte Gleichung lösen.

Die Gleichung ist hart, aber lassen Sie uns ihre physikalische Bedeutung verstehen. Stellen Sie sich einen Strahl vor, der von einer Wolke durchbohrt wird, die eine Wolke durchbohrt. Wie gelangt Licht in diese Richtung in die Kamera? Erstens kann das Licht den Austrittspunkt des Strahls aus der Wolke erreichen und sich dann entlang dieses Strahls innerhalb der Wolke ausbreiten.
Für die zweite Methode der "Lichtausbreitung entlang der Richtung" ist der integrale Term der Gleichung. Seine physikalische Bedeutung ist wie folgt.
Betrachten Sie das Segment innerhalb der Wolke auf dem Strahl - vom Eintrittspunkt zum Austrittspunkt. Die Integration erfolgt genau über dieses Segment, und für jeden Punkt darauf betrachten wir die sogenannte
indirekte Lichtenergie L (x, ω) - die Bedeutung des Integrals I
1 - indirekte Beleuchtung am Punkt. Es erscheint aufgrund der Tatsache, dass Tropfen auf unterschiedliche Weise Sonnenlicht reflektieren. Dementsprechend kommt eine große Menge von vermittelten Strahlen von umgebenden Tröpfchen auf den Punkt. I
1 ist das Integral über der Kugel, das einen Punkt auf dem Strahl umgibt. Im klassischen Algorithmus wird es nach der
Monte-Carlo- Methode gezählt.
Der klassische Algorithmus.
- Rendern Sie ein Bild aus Pixeln und erzeugen Sie einen Strahl, der von der Mitte der Kamera zu einem Pixel und dann weiter geht.
- Wir überqueren den Strahl mit der Wolke, wir finden die Eintritts- und Austrittspunkte.
- Wir betrachten den letzten Term der Gleichung: kreuzen, mit der Sonne verbinden.
- Erste Schritte Wichtige Stichproben
Wie man die Monte-Carlo-Schätzung I
1 betrachtet, werden wir nicht analysieren, da sie schwierig und nicht so wichtig ist. Es genügt zu sagen, dass dies der längste und schwierigste Teil des gesamten Algorithmus ist.
Wir verbinden neuronale Netze
Aus der Hauptidee und Beschreibung des klassischen Algorithmus folgt ein Rezept, wie neuronale Netze auf diese Aufgabe angewendet werden können. Am schwierigsten ist es, den Monte-Carlo-Wert zu berechnen. Es gibt eine Zahl, die indirekte Beleuchtung an einem Punkt bedeutet, und genau das wollen wir vorhersagen.

Wir haben uns für den Ausgang entschieden, jetzt werden wir den Eingang verstehen - aus welchen Informationen wird ersichtlich, wie groß das indirekte Licht am Punkt ist. Dies ist Licht, das von den vielen Wassertropfen reflektiert wird, die den Punkt umgeben. Die Lichttopologie wird stark von der Dichte-Topologie um den Punkt, der Richtung zur Quelle und der Richtung zur Kamera beeinflusst.
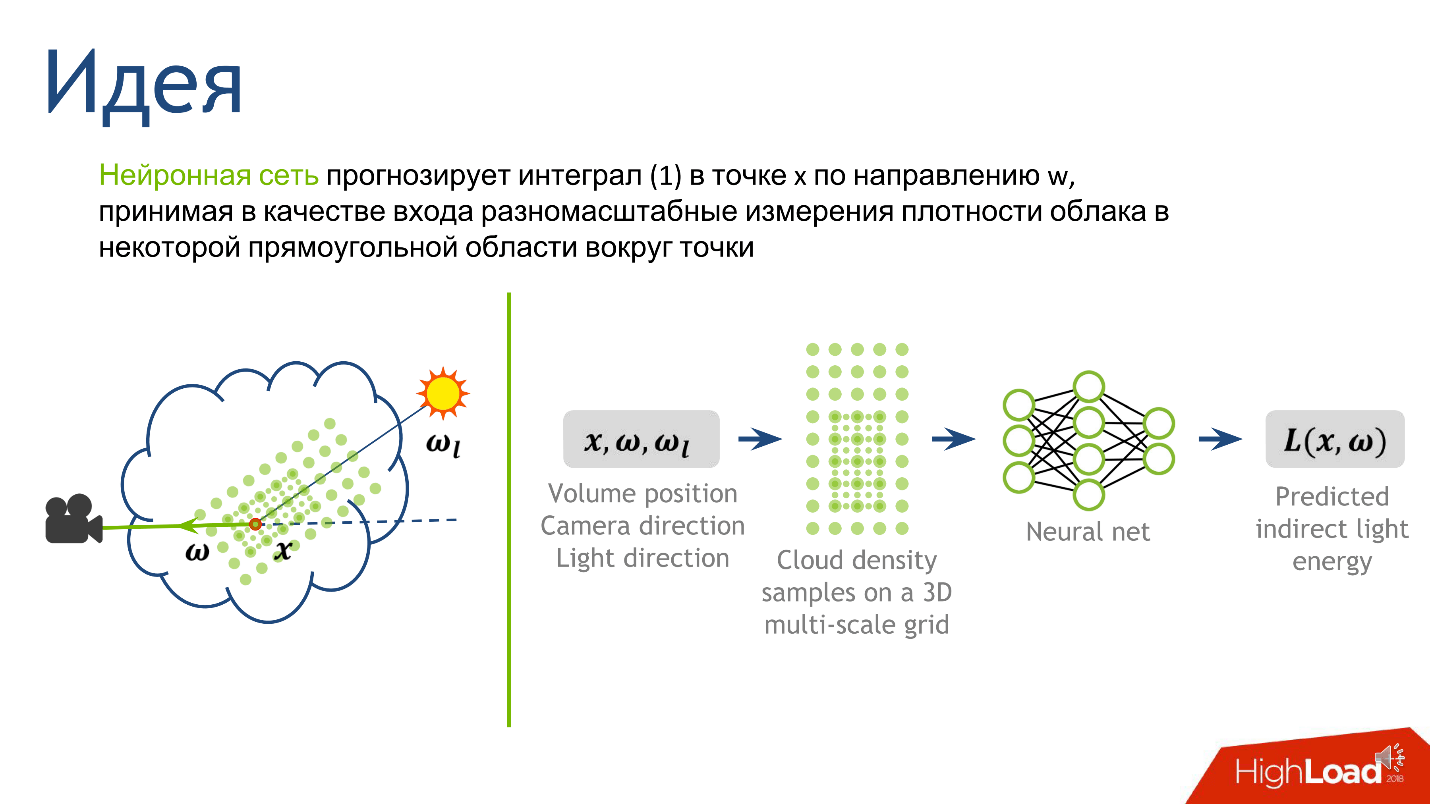
Um den Eingang zum neuronalen Netzwerk zu konstruieren, beschreiben wir die lokale Dichte. Es gibt viele Möglichkeiten, dies zu tun, aber wir haben uns auf den Artikel
Deep Scattering: Rendern atmosphärischer Wolken mit Strahlungsvorhersage neuronaler Netze konzentriert, Kallwcit et al. 2017 und viele Ideen kamen von dort.
Kurz gesagt sieht die Methode der lokalen Darstellung der Dichte um einen Punkt so aus.
- Fixiere eine ziemlich kleine Konstante . Sei es der mittlere freie Weg in der Wolke.
- Zeichnen Sie um einen Punkt in unserem Segment ein volumetrisches rechteckiges Gitter fester Größe , z. B. 5 * 5 * 9. In der Mitte dieses Würfels wird unser Punkt sein. Der Gitterabstand ist eine kleine feste Konstante. An den Gitterknoten messen wir die Dichte der Wolke.
- Erhöhen wir die Konstante um das Zweifache , zeichnen ein größeres Gitter und machen dasselbe - messen Sie die Dichte an den Knoten des Gitters.
- Wiederholen Sie den vorherigen Schritt mehrmals . Wir haben dies 10 Mal gemacht und nach dem Verfahren haben wir 10 Gitter erhalten - 10 Tensoren, von denen jeder die Wolkendichte speichert, und jeder der Tensoren deckt eine immer größere Nachbarschaft um den Punkt ab.
Dieser Ansatz gibt uns die detaillierteste Beschreibung eines kleinen Gebiets - je näher am Punkt, desto detaillierter die Beschreibung. Über die Ausgabe und Eingabe des Netzwerks entschieden, bleibt abzuwarten, wie es trainiert wird.
Schulung
Wir werden 100 verschiedene Wolken mit unterschiedlichen Topologien erzeugen. Wir werden sie einfach mit dem klassischen Algorithmus rendern, aufschreiben, was der Algorithmus in der Zeile empfängt, in der er die Monte-Carlo-Integration durchführt, und Eigenschaften aufschreiben, die dem Punkt entsprechen. So erhalten wir einen Datensatz, über den wir lernen können.

Was zu lehren oder Netzwerkarchitektur
Die Netzwerkarchitektur für diese Aufgabe ist nicht der wichtigste Moment, und wenn Sie nichts verstehen - keine Sorge - ist dies nicht das Wichtigste, was ich vermitteln wollte. Wir haben die folgende Architektur verwendet: Für jeden Punkt gibt es 10 Tensoren, von denen jeder auf einem immer größer werdenden Gitter berechnet wird. Jeder dieser Tensoren fällt in den entsprechenden Block.
- Zuerst in die erste reguläre vollständig verbundene Schicht .
- Nach dem Verlassen der ersten vollständig verbundenen Schicht in der zweiten vollständig verbundenen Schicht, die keine Aktivierung hat.
Eine vollständig verbundene Schicht ohne Aktivierung ist nur eine Multiplikation mit einer Matrix. Zum Ergebnis der Multiplikation mit der Matrix addieren wir die Ausgabe des vorherigen
Restblocks und wenden erst dann die Aktivierung an.
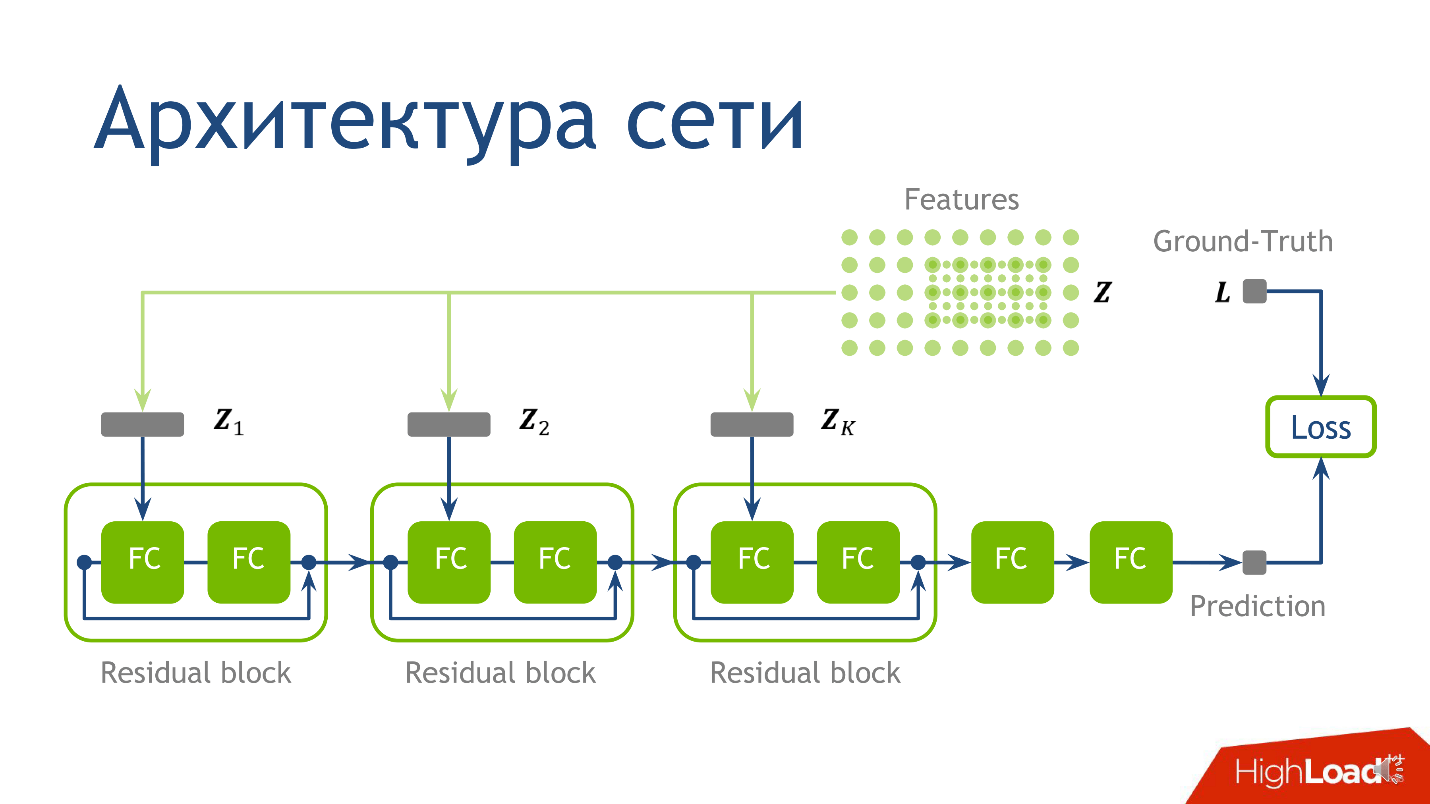
Wir nehmen einen Punkt, zählen die Werte auf jedem der Gitter, setzen die erhaltenen Tensoren in den entsprechenden Restblock - und Sie können
Rückschlüsse auf das neuronale Netzwerk ziehen - Produktionsmodus des Netzwerks. Wir haben das gemacht und dafür gesorgt, dass wir Bilder von Wolken bekommen.
Ergebnisse
Die erste Beobachtung - wir haben bekommen, was wir wollten: Ein neuronaler Netzanruf funktioniert im Vergleich zur Monte-Carlo-Schätzung schneller, was bereits gut ist.
Es gibt jedoch noch eine andere Beobachtung zu den Ergebnissen des Trainings - es ist die Konvergenz der Anzahl der Proben. Worüber sprichst du?

Wenn Sie ein Bild rendern, schneiden Sie es in kleine Kacheln - Pixelquadrate, z. B. 16 * 16. Betrachten Sie eine Bildkachel ohne Verlust der Allgemeinheit. Wenn wir diese Kachel rendern, setzen wir für jedes Pixel der Kamera viele Strahlen frei, die einem Pixel entsprechen, und fügen den Strahlen ein wenig Rauschen hinzu, so dass sie sich geringfügig unterscheiden. Diese Strahlen werden als
Anti-Aliasing bezeichnet und wurden erfunden, um das Rauschen im endgültigen Bild zu reduzieren.
- Wir setzen für jedes Pixel mehrere Anti-Aliasing-Strahlen frei.
- Im inneren Teil des Strahls von der Kamera, in der Wolke, in einem Segment berechnen wir n Stichproben von Punkten, an denen wir eine Monte-Carlo-Bewertung durchführen oder ein Netzwerk für sie aufrufen möchten.
Es gibt noch Beispiele, die der Verbindung mit den Lichtquellen entsprechen. Sie erscheinen, wenn wir einen Punkt mit einer Lichtquelle verbinden, zum Beispiel mit der Sonne. Dies ist einfach zu tun, da die Sonne die Strahlen sind, die parallel zueinander auf die Erde fallen. Zum Beispiel ist der Himmel als Lichtquelle viel komplizierter, weil er als unendlich entfernte Kugel erscheint, die in Richtung eine Farbfunktion hat. Wenn der Vektor gerade vertikal in den Himmel schaut, ist die Farbe blau. Je niedriger desto heller. Am unteren Rand der Kugel befindet sich normalerweise eine neutrale Farbe, die die Erde imitiert: grün, braun.
Wenn wir einen Punkt mit dem Himmel verbinden, um zu verstehen, wie viel Licht in ihn eindringt, setzen wir immer ein paar Strahlen frei, um eine Antwort zu erhalten, die zur Wahrheit konvergiert. Wir geben mehr als einen Strahl frei, um eine bessere Note zu erhalten. Daher benötigt das gesamte
Pipeline-Rendering so viele Beispiele.
Als wir das neuronale Netzwerk trainierten, stellten wir fest, dass es eine viel durchschnittlichere Lösung lernt. Wenn wir die Anzahl der Stichproben festlegen, sehen wir, dass der klassische Algorithmus in der linken Zeile der Bildspalte konvergiert und das Netzwerk nach rechts lernt. Dies bedeutet nicht, dass die ursprüngliche Methode schlecht ist - wir konvergieren nur schneller. Wenn wir die Anzahl der Proben erhöhen, wird die ursprüngliche Methode immer näher an dem sein, was wir erhalten.
Unser Hauptergebnis, das wir erzielen wollten, ist eine Erhöhung der Rendergeschwindigkeit. Für eine bestimmte Wolke in einer bestimmten Auflösung mit Beispielparametern sehen wir, dass die vom Netzwerk und der klassischen Methode erhaltenen Bilder nahezu identisch sind, aber wir erhalten das richtige Bild 800-mal schneller.

Implementierung
Es gibt ein Open Source-Programm für die 3D-Modellierung -
Blender , das den klassischen Algorithmus implementiert. Wir selbst haben keinen Algorithmus geschrieben, sondern dieses Programm verwendet: Wir haben in Blender trainiert und alles aufgeschrieben, was wir für den Algorithmus brauchten. Die Produktion erfolgte ebenfalls im Programm: Wir haben das Netzwerk in
TensorFlow geschult, es mit TensorRT auf C ++ übertragen und das TensorRT-Netzwerk bereits in Blender integriert, da sein Code offen ist.
Da wir alles für Blender getan haben, bietet unsere Lösung alle Funktionen des Programms: Wir können jede Art von Szene und viele Wolken rendern. Die Wolken in unserer Lösung werden durch Erstellen eines Würfels festgelegt, in dem wir die Dichtefunktion auf eine bestimmte Weise für 3D-Programme bestimmen. Wir haben diesen Prozess optimiert - die Cache-Dichte. Wenn der Benutzer dieselbe Wolke auf einem Haufen unterschiedlicher Szeneneinstellungen zeichnen möchte: unter verschiedenen Lichtbedingungen mit unterschiedlichen Objekten auf der Bühne, muss er die Dichte der Wolke nicht ständig neu berechnen. Was passiert ist, können Sie das
Video sehen .
Abschließend wiederhole ich noch einmal die Hauptidee, die ich vermitteln wollte:
Wenn Sie in Ihrer Arbeit lange und hart etwas als einen bestimmten Rechenalgorithmus betrachten und dies nicht zu Ihnen passt - finden Sie den schwierigsten Platz im Code, ersetzen Sie ihn durch ein neuronales Netzwerk und Vielleicht hilft dir das.Neuronale Netze und künstliche Intelligenz sind eines der neuen Themen, die wir im April auf der Saint HighLoad ++ 2019 diskutieren werden . Wir haben bereits mehrere Bewerbungen zu diesem Thema erhalten. Wenn Sie eine coole Erfahrung haben, nicht unbedingt in neuronalen Netzen, reichen Sie vor dem 1. März eine Bewerbung für einen Bericht ein . Wir freuen uns, Sie unter unseren Referenten zu sehen.
Abonnieren Sie den Newsletter, um auf dem Laufenden zu bleiben, wie das Programm aufgebaut ist und welche Berichte akzeptiert werden. Darin veröffentlichen wir nur thematische Sammlungen von Berichten, Artikelübersichten und neuen Videos.