Im
letzten Artikel haben wir die Einschränkungen und Hindernisse untersucht, die auftreten, wenn Sie Daten horizontal skalieren und die ACID-Eigenschaften von Transaktionen garantieren müssen. In diesem Artikel sprechen wir über die FoundationDB-Technologie und verstehen, wie diese Einschränkungen bei der Entwicklung geschäftskritischer Anwendungen überwunden werden können.
FoundationDB ist eine verteilte NoSQL-Datenbank mit serialisierbaren ACID-Transaktionen, in der sortierte Schlüssel-Wert-Speicherpaare gespeichert sind. Schlüssel und Werte können beliebige Folgen von Bytes sein. Es gibt keinen einzigen Inzidenzpunkt - alle Cluster-Maschinen sind gleich. Es selbst verteilt die Daten auf die Cluster-Server und skaliert im laufenden Betrieb: Wenn Sie dem Cluster Ressourcen hinzufügen müssen, fügen Sie einfach die Adresse des neuen Computers auf den Konfigurationsservern hinzu, und die Datenbank nimmt sie selbst auf.
In FoundationDB blockieren sich Transaktionen niemals gegenseitig. Das Lesen erfolgt über die
Multiversion-Versionskontrolle (MVCC) und das Lesen über die
optimistische Parallelitätskontrolle (OCC). Die Entwickler behaupten, dass sich alle Schreibmaschinen im Cluster im selben Rechenzentrum befinden, die Schreiblatenz 2-3 ms und die Leselatenz weniger als eine Millisekunde beträgt. Die Dokumentation enthält Schätzungen von 10-15 ms, was unter realen Bedingungen wahrscheinlich näher an den Ergebnissen liegt.
 * Unterstützt keine ACID-Eigenschaften für mehrere Shards.
* Unterstützt keine ACID-Eigenschaften für mehrere Shards.FoundationDB hat einen einzigartigen Vorteil - das automatische Resharding. Das DBMS selbst sorgt für ein gleichmäßiges Laden der Computer im Cluster: Wenn ein Server voll ist, werden die Daten im Hintergrund an benachbarte Computer weitergegeben. Gleichzeitig bleibt die Garantie für den Serialisierbarkeitsgrad für alle Transaktionen erhalten, und der einzige Effekt, der für die Kunden erkennbar ist, ist eine geringfügige Erhöhung der Latenz der Antworten. Die Datenbank stellt sicher, dass sich die Datenmenge auf den am meisten und am wenigsten belasteten Clusterservern um nicht mehr als 5% unterscheidet.
Architektur
Ein FoundationDB-Cluster besteht logischerweise aus einer Reihe von Prozessen desselben Typs auf verschiedenen physischen Computern. Prozesse haben keine eigenen Konfigurationsdateien, daher sind sie austauschbar. Mehrere feste Prozesse haben eine dedizierte Rolle - Koordinatoren, und jeder Clusterprozess beim Start kennt seine Adressen. Es ist wichtig, dass die Abstürze der Koordinatoren so unabhängig wie möglich sind. Daher ist es am besten, sie auf verschiedenen physischen Maschinen oder sogar in verschiedenen Rechenzentren zu platzieren.
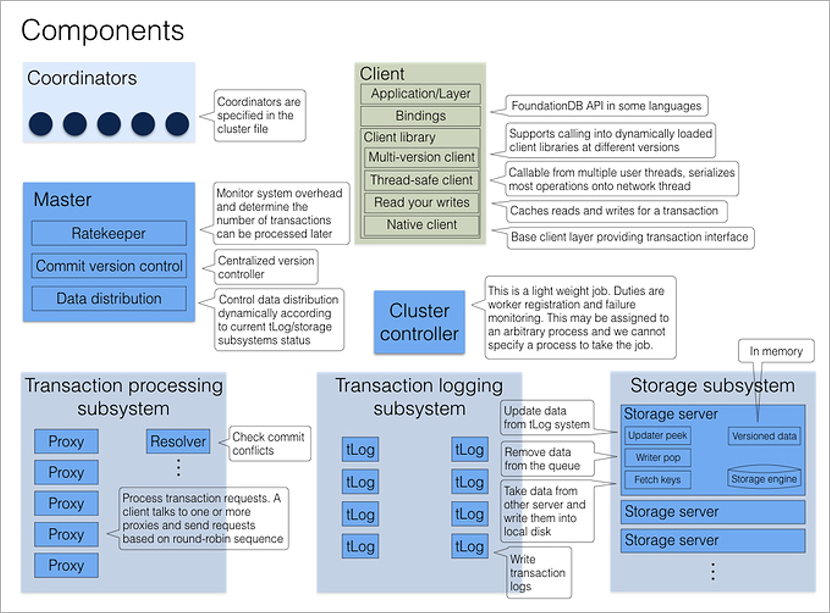
Die Koordinatoren sind sich über den
Paxos- Konsensalgorithmus einig. Sie wählen den Cluster-Controller-Prozess aus, der dann den übrigen Cluster-Prozessen Rollen zuweist. Der Cluster-Controller informiert kontinuierlich alle Koordinatoren darüber, dass er lebt. Wenn die meisten Koordinatoren glauben, er sei tot, wählen sie einfach einen neuen aus. Weder Cluster Controller noch Coordinators sind an der Transaktionsverarbeitung beteiligt. Ihre Hauptaufgabe besteht darin, die Situation des
gespaltenen Gehirns zu beseitigen.
Wenn ein Client eine Verbindung zur Datenbank herstellen möchte, kontaktiert er sofort alle Koordinatoren, um die Adresse des aktuellen Cluster-Controllers zu erfahren. Wenn die meisten Antworten übereinstimmen, erhält es vom Cluster Controller die vollständige aktuelle Clusterkonfiguration (wenn sie nicht übereinstimmen, werden die Koordinatoren erneut aufgerufen).
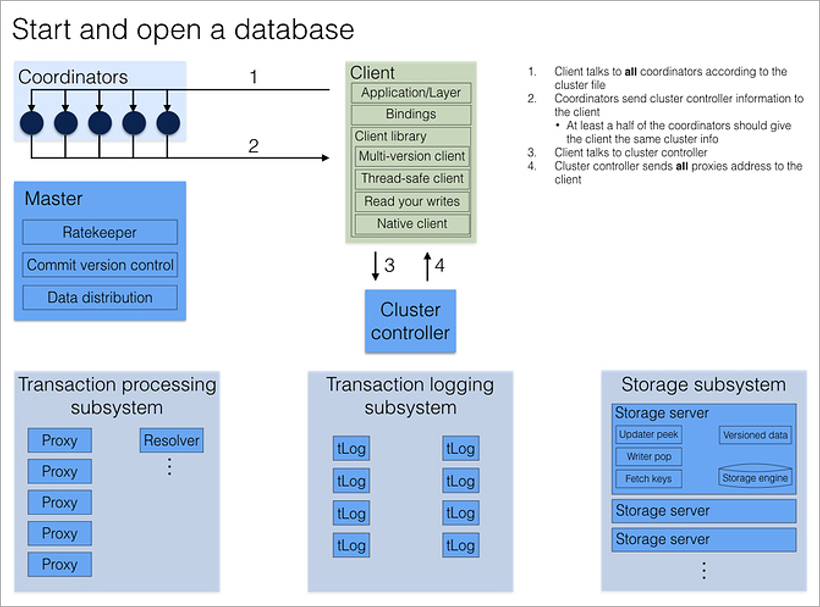
Cluster Controller kennt die Gesamtzahl der verfügbaren Prozesse und verteilt die Rollen: Diese 5 sind Proxy, diese 2 sind Resolver, dieser ist Master. Und wenn einer von ihnen stirbt, wird er sofort einen Ersatz für ihn finden und die notwendige Rolle einem willkürlichen freien Prozess zuweisen. Dies alles geschieht im Hintergrund, für den Anwendungsprogrammierer unsichtbar.
Der Master-Prozess ist verantwortlich für die Nummer der aktuellen Version des Datensatzes (sie steigt mit jedem Datensatz in der Datenbank) sowie für die Verteilung vieler Schlüssel an Speicherserver und die Rateneinschränkung (künstlich geringere Leistung bei hoher Last: Wenn der Cluster weiß, dass der Client wird viele kleine Anfragen stellen, er wird warten, sie gruppieren und das ganze Paket auf einmal beantworten).
Transaktionsprotokollierung und Speicherung sind zwei unabhängige Speichersubsysteme. Der erste ist der temporäre Speicher zum schnellen Schreiben von Daten auf die Festplatte in der Reihenfolge des Empfangs, der zweite ist der permanente Speicher, bei dem die Daten auf der Festplatte in aufsteigender Reihenfolge der Schlüssel sortiert werden. Bei jedem Transaktions-Commit müssen mindestens drei tLog-Prozesse Daten speichern, bevor der Cluster dem Client den Erfolg meldet. Parallel dazu werden Daten im Hintergrund von tLog-Servern auf Speicherserver verschoben (Speicher, auf dem auch redundant ist).
Anfrage bearbeiten
Alle Clientanforderungen verarbeiten Proxy-Prozesse. Beim Öffnen einer Transaktion greift der Client auf einen beliebigen Proxy zu, fragt alle anderen Proxys ab und gibt die aktuelle Versionsnummer der Clusterdaten zurück. Alle nachfolgenden Ablesungen erfolgen bei dieser Versionsnummer. Wenn ein anderer Client die Daten nach dem Öffnen der Transaktion notiert hat, werden die Änderungen einfach nicht angezeigt.
Das Aufzeichnen einer Transaktion ist etwas komplizierter, da Sie Konflikte lösen müssen. Dies schließt den Resolver-Prozess ein, bei dem alle geänderten Schlüssel für einen bestimmten Zeitraum im Speicher gespeichert werden. Wenn der Client die Festschreibungstransaktion abschließt, prüft der Resolver, ob die gelesenen Daten veraltet sind. (Das heißt, ob die Transaktion, die später als meine geöffnet wurde, abgeschlossen wurde und die von mir gelesenen Schlüssel geändert hat.) In diesem Fall wird die Transaktion zurückgesetzt und die Clientbibliothek selbst (!) Führt einen zweiten Festschreibungsversuch durch. Das einzige, woran der Entwickler denken sollte, ist, dass die Transaktionen idempotent sind, dh eine wiederholte Verwendung sollte zu einem identischen Ergebnis führen. Eine Möglichkeit, dies zu erreichen, besteht darin, einen eindeutigen Wert innerhalb der Transaktion zu speichern und zu Beginn der Transaktion deren Vorhandensein in der Datenbank zu überprüfen.
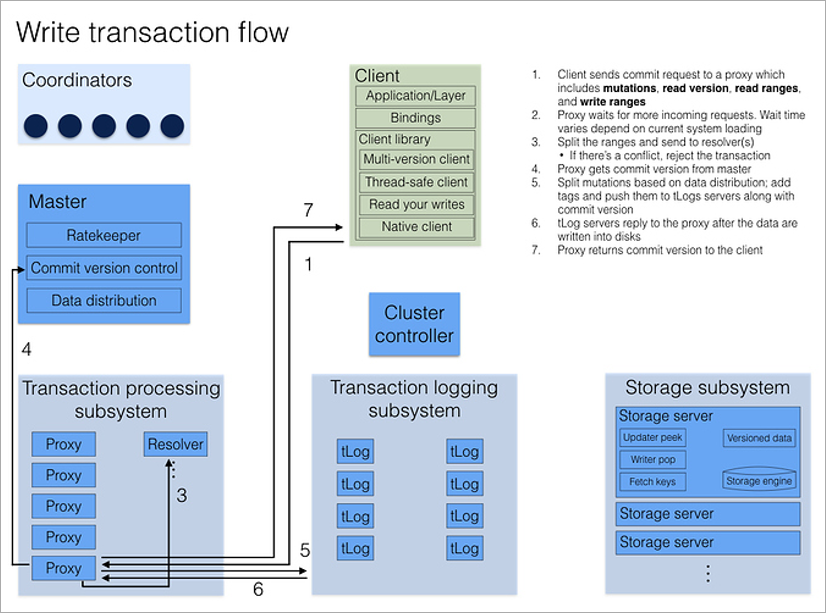
Wie in jedem Client-Server-System gibt es Situationen, in denen die Transaktion erfolgreich abgeschlossen wurde, der Client jedoch aufgrund einer Unterbrechung keine Bestätigung erhalten hat. Die Client-Bibliothek behandelt sie wie jeden anderen Fehler - sie versucht es einfach erneut. Dies könnte möglicherweise zur erneuten Ausführung der gesamten Transaktion führen. Wenn die Transaktion jedoch idempotent ist, gibt es kein Problem damit - es hat keinen Einfluss auf das Endergebnis.
Skalieren
In einem Speichersubsystem können sich Tausende von Servern befinden. Welche von ihnen sollte ein Kunde kontaktieren, wenn er Daten zu einem bestimmten Schlüssel benötigt? Vom Cluster Controller kennt der Client die vollständige Konfiguration des gesamten Clusters und enthält Schlüsselbereiche auf jedem Speicherserver. Daher greift es einfach ohne Zwischenanforderungen direkt auf die gewünschten Speicherserver zu.
Wenn der gewünschte Speicherserver nicht verfügbar ist, übernimmt die Clientbibliothek eine neue Konfiguration von Cluster Controller. Wenn der Cluster infolge eines Serverabsturzes erkennt, dass die Redundanz nicht ausreicht, beginnt er sofort, einen neuen Knoten aus Teilen eines anderen Speichers zu sammeln.
Angenommen, Sie speichern ein Gigabyte an Daten in einer Transaktion. Wie können Sie schnell antworten? Auf keinen Fall hat FoundationDB die Größe einer Transaktion einfach auf 10 Megabyte begrenzt. Darüber hinaus ist dies eine Einschränkung für alle Daten, die die Transaktion
betrifft - Lesen oder Schreiben. Jeder Eintrag in der Datenbank ist ebenfalls begrenzt - der Schlüssel darf 10 Kilobyte nicht überschreiten, der Wert beträgt 100 Kilobyte. (Für eine optimale Leistung empfehlen Entwickler Schlüssel mit einer Länge von 32 Byte und Werte mit einer Länge von 10 Kilobyte.)
Jede Transaktion kann möglicherweise zu einer Konfliktquelle werden und muss dann zurückgesetzt werden. Aus Gründen der Geschwindigkeit ist es daher sinnvoll, die aktuellen Änderungen im RAM und nicht auf der Festplatte beizubehalten, bis der Commit-Befehl eintrifft. Angenommen, Sie schreiben Daten mit einer Last von 1 GB / Sekunde in eine Datenbank. Im Extremfall weist Ihr Cluster dann jede Sekunde 3 GB RAM zu (wir schreiben Transaktionen auf 3 Computern). Wie kann ein solches Lawinenwachstum des verwendeten Speichers begrenzt werden? Es ist sehr einfach, die maximale Transaktionszeit zu begrenzen. In FoundationDB kann eine Transaktion nicht länger als 5 Sekunden dauern. Wenn der Client 5 Sekunden nach dem Öffnen der Transaktion versucht, auf die Datenbank zuzugreifen, ignoriert der Cluster alle seine Befehle, bis er einen neuen öffnet.
Indizes
Angenommen, Sie führen eine Liste mit Personen, jede Person hat eine eindeutige Kennung, wir verwenden diese als Schlüssel und in den Wert schreiben wir alle anderen Attribute - Name, Geschlecht, Alter usw.
| Schlüssel | Wert |
| 12345 | (Ivanov Ivan Ivanovich, M, 35) |
Wie bekomme ich eine Liste aller Personen, die 30 Jahre alt sind, ohne umfassende Suche? In der Regel wird hierfür ein Index in der Datenbank erstellt. Ein Index ist eine weitere Datenansicht, mit der schnell nach zusätzlichen Attributen gesucht werden kann. Wir können einfach Einträge des Formulars hinzufügen:
| Schlüssel | Wert |
| (35, 12345) | '' |
Um die gewünschte Liste zu erhalten, müssen Sie nur noch den Tastenbereich (30, *) durchsuchen. Da FoundationDB nach Schlüssel sortierte Daten speichert, wird eine solche Abfrage sehr schnell ausgeführt. Natürlich belegt der Index zusätzlichen Speicherplatz, aber nur sehr wenig. Bitte beachten Sie, dass nicht alle Attribute dupliziert werden, sondern nur Alter und Kennung.
Es ist wichtig, dass die Vorgänge zum Hinzufügen des Datensatzes selbst und des Index in einer Transaktion ausgeführt werden.
Zuverlässigkeit
FoundationDB ist in C ++ geschrieben. Die Autoren begannen 2009 damit zu arbeiten, die erste Version wurde 2013 veröffentlicht und im März 2015 kaufte Apple sie. Drei Jahre später öffnete Apple unerwartet den Quellcode.
Gerüchten zufolge verwendet Apple es unter anderem zum Speichern von iCloud-Servicedaten.
Erfahrene Entwickler vertrauen neuen Lösungen normalerweise nicht sofort. Es kann Jahre dauern, bis sich die Technologie zuverlässig etabliert und in der Produktion massiv eingesetzt wird. Um diese Zeit zu verkürzen, haben die Autoren eine interessante Erweiterung der Sprache C ++:
Flow vorgenommen . Es ermöglicht Ihnen, die Arbeit mit unzuverlässigen externen Komponenten mit der Möglichkeit einer vollständig vorhersehbaren Wiederholung der Programmausführung elegant zu emulieren. Jeder Aufruf eines Netzwerks oder einer Festplatte ist in einen Wrapper (Actor) eingeschlossen, und jeder Actor verfügt über mehrere Implementierungen. Die Standardimplementierung schreibt Daten wie beabsichtigt auf die Festplatte oder in das Netzwerk. Und der andere schreibt 999 mal von 1000 auf die Festplatte und verliert 1 mal von 1000. Eine alternative Netzwerkimplementierung kann beispielsweise Bytes in Netzwerkpaketen austauschen. Es gibt sogar Schauspieler, die die Arbeit eines unachtsamen Systemadministrators nachahmen. Dadurch kann der Datenordner gelöscht oder zwei Ordner ausgetauscht werden. Entwickler führen
Tausende von Simulationen durch , ersetzen verschiedene Akteure und verwenden Flow, um eine 100% ige Reproduzierbarkeit zu erreichen: Wenn ein Test fehlschlägt, können sie die Simulation neu starten und an derselben Stelle abstürzen. Insbesondere um die Unsicherheit zu beseitigen, die durch das Wechseln der Threads des OS-Schedulers entsteht, ist jeder FoundationDB-Prozess ausschließlich Single-Threaded.
Als ein
Forscher , der
Datenverlustszenarien in fast allen gängigen NoSQL-Lösungen entdeckte, gebeten wurde, FoundationDB zu testen, lehnte er ab und stellte fest, dass er den Punkt nicht erkannte, da die Autoren
einen riesigen Job machten und
sie viel tiefer und gründlicher
testeten als seine eigenen.
Es ist üblich zu glauben, dass Clusterfehler zufällig sind, aber erfahrene Entwickler wissen, dass dies weit davon entfernt ist. Wenn Sie 10 Tausend Festplatten desselben Herstellers und dieselbe Anzahl anderer Festplatten haben, ist die Ausfallrate unterschiedlich. In FoundationDB ist eine sogenannte maschinenbewusste Konfiguration möglich, in der Sie dem Cluster mitteilen können, welche Maschinen sich im selben Rechenzentrum und welche Prozesse auf demselben Computer befinden. Die Datenbank berücksichtigt dies bei der Verteilung der Last auf die Maschinen. Und Maschinen in einem Cluster haben normalerweise unterschiedliche Eigenschaften. FoundationDB berücksichtigt dies ebenfalls, untersucht die Länge der Anforderungswarteschlangen und verteilt die Last auf ausgeglichene Weise: Schwächere Computer erhalten weniger Anforderungen.
Daher bietet FoundationDB ACID-Transaktionen und die höchste Isolationsstufe Serializable auf einem Cluster von Tausenden von Computern. Zusammen mit erstaunlicher Flexibilität und hoher Leistung klingt es nach Magie. Aber Sie müssen für alles bezahlen, daher gibt es einige technologische Einschränkungen.
Einschränkungen
Zusätzlich zu den bereits erwähnten Beschränkungen für die Größe und Länge der Transaktion ist es wichtig, die folgenden Merkmale zu beachten:
- Die Abfragesprache ist nicht SQL, dh Entwickler mit SQL-Erfahrung müssen neu lernen.
- Die Clientbibliothek unterstützt nur 5 Hochsprachen (Phyton, Ruby, Java, Golang und C). Es gibt noch keinen offiziellen Client für C #. Da es keine REST-API gibt, besteht die einzige Möglichkeit, eine andere Sprache zu unterstützen, darin, einen Wrapper über die Standard-C-Bibliothek zu schreiben.
- Es gibt keine Freigabemechanismen. Diese Logik sollte von Ihrer Anwendung bereitgestellt werden.
- Das Datenspeicherformat ist nicht dokumentiert (obwohl es normalerweise auch nicht in kommerziellen Datenbanken dokumentiert ist). Dies ist ein Risiko, denn wenn sich der Cluster plötzlich nicht mehr zusammensetzt, ist nicht sofort klar, was zu tun ist, und er muss sich mit den Quelldateien befassen.
- Ein streng asynchrones Programmiermodell kann Anfängern kompliziert erscheinen.
- Sie müssen ständig über die Idempotenz von Transaktionen nachdenken.
- Wenn Sie lange Transaktionen in kleine Transaktionen aufteilen müssen, müssen Sie sich selbst um die Integrität auf globaler Ebene kümmern.
Aus dem Englischen übersetzt bedeutet „Foundation“ „Foundation“, und die Autoren dieses DBMS sehen seine Rolle folgendermaßen: Sie bieten ein hohes Maß an Zuverlässigkeit auf der Ebene einfacher Datensätze, und jede andere Datenbank kann als Add-On über die Grundfunktionalität implementiert werden. So können Sie zusätzlich zu FoundationDB möglicherweise verschiedene andere Ebenen erstellen - Dokumente, Grafiken usw. Es bleibt die Frage, wie diese Ebenen skaliert werden, ohne an Leistung zu verlieren. Zum Beispiel haben die Autoren von CockroachDB diesen Weg bereits eingeschlagen - indem sie eine SQL-Schicht über der RocksDB (lokaler Schlüsselwertspeicher) erstellt haben und Leistungsprobleme bei relationalen Verknüpfungen auftreten.
Bisher hat Apple zwei Layer über FoundationDB entwickelt und veröffentlicht:
Document Layer (unterstützt die MongoDB-API) und
Record Layer (speichert Datensätze als Feldsätze im
Protokollpufferformat , unterstützt Indizes und ist nur in Java verfügbar). Es ist erfreulich und angenehm überraschend, dass das historisch geschlossene Unternehmen von Apple heute in die Fußstapfen von Google und Microsoft tritt und den Quellcode der darin verwendeten Technologien veröffentlicht.
Perspektiven
Es gibt einen solchen existenziellen Konflikt in der Softwareentwicklung: Das Unternehmen möchte ständig Änderungen und Verbesserungen am Produkt. Gleichzeitig will er zuverlässige Software. Und diese beiden Anforderungen widersprechen sich, denn wenn sich die Software ändert, treten Fehler auf und das Unternehmen leidet darunter. Wenn Sie sich in Ihrem Produkt auf eine zuverlässige, bewährte Technologie verlassen und selbst weniger Code schreiben können, lohnt es sich immer, dies zu tun. In diesem Sinne ist es trotz bestimmter Einschränkungen cool, keine Krücken in verschiedene NoSQL-Datenbanken zu formen, sondern eine produktionserprobte Lösung mit ACID-Eigenschaften zu verwenden.
Vor einem Jahr waren wir
optimistisch in
Bezug auf eine andere Technologie - CockroachDB, aber sie entsprach nicht unseren Leistungserwartungen. Seitdem haben wir unseren Appetit auf die Idee einer SQL-Schicht über einen verteilten Schlüsselwertspeicher verloren und uns daher beispielsweise
TiDB nicht genau
angesehen . Wir planen, FoundationDB als sekundäre Datenbank für die größten Datensätze in unserem Projekt sorgfältig zu testen. Wenn Sie bereits Erfahrung mit der tatsächlichen Verwendung von FoundationDB oder TiDB in der Produktion haben, freuen wir uns über Ihre Meinung in den Kommentaren.