
Im vergangenen Jahr gab es so viele Veröffentlichungen über Microservices, dass es Zeitverschwendung wäre, zu sagen, was es ist und warum. Der Rest der Diskussion wird sich daher auf die Frage konzentrieren, wie diese Architektur implementiert werden kann und warum sie genau konfrontiert wurde und auf welche Probleme sie stieß.
Wir hatten große Probleme in einer kleinen Bank: 3 Python-Monolithen, die durch eine ungeheure Menge synchroner RPC-Interaktionen mit einem großen Volumen an Legacy verbunden waren. Um alle gleichzeitig auftretenden Probleme zumindest teilweise zu lösen, wurde beschlossen, auf eine Microservice-Architektur umzusteigen. Bevor Sie sich jedoch für einen solchen Schritt entscheiden, müssen Sie drei Hauptfragen beantworten:
- Wie man einen Monolithen in Mikrodienste zerlegt und welche Kriterien befolgt werden sollten.
- Wie werden Microservices interagieren?
- Wie zu überwachen?
Tatsächlich werden diesem Artikel kurze Antworten auf diese Fragen gewidmet.
Wie man einen Monolithen in Mikrodienste zerlegt und welche Kriterien befolgt werden sollten.
Diese scheinbar einfache Frage bestimmte letztendlich die gesamte zukünftige Architektur.
Wir sind eine Bank, daher dreht sich das gesamte System um Operationen mit Finanzen und verschiedenen Hilfsmitteln. Es ist sicherlich möglich, finanzielle ACID-Transaktionen mit Sagen auf ein verteiltes System zu übertragen , aber im Allgemeinen ist dies äußerst schwierig. Daher haben wir die folgenden Regeln entwickelt:
- Beachten Sie für Microservices S von SOLID
- Die Transaktion sollte vollständig im Microservice ausgeführt werden - keine verteilten Transaktionen über den Schaden der Datenbank
- Um zu funktionieren, benötigt der Microservice Informationen aus seiner eigenen Datenbank oder aus einer Anfrage
- Versuchen Sie, die Sauberkeit (im Sinne funktionaler Sprachen) von Microservices sicherzustellen
Gleichzeitig war es natürlich unmöglich, sie vollständig zu befriedigen, aber selbst eine teilweise Implementierung vereinfacht die Entwicklung erheblich.
Wie werden Microservices interagieren?
Es gibt viele Optionen, aber am Ende können sie alle mit einfachen „Microservices Exchange Messages“ abstrahiert werden. Wenn Sie jedoch ein synchrones Protokoll implementieren (z. B. RPC über REST), bleiben die meisten Nachteile des Monolithen bestehen, aber die Vorteile von Microservices werden kaum sichtbar. Die naheliegende Lösung bestand also darin, einen beliebigen Nachrichtenbroker zu nehmen und loszulegen. Die Wahl zwischen RabbitMQ und Kafka entschied sich für Letzteres, und hier ist der Grund:
- Kafka ist einfacher und bietet ein einziges Messaging-Modell - Veröffentlichen - Abonnieren
- Es ist relativ einfach, ein zweites Mal Daten von Kafka zu erhalten. Dies ist äußerst praktisch zum Debuggen oder Beheben von Fehlern während einer fehlerhaften Verarbeitung sowie zum Überwachen und Protokollieren.
- Eine klare und einfache Möglichkeit, den Dienst zu skalieren: Partitionen zum Thema hinzugefügt, mehr Abonnenten gestartet - der Rest wird von kafka erledigt.
Zusätzlich möchte ich auf einen sehr hochwertigen und detaillierten Vergleich aufmerksam machen .
Warteschlangen bei kafka + asynchrony ermöglichen es uns:
- Schalten Sie einen Microservice für Updates kurz aus, ohne dass sich daraus Konsequenzen ergeben
- Schalten Sie einen Dienst für längere Zeit aus und kümmern Sie sich nicht um die Datenwiederherstellung. Beispielsweise ist der Fiskalisierungs-Microservice kürzlich gesunken. Es wurde nach 2 Stunden repariert, er nahm die Rohkonten von Kafka und verarbeitete alles. Nach wie vor war es nicht erforderlich, das, was dort geschehen sollte, wiederherzustellen und HTTP-Protokolle und eine separate Tabelle in der Datenbank manuell auszuführen.
- Führen Sie Testversionen von Diensten für aktuelle Daten aus dem Verkauf aus und vergleichen Sie die Ergebnisse ihrer Verarbeitung mit der Version des Dienstes beim Verkauf.
Als Datenserialisierungssystem haben wir uns für AVRO entschieden, warum - beschrieben in einem separaten Artikel .
Unabhängig von der gewählten Serialisierungsmethode ist es jedoch wichtig zu verstehen, wie das Protokoll aktualisiert wird. Obwohl AVRO die Schemaauflösung unterstützt , verwenden wir diese nicht und entscheiden rein administrativ:
- Daten in Themen werden nur über AVRO geschrieben und gelesen. Der Name des Themas entspricht dem Namen des Schemas (und Confluent verfolgt einen anderen Ansatz : Sie schreiben ID-AVRO-Schemata aus der Registrierung in die hohen Bytes der Nachricht, sodass sie unterschiedliche Nachrichtentypen in einem Thema haben können
- Wenn Sie Daten hinzufügen oder ändern müssen, wird in kafka ein neues Schema mit einem neuen Thema erstellt. Anschließend wechseln alle Hersteller zu einem neuen Thema, gefolgt von Abonnenten
Wir speichern die AVRO-Schaltungen selbst in Git-Submodulen und verbinden uns mit allen Kafka-Projekten. Sie beschlossen, noch kein zentrales Systemregister einzuführen.
PS: Kollegen haben die OpenSource-Option gewählt, jedoch nur mit JSON-Schema anstelle von AVRO .
Einige Feinheiten
Jeder Teilnehmer erhält alle Nachrichten vom Thema
Dies ist die Besonderheit des Publish - Subscribe-Interaktionsmodells. Wenn ein Abonnent ein Thema abonniert hat, erhält der Abonnent alle. Wenn der Dienst nur einige der Nachrichten benötigt, muss er diese herausfiltern. Wenn dies zu einem Problem wird, kann ein separater Service-Router erstellt werden, der Nachrichten zu verschiedenen Themen auslegt, wodurch ein Teil der RabbitMQ-Funktionalität implementiert wird, der nicht in der Kafka enthalten ist. Jetzt haben wir einen Python-Abonnenten in einem Thread, der ungefähr 7-5.000 Nachrichten pro Sekunde verarbeitet. Wenn Sie jedoch über PyPy laufen, steigt die Geschwindigkeit auf 11-15.000 / Sek.
Begrenzen Sie die Lebensdauer eines Zeigers in einem Thema
In den Einstellungen der Kafka gibt es einen Parameter, der die Zeit begrenzt, in der sich die Kafka "erinnert", wo der Leser angehalten hat - die Standardeinstellung ist 2 Tage. Es wäre schön, es auf eine Woche anzuheben, damit, wenn das Problem in den Ferien auftritt und 2 Tage nicht gelöst werden, dies nicht zu einem Positionsverlust im Thema führen würde.
Bestätigungszeitlimit lesen
Wenn der Kafka-Leser den Messwert nicht innerhalb von 30 Sekunden bestätigt (ein konfigurierbarer Parameter), glaubt der Broker, dass ein Fehler aufgetreten ist und beim Versuch, den Messwert zu bestätigen, ein Fehler auftritt. Um dies zu vermeiden, senden wir bei der Verarbeitung einer Nachricht über einen längeren Zeitraum Lesebestätigungen, ohne den Zeiger zu bewegen.
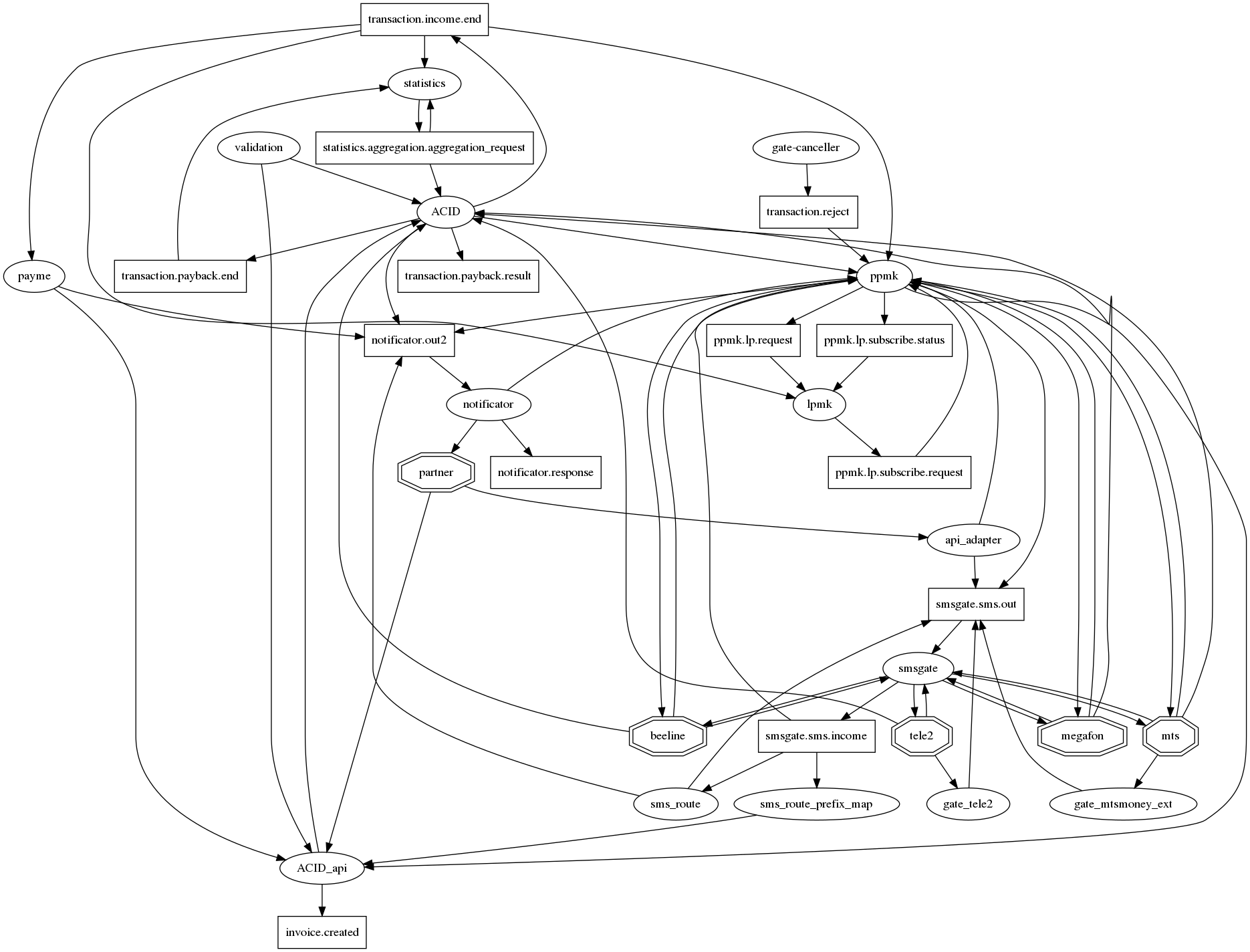
Das Diagramm der Verbindungen ist schwer zu verstehen.
Wenn Sie ehrlich alle Beziehungen in graphviz zeichnen, dann gibt es einen Igel der Apokalypse, der für Mikrodienste mit Dutzenden von Verbindungen in einem Knoten traditionell ist. Um es zumindest irgendwie lesbar zu machen (das Diagramm der Verbindungen), haben wir uns auf die folgende Notation geeinigt: Microservices - Ovale, Themen von Kafka - Rechtecken. Somit ist es in einem Diagramm möglich, sowohl die Tatsache der Interaktion als auch deren Typ anzuzeigen. Aber leider wird es nicht viel besser. Diese Frage ist also noch offen.
Wie zu überwachen?
Selbst als Teil des Monolithen hatten wir Protokolle in Dateien und Sentry. Als wir jedoch über Kafka auf Interaktion umstellten und auf k8s bereitstellten, wurden die Protokolle auf ElasticSearch verschoben und dementsprechend haben wir zuerst das Lesen der Protokolle des Abonnenten in Elastic überwacht. Keine Protokolle - keine Arbeit.
Danach nutzten sie Prometheus und kafka-exporter modifizierte sein Dashboard leicht: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
Als Ergebnis erhalten wir diese Bilder:
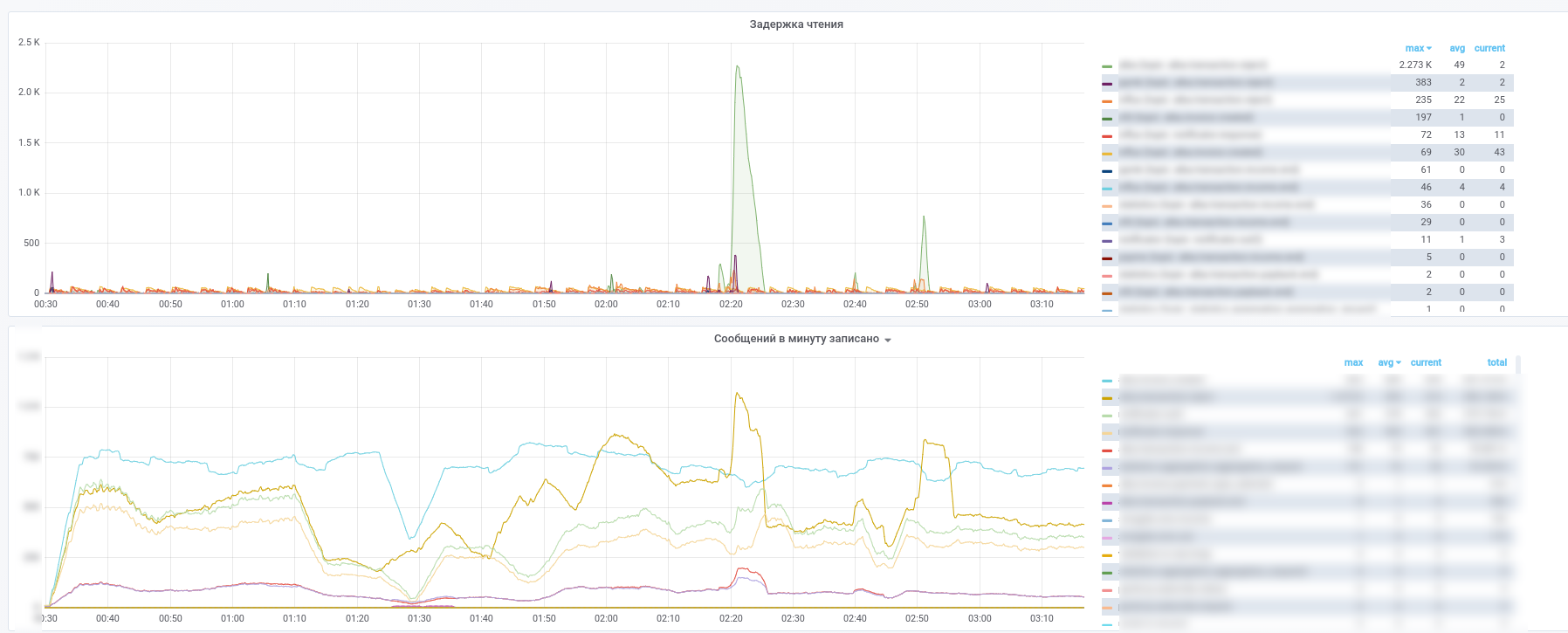
Sie können sehen, welcher Dienst die Verarbeitung welcher Nachrichten beendet hat.
Darüber hinaus werden alle Nachrichten aus Schlüsselthemen (Zahlungstransaktionen, Benachrichtigungen von Partnern usw.) in InfluxDB kopiert, das in derselben Grafik eingerichtet ist. So können wir nicht nur die Tatsache der Nachrichtenübermittlung aufzeichnen, sondern auch verschiedene Beispiele entsprechend dem Inhalt erstellen. Antworten auf Fragen wie „Was ist die durchschnittliche Verzögerungszeit für eine Antwort von einem Service?“ Oder „Unterscheidet sich der Transaktionsfluss heute in diesem Geschäft stark von gestern?“ Sind immer verfügbar.
Um die Analyse von Vorfällen zu vereinfachen, verwenden wir den folgenden Ansatz: Jeder Dienst ergänzt eine Nachricht bei der Verarbeitung mit Metainformationen, die die UUID enthalten, die ausgegeben wird, wenn das System ein Array von Datensätzen des Typs anzeigt:
- Servicename
- UUID des Verarbeitungsprozesses in diesem Microservice
- Prozessstart-Zeitstempel
- Prozesszeit
- Tag-Set
Infolgedessen wird die Nachricht beim Durchlaufen des Rechengraphen mit Informationen über den im Graphen zurückgelegten Pfad angereichert. Es stellt sich ein Analogon von Zipkin / Opentracing für MQ heraus, das es ermöglicht, eine Nachricht zu empfangen, um ihren Pfad in der Grafik einfach wiederherzustellen. Dies erhält einen besonderen Wert in den Fällen, in denen Zyklen in der Grafik erscheinen. Denken Sie an das Beispiel eines kleinen Dienstes, dessen Anteil an Zahlungen nur 0,0001% beträgt. Durch die Analyse der Metainformationen in der Nachricht kann er feststellen, ob sie der Initiator der Zahlung waren, ohne die Datenbank zur Überprüfung zu kontaktieren.